一. 进程创建
1)fork创建进程常规应用情况
-
一个父进程希望复制自己,fork创建子进程,通过fork的返回值进行父子分流,执行同一代码的不同部分。例如,父进程等待客户端请求,生成子进程来处理请求。
-
创建的子进程用来执行另一份不同的代码。例如子进程创建好后,自己调用exec函数。
-
上面的两个例子现在都还理解不了,一个要到网络部分,另一个是在程序替换部分,所以先看个眼熟就行。
2)fork调用失败的原因
-
系统中进程太多,空间不足。
-
每个用户有最大进程数限制,实际用户的进程数超过了限制。
3)父子进程修改时发生写时拷贝是如何实现的
当父进程要创建子进程之前,OS会将父进程数据段在页表中的读写属性修改为只读的,当子进程被创建出来拷贝了父进程的虚拟内存和页表,子进程的数据段也是只读的。所以,当之后父子进程其中有人想要修改数据时,会因为权限问题出错,提醒操作系统介入。操作系统发现原本应该可读可写的数据段变成了只读并且有人要修改数据,就为要修改的一方重新开辟物理空间,修改页表映射关系,以及将父子进程权限改回为读写(因为对于这个变量,父子进程已经在不同的实际物理地址了,可读可写权限不影响彼此),此时就是发生了写时拷贝。
二. 进程终止
1)进程终止时,内核在做什么?
先释放代码和数据,再释放进程PCB(因为可能有僵尸进程)。
2)一个进程终止可能会有哪几种情况?
① 代码跑完,结果正确
② 代码跑完,结果不正确
③ 代码没跑完,进程异常
1. 代码跑完,结果正确
我们平时写代码最后都会return 0; 这个0叫做进程的退出码,为什么是0?他代表什么?这个值被返回给了谁?
bash
[lsy@hcss-ecs-116a code_proc_control]$ cat makefile
process:process.c
@gcc -o $@ $^
.PHONY:clean
clean:
@rm -rf process
[lsy@hcss-ecs-116a code_proc_control]$ cat process.c
int main()
{
return 0;
}
[lsy@hcss-ecs-116a code_proc_control]$ make
[lsy@hcss-ecs-116a code_proc_control]$ ll
total 20
-rw-rw-r-- 1 lsy lsy 71 Jan 29 21:16 makefile
-rwxrwxr-x 1 lsy lsy 8312 Jan 29 21:18 process
-rw-rw-r-- 1 lsy lsy 29 Jan 29 21:08 process.c
[lsy@hcss-ecs-116a code_proc_control]$ ./process
[lsy@hcss-ecs-116a code_proc_control]$ 这段简单的代码并没有任何输出,我们怎么知道结果是否正确呢?
事实上,main函数return的值会交给父进程,通过 echo $? 命令可以查看上一个进程的退出码。

不同的退出码通常有不同的特殊的含义,包括是否正确运行、错误原因等。这个含义通常可以自定义,但是语言提供了一套数字到字符串的转化表。我们打印出来看一下(由于不知道有多少个退出码 所以多打印几个看看),需要用到strerror() 函数。
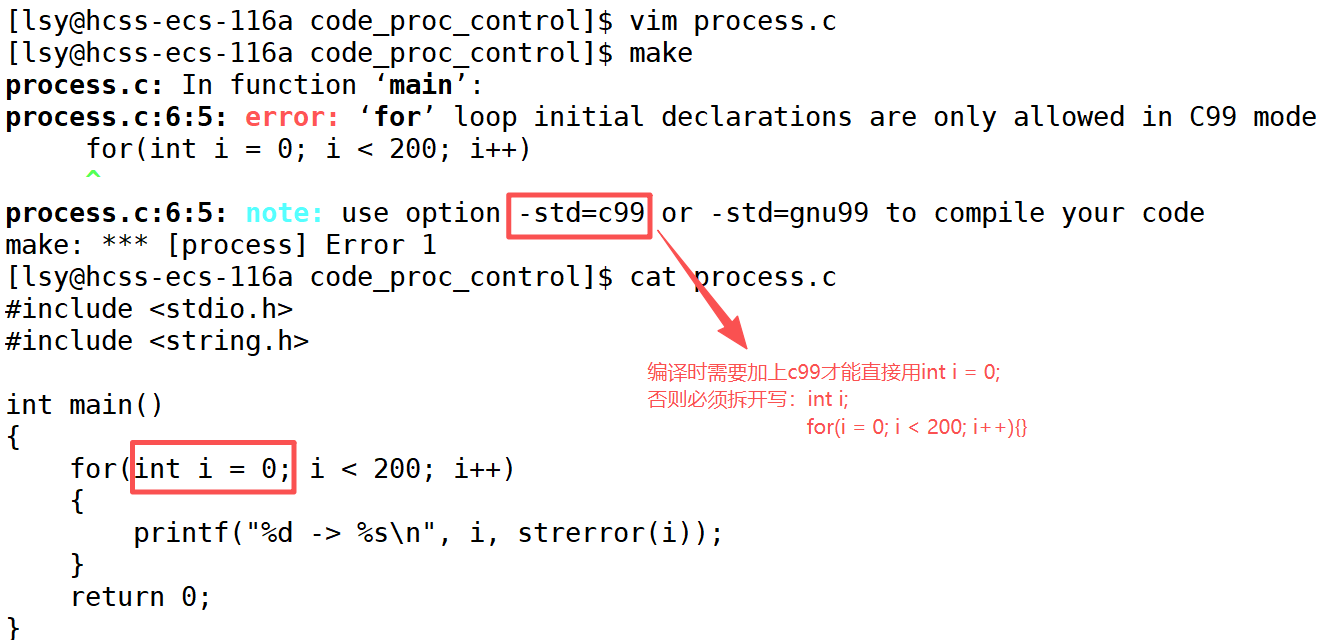
bash
[lsy@hcss-ecs-116a code_proc_control]$ vim makefile
[lsy@hcss-ecs-116a code_proc_control]$ cat makefile
process:process.c
@gcc -o $@ $^ -std=c99
.PHONY:clean
clean:
@rm -rf process
[lsy@hcss-ecs-116a code_proc_control]$ make
[lsy@hcss-ecs-116a code_proc_control]$ ll
total 20
-rw-rw-r-- 1 lsy lsy 80 Jan 29 21:39 makefile
-rwxrwxr-x 1 lsy lsy 8416 Jan 29 21:40 process
-rw-rw-r-- 1 lsy lsy 160 Jan 29 21:35 process.c
[lsy@hcss-ecs-116a code_proc_control]$ ./process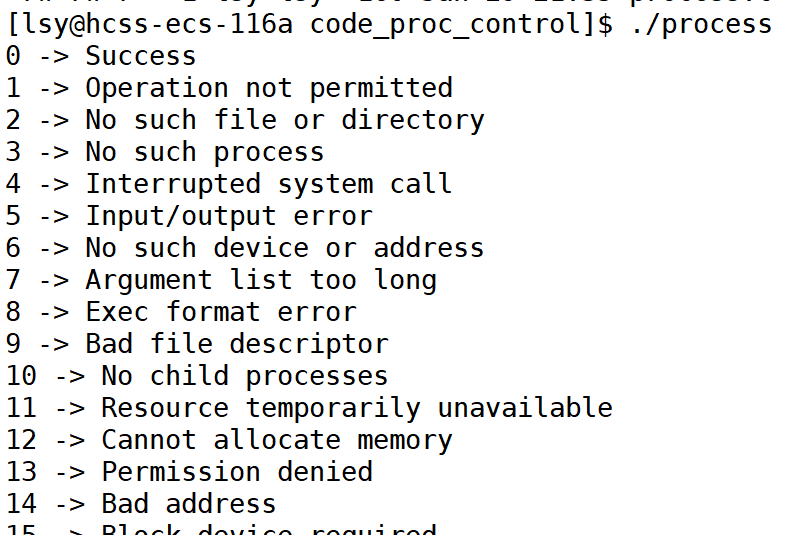
可以看出我们最开始那个什么都没写的直接返回的代码的退出码是0,代表success成功。库里面一共定义了134种退出码的含义。
2. 代码跑完,结果不正确
errno 是 C 语言标准库中的一个全局整型变量 ,用于存储最近一次函数调用失败的错误代码 。如果函数调用成功errno = 0,如果函数调用失败errno = !0。

函数调用失败C语言的全局变量errno会被设置,这个叫函数调用的错误码 ;与进程是否正常退出得到的退出码 ,是两个独立的概念。 我们可以在处理好函数失败后,让进程正常退出(返回0)。
bash
[lsy@hcss-ecs-116a code_proc_control]$ cat process.c
#include <stdio.h>
#include <string.h>
#include <errno.h>
int main()
{
// 函数调用成功errno = 0,失败errno = !0(非零)
FILE* fp = fopen("./log.txt", "r"); // 没有这个文件,以读的方式打开会失败
if(fp == NULL)
{
printf("%d->%s\n", errno, strerror(errno));
}
// for(int i = 0; i < 200; i++)
// {
// printf("%d -> %s\n", i, strerror(i));
// }
return 0;
}
[lsy@hcss-ecs-116a code_proc_control]$ make
[lsy@hcss-ecs-116a code_proc_control]$ ./process
2->No such file or directory
[lsy@hcss-ecs-116a code_proc_control]$ echo $?
0可以看到代码跑完了,退出码为0,但是函数调用失败错误码被设置为2,原因是文件不存在。
推荐自定义的做法,自己建一个表,下标和字符串一一对应,也可以直接定义宏。
3. 代码没跑完,进程异常
如果代码没跑完,说明return语句没有被执行,退出码是无意义的。
什么情况会导致进程异常?
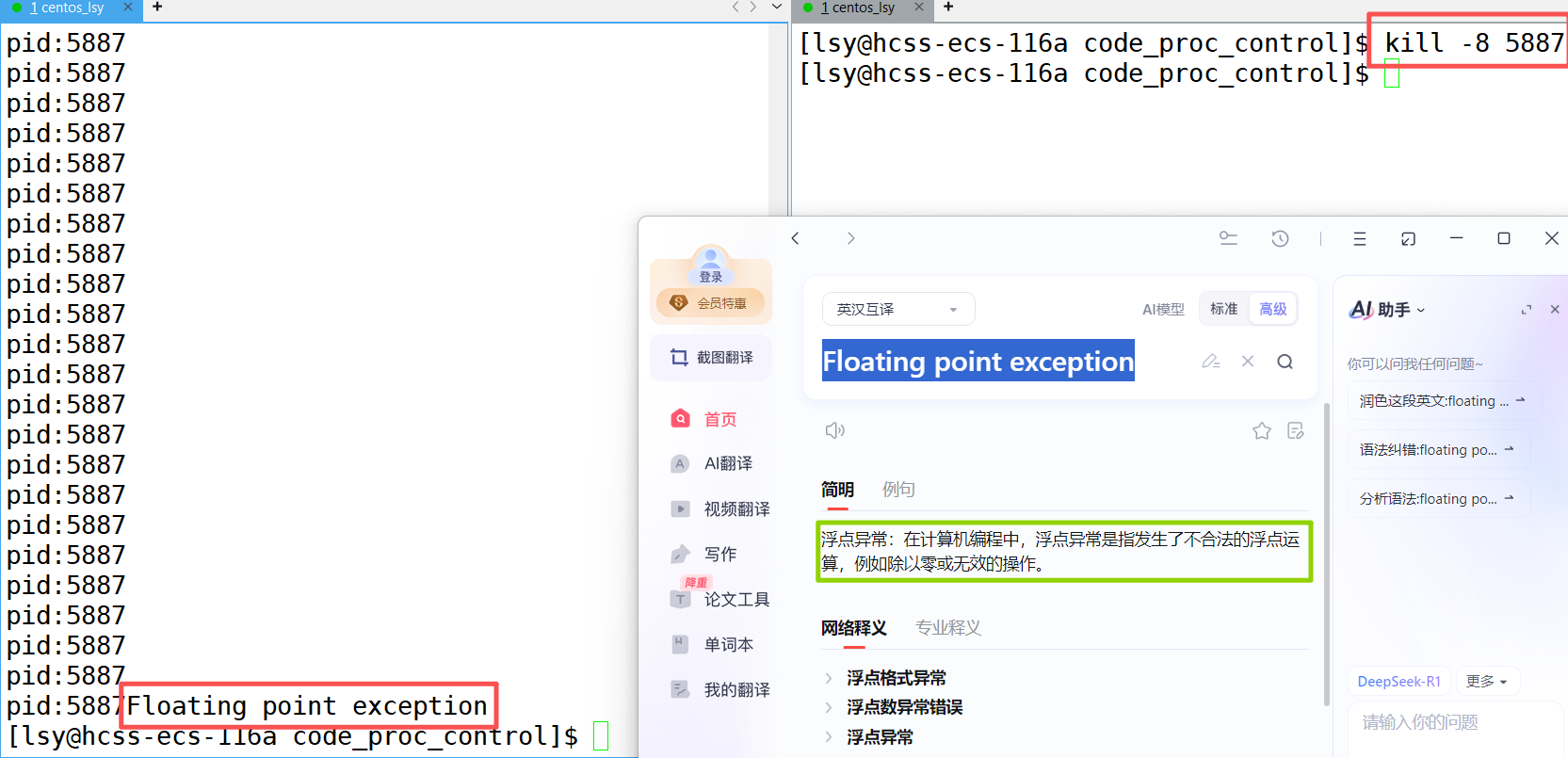
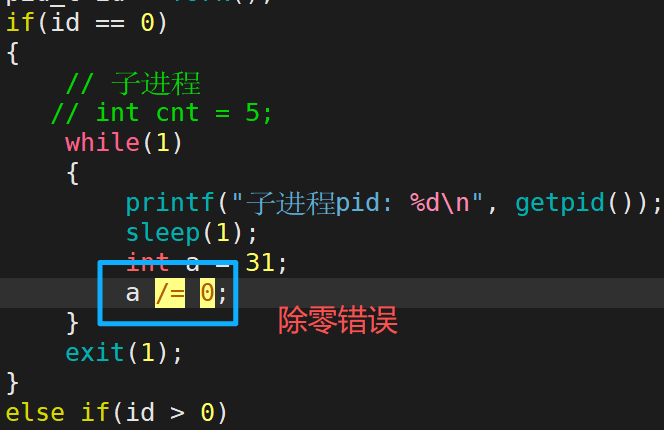
因出现某种错误,比如除零、越界、野指针等,代码没跑完就被信号终止了,就是进程异常。
信号编号signumber 是操作系统内核为每一种信号分配的唯一数字标识符。比如8号是除零错误的信号,当程序中出现除零错误,进程就会收到这个信号;11号是野指针信号等等。进程收到这些信号都会终止。
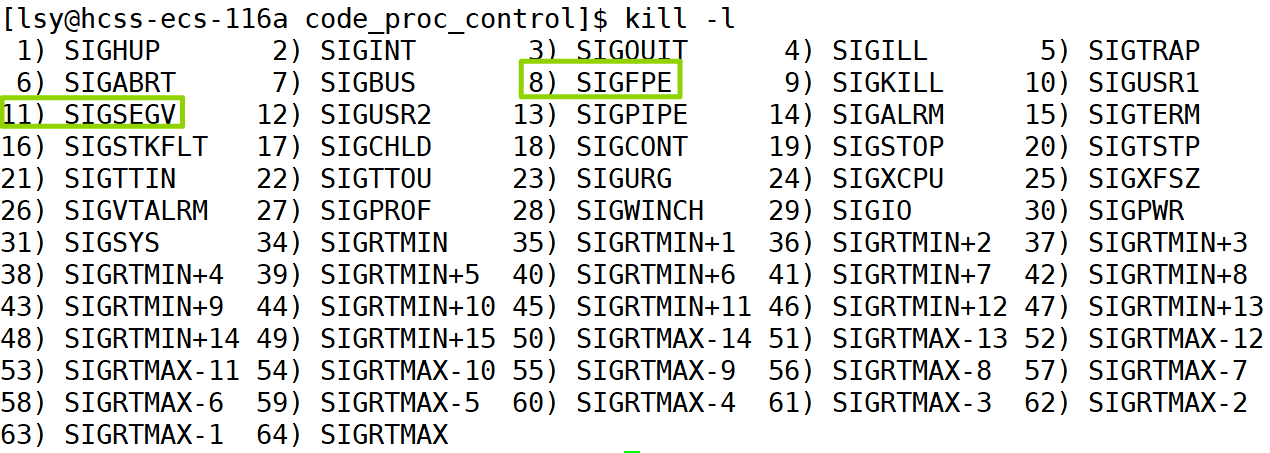
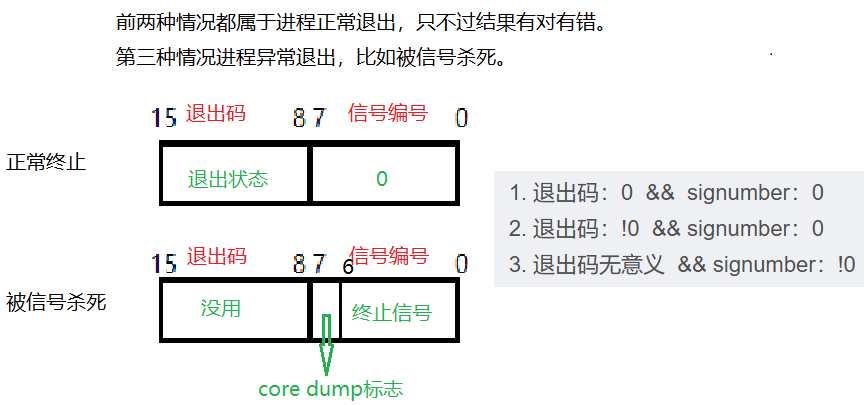
重新总结上面的三种情况:
退出码:0 && signumber:0
退出码:!0 && signumber:0
退出码无意义 && signumber:!0
进程执行的结果可以用两个数字表示:int exit_signal, int exit_code 这两个数字不需要用户自己维护,当一个进程退出的时候,操作系统会把进程退出的详细信息写入到进程的task_struct中。所以进程退出需要僵尸,维持自己的退出状态。
3)不考虑异常的情况下,如何让进程退出?
- 在main函数中return。
2.exit -- 语言提供
在程序中的任意位置调exit() --> 语言提供的,传递的参数是进程的退出码。

cpp
#include <stdlib.h>
int main()
{
// exit
printf("pid:%d, ppid:%d\n", getpid(), getppid());
exit(0);
return 0;
}
现在修改一下退出码:
cpp
#include <stdlib.h>
int main()
{
// exit
printf("pid:%d, ppid:%d\n", getpid(), getppid());
exit(12);
return 0;
}
在非main函数中使用return只是函数结束,而使用exit是进程结束。
3. _exit -- 系统调用

cpp
#include <unistd.h>
void test01()
{
printf("hello world\n");
_exit(16);
}
int main()
{
// exit
printf("进程:pid:%d, ppid:%d\n", getpid(), getppid());
test01();
exit(12);
return 0;
}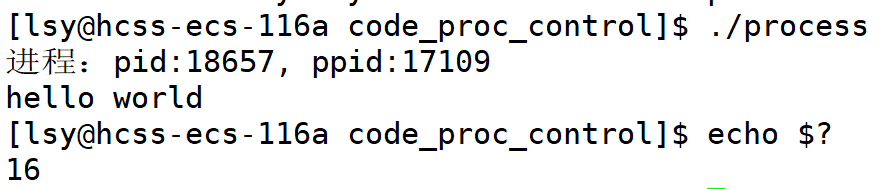
这样看起来exit和_exit效果是一样的,那么他们的区别是什么呢?
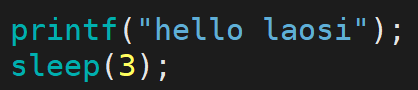
这个程序的现象我们前面说过,明明是先执行printf再休眠,但是实际现象是先休眠了3秒再打印。原因是字符被先放进了缓冲区,有换行符\n或者进程结束才会被刷新出来。那如果我们不给换行符,用这两个函数来中止进程会有什么现象:
① _exit版本,休眠三秒后什么都没有打印。
② exit版本,休眠三秒后打印出了hello laosi 。
所以exit和_exit的区别:
exit在终止进程的同时会刷新一次缓冲区,但是_exit不会(所以建议使用exit终止进程,不然结果可能和我们预期不同,比如该打印的东西没打印出来)。
exit是库函数,_exit是系统调用。库函数底层封装了系统调用,在系统调用的上层。
系统调用是内核操作,而系统调用不是,说明缓冲区及刷新缓冲区的操作一定不在内核中,实际上是由C/C++维护的。
三. 进程等待
1)为什么要进行进程等待?
- 不等待会造成内存泄漏的问题。
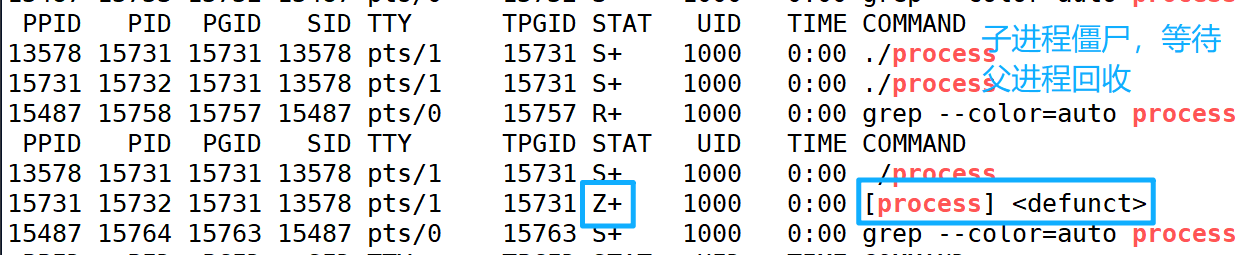
因为父进程如果不回收子进程的退出信息,就会造成子进程变成僵尸进程,一旦变成僵尸进程除非有人回收不然kill -9也杀不死该进程(因为它已经死了,只是资源未被回收),最终内存中的僵尸进程越来越多,他们的PCB被保存,造成内存泄露。
- 父进程可能有要获取子进程退出信息的需求。比如父进程派给子进程的任务完成得怎样,结果对不对?是否正常退出?等等。
**解决方案:**父进程通过进程等待的方式回收子进程的资源,并获取子进程的退出信息。
2)怎么进行等待?

1. 验证父进程等待可以解决子进程僵尸问题
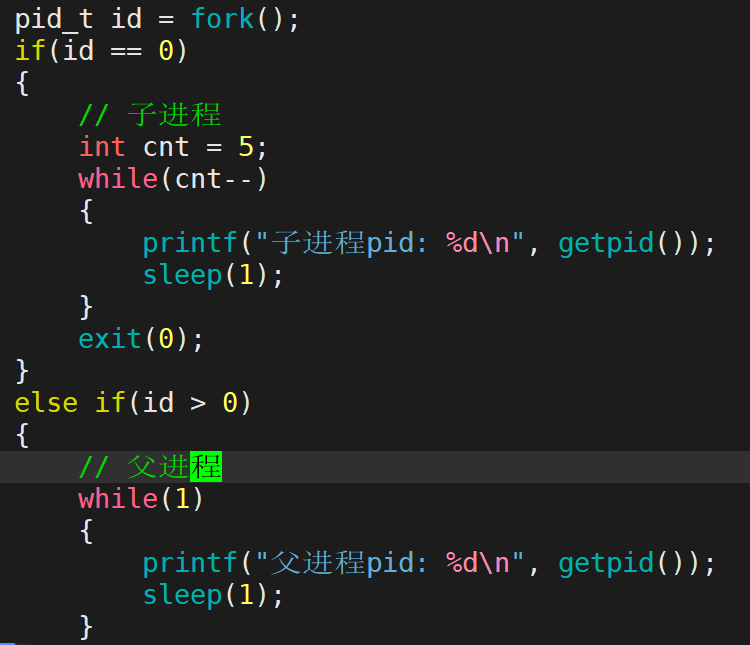
上面这段代码我们在介绍僵尸进程的时候写过一次,子进程退出后会变成并保持Z(僵尸)状态。现在我们修改一下代码,让父进程等待一下子进程。子进程什么时候退出父进程等到什么时候。
cpp
#include <stdio.h>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
int main()
{
pid_t id = fork();
if(id == 0)
{
// 子进程
int cnt = 5;
while(cnt--)
{
printf("子进程pid: %d\n", getpid());
sleep(1);
}
exit(0);
}
else if(id > 0)
{
// 父进程
pid_t rid = wait(NULL);
// fork给父进程返回的是子进程的id,wait成功后返回的也是等待的子进程的id值
if(rid == id)
{
printf("pid:%d wait success\n", getpid());
}
}
return 0;
}
bash
[lsy@hcss-ecs-116a code_proc_control]$ ./process
子进程pid: 11294
子进程pid: 11294
子进程pid: 11294
子进程pid: 11294
子进程pid: 11294
pid:11293 wait success
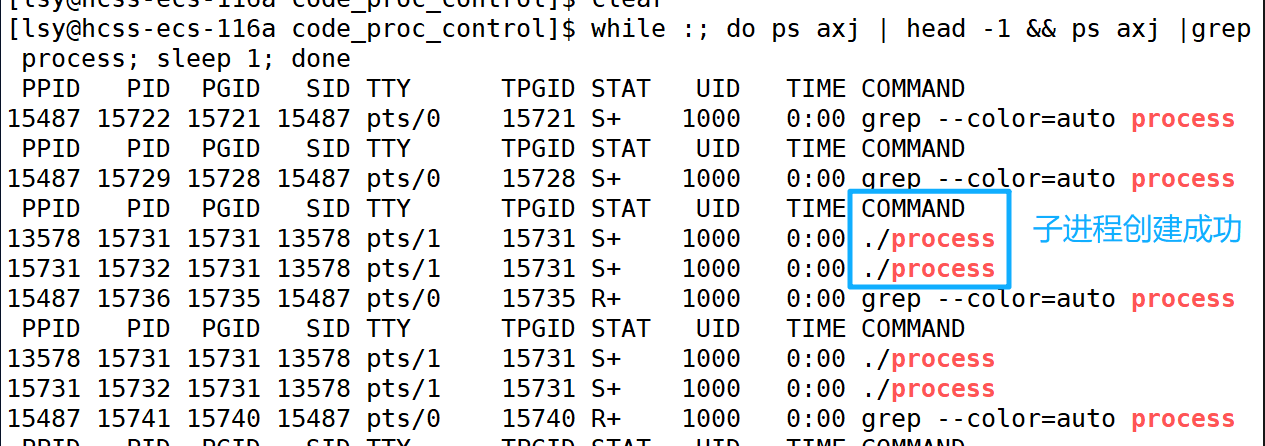
[lsy@hcss-ecs-116a code_proc_control]$ - 如果父进程在等待子进程,但是子进程没有退出,则父进程会阻塞在wait函数中。进程不仅可以因为等待硬件就绪而阻塞,也可因为软件。
我们在父进程的wait前和printf后都加上几秒的睡眠,方便我们使用ps观察进程状态,否则例如子进程退出后立即被父进程等待回收,可能看不到子进程的僵尸状态。

2.验证获取子进程退出信息
waitpid不仅包含wait的功能,还有自己特有的功能,所以使用是的最佳实践是waitpid。
① waitpid函数
cpp
pid_t waitpid(pid_t pid, int *status, int options);- 返回值:
|-----|------------------------------------------------|
| 返回值 | 含义 |
| >0 | 成功回收了一个已经终止的子进程,返回该子进程的PID |
| =0 | 设置了选项WNOHANG,但没有子进程状态变化,子进程还在运行 |
| -1 | 调用中出错,比如指定的子进程并不存在或者没有子进程;将errno设置成相应的值,指示错误所在 |
WNOHANG (Wait No Hang) 是waitpid()系统调用的一个选项标志,意思是 "非阻塞等待"。
它的作用就是让waitpid()变成非阻塞调用,让父进程在子进程没结束是能继续做别的事情,而不是阻塞在那里一直等待。
计算机中,屏幕突然卡住怎样都没反应叫夯住了。如果突然黑屏蓝屏叫宕机了。
设置了WNOHANG之后如果没有子进程状态变化,立即返回0,父进程不会暂停,立即继续执行。
-
参数:
pid:|------|-----------------------|
| pid值 | 含义 |
| -1 | 只有一个子进程,等待它。与wait等效 |
| >0 | 有多个子进程,填你要等的那个子进程的pid |status:输出型参数,用来获取子进程的退出信息。
调用前:是一个普通的整型变量
调用后:系统会填充这个变量,包含子进程的退出信息,这个整数不是简单的退出码,而是包含多个信息的位图(共32位):高16位(16-31位):不用。次低8位(8-15位):退出码。低八位:信号编号
WIFEXITED() :回答 进程是不是正常退出的问题。若为正常终止子进程返回的状态,则为真。
WEXITSTATUS():回答 正常退出的退出码是多少?前提是正常退出,即WIFEXITED非零。
cpp
int status;
pid_t result = waitpid(child_pid, &status, 0);options:
默认为0,表示阻塞等待(wait就是阻塞等待)。
WNOHANG: 若pid指定的子进程没有结束,则waitpid()函数返回0,不予以等待。若正常结束,则返回该进程的ID。
cpp
int main()
{
pid_t id = fork();
if(id == 0)
{
// 子进程
int cnt = 5;
while(cnt--)
{
printf("子进程pid: %d\n", getpid());
sleep(1);
}
exit(1);
}
else if(id > 0)
{
// 父进程
int status = 0;
pid_t rid = waitpid(id, &status, 0); // 取地址
if(rid == id)
{
printf("pid: %d, wait success! status: %d\n", getpid(), status);
}
}
return 0;
}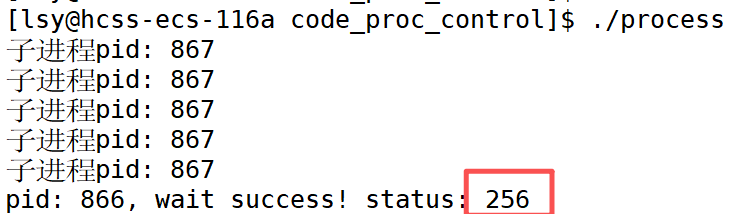
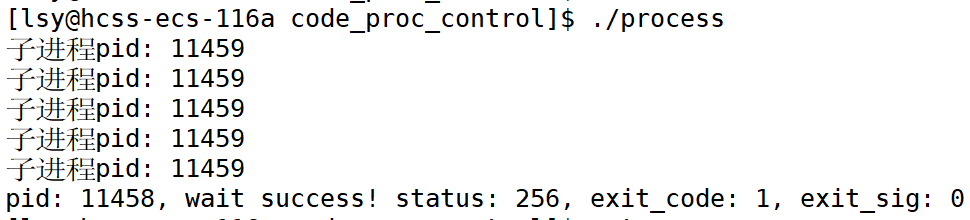
我们设置的子进程的退出码不是1吗,怎么打印出来的退出信息status是256?
根据前面总结的子进程退出的三种情况的部分,我们知道子进程的退出情况可以用两个数字--退出码和信号编号表示。所以status获取子进程的退出信息实际是要得到这两个数字。但一个参数如何获得两个数字呢?用到位图。 信号编号的8位实际上只有7位真正用来存储信号编号,其中有一位用于core dump标志,之后说这个标志的问题。
cpp
int main()
{
pid_t id = fork();
if(id == 0)
{
// 子进程
int cnt = 5;
while(cnt--)
{
printf("子进程pid: %d\n", getpid());
sleep(1);
}
exit(1);
}
else if(id > 0)
{
// 父进程
int status = 0;
pid_t rid = waitpid(id, &status, 0);
if(rid == id)
{
int exit_code = ((status >> 8) & 0xFF); // 退出码,次低八位
int exit_sig = status & 0x7F; // 0111 1111
printf("pid: %d, wait success! status: %d, exit_code: %d, exit_sig: %d\n",
getpid(), status, exit_code, exit_sig);
}
}
return 0;
}
上面这是进程正常终止的情况,下面我们用信号杀死子进程,模拟一个异常退出的情况,看一看进程的退出码和信号编号。
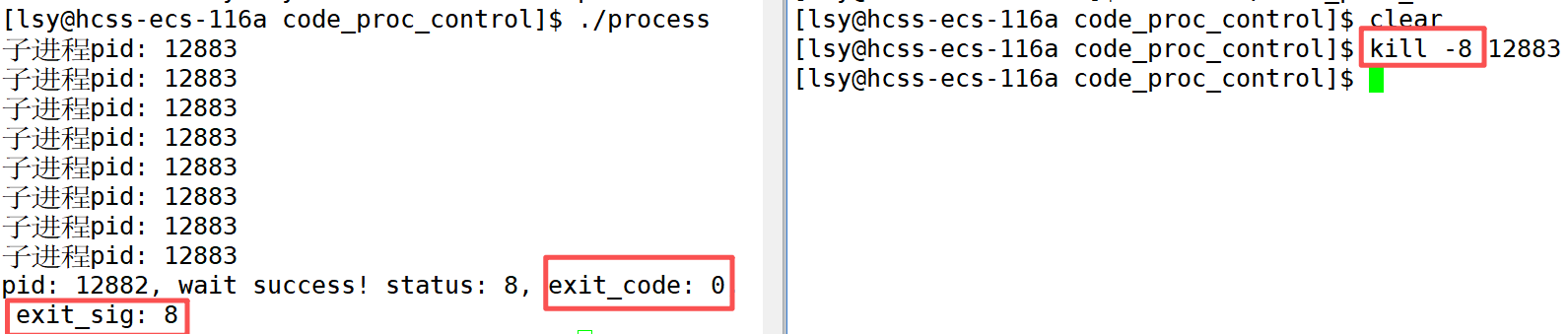
如果代码中真的有异常呢?刚运行就崩溃了。
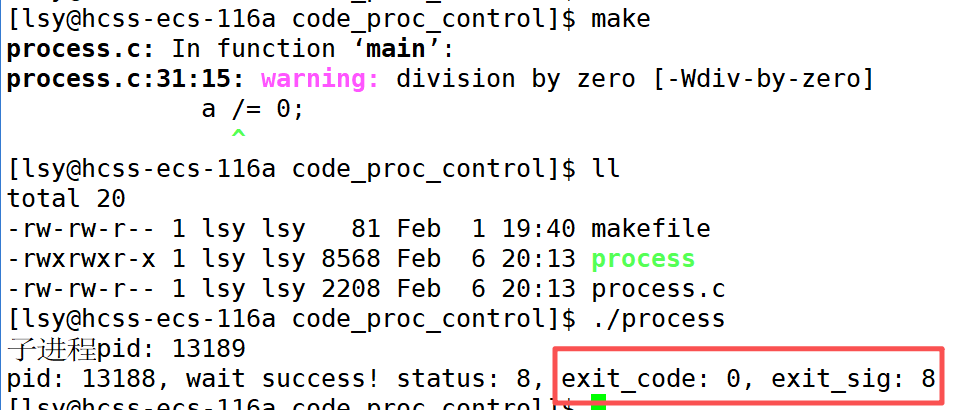
3. 父进程通过waitpid()这一系统调用是如何得到子进程的退出信息的
子进程僵尸之后会将自己的exit_code和exit_sig写在PCB中,waitpid通过第一个参数pid找到要回收的子进程的PCB从而获取这两个数字。
那如果pid传的是-1呢,怎么找对应进程的PCB呢?
源码中可以看到,父进程的PCB中有子进程的链表结构(也就是说父进程会把自己的子进程通过链表管理起来),父进程会遍历链表找到第一个状态为Z(僵尸)的子进程并回收。
4. waitpid返回值
_bash:代表远程登陆的bash
fork之后父子进程谁先运行?
不一定,由调度器决定。
一般父子进程谁先退出?
子进程,因为父进程要负责回收子进程资源。
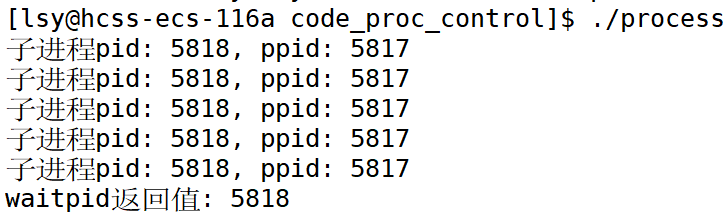
① 正确退出时,返回值>0,是成功等待的子进程的id值。
cpp
pid_t id = fork();
if(id == 0)
{
// 子进程
int cnt = 5;
while(cnt--)
{
printf("子进程pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
exit(0);
}
else if(id > 0)
{
// 父进程
int status = 0;
pid_t rid = waitpid(id, &status, 0);
if(rid == id)
{
printf("waitpid返回值: %d\n", rid);
// int exit_code = ((status >> 8) & 0xFF); // 退出码,次低八位
// int exit_sig = status & 0x7F; // 信号编号,0111 1111
// printf("pid: %d, wait success! exit_code: %d, exit_sig: %d\n",
// getpid(), exit_code, exit_sig);
}
}
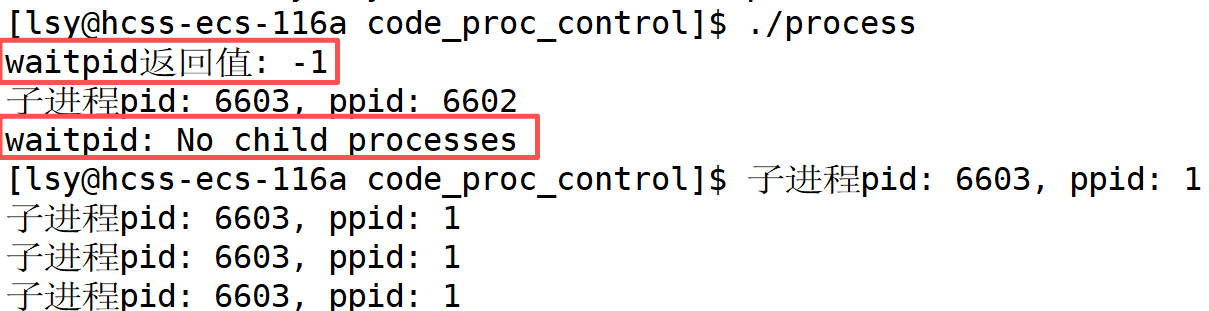
② waitpid调用失败 时会返回-1。
什么情况下会失败呢?等待一个不属于自己的进程就会失败。
cpp
pid_t id = fork();
if(id == 0)
{
// 子进程
int cnt = 5;
while(cnt--)
{
printf("子进程pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
exit(0);
}
else if(id > 0)
{
// 父进程
int status = 0;
pid_t rid = waitpid(id+1, &status, 0);
if(rid <= 0)
{
printf("waitpid返回值: %d\n", rid);
perror("waitpid");
}
else
{
printf("wait success! 子进程id: %d", getpid());
}
}
5. waitpid为提取status准备的宏
cpp
int exit_code = ((status >> 8) & 0xFF); // 退出码,次低八位
int exit_sig = status & 0x7F; // 0111 1111前面我们在获取status的时候还要进行位操作提取两个退出信息,不太方便,所以waitpid为提取status创建了若干个宏函数。我们只重点看两个 -- WIFEXITED 和 WEXITSTATUS 。
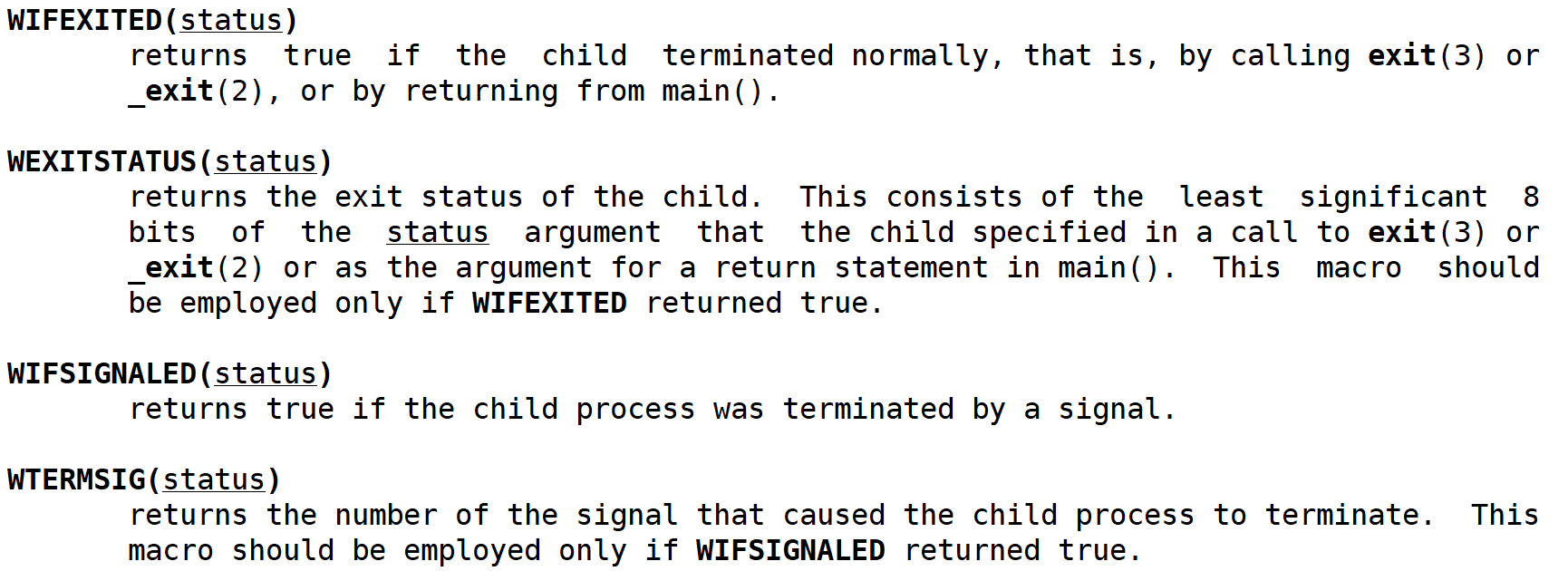
WIFEXITED: 如果子进程正常终止,则返回true。(查看子进程是否正常退出)
WEXITSTATUS: 如果WIFEXITED非零,提取子进程退出码。(查看进程的退出码)
这两个宏的定义大致为(当我们在使用时不用自己定义,直接用就行):
cpp
#define WIFEXITED(status) (!(status & 0x7F))
#define WEXITSTATUS(status) ((status>>8) & OxFF)我们举一个使用的例子:在rid>0,即等待成功的情况下,父进程拿到子进程的退出信息,我们用宏函数来提取。
cpp
pid_t id = fork();
if(id == 0)
{
// 子进程
int cnt = 5;
while(cnt--)
{
printf("子进程pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
exit(0);
}
else if(id > 0)
{
// 父进程
int status = 0;
pid_t rid = waitpid(id, &status, 0);
if(rid > 0) // 如果等待成功了,说明拿到退出信息了
{
if(WIFEXITED(status)) // 如果进程正常退出了,则WIFEXITED(status)返回true
{
// 那我们就把退出码提取出来
printf("wait sucess! 子进程id: %d, exit_code: %d\n",
rid, WEXITSTATUS(status));
}
else
{
printf("子进程异常退出\n");
}
}
else
{
printf("等待失败,waitpid返回值: %d\n", rid);
perror("waitpid");
}
}
6. waitpid参数--option
① option为0,父进程阻塞等待。因为这样比较简单所以在实际应用中,阻塞等待是比较常见的。
② 但是有时我们会觉得,只要子进程没退出父进程就一直阻塞,什么任务都不做,比较浪费资源,所以定义了一个宏--WNOHANG ,他会让waitpid处于非阻塞的工作状态。
这个非阻塞的工作状态就是:调用一次waitpid,不管子进程是否退出都立即返回做其他任务,进行多次系统调用检查子进程是否已经退出,也叫非阻塞轮询。
之前我们写的那种调用一次waitpid只要系统没检测出子进程已经退出了就一直等待的情况都叫阻塞等待。
如果想要等待这项工作非阻塞,那么等待方式option就要选择WNOHANG。
非阻塞等待使用举例 :
非阻塞轮询中的非阻塞是由系统提供的,而轮询(一段时间后检测一次子进程是否退出)是需要我们自己在程序中通过循环实现的。
cpp
pid_t id = fork();
if(id == 0)
{
// 子进程
int cnt = 2;
while(cnt--)
{
printf("子进程pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
exit(0);
}
else if(id > 0)
{
// 父进程
while(1) // 只有子进程退出,等待成功了才停止检测
{
int status = 0;
pid_t rid = waitpid(id, &status, WNOHANG);
if(rid > 0) // 如果等待成功了,rid是子进程的id值
{
if(WIFEXITED(status))
{
printf("wait success! 子进程id: %d, exit_code: %d\n", rid, WEXITSTATUS(status));
}
break;
}
else if(rid == 0) // 子进程还没有退出,每隔100ms检测一次
{
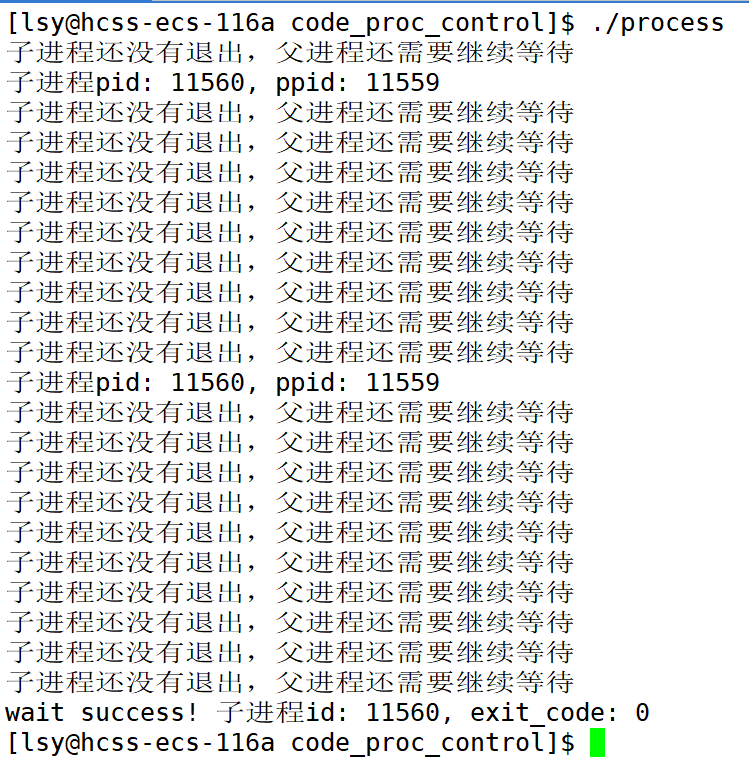
printf("子进程还没有退出,父进程还需要继续等待\n");
usleep(100000); // 0.1s 100ms
}
else // 返回值<0,子进程异常退出的情况
{
perror("waitpid");
break;
}
}
}
父进程总共要等多长时间是由子进程决定的,所以两种等待方式从等待的角度效率没有什么差别,不过非阻塞等待利用等待的时间做了更多事,完成了更多任务。
那么如何理解非阻塞模式下父进程能做其他的事,父进程是如何把等待的时间利用起来的?
makefile
cpp
proc:proc.cpp
@g++ proc.cpp -o proc -std=c++11
.PHONY:clean
clean:
@ rm -rf procproc.cpp
cpp
#include <iostream>
#include <vector>
#include <sys/wait.h>
#include <sys/types.h>
#include <unistd.h>
// 函数指针,定义了一个叫callback的类型,它的实例是指向函数的指针
// 我们这里指向的是没有返回值也没有参数的函数
typedef void (*callback_t)();
// 模拟一些任务给父进程做
void PrintLog()
{
std::cout << "print log" << std::endl;
}
void Hello()
{
std::cout << "hello" << std::endl;
}
void lsy()
{
std::cout << "lsy" << std::endl;
}
int main()
{
std::vector<callback_t> tasks;
tasks.push_back(PrintLog);
tasks.push_back(PrintLog);
tasks.push_back(PrintLog);
pid_t id = fork();
if(id == 0)
{
// 子进程
int cnt = 2;
while(cnt--)
{
printf("子进程pid: %d, ppid: %d\n", getpid(), getppid());
sleep(1);
}
exit(0);
}
else if(id > 0)
{
// 父进程
while(1) // 只有子进程退出,等待成功了才停止检测
{
int status = 0;
pid_t rid = waitpid(id, &status, WNOHANG);
if(rid > 0) // 如果等待成功了,rid是子进程的id值
{
if(WIFEXITED(status))
{
printf("wait success! 子进程id: %d, exit_code: %d\n", rid, WEXITSTATUS(status));
}
break;
}
else if(rid == 0) // 子进程还没有退出,每隔100ms检测一次
{
printf("子进程还没有退出,父进程还需要继续等待\n");
usleep(100000); // 0.1s 100ms
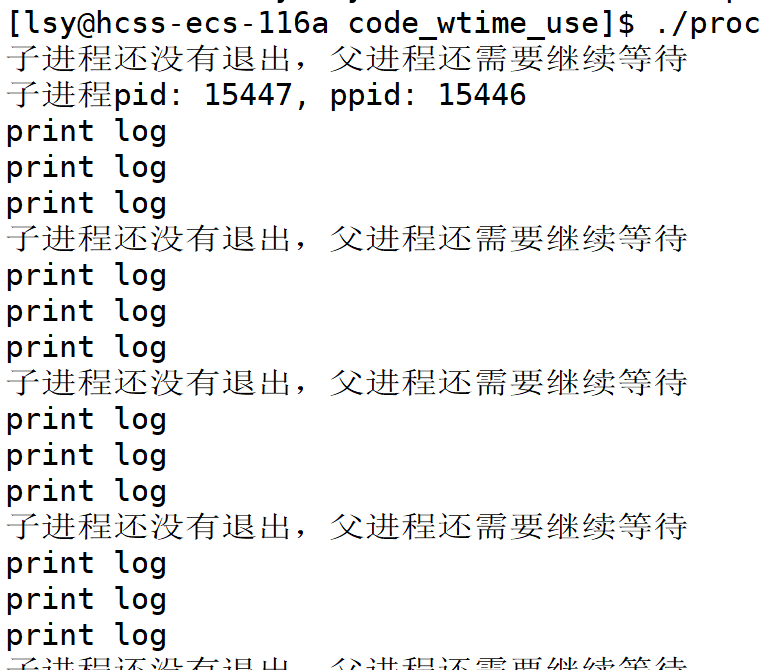
// 每当检测到子进程还没有退出就把任务做一遍
for(auto& task : tasks)
{
task();
}
}
else // 返回值<0,子进程异常退出的情况
{
perror("waitpid");
break;
}
}
}
return 0;
}可见父进程在检测到子进程并没有退出时,并没有阻塞而是继续执行,完成其他任务。知道子进程运行结束退出。我们上面的代码中,相当于使用函数指针和vector制作了一份任务清单,让父进程在等待期间都做一遍。

四. 创建多进程
cpp
// 创建多进程
#include <iostream>
#include <string>
#include <vector>
#include <unistd.h>
#include <sys/types.h>
#include <sys/wait.h>
using namespace std;
// 现在我不想让多个子进程总做同样的工作,通过函数指针来实现
typedef void (*callback_t)();
// 枚举几个退出码
enum
{
// 默认值从0开始
SUCCESS,
USAGE_ERR // 用法出错
};
void Tasks()
{
// 被创建出来的子进程需要完成的任务
int cnt = 2;
while(cnt--)
{
printf("子进程pid: %d, ppid: %d, cnt: %d\n",
getpid(), getppid(), cnt);
sleep(1);
}
}
void Hello()
{
printf("Hello\n");
}
// 输入输出参数一般总结
// 输入: const&
// 输出: *
// 输入输出: & (引用)
void CreatChildProcess(int num, vector<pid_t>* subs, callback_t cb) // 用一个输出型参数subs把id值带出去
{
// 每次创建好一个进程都将子进程的id保存起来
for(int i = 0; i < num; i++)
{
pid_t id = fork();
if(id == 0)
{
// 只有这段代码块内是子进程
// Tasks();
cb();
exit(0);
}
subs->push_back(id);
}
}
void WaitAllChild(int num, const vector<pid_t>& subs)
{
int status = 0;
for(int i = 0; i < num; i++)
{
pid_t rid = waitpid(subs[i], &status, 0);
if(rid > 0)
{
// 如果等待成功
cout << "成功回收子进程" << subs[i] <<
", exit_code: " << WEXITSTATUS(status) <<endl;
}
}
}
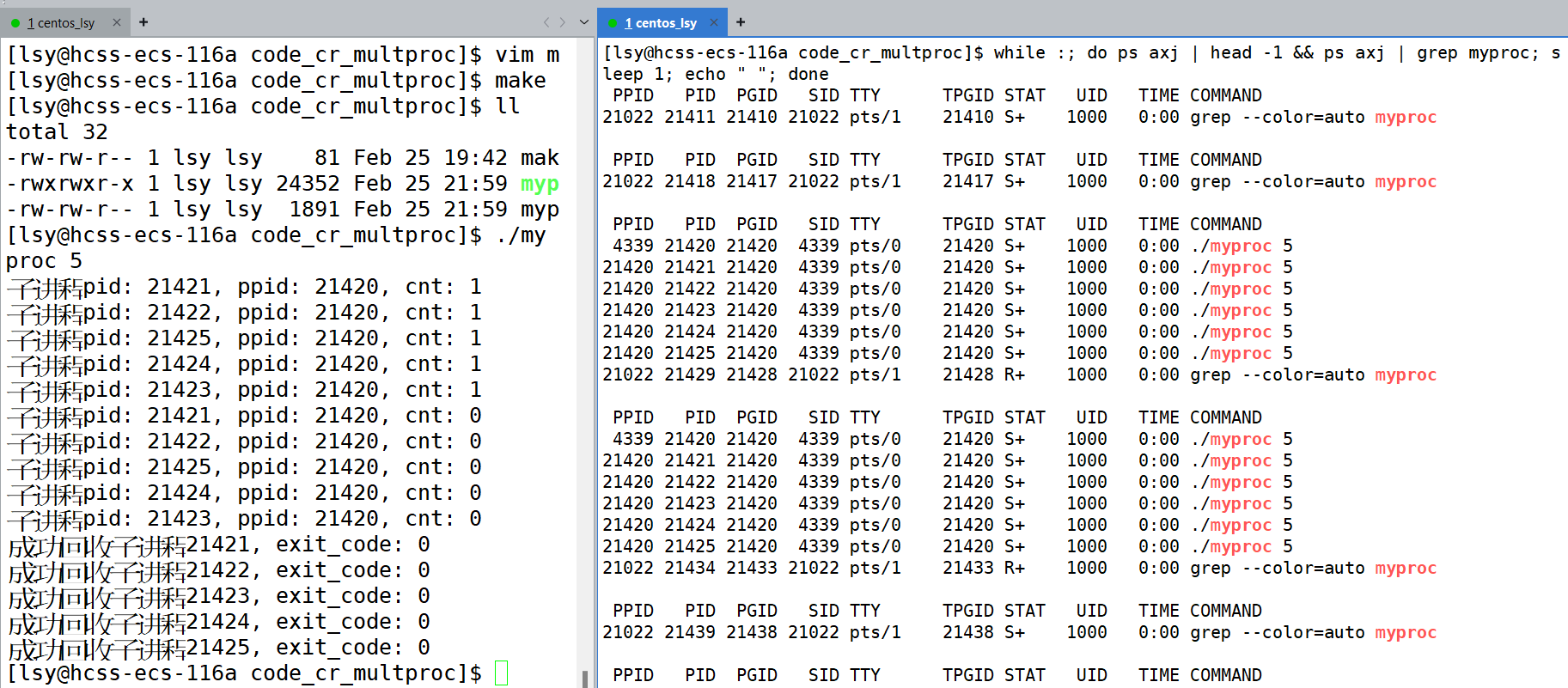
int main(int argc, char* argv[])
{
// 使用指令比如: ./myproc 3 代表要创建三个子进程
if(argc != 2) // 说明指令传的有问题,提示一下正确的指令格式
{
cout << "Use of the correct way:" << argv[0] << ' ' << "ProcessNum" << endl;
exit(USAGE_ERR);
}
int num = stoi(argv[1]);
vector<pid_t> subs;
// 还可创建任务清单,实现每一个子进程都执行不同的任务
// vector<callback_t> cbs;
// 创建多进程
CreatChildProcess(num, &subs, Hello);
// 等待回收多进程
WaitAllChild(num, subs);
return SUCCESS;
}
这段代码还有可以扩展的地方,比如任务清单实现不同的子进程分别执行不同的任务,可以自己尝试。