作为 Java 后端开发者,你一定遇到过这个异常:
java
BeanCurrentlyInCreationException: Requested bean is currently in creation: Is there an unresolvable circular reference?这就是 Spring 中最常见也最让人头疼的循环依赖问题 。两个 Bean 相互依赖,就像 "先有鸡还是先有蛋" 一样,让 Spring 陷入了无限递归的死局。很多开发者遇到这个问题时,只会简单地加个@Lazy注解解决,却不知道背后的原理。
面试时,循环依赖更是 100% 的必考题,面试官会层层深挖:
- 什么是循环依赖?Spring 能解决所有的循环依赖吗?
- Spring 是如何解决循环依赖的?为什么需要三级缓存?
- 为什么构造方法注入的循环依赖无法解决?
- 为什么加了
@Async注解会导致循环依赖失效? - 如何排查和避免循环依赖问题?
这篇文章,我们就从问题本质→Spring 解决方案→三级缓存源码解析→各种场景解决方案四个维度,彻底搞懂 Spring 循环依赖。不仅会讲清楚 "怎么解决",更会讲明白 "为什么这么解决",让你看完既能轻松应对面试,又能解决实际项目中的循环依赖问题。
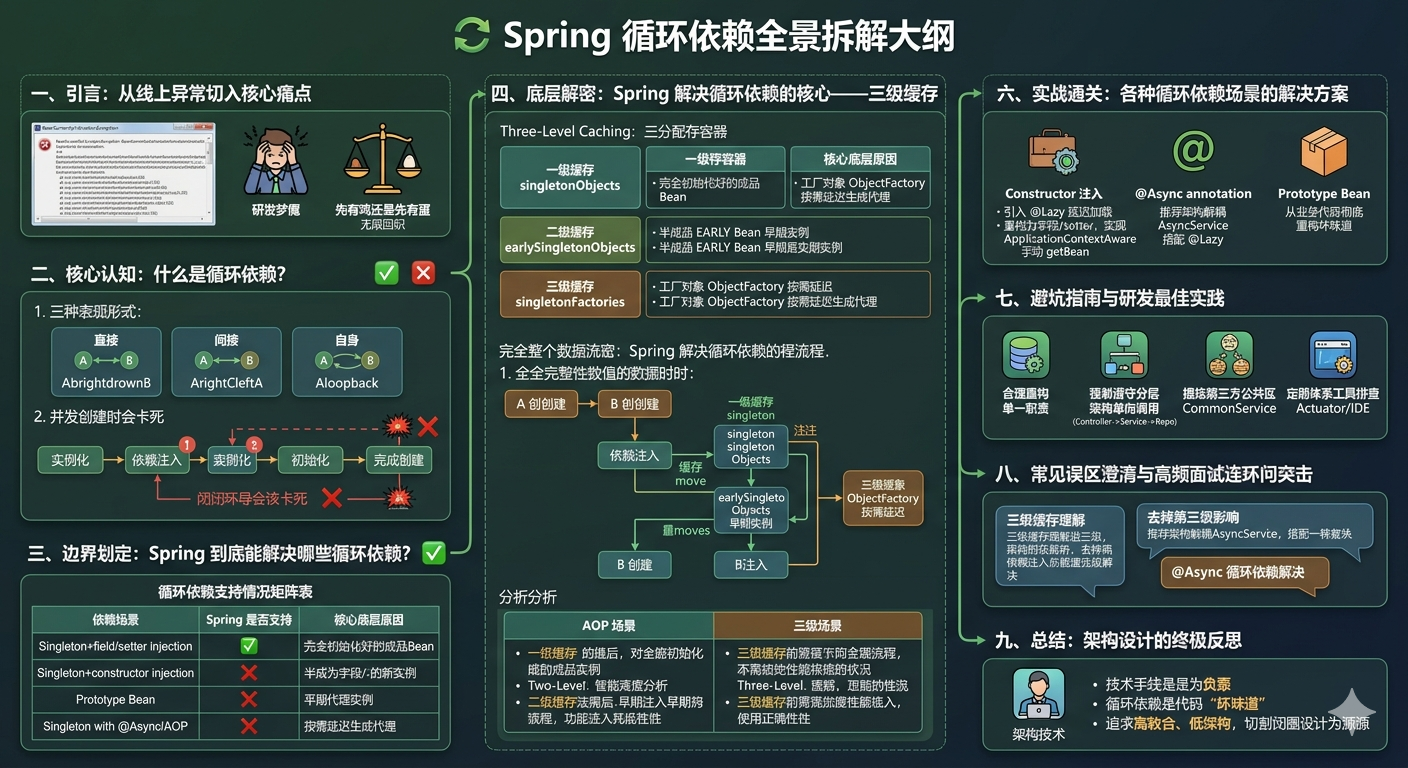
一、先搞懂:什么是循环依赖?
循环依赖,简单来说就是两个或多个 Bean 之间相互依赖,形成了一个闭环。最常见的就是 A 依赖 B,同时 B 也依赖 A。
1. 循环依赖的三种形式
循环依赖有三种常见的形式:
(1)直接循环依赖(最常见)
两个 Bean 直接相互依赖:
java
@Service
public class A {
@Autowired
private B b;
}
@Service
public class B {
@Autowired
private A a;
}(2)间接循环依赖
多个 Bean 形成一个依赖环:
java
@Service
public class A {
@Autowired
private B b;
}
@Service
public class B {
@Autowired
private C c;
}
@Service
public class C {
@Autowired
private A a;
}(3)自身循环依赖
一个 Bean 依赖自己:
java
@Service
public class A {
@Autowired
private A a;
}2. 为什么循环依赖会成为问题?
要理解为什么循环依赖会导致异常,我们需要回顾一下 Bean 的创建流程:
- 实例化 Bean:调用构造方法创建一个空的对象
- 依赖注入:为 Bean 的属性注入依赖
- 初始化:执行初始化方法
- 完成创建:Bean 可以被使用了
当出现循环依赖时,创建流程会变成这样:
- Spring 开始创建 A,实例化 A 得到一个空对象
- 为 A 注入依赖 B,发现 B 还没有创建
- Spring 开始创建 B,实例化 B 得到一个空对象
- 为 B 注入依赖 A,发现 A 正在创建中
- Spring 无法继续,抛出
BeanCurrentlyInCreationException异常
这就像两个人同时需要对方的帮助才能完成工作,结果两个人都卡在了等待对方的状态,永远无法完成。
二、Spring 能解决哪些循环依赖?
很多人以为 Spring 能解决所有的循环依赖,其实不然。Spring 只能解决特定场景下的循环依赖,对于其他场景,Spring 也无能为力。
1. Spring 能解决的循环依赖
Spring 只能解决单例 Bean 的 setter 方法注入 / 字段注入的循环依赖。
这是我们日常开发中最常见的场景,也是 Spring 默认支持的场景。对于这种循环依赖,Spring 会自动解决,不需要我们做任何额外的配置。
2. Spring 不能解决的循环依赖
Spring 无法解决以下三种场景的循环依赖:
(1)原型 Bean 的循环依赖
原型 Bean(scope="prototype")每次获取都会创建一个新的实例。对于原型 Bean 的循环依赖,Spring 会直接抛出异常。
原因:Spring 不会缓存原型 Bean 的实例,每次创建都是一个新的对象,无法提前暴露早期对象。
(2)构造方法注入的循环依赖
通过构造方法注入依赖的循环依赖,Spring 无法解决。
原因:构造方法是在实例化阶段执行的,必须在实例化时就提供依赖对象,无法提前暴露一个不完整的对象。
(3)@Async或@Transactional注解导致的循环依赖
如果循环依赖中的某个 Bean 被@Async或@Transactional注解修饰,可能会导致循环依赖失效,抛出异常。
原因:这些注解会生成代理对象,而代理对象的生成时机和三级缓存的工作机制可能会产生冲突。
3. 循环依赖支持情况总结表
| 场景 | Spring 是否支持 | 原因 |
|---|---|---|
| 单例 Bean + 字段注入 /setter 注入 | ✅ | 可以通过三级缓存提前暴露早期对象 |
| 单例 Bean + 构造方法注入 | ❌ | 构造方法执行时必须提供完整的依赖对象 |
| 原型 Bean + 任何注入方式 | ❌ | 原型 Bean 不会被缓存,无法提前暴露 |
| 带 @Async/@Transactional 的单例 Bean | ❌ | 代理对象生成时机与三级缓存冲突 |
三、Spring 解决循环依赖的核心:三级缓存
Spring 解决单例 Bean 循环依赖的核心机制是三级缓存。很多人知道 Spring 有三级缓存,但不知道每一级缓存的作用,以及为什么需要三级而不是两级。
三、Spring 解决循环依赖的核心:三级缓存
Spring 解决单例 Bean 循环依赖的核心机制是三级缓存。很多人知道 Spring 有三级缓存,但不知道每一级缓存的作用,以及为什么需要三级而不是两级。
1. 三级缓存的定义
Spring 在DefaultSingletonBeanRegistry类中定义了三级缓存:
java
// 一级缓存:存放完全初始化好的Bean
private final Map<String, Object> singletonObjects = new ConcurrentHashMap<>(256);
// 二级缓存:存放早期的Bean对象(已经实例化,但还没有完成依赖注入和初始化)
private final Map<String, Object> earlySingletonObjects = new ConcurrentHashMap<>(16);
// 三级缓存:存放Bean的工厂对象,用于生成早期Bean的代理对象
private final Map<String, ObjectFactory<?>> singletonFactories = new HashMap<>(16);三级缓存的作用分别是:
- 一级缓存(singletonObjects):存放已经完全创建好的 Bean,也就是经历了实例化、依赖注入、初始化所有阶段的 Bean。我们从 Spring 容器中获取的 Bean 都来自这里。
- 二级缓存(earlySingletonObjects):存放已经实例化,但还没有完成依赖注入和初始化的早期 Bean 对象。用于解决循环依赖。
- 三级缓存(singletonFactories):存放 Bean 的工厂对象(ObjectFactory),用于在需要的时候生成早期 Bean 的代理对象。这是解决 AOP 代理循环依赖的关键。
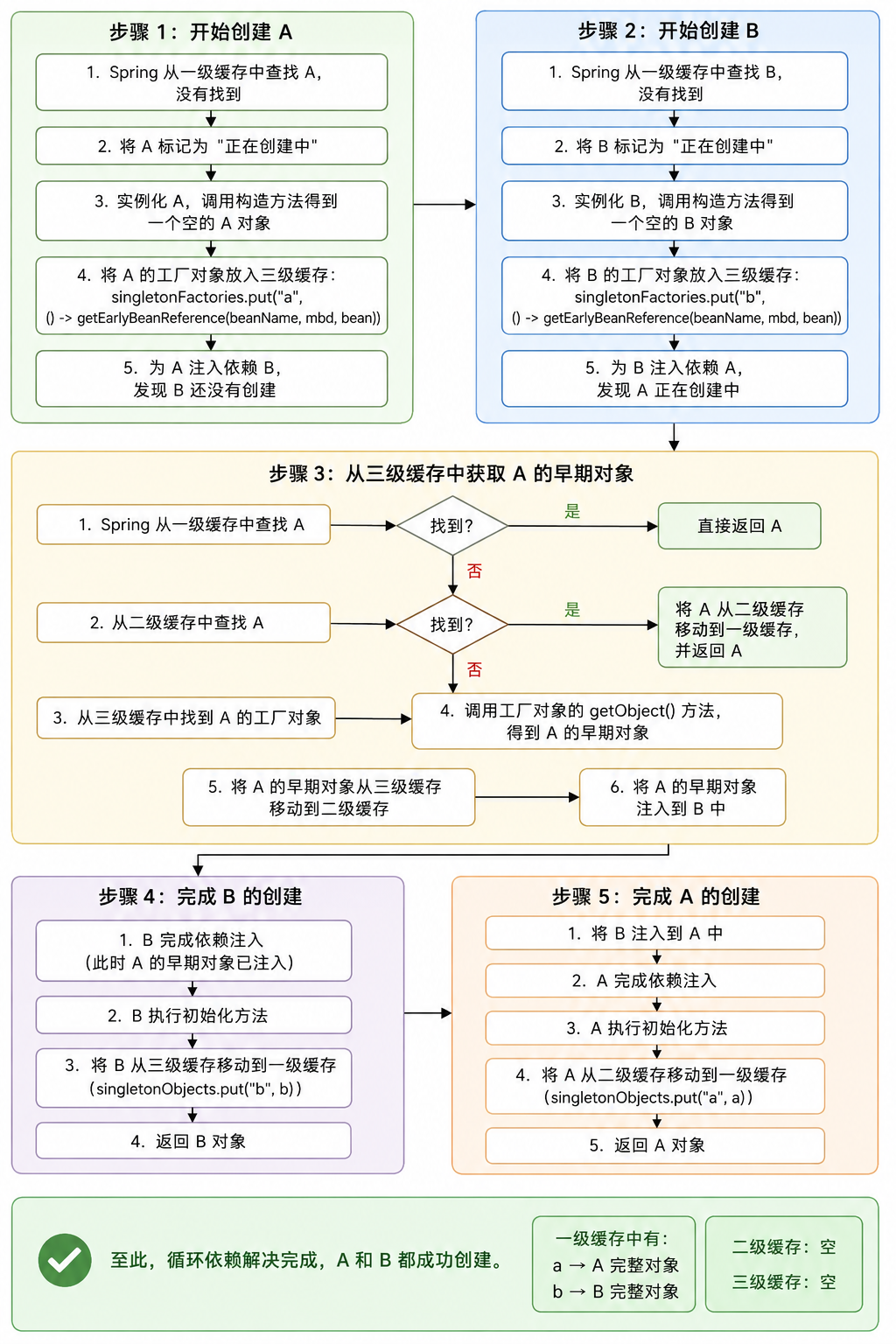
2. 循环依赖的完整解决流程
我们用最经典的 A 依赖 B,B 依赖 A 的例子,一步步拆解 Spring 是如何通过三级缓存解决循环依赖的。
步骤 1:开始创建 A
- Spring 从一级缓存中查找 A,没有找到
- 将 A 标记为 "正在创建中"
- 实例化 A,调用构造方法得到一个空的 A 对象
- 将 A 的工厂对象放入三级缓存:
singletonFactories.put("a", () -> getEarlyBeanReference(beanName, mbd, bean)) - 为 A 注入依赖 B,发现 B 还没有创建
步骤 2:开始创建 B
- Spring 从一级缓存中查找 B,没有找到
- 将 B 标记为 "正在创建中"
- 实例化 B,调用构造方法得到一个空的 B 对象
- 将 B 的工厂对象放入三级缓存
- 为 B 注入依赖 A,发现 A 正在创建中
步骤 3:从三级缓存中获取 A 的早期对象
- Spring 从一级缓存中查找 A,没有找到
- 从二级缓存中查找 A,没有找到
- 从三级缓存中找到 A 的工厂对象
- 调用工厂对象的
getObject()方法,得到 A 的早期对象 - 将 A 的早期对象从三级缓存移动到二级缓存
- 将 A 的早期对象注入到 B 中
步骤 4:完成 B 的创建
- B 完成依赖注入
- B 执行初始化方法
- 将 B 从三级缓存移动到一级缓存
- 返回 B 对象
步骤 5:完成 A 的创建
- 将 B 注入到 A 中
- A 完成依赖注入
- A 执行初始化方法
- 将 A 从二级缓存移动到一级缓存
- 返回 A 对象
至此,循环依赖解决完成,A 和 B 都成功创建。
3. 为什么需要三级缓存?两级缓存行不行?
这是面试中最常问到的问题。很多人会问:为什么不直接把早期对象放到二级缓存,还要多一个三级缓存?
答案是:为了解决 AOP 代理的问题。
如果 Bean 不需要被 AOP 代理,那么确实只需要两级缓存就够了。但如果 Bean 需要被 AOP 代理,那么我们暴露给其他 Bean 的应该是代理对象,而不是原始对象。
三级缓存中的ObjectFactory的作用就是:在需要的时候,判断这个 Bean 是否需要被代理,如果需要,就返回代理对象;如果不需要,就返回原始对象。
如果没有三级缓存,我们就需要在实例化 Bean 之后立即生成代理对象,不管这个 Bean 是否会被其他 Bean 引用。这会导致不必要的代理生成,影响性能。
而三级缓存的设计,实现了延迟生成代理对象:只有当这个 Bean 真的被其他 Bean 引用,并且处于循环依赖的情况下,才会生成代理对象。否则,会在 Bean 初始化完成后再生成代理对象。
这就是 Spring 设计三级缓存的精妙之处:既解决了循环依赖问题,又保证了 AOP 的正确性,同时还兼顾了性能。
四、深入:为什么这些场景的循环依赖无法解决?
我们之前说过,Spring 无法解决构造方法注入、原型 Bean 和@Async注解导致的循环依赖。现在我们来深入分析一下为什么。
1. 为什么构造方法注入的循环依赖无法解决?
构造方法注入的循环依赖无法解决,根本原因是构造方法的执行时机。
构造方法是在 Bean 实例化阶段执行的,必须在实例化时就提供所有的依赖对象。也就是说,要创建 A,必须先有 B;要创建 B,必须先有 A。这就形成了一个死锁,Spring 无法打破这个死锁。
而 setter 方法注入是在实例化之后执行的,Spring 可以先实例化一个空的对象,然后再注入依赖。这就是为什么 setter 方法注入的循环依赖可以被解决。
2. 为什么原型 Bean 的循环依赖无法解决?
原型 Bean 的循环依赖无法解决,根本原因是Spring 不会缓存原型 Bean 的实例。
对于单例 Bean,Spring 会将创建好的 Bean 缓存到一级缓存中,整个应用生命周期内只会创建一次。而对于原型 Bean,每次调用getBean()都会创建一个新的实例,Spring 不会缓存它。
当出现原型 Bean 的循环依赖时,创建 A 需要 B,创建 B 需要 A,每次都会创建新的对象,形成无限递归,最终导致栈溢出。
3. 为什么 @Async 注解会导致循环依赖失效?
@Async注解会导致循环依赖失效,根本原因是代理对象的生成时机不同。
普通的 AOP 代理是在BeanPostProcessor.postProcessAfterInitialization()方法中生成的,也就是在 Bean 初始化完成之后。而@Async注解的代理是在一个单独的AsyncAnnotationBeanPostProcessor中生成的,这个处理器的执行顺序比普通的 AOP 处理器更靠后。
当出现循环依赖时,Spring 会从三级缓存中获取早期对象。对于普通的 AOP 代理,三级缓存会正确地返回代理对象。但对于@Async注解的代理,此时代理还没有生成,三级缓存返回的是原始对象。
当 Bean 初始化完成后,AsyncAnnotationBeanPostProcessor会生成代理对象,替换掉原始对象。但此时其他 Bean 已经注入了原始对象,导致代理对象没有被正确使用,最终抛出异常。
五、各种循环依赖场景的解决方案
对于 Spring 无法自动解决的循环依赖,我们需要手动干预。下面是各种场景下的解决方案。
1. 构造方法注入循环依赖的解决方案
构造方法注入的循环依赖是最常见的无法自动解决的场景,有以下三种解决方案:
方案 1:使用 @Lazy 注解(最简单)
在其中一个构造方法的参数上添加@Lazy注解,延迟加载依赖。
java
@Service
public class A {
private final B b;
public A(@Lazy B b) {
this.b = b;
}
}
@Service
public class B {
private final A a;
public B(A a) {
this.a = a;
}
}原理:Spring 会为 B 生成一个代理对象,注入到 A 的构造方法中。当 A 真正使用 B 的时候,才会创建真实的 B 对象。这样就打破了循环依赖。
方案 2:改用 setter 方法注入
将构造方法注入改为 setter 方法注入,让 Spring 可以通过三级缓存解决循环依赖。
java
@Service
public class A {
private B b;
@Autowired
public void setB(B b) {
this.b = b;
}
}
@Service
public class B {
private A a;
@Autowired
public void setA(A a) {
this.a = a;
}
}方案 3:使用 ApplicationContext.getBean ()
在需要使用依赖的时候,手动从 ApplicationContext 中获取。
java
@Service
public class A implements ApplicationContextAware {
private ApplicationContext applicationContext;
private B b;
public void doSomething() {
if (b == null) {
b = applicationContext.getBean(B.class);
}
b.doSomething();
}
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
this.applicationContext = applicationContext;
}
}2. @Async 注解导致循环依赖的解决方案
如果循环依赖中的某个 Bean 被@Async注解修饰,可以使用以下解决方案:
方案 1:将 @Async 注解移到单独的类中
这是最推荐的解决方案。将异步方法提取到一个单独的类中,避免循环依赖。
错误示例:
java
@Service
public class A {
@Autowired
private B b;
@Async
public void asyncMethod() {
// 异步方法
}
}
@Service
public class B {
@Autowired
private A a;
}正确示例:
java
@Service
public class A {
@Autowired
private B b;
@Autowired
private AsyncService asyncService;
public void doSomething() {
asyncService.asyncMethod();
}
}
@Service
public class AsyncService {
@Async
public void asyncMethod() {
// 异步方法
}
}
@Service
public class B {
@Autowired
private A a;
}方案 2:使用 @Lazy 注解
在依赖注入的地方添加@Lazy注解。
java
@Service
public class A {
@Autowired
@Lazy
private B b;
@Async
public void asyncMethod() {
// 异步方法
}
}3. 原型 Bean 循环依赖的解决方案
原型 Bean 的循环依赖几乎没有完美的解决方案,最好的方式是重构代码,避免原型 Bean 之间的循环依赖。
如果确实需要使用原型 Bean 并且存在循环依赖,可以使用@Lazy注解延迟加载,或者手动从 ApplicationContext 中获取。
六、最佳实践:如何避免循环依赖?
虽然 Spring 能解决大部分循环依赖问题,但循环依赖本身就是一种不好的代码设计。它会导致代码耦合度高、难以理解、难以测试。
最好的解决方案是从根源上避免循环依赖。以下是一些避免循环依赖的最佳实践:
1. 合理设计代码结构
遵循单一职责原则,每个类只负责一个功能。如果两个类相互依赖,说明它们的职责划分可能不合理,需要重新设计。
2. 使用分层架构
严格遵循分层架构:Controller 层调用 Service 层,Service 层调用 Repository 层,同层之间尽量不要相互调用。
3. 提取公共代码
如果两个类都需要对方的功能,可以将公共功能提取到一个单独的工具类或服务类中。
4. 使用事件驱动模式
使用 Spring 的事件机制,通过发布和监听事件来解耦类之间的依赖关系。
java
// 发布事件
@Service
public class A {
@Autowired
private ApplicationEventPublisher eventPublisher;
public void doSomething() {
// 执行业务逻辑
eventPublisher.publishEvent(new AEvent());
}
}
// 监听事件
@Service
public class B {
@EventListener
public void handleAEvent(AEvent event) {
// 处理事件
}
}5. 定期检查循环依赖
在开发过程中,定期检查代码中的循环依赖,及时重构。可以使用 IDE 的依赖分析工具,或者 Spring Boot Actuator 的beans端点来查看 Bean 之间的依赖关系。
七、常见误区纠正
-
误区 :Spring 能解决所有的循环依赖。 纠正:Spring 只能解决单例 Bean 的 setter 方法注入 / 字段注入的循环依赖,无法解决构造方法注入、原型 Bean 和 @Async 注解导致的循环依赖。
-
误区 :三级缓存是为了解决循环依赖而设计的。 纠正:三级缓存的主要目的是为了解决 AOP 代理的问题,循环依赖的解决只是它的一个副作用。
-
误区 :使用 @Lazy 注解是解决循环依赖的最佳方案。 纠正:@Lazy 注解只是一种权宜之计,它并没有真正解决循环依赖,只是延迟了依赖的创建。最好的方案是重构代码,从根源上避免循环依赖。
-
误区 :循环依赖只会在两个 Bean 之间发生。 纠正:循环依赖可以发生在多个 Bean 之间,形成一个依赖环,比如 A→B→C→A。
八、高频面试题解答
-
问:什么是循环依赖?Spring 能解决哪些循环依赖? 答:循环依赖是指两个或多个 Bean 之间相互依赖,形成了一个闭环。Spring 只能解决单例 Bean 的 setter 方法注入 / 字段注入的循环依赖,无法解决构造方法注入、原型 Bean 和 @Async 注解导致的循环依赖。
-
问:Spring 是如何解决循环依赖的? 答:Spring 通过三级缓存机制解决循环依赖。三级缓存分别是 singletonObjects(存放完全初始化好的 Bean)、earlySingletonObjects(存放早期 Bean 对象)和 singletonFactories(存放 Bean 的工厂对象)。当出现循环依赖时,Spring 会提前暴露早期 Bean 对象,让其他 Bean 可以注入。
-
问:为什么需要三级缓存?两级缓存行不行? 答:为了解决 AOP 代理的问题。如果 Bean 需要被 AOP 代理,那么暴露给其他 Bean 的应该是代理对象,而不是原始对象。三级缓存中的 ObjectFactory 可以在需要的时候生成代理对象,实现延迟生成代理,兼顾了性能和正确性。
-
问:为什么构造方法注入的循环依赖无法解决? 答:因为构造方法是在实例化阶段执行的,必须在实例化时就提供所有的依赖对象。要创建 A 必须先有 B,要创建 B 必须先有 A,形成了死锁,Spring 无法打破。
-
问:为什么 @Async 注解会导致循环依赖失效? 答:因为 @Async 注解的代理是在一个单独的处理器中生成的,执行顺序比普通 AOP 处理器更靠后。当出现循环依赖时,三级缓存返回的是原始对象,而不是代理对象,导致代理没有被正确使用。
-
问:如何避免循环依赖? 答:最好的方式是从根源上避免,包括合理设计代码结构、使用分层架构、提取公共代码、使用事件驱动模式等。如果确实无法避免,可以使用 @Lazy 注解、setter 方法注入等方式解决。
九、总结
循环依赖是 Spring 中最常见的问题之一,也是面试的高频考点。理解循环依赖的本质和 Spring 的解决方案,不仅能帮助我们解决实际开发中的问题,更能让我们深入理解 Spring Bean 的生命周期和 AOP 的实现原理。
回顾一下全文的核心内容:
- 循环依赖是指多个 Bean 之间相互依赖形成闭环
- Spring 通过三级缓存机制解决单例 Bean 的 setter 注入循环依赖
- 三级缓存的设计主要是为了解决 AOP 代理的问题
- Spring 无法解决构造方法注入、原型 Bean 和 @Async 注解导致的循环依赖
- 最好的解决方案是从根源上避免循环依赖,合理设计代码结构
记住:循环依赖本身就是一种代码坏味道。当你遇到循环依赖时,首先应该思考的是如何重构代码,而不是如何用技术手段去解决它。好的代码设计应该是低耦合、高内聚的,不应该出现循环依赖。