本节总结redis,将深度探讨redis作为缓存的场景
redis基本用途
从前面的学习可以知道,redis最主要的用途,基本分为三个方面
1:存储数据(内存数据库)
- 把 Redis 当作数据库来用,数据主要存在内存,配合持久化(RDB/AOF)保证数据不丢。
- 适合对读写延迟要求极高的场景,如用户会话、商品库存、排行榜等。
2:缓存(redis最常用的场景)
- 作为 MySQL 等慢速磁盘数据库的前置缓存,拦截大部分读请求,降低数据库压力。
- 这是 Redis 在互联网公司最普遍的用法。
3:消息队列
- 利用
List、Pub/Sub、Stream等数据结构实现简单的消息队列功能。- 注意:Redis 作为消息队列是 "轻量级" 的,在可靠性、持久化和复杂路由上不如专业 MQ(如 Kafka、RabbitMQ)。
redis作为缓存
一般来说快 的设备可以作为慢的设备的缓存
最常见的就是使用内存作为硬盘的缓存,这也就是redis的定位
这里硬盘也可以作为网络的缓存
一般来说浏览器从服务器上拉取资源的时候,有时候html,文字,视频等体积大但是又不轻易改变的,浏览器会缓存到本地磁盘,然后后面再拉取的时候先看本地磁盘有没有缓存
用户可以通过ctrl+F5进行刷新缓存,避免旧版本的前端代码导致bug
这里什么时候刷新缓存浏览器自己也有策略的,可以自行查略资料
缓存的设计核心思想:二八定律
虽然空间小,但是速度快,百分之20的数据就可以应对百分之80的请求
- 互联网业务中,大部分请求都集中在一小部分 "热点数据" 上(如热门商品、热门新闻)。
- 我们只需要把这 20% 的热点数据放到高速缓存(Redis 内存)中,就能拦截 80% 的请求,极大提升系统性能。
- 这也是为什么缓存空间不需要太大,却能发挥巨大作用的原因。
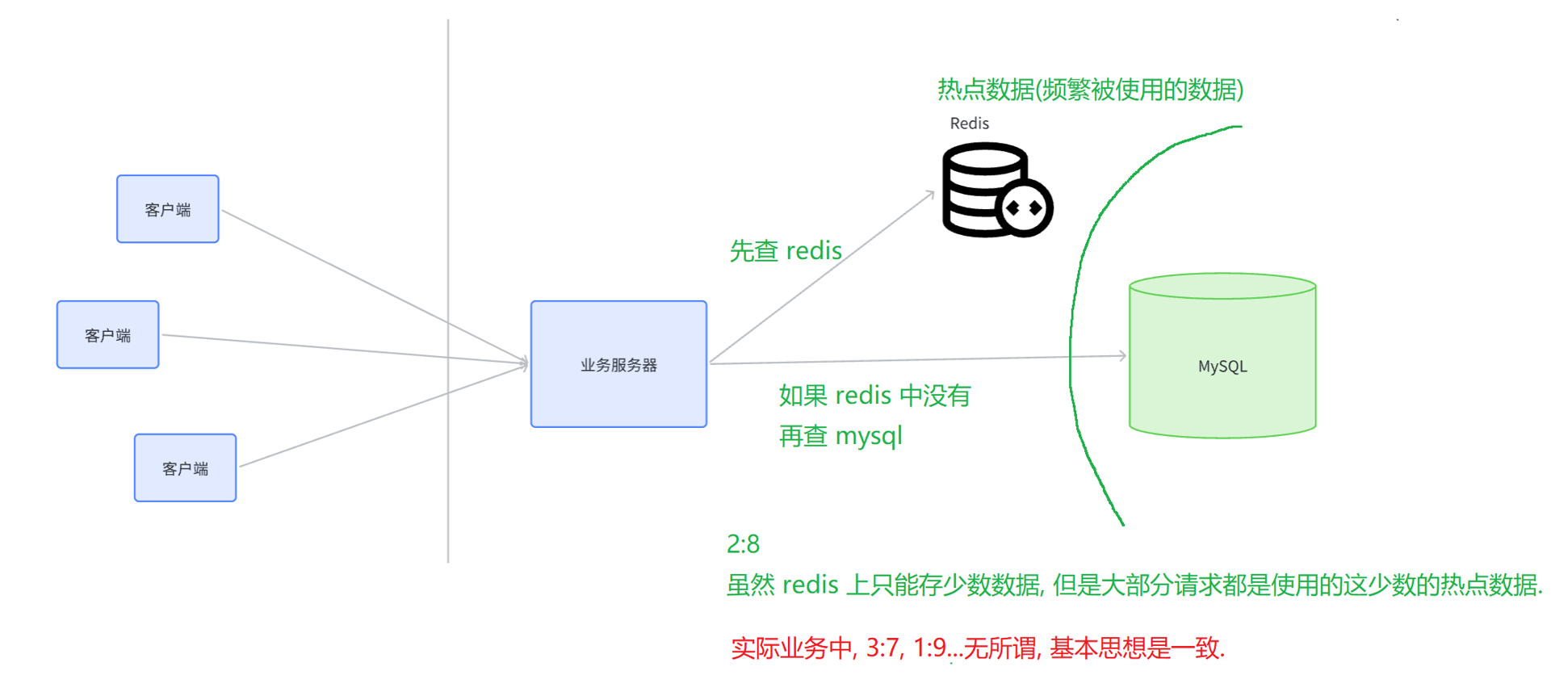
通常来说,我们会使用redis作为mysql的缓存mysql作为关系型数据库
硬件层面
数据存储在硬盘上,硬盘 I/O(尤其是随机访问)速度远慢于内存。
每次查询都要进行磁盘读写,这是性能的主要瓶颈。
软件层面
如果查询不走索引,需要全表扫描,大大增加 I/O 次数。
关系型数据库需要对 SQL 进行解析、校验、优化等一系列工作,增加了 CPU 开销。
复杂查询(如联合查询)需要进行笛卡尔积、排序等操作,效率更低。
每一次请求都需要消耗一些硬件资源(cpu,内存,硬盘,网络)等,如果达到上限很可能就会出现故障
MySQL 等关系型数据库的并发承载能力有限,当请求量激增时,很容易成为系统瓶颈,甚至宕机。
提高并发的两个思路
开源(Scale Out):
- 引入更多机器,构成数据库集群(如 MySQL 主从、分库分表)。
- 通过水平扩展,把压力分散到多台机器上。
节流(Cache):
- 引入缓存(如 Redis),把频繁读取的热点数据保存到缓存中。
- 后续查询时,先查缓存,缓存命中就直接返回,不再访问 MySQL。
- 这是互联网公司最常用、最有效的 "节流" 方案。

redis应该存储哪些数据???
定期缓存
- 日志记录:将用户的访问数据(如搜索引擎的查询词)以日志形式记录下来。
- 离线统计:使用大数据工具(如 Hadoop、Hive)对日志进行分析,统计出访问频率最高的前 20% 数据,即 "热点词"。(这里看自己的业务场景,一天还是一周统计一次)这里的工作主要是大数据工程师
- 同步服务器:根据统计出的热点词,提前从数据库中取出对应的搜索结果或广告数据,写入 Redis。
- 定时更新:通过python/shell脚本写的定时任务(如每天、每月)重复上述流程,更新缓存中的热点数据。完成统计热词的过程,找到对应的搜索结果,同步到缓存服务器上,写入到redis
- 优点 :
- 过程可控,缓存中的数据是固定的,方便排查问题。
- 能有效应对已知的、稳定的热点,大幅降低数据库压力。
- 缺点 :
- 实时性不足:无法应对突发的热点(如春晚、突发事件),新的热点可能因未被统计而直接打到数据库。
实时生成
不提前加载数据,而是在用户请求时按需加载:
- 先查 Redis。
- 如果命中,直接返回。
- 如果未命中,从数据库查询,并将结果写入 Redis,供下次使用。
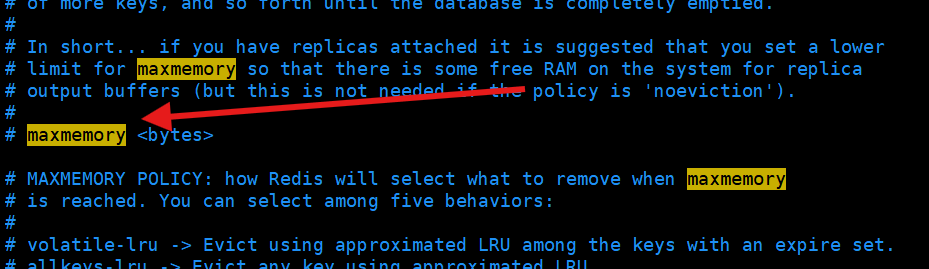
有时候不是达到机器的内存上限,而是你自己配置文件当中运行redis使用的内存上限
这种 "写回" 模式会导致 Redis 内存占用越来越高,最终达到
maxmemory上限。为了解决这个问题,Redis 引入了内存淘汰策略(经典面试题)。LFU 确实能更精准地识别长期热点,但它需要额外的空间存储每个 key 的访问计数,且对 "突发热点" 不敏感。例如,一个突发的新热点可能因为历史访问次数少而被错误地淘汰。因此,LRU 是更通用、更稳妥的选择,而 LFU 只在特定场景下更优。
具体采用哪个策略结合具体场景分析
策略 全称 核心逻辑 适用场景 volatile-lru Least Recently Used 在设置了过期时间的 key 中,淘汰最近最少使用的。 大部分缓存场景,优先淘汰冷数据。 allkeys-lru Least Recently Used 在所有 key 中,淘汰最近最少使用的。 最常用,符合 "二八定律",保留热点数据。 volatile-lfu Least Frequently Used 在设置了过期时间的 key 中,淘汰最近访问次数最少的。 需要精准识别长期热点的场景。 allkeys-lfu Least Frequently Used 在所有 key 中,淘汰最近访问次数最少的。 对访问频率敏感的场景。 volatile-random Random 在设置了过期时间的 key 中,随机淘汰。 不推荐,无策略可言。 allkeys-random Random 在所有 key 中,随机淘汰。 不推荐。 volatile-ttl Time To Live 在设置了过期时间的 key 中,淘汰即将过期的。 对数据时效性敏感的场景。 noeviction 默认 不淘汰,新写入操作直接报错。 不适合缓存场景,会导致服务不可用。

缓存预热(Cache Preheating)
- 定期生成:离线统计热点数据,主动写入 Redis(不涉及 "预热")。
- 实时生成:用户请求时按需加载,先查 Redis,未命中再查 MySQL,查到后写入 Redis。
- 冷启动问题:Redis 刚接入时是空的,所有请求都会打到 MySQL,压力极大。
缓存预热的作用
- 把 "定期生成" 和 "实时生成" 结合,提前把热点数据导入 Redis,解决冷启动问题。
- 随着时间推移,新的热点数据会通过淘汰策略覆盖旧数据。
是主动填充缓存 的手段,它解决的是 "实时生成" 模式下的冷启动空窗期问题
缓存穿透(Cache Penetration)
- 定义:查询的 key 在 Redis 和 MySQL 中都不存在,且会被反复查询,导致数据库压力过大。(意思就是导致查询还是一直打给mysql,导致承受巨大压力,redis相当于没用)
- 典型原因 :
- 业务设计不合理(如缺少参数校验,非法 key 被反复查询)。
- 开发 / 运维误操作(如误删数据库数据)。
- 黑客恶意攻击(用大量不存在的 key 扫库,是最常见的原因)。
- 解决方案 :
- 缓存空值:把不存在的 key 写入 Redis,value 设为非法值(如
"")。- 布隆过滤器:在查询前判断 key 是否存在,过滤不存在的 key。(我的c++部分有讲解布隆过滤器)
- 优点:空间效率和查询效率极高。
- 缺点:存在一定的误判率(判断存在的 key 可能真不存在,但判断不存在的 key 一定不存在)。
- 生产优化 :
- 提前把数据库中所有合法 key 初始化到布隆过滤器。
- 新增数据时同步更新布隆过滤器。
- 定期重建布隆过滤器,避免误判率过高。
缓存雪崩(Cache avalanche)
- 定义:短时间内 Redis 上大规模 key 失效,缓存命中率骤降,所有请求打到 MySQL,导致数据库宕机。
- 两种典型场景 :
- Redis 宕机 / 集群大量节点宕机(最严重的情况)。
- 大量 key 设置了相同的过期时间,同时失效。
- 解决方案 :
- 加强监控报警,保证 Redis 集群可用性。
- 设置过期时间时,添加一个随机偏移量 (如
EX 3600 + random(600)),让 key 在 3600~4200 秒之间随机过期,避免同时失效。应对 Redis 宕机的高可用方案
缓存雪崩最严重的情况是 Redis 宕机,生产中通常采用以下方案:
- Redis 集群 + 哨兵模式:实现自动故障转移,避免单点故障。
- 多级缓存:L1 缓存(本地内存,如 Caffeine)+ L2 缓存(Redis),Redis 宕机时,L1 缓存仍能扛住部分流量。
- 服务降级:Redis 宕机时,直接返回默认值或静态页面,避免请求打到数据库。
缓存击穿(Cache breakdown)
- 定义 :缓存雪崩的特殊情况,针对热点 key突然过期,导致大量请求直接打到数据库,引发数据库宕机。
- 特点:热点 key 访问频率高,影响更大,往往需要对服务器结构做较大调整。
- 解决方案 :
- 基于统计发现热点 key,设置永不过期。
- 分布式锁:限制数据库的访问频率。
- 服务降级:在特定情况下关闭不重要的功能,只保留核心功能。
"热点 key 永不过期" 不是真的不设置过期时间,而是采用逻辑过期:
- 把热点 key 的过期时间存在 value 中(如
{"data": "...", "expire_at": 1740245678})。- 业务查询时,先判断
expire_at是否过期。- 如果过期,用分布式锁 (如 Redis
SETNX)保证只有一个请求去数据库更新缓存,其他请求直接返回旧数据。- 这样既保证了数据的时效性,又避免了大量请求同时打到数据库。

分布式锁
在一个分布式系统中,也会涉及到多个节点访问同一个公共资源的情况,此时旧需要通过锁来做互斥控制,避免出现类似于"线程安全 "的问题,而Java的synchronized或者C++的std::mutex,这样的锁都只能在当前线程中生效 ,在分布式的这样多个进程多个主机的场景中就无能为力了,此时就需要使用分布式锁,来保证在任意顺序下执行逻辑都是ok的
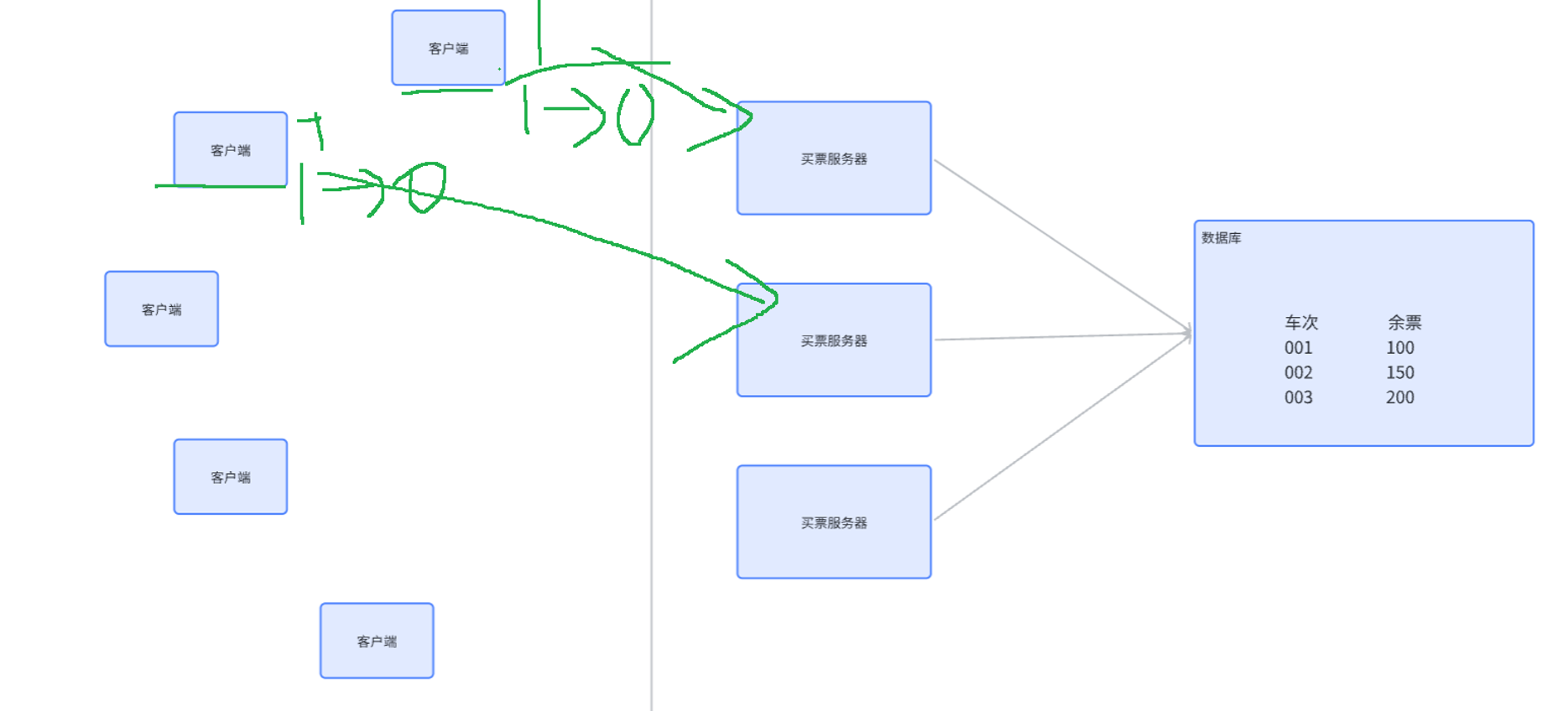
在分布式系统中,"查询剩余票" 和 "扣减剩余票" 这两个操作不是原子的,并发执行时会出现竞态条件(Race Condition)。
引入分布式锁是因为多个进程当中之间的执行顺序也有随机性,并且操作都不是原子的
如果不加分布式锁,此时可能就会出现超卖
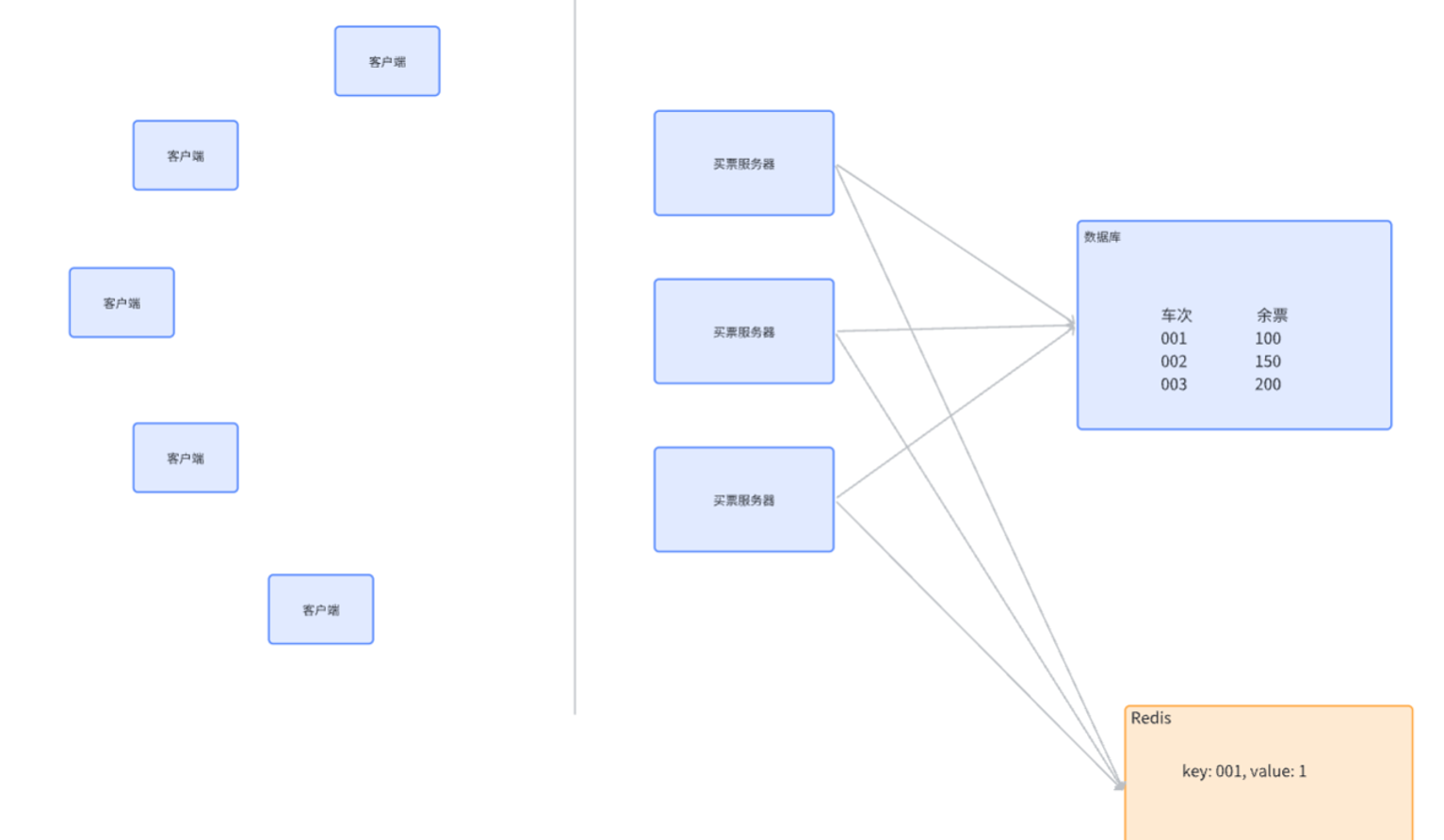
- 分布式锁是一个 / 一组单独的服务程序,提供 "加锁" 服务;
- Redis 是实现分布式锁的典型方案(但不是唯一的,也可以用 MySQL、ZooKeeper 等);
- 加锁后,保证只有一个服务器能执行 "查询 → 更新" 的原子操作,其他服务器会阻塞或放弃,从而避免超卖。
SETNX(Set if Not eXists)是 Redis 实现分布式锁的基础命令:
- 功能:如果 key 不存在,就设置 value;如果 key 已存在,就返回失败;
- 语义:"不存在就设置,存在就失败返回0",正好对应 "加锁成功 / 失败" 的逻辑。
- 加锁 :用
SETNX实现 "不存在则加锁",能拿到分布式锁的排他性;- 解锁 :用
DEL实现,但存在程序崩溃导致解锁失败 的问题:
- 即使把
DEL放在finally(Java)、RAII(C++)中,能解决进程内异常(如代码报错、逻辑崩溃);- 但无法解决进程外异常即分布式锁 (如服务器断电、内核崩溃、网络断连),此时
DEL完全无法执行,Redis 中的锁 Key 会永久存在,导致其他服务无法加锁,形成死锁。为了打破死锁,必须给锁 Key 加过期时间(TTL),即使服务崩溃,锁也会在超时后自动删除,释放资源。
禁止 "SETNX + EXPIRE" 分两次执行,必须SET key value NX EX ttl
Redis 中非事务 / 非脚本的多条命令不具备原子性,可能出现 "加锁成功,但设置过期时间失败" 的极端情况:
- 服务 A 执行
SETNX lock:ticket 1→ 加锁成功;- 服务 A 此时发生 GC 停顿 / 网络抖动 / 进程被杀死,
EXPIRE lock:ticket 5未执行;- 服务 A 后续崩溃,锁 Key 无过期时间,永久存在 → 死锁。
**问题一:**到这里很自然的会想到,如果执行业务逻辑的时间超过了超时时间呢?key-value被销毁了,那此时别的就会进来加锁,就可能超卖?那应该设多大的超时时间呢?
解决方案:看门狗(Watch Dog)机制
- 在 C++ 中启动一个后台线程 ,每隔
ttl/3秒(如 5 秒锁,每隔 1.5 秒),检查当前服务是否还持有锁;- 如果持有,就用
SET key value NX XX EX ttl命令原子续期 (XX:仅当 Key 存在时设置);- 若服务崩溃,后台线程停止,锁会在超时后自动释放,无死锁风险。
**问题二:**有可能别的服务器删除key-value呢???那锁直接没了,就可以进来加锁了,就可能超卖
解决方案:
"唯一标识 + Lua 脚本原子解锁":
- 加锁时 :给
value设置一个唯一标识 (如 C++ 生成的 UUID、进程 ID + 线程 ID),避免锁混淆;示例:SET lock:ticket "serverA_123" NX EX 5- 解锁时 :不能直接
DEL,而是用 Lua 脚本 原子判断 "锁的持有者是否是自己",只有匹配才删除:
Lua-- 解锁 Lua 脚本(C++ 中需嵌入) -- KEYS[1] = 锁Key,ARGV[1] = 唯一标识 if redis.call("GET", KEYS[1]) == ARGV[1] then return redis.call("DEL", KEYS[1]) else return 0 endLua 脚本在 Redis 中是原子执行的,避免 "判断持有者" 和 "删除" 的中间态。
为什么需要使用lua脚本,假设你的服务器是多线程,那就可以同时get,然后判断,然后get和del不是原子操作,就会导致a线程执行get,在执行del之前,b线程去get成功,但在bdel之前,别的服务器由于a线程释放锁了所以可以加锁,那么此时b去del就会导致锁被释放
归根结底:是因为get和del不是原子操作,所以必须使用lua脚本把命令组合起来,Lua 脚本中的所有命令,要么全部执行,要么全部不执行(Redis 执行脚本时不会被其他命令打断);
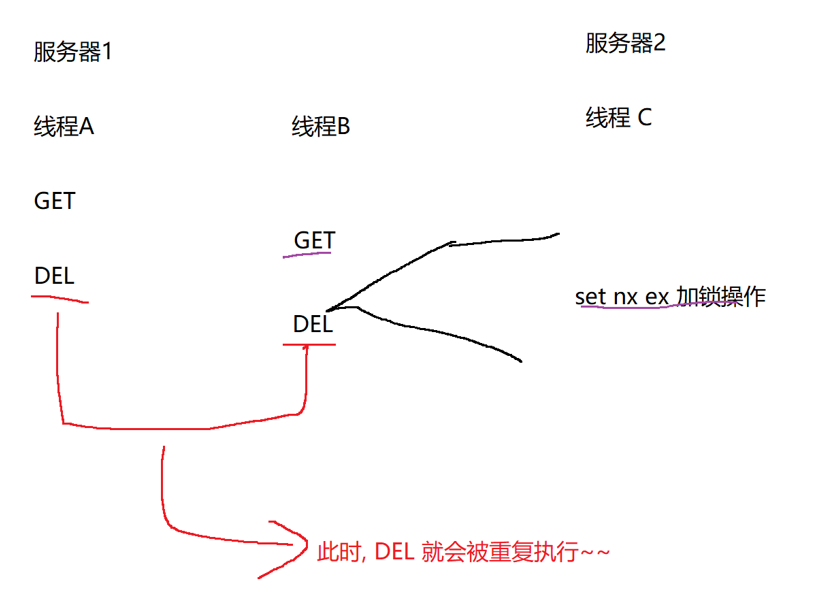
问题三:Redis 集群的 "主从延迟" 导致的锁丢失
- 服务 A 在主节点加锁成功;
- 主节点还没把 "锁 Key" 同步到从节点,主节点宕机;
- 哨兵把从节点升级为主节点,服务 B 在新主节点加锁成功 → 多服务同时持有锁。那就会出现超卖
解决方案(两种选型):
- Redlock 算法 :在多个独立的 Redis 主节点加锁,超过半数节点加锁成功才认为锁有效,同理解锁的时候也需要超过半数(Redis 官方方案,性能较低)
- 生产主流选型 :接受 "极小概率的锁丢失",结合业务兜底(如数据库唯一索引、库存扣减校验),因为 Redlock 性能开销大,且实际业务中 "主从切换 + 锁丢失" 的概率极低。
Redlock (仅金融级场景)
部署 5 个独立的 Redis 集群(而非独立节点),每个集群作为 Redlock 的一个 "节点":
- 加锁时,向 5 个集群的主节点加锁;
- 超过半数加锁成功,才认为锁有效;
- 解锁时同理。
- 效果:根治锁丢失问题;
- 代价:部署维护成本极高,性能极低(加锁需要访问 5 个集群)。
你需要部署多个独立的主节点,也就是有集群,每个集群都独立,所以这种算法性能很低
一般来说优先使用业务兜底,你需要自己写类似if语句去判断,而不是单单去防止锁丢失,使用redlock性能较低


更多的是阅读源码,看看redis是如何处理的