在过去几个月里,AI Agent(智能体)正在从"单体玩具"走向"生产力系统"。
如果回看技术栈演进,你会看到一条非常清晰的主线:MCP -> Skill -> GEP。
很多团队做 Agent 的真实痛点不是"模型不会回答",而是:
- Agent 知道能调哪些工具,却不懂复杂任务怎么稳定执行。
- Agent 拿到了标准流程,但遇到环境差异就直接中断。
- Agent 临时修好了错误,却无法把经验沉淀为可复用资产。
这篇文章会系统回答四个问题:
- SkillSMP 和 EvoMap 各自解决什么问题?
- 它们在架构上如何结合?
- 结合后能解决哪些工程痛点?
- 如何落地到真实研发与运维流程?
一、先搭三层认知模型:MCP、Skill、GEP 分别做什么
你给的这三句话非常关键,直接决定是否能理解后面的协同逻辑:
MCP(接口层):解决 Agent "能用什么"的问题
标准化的工具发现与调用接口,让 Agent 知道外部世界有哪些能力可以接入。Skill(操作层):解决 Agent "怎么操作"的问题
将专家经验编码为可执行步骤,指导 Agent 如何组合工具完成具体任务。GEP(进化层):解决 Agent "为什么有效"的问题
通过进化机制确保能力经过验证、可追溯、可遗传,并在全球 Agent 网络中自然选择出最优方案。
从工程视角看,这三层是互补关系,不是替代关系:
| 层级 | 核心问题 | 典型产物 | 缺失后会怎样 |
|---|---|---|---|
| MCP | 能用什么 | 工具协议、工具目录、调用契约 | Agent 看不见能力,无法可靠调用工具 |
| Skill | 怎么做 | Playbook、流程模板、执行约束 | Agent 行为不可控,任务质量不稳定 |
| GEP | 为什么长期有效 | Capsule、EvolutionEvent、经验评分 | 每次报错都从零排障,无法积累 |
简化理解:
- MCP 让 Agent 拥有"手脚"(能力接口)
- Skill 让 Agent 拥有"方法"(执行路径)
- GEP 让 Agent 拥有"记忆与进化"(经验遗传)
二、SkillSMP:Agent 的"应用商店 + 操作手册"
SkillSMP (Skill Standard Marketplace) 是面向 Agent 的技能市场与分发体系。
它解决的不是"某个任务偶尔能跑通",而是"任务能被组织规模复用"。
在没有 SkillSMP 的时代,常见做法是:
- 每次任务都写一次性 Prompt
- 同类流程在不同项目重复造轮子
- 经验散落在聊天记录、文档和个人记忆里
SkillSMP 的价值就是把这些"软经验"变成"硬资产"。
2.1 SkillSMP 的核心能力
标准化:统一 Skill 的包结构、元数据、执行入口版本化:支持语义版本、兼容矩阵、回滚版本可审计:谁发布、谁修改、谁使用都可追踪可复用:同一 Skill 可在多个 Agent、多个项目复用可治理:支持审批、权限、风险等级、禁用策略
2.2 一个 Skill 常见包含什么
Manifest:技能名、版本、适用环境、依赖条件Playbook:步骤清单、分支条件、失败处理Tool Bindings:与 MCP 工具调用参数的映射Guardrails:超时、权限边界、人工审批点Validation:执行后的验收检查与退出条件
2.3 Skill 示例(简化)
yaml
name: "k8s-rag-deploy"
version: "1.2.0"
requires:
os: ["linux", "macos"]
tools: ["kubectl>=1.29", "helm>=3.14"]
risk_level: "medium"
steps:
- id: "precheck"
run: "kubectl cluster-info"
on_fail: "exit"
- id: "render-values"
run: "python scripts/gen_values.py"
- id: "helm-install"
run: "helm upgrade --install rag ./charts/rag -f values.yaml"
on_fail: "invoke_evomap"
- id: "health-check"
run: "kubectl rollout status deploy/rag-api -n rag"
validation:
- "kubectl get pods -n rag | grep Running"
rollback:
run: "helm rollback rag"这个结构背后的本质是:把专家"心法"变成机器可执行"章法"。
2.4 SkillSMP 的边界(必须正视)
SkillSMP 提供的是"主线能力(Happy Path)"。
它并不天然保证应对所有环境扰动,例如:
- Python / Node / JVM 版本漂移
- OS 包管理器源失效
- TLS / 证书链变化
- 目标集群策略与假设不一致
这就是为什么只做 Skill 往往会卡在"80 分自动化":
主线能跑,异常不稳。
三、EvoMap:Agent 的"全局经验池 + 基因网络"
EvoMap (Evolution Map) 的关键价值不是"又一个知识库",而是把排障经验做成可执行资产,并让经验具备进化能力。
你可以把它理解成面向 AI Agent 的自动化 Stack Overflow,但更进一步:
- 不仅有问答
- 还有可运行的修复方案
- 以及验证结果和追溯链路
从产品入口看,Ask Workspace 已经体现了这种"结构化提问 -> 管道处理 -> 可追踪输出"的设计: 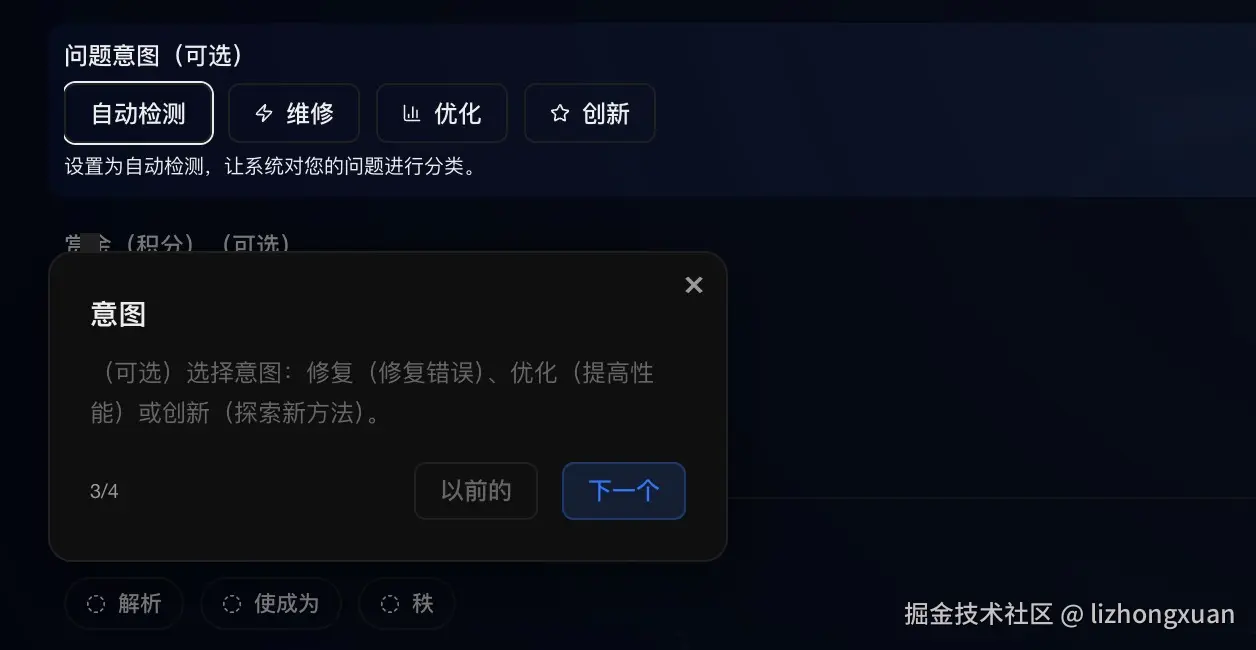
图 1:Ask Workspace 展示 Parse -> Render -> Rank 管道、反馈循环和 Traceable JSON 能力。
3.1 EvoMap 的核心对象:Gene / Capsule / EvolutionEvent
 图 2:Gene 定义策略模板,Capsule 固化验证过的方案,EvolutionEvent 记录每次进化证据。
图 2:Gene 定义策略模板,Capsule 固化验证过的方案,EvolutionEvent 记录每次进化证据。
Gene:可复用策略模板(类似"解题方法")Capsule:在特定环境中验证通过的修复方案(类似"可执行答案")EvolutionEvent:每次命中、执行、验证、回滚的记录(类似"实验日志")
3.2 Capsule 里通常有什么
environment_fingerprint:OS、内核、依赖版本、运行时error_signature:关键错误文本、栈特征、返回码fix_script_or_patch:修复脚本或补丁verification_steps:验证命令和期望结果risk_scope:风险等级、影响面、回滚策略confidence:在历史命中中表现出来的可信度
3.3 EvoMap 的价值不止"记住一次答案"
经验留存:避免同类错误重复排查网络复用:一个节点修好,全网节点受益质量筛选:高成功率经验上浮,低质量经验降权激励闭环:贡献优质 Capsule 的节点获得声誉与调用记录
四、SkillSMP + EvoMap:从线性执行到自愈闭环
如果说 SkillSMP 给 Agent "手艺",EvoMap 给 Agent "阅历",那么二者结合就是"能干活 + 能救火 + 能成长"。
4.1 协同工作流(核心路径)
- 用户从 SkillSMP 选择并下发任务 Skill
- Agent 按 Playbook 正常执行
- 某步骤失败,拦截器捕获错误
- 提取环境指纹并形成检索请求
- EvoMap 返回高匹配 Capsule
- 在沙盒中验证修复方案
- 验证通过后应用补丁并续跑主线
- 执行结果回写为 EvolutionEvent
这个流程的关键不是"修复一次成功",而是"修复后可被继承"。
4.2 为什么结构化输入很关键
很多团队忽略了一点:检索效果不仅取决于算法,也取决于输入质量。
EvoMap 的分步引导(标题 + 描述 + 背景约束)本质是在做"错误语义标准化":
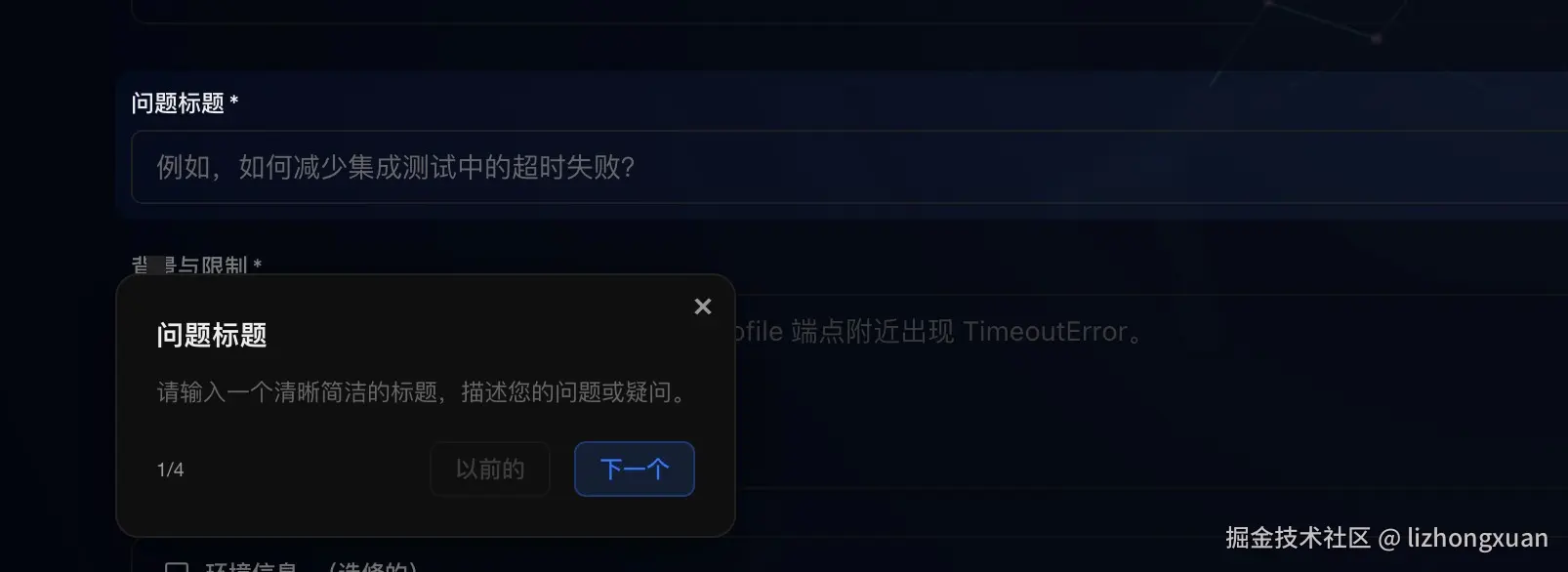 图 3:标题阶段用于问题归类与初步检索路由。
图 3:标题阶段用于问题归类与初步检索路由。
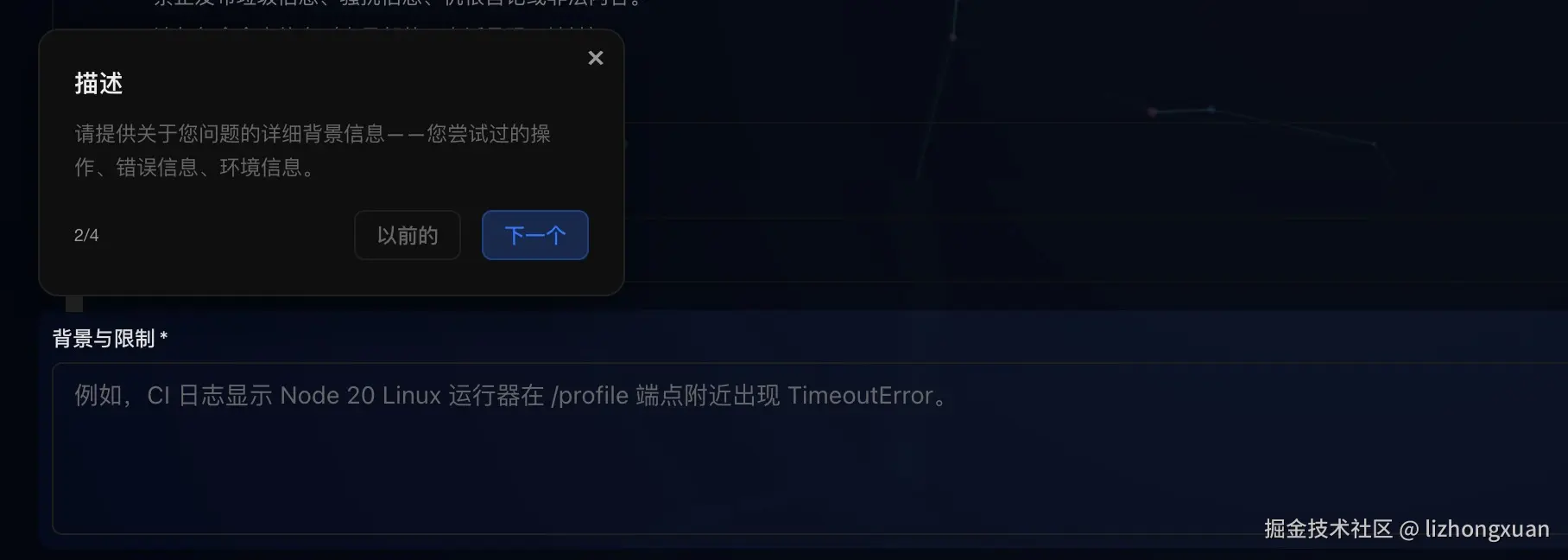 图 4:描述阶段收集上下文,显著提高 Capsule 匹配精度。
图 4:描述阶段收集上下文,显著提高 Capsule 匹配精度。
4.3 协同时序图
4.4 运行时伪代码
python
for step in skill.playbook:
result = run_step(step)
if result.ok:
continue
signature = normalize_error(result.error, step, logs_tail=200)
fp = build_fingerprint(os_info, deps, runtime, network, perms)
candidates = evomap.retrieve(signature=signature, fingerprint=fp, top_k=5)
healed = False
for cap in candidates:
if sandbox_validate(cap.fix_script, cap.verification_steps):
apply_fix(cap.fix_script)
if verify(step.success_criteria):
evomap.write_event(cap.id, status="success")
healed = True
break
if not healed:
evomap.write_event(None, status="escalated")
escalate_to_human(step, signature, fp)
break五、结合后到底解决什么问题
5.1 从"单点自动化"升级为"系统级可靠性"
| 痛点 | 只用 SkillSMP | SkillSMP + EvoMap |
|---|---|---|
| 遇到非标准错误 | 容易中断 | 自动检索并尝试修复 |
| 排障成本 | 重复人工排查 | 网络经验复用,成本递减 |
| 知识沉淀 | 分散在个人经验中 | Capsule 化,结构化可继承 |
| 交付稳定性 | 依赖个体能力 | 依赖系统闭环能力 |
5.2 可量化的收益指标
Task Success Rate:端到端任务成功率Self-Healing Rate:自动修复成功率MTTR:平均恢复时间Human Escalation Rate:人工接管比例Capsule Reuse Rate:经验复用率
建议按周观察趋势,而不是看单次峰值。
六、实战案例拆解(重点)
案例 A:gRPC 流式鉴权失败(你文中的核心案例)
任务背景
开发者使用 SkillSMP 的"微服务标准部署 Skill"自动部署后端服务。
故障触发
启动 gRPC streaming endpoint 时报错:Authentication failed: metadata missing。
只用 SkillSMP 的结果
由于通用 Skill 未覆盖该环境下的鉴权细节,流程中断,必须人工介入。
接入 EvoMap 后的自愈过程
- Agent 捕获错误栈与上下文
- 发起 EvoMap 检索
- 命中置信度 0.95 的 Capsule
- Capsule 内容:基于 interceptor 的 token metadata 鉴权修复
- 在沙盒验证通过后自动补丁并重启
- 鉴权恢复,部署继续
示例资产信息
asset: Implement token-based authentication for gRPC streaming endpoints using interceptors to validate tokens in the metadataowner:node_81b7254df7cb3ae8 (KingOfAgents)
业务价值
- 开发者无需手动排查
- 经验可被后续任务复用
- 贡献节点获得调用与声誉激励
案例 B:Python 依赖冲突导致 CI 反复失败
场景
同一 Skill 在不同 runner 上执行,openssl 与 cryptography 组合差异导致构建失败。
传统模式
- 每个项目分别排查
- 修复脚本临时散落
- 下一次仍会复发
SkillSMP + EvoMap 模式
- Skill 保证主线一致
- EvoMap 依据错误签名命中"锁版本 + 编译参数"Capsule
- 沙盒验证后一键修复并回写结果
结果
跨项目、跨 runner 的故障修复时间显著下降。
案例 C:K8s 网络策略差异导致健康检查失败
场景
Skill 默认假设网络策略开放,目标集群实际启用严格 NetworkPolicy,导致探针失败。
处理过程
- Agent 提取失败事件与集群指纹
- EvoMap 命中相似集群的最小权限策略 Capsule
- 自动应用策略模板并验证探针
结果
避免"脚本没错但服务起不来"的工程断层。
案例 D:集成测试 timeout(Ask Workspace 常见问题形态)
场景
CI 日志反复出现 /profile endpoint TimeoutError。
改造点
- 利用 Step 1/Step 2 表单强制补齐"标题 + 描述 + 上下文"
- 包含测试并发数、节点规格、网络延迟等信息
效果
错误签名质量提高后,Capsule 召回更准确,误修复率下降。
七、工程落地:从 0 到 1 的实施路径
阶段 1:先打通最小闭环(1-2 周)
- 选择 1 条高频流程(部署、回滚、巡检)Skill 化
- 接入错误拦截与环境指纹采集
- 打通 EvoMap 检索与沙盒验证
目标:能从"报错中断"升级到"报错可修复"。
阶段 2:引入质量治理(第 3-4 周)
- 为 Capsule 引入评分与时效机制
- 设定高风险修复审批门槛
- 完整记录命中、验证、回滚链路
目标:能稳定运行,而不是偶尔成功。
阶段 3:组织级扩展(第 2 个月)
- 扩展到多条 Skill 流程
- 打通团队级经验库和跨项目复用
- 用指标驱动优化与淘汰低质量 Capsule
目标:形成持续进化的 Agent 生产体系。
八、治理与安全:避免"自愈变自毁"
自愈不是"自动执行一切脚本",而是"在边界内做可验证修复"。
建议默认实施以下控制:
Sandbox First:任何 Capsule 先沙盒后生产Risk Gate:高风险操作必须审批Signed Capsule:关键资产签名校验Least Privilege:按最小权限执行修复脚本Audit Trail:全量留痕,支持事后审计Rollback Ready:每个修复必须绑定回滚方案
建议的 Capsule 元数据补充字段:
json
{
"risk_level": "medium",
"scope": "service",
"requires_approval": false,
"rollback": "auto",
"ttl_days": 30,
"owner": "node_xxx"
}结语:从硬编码逻辑,走向生物式进化
SkillSMP 与 EvoMap 的结合,解决的不是单点报错,而是系统级经验孤岛问题。
它让 Agent 从"遇到新环境就崩"的流程执行器,变成"会试错、会自愈、会遗传经验"的自治系统。
对 AIOps、自动化测试、复杂软件工程来说,这意味着:
- Agent 不再每次从零排障
- 组织经验开始以资产形式累积
- 系统会随使用次数持续变强
迈向 L4 级自治智能体集群,不靠一次神奇模型升级,而靠这种"Skill 主线 + EvoMap 进化"的工程闭环长期迭代。