一、LVS介绍
LVS(Linux Virtual Server)是Linux 内核级四层(TCP/UDP)负载均衡方案,由章文嵩博士于 1998 年发起,现已集成到 Linux 内核,核心是通过 IP 层调度构建高并发、高可用的服务器集群。
1.1 核心架构与术语
- 调度器(Director) :集群入口,对外提供VIP(虚拟 IP),负责分发请求。
- 真实服务器(RS) :后端实际处理请求的服务器,使用RIP通信。
- DIP:调度器与后端通信的内网 IP。
- 工具 :内核模块为ipvs ,用户态管理工具为ipvsadm。
1.2 三种核心工作模式
| 模式 | 核心动作 | 响应路径 | 性能 | 适用场景 |
|---|---|---|---|---|
| DR(直接路由) | 改写 MAC 地址 | RS 直接回客户端 | 最高 | 同网段、高吞吐(首选) |
| TUN(IP 隧道) | 封装新 IP 头 | RS 直接回客户端 | 高 | 跨网段、RS 分散部署 |
| NAT | 改写目标 / 源 IP | 经调度器回客户端 | 低 | 小规模、网关统一(简单) |
口诀:DR 改 MAC,TUN 封隧道,NAT 改 IP;直回性能高,回调度兼容强。
1.3 常用调度算法
- RR(轮询):顺序分配,简单公平。
- WRR(加权轮询):按权重分配,适配性能差异。
- LC(最少连接):选当前连接数最少的 RS。
- WLC(加权最少连接):结合权重与连接数,默认推荐。
- SH(源地址哈希):同一客户端固定到同一 RS,保证会话粘滞。
1.4 核心优势与定位
- 性能强:内核态处理,无用户态切换开销,支撑数万并发。
- 高可用 :配合Keepalived实现主备切换,避免单点故障。
- 成本低:开源免费,可替代高端硬件负载均衡器。
与 Nginx/HAProxy 对比 :LVS 是四层 ,适合纯流量分发、高并发场景;Nginx/HAProxy 擅长七层 (如 URL 路由、SSL 终止),通常架构为LVS+Keepalived(四层)前置,Nginx(七层)后置。
二、LVS实战案例
1. NAT模式(网络地址转换)
LVS(Linux Virtual Server)的 NAT 模式是一种经典的负载均衡实现方式,核心原理是通过负载均衡器(VS)对请求报文做网络地址转换,将请求转发到后端真实服务器(RS),并将 RS 的响应报文反向转换后返回给客户端。
1.1 NAT模式实战
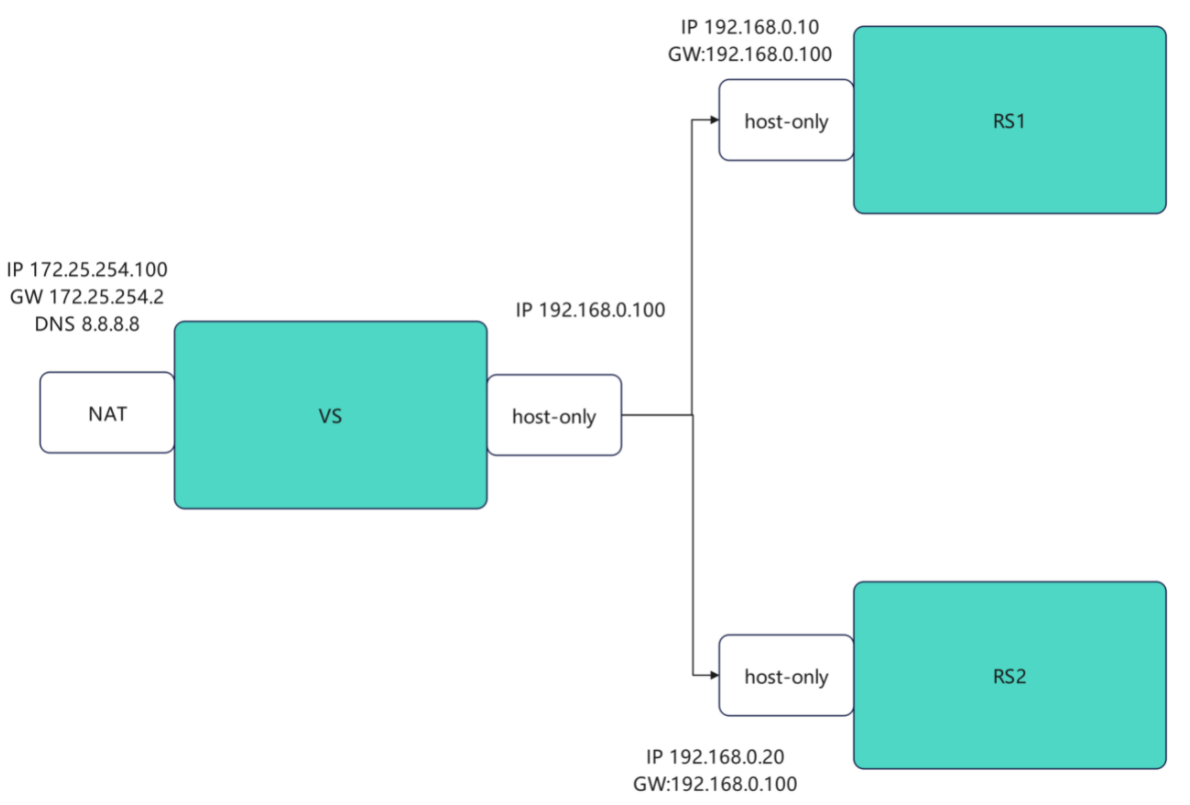
| 节点 | 网卡 / IP 配置 | 角色 |
|---|---|---|
| VS(vsnode) | eth0: 172.25.254.100(公网 / 外部网段)eth1: 192.168.0.100(内网 / RS 网段) | 负载均衡器(LVS 节点) |
| RS1 | eth0: 192.168.0.10网关:192.168.0.100 | 后端真实服务器 1 |
| RS2 | eth0: 192.168.0.20网关:192.168.0.100 | 后端真实服务器 2 |
关键:RS 的默认网关必须指向 VS 的内网 IP(192.168.0.100),否则响应报文无法回传给 VS,导致客户端无法收到结果。
1. 阶段 1:基础网络环境配置(打通 VS 和 RS 的通信)
- VS 节点网络配置
bash
# 配置eth0(外部网段)和eth1(内网网段),noroute表示暂不设置路由(后续靠内核转发)
[root@vsnode ~]# vmset.sh eth0 172.25.254.100 vsnode
[root@vsnode ~]# vmset.sh eth1 192.168.0.100 vsnode noroute作用:给 VS 配置双网卡,分别对接 "外部客户端" 和 "内部 RS 集群",实现跨网段转发的基础。
- RS1/RS2 网络配置(RS2 仅 IP 不同,逻辑一致)
RS1
bash
#RS1设定网络
[root@RS1 ~]# vmset.sh eth0 192.168.0.10 RS1 noroute
# 手动指定网关为VS的内网IP(核心!)
[root@RS1 ~]# nmcli connection modify eth0 ipv4.gateway 192.168.0.100
[root@RS1 ~]# nmcli connection reload
[root@RS1 ~]# nmcli connection up eth0
#验证网络:route -n 确认默认网关是 192.168.0.100,确保 RS 的响应能回传给 VS。
[root@RS1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.0.100 0.0.0.0 UG 100 0 0 eth0
192.168.0.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0RS2
bash
#设定网络
[root@RS2 ~]# vmset.sh eth0 192.168.0.20 RS1 noroute
# 手动指定网关为VS的内网IP(核心!)
[root@RS2 ~]# nmcli connection modify eth0 ipv4.gateway 192.168.0.100
[root@RS2 ~]# nmcli connection reload
[root@RS2 ~]# nmcli connection up eth0
[root@RS2 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.0.100 0.0.0.0 UG 100 0 0 eth0
192.168.0.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0- RS 业务部署(HTTP 服务)
安装httpd并启动,创建差异化页面(区分RS1/RS2)
bash
#RS1
[root@RS1 ~]# dnf install httpd -y
[root@RS1 ~]# systemctl enable --now httpd
[root@RS1 ~]# echo RS1 - 192.168.0.10 > /var/www/html/index.html
#RS2
[root@RS2 ~]# dnf install httpd -y
[root@RS2 ~]# systemctl enable --now httpd
[root@RS2 ~]# echo RS2 - 192.168.0.20 > /var/www/html/index.html- VS 测试连通性
curl 192.168.0.10/curl 192.168.0.20 能返回对应页面,说明 VS 和 RS 的内网通信正常。
bash
[root@vsnode ~]# curl 192.168.0.10
RS1 - 192.168.0.10
[root@vsnode ~]# curl 192.168.0.20
RS2 - 192.168.0.20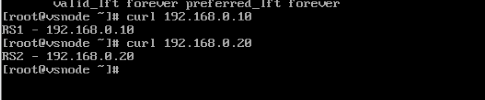
2. 阶段 2:LVS NAT 模式核心配置(VS 节点)
- 开启内核 IP 转发(NAT 模式的前提)
LVS NAT 依赖内核转发报文,必须开启:
bash
[root@vsnode ~]# echo net.ipv4.ip_forward=1 >> /etc/sysctl.conf
[root@vsnode ~]# sysctl -p
net.ipv4.ip_forward = 1 # 生效配置,验证输出net.ipv4.ip_forward = 1原理:如果关闭 IP 转发,VS 收到 RS 的响应报文后无法转发回客户端,整个 NAT 流程中断。
- 配置 ipvsadm 规则(负载均衡核心)
ipvsadm 是 LVS 的管理工具,核心参数解释:
- -C:清空旧规则;
- -A -t 172.25.254.100:80 -s wrr:创建虚拟服务(VIP:172.25.254.100,端口 80),调度算法为wrr(加权轮询);
- -a -t VIP:端口 -r RS_IP:端口 -m -w 权重:添加真实服务器,-m表示 NAT 模式(Masquerade),-w
是权重;
bash
[root@vsnode ~]# ipvsadm -C # 清空规则
# 创建虚拟服务(VIP+端口+调度算法)
[root@vsnode ~]# ipvsadm -A -t 172.25.254.100:80 -s wrr
# 添加RS1,权重1,NAT模式
[root@vsnode ~]# ipvsadm -a -t 172.25.254.100:80 -r 192.168.0.10:80 -m -w 1
# 添加RS2,权重1,NAT模式
[root@vsnode ~]# ipvsadm -a -t 172.25.254.100:80 -r 192.168.0.20:80 -m -w 1验证规则:ipvsadm -Ln 能看到 RS 列表和配置,说明规则生效。
bash
[root@vsnode ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.25.254.100:80 wrr
-> 192.168.0.10:80 Masq 1 0 0
-> 192.168.0.20:80 Masq 1 0 03. 阶段 3:测试负载均衡效果
- 基础测试(权重 1:1)
bash
[root@vsnode ~]# for i in {1..10};do curl 172.25.254.100;done
RS2 - 192.168.0.20
RS1 - 192.168.0.10
RS2 - 192.168.0.20
RS1 - 192.168.0.10
RS2 - 192.168.0.20
RS1 - 192.168.0.10
RS2 - 192.168.0.20
RS1 - 192.168.0.10
RS2 - 192.168.0.20
RS1 - 192.168.0.10输出交替显示RS1 - 192.168.0.10和RS2 - 192.168.0.20,符合wrr(权重 1:1)的轮询逻辑。
- 调整权重测试(权重 2:1)
修改 RS1 权重为 2:
bash
#更改权重
[root@vsnode ~]# ipvsadm -e -t 172.25.254.100:80 -r 192.168.0.10:80 -m -w 2
[root@vsnode ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 172.25.254.100:80 wrr
-> 192.168.0.10:80 Masq 2 0 5
-> 192.168.0.20:80 Masq 1 0 5再次测试:
bash
[root@vsnode ~]# for i in {1..10};do curl 172.25.254.100;done
RS2 - 192.168.0.20
RS1 - 192.168.0.10
RS1 - 192.168.0.10
RS2 - 192.168.0.20
RS1 - 192.168.0.10
RS1 - 192.168.0.10
RS2 - 192.168.0.20
RS1 - 192.168.0.10
RS1 - 192.168.0.10
RS2 - 192.168.0.20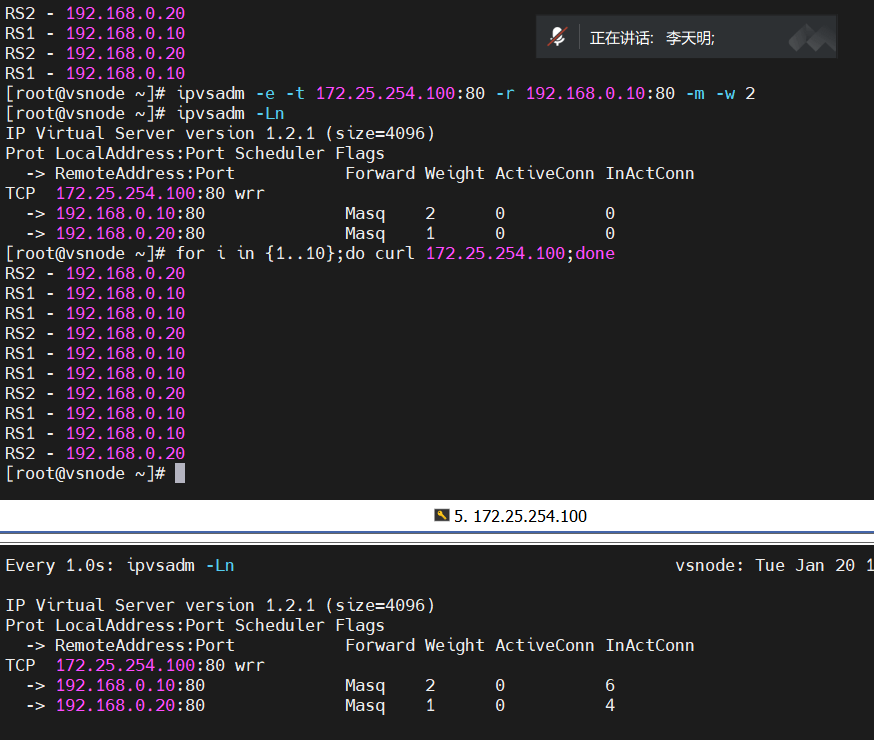
输出中 RS1 出现次数约为 RS2 的 2 倍(如 RS2、RS1、RS1、RS2...),验证wrr加权调度的效果。
4. 阶段 4:LVS 规则持久化(避免重启失效)
实验过程可以用过打开另外一个shell的并执行监控命令的方式进行观察
- 自定义文件持久化
bash
#利用自定义文件进行持久化
[root@vsnode ~]# ipvsadm-save -n
-A -t 172.25.254.100:80 -s wrr
-a -t 172.25.254.100:80 -r 192.168.0.10:80 -m -w 2
-a -t 172.25.254.100:80 -r 192.168.0.20:80 -m -w 1
[root@vsnode ~]# ipvsadm-save -n > /mnt/ipvs.rule # 导出规则到文件
[root@vsnode ~]# ipvsadm -C # 清空规则(模拟重启)
[root@vsnode ~]# ipvsadm-restore < /mnt/ipvs.rule # 恢复规则- 系统服务持久化(推荐)
bash
#利用守护进程进行规则持久化
[root@vsnode ~]# ipvsadm-save -n > /etc/sysconfig/ipvsadm # 导出到默认配置文件
[root@vsnode ~]# ipvsadm -C
[root@vsnode ~]# systemctl enable --now ipvsadm.service # 启动服务,自动加载规则
Created symlink /etc/systemd/system/multi-user.target.wants/ipvsadm.service → /usr/lib/systemd/system/ipvsadm.service.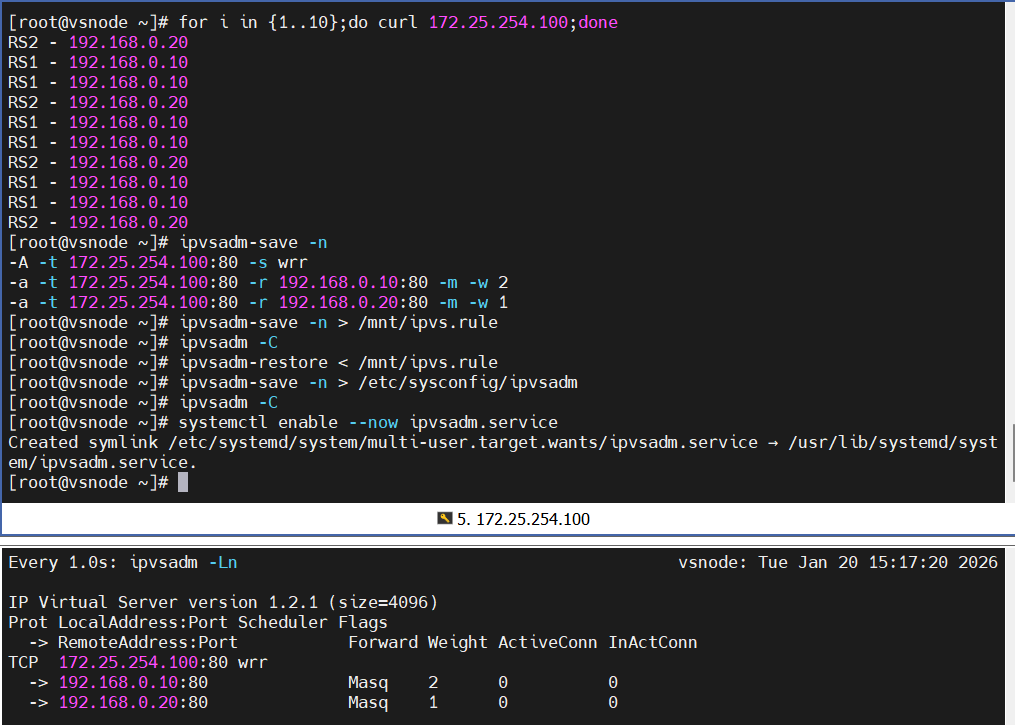
1.2 NAT 模式核心原理(报文流转)
- 客户端请求 :客户端访问
172.25.254.100:80(VS 的 VIP),报文目标 IP=VIP,目标端口 = 80; - VS 转发:VS 通过 ipvsadm 规则,将报文的目标 IP 改为某台 RS 的 IP(如 192.168.0.10),目标端口不变,源 IP 仍为客户端 IP,然后转发给 RS;
- RS 响应:RS 收到报文后,处理请求并生成响应,由于网关指向 VS,响应报文的目标 IP=VS 的内网 IP(192.168.0.100),源 IP=RS 自身 IP;
- VS 回包:VS 收到 RS 的响应后,将报文的源 IP 改为 VIP(172.25.254.100),目标 IP 改回客户端 IP,然后转发给客户端;
- 客户端接收:客户端收到响应,感知到的是 VIP 的响应,完全不知道后端 RS 的存在。
1.3 NAT 模式的特点总结
| 优点 | 缺点 |
|---|---|
| 配置简单,RS 无需特殊配置 | VS 是单点瓶颈(所有报文经过 VS) |
| RS 可使用任意操作系统 | 仅支持 TCP/UDP,不支持复杂协议 |
| 可通过权重灵活调度 | 转发效率低于 DR/TUN 模式 |
1.4 关键注意事项
- RS 的默认网关必须指向 VS 的内网 IP,否则响应报文无法回传;
- VS 必须开启
ip_forward,否则无法转发报文; - NAT 模式下,VS 的 VIP 需要对外暴露(客户端可访问),RS 仅需和 VS 内网互通,无需公网 IP;
- 调度算法
wrr(加权轮询)可根据 RS 性能调整权重,性能高的 RS 设更高权重。
通过这个实验,完整验证了 LVS NAT 模式从 "网络打通"→"规则配置"→"负载测试"→"规则持久化" 的全流程,核心是理解 "地址转换" 和 "报文转发" 的逻辑,以及 RS 网关指向 VS 的关键要求。
2. DR模式
LVS(Linux Virtual Server)的 DR(Direct Routing,直接路由)模式是 LVS 三种核心模式(NAT/DR/TUN)之一,核心特点是数据请求经过调度器,响应直接从真实服务器(RS)返回给客户端,避免了调度器成为瓶颈,是高性能负载均衡的常用方案。
2.1 DR模式实战
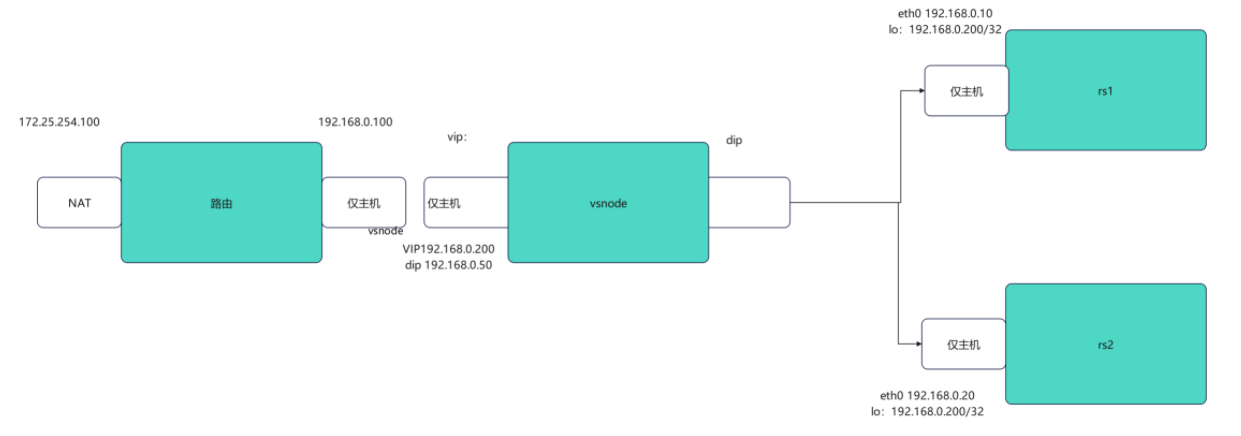
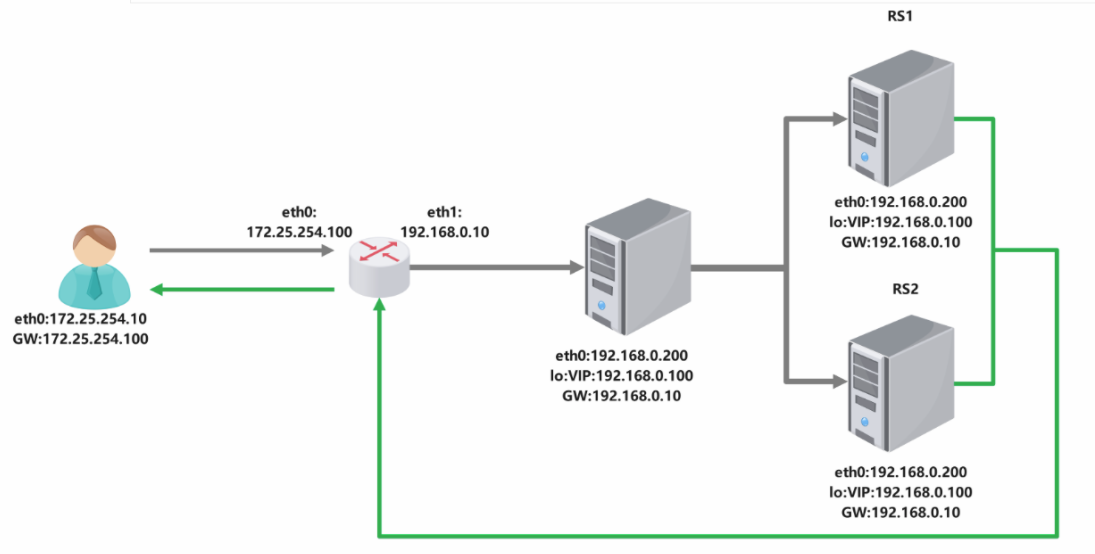
| 角色 | 网卡 / IP 配置 | 核心作用 |
|---|---|---|
| 路由器 (router) | eth0:172.25.254.100 eth1:192.168.0.100 | 跨网段转发(172.25.254.0/24 ↔ 192.168.0.0/24),开启 IP 转发和 SNAT |
| 调度器 (vsnode) | eth0:192.168.0.50 lo:192.168.0.200(VIP) | LVS 调度节点,承载 VIP(虚拟 IP),负责分发请求到 RS |
| 客户端 (client) | eth0:172.25.254.99 | 发起请求的终端,访问 VIP(192.168.0.200) |
| 真实服务器 (RS1) | eth0:192.168.0.10 lo:192.168.0.200(VIP) | 处理实际业务,承载 VIP(仅 lo 回环) |
| 真实服务器 (RS2) | eth0:192.168.0.20 lo:192.168.0.200(VIP) | 同 RS1,实现负载均衡冗余 |
核心网络逻辑
- 客户端处于 172.25.254.0/24 网段,只能直接访问路由器的 eth0 口;
- 路由器通过 eth1 口连接 192.168.0.0/24 网段(VS、RS1、RS2),实现跨网段转发;
- VIP(192.168.0.200)是客户端访问的目标地址,同时配置在 VS 的 lo 口和所有 RS 的 lo 口(核心设计)。
1. 路由器配置:实现跨网段转发 + SNAT
bash
# 关闭ipvsadm服务(避免与LVS冲突)
[root@router ~]# systemctl disable --now ipvsadm.service
Removed "/etc/systemd/system/multi-user.target.wants/ipvsadm.service".
[root@router ~]# ipvsadm -C # 清空ipvsadm规则
# 配置双网卡IP:eth0(172.25.254.100)、eth1(192.168.0.100)
[root@router ~]# vmset.sh eth0 172.25.254.100 vsnode
[root@router ~]# vmset.sh eth1 192.168.0.100 vsnode noroute
# 开启内核转发(关键:实现跨网段数据包转发)
[root@router ~]# echo net.ipv4.ip_forward=1 >> /etc/sysctl.conf
[root@router ~]# sysctl -p
net.ipv4.ip_forward = 1
# SNAT策略:让172.25.254.0/24网段的数据包出eth1时,源IP转为192.168.0.100
[root@router ~]# iptables -t nat -A POSTROUTING -o eth1 -j SNAT --to-source 192.168.0.100
# 反向SNAT:让192.168.0.0/24网段数据包出eth0时,源IP转为172.25.254.100
[root@vsnode ~]# iptables -t nat -A POSTROUTING -o eth0 -j SNAT --to-source 172.25.254.100核心作用:
- 开启 IP 转发,让客户端(172.25.254.99)的请求能到达 192.168.0.0/24 网段的 VS;
- SNAT 转换解决跨网段通信的源 IP 合法性问题,确保 RS 的响应能原路返回客户端。
2. 负载均衡器(vsnode调度器)配置:绑定 VIP + 配置路由
bash
# 配置eth0的IP和网关(指向路由器eth1)
[root@vsnode ~]# vmset.sh eth0 192.168.0.50 vsnode noroute
[root@vsnode ~]# vim /etc/NetworkManager/system-connections/eth0.nmconnection
[connection]
id=eth0
type=ethernet
interface-name=eth0
[ipv4]
method=manual
address1==192.168.0.50/24,192.168.0.100
[root@vsnode ~]# cd /etc/NetworkManager/system-connections/
# 给lo回环口绑定VIP(192.168.0.200/32)
[root@vsnode system-connections]# cp -p eth0.nmconnection lo.nmconnection
[root@vsnode system-connections]# vim lo.nmconnection
[connection]
id=lo
type=loopback
interface-name=lo
[ipv4]
method=manual
address1==127.0.0.1/8
address2=192.168.0.200/32 # VIP仅绑定在lo口,避免ARP广播冲突
# 重载网络配置并验证
[root@RS1 system-connections]# nmcli connection reload
[root@RS1 system-connections]# nmcli connection up eth0
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/7)
[root@RS1 system-connections]# nmcli connection up lo
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/8)
bash
#检测
root@vsnode system-connections]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.0.100 0.0.0.0 UG 100 0 0 eth0
192.168.0.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
192.168.0.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
[root@vsnode system-connections]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet 192.168.0.200/32 brd 192.168.0.255 scope global noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 00:0c:29:41:e5:8b brd ff:ff:ff:ff:ff:ff
altname enp3s0
altname ens160
inet 192.168.0.50/24 brd 192.168.0.255 scope global secondary noprefixroute eth0
valid_lft forever preferred_lft forever
inet6 fe80::e40:8975:6b9:fea8/64 scope link noprefixroute
valid_lft forever preferred_lft forever核心设计:
- VS 的 eth0 仅作为通信入口,VIP(192.168.0.200)绑定在 lo 口,原因是:DR 模式下 VS 仅需接收客户端请求,无需让 VIP 参与 ARP 广播(避免与 RS 的 VIP 冲突);
- 路由指向路由器(192.168.0.100),确保 VS 能接收到客户端跨网段的请求。
3. 客户端配置:指向网关 + 访问 VIP
bash
# 配置eth0的IP(172.25.254.99)和网关(路由器eth0:172.25.254.100)
[root@client ~]# vmset.sh eth0 172.25.254.99 client
[root@client ~]# vim /etc/NetworkManager/system-connections/eth0.nmconnection
[connection]
id=eth0
type=ethernet
interface-name=eth0
[ipv4]
method=manual
address1=172.25.254.99/24,172.25.254.100 # 网关指向路由器
dns=8.8.8.8;
[root@client ~]# nmcli connection reload
[root@client ~]# nmcli connection up eth0
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/3)
[root@client ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 172.25.254.100 0.0.0.0 UG 100 0 0 eth0
172.25.254.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
#验证:ping VIP(192.168.0.200)
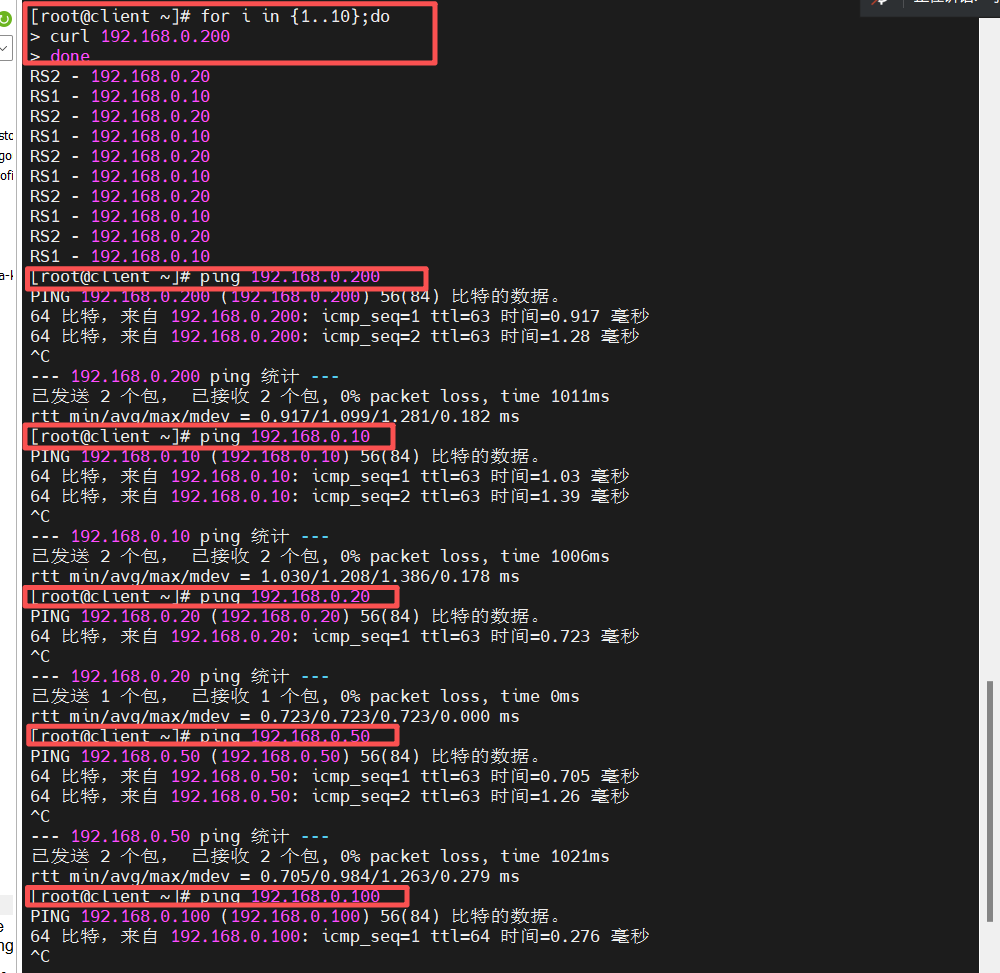
[root@client ~]# ping 192.168.0.200
PING 192.168.0.200 (192.168.0.200) 56(84) 比特的数据。
64 比特,来自 192.168.0.200: icmp_seq=1 ttl=128 时间=1.08 毫秒核心逻辑:
- 客户端的默认网关是路由器,因此访问 192.168.0.200(VIP)的请求会先发送到路由器,再转发到 VS;
- ping 通 VIP 说明跨网段转发和 VS 的 VIP 绑定已生效。
4. 真实服务器(RS1/RS2)配置:绑定 VIP+ARP 抑制 + 路由指向网关
RS1(RS2 配置完全一致,仅 IP 不同)
bash
# 配置eth0的IP(192.168.0.10)和网关(路由器eth1:192.168.0.100)
[root@RS1 ~]# vmset.sh eth0 192.168.0.10 RS1 noroute
[root@RS1 ~]# nmcli connection modify eth0 ipv4.gateway 192.168.0.100
[root@RS1 ~]# nmcli connection reload
[root@RS1 ~]# nmcli connection up eth0
[root@RS1 ~]# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 192.168.0.100 0.0.0.0 UG 100 0 0 eth0
192.168.0.0 0.0.0.0 255.255.255.0 U 100 0 0 eth0
# 给lo口绑定VIP(和VS的VIP一致:192.168.0.200/32)
[root@RS1 ~]# cd /etc/NetworkManager/system-connections/
[root@RS1 system-connections]# cp -p eth0.nmconnection lo.nmconnection
[root@RS1 system-connections]# vim lo.nmconnection
[connection]
id=lo
type=loopback
interface-name=lo
[ethernet]
[ipv4]
address1=127.0.0.1/8
address2=192.168.0.200/32 # 核心:RS的lo口绑定VIP
method=manual
bash
[root@RS1 system-connections]# nmcli connection reload
[root@RS1 system-connections]# nmcli connection up lo
连接已成功激活(D-Bus 活动路径:/org/freedesktop/NetworkManager/ActiveConnection/6)
[root@RS1 system-connections]# ip a # 可看到lo口有192.168.0.200/32的IP
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet 192.168.0.200/32 scope global lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
# 关键:ARP抑制(解决VIP冲突问题)
[root@rs1 ~]# echo 1 > /proc/sys/net/ipv4/conf/all/arp_ignore
[root@rs1 ~]# echo 1 > /proc/sys/net/ipv4/conf/lo/arp_ignore
[root@rs1 ~]# echo 2 > /proc/sys/net/ipv4/conf/lo/arp_announce
[root@rs1 ~]# echo 2 > /proc/sys/net/ipv4/conf/all/arp_announce验证:
(1)ARP 抑制的核心原理
DR 模式下,所有 RS 和 VS 都绑定了同一个 VIP(192.168.0.200),如果不做 ARP 抑制:
- 当交换机 / 路由器发送 ARP 请求 "谁是 192.168.0.200" 时,所有 RS 和 VS 都会响应,导致 ARP 冲突,请求分发混乱;
arp_ignore=1:表示只响应目标 IP 为本地网卡(eth0/lo)配置的 IP 的 ARP 请求,拒绝响应 VIP 的 ARP 请求(因为 VIP 在 lo 口且仅用于本地);arp_announce=2:表示发送 ARP 包时,优先使用数据包的源 IP 所在网卡的 IP 作为 ARP 包的源 IP,避免 RS 向外广播 VIP 的 MAC 地址。
(2)路由配置的作用
RS 的默认网关指向路由器(192.168.0.100),确保 RS 处理完请求后,能将响应数据包直接发送给客户端(无需经过 VS)。
2.2 LVS DR 模式的核心工作流程
结合实验环境,客户端访问 VIP(192.168.0.200)的完整流程:
- 客户端发起请求:客户端(172.25.254.99)向 VIP(192.168.0.200)发送请求,由于网关是路由器(172.25.254.100),请求先到达路由器 eth0;
- 路由器转发请求:路由器通过 IP 转发功能,将请求从 eth1(192.168.0.100)转发到 192.168.0.0/24 网段的 VS(192.168.0.50);
- VS 分发请求 :VS 接收请求后,通过 LVS DR 模式的调度算法(如 rr、wrr),将请求仅修改 MAC 地址(目标 MAC 改为某台 RS 的 MAC)后转发到对应的 RS(如 RS1:192.168.0.10);(关键:VS 仅修改数据链路层的 MAC,IP 层的源(客户端)、目标(VIP)地址完全不变;)
- RS 处理请求:RS 接收到请求后,由于 lo 口绑定了 VIP(192.168.0.200),会认为请求是发给自己的,处理请求后直接生成响应数据包;
- RS 直接响应客户端 :RS 的响应数据包源 IP 为 VIP(192.168.0.200),目标 IP 为客户端(172.25.254.99),通过默认网关(路由器 192.168.0.100)转发回客户端;
- 核心优势:响应数据包不经过 VS,VS 仅负责分发请求,极大降低了 VS 的负载,提升整体吞吐量。
2.3 实验关键注意事项
- VIP 的绑定位置:VS 和所有 RS 的 VIP 必须绑定在 lo 回环口,且配置为 / 32(主机路由),避免 ARP 广播冲突;
- ARP 抑制必须配置:RS 如果不配置 arp_ignore/arp_announce,会导致 VIP 的 ARP 响应冲突,请求分发失败;
- IP 转发必须开启:路由器和 VS/RS 的内核 IP 转发(net.ipv4.ip_forward=1)必须开启,否则跨网段通信失败;
- 路由指向正确:所有节点的默认网关必须指向路由器的对应网段 IP(客户端→172.25.254.100,VS/RS→192.168.0.100);
2.4 DR 模式的优势与适用场景
- 优势
- 性能极高:VS 仅分发请求(修改 MAC),响应数据包由 RS 直接返回客户端,VS 无带宽瓶颈;
- 无连接数限制:VS 不维护 TCP 连接(仅做数据包转发),支持海量并发请求;
- 兼容性好:对 RS 的操作系统无特殊要求,只需能绑定 VIP 并配置 ARP 抑制。
- 适用场景
- 高并发、高吞吐量的业务(如电商秒杀、直播弹幕、静态资源分发);
- 要求低延迟、高可用的 TCP/UDP 服务(如数据库读写分离、API 网关)。
总结:本次实验完整还原了 LVS DR 模式的核心配置和网络逻辑,关键点在于 VIP 的 lo 口绑定、ARP 抑制、跨网段转发和直接路由响应,理解这些细节就能掌握 DR 模式的核心原理。
3. 利用火墙标记解决轮询错误
3.1 背景与问题核心
这个案例围绕 LVS(Linux Virtual Server)负载均衡 展开,核心解决的是「HTTP(80 端口)和 HTTPS(443 端口)独立轮询导致的请求重复分配」问题。
先明确核心组件:
- VSNode:LVS 负载均衡器(调度器),VIP(虚拟 IP)是 192.168.0.200;
- RS1/RS2:真实服务器(后端节点),IP 分别为 192.168.0.10、192.168.0.20;
- Client:测试客户端,用于访问 VIP 验证负载效果;
- 调度算法 :
rr(Round Robin,轮询),即请求按顺序轮流分配给后端节点。
3.2 初始配置与问题分析
1.在rs主机中同时开始http和https两种协议
bash
#在RS1和RS2中开启https
[root@RS1+RS2 ~]# dnf install mod_ssl -y
[root@RS1+RS2 ~]# systemctl restart httpd
[root@RS1+RS2 ~]# systemctl restart httpd2.在vsnode中添加https的轮询策略
在 VSNode 上为 80 和 443 端口分别配置 LVS 规则:
- 为 80 端口创建虚拟服务,轮询分配给 RS1:80、RS2:80;
- 为 443 端口创建虚拟服务,轮询分配给 RS1:443、RS2:443;
bash
[root@vsnode boot]# ipvsadm -A -t 192.168.0.200:80 -s rr
[root@vsnode boot]# ipvsadm -a -t 192.168.0.200:80 -r 192.168.0.20 -g
[root@vsnode boot]# ipvsadm -a -t 192.168.0.200:80 -r 192.168.0.10 -g
[root@vsnode boot]# ipvsadm -A -t 192.168.0.200:443 -s rr
[root@vsnode boot]# ipvsadm -a -t 192.168.0.200:443 -r 192.168.0.10:443 -g
[root@vsnode boot]# ipvsadm -a -t 192.168.0.200:443 -r 192.168.0.20:443 -g
[root@vsnode boot]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
TCP 192.168.0.200:80 rr
-> 192.168.0.10:80 Route 1 0 0
-> 192.168.0.20:80 Route 1 0 0
TCP 192.168.0.200:443 rr
-> 192.168.0.10:443 Route 1 0 0
-> 192.168.0.20:443
[root@vsnode ~]# systemctl restart ipvsadm3.轮询错误展示
bash
# 客户端测试:两次请求(80+443)都分配到了RS2
[root@client ~]# curl 192.168.0.200;curl -k https://192.168.0.200
RS2 - 192.168.0.20
RS2 - 192.168.0.20
#当上述设定完成后http和https是独立的service,轮询会出现重复问题- 问题根源
LVS 中,80 端口和 443 端口是两个完全独立的「虚拟服务」:
- HTTP 请求(80)走「80 端口的轮询队列」,HTTPS 请求(443)走「443 端口的轮询队列」;
- 两个队列各自独立计数,导致 HTTP 和 HTTPS 请求可能被分配到同一个 RS,破坏了「轮询均匀分配」的预期。
3.3 解决方案:防火墙标记(MARK)+ 基于标记的 LVS 调度
- 核心思路:将访问 VIP 的 80/443 端口的所有数据包打上统一标记,让 LVS 基于「标记」而非「端口」做轮询,把 80 和 443 的请求合并到同一个轮询队列中。
给 80/443 数据包打标记(iptables mangle 表)
bash
[root@vsnode boot]# iptables -t mangle -A PREROUTING -d 192.168.0.200 -p tcp -m multiport --dports 80,443 -j MARK --set-mark 6666
t mangle:操作「mangle 表」(专门用于修改数据包标记 / TTL 等属性);A PREROUTING:在「PREROUTING 链」(数据包进入本机前的处理环节)添加规则;d 192.168.0.200:目标 IP 是 VIP(只匹配访问负载均衡 VIP 的数据包);p tcp:协议为 TCP;m multiport --dports 80,443:匹配目标端口为 80 或 443 的数据包;j MARK --set-mark 6666:对匹配的数据包打上「6666」的标记。
- 基于标记创建 LVS 虚拟服务
bash
[root@vsnode boot]# ipvsadm -A -f 6666 -s rr
ipvsadm:LVS 的核心配置工具;-A:添加(Add)一个虚拟服务;-f 6666:基于「防火墙标记(fwmark)6666」创建虚拟服务(替代原来的「端口 + IP」);-s rr:调度算法为轮询(Round Robin)。
- 绑定后端 RS 到标记服务
bash
[root@vsnode boot]# ipvsadm -a -f 6666 -r 192.168.0.10 -g
[root@vsnode boot]# ipvsadm -a -f 6666 -r 192.168.0.20 -g
-a:添加(Add)后端真实服务器到虚拟服务;-f 6666:关联到标记为 6666 的虚拟服务;-r 192.168.0.10/20:指定后端真实服务器的 IP;-g:转发模式为「Gateway」(DR 模式,直接路由),这是 LVS 最常用的高效转发模式(数据包不经过 VSNode 转发回包,仅调度请求)。
- 在客户端测试结果
bash
[root@client ~]# curl 192.168.0.200;curl -k https://192.168.0.200
RS2 - 192.168.0.20
RS1 - 192.168.0.10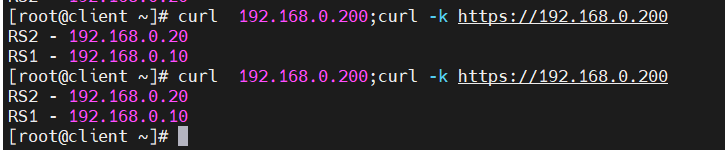
HTTP(80)请求分配到 RS2,HTTPS(443)请求分配到 RS1,实现了跨端口的统一轮询。
底层原理
- 所有访问 VIP:80 和 VIP:443 的数据包,都会被 iptables 打上 6666 标记;
- LVS 不再区分 80/443 端口,而是以「标记 6666」为维度做轮询;
- 80 和 443 的请求进入同一个轮询队列,按顺序分配给 RS1、RS2,解决了「独立端口轮询导致的重复分配」问题。
3.4 总结
这个案例的核心是「通过防火墙标记(MARK)将多端口请求归一化,让 LVS 基于标记而非端口做负载调度」,解决了 HTTP/HTTPS 独立轮询导致的分配重复问题。核心步骤:
- 给 VIP 的 80/443 数据包打统一标记;
- 基于标记创建 LVS 虚拟服务;
- 绑定后端 RS 到标记服务;
- 实现跨端口的统一轮询调度。
4. 利用持久连接实现会话粘滞
4.1 核心背景
会话粘滞(会话持久性)是负载均衡中的重要需求,指同一客户端的多次请求被固定转发到同一台后端服务器,而 IPVS 的persistent(持久连接)参数可实现这一效果,文件中通过具体命令和测试验证了该功能。
4.2 配置
- 设定 IPVS 调度策略
bash
[root@vsnode ~]# ipvsadm -A -f 6666 -s rr -p 1
-A:添加新的虚拟服务;-f 6666:基于防火墙标记(fwmark)6666 定义虚拟服务(而非传统的 IP + 端口);-s rr:调度算法为rr(轮询,Round Robin);-p 1:启用持久连接,超时时间为 1 秒(即 1 秒内同一客户端的请求会固定到同一后端服务器)。
bash
[root@vsnode ~]# ipvsadm -Ln
IP Virtual Server version 1.2.1 (size=4096)
Prot LocalAddress:Port Scheduler Flags
-> RemoteAddress:Port Forward Weight ActiveConn InActConn
FWM 6666 rr persistent 1
-> 192.168.0.10:0 Route 1 0 0
-> 192.168.0.20:0 输出解读:
FWM 6666:基于防火墙标记 6666 的虚拟服务;rr persistent 1:轮询调度 + 1 秒持久连接;- 后端节点:
192.168.0.10和192.168.0.20(两台真实服务器 RS),转发模式为Route(路由模式),权重Weight=1(调度优先级相同)。
- 测试会话粘滞效果
bash
[root@client ~]# curl 192.168.0.200
RS1 - 192.168.0.10
[root@client ~]# curl 192.168.0.200
RS1 - 192.168.0.10
- 操作:客户端多次访问虚拟服务 IP(192.168.0.200);
- 结果:两次请求均返回
RS1 - 192.168.0.10,说明持久连接生效 ------ 即便调度算法是轮询,但 1 秒内同一客户端的请求被固定到了192.168.0.10这台后端服务器,验证了会话粘滞。
- 观察 IPVS 连接状态
bash
[root@vsnode ~]# watch -n 1 ipvsadm -Lnc
IPVS connection entries
pro expire state source virtual destination
TCP 01:56 FIN_WAIT 172.25.254.99:42420 192.168.0.200:80 192.168.0.20:80
IP 00:57 ASSURED 172.25.254.99:0 0.0.26.10:0 192.168.0.20:0
TCP 01:54 FIN_WAIT 172.25.254.99:46216 192.168.0.200:80 192.168.0.20:80
TCP 01:55 FIN_WAIT 172.25.254.99:46222 192.168.0.200:80 192.168.0.20:80输出解读:
pro:协议(TCP/IP);expire:连接过期时间(如 01:56 表示 1 分 56 秒后过期);state:连接状态(FIN_WAIT 为关闭阶段,ASSURED 为稳定连接);source:客户端 IP + 端口(172.25.254.99);virtual:虚拟服务 IP + 端口(192.168.0.200:80);destination:后端服务器 IP + 端口(192.168.0.20:80);- 核心结论:客户端的多个连接均指向同一后端服务器,验证了会话粘滞的有效性。
4.3 整体总结
通过配置 IPVS 持久连接规则→测试访问效果→观察连接状态 的流程,演示了如何利用 IPVS 的persistent参数实现会话粘滞:
- 基于防火墙标记定义虚拟服务,避免依赖具体 IP + 端口;
- 轮询调度结合短时间(1 秒)持久连接,确保同一客户端的请求固定到同一后端;
- 从测试和连接状态观察两方面验证了会话粘滞的效果。