在现代云原生环境中,内核级故障往往是生产事故中最棘手的一类,它们隐蔽、突然、且灾难性。本项目在单台 EC2 实例上构建了一套完整的内核可观测性 AI 分析管道,将 eBPF 深度内核追踪、事件流管道、规则引擎与大语言模型诊断能力融为一体。
HUATUO v2.2.0 版本新增了SSE发布CloudEvents规范内核事件的功能,现在我们可以主动对目标事件进行订阅并更加灵活地处理了。
官方的内核事件采集发布示意图如下
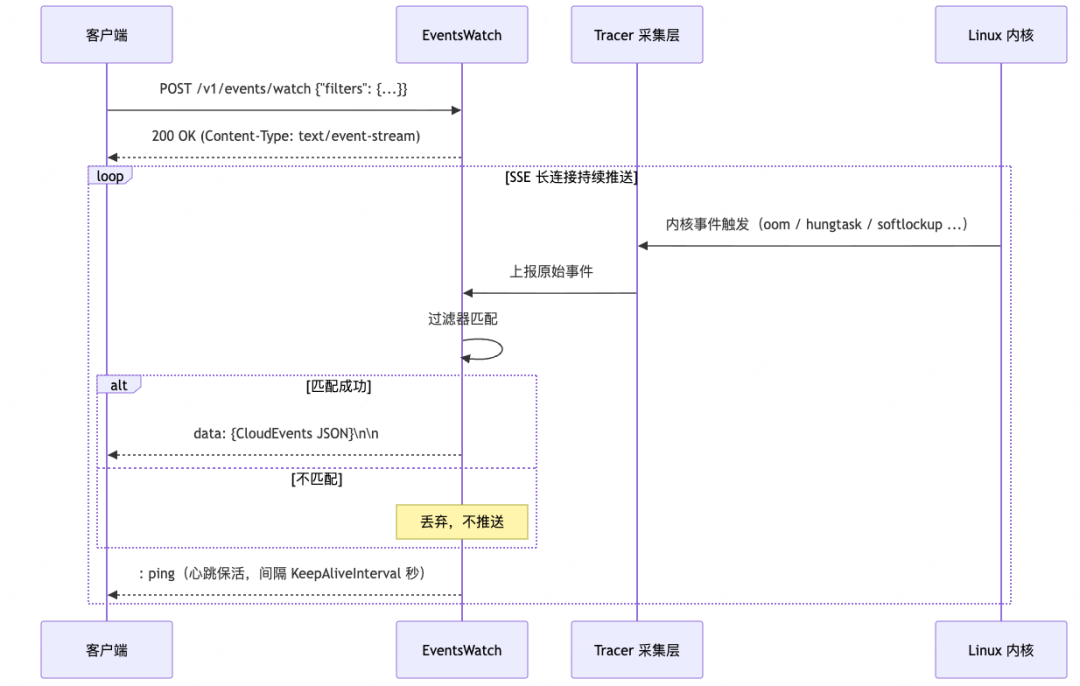
本文项目的主要工作流程如下:
- HUATUO 通过 eBPF tracer 在内核态采集事件,经由 SSE(Server-Sent Events)规范暴露为 CloudEvents 格式的事件流
- Python 编写的 SSEProducer 将事件实时写入 Redis Streams
- AIConsumer 从流中消费事件
- 通过规则引擎快速匹配已知模式
- 对于复杂或未知事件则调用 LiteLLM 代理的大模型进行深度诊断。
DeepSeek大模型 litellm代理服务 规则引擎 AIConsumer Redis7 Streams SSEProducer(Python) huatuov2.2.0(eBPF采集) DeepSeek大模型 litellm代理服务 规则引擎 AIConsumer Redis7 Streams SSEProducer(Python) huatuov2.2.0(eBPF采集) 整体部署:Amazon Linux2023 EC2单机架构 alt 规则无法判定/需深度分析 eBPF采集数据推送(SSE 19704) xadd 写入流数据 写入确认 xreadgroup 消费流数据 批量原始观测数据 送入已知模式规则引擎 规则匹配结果(无LLM快速判定) 构造提示词调用LLM接口 转发请求至DeepSeek 智能分析结果返回 LLM结构化结论回传 融合规则+LLM结果完成业务研判
运行环境是一台 Amazon Linux 2023 EC2 实例:内核版本 6.1.131。所有组件通过 Docker 容器部署,HUATUO 主进程以 privileged 权限运行以满足 eBPF 的内核访问需求。
理论基础
eBPF
Extended Berkeley Packet Filter(eBPF)是近年来 Linux 内核领域最具颠覆性的技术之一。它允许开发者在不重新编译内核、不加载内核模块的前提下,在内核态安全地运行沙盒程序。这种能力彻底改变了内核可观测性的实现方式,从"侵入式插桩"进化为"安全动态追踪"。
-
eBPF 程序通过挂载点(hook points)介入内核执行流程。常见的挂载点包括:tracepoints(内核预定义的静态探测点)、kprobes(动态插入到内核函数入口或返回点)、perf events(硬件性能计数器和软件事件)。当内核执行到挂载点时,eBPF 字节码被触发,可以读取上下文数据并传递到用户空间。
-
安全性是 eBPF 能够进入生产环境的关键。eBPF verifier 会在加载程序前进行静态分析:确保内存访问边界安全、循环次数有界、不存在空指针解引用、不会导致内核崩溃。
-
传统内核追踪工具各有局限:
ftrace功能强大但只能追踪内核预定义点;perf擅长采样分析但难以做事件驱动;SystemTap功能完整却需要编译内核模块,生产环境风险极高。eBPF 集各家之长:动态加载、安全可验证、可编程能力强大、性能开销可控。
HUATUO 充分利用了 eBPF 的上述优势,内置了丰富的 tracer 集合:
softirq_tracing追踪软中断禁用时长;net_rx_latency监控网络数据包处理延迟;oom捕获 OOM Killer 事件;hungtask检测 D 状态阻塞进程;softlockup识别 CPU 软锁定;memreclaim追踪内存回收阻塞;dropwatch监控内核丢包;ras捕获硬件可靠性错误;memburst检测内存突发分配;netdev_txqueue_timeout追踪网卡发送队列超时。
每个 tracer 都针对特定的内核故障场景,共同构成完整的内核健康监测矩阵。
CloudEvents
CloudEvents 是 CNCF 托管的事件数据规范,定义了一套与平台无关的事件描述格式。在事件驱动架构中,不同系统产生的事件往往格式各异:有的用 timestamp,有的用 created_at;有的把事件体放在 body,有的放在 payload。这种碎片化导致事件消费者需要为每个来源适配解析逻辑,维护成本极高。
CloudEvents 规范定义了一组必需和可选属性:
specversion标识规范版本;id是事件的唯一标识符;source标识事件来源(通常是一个 URI 路径);type描述事件类型(采用反向域名格式);datacontenttype声明数据体编码格式;time是事件发生的时间戳;data是事件的实际负载。
这种标准化带来的好处是事件消费者只需理解一种格式,事件路由器可以基于标准属性做匹配过滤,事件溯源系统可以有统一的存储 schema。CloudEvents 已经成为云原生生态的事实标准------Knative、Azure Event Grid 都对其提供原生支持。
HUATUO v2.2.0 的 SSE 端点完整实现了 CloudEvents 规范。以下是从实际测试中截取的原始输出:
id 是 UUID 格式的唯一标识;source 包含了主机名和 tracer 名称;type 采用 tech.huatuo.kernel.event 的反向域名格式;time 是 ISO 8601 格式的 UTC 时间戳;data 字段包含了实际的内核事件详情------主机名、区域、观测时间戳、tracer 名称和运行类型。完整的 CloudEvents 结构让下游系统无需额外适配即可消费这些事件。
bash
$ curl -s http://localhost:19704/v1/events/watch -X POST \
-H "Content-Type: application/json" \
-H "Accept: text/event-stream" \
-d '{}'
data: {
"specversion": "1.0",
"id": "2d833c8e-cd9f-47f0-b83b-8b129d7d2b69",
"source": "/huatuo/ip-172-31-14-46.cn-north-1.compute.internal/softirq_tracing",
"type": "tech.huatuo.kernel.event",
"datacontenttype": "application/json",
"time": "2026-05-19T15:31:58.354290512Z",
"data": {
"hostname": "ip-172-31-14-46.cn-north-1.compute.internal",
"region": "example",
"observed_timestamp": "2026-05-19 15:31:58.354 +0000",
"tracer_name": "softirq_tracing",
"tracer_run_type": "auto"
}
}SSE
Server-Sent Events(SSE)是一种基于 HTTP 的服务端推送技术。WebSocket 可以双向通信,但如果场景只是服务端向客户端单向推送事件流,SSE 往往是更务实的选择。
SSE 协议极其简洁:响应头 Content-Type: text/event-stream 声明这是一个事件流;每条消息以 data: 开头,后跟 JSON 或文本内容;消息之间以空行分隔。客户端通过标准的 EventSource API 或简单的 HTTP 请求即可消费流。SSE 原生支持断线重连------客户端重连时可以带上 Last-Event-ID 头,服务端据此从断点续传。
HUATUO 在 /v1/events/watch 端点暴露 SSE 接口。值得注意的是,这个端点接受 POST 请求(而非传统 SSE 的 GET),请求体是一个 JSON 对象,可以包含过滤条件。这种设计让客户端能够按需订阅特定类型的事件,减少网络传输开销。
测试 SSE 端点的方法非常直接:
bash
curl -s http://localhost:19704/v1/events/watch -X POST \
-H "Content-Type: application/json" \
-H "Accept: text/event-stream" \
-d '{}'返回结果如下:
data: {"specversion":"1.0","id":"2d833c8e-cd9f-47f0-b83b-8b129d7d2b69",...}
data: {"specversion":"1.0","id":"0f0e3582-bf96-488b-a471-a1fccef58c51",...}
data: {"specversion":"1.0","id":"4777afd9-23d5-49c0-a074-a3ca706bfb0f",...}每一行 data: 后面跟着一个完整的 CloudEvents JSON 对象。空行(虽然在显示中不明显)分隔各个事件。这种极简的协议设计让 SSE 在单向事件推送场景中比 WebSocket 更轻量、更易调试。
Redis Streams
Redis Streams 是 Redis 5.0 引入的数据结构,专门用于实现消息队列和事件流。它本质上是一个 append-only log,每条消息通过 XADD 命令追加到流,消费者通过 XREADGROUP 命令以消费者组模式读取------这种模式与 Kafka 的消费者组概念如出一辙。
关键命令包括:
-
XADD stream_name * field1 value1 field2 value2:向流中追加消息Redis 所有数据结构(String/Hash/List/Stream)都是 惰性创建 的,没有创建流这个单独操作,因此需要在写入消息(XADD)时把 maxlen 带上
-
XGROUP CREATE stream_name group_name $:创建消费者组$表示从现在开始的新消息才消费 ,不消费历史消息。0表示从消息流第一条消息开始消费
-
XREADGROUP GROUP group_name consumer_name BLOCK timeout STREAMS stream_name >:以消费者组模式读取,>表示只读取新消息 -
XACK stream_name group_name message_id:确认消息已处理
本文中为什么选择 Redis Streams 而非 Kafka ?
- Kafka 功能强大,但即使是单节点部署也需要 Zookeeper(尽管 KRaft 模式已经去掉这个依赖,但复杂度依然存在)。对于单台 EC2 实例的轻量级场景,Kafka 显然过于重量级。
- Redis Streams 在这个问题域中恰到好处:单机部署、毫秒级延迟、内置持久化(AOF/RDB)、支持消费者组、支持消息过期(通过
MAXLEN限制流长度)、内存效率高。我们的场景部署在单台 EC2 实例上事件来源单一,不需要 Kafka 的分布式能力,Redis Streams 的单机性能绰绰有余。
我们配置 maxlen=10000,即流中最多保留 10000 条消息,超出时自动淘汰最旧的消息。这是基于内存安全的角度考虑。对于实时分析场景,超过一定窗口的旧事件已经失去了即时处理的价值。流名称为 huatuo:kernel:events,消费者组名称为 ai-analyzer。
LiteLLM
LiteLLM 是一个开源的 LLM 代理服务,它提供了统一的大模型调用接口。无论底层是 OpenAI、Azure、Anthropic 还是 Bedrock,调用方都只需面对统一的 REST API。这种代理模式带来的好处是显而易见的:模型切换无需改代码、API Key 集中管理、内置速率限制、支持负载均衡。
我们的环境部署 LiteLLM 于 localhost:4000,AIConsumer 通过 POST /chat/completions 端点调用模型,请求头携带 Bearer Token 认证。当内核事件触发 LLM 分析通道时,完整的事件上下文会被封装成 Prompt 发送到 LiteLLM,由其转发给模型进行诊断推理。
组件部署
HUATUO 部署
HUATUO 容器以 privileged 特权模式运行。
- eBPF 程序需要
CAP_BPF和CAP_PERFMON能力才能加载和访问 perf 事件; - 此外,还需要访问
/sys(内核参数和 tracepoint 控制)、/proc(进程信息)、/run(cgroup 挂载点)等目录。
虽然理论上可以通过细粒度的 capability 授予而非完全 privilege,但实践中privileged 模式是最省心的选择------尤其在内核版本 5.8 之前,CAP_BPF 还不存在,必须依赖更底层的权限。
完整的部署命令如下
--privileged:授予所有 Linux capabilities,访问所有设备--cgroupns=host:使用宿主机的 cgroup namespace(内核事件发生在宿主机层面)--network=host:直接使用宿主机网络栈,无网络隔离-v /sys:/sys:rw:读写挂载 /sys,访问 tracepoint 和内核参数-v /proc:/proc:rw:读写挂载 /proc,访问进程信息和 perf 事件-v /run:/run:rw:访问 cgroup 文件系统-v /etc:/etc:ro:只读访问系统配置(用于识别主机名、发行版等)-v /var:/var:ro:只读访问系统日志目录
bash
docker run -d \
--name huatuo-bamai \
--privileged \
--cgroupns=host \
--network=host \
--restart unless-stopped \
-v /sys:/sys:rw \
-v /proc:/proc:rw \
-v /run:/run:rw \
-v /etc:/etc:ro \
-v /var:/var:ro \
-v /home/ec2-user/huatuo-analyzer/record:/home/huatuo-bamai/record \
huatuo/huatuo-bamai:latestRedis 部署
Redis 部署同样采用 host 网络模式以最小化延迟,事件生产和消费都发生在同一台机器上。
--maxmemory 512mb:限制 Redis 最大内存使用量为 512MB--maxmemory-policy allkeys-lru:当内存达到上限时,对所有键执行 LRU 淘汰
bash
docker run -d \
--name huatuo-redis \
--network=host \
--restart unless-stopped \
redis:7-alpine \
redis-server --maxmemory 512mb --maxmemory-policy allkeys-lru内存淘汰策略选择 allkeys-lru 而非 volatile-lru(只淘汰有过期时间的键),因为我们期望 Redis Streams 作为实时事件缓冲区,而非持久存储。当内存压力增大时,应该淘汰最旧的未访问数据以保护新事件的写入能力。这与我们设置的 MAXLEN=10000 语义一致,即超过窗口的数据可以被安全丢弃。
核心代码详解
整个分析管道的核心逻辑实现在 kernel_event_analyzer.py中。配置与规则引擎在文件前段,SSEProducer 负责事件摄入,AIConsumer 负责事件分析与诊断输出。
配置与规则引擎
配置采用环境变量模式,所有关键参数都可以在运行时覆盖:
python
HUATUO_SSE_URL = os.getenv("HUATUO_SSE_URL", "http://localhost:19704/v1/events/watch")
REDIS_HOST = os.getenv("REDIS_HOST", "127.0.0.1")
REDIS_PORT = int(os.getenv("REDIS_PORT", "6379"))
STREAM_NAME = "huatuo:kernel:events"
CONSUMER_GROUP = "ai-analyzer"
CONSUMER_NAME = "analyzer-1"
LLM_URL = os.getenv("LLM_URL", "http://localhost:4000/chat/completions")
LLM_MODEL = os.getenv("LLM_MODEL", "deepseek.v3-v1:0")
WINDOW_SECONDS = int(os.getenv("WINDOW_SECONDS", "30"))
MAX_EVENTS = int(os.getenv("MAX_EVENTS", "15"))
STORM_THRESHOLD = int(os.getenv("STORM_THRESHOLD", "20"))
STORM_COOLDOWN = int(os.getenv("STORM_COOLDOWN", "60"))规则引擎的核心理念是:已知的问题模式不需要 LLM 分析(既节省 Token 成本,也避免了大模型的不确定性)。KNOWN_PATTERNS 字典定义了 10 种已知 tracer 的诊断知识:
python
KNOWN_PATTERNS = {
"oom": {
"severity": Severity.HIGH,
"summary": "OOM Killer 触发",
"diagnosis": "进程内存使用超过可用物理内存 + Swap,内核选择了进程终止。",
"actions": [
"检查触发进程的内存使用趋势",
"确认容器内存限制是否合理",
"考虑增加内存限制或优化内存使用",
"检查是否存在内存泄漏",
],
},
"hungtask": {
"severity": Severity.HIGH,
"summary": "D 状态进程阻塞",
"diagnosis": "进程进入不可中断睡眠状态(D state),通常由 I/O 阻塞或锁竞争导致。",
"actions": [
"检查磁盘 I/O 状态和延迟 (iostat -xz 1)",
"排查 NFS/网络存储是否正常",
"检查是否有锁竞争",
"超过 120s 可能需要重启受影响服务",
],
},
"softlockup": {
"severity": Severity.CRITICAL,
"summary": "CPU 软锁定",
"diagnosis": "某个 CPU 核心长时间未调度,可能由死锁、长时间关中断或死循环导致。",
"actions": [
"立即检查系统日志 (dmesg / journalctl -k)",
"排查是否有内核模块死锁",
"严重时可能需要重启节点",
],
},
"softirq_tracing": {
"severity": Severity.MEDIUM,
"summary": "软中断异常",
"diagnosis": "软中断被禁用时间超过阈值,可能影响网络和块 I/O 性能。",
"actions": [
"检查是否有频繁关中断的代码路径",
"监控网络和磁盘 I/O 延迟变化",
],
},
"memreclaim": {
"severity": Severity.MEDIUM,
"summary": "内存回收阻塞",
"diagnosis": "直接内存回收阻塞进程超过阈值,表明系统内存压力大。",
"actions": [
"检查系统内存使用情况 (free -h)",
"考虑增加内存或调整 vm.watermark 配置",
],
},
"dropwatch": {
"severity": Severity.MEDIUM,
"summary": "内核网络丢包",
"diagnosis": "内核网络栈中发生丢包,可能由缓冲区溢出、路由问题导致。",
"actions": [
"检查网络接口统计 (ethtool -S <dev>)",
"排查 socket 缓冲区是否不足",
],
},
"net_rx_latency": {
"severity": Severity.MEDIUM,
"summary": "网络入向延迟异常",
"diagnosis": "网络数据包从驱动到内核栈的处理延迟超过阈值。",
"actions": [
"检查 CPU 负载和 softirq 分布 (/proc/softirqs)",
"排查是否有流量突发",
],
},
"netdev_txqueue_timeout": {
"severity": Severity.HIGH,
"summary": "网卡发送队列超时",
"diagnosis": "网卡发送队列超时,可能指示网卡硬件故障或网络拥塞。",
"actions": [
"检查网卡链路状态 (ethtool <dev>)",
"考虑更换网卡或调整 TX 队列参数",
],
},
"ras": {
"severity": Severity.CRITICAL,
"summary": "硬件错误(RAS)",
"diagnosis": "检测到硬件级错误,可能预示硬件即将失效。",
"actions": [
"立即检查硬件日志",
"强烈建议尽快更换故障硬件",
],
},
"memburst": {
"severity": Severity.MEDIUM,
"summary": "内存突发分配",
"diagnosis": "检测到内存使用量在短时间内大幅增长。",
"actions": [
"检查是否有突发内存分配的进程",
"排查内存泄漏",
],
},
}每个 tracer 的规则包含四个字段:severity 表示严重程度(LOW/MEDIUM/HIGH/CRITICAL);summary 是一句话摘要,用于快速识别问题类型;diagnosis 是问题原因的技术解释;actions 是按优先级排序的排查步骤列表。
除了单事件匹配,规则引擎还定义了事件关联规则:
python
CRITICAL_COMBOS = [
frozenset({"oom", "hungtask"}),
frozenset({"oom", "softlockup"}),
frozenset({"hungtask", "softlockup"}),
frozenset({"softirq_tracing", "softlockup"}),
frozenset({"oom", "memreclaim"}),
]这些组合表示"同时出现时情况可能更严重"的事件集合。例如,OOM 和 hungtask 同时发生暗示系统可能在极端内存压力下出现 I/O 阻塞;softlockup 与任何其他事件同时出现通常意味着系统已经处于不稳定状态。当检测到这些组合时,即使所有涉及的 tracer 都在 KNOWN_PATTERNS 中,也会触发 LLM 分析通道以获取更深度的关联诊断。
SSEProducer:事件摄入管道
SSEProducer 类负责从 HUATUO 的 SSE 端点拉取事件并写入 Redis Streams。核心逻辑在 run() 方法中:
python
class SSEProducer:
def __init__(self, rdb):
self.rdb = rdb
self.running = True
self.stats = {"ingested": 0, "errors": 0}
def run(self):
log("INFO", f"连接 SSE: {HUATUO_SSE_URL}")
while self.running:
try:
resp = requests.post(
HUATUO_SSE_URL,
json={"filters": {}},
headers={
"Content-Type": "application/json",
"Accept": "text/event-stream",
"Cache-Control": "no-cache",
},
stream=True,
timeout=300,
)
resp.raise_for_status()
log("OK", "SSE 连接建立,接收内核事件中")
for line in resp.iter_lines(decode_unicode=True):
if not self.running:
break
if line and line.startswith("data:"):
try:
event = json.loads(line[5:].strip())
self._publish(event)
except json.JSONDecodeError:
pass
except requests.RequestException as e:
log("WARN", f"SSE 断开: {e},5s 后重连")
self.stats["errors"] += 1
time.sleep(5)关键设计点:
stream=True让requests以流式方式读取响应,而不是等待整个响应体加载完毕------这对于长连接的 SSE 是必需的timeout=300设置 5 分钟的 socket 超时,防止连接僵死- 自动重连机制:当连接断开时,等待 5 秒后重新建立连接
- JSON 解析在
line[5:].strip()上进行,跳过data:前缀
_publish() 方法将事件写入 Redis Streams:
python
def _publish(self, event):
try:
data = event.get("data", {})
self.rdb.xadd(STREAM_NAME, {
"event_id": event.get("id", ""),
"tracer_name": data.get("tracer_name", "unknown"),
"hostname": data.get("hostname", ""),
"observed_timestamp": data.get("observed_timestamp", ""),
"region": data.get("region", ""),
"container_id": data.get("container_id", ""),
"full_event": json.dumps(event, ensure_ascii=False),
}, maxlen=10000)
self.stats["ingested"] += 1
if self.stats["ingested"] <= 3 or self.stats["ingested"] % 500 == 0:
log("REDIS", f"已写入 {self.stats['ingested']} 条")
except redis.RedisError as e:
log("ERR", f"Redis 写入失败: {e}")xadd() 的 maxlen=10000 参数确保流不会无限增长。写入事件时,我们同时存储了 CloudEvents 的顶层字段(event_id)和 data 字段中的关键信息(tracer_name, hostname 等),同时将完整事件 JSON 存储在 full_event 字段中以便后续分析使用。
实际运行时的日志输出:
[15:28:02] ℹ️ 连接 SSE: http://localhost:19704/v1/events/watch
[15:28:02] ✅ SSE 连接建立,接收内核事件中
[15:28:02] 💾 已写入 1 条AIConsumer:事件消费与智能分析
AIConsumer 是整个管道的大脑,负责从 Redis Streams 消费事件并决定如何分析。
初始化时创建消费者组(如果不存在):
python
class AIConsumer:
def __init__(self, rdb):
self.rdb = rdb
self.running = True
self.event_buffer = []
self.last_flush_time = time.time()
self.event_counts = defaultdict(int)
self.storm_active = {}
self.lock = threading.Lock()
self.stats = {"total": 0, "rule": 0, "ai": 0, "suppressed": 0}
try:
self.rdb.xgroup_create(STREAM_NAME, CONSUMER_GROUP, id="0", mkstream=True)
except redis.ResponseError as e:
if "BUSYGROUP" not in str(e):
raisexgroup_create() 的 id="0" 表示消费者组从流的最开始读取(而非只读取新消息),mkstream=True 如果流不存在则自动创建。BUSYGROUP 错误表示消费者组已存在,这是预期行为,直接忽略。
消费循环使用 xreadgroup() 以阻塞模式读取:
python
def run(self):
log("INFO", f"消费者启动 (窗口: {WINDOW_SECONDS}s / {MAX_EVENTS} 条)")
while self.running:
try:
messages = self.rdb.xreadgroup(
CONSUMER_GROUP, CONSUMER_NAME,
{STREAM_NAME: ">"},
count=MAX_EVENTS, block=5000,
)
if not messages:
self._flush_if_timeout()
continue
for stream, msgs in messages:
for msg_id, fields in msgs:
event = json.loads(fields.get("full_event", "{}"))
self._on_event(event)
self.rdb.xack(STREAM_NAME, CONSUMER_GROUP, msg_id)
except redis.RedisError as e:
log("ERR", f"Redis 读取失败: {e}")
time.sleep(2)block=5000 表示最多阻塞 5 秒等待新消息。当消费者成功处理消息后,调用 xack() 确认消息,防止被重复投递。注意这里的确认粒度是单条消息,虽然 count=MAX_EVENTS 每次最多读取 15 条,但每条消息独立确认,失败重试时不会影响已处理的消息。
事件风暴检测在 _on_event() 中实现:
python
def _on_event(self, event):
data = event.get("data", {})
tracer = data.get("tracer_name", "unknown")
self.stats["total"] += 1
self.event_counts[tracer] += 1
if self.event_counts[tracer] >= STORM_THRESHOLD:
if not self.storm_active.get(tracer):
log("STORM", f"事件风暴: {tracer} ({self.event_counts[tracer]} 条)")
self.storm_active[tracer] = time.time()
if tracer in self.storm_active:
if time.time() - self.storm_active[tracer] > STORM_COOLDOWN:
del self.storm_active[tracer]
self.event_counts[tracer] = 0
else:
self.stats["suppressed"] += 1
return
with self.lock:
self.event_buffer.append(event)
self._flush_if_ready()风暴检测的逻辑是:当某个 tracer 的事件数量达到 STORM_THRESHOLD=20 时,标记该 tracer 进入风暴状态,在 STORM_COOLDOWN=60 秒内,该 tracer 的新事件被抑制(不计入分析管道)。这是一种背压机制 :在一个繁忙的生产环境中,net_rx_latency 在网络故障时可能每秒产生数百条事件,如果不加以抑制,会迅速消耗分析管道的处理能力甚至打爆 LLM API 配额。
窗口刷新逻辑支持两种触发条件:
python
def _flush_if_ready(self):
with self.lock:
should = (len(self.event_buffer) >= MAX_EVENTS
or time.time() - self.last_flush_time >= WINDOW_SECONDS)
if should:
self._flush()时间窗口(30 秒)或计数窗口(15 条事件)任一满足即触发刷新。这种双触发设计兼顾了低流量和高流量场景:低流量时不会因为凑不够 15 条而无限等待;高流量时不会因为时间窗口未到而积压过多事件。
_flush() 方法执行实际的分析逻辑:
python
def _flush(self):
with self.lock:
if not self.event_buffer:
return
events = list(self.event_buffer)
self.event_buffer.clear()
self.last_flush_time = time.time()
tracer_buckets = defaultdict(list)
for e in events:
tracer_buckets[e.get("data", {}).get("tracer_name", "unknown")].append(e)
known_tracers = [t for t in tracer_buckets if t in KNOWN_PATTERNS]
unknown_tracers = [t for t in tracer_buckets if t not in KNOWN_PATTERNS]
for tracer in known_tracers:
self._handle_rule_aggregated(tracer, tracer_buckets[tracer])
self.stats["rule"] += 1
all_tracers = set(tracer_buckets.keys())
has_combo = any(c.issubset(all_tracers) for c in CRITICAL_COMBOS)
if unknown_tracers or has_combo:
batch = events if has_combo else [e for t in unknown_tracers for e in tracer_buckets[t]]
self._handle_ai(batch, has_combo)
self.stats["ai"] += 1首先将事件按 tracer 类型分桶。对于已知的 tracer,调用规则引擎处理;对于未知 tracer 或存在关键事件组合的场景,调用 LLM 分析。
_handle_rule_aggregated() 方法输出格式化的诊断报告:
python
def _handle_rule_aggregated(self, tracer, events):
pattern = KNOWN_PATTERNS.get(tracer, {})
sev = pattern.get("severity", Severity.MEDIUM)
icons = {"low": "🟢", "medium": "🟡", "high": "🔴", "critical": "💀"}
sample = events[0].get("data", {})
times = sorted({e.get("data", {}).get("observed_timestamp", "") for e in events})
print(f"\n{'=' * 60}", flush=True)
print(f"{icons.get(sev.value, '⚪')} [{sev.value.upper()}] "
f"{pattern.get('summary', tracer)} ×{len(events)}", flush=True)
print(f"{'=' * 60}", flush=True)
print(f" 主机: {sample.get('hostname', 'N/A')}", flush=True)
print(f" 时间范围: {times[0][:23]} ~ {times[-1][:23]}", flush=True)
print(f" 事件数: {len(events)}", flush=True)
if pattern.get("diagnosis"):
print(f" 诊断: {pattern['diagnosis']}", flush=True)
if pattern.get("actions"):
print(f" 建议:", flush=True)
for i, a in enumerate(pattern["actions"], 1):
print(f" {i}. {a}", flush=True)
print(f"{'=' * 60}\n", flush=True)关键设计是"聚合输出":同一 tracer 的多条事件合并成一条报告,用 ×N 标记事件数量。这避免了在事件密集时刷屏式输出,同时保留了时间范围信息。
实际运行时的输出示例:
============================================================
🟡 [MEDIUM] 网络入向延迟异常 ×14
============================================================
主机: ip-172-31-14-46.cn-north-1.compute.internal
时间范围: 2026-05-19 15:28:02.254 ~ 2026-05-19 15:28:02.255
事件数: 14
诊断: 网络数据包从驱动到内核栈的处理延迟超过阈值。
建议:
1. 检查 CPU 负载和 softirq 分布 (/proc/softirqs)
2. 排查是否有流量突发
============================================================风暴检测日志:
[15:28:02] 🌊 事件风暴: net_rx_latency (20 条)最终统计:
[15:28:47] 📊 Consumer: {'total': 3287, 'rule': 4, 'ai': 0, 'suppressed': 3249}
[15:28:47] 📊 Producer: {'ingested': 3287, 'errors': 0}这组数字很有意思:45 秒内摄入了 3287 条事件,约每秒 73 条;风暴抑制机制捕获了 3249 条(98.5%),只有 4 条触发了规则引擎输出,LLM 通道完全没有触发(没有未知事件类型,也没有关键事件组合)。这说明在空闲的机器上,主要是 net_rx_latency 和 softirq_tracing 这类低级别 tracer 在持续产生噪声事件------它们在阈值边缘波动,但并不代表真正的故障。
LLM 分析通道
当规则引擎无法处理时,事件进入 LLM 分析通道。核心在 _handle_ai() 方法:
python
def _handle_ai(self, events, is_combo=False):
events_json = json.dumps(events, indent=2, ensure_ascii=False)
tracers = sorted({e.get("data", {}).get("tracer_name", "") for e in events})
combo_hint = ""
if is_combo:
combo_hint = ("\n⚠️ 检测到多种内核事件同时发生,通常暗示系统级故障,"
"请关注事件间因果关系。")
prompt = f"""你是 Linux 内核诊断专家和 SRE 工程师。
## 当前事件(过去 {WINDOW_SECONDS} 秒,CloudEvents 格式)
{events_json}
## 涉及的事件类型
{', '.join(tracers)}
{combo_hint}
## 请分析
1. **事件摘要**:2-3 句话概括。
2. **根因分析**:为什么发生?事件间是否有因果关系?
3. **影响评估**:低/中/高/严重,说明理由。
4. **修复建议**:按优先级列出步骤。
5. **紧急程度**:是否需要立即人工介入?
用中文,简洁、专业、可操作。"""
label = "关联事件" if is_combo else "异常事件"
print(f"\n{'~' * 60}", flush=True)
print(f"🤖 [AI {label}] 事件: {len(events)}, 类型: {tracers}", flush=True)
print(f"{'~' * 60}", flush=True)
try:
resp = requests.post(
LLM_URL,
headers={"Authorization": f"Bearer {LLM_KEY}",
"Content-Type": "application/json"},
json={
"model": LLM_MODEL,
"messages": [
{"role": "system",
"content": "你是 Linux 内核诊断专家。简洁、专业、可操作。"},
{"role": "user", "content": prompt},
],
"temperature": 0.3, "max_tokens": 1500,
},
timeout=120,
)
resp.raise_for_status()
diagnosis = resp.json()["choices"][0]["message"]["content"]
print(f"\n{diagnosis}", flush=True)
except Exception as e:
log("ERR", f"LLM 调用失败: {e}")
finally:
print(f"{'~' * 60}\n", flush=True)Prompt 设计遵循结构化原则:首先给出角色定位(内核专家 + SRE),然后提供完整的 CloudEvents JSON 作为上下文,列出涉及的 tracer 类型,最后给出明确的分析框架(摘要、根因、影响、修复建议、紧急程度)。temperature=0.3 确保输出的确定性和一致性,max_tokens=1500 为详细分析预留足够空间。
当检测到关键事件组合时,Prompt 中会加入 combo_hint 提示,引导 LLM 关注事件间的因果关系。这种"提示工程"显著提升了复杂场景的诊断质量。
系统消息(system role)设定了 LLM 的基调:"简洁、专业、可操作"------我们不希望输出冗长的学术性分析,而是可执行的运维建议。
错误处理采用"优雅降级"策略:LLM 调用失败时只输出错误日志,不会中断整个分析管道。这种设计保证了系统韧性------在大模型服务不可用时,规则引擎通道仍然可用。
测试与验证
SSE 端点验证
首先验证 HUATUO 的 SSE 端点是否正常工作:
bash
$ curl -s http://localhost:19704/v1/events/watch -X POST \
-H "Content-Type: application/json" \
-H "Accept: text/event-stream" \
-d '{}' | head -3
data: {"specversion":"1.0","id":"2d833c8e-cd9f-47f0-b83b-8b129d7d2b69",...}
data: {"specversion":"1.0","id":"0f0e3582-bf96-488b-a471-a1fccef58c51",...}
data: {"specversion":"1.0","id":"4777afd9-23d5-49c0-a074-a3ca706bfb0f",...}SSE 端点确认工作正常,每条消息都是标准的 CloudEvents v1.0 格式,data: 前缀符合 SSE 规范。
Metrics 端点验证
HUATUO 在 /metrics 端点暴露 Prometheus 格式的指标:
bash
$ curl -s http://localhost:19704/metrics | grep -c "huatuo_bamai"
1095共暴露了 1095 个指标。采样几个关键指标:
huatuo_bamai_cpu_util_sys{host="ip-172-31-14-46.cn-north-1.compute.internal",region="example"} 1.64
huatuo_bamai_cpu_util_total{...} 7.40
huatuo_bamai_go_goroutines 62
huatuo_bamai_go_memstats_alloc_bytes 7.59e+07这些指标可用于后续与 Prometheus 集成,实现对 HUATUO 自身的监控。
完整 Pipeline 测试
启动完整的分析管道,运行 45 秒后中断。完整日志如下(中间部分省略):
############################################################
HUATUO Kernel Event AI Analyzer (SSE)
HUATUO SSE → Redis Streams → 规则引擎 / LLM
############################################################
[15:28:02] ℹ️ SSE: http://localhost:19704/v1/events/watch
[15:28:02] ℹ️ 窗口: 30s / 15 条 | 风暴阈值: 20
[15:28:02] ℹ️ LLM: deepseek.v3-v1:0 @ http://localhost:4000/chat/completions
[15:28:02] ✅ Redis 连接成功
[15:28:02] ✅ SSE 连接建立,接收内核事件中
[15:28:02] ✅ 系统就绪,等待内核事件...
[15:28:02] 💾 已写入 1 条
[15:28:02] 🌊 事件风暴: net_rx_latency (20 条)
============================================================
🟡 [MEDIUM] 网络入向延迟异常 ×14
============================================================
主机: ip-172-31-14-46.cn-north-1.compute.internal
时间范围: 2026-05-19 15:28:02.254 ~ 2026-05-19 15:28:02.255
事件数: 14
诊断: 网络数据包从驱动到内核栈的处理延迟超过阈值。
建议:
1. 检查 CPU 负载和 softirq 分布 (/proc/softirqs)
2. 排查是否有流量突发
============================================================
[15:28:47] 📊 Consumer: {'total': 3287, 'rule': 4, 'ai': 0, 'suppressed': 3249}
[15:28:47] 📊 Producer: {'ingested': 3287, 'errors': 0}数据解读:
- 事件吞吐 :45 秒摄入 3287 条事件,约每秒 73 条。在没有人为负载的空闲 EC2 实例上,这个数量主要由
net_rx_latency和softirq_tracing的低级别检测事件贡献。 - 风暴抑制 :3249 条事件被抑制(98.5%),说明
net_rx_latency触发了风暴检测机制。这是正确的行为------在空闲机器上,网络延迟的小幅波动是噪音而非信号。 - 规则引擎:4 条输出来自规则引擎,对应两类已知 tracer 的分析报告。
- LLM 通道:0 次 LLM 调用。这是预期行为------本次测试中没有未知事件类型,也没有关键事件组合,LLM 通道未被触发。
SSE 摄入正常、Redis Streams 读写正常、风暴抑制机制工作正常、规则引擎输出格式正确。
要验证 LLM 通道,需要在有故障注入的环境中进行测试,例如模拟 OOM Killer 触发、人为制造 hungtask、或通过压力测试触发 softlockup。
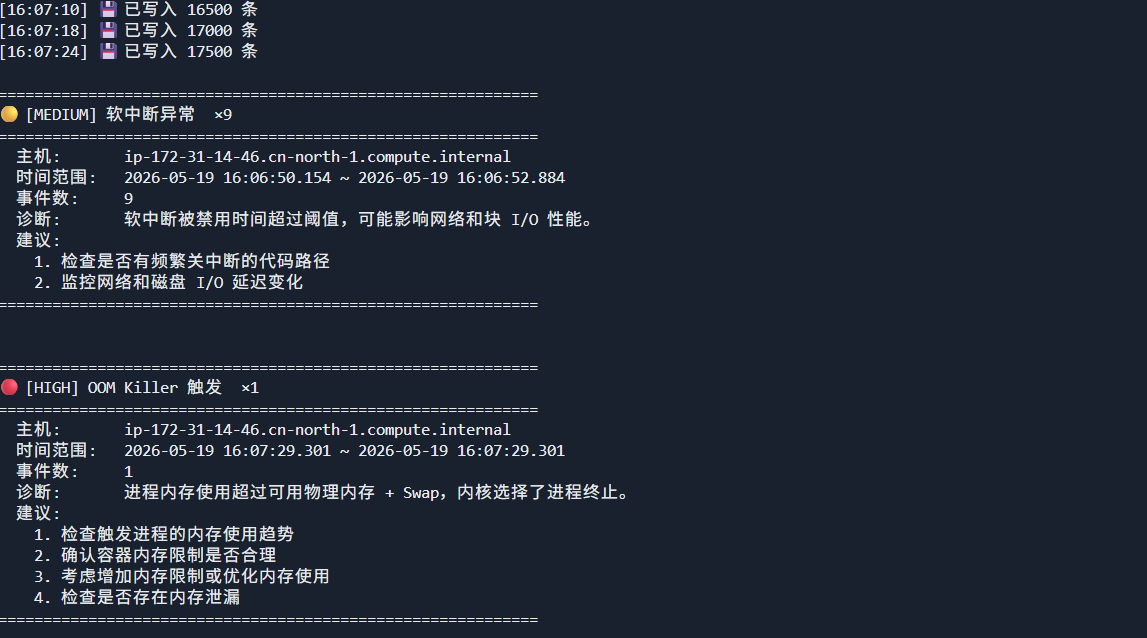
如下代码构建镜像后,我们在docker容器中反复重启来模拟 OOM Killer。
py
import time
import sys
import gc
def allocate_memory(mb_chunk=100, delay=0.1):
memory_blocks = []
allocated_mb = 0
try:
while True:
# 分配内存块(1 byte * 1024 * 1024 * mb_chunk)
block = bytearray(mb_chunk * 1024 * 1024)
memory_blocks.append(block)
allocated_mb += mb_chunk
# 每 1GB 输出一次状态
if allocated_mb % 1024 == 0:
print(f"[{time.strftime('%H:%M:%S')}] 已分配: {allocated_mb // 1024} GB ({allocated_mb} MB)")
# 禁用垃圾回收,确保内存不被释放
gc.disable()
# 延迟,让内存分配更平滑
time.sleep(delay)
except MemoryError:
print(f"\nMemoryError: 已分配 {allocated_mb} MB 时内存不足")
sys.exit(1)
except KeyboardInterrupt:
print(f"\n\n手动停止。总共分配了: {allocated_mb} MB")
sys.exit(0)
if __name__ == "__main__":
allocate_memory(mb_chunk=100, delay=0.1)可见直接匹配规则引擎并触发记录
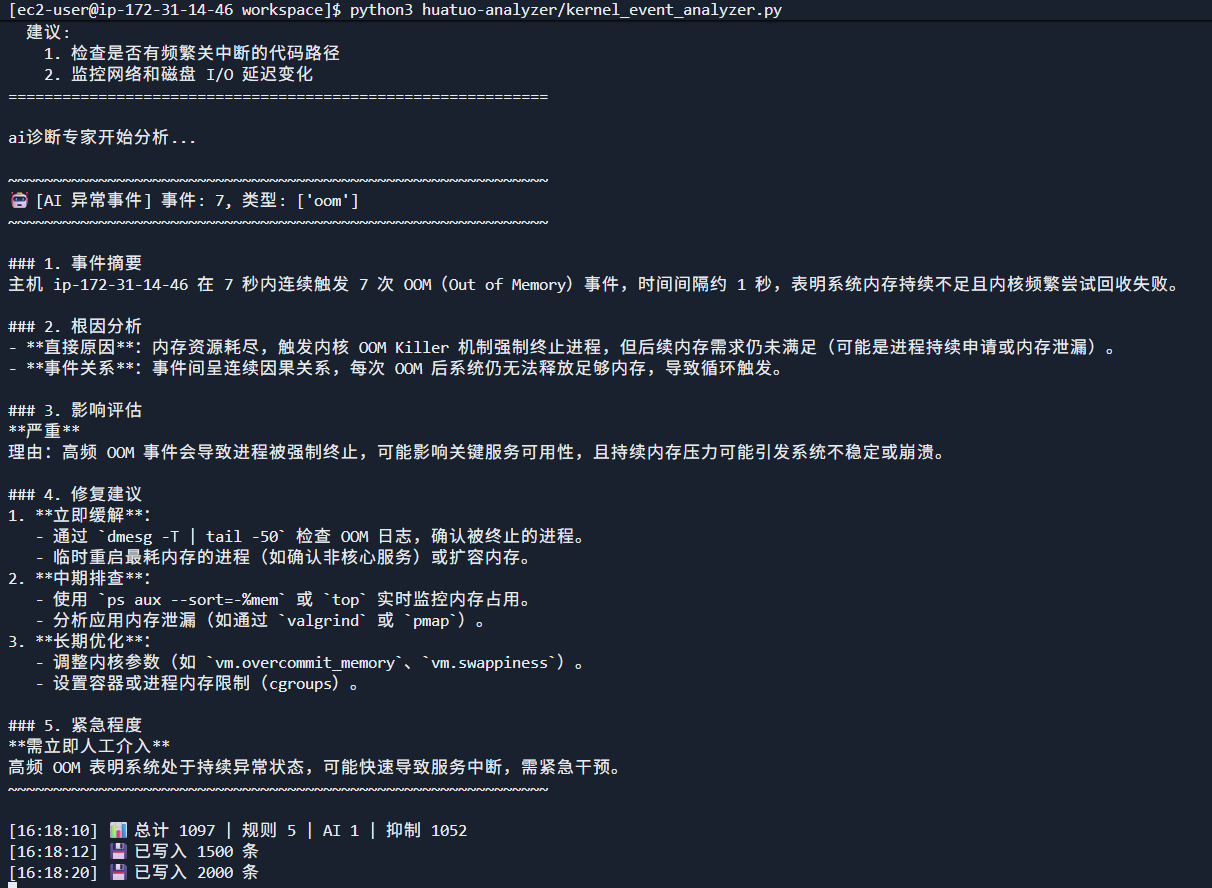
将oom从KNOWN_PATTERNS注释掉,然后再次测试触发AI诊断
运维命令
启动与停止
前台运行:
bash
python3 /home/ec2-user/huatuo-analyzer/kernel_event_analyzer.py后台运行:
bash
nohup python3 /home/ec2-user/huatuo-analyzer/kernel_event_analyzer.py \
> /tmp/huatuo-ai.log 2>&1 &通过环境变量覆盖默认配置:
bash
export HUATUO_SSE_URL=http://localhost:19704/v1/events/watch
export REDIS_HOST=127.0.0.1
export REDIS_PORT=6379
export LLM_MODEL=deepseek.v3-v1:0
export WINDOW_SECONDS=30
export MAX_EVENTS=15
export STORM_THRESHOLD=20
export STORM_COOLDOWN=60
python3 /home/ec2-user/huatuo-analyzer/kernel_event_analyzer.py停止时使用 Ctrl+C 或发送 SIGTERM 信号,程序会优雅退出并输出最终统计。
Redis Streams 监控
查看流基本信息:
bash
docker exec huatuo-redis redis-cli XINFO STREAM huatuo:kernel:events查看流长度(消息数量):
bash
docker exec huatuo-redis redis-cli XLEN huatuo:kernel:events查看消费者组状态:
bash
docker exec huatuo-redis redis-cli XINFO GROUPS huatuo:kernel:events查看待处理消息(未确认的消息):
bash
docker exec huatuo-redis redis-cli XPENDING huatuo:kernel:events ai-analyzer