前言
上篇分享 LangChain DeepAgents 速通指南(一)------ 一文详解DeepAgents核心特性 笔者介绍了DeepAgents的强大特性。借助 create_deep_agent 函数,开发者仅需少量代码即可搭建出功能复杂的智能体,真正实现了"搭积木式"的开发体验。而 create_deep_agent 之所以如此强大,其核心原因在于 LangChain DeepAgents 团队在 LangChain 1.0 的 create_agent API 基础上,内置了丰富的中间件和工具函数。从本期开始笔者将逐一剖析这些经典组件,帮助大家更深入地理解它们的设计与用途。
本期内容将聚焦 Summarization(摘要中间件) 。在实际开发中,由于大模型上下文窗口的限制,一个常见且棘手的问题逐渐浮现:随着任务推进,对话历史的不断累积会迅速耗尽上下文窗口,导致信息丢失甚至任务中断。
当 Agent 需要处理长篇文档、进行多轮交互,或从冗余信息(如网页内容)中提取关键数据时,消息列表很容易突破模型的 token 限制。尤其是在 DeepAgents 这类复杂智能体中,中间消息和上下文信息更是急剧增加,进一步加剧了上下文窗口的压力。为解决这一痛点,LangChain 1.0 提供了一个非常实用的中间件------Summarization(摘要中间件),它也被 DeepAgents 默认集成到智能体构建流程中。今天笔者就和大家一起来深入探讨它的使用方法与实现原理,看看它是如何为 Agent 的记忆"做减法"的。
一、Summarization中间件核心原理
1.1 为什么需要Summarization?
在基于大模型与工具构建的Agent中,每次调用模型都需要将之前的对话历史一并传入,以便模型理解当前上下文。然而,模型的上下文窗口是有限的(例如常见的 8K、32K token 限制)。当任务变得复杂,或工具返回的信息量很大时,消息列表很容易就会"爆表",超出模型的处理能力。
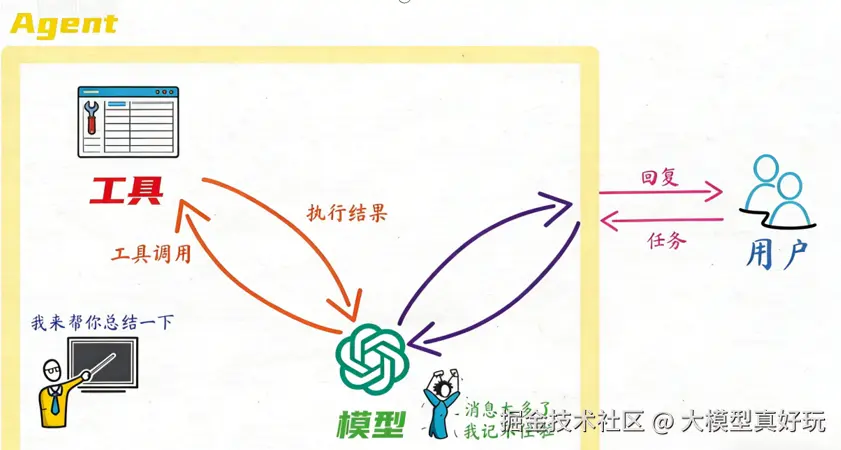
Summarization中间件的作用,正是在接近Token限制或其他预设条件时,自动对较旧的对话记录进行摘要。它会在保留近期关键消息的同时,将早期内容压缩成一段精炼的总结。这样一来,Agent既能维持对任务背景的连贯理解,又不会因Token溢出而导致执行中断。
1.2 适用场景
- 长文本处理:当模型需要阅读并分析长文档、多页网页时,工具返回的内容可能一次就占满上下文。Summarization可以在每次工具调用前对已积累的内容做摘要,防止溢出。
- 多轮次对话:在客服、咨询等场景中,对话轮次可能多达几十轮。Summarization可以将早期的寒暄或确认信息压缩,让模型聚焦当前核心问题。
- 高冗余工具调用:某些工具(如搜索引擎、爬虫)返回的信息往往包含大量无关内容(广告、导航栏等)。Summarization可以提炼关键信息,减少噪声。
1.3 Summarization中间件原理
Summarization中间件继承自 AgentMiddleware 基类,通过覆写 before_model 与 abefore_model 方法,在信息进入模型前执行压缩处理。对中间件机制不太熟悉的读者,可以参考我之前的文章:LangChain1.0速通指南(三)------LangChain1.0 create_agent api 高阶功能 和 LangChain不支持AgentSkills?那就从0到1实现一个!。
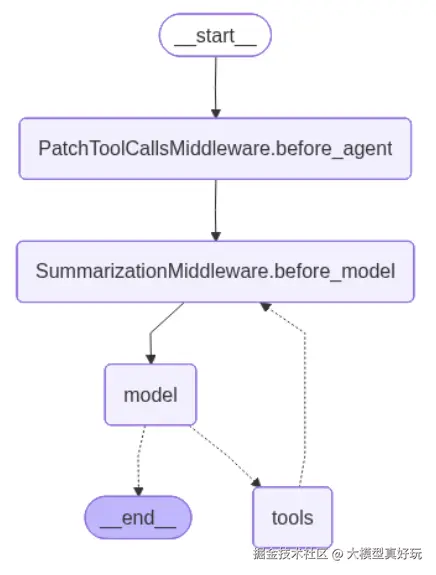
Summarization属于 before model钩子 类型的中间件,意味着它会在每一次模型调用前被触发执行。它的核心工作流程如下:
- 检查消息列表:获取当前Agent的完整消息列表(包括历史消息、用户最新输入、工具响应等)。
- 判断触发条件 :根据用户配置的
trigger参数(例如消息数量超过阈值、Token总数超限、达到模型上下文窗口的一定比例等),判断当前是否需要进行摘要。 - 执行摘要 :如果条件满足,中间件会先根据
keep参数保留最新的一定数量的消息(例如保留最近的3条),然后将剩余的历史消息一并发送给摘要模型,生成一段概括性的总结。 - 重组消息列表 :用新生成的摘要消息(通常包装为一条
HumanMessage)与之前保留的最近消息组合,形成一个新的、更精简的消息列表,再传递给模型进行后续的处理。
二、快速上手:配置你的第一个Summarization中间件
下面笔者通过实际的代码示例,演示如何在 LangChain 1.0 中使用 Summarization 中间件。
- 环境准备与依赖引入 :在
langchain>=1.0.5、python>=3.12的环境中编写以下脚本,引入必要的依赖,并定义模型和工具。本例中使用 DeepSeek 模型。
python
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langchain_deepseek import ChatDeepSeek
from dotenv import load_dotenv
from langchain.messages import HumanMessage,AIMessage,ToolMessage
import os
from typing import Literal
from langchain_core.tools import tool
from tavily import TavilyClient
tavily_client = TavilyClient(api_key=os.environ["TAVILY_API_KEY"])
load_dotenv()
@tool
def internet_search(
query: str,
max_results: int = 5,
topic: Literal["general", "news", "finance"] = "general",
include_raw_content: bool = False,
):
"""
Search the internet for information using Tavily search engine
"""
search_docs = tavily_client.search(
query,
max_results=max_results,
include_raw_content=include_raw_content,
topic=topic,
)
return search_docs
@tool
def calculate(expression: str) -> str:
"""Perform mathematical calculations and return the result.
Args:
expression: Mathematical expression to evaluate
(e.g., "2 + 3 * 4", "sqrt(16)", "sin(pi/2)")
Returns:
The calculated result as a string
"""
result = str(eval(expression))
return result
model = ChatDeepSeek(
model="deepseek-chat",
)- 为 Agent 配置 Summarization 中间件 : 与其他中间件类似,使用 Summarization 中间件需要先将其引入,并添加到 Agent 的中间件列表中。配置后,中间件会按照设定的规则,在任务执行过程中自动精简消息列表。在下面的代码中笔者为
SummarizationMiddleware传入了三个关键配置:
model:指定用于生成摘要的模型。摘要的质量直接取决于此模型的能力。trigger:设置触发摘要的条件 。例如("messages", 5)表示当消息列表中的消息数量大于 5 条时,触发摘要。keep:设置摘要后需要保留 的最新消息数量。例如("messages", 3)表示摘要完成后,只保留最近的 3 条原始消息,其余被压缩成一条摘要。
python
agent = create_agent(
model=model,
tools=[internet_search, calculate],
middleware=[
SummarizationMiddleware(
model=model,
trigger=("messages", 5),
keep=("messages", 3),
),
],
)- 测试调用与效果验证 :笔者构造一个包含四条历史消息的初始状态,然后追加一条新的用户询问,最后调用 Agent 进行处理。从返回的结果可以看到,Agent 的回复中包含了五条消息,其中第一条
HumanMessage正是 Summarization 中间件对历史信息进行总结后生成的摘要内容。
python
status = {
"messages":[
HumanMessage(content='deepseek公司最近有什么最新的资讯?', additional_kwargs={}, response_metadata={}, id='3804b3f2-827c-411a-be33-f3cc84eda168'),
AIMessage(content='', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 21, 'prompt_tokens': 164, 'total_tokens': 185, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini', 'system_fingerprint': 'fp_50906f2aac', 'id': 'chatcmpl-Cid0iHZVVPLVE2vyntv2DHGuZKD4Q', 'service_tier': 'default', 'finish_reason': 'tool_calls', 'logprobs': None}, id='lc_run--0f8cfeb6-ec02-46cc-b24f-abdb5d29e407-0', tool_calls=[{'name': 'internet_search', 'args': {'query': 'deepseek 最新资讯', 'topic': 'news'}, 'id': 'call_CDVy2avyMw2QExcEs1f0xdNc', 'type': 'tool_call'}], usage_metadata={'input_tokens': 164, 'output_tokens': 21, 'total_tokens': 185, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}}),
ToolMessage(content='{"query": "deepseek 最新资讯", "follow_up_questions": null, "answer": null, "images": [], "results": [{"url": "https://indianexpress.com/article/technology/artificial-intelligence/deepseeks-math-v2-ai-model-self-verify-complex-theorems-10390760/", "title": "DeepSeek's new Math-V2 AI model can solve and self-verify complex theorems - The Indian Express", "score": 0.72907686, "published_date": "Fri, 28 Nov 2025 06:34:57 GMT", "content": "# DeepSeek's new Math-V2 AI model can solve and self-verify complex theorems ## DeepSeek-Math-V2 is said to match the performances of OpenAI and Google DeepMind's models on problems from the International Maths Olympiad 2025. Chinese AI startup DeepSeek on Thursday, November 27, unveiled a new open-weight AI model designed to generate and self-verify mathematical theorems using advanced reasoning skills that the company says were developed specifically for this task. Named DeepSeek-Math-V2, the specialist mathematical reasoning LLM (large language model) is said to possess strong theorem-proving capabilities. In terms of performance, DeepSeek said that Math-V2 achieved gold medal-worthy scores when tested on math problems from the International Mathematical Olympiad (IMO) 2025 and CREST Mathematics Olympiad (CMO) 2024.", "raw_content": null}, {"url": "https://global.chinadaily.com.cn/a/202511/28/WS69295341a310d6866eb2bf02.html", "title": "DeepSeek AI mathematical reasoning model pioneering self-verifying reasoning - China Daily - Global Edition", "score": 0.61168414, "published_date": "Fri, 28 Nov 2025 00:00:00 GMT", "content": "* China Edition * CHINA * CHINA + China Daily PDF + China Daily E-paper # DeepSeek AI mathematical reasoning model pioneering self-verifying reasoning HANGZHOU -- Chinese AI firm DeepSeek has launched DeepSeekMath-V2, a groundbreaking mathematical reasoning model that sets new performance benchmarks and pushes the frontiers of AI-powered problem-solving. Ten photos from across China: Nov 21 - 27 GMD SCO Summit Cities Tianjin The content (including but not limited to text, photo, multimedia information, etc) published in this site belongs to China Daily Information Co (CDIC). China Edition * CHINA + China Daily PDF The content (including but not limited to text, photo, multimedia information, etc) published in this site belongs to China Daily Information Co (CDIC). About China Daily", "raw_content": null}, {"url": "https://ts2.tech/en/nvidia-stock-after-the-bell-nvda-near-180-as-2-billion-synopsys-stake-hpe-deal-and-ai-bubble-fears-collide-december-1-2025/", "title": "Nvidia Stock After the Bell: NVDA Near $180 as $2 Billion Synopsys Stake, HPE Deal and AI Bubble Fears Collide -- December 1, 2025 - ts2.tech", "score": 0.36724812, "published_date": "Mon, 01 Dec 2025 21:29:54 GMT", "content": "# Nvidia Stock After the Bell: NVDA Near $180 as $2 Billion Synopsys Stake, HPE Deal and AI Bubble Fears Collide -- December 1, 2025 Below is a detailed after‑the‑bell wrap‑up of\xa0**today's Nvidia stock move, the latest forecasts and the key arguments from both bulls and bears**\xa0as of\xa0**December 1, 2025, 10 p.m. EST**. For now, the market's verdict is cautious optimism:\xa0**Nvidia is holding near $180**, comfortably below its highs but far above where it started the year, while investors digest whether today's deals will translate into\xa0**sustainable, high‑quality growth**\xa0--- or simply inflate the debate around the most important stock in AI. Nvidia Buys $2B of Synopsys Stock, DeepSeek Debuts New AI Models", "raw_content": null}, {"url": "https://www.reuters.com/business/world-at-work/chinas-baidu-starts-layoffs-after-reporting-third-quarter-loss-sources-2025-11-28/", "title": "China's Baidu starts layoffs after reporting third-quarter loss - sources - Reuters", "score": 0.36006194, "published_date": "Fri, 28 Nov 2025 07:15:00 GMT", "content": "# China's Baidu starts layoffs after reporting third-quarter loss - sources BEIJING/SHANGHAI, Nov 28 (Reuters) - China's Baidu (9888.HK), opens new tab started layoffs this week that will hit multiple business units, six sources briefed on the matter said, as the company struggles with intensifying competition in artificial intelligence and declining advertising revenue. Although Baidu was the first major Chinese tech firm to roll out a ChatGPT-style service in 2023, it has struggled to maintain an early lead against competitors including Alibaba (9988.HK), opens new tab and AI start-up DeepSeek. Baidu's Ernie large language model is trailing offerings from rivals including Alibaba and DeepSeek after multiple strategy shifts, including a move to open source it earlier this year. * World at WorkcategoryChina's Baidu starts layoffs after reporting third-quarter loss - sources", "raw_content": null}, {"url": "https://www.startupecosystem.ca/news/chinas-tech-giants-take-ai-model-training-offshore-to-tap-nvidia-chips/", "title": "China's Tech Giants Take AI Model Training Offshore to Tap Nvidia Chips - Startup Ecosystem Canada", "score": 0.35824135, "published_date": "Thu, 27 Nov 2025 06:07:50 GMT", "content": "## China's Tech Giants Take AI Model Training Offshore to Tap Nvidia Chips * Canada startup news acquisition AI AI development AI infrastructure AI innovation AI integration AI investment AI models AI technology Anthropic Apple Artificial Intelligence Autonomous vehicles Canada founder news Canada startup news ChatGPT cryptocurrency Cybersecurity DeepSeek Electric Vehicles Elon Musk entrepreneurship fintech Funding round Generative AI Global founder news Global startup news healthcare innovation Innovation investment IPO Meta Microsoft Nvidia Ontario startup news OpenAI Sam Altman Seed funding Series A funding Startup growth TechCrunch Disrupt Tech innovation Tesla Toronto startup news venture capital 5 months ago Global Startupfest 2025 Awards Over $1 Million in Prizes to Diverse Startups 5 months ago Global TechCrunch All Stage Summit Offers Discounted Rates for Startups and Founders", "raw_content": null}], "response_time": 0.4, "request_id": "1b4e0fba-2245-4c1f-89ca-dce564fd40a4"}', name='internet_search', id='358baeca-7567-4ff1-b7f3-7a8c9f1ee886', tool_call_id='call_CDVy2avyMw2QExcEs1f0xdNc'),
AIMessage(content='最近,DeepSeek 公司推出了其最新的数学推理模型 DeepSeek-Math-V2。这个模型可以生成并自我验证复杂的数学定理,其推理能力被专门开发以应对这一任务。DeepSeek 声称,Math-V2 在 2025 年国际数学奥林匹克(IMO)和 2024 年 CREST 数学奥林匹克的测试中表现优异,达到了金牌水平。\n\n以下是一些相关的资讯链接:\n\n1. [DeepSeek的数学V2 AI模型可以解决和自我验证复杂定理 - The Indian Express](https://indianexpress.com/article/technology/artificial-intelligence/deepseeks-math-v2-ai-model-self-verify-complex-theorems-10390760/)\n - 发布时间:2025年11月28日\n\n2. [DeepSeek AI数学推理模型开创自我验证推理 - China Daily](https://global.chinadaily.com.cn/a/202511/28/WS69295341a310d6866eb2bf02.html)\n - 发布时间:2025年11月28日\n\n这些信息表明,DeepSeek 在数学推理领域取得了显著进展,可能会在人工智能技术中引发更多关注。', additional_kwargs={'refusal': None}, response_metadata={'token_usage': {'completion_tokens': 272, 'prompt_tokens': 1657, 'total_tokens': 1929, 'completion_tokens_details': {'accepted_prediction_tokens': 0, 'audio_tokens': 0, 'reasoning_tokens': 0, 'rejected_prediction_tokens': 0}, 'prompt_tokens_details': {'audio_tokens': 0, 'cached_tokens': 0}}, 'model_provider': 'openai', 'model_name': 'gpt-4o-mini', 'system_fingerprint': 'fp_50906f2aac', 'id': 'chatcmpl-Cid0lkGkGMPYqQSaSFGfxBj2O6Isg', 'service_tier': 'default', 'finish_reason': 'stop', 'logprobs': None}, id='lc_run--b4804d4c-2865-46cb-befe-1712e3d2e09b-0', usage_metadata={'input_tokens': 1657, 'output_tokens': 272, 'total_tokens': 1929, 'input_token_details': {'audio': 0, 'cache_read': 0}, 'output_token_details': {'audio': 0, 'reasoning': 0}})
]
}
status["messages"].append(
HumanMessage("deepseek的新模型有哪些特点与突破?")
)
result = agent.invoke(status)
print(result)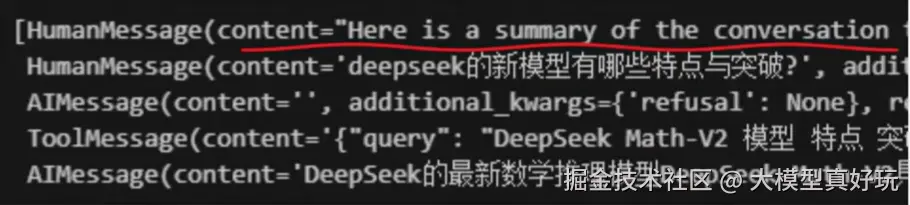
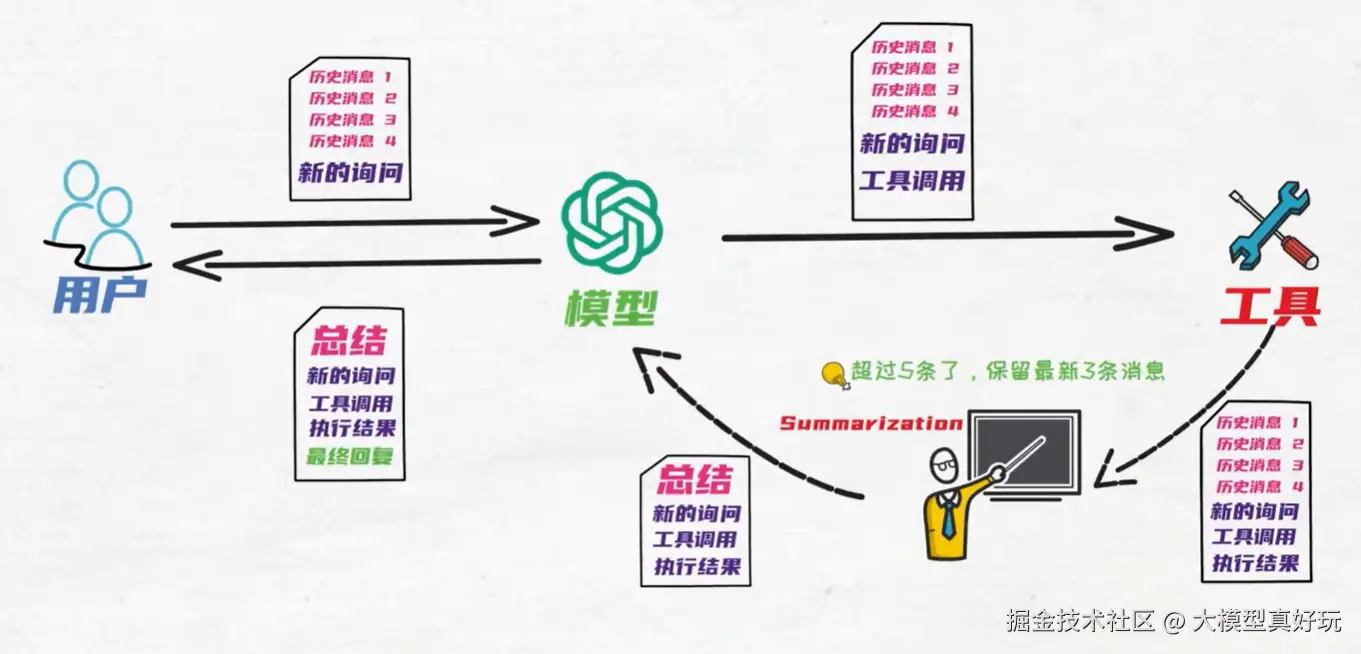
- 内部流程解析:详细拆解一下在上述调用过程中,Agent 内部的消息流转与 Summarization 中间件的工作细节:
- 初始状态 :用户调用 Agent 时,消息列表的初始状态包含 4 条历史消息和 1 条新询问,共计 5 条消息 。此时,消息数量刚好达到我们设置的
trigger阈值(5 条),但并未超过。 - 第一次模型调用 :模型接收这 5 条消息后,判断需要调用工具(
internet_search)。 - 工具返回结果 :工具执行完毕并将结果(
ToolMessage)返回后,消息列表中新增了这条工具消息。此时,列表中的消息总数变为 7 条 ,已超过trigger阈值。 - 第二次模型调用前(触发摘要) :在将工具返回的结果和之前的消息再次送入模型进行最终回复前,Summarization 中间件会检查消息列表。发现 7 > 5,触发摘要条件。
- 执行摘要 :中间件根据我们配置的
keep=3,首先保留最新的 3 条消息(即工具返回的消息、引发工具调用的 AI 消息,以及用户的最新提问?)。然后,将剩余的所有更早的消息发送给摘要模型,生成一段总结。 - 重组消息列表 :这段新生成的总结被包装为一条
HumanMessage(即我们在最终输出中看到的第一条消息),并与之前保留的 3 条最新消息组合,形成一个新的、共 4 条消息的列表,传递给模型。 - 最终回复:模型基于这个精简后的消息列表,生成对用户提问的最终回答。
三、 Summarization配置详解
Summarization中间件提供了四个核心配置参数:trigger、keep、model以及可选的summary_prompt。下面逐一详解其用法与注意事项。
3.1 trigger:触发条件
trigger参数决定了何时对消息列表进行摘要。它可以是一个单一条件元组 ,也可以是一个由多个条件元组组成的列表(采用"或"逻辑,满足任一条件即触发)。LangChain内置了以下几种条件类型:
- 基于消息数量 :例如
("messages", ">=", 10)表示当消息总数达到或超过10条时触发。 - 基于Token数量 :例如
("tokens", ">=", 3000)表示当所有消息的总Token数达到或超过3000时触发(LangChain会自动对消息进行编码以计算Token数)。 - 基于上下文窗口占比 :例如
("fraction", ">=", 0.7)表示当前消息的总Token数占模型最大上下文Token数的比例达到或超过70%时触发。
除了单一条件,还可以组合多个条件以实现更灵活的触发策略。当使用列表时,条件之间为"或"关系,即任意一个条件满足就会触发摘要。示例如下:
python
trigger = [
("messages", ">=", 8),
("fraction", ">=", 0.8)
]
# 当消息数量≥8 **或** 上下文占用≥80%时触发3.2 keep:保留最新消息的数量
keep参数指定在触发摘要后,需要保留多少条最新的原始消息 (这些消息不会被摘要)。与trigger不同,keep只能使用一个单一条件元组,不支持列表,因为保留策略必须具有确定性。
常见的配置方式包括:
- 基于消息数量 :
keep = ("messages", "=", 5)表示保留最新的5条消息。 - 基于Token数量 :
keep = ("tokens", "<=", 1000)表示保留最新的消息,直到其总Token数不超过1000为止。 - 基于上下文占比 :
keep = ("fraction", "<=", 0.3)表示保留最新的消息,直到其占用模型上下文的比例不超过30%为止。
通常情况下,基于消息数量来配置keep最为直观和常用。
注意 :keep不能像trigger那样配置多个条件,因为保留策略必须是单一且明确的。
3.3 model:摘要模型
model参数用于指定生成摘要所使用的语言模型。它可以是一个模型名称字符串(例如 "gpt-3.5-turbo"),也可以是一个已经初始化的模型实例。在实际应用中,通常建议选用轻量、快速的模型来执行摘要任务,以避免占用Agent主模型的计算资源,从而提升整体效率。
3.4 summary_prompt:自定义摘要提示词
LangChain为摘要模型预设了一个默认的系统提示词,其内容大致为"请总结以下对话历史,保留关键信息"。如果你希望摘要以特定格式输出,或需要加入额外的指令,可以通过summary_prompt参数传入自定义的提示词模板。在自定义提示词时,必须包含{messages}占位符,以便中间件将待总结的消息列表传入模板。示例如下:
python
from langchain.middleware.summarization import DEFAULT_SUMMARY_PROMPT
from langchain.prompts import PromptTemplate
custom_prompt = PromptTemplate.from_template(
"请将以下对话浓缩成一段简洁的总结,重点关注事实和行动项:\n\n{messages}"
)
summarization_mw = SummarizationMiddleware(
model=summary_llm,
trigger=trigger,
keep=keep,
summary_prompt=custom_prompt
)以上就是笔者今天的全部内容。完整的源码示例已整理好,欢迎大家关注我的同名微信公众号 大模型真好玩 ,在公众号后台私信发送 LangChain智能体开发 即可免费获取。
四、总结
本文深入讲解LangChain DeepAgents内置的Summarization中间件,它能自动压缩对话历史,解决大模型上下文窗口限制问题。通过配置trigger(触发条件)、keep(保留最新消息)、model(摘要模型)等参数,中间件在达到阈值时将旧消息摘要并重组列表。支持消息数、token数、占比等多条件触发,可自定义摘要提示词,为Agent记忆"做减法",助力高效处理长任务。除了Summarization中间件,DeepAgents还内置了其它许多重要的中间件,下期内容笔者将分享任务规划中间件与工具,大家敬请期待~
本系列相关内容均列于笔者的专栏《深入浅出LangChain&LangGraph AI Agent 智能体开发》,该专栏适合所有对 LangChain 感兴趣的学习者,无论之前是否接触过 LangChain。该专栏基于笔者在实际项目中的深度使用经验,系统讲解了使用LangChain/LangGraph如何开发智能体,目前已更新 39 讲,并持续补充实战与拓展内容。欢迎感兴趣的同学关注笔者的掘金账号与专栏,也可关注笔者的同名微信公众号大模型真好玩 ,每期分享涉及的代码均可在公众号私信: LangChain智能体开发免费获取。
2026年笔者的另一大重心还会放在大模型训练专栏分享上,当然,谈论训练无法绕过算力这道现实的门槛。昂贵的GPU是许多人探索技术的拦路石。正因如此笔者今年特意与一些可靠的算力平台展开了合作,希望能为大家解决算力瓶颈。大家可以通过Lab4AI 注册Lab4ai算力平台 ,提供了包括英伟达H系列在内的多种选择,更有 5小时的免费体验额度。