威胁设计器:用于安全系统设计的 AI 驱动型威胁建模
Threat Designer是一款人工智能驱动的代理程序,可自动执行并简化安全系统设计中的威胁建模流程。它利用大型语言模型 (LLM) 的强大功能,分析系统架构,识别潜在的安全威胁,并生成详细的威胁模型,从而使开发人员和安全专业人员能够在开发的最初阶段就融入安全性。
特征
- 架构分析- 提交架构图并分析其威胁
- 交互式编辑- 通过用户界面更新威胁建模结果
- 迭代改进- 根据您的编辑和补充输入重新构建威胁模型
- 多种导出格式- 可将结果导出为 PDF、DOCX 或 JSON 格式
- AI助手(哨兵) ------与内置助手交互,深入了解威胁模型
- 威胁目录- 浏览和管理过往威胁模型
解决方案
解决方案架构
使用的AWS服务:
- AWS Amplify
- Amazon API Gateway
- 亚马逊 Cognito
- AWS Lambda
- Amazon Bedrock AgentCore 运行时
- Amazon DynamoDB
- 亚马逊 S3
代理逻辑流程
入门
先决条件
所需工具:
您的本地计算机上必须安装以下工具:
AI模型提供商:
Threat Designer 支持两家 AI 提供商。请根据您的偏好选择其中一家:
选项 1:亚马逊基岩版(默认)
您必须在 AWS 区域中启用对以下模型的访问权限:
- Claude 4.6 Opus
- Claude 4.5 Sonnet
- Claude 4.5 Haiku
要启用 Claude 模型,请按照此处的说明操作。请确保您已订阅这些模型,否则AccessDeniedException在使用应用程序时会收到异常。
注意: 如果部署在非美国地区,请验证您所在地区的推理配置文件 ID。请参阅"支持的区域和推理配置文件模型"。
选项 2:OpenAI
你需要:
- 有效的 OpenAI API 密钥
- 可访问 GPT-5.2 或 GPT-5 Mini 模型
部署过程中,系统会提示您输入 API 密钥。
安装与部署
- 克隆仓库
git clone https://github.com/awslabs/threat-designer.git
cd threat-designer- 使部署脚本可执行:
chmod +x deployment.sh- 导出 AWS 凭证
# Option I: Export AWS temporary credentials
export AWS_ACCESS_KEY_ID="your_temp_access_key"
export AWS_SECRET_ACCESS_KEY="your_temp_secret_key"
export AWS_SESSION_TOKEN="your_temp_session_token"
export AWS_DEFAULT_REGION="your_region"
# Option II: Export AWS Profile
export AWS_PROFILE="your_profile_name"- 运行部署:
./deployment.sh部署过程中,系统会提示您执行以下操作:
- 选择您的AI模型提供商(Amazon Bedrock或OpenAI)
- 请输入您的 OpenAI API 密钥(如果您使用 OpenAI)
- 请提供有效的电子邮件地址以用于用户凭据
- 选择是否启用哨兵AI助手
**注意:**将在 Amazon Cognito 用户池中创建一个用户,并将临时凭证发送到配置的电子邮件地址。
访问应用程序
部署成功后,您可以在输出结果中找到登录 URL:
Application Login page: https://dev.xxxxxxxxxxxxxxxx.amplifyapp.com配置选项
人工智能模型提供商选择
Threat Designer 支持两个可在部署期间选择的 AI 提供商:
notranslate
<span style="background-color:#f6f8fa"><span style="color:#1f2328"><span style="color:#1f2328"><span style="background-color:#f6f8fa"><code>Select AI model provider:
1) Amazon Bedrock (Claude) (default)
2) OpenAI (GPT-5.2)
</code></span></span></span></span>Amazon Bedrock 配置(默认模型)
Used Models :
- Claude 4.X family models
主要特点:
- 推理:混合模型
- 推理等级:无、低、中、高、最高(对应不同的推理代币预算或自适应努力程度)
注意: Terraform 变量中列出的模型
adaptive_thinking_models(例如 Claude Opus 4.6)使用基于工作量级别的自适应思维(例如low,` 1`、medium`2`、`high3`、`4`max),而不是基于令牌预算。对于这些模型,reasoning_budget配置将被忽略------用户界面中的推理级别将直接映射到工作量字符串。标准模型继续像以前一样使用基于令牌预算的推理。
注意: Claude Opus 4.6 最大支持 128K 个代币的输出,而其他 Claude 4.x 系列型号最大支持 64K 个代币的输出。如果在不同型号之间切换,请务必max_tokens相应地更新配置,以避免 API 错误。
OpenAI 配置
Used Models :
- GPT-5 Mini(默认)------速度更快,成本效益更高
- GPT-5.2 - 最高推理能力
主要特点:
- 理由:始终启用(内置功能,无法禁用)
- 推理等级:低、中、高(对应于 OpenAI 的推理难度)
使用 OpenAI:
2部署过程中,当系统提示选择模型提供商时,请选择相应的选项。- 出现提示时,请输入您的 OpenAI API 密钥。
- 该系统将配置 Threat Designer 和 Sentry 以使用 OpenAI
在不同服务提供商之间切换
在 Amazon Bedrock 和 OpenAI 之间切换:
- 使用以下方式重新部署解决方案
./deployment.sh - 出现提示时,请选择其他服务提供商。
**重要提示:**无法在切换服务提供商后继续之前已建立的会话。您需要重新开始威胁建模会话。
网络搜索集成(可选功能)
Sentry 可以使用Tavily进行实时网络搜索,以查找 CVE、漏洞和安全主题。此功能为可选功能,需要 Tavily API 密钥。
启用网络搜索
部署过程中,系统会提示您:
notranslate
<span style="background-color:#f6f8fa"><span style="color:#1f2328"><span style="color:#1f2328"><span style="background-color:#f6f8fa"><code>Enter your Tavily API key (optional, press Enter to skip):
(Enables web search and content extraction in Sentry assistant)
</code></span></span></span></span>- 通过 API 密钥 :Sentry 可访问实时安全研究所需的
tavily_search工具tavily_extract - 如果没有 API 密钥:Sentry 可以正常工作,但无法执行网络搜索。
获取 Tavily API 密钥
- 请访问tavily.com注册
- 请前往您的控制面板获取您的 API 密钥
- 密钥以
tvly-前缀开头
网络搜索功能
启用后,哨兵功能可以:
- 搜索 CVE 和漏洞信息
- 研究威胁情报和攻击技术
- 查阅技术安全文档
- 从安全公告和研究论文中提取内容
网络搜索专注于安全相关主题,不会搜索一般信息、人物或组织。
哨兵AI助手(可选功能)
Sentry 是一款人工智能助手,可通过对话式交互帮助您分析和探索威胁模型。此功能为可选功能,可在部署期间启用或禁用。
部署期间启用/禁用哨兵系统
运行程序时./deployment.sh,系统会提示:
notranslate
<span style="background-color:#f6f8fa"><span style="color:#1f2328"><span style="color:#1f2328"><span style="background-color:#f6f8fa"><code>Enable Sentry AI Assistant? (y/n, default: y)
</code></span></span></span></span>- 启用 (y):部署完整的 Sentry 基础架构,包括 Amazon Bedrock AgentCore Runtime、DynamoDB 会话表和 ECR 存储库。用户界面中将显示"助手"抽屉。
- 禁用 (n):跳过 Sentry 基础架构部署。助手抽屉将从用户界面中隐藏,核心威胁建模功能将继续正常运行。
在现有部署中切换哨兵
要禁用哨兵:
- 更新
.deployment.config项目根目录中的文件:
ENABLE_SENTRY=false- 重新部署解决方案
启用哨兵模式:
- 更新
.deployment.config项目根目录中的文件:
ENABLE_SENTRY=true- 重新部署解决方案
清理
-
按照此处的说明清空架构桶。
-
使销毁脚本可执行:
chmod +x destroy.sh- 导出 AWS 凭证
# Option I: Export AWS temporary credentials
export AWS_ACCESS_KEY_ID="your_temp_access_key"
export AWS_SECRET_ACCESS_KEY="your_temp_secret_key"
export AWS_SESSION_TOKEN="your_temp_session_token"
export AWS_DEFAULT_REGION="your_region"
# Option II: Export AWS Profile
export AWS_PROFILE="your_profile_name"- 执行脚本:
./destroy.sh利用生成式人工智能加速威胁建模
本文探讨了生成式人工智能如何通过自动化漏洞识别、生成全面的攻击场景以及提供情境化的缓解策略,革新威胁建模实践。与以往难以应对威胁分析中创造性和情境化挑战的自动化方法不同,生成式人工智能凭借其理解复杂系统关系、推理新型攻击途径以及适应独特架构模式的能力,克服了这些局限。传统的自动化工具依赖于僵化的规则集和预定义的模板,而人工智能模型现在能够解读细致入微的系统设计,推断组件间的安全隐患,并生成人类分析师可能忽略的威胁场景,从而使高效的自动化威胁建模成为现实。
威胁建模及其重要性
威胁建模是一种结构化的方法,用于识别、量化和应对与应用程序或系统相关的安全风险。它从攻击者的角度分析系统架构,以发现潜在漏洞、确定其影响并实施相应的缓解措施。有效的威胁建模会检查数据流、信任边界和潜在攻击途径,从而制定针对特定系统的全面安全策略。
在安全左移策略中,威胁建模是一项至关重要的早期干预措施。通过在设计阶段(即编写任何一行代码之前)实施威胁建模,组织可以从源头上识别并解决潜在漏洞。下图展示了这一工作流程。

这种积极主动的策略能够显著减少安全债务的累积,并将安全从瓶颈转变为创新的推动力。从一开始就将安全考量融入其中,团队便可在整个开发生命周期中实施适当的控制措施,从而从一开始就构建出更具弹性的系统。
尽管威胁建模具有诸多显而易见的优势,但在软件开发行业中,其应用仍然不足。这种应用受限源于传统威胁建模方法固有的几个重大挑战:
- 时间 要求------整个过程需要1-8天才能完成,并且需要多次迭代才能全面覆盖。这与现代软件开发环境中紧迫的开发周期相冲突。
- 评估 不一致------威胁建模存在主观性问题。安全专家在威胁识别和风险等级评估方面往往存在差异,导致不同项目和团队之间评估结果不一致。
- 扩展性 限制------手动威胁建模无法有效应对现代系统的复杂性。微服务、云部署和系统依赖关系的增长速度超过了安全团队识别漏洞的能力。
生成式人工智能如何提供帮助
生成式人工智能彻底革新了威胁建模,它自动化了以往需要人类判断、推理和专业知识才能完成的复杂分析任务。生成式人工智能为威胁建模带来了强大的功能,它将自然语言处理与视觉分析相结合,能够同时评估系统架构、图表和文档。这些模型借鉴了MITRE ATT&CK和OWASP等广泛的安全数据库,可以快速识别复杂系统中的潜在漏洞。这种能够同时处理文本和图像并参考全面安全框架的双重能力,使得威胁评估比传统的人工方法更快、更彻底。
我们的解决方案Threat Designer利用Amazon Bedrock中提供的企业级基础模型 (FM)来革新威胁建模。借助Anthropic 的 Claude Sonnet 3.7高级多模态功能,我们能够大规模地创建全面的威胁评估。您还可以使用模型目录中的其他可用模型,或使用您自己精心调校的模型,从而最大限度地灵活运用预训练的专业知识或根据您的安全领域和组织需求量身定制的功能。这种适应性确保您的威胁建模解决方案能够提供与您独特的安全态势相符的精准洞察。
解决方案概述
Threat Designer 是一款用户友好的 Web 应用程序,它使开发和安全团队能够轻松进行高级威胁建模。Threat Designer 使用大型语言模型 (LLM) 来简化威胁建模流程,并以最少的人工干预识别漏洞。
主要特点包括:
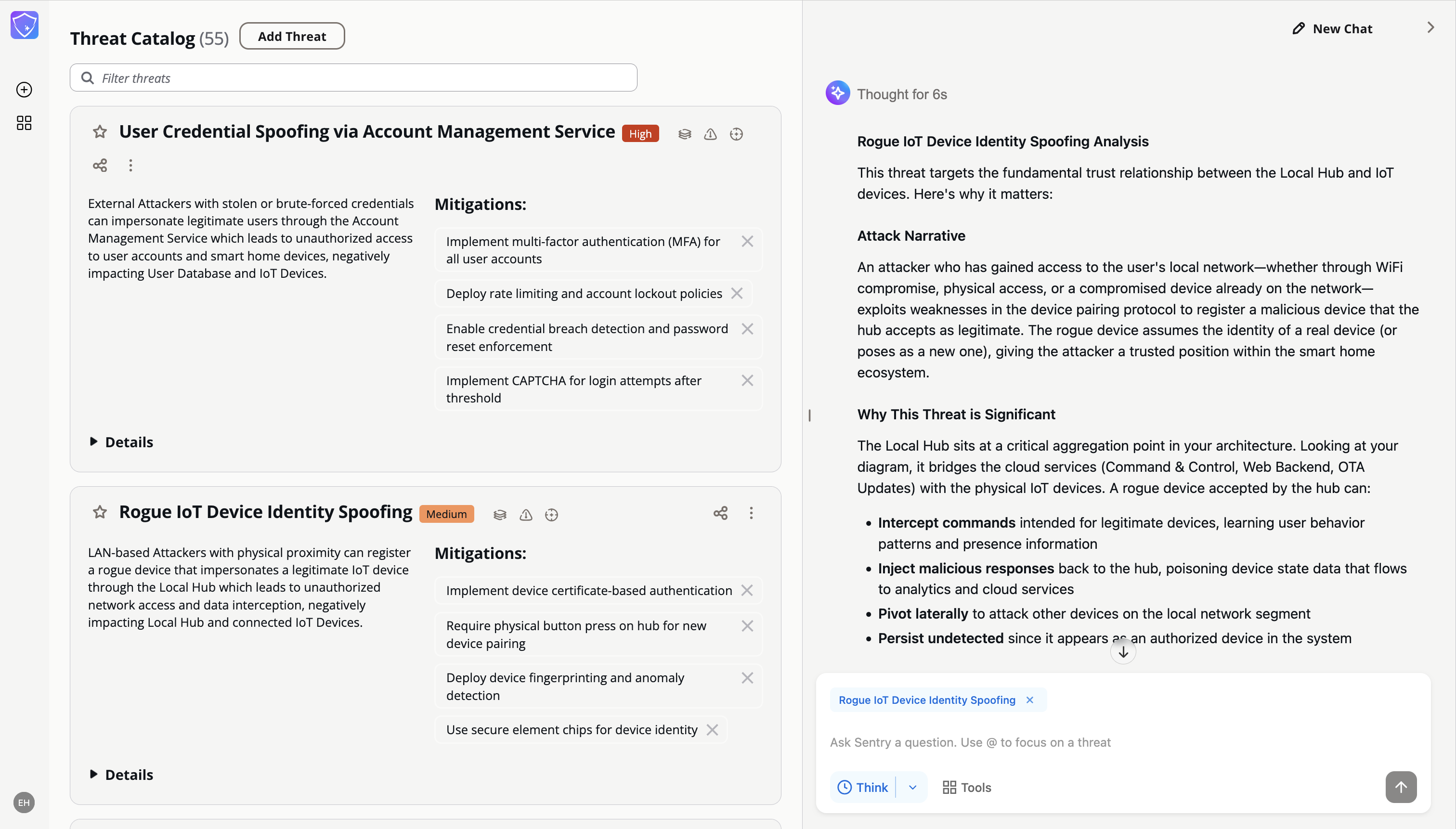
- 架构图分析------用户可以提交系统架构图,应用程序将利用多模态人工智能功能处理这些架构图,以理解系统组件及其关系。
- 交互式威胁目录------该系统生成一个全面的潜在威胁目录,用户可以通过直观的界面浏览、筛选和细化这些威胁。
- 迭代改进------借助回放功能,团队可以重新运行威胁建模流程,并进行设计改进或修改,从而了解这些更改如何影响系统的安全态势。
- 标准化导出------结果可以导出为 PDF 或 DOCX 格式,便于与现有安全文档和合规流程集成。
- 无服务器架构------该解决方案运行在基于云的无服务器基础架构上,无需专用服务器,并可根据需求自动扩展。
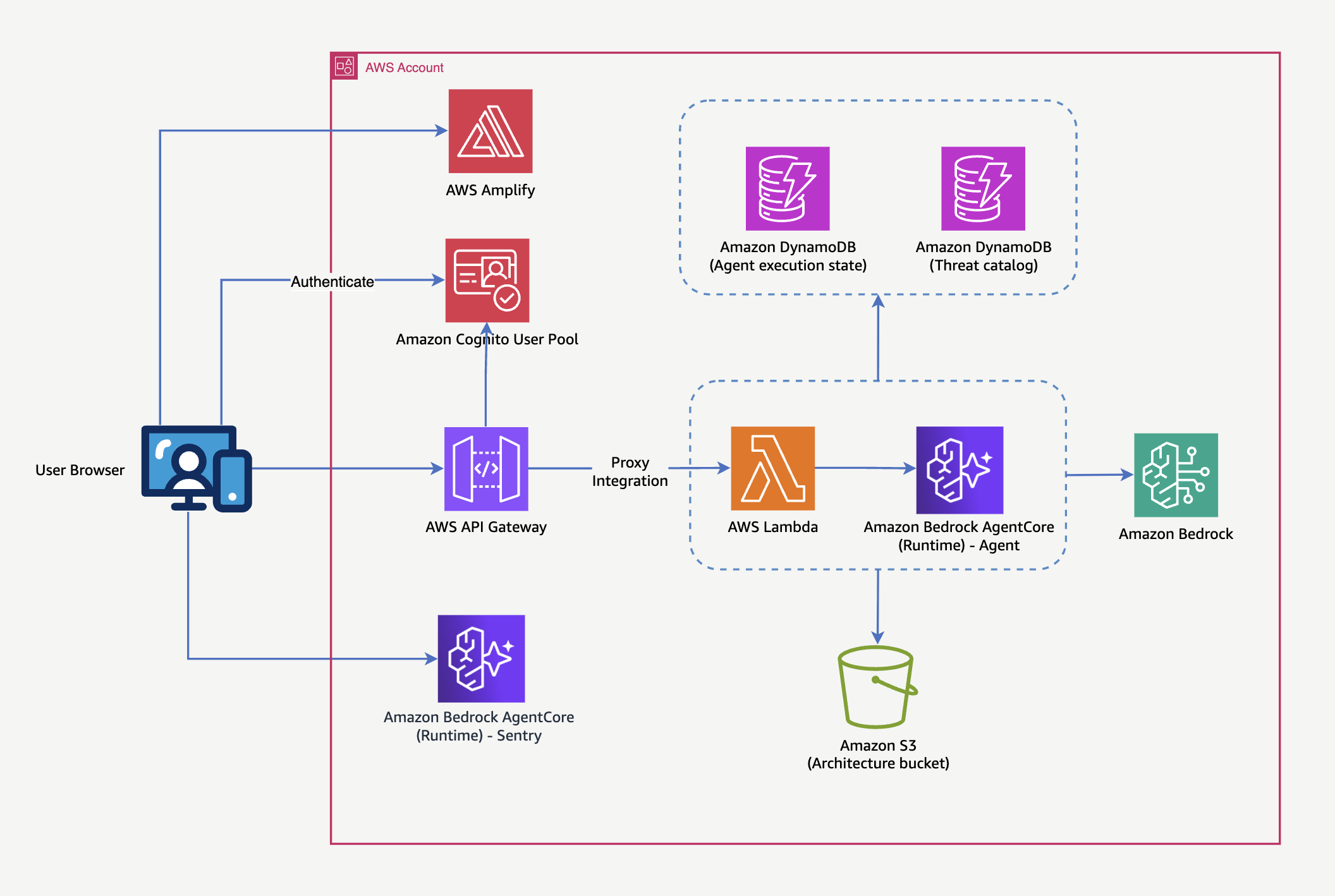
下图展示了威胁设计器的架构。

该解决方案基于无服务器架构构建,利用 AWS 托管服务实现自动扩展、高可用性和成本效益。该解决方案由以下核心组件构成:
- 前端 -- AWS Amplify托管了一个使用Cloudscape设计系统构建的 ReactJS 应用程序,提供用户界面。
- 身份验证 -- Amazon Cognito管理用户池,处理身份验证流程并确保对应用程序资源的访问安全。
- API 层 ------Amazon API Gateway作为通信枢纽,提供前端和后端服务之间的代理集成,并负责请求路由和授权。
- 数据存储 ------我们使用以下服务进行数据存储:
- 两个Amazon DynamoDB表:
- 代理执行状态表维护处理状态
- 威胁目录表存储已识别的威胁和漏洞
- Amazon Simple Storage Service (Amazon S3) 架构存储桶用于存储系统图和工件。
- 两个Amazon DynamoDB表:
- 生成式人工智能------Amazon Bedrock 提供 FM 功能,用于威胁建模、分析架构图和识别潜在漏洞
- 后端服务 -- AWS Lambda函数包含 REST 接口业务逻辑,使用Powertools for AWS Lambda (Python)构建。
- 代理服务-- 该代理服务托管在 Lambda 函数上,异步运行,用于管理威胁分析工作流、处理图表以及维护 DynamoDB 中的执行状态。
代理服务工作流程
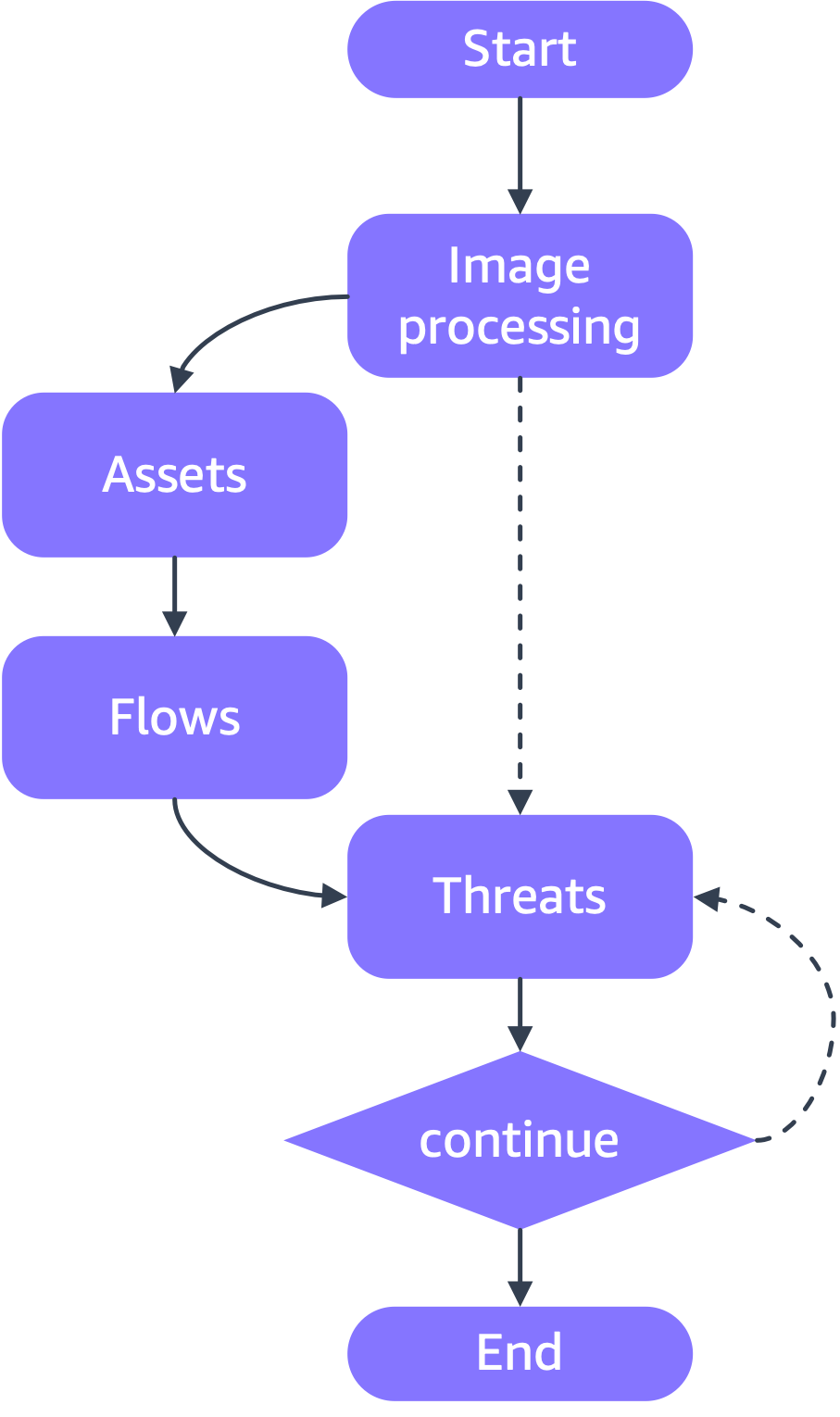
该代理服务基于 LangChain 的LangGraph构建,我们可以通过基于图的结构来编排复杂的工作流程。这种方法融合了两种关键的设计模式:
- 关注点分离------威胁建模过程被分解为离散的、专门化的步骤,这些步骤可以独立且迭代地执行。图中的每个节点代表一个特定的功能,例如图像处理、资产识别、数据流分析或威胁枚举。
- 结构化输出------工作流程中的每个组件都会生成标准化的、定义明确的输出,这些输出可作为后续步骤的输入,从而提供一致性并促进下游集成,以实现一致的表示。
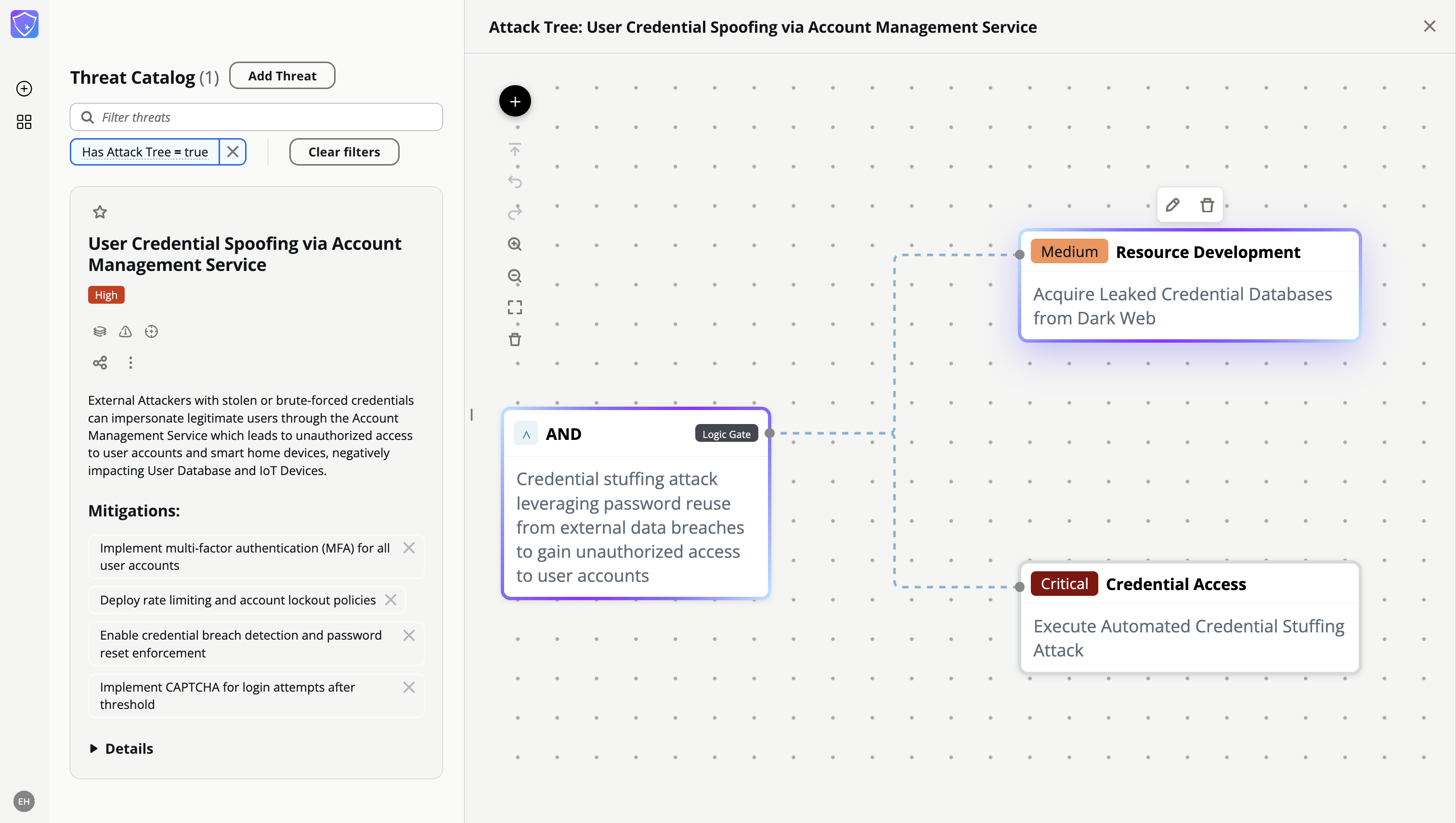
代理工作流程遵循有向图,处理从开始节点开始,并经过几个专门的阶段,如下图所示。

工作流程包含以下节点:
- 图像处理------图像处理节点处理架构图图像,并将其转换为LLM可以读取的合适格式。
- 资产-- 此信息连同文本描述一起输入到"资产"节点,该节点用于识别和编目系统组件。
- 流程-- 工作流随后进入"流程"节点,映射组件之间的数据移动和信任边界。
- 威胁------最后,"威胁"节点利用这些信息来识别潜在的漏洞和攻击途径。
我们代理架构的一项关键创新是通过图中的条件边实现的自适应迭代机制。该特性解决了基于LLM的威胁建模中的一个根本挑战:控制分析的全面性和深度。
"威胁"节点之后的条件边支持两种强大的操作模式:
- 用户控制迭代------在此模式下,用户可以指定代理程序应执行的迭代次数。每次循环迭代,代理程序都会分析之前迭代中可能被忽略的极端情况,从而丰富威胁目录。这种方法使安全专业人员能够直接控制分析的彻底程度。
- 自主差距分析------在完全智能体模式下,一个专门的差距分析组件会对当前的威胁目录进行评估。该组件会识别威胁模型中潜在的盲点或未完善的领域,并触发额外的迭代,直到确定威胁目录足够全面为止。智能体本质上是在执行自身的质量保证,不断完善其输出,直到满足预定义的完整性标准。
先决条件
在部署 Threat Designer 之前,请确保已满足所有必要的先决条件。更多信息,请参阅GitHub 代码库。
开始使用威胁设计器
要开始使用 Threat Designer,请按照 GitHub 上项目README 文件中的分步部署说明进行操作。部署解决方案后,即可创建您的第一个威胁模型。登录并完成以下步骤:
- 选择**"提交威胁模型"**以创建新的威胁模型。
- 请填写提交表格,提供您的系统详细信息:
- 必填字段:请提供标题和架构图。
- 建议字段:提供解决方案描述和假设(这些可以显著提高威胁模型的质量)。
- 配置分析参数:
- 选择迭代模式:
- 自动(默认):代理程序会智能地判断威胁目录何时已全面。
- 手动:最多可指定 15 次迭代,以获得更精细的控制。
- 配置推理增强功能,以指定模型在分析上花费多少时间(使用 Anthropic 的 Claude Sonnet 3.7 时可用)。
- 选择迭代模式:
- 选择**"开始威胁建模"**以启动分析。

您可以通过直观的界面监控进度,该界面会实时显示每个执行步骤。完整的分析通常需要 5 到 15 分钟,具体时间取决于系统复杂程度和所选参数。

分析完成后,您将获得一个全面的威胁模型,您可以对其进行探索、完善和导出。

在本文中,我们展示了生成式人工智能如何将威胁建模从专家主导的专属流程转变为所有开发团队都能轻松使用的安全实践。通过我们的威胁设计器解决方案,我们利用功能模型(FM)实现了复杂安全分析的普及化,使组织能够更早、更一致地识别漏洞。这种人工智能驱动的方法打破了时间、专业知识和可扩展性方面的传统壁垒,使左移安全不再仅仅是愿景,而是切实可行的方案------最终在不牺牲开发速度的前提下,构建更具弹性的系统。
按照README文件中的说明部署 Threat Designer ,上传您的架构图,即可快速获得 AI 生成的安全洞察。这种简化的方法可帮助您将主动安全措施集成到开发流程中,而不会影响速度或创新,从而使不同规模的团队都能轻松进行全面的威胁建模。