文章目录
- 1.并发
-
- [1.1 可见性](#1.1 可见性)
- [1.2 原子性](#1.2 原子性)
- 2.IO多路复用
-
- [2.1 select](#2.1 select)
- [2.2 poll](#2.2 poll)
- [2.3 epoll](#2.3 epoll)
- [2.4 inode](#2.4 inode)
- 3.内存管理
1.并发
并发对应硬件是cpu,线程是操作系统如何利用cpu资源的一种抽象,是cpu调度的最小单位。一个进程的内存空间是一套完整的虚拟内存地址空间,这个进程中所有线程都共享这一套地址空间。
多线程需调用系统底层API才能开辟(线程本质向cpu申请计算资源),在多线程开辟过程中浪费时间,并且在线程运行中上下文切换部分(左边切换多次,右边切换三次)有用户态和内核态转换浪费在cpu切换时间点上。所以服务端连接的客户端不活跃多(即io次数少)时用单线程。

如下是cpu常见参数:6种指令集即架构(方框),soc是A系列高端,ARM/MIPS都是公司名。

如下2个物理cpu,1个物理cpu有38个逻辑核【76个线程/频率/处理单元processor)】。CPU(S):所有cpu的总逻辑核数。socket:物理cpu数量。top -d 1。

1.1 可见性
c语言中也有volatile:一般用于中断程序,寄存器内存映射场景。


如下第一个core为主线程,第二个core为开辟的线程。


如上线程2不能立即读到线程1写后的最新变量值(线程1写,线程2读),多线程不可见性。如何解决多线程不可见性:加volatile关键字使a在主存和localcache间强制刷新一致。

1.2 原子性
如果线程1和2都进行基于读的变量再对读的变量再进行写,最典型操作i++,T1和T2都进行i++操作。读写原子AtomicInteger/synchronized。

一开始i=0,经过两个线程两次i++操作结果变成了1,这显然是不对的,并且这种情况下不能用volatile保证这样操作的正确性(两个线程既有读操作,又有基于读操作的写操作,可见性只保证一个线程写另一个线程读是正确的,这里可见性不适用)。

现在想做的是将读操作和写操作合为一步,要么同时发生要么同时不发生(原子性)。在保证原子性同时一定以保证可见性为前提(不是并列关系,AtomicInteger类里本质上就是volatile),本身不可见的话没办法保证原子性。

也可用synchronized同步关键字来保证原子性发生,同步关键字同一时间只有一个线程进入代码段。

volatile可见性关键字最轻量级(保证一个线程写,一个线程读能读到最新的值),AtomicInteger(保证既有读操作又有写操作如i++这种场景下能保证操作的原子性)基于volatile,synchronized最重量级(能保证整个代码块中所有操作都是原子性的)。多线程情况下需要自增请使用Atomicxxx类来实现。查看线程top -H,线程thread/进程process区别(process不能共享内存,一个进程一个资源)。


线程传参区分线程:

全局变量s++要加锁(类似synchronized):数字大出现race condition。


c
int a=200;
int b=100;
pthread_mutex_t lock; //互斥锁的宏
void ThreadA(void)
{
printf("线程A.....\n");
pthread_mutex_lock(&lock);
a-=50; //a=a-50
sleep(5);
b+=50; //b=b+50
printf("a:%d,b:%d\n",a,b);
pthread_mutex_unlock(&lock);
}
void ThreadB(void)
{
printf("线程B.....\n");
sleep(1);
pthread_mutex_lock(&lock);//加锁
printf("%d\n",a+b);
pthread_mutex_unlock(&lock);//解锁
}
int main(void)
{
pthread_t tida,tidb;
pthread_mutex_init(&lock,NULL);//建立一个互斥锁
pthread_create(&tida,NULL,(void *)ThreadA,NULL); //创建一个线程,1.句柄,2.线程属性,3.线程函数,4.函数的参数
pthread_create(&tidb,NULL,(void *)ThreadB,NULL);
pthread_join(tida,NULL);//等待一个线程结束
pthread_join(tidb,NULL);
pthread_mutex_destroy(&lock);
return 1;
}
// -server:~/bak$ gcc test.c -lpthread
// -server:~/bak$ ./a.out
// 线程A.....
// 线程B.....
// a:150,b:150
// 3002.IO多路复用
如下A,B...都是客户端,方框是服务端。首先想到应对并发,写一个多线程程序,每个传上来的请求都是一个线程,线程弊端cpu上下文切换,转回单线程。如下while(1)...for...就是单线程。

2.1 select
参考【notes8】socket章节,rset就是bitmap(不是二进制8421计算,而是从左到右012345...对应数字排序),FD_ZERO将rset初始化0,FD_SET将12579对应bitmap上(表示关心哪些,并不是select判断有数据),FD_ISSET对照rset确定当前fd是否有数据。


2.2 poll
pollfds数组替代bitmap,pollfdsi.events = POLLIN:告诉内核,这个fd一旦有数据可读,请把 revents 的 POLLIN 位给我置 1,好让poll 返回后能知道它准备好了。events默认是 0,内核会认为你对任何事件都不关心,于是revents永远0,poll 也就永远收不到就绪通知。
c
#define POLLIN 0x0001 // 表示掩码位
if (fds[i].revents & POLLIN) { // 按位与后非 0 说明位被置 1
2.3 epoll
epoll_wait和前面select和poll不一样,有返回值。最后只遍历nfds,不需要轮询,时间复杂度为O(1)。epoll解决select的4个缺点。

阻塞:发起io读取数据的线程中函数不能返回。同步:拿到io读取完的数据之后,对数据的处理是在接收数据线程的上下文后紧接着处理。异步:回调函数中进行数据处理。






如上看出java比C语言系统调用多的多,因为java要启动jvm虚拟机,jvm要读jdk的lib库等很多操作。如上并没有发现open...xml操作,因为java程序主要启动jvm进程,jvm进程可能又起了很多线程去真正运行main函数,所以加-f。

2.4 inode
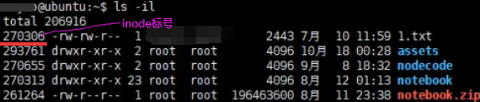
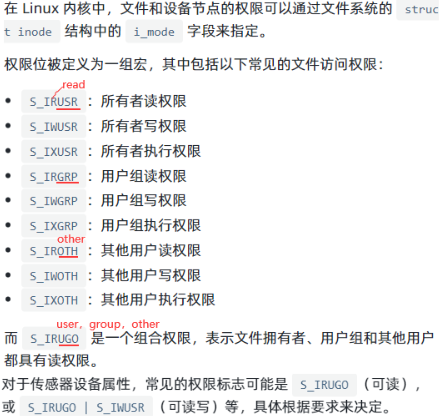
inode【用来存储文件原数据信息,不存储文件内容】以什么样格式存储的呢?整个inode以数组形式存储,每个元素是一个inode,inode会有一个固定128或256字节大小。除了inode数组,fs初始化好后还会生成一个Map映射关系表(存储filename和inode index)。现在要读取/ect/1.txt,整个过程怎么样?先根据文件名到Map中找到inode index,找到下标为假如是3的inode后拿出来如下图左边整个框。当前在读取/ect/1.txt,所以查看是否有读权限,如果有读权限就继续往下找到文件内容所在位置(最后一行,磁盘上块的下标)。
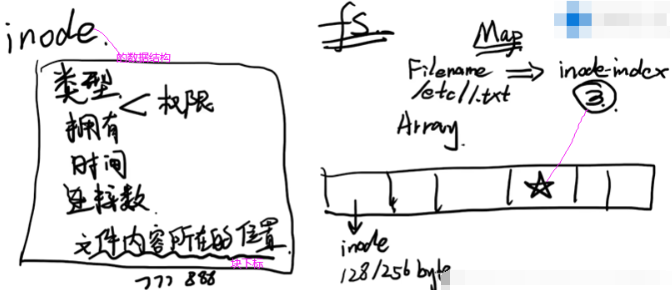
文件内容在磁盘中存储区域如下:以块进行分隔,一个块(fs概念)采用多少扇区(硬件概念)也是有权衡的,比如一个块有好几兆,存一个1k文件也要占一个文件块,造成磁盘空间浪费。块选择过小的话也不好,如果一个块大小1bit,导致一个文件假如是1kb,它所在的块由1千个块组成,在inode中存储文件内容所在位置这个字段时候造成存1千个块信息(1千个块下标),一个inode(存1千个块下标)不可能128/256字节大小了,一个inode会很大,进而导致inode数组会很大,整个inode区大,这样导致磁盘损耗大量空间存储inode信息,较少的空间存储真正文件内容。

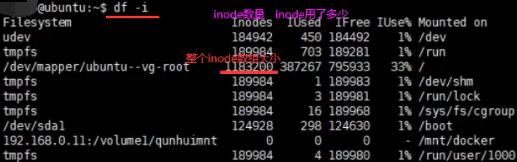
查看linux系统中inode数组以及每个文件所对应inode标号:df -i(inode),查看当前文件夹下文件所在的inode标号是什么ls -il。访问1.txt先查文件名和inode标号映射即Map,1.txt能找到270306这个标号。根据这个标号到1183200这个数组中拿取第270306个标号的inode。根据这个inode信息查看权限,最终找到1.txt在磁盘中存储位置,最后把这些磁盘块进行读取,最终读取到1.txt这个文件。
c
#include <stdio.h>
#include <dirent.h>
int main() {
DIR *dir;
struct dirent *node;
dir = opendir("."); // 打开当前目录
if (dir == NULL) {
printf("无法打开目录\n");
return 1;
}
while ((node = readdir(dir)) != NULL) { // 遍历目录, node->d_name是文件或目录名
if (node->d_type == DT_REG) {
printf("文件: %s,%d\n", node->d_name, DT_REG); // DT_REG:8
} else if (node->d_type == DT_DIR) {
printf("目录: %s,%d\n", node->d_name, DT_DIR); // DT_DIR:4
} else if (node->d_type == DT_LNK) {
printf("符号链接: %s,%d\n", node->d_name,DT_LNK); // DT_LNK:10
} else {
printf("其他类型: %s\n", node->d_name);
}
}
closedir(dir);
return 0;
}如下系统调用作用是:给定一个文件路径,内核查询该文件的索引节点(inode),并将文件的各种属性信息填充到用户提供的 struct stat 缓冲区中, struct stat结构体st_blksize字段设置应用层缓存大小。

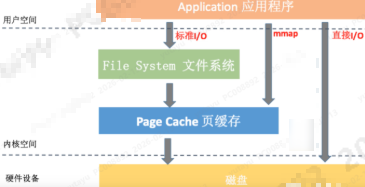
出于性能考虑,读写磁盘文件应使用fread和fwrite(glibc提供,内部维护一个数据缓存减少系统调用次数),不直接使用read和write系统调用,glic还提供fflush函数可在缓冲区满之前,手动将数据刷新到内核缓冲区。
c
int fdatasync(int fd); // 数据完整性是指文件的内容数据已写入到磁盘中
int fsync(int fd); // 文件完整性指的是不止文件的内容数据,文件的元数据也写入磁盘中3.内存管理


如下m.2(2个缺口是sata)也是走pcie协议,m.2有的管脚,pcie插槽都有。

读写文件和申请内存是用户态转内核态的两个例子:malloc的两种实现方式brk和mmap,两者只选一种。brk和mmap申请的都是虚拟内存,不是物理内存,想真拿到物理内存空间还要第一次访问时发现虚拟内存地址未映射到物理内存地址,于是促发一个缺页中断。C语言是malloc,而java和c++中new对象申请内存空间,也是经过这么过程。man syscalls查看系统调用。

3.1 虚拟内存
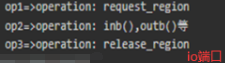
ioremap(驱动)将物理寄存器地址映射成虚拟内存 或 devmem(应用)。通过IO内存访问外设:有的外设将自己的寄存器映射到了物理内存某个区域,那这个区域叫做io内存区域,linux内核访问这个区域能实现对外设控制和读写
c
/*
hello.c:
request_mem_region() //访问外设前需要先申请这片io内存区域
release_mem_region()
ioremap() //io内存区域(上行申请的)是物理地址,内核使用的是虚拟地址,ioremap将物理地址映射为虚拟地址
iounmap()
ioread32()/ioread8()/ioread16() //读取io内存 ,硬件是树莓派,四字节对齐地址读写的话8/16/32位都能读到正常值
iowrite32()/iowrite8()/iowrite16()
*/
#include<linux/module.h>
#include<linux/io.h>
unsigned long gpio_base = 0x3f200000; //树莓派gpio基地址
int gpio_len =0xb3; //寄存器范围
struct timer_list t1; //内核定时器,让1s开一次灯,1s关一次灯
int tdelay;
uint8_t flag=0;
void timer_fn(struct timer_list *t) //定时器回调函数
{
if(flag)
iowrite32(ioread32((void *)(gpio_base+0x1c)) | (1<<4), (void*)(gpio_base+0x1c)); //1c寄存器将gpio置为高电平, 1位一个,GPIO4就是bit4
else
iowrite32(ioread32((void *)(gpio_base+0x28)) | 1<<4, (void*)(gpio_base+0x28)); //28寄存器将gpio置为低电平
flag=!flag; // 翻转状态
mod_timer(&t1,jiffies+msecs_to_jiffies(1000)); //gpio4接了一个led灯,以1s频率亮灭 ,参考【notes10】推迟操作
}
//111111111111111111111111111111111111111111111111111111111111111111111111111
static int __init hello_init(void)
{
printk(KERN_INFO "HELLO LINUX MODULE\n");
// if (! request_mem_region(gpio_base,gpio_len , "gpio")) {
//理论上先申请这片区域,不过树莓派已经将这片区域申请好了,可通过cat /proc/iomem了解i/o内存分配情况(gpio....)
// printk(KERN_INFO " can't get I/O mem address 0x%lx\n", gpio_base);
// return -ENODEV; }
gpio_base = (unsigned long)ioremap(gpio_base,gpio_len);
//下行将基地址内容读出来或上要改变的值,再写回去。iowrite32第一个参数是写的值,第二个参数是写的地址
iowrite32(ioread32((void *)gpio_base)|(1<<12), (void*)gpio_base); //这一整行代码意思是将pin4(3位一组,GPIO4在第4组)设置为输出
printk(KERN_INFO"gpio remap base:0x%lx\n",gpio_base); //打印地址
//如下gpio地址是4字节对齐的,可以用如下8 16 32读, 如果将gpio_base+1,+2,+3就不对了
printk(KERN_INFO"read %x %x %x\n",ioread8((void *)(gpio_base)),ioread16((void *)(gpio_base)),ioread32((void *)(gpio_base)));
timer_setup(&t1,timer_fn,0); //初始化定时器
mod_timer(&t1,jiffies+msecs_to_jiffies(1000)); //设置溢出时间1s
return 0;
}
static void __exit hello_exit(void)
{
printk(KERN_INFO "GOODBYE LINUX\n");
//release_mem_region(gpio_base,gpio_len);
del_timer(&t1); //删除定时器
iounmap((void *)gpio_base);
}
module_init(hello_init);
module_exit(hello_exit); ...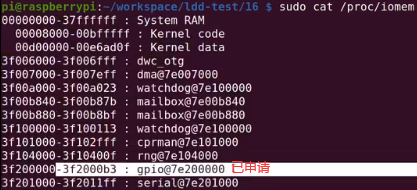
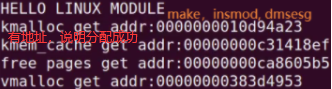
如下make,insmod,打印的地址是虚拟地址,8位读到的是0,16位读到的是1900。

io端口cat /proc/ioports,x86架构的。
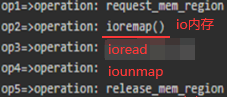
如下固定偏移量映射:程序1的偏移量(初始位置)是0,程序2的偏移量(初始位置)200:如果程序1操作的逻辑地址是100,那么映射的物理地址也100(因为偏移量0);如果程序2操作的逻辑地址是50,映射到物理内存250(因为偏移量200),存在两个缺陷:第一个缺陷:蓝色区域中内存使用率并不高,其中存在很多没有利用起来的内存,我们把没利用起来的内存叫内碎片。

第二个缺陷:当程序运行完,内存被释放,比如程序1执行完后,0-200这块地址被释放出来了,此时程序3使用了内存大小是201,这时程序3没法直接使用0-200这段内存了,假设很长一段时间内都没有占用200以内的内存这样的程序被创建,那么0-200一直被闲置,称这段内存为外碎片。

分页
将内存空间包括逻辑内存(左,页,地址连续)和物理内存(右,帧,地址不连续)都进行切分,分成固定大小很多片,每一片称它为页,降低了内存碎片问题。

页表是每个进程都需要维护的,因为每个进程映射关系是互相独立的,所以不能共用映射表,每个进程有自己的pagetable。

32位os物理地址有2的32次方个即4000000000个地址(内存的一个地址里住着一字节Byte数据)即4GB。32位程序以为自己拥有4GB内存,如两个32位程序,一个使用了2GB内存,另一个使用了3GB内存。但整个物理机只有4GB内存,造成虚拟地址可能比物理地址大,多出来部分可将虚拟地址的页映射到磁盘上。但映射到磁盘上导致下一次读映射到磁盘上这一页内存时会触发一个缺页中断进入到内核态,整个会产生一个大(major)错误。linux下这磁盘部分又叫swapping(与物理帧交换)。

分段/进程
对虚拟地址分成多个段:堆区heap和栈区stack中间是共享内存如Libraries函数库(so/dll文件),参考【notes7】引用传递。
c
struct task_struct { // 该结构体表示进程如下图
volatile long state;
pid_t pid;
pid_t tgid;
struct mm_struct *mm; // 这个结构体中有struct rb_root(红黑树索引目录) 和 struct list_head(链表顺序记录下图VMA【bss,data,heap...】)
struct fs_struct *fs; // 包含了进程运行的目录信息,比如我们在命令行中 cat 一个文件时,比如 "cat a.txt",为什么没有指定 a.txt 的绝对路径也可以打开这个文件呢?进程运行的当前目录是保存在 cat 进程的 fs_struct 的 pwd 字段里
struct files_struct *files; // 一个进程启动,系统就默认会分配三个文件描述符,文件描述符 0 表示 stdin 标准输入,文件描述符 1 表示 stdout 标准输出,文件描述符 2 表示 stderr 标准错误输出。后面进程打开文件 fd 从 3 开始分配
int exit_code; // 参考【notes8】信号
}
如下是state:TASK_RUNNING 并不是说进程正在运行,而是表示进程在时刻准备运行的状态。当处于这个状态的进程获得时间片的时候,就是在运行中。在运行中的进程,一旦要进行一些 I/O 操作,需要等待 I/O 完毕,这个时候会释放CPU,进入睡眠状态【TASK_UNINTERRUPTIBLE不可中断的睡眠状态,慎用,kill也失效】。
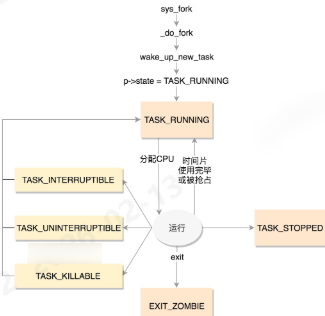
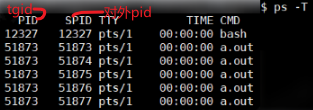
c
// pid_test.c : gcc pid_test.c -lpthread , ./a.out &
#include <stdio.h>
#include <pthread.h>
#include <stdlib.h>
void *foo(void *args) {
sleep(1000);
}
int main() {
pthread_t t[4];
int i;
for (i = 0; i < 4; ++i) { // 0-3: 4个子线程
pthread_create(&t[i], NULL, foo, NULL);
}
for (i = 0; i < 4; ++i) {
pthread_join(t[i], NULL);
}
return 0;
}
【notes8】中进程通讯提到的管道、消息队列、套接字socket、信号都属于下面内核空间。



buffer/cache
如下free206M和available1.6G能用的是哪个?是1.6G。used包含shared,free是真正的空闲,没有任何东西在使用的大小。文件磁盘缓存buffer/cache指读过的文件暂时帮我们缓存到内存中下次再读的时候直接从内存中拿出来就能加速对文件读写操作。比如说现在free的空间只有206M,我有个程序要用1G内存,能用吗?能,buffer/cache这边1.6G中有800M扔出去释放掉+206M=1G给程序。man free查看字段介绍,free中各字段同/proc/meminfo(man proc)。

shell
echo 3 > /proc/sys/vm/drop_caches # 清空vmstat显示的buff/cache
vmstat 1 # 1秒输出一次, bi【block in: 每秒从块设备读取, 单位: 块/秒 即 kb/s】, bo【block out】
dd if=/dev/urandom of=/tmp/1 bs=1M count=500 # 写内存文件【df -T /tmp,mount | grep /tmp ,查看/tmp是不是挂在tmpfs下】,cache页缓存增加,buff磁盘缓存不变:同读(dd if=/tmp/1 of=/dev/null):且bi大于0
dd if=/dev/urandom of=/dev/mmcblkp9 bs=1M count=2048 # 写磁盘文件,buff增加快,cache增加很慢: 同读: 且bi大于03.2 内存分配函数
brk
C语言中有sbrk库函数是对brk的一个封装,如下brk申请内存,内存是连续的:

当前我们对第5,6,7,8四个字节赋int值123。只有第一个字节通brk申请出,却给第5-8字节赋值,这样会不会报错呢?不会,主要原因是在上节讲到的操系内存的分页管理所导致的,也就是说brk申请内存申请最小单位为1页,一般系统中页大小4k,所以brk看似申请1字节其实申请了一页(4096个字节),所以第5-8字节也属于4096字节里,也是当前进程所能支配的内存,所以不报错。


mmap

mmap还有直接将磁盘文件映射到内存作用(类似read,不是malloc)。mmap这么牛干嘛还用read函数?mmap虽减少了内核空间到用户空间拷贝(0拷贝,参考epoll),但mmap没法利用前面讲的buffer/cache对文件缓冲这么一块空间,而且mmap第一次触发的缺页异常耗时不一定比read少。

如下触发大错误因为对文件的映射,将文件映射到内存也是惰性的,这文件没有直接读到内存里,而是当真正需读文件里内容时才会映射到内存里。第一次触发是上面for循环里打印文件内容时到内存中读,发现这一页在查页表时对应是磁盘就触发一个缺页错误,对应是磁盘即触发majflt,将磁盘内容加载到内存中,之后就是一些小错误了。

内核空间
c
/*
top,free,cat /pro/meminfo查看内存使用情况,cat /pro/slabinfo,cat /pro/buddyinfo,proc/sys/vm/下文件是虚拟内存更详细信息,和硬件有关,需要用到物理地址的,都不能使用vmalloc。brk和mmap都是用户空间,如下都是驱动里用的内核空间分配内存:
1.如下两个一般千字节以下空间
kmalloc() 分配空间不清0
kzalloc() 分配空间并清0
kfree()
2.如下对于某些应用需要频繁分配或释放固定大小空间,如下可提前创建一个高速缓冲区,从高速缓冲区中分配空间,这样运行速度会快,内存使用效率也会高
struct kmem_cache //slab分配器/专用高速缓存 速度快 利用率高
kmem_cache_create() //创建高速缓冲区,返回地址保存在上面一行的结构指针中,然后可调用下行函数分配空间,使用完后,free释放
kmem_cache_alloc()
kmem_cache_free()
kmem_cache_destroy() //清除高速缓冲区
3.大块内存
__get_free_page() //按页分配,单独一页
__get_free_pages() //多页
get_zeroed_page() //清0
free_page()
free_pages()
vmalloc() / vfree() //分配的虚拟地址连续,物理地址不连续,效率不高,用在分配大的连续的、只在软件中使用的、用于缓存的内存区域, 和硬件有关和需用到物理地址的都不能用
*/
#include<linux/module.h>
#include<linux/slab.h>
#include<linux/gfp.h> //按页分配__get_free_page(),包含在slab.h中
#include<linux/vmalloc.h>
char * kmlcp;
struct kmem_cache *h_cache;
char * kmemcp;
char * frpgp;
char * vmlcp;
static int hello_init(void)
{
printk(KERN_INFO "HELLO LINUX MODULE\n");
//111111111111111111111111111111111111 1
kmlcp = kmalloc(1024,GFP_KERNEL); //第一个参数:分配空间的大小,第二个参数:常用flag有GFP_KERNEL(kmalloc可休眠)和GFP_ATOMIC(kmalloc不可休眠),中断中分配空间用GFP_ATOMIC
if(!kmlcp) //不休眠可能会失败,所以这里判断下
{
return -ENOMEM;
}
printk(KERN_INFO"kmalloc get addr:%p\n",kmlcp); //分配成功,将地址打印出
//111111111111111111111111111111111111 2
h_cache = kmem_cache_create("h_cache",512,0,SLAB_HWCACHE_ALIGN|SLAB_POISON,NULL);
if(!h_cache)
{
kfree(kmlcp);
return -ENOMEM;
}
kmemcp = kmem_cache_alloc(h_cache,GFP_KERNEL); //第一个参数就是kmem_cache_create返回发的地址
if(!kmemcp)
{
return -ENOMEM;
}
printk(KERN_INFO"kmem_cache get addr:%p\n",kmemcp);
//111111111111111111111111111111111111 3
frpgp =(void *) __get_free_pages(GFP_KERNEL,0); //第二个参数是页面数,以2为底的对数值,0:1 1:2 2:4 3:8 ,填的0分配1个页,填的1分配2个页,填的2分配4个页
if(!frpgp)
{
return -ENOMEM;
}
printk(KERN_INFO"free pages get addr:%p\n",frpgp);
//111111111111111111111111111111111111 4
vmlcp = vmalloc(PAGE_SIZE<<4); //大空间,大于一个页,这里分配16个页空间
if(!vmlcp)
{
return -ENOMEM; //清除分配的资源
}
printk(KERN_INFO"vmalloc get addr:%p\n",vmlcp);
return 0;
}
static void __exit hello_exit(void)
{
printk(KERN_INFO "GOODBYE LINUX\n");
// 1
kfree(kmlcp);
// 2
kmem_cache_free(h_cache,kmemcp);
kmem_cache_destroy(h_cache);
// 3
free_pages((unsigned long)frpgp,0);
// 4
vfree(vmlcp);
}
module_init(hello_init);
module_exit(hello_exit); ...