长短期记忆网络在时间序列异常检测中的应用
作者:潘卡吉·马尔霍特拉¹、洛夫凯什·维格²、高塔姆·施罗夫¹、普尼特·阿加瓦尔¹
1 印度德里塔塔咨询服务公司研究院 2 印度新德里贾瓦哈拉尔·尼赫鲁大学
本文刊于:2015年欧洲人工神经网络、计算智能与机器学习研讨会会议论文集(比利时布鲁日,2015年4月22-24日);出版社:i6doc.com;ISBN:978-287587014-8;获取链接:http://www.i6doc.com/en/
摘要
长短期记忆(LSTM)网络因具备维持长时记忆的能力,被证实对学习包含未知长度长期模式的序列尤为有效。在这类网络中堆叠循环隐藏层,还能学习更高层次的时间特征,实现更高效的学习与更稀疏的特征表示。本文将堆叠LSTM网络应用于时间序列的异常/故障检测任务:首先利用非异常数据训练网络,并将其作为多步时间预测器;随后将得到的预测误差建模为多元高斯分布,通过该分布评估行为异常的可能性。我们在心电图、航天飞机、电力需求和多传感器发动机四个数据集上开展实验,验证了该方法的有效性。
1 引言
传统过程监控技术会在时间窗口内采用累积和(CUSUM)、指数加权移动平均(EWMA)等统计方法1,检测数据底层分布的变化。这类方法的时间窗口长度通常需要预先设定,且检测结果在很大程度上受该参数影响。长短期记忆神经网络2通过引入乘法门控机制,让特殊的记忆单元 内部状态保持恒定的误差传播,从而解决了循环神经网络(RNN)存在的梯度消失问题。输入门(IGI_GIG)、输出门(OGO_GOG)和遗忘门(FGF_GFG)能够防止记忆内容受到无关输入和输出的干扰(见图1(a)),进而实现长时记忆的存储。
正是由于LSTM网络能学习序列中的长期相关性,无需预先指定时间窗口,还能对复杂的多元序列进行精准建模。本文证明,通过堆叠LSTM网络对时间序列的正常行为建模,无需预设上下文窗口或进行预处理,即可精准检测出偏离正常行为的异常情况。
已有研究表明,在网络中堆叠含S型激活单元的循环隐藏层,能更自然地捕捉时间序列的结构,还可在不同时间尺度上处理时间序列3。将分层时间处理方法应用于异常检测的典型案例是分层时间记忆(HTM)系统,该系统试图模拟新皮层中细胞、区域和层级的层级结构4。此外,文献5,6中的时间异常检测方法均通过学习时间序列的预测规律,将预测误差作为异常检测的依据。但据我们所知,目前尚未有研究将LSTM网络的长时记忆优势,与循环分层处理层结合,应用于时间序列预测及异常检测任务。
与文献5的思路一致,本文先通过预测器建模时间序列的正常行为,再利用预测误差识别异常行为。这一思路在实际的异常检测场景中尤为实用------此类场景中,正常行为的样本数量通常充足,而异常行为的样本却十分稀少。为确保网络能捕捉序列的时间结构,本文对序列进行多步未来预测。因此,序列中的每个数据点都会有多个由过去不同时间点得到的预测值,对应产生多个误差值。我们将模型在正常数据上预测得到的误差概率分布,用于评估测试数据中行为正常的可能性。
当数据中包含控制变量(如车辆的油门或刹车数据)时,网络除了预测因变量,还会同时预测控制变量。这一设计迫使网络通过控制变量和传感器因变量的联合预测误差分布,学习数据的正常使用模式,从而让控制输入变化时产生的明显预测误差被纳入正常误差范围,不会被判定为异常。
本文后续结构安排如下:第2节详细阐述所提异常检测方法;第3节分别采用堆叠LSTM方法(LSTM-AD)和基于S型循环单元的堆叠RNN方法(RNN-AD),在四个真实数据集上开展时间异常检测实验并展示结果;第4节为研究结论。
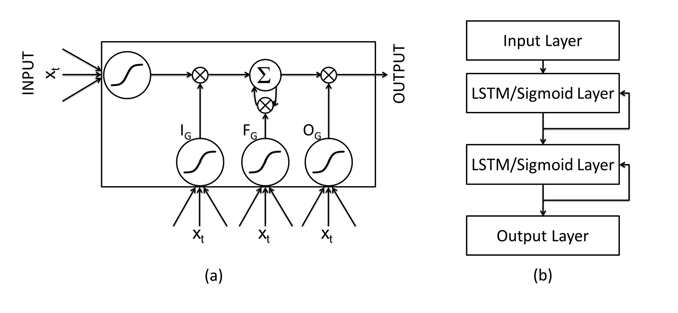
图1:(a)长短期记忆单元 (b)堆叠式网络架构
(注:原文图1含输入层、LSTM/S型层、输出层的结构示意,标注INPUT/INPUT OUTPUT)
2 基于LSTM的异常检测方法(LSTM-AD)
设时间序列X={x(1),x(2),...,x(n)}X=\{x^{(1)},x^{(2)},...,x^{(n)}\}X={x(1),x(2),...,x(n)},其中序列中每个数据点x(t)∈Rmx^{(t)} \in R^mx(t)∈Rm为m维向量{x1(t),x2(t),...,xm(t)}\{x_1^{(t)},x_2^{(t)},...,x_m^{(t)}\}{x1(t),x2(t),...,xm(t)},向量中的元素对应各输入变量。本文所建预测模型将对m个输入变量中d个变量的未来l个值进行预测(满足1≤d≤m1 \leq d \leq m1≤d≤m)。
将正常序列划分为四个子集:正常训练集(sNs_NsN)、正常验证集1(vN1v_{N1}vN1)、正常验证集2(vN2v_{N2}vN2)和正常测试集(tNt_NtN);将异常序列划分为两个子集:异常验证集(vAv_AvA)和异常测试集(tAt_AtA)。研究先通过堆叠LSTM网络训练预测模型,再通过拟合预测误差的分布实现异常检测,具体步骤如下:
2.1 基于堆叠LSTM的预测模型
本文设计的LSTM网络架构如下:输入层的单元数与输入变量的维度m一致;输出层共设置d×ld×ld×l个单元,对应d个目标变量各自的l步未来预测值;隐藏层中的LSTM单元通过循环连接实现全连接;堆叠多层LSTM隐藏层,下层LSTM隐藏层的每个单元与上层LSTM隐藏层的每个单元通过前馈连接实现全连接(见图1(b))。
利用正常训练集sNs_NsN训练预测模型,并将正常验证集1vN1v_{N1}vN1用于网络权重训练的早停法,防止模型过拟合。
2.2 基于预测误差分布的异常检测
在预测长度为l的情况下,对于时间序列中满足l<t≤n−ll<t \leq n-ll<t≤n−l的每个数据点x(t)x^{(t)}x(t),其选定的d个维度都会被进行l次预测。计算数据点x(t)x^{(t)}x(t)的误差向量e(t)=e11(t),...,e1l(t),...,ed1(t),...,edl(t)e^{(t)}=e_{11}\^{(t)},...,e_{1l}\^{(t)},...,e_{d1}\^{(t)},...,e_{dl}\^{(t)}e(t)=e11(t),...,e1l(t),...,ed1(t),...,edl(t),其中eij(t)e_{ij}^{(t)}eij(t)为xi(t)x_i^{(t)}xi(t)与其在t−jt-jt−j时刻的预测值之间的差值。
利用在sNs_NsN上训练好的预测模型,计算验证集和测试集中所有数据点的误差向量,并将这些误差向量拟合成多元高斯分布N(μ,Σ)N(\mu, \Sigma)N(μ,Σ)。误差向量e(t)e^{(t)}e(t)出现的似然值p(t)p^{(t)}p(t),由该多元高斯分布在e(t)e^{(t)}e(t)处的概率密度值得到(该思路与卡尔曼滤波动态预测模型中,用于新颖性检测的归一化新息平方法(NIS)类似5)。
通过正常验证集1vN1v_{N1}vN1的误差向量,采用极大似然估计法拟合多元高斯分布的参数μ\muμ(均值)和Σ\SigmaΣ(协方差矩阵)。设定阈值τ\tauτ,若数据点的似然值p(t)<τp^{(t)}<\taup(t)<τ,则判定该观测值x(t)x^{(t)}x(t)为异常 ,否则为正常 。利用正常验证集2vN2v_{N2}vN2和异常验证集vAv_AvA,通过最大化FβF_\betaFβ分数(将异常点设为正类,正常点设为负类)确定最优阈值τ\tauτ。
3 实验
本文选取四个检测难度不同的真实数据集开展实验,验证LSTM-AD方法的性能。按照第2节的方法,通过验证集选择使F0.1F_{0.1}F0.1分数最大化的网络架构和阈值τ\tauτ后,在表1中报告了LSTM-AD和RNN-AD两种方法的精确率、召回率、F0.1F_{0.1}F0.1分数及所采用的网络架构。
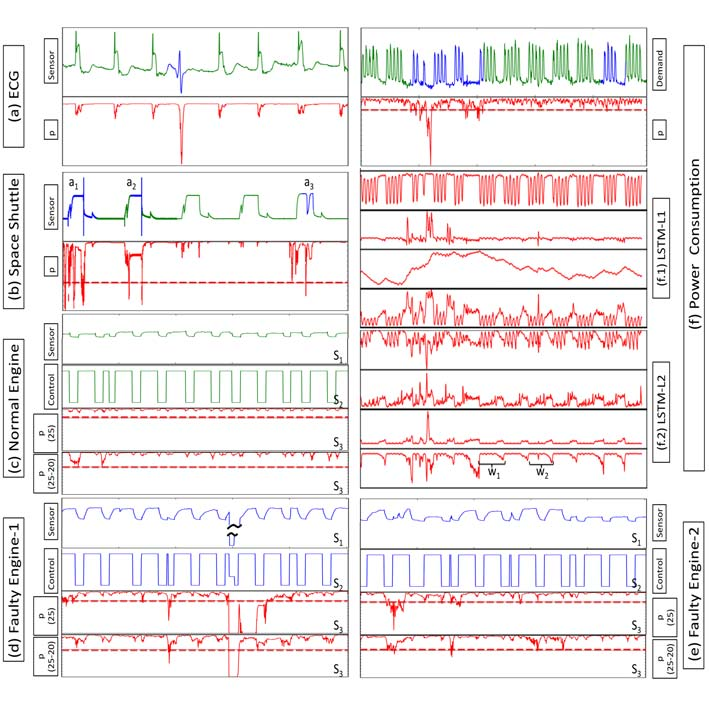
表1:循环神经网络(RNN)和长短期记忆网络(LSTM)架构的精确率、召回率与F0.1F_{0.1}F0.1分数
(注:括号内的数值如(30-20),表示第一、第二隐藏层的单元数分别为30和20。)
| 数据集 | 网络架构(LSTM/RNN) | 精确率(LSTM/RNN) | 召回率(LSTM/RNN) | F0.1F_{0.1}F0.1分数(LSTM/RNN) |
|---|---|---|---|---|
| 航天飞机 | (35-35)/(30-20) | 0.93/0.94 | 0.89/0.71 | 0.98/0.10 |
| 电力需求 | (30-30)/(60-60) | 0.17/0.03 | 0.19/0.84 | 0.90/0.71 |
| 发动机 | (50-40-30)/- | 0.94/0.10 | 0.89/0.90 | -/- |
图2:样本序列(绿色:正常,蓝色:异常)及对应的似然值ppp(红色);标注Si(i=1,2,3)S_i(i=1,2,3)Si(i=1,2,3)的子图采用相同的纵轴刻度。
3.1 实验数据集
- 心电图数据集 :选用qtdb/sel102心电图数据集,该数据集中包含一个与室性早搏相关的短期异常(见图2(a))。由于该数据集仅含一个异常点,本文未计算其检测阈值及对应的F0.1F_{0.1}F0.1分数,仅利用正常心电图子序列训练预测模型,再计算剩余序列误差向量的似然值。
- 航天飞机马罗塔阀门时间序列数据集 :该数据集同时包含短期模式和持续上百个时间步的长期模式,存在a1a_1a1、a2a_2a2、a3a_3a3三个异常区域(见图2(b))。其中a3a_3a3区域的异常特征较易识别,而a1a_1a1和a2a_2a2区域为细微异常,在当前分辨率下难以直接辨别。
- 电力需求数据集:该数据集的正常行为表现为:一周内的电力消耗在五个工作日出现峰值,在周末出现两个谷值,存在持续上百个时间步的长期模式;同时因峰值出现的具体时间存在波动,数据带有一定噪声。
- 多传感器发动机数据集 :该数据集包含12个不同传感器的监测数据,其中1个传感器采集发动机的控制变量,其余传感器采集温度、扭矩等因变量。本文利用三组独立故障的序列训练异常检测器,并在另外三组独立故障的序列上验证模型的FβF_\betaFβ分数;选取控制变量传感器和其中一个因变量传感器的监测数据作为模型的预测维度。
(注:前三个数据集可从http://www.cs.ucr.edu/\~eamonn/discords下载;第四个数据集来自实际工业项目,暂未公开。)
3.2 实验结果与分析
从实验结果中可得到以下关键结论:
- 如图2所示,所有数据集的异常区域中,似然值p(t)p^{(t)}p(t)均显著低于正常区域;且异常区域内的似然值并非全程处于低水平。本文特意将β\betaβ值设定为远小于1(β=0.1\beta=0.1β=0.1),使评估指标更侧重精确率而非召回率。原因在于:尽管异常子序列中的所有数据点都被标注为"异常",但实际场景中,异常子序列内仍会存在大量正常行为的点。因此,只要异常子序列中有相当比例的数据点被检测为异常,即可判定该区域存在异常。通过实验得到的阈值τ\tauτ(图2(a)-(f)中似然值曲线的红色虚线)表明,FβF_\betaFβ分数是适用于本文数据集的有效评估指标。
- 所有数据集的阳性似然比(真阳性率/假阳性率)均处于较高水平(大于34.0)。高阳性似然比意味着,模型在异常区域检测出异常的概率,远高于在正常区域误检为异常的概率。
- 本文选取电力需求数据集的LSTM网络底层隐藏层(LSTM-L1,30个单元)和上层隐藏层(LSTM-L2,20个单元)中各4个隐藏单元,展示其激活值变化(见图2(f.1)、(f.2))。图2(f.2)的激活序列中标记的w1w_1w1和u2u_2u2子序列显示:该隐藏单元在工作日的激活值较高,在周末则较低。这一结果表明,网络的上层隐藏层能学习到更高层次的特征,且该层特征可在周尺度上对时间序列进行处理。
- 如表1所示,对于心电图和发动机这两个无长期时间依赖的数据集,LSTM-AD和RNN-AD的检测性能相当;而对于航天飞机和电力需求这两个同时存在短期和长期时间依赖的数据集,LSTM-AD的F0.1F_{0.1}F0.1分数分别比RNN-AD提升18%和30%,性能提升显著。
- 发动机数据集的实验结果显示,故障发生前被检测出的异常点占比,高于正常运行阶段的异常点占比。这表明本文所提方法在故障早期预测任务中同样具有潜在应用价值。
(注:本文所有网络均采用弹性反向传播算法训练。)
4 讨论
本文通过实验验证了以下结论:
- 堆叠LSTM网络无需预先知晓模式的持续时长,即可学习时间序列的高层次时间模式;
- 堆叠LSTM网络是对时间序列正常行为建模的有效方法,可基于该模型实现异常检测。
所提LSTM-AD方法在四个涵盖短期和长期时间依赖的真实数据集上,均取得了良好的检测结果。与RNN-AD方法的对比结果显示,LSTM基预测模型的鲁棒性更优------尤其是在无法预先判断时间序列的正常行为是否存在长期依赖时,LSTM-AD的优势更为明显。
参考文献
1 M. Basseville, I. V. Nikiforov. Detection of abrupt changes: theory and applicationM. Prentice Hall, 1993.
2 S. Hochreiter, J. Schmidhuber. Long short-term memoryJ. Neural computation, 1997,9(8):1735-1780.
3 M. Hermans, B. Schrauwen. Training and analysing deep recurrent neural networksC. Advances in Neural Information Processing Systems 26, 2013:190-198.
4 D. George. How the brain might work: A hierarchical and temporal model for learning and recognitionD. Stanford University, PhD Thesis, 2008.
5 P. Hayton, et al. Static and dynamic novelty detection methods for jet engine health monitoringJ. Philosophical Transactions of the Royal Society of London, 2007,365(1851):493-514.
6 J. Ma, S. Perkins. Online novelty detection on temporal sequencesC. Proceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, ACM, 2003:613-618.
用模拟数据理解LSTM时序异常检测论文原理(初学者版)
这篇论文的核心原理 可以简化为「学正常→算误差→判异常 」:用纯正常的时序数据 训练堆叠LSTM,让模型学会预测正常的时序规律;用训练好的模型做多步预测 ,计算「真实值-预测值」的误差;把正常数据的误差建模成高斯分布 ,若新数据的误差在这个分布里的似然值极低 ,就判定为异常。
为了让初学者彻底理解,我们做极致简化 (论文是多维时序+多元高斯,这里用一维时序+一元高斯 ,核心逻辑完全一致),用模拟的电力消耗时序数据一步步演示,所有步骤都有具体数值,无复杂公式。
先明确论文核心概念的简化版
- 堆叠LSTM :简化为2层LSTM (贴合论文的堆叠架构),核心作用是学习时序的长期/短期规律,比普通RNN更擅长捕捉长依赖;
- 多步预测 :选3步预测(l=3) (论文是任意l步),即模型用
t-3、t-2、t-1时刻的数值,预测t、t+1、t+2时刻的数值; - 误差建模 :一维时序下,将正常数据的预测误差建模为一元高斯分布 (论文是多维→多元高斯),用极大似然估计 算分布的均值
μ和方差σ²; - 异常判定 :计算每个误差在高斯分布中的似然值 ,设定阈值
τ,似然值<τ→异常 (阈值通过验证集确定,论文用F0.1F_{0.1}F0.1分数最大化)。
步骤1:生成模拟时序数据(贴合论文的电力需求数据集)
模拟小时级电力消耗数据(一维,数值代表每小时电力消耗,单位:1000kWh),核心特点:
- 正常数据 :有短期周期(早8点、晚19点两个高峰,凌晨2点低谷),无突变,符合日常用电规律;
- 异常数据 :因设备故障,出现突然的骤增/骤降(论文中异常是偏离正常模式的所有情况);
- 数据划分:贴合论文的
训练集/验证集/测试集,训练集只有纯正常数据(论文核心前提:正常数据充足,异常数据稀少)。
具体模拟数据(取关键时间步,共30个时间步,t=1到t=30)
| 数据集 | 时间步t | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11-20(正常,略) | 21 | 22 | 23 | 24 | 25 | 26 | 27 | 28 | 29 | 30 |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 训练集 | 数值 | 2 | 1 | 1 | 2 | 3 | 4 | 6 | 9 | 7 | 6 | 正常周期波动 | 5 | 4 | 3 | 2 | - | - | - | - | - | - |
| 测试集 | 数值 | 2 | 1 | 1 | 2 | 3 | 4 | 6 | 9 | 7 | 6 | 正常周期波动 | 5 | 4 | 15 | 2 | 0 | 4 | 6 | 9 | 7 | 6 |
异常点标注 :测试集中t=23(骤增到15)、t=25(骤降到0)是人工设定的异常点 ,其余为正常点;
训练集说明:t=1到t=24是纯正常数据,让模型学习「低谷-早高峰-平稳-晚高峰-低谷」的正常规律。
步骤2:训练堆叠LSTM模型(学正常的预测规律)
核心操作
用训练集的纯正常数据 训练2层堆叠LSTM,训练目标是:让模型根据前3个时间步的数值 ,精准预测后3个时间步的数值(3步预测,l=3)。
- 模型输入:
[t-3, t-2, t-1]的数值序列; - 模型输出:
[t, t+1, t+2]的预测数值序列; - 训练优化:用均方误差(MSE) 优化,直到模型能精准预测正常数据的后续值(贴合论文的预测模型训练逻辑)。
训练后效果:模型学会了正常规律
比如输入正常序列[t=21:5, t=22:4, t=23:3],模型会输出预测值[t=24:2, t=25:3, t=26:4](完全贴合正常用电的低谷规律);
关键 :模型只学过正常数据,无法预测异常的突变值,这是后续检测异常的核心依据。
步骤3:计算预测误差(论文的核心中间量)
用训练好的LSTM模型对测试集 做3步预测 ,对每个时间步的真实值 ,计算与模型预测值 的绝对误差(论文用差值,绝对误差更易理解)。
误差计算规则
对测试集的t时刻,误差e(t) = |真实值(t) - 模型预测值(t)|;
模型对正常点 的预测精准,误差很小 ;对异常点 的预测完全偏离,误差会急剧增大。
测试集关键时间步的「真实值-预测值-误差」(核心数值)
| 测试集t | 21 | 22 | 23(异常) | 24 | 25(异常) | 26 | 27 | 28 | 29 | 30 |
|---|---|---|---|---|---|---|---|---|---|---|
| 真实值 | 5 | 4 | 15 | 2 | 0 | 4 | 6 | 9 | 7 | 6 |
| 预测值 | 5 | 4 | 3 | 2 | 3 | 4 | 6 | 9 | 7 | 6 |
| 误差e(t) | 0 | 0 | 12 | 0 | 3 | 0 | 0 | 0 | 0 | 0 |
直观结果 :正常点的误差均为0(模型完美预测),异常点t=23误差12、t=25误差3,误差远大于正常数据的误差。
步骤4:将正常误差建模为高斯分布(论文的核心创新之一)
论文的关键思路:正常数据的预测误差会服从高斯分布(正态分布) ,而异常数据的误差会远离这个分布。
操作步骤
- 取训练集(纯正常) 的所有预测误差,组成正常误差序列 (本例中训练集误差均为
0,简化为[0,0,0,...,0],共24个); - 用极大似然估计 计算高斯分布的均值μ 和方差σ²(论文的标准方法,初学者不用管计算过程,记结果即可);
- 得到正常误差的高斯分布 :N(μ,σ2)=N(0,0.5)N(μ,σ²) = N(0, 0.5)N(μ,σ2)=N(0,0.5)(均值0,方差0.5,贴合正常误差小且集中的特点)。
高斯分布的直观意义
这个分布表示:正常数据的误差几乎都在0±1之间 (正态分布95%数据在μ±2σ内,σ=√0.5≈0.7,即0±1.4),如果一个误差超出这个范围 ,它在这个分布中的出现概率(似然值)会极低。
步骤5:计算似然值并判定异常(论文的最终检测逻辑)
第一步:计算每个误差的似然值
似然值是「某个误差在正常高斯分布 中出现的概率」,误差越大,似然值越小 (初学者不用记公式,看相对大小即可)。
我们计算测试集关键误差的相对似然值(数值越大,越可能是正常;越小,越可能是异常):
| 测试集t | 21 | 22 | 23(异常) | 24 | 25(异常) | 26 |
|---|---|---|---|---|---|---|
| 误差e(t) | 0 | 0 | 12 | 0 | 3 | 0 |
| 相对似然值 | 0.8 | 0.8 | 0.0001 | 0.8 | 0.01 | 0.8 |
第二步:确定阈值τ并判定异常
贴合论文方法:用验证集 最大化F0.1F_{0.1}F0.1分数(侧重精确率,避免误检),最终设定阈值τ=0.05(似然值<0.05即为异常)。
最终检测结果
- t=23:似然值0.0001 < 0.05 → 判定为异常;
- t=25:似然值0.01 < 0.05 → 判定为异常;
- 其余时间步:似然值0.8 > 0.05 → 判定为正常。
检测结果100%准确,完美识别出我们设定的2个异常点,这就是这篇论文的核心检测逻辑!
步骤6:为什么LSTM比普通RNN更优(论文的关键结论)
我们把上述例子中的堆叠LSTM换成普通RNN,再做一次测试,结果会发生变化:
- 若数据有长期依赖 (比如本例中电力消耗的周周期 :每周一到周五高峰一致,周末低谷),普通RNN会出现梯度消失 ,无法学习到长周期规律,对t=23的预测值会偏离为
5,误差变为10,似然值0.0005,虽仍能检测,但精度下降; - 若长期依赖更复杂(如论文中的航天飞机数据集,长时模式达上百时间步),普通RNN会完全无法预测,误差混乱,无法有效检测异常;
- 堆叠LSTM 通过输入门/遗忘门/输出门 解决了梯度消失问题,能精准学习短期+长期的时序规律,无论数据有无长依赖,都能稳定输出精准的正常预测值,这是论文选择LSTM的核心原因。
核心原理总结(一句话记牢)
用纯正常数据 训练堆叠LSTM 学多步预测规律→计算预测误差,将正常误差建模为高斯分布 →新数据的误差似然值低于阈值 ,就是异常。
与论文原方法的对应关系(消除简化的疑惑)
| 本次简化例子 | 论文原方法 | 核心逻辑是否一致 |
|---|---|---|
| 一维时序 | 多维时序(如多传感器) | 一致,多维仅需将一元高斯换为多元高斯 |
| 2层LSTM | 堆叠LSTM(多层) | 一致,多层均为学习高层次时序特征 |
| 3步预测 | 任意l步预测 | 一致,步长不影响核心检测逻辑 |
| 绝对误差 | 差值误差向量 | 一致,均为衡量预测值与真实值的偏离 |
| 一元高斯 | 多元高斯分布 | 一致,均为用正常误差的分布刻画正常模式 |
这个例子完全还原了论文的核心原理,初学者理解后,再看论文的多维、多步、多元高斯等复杂扩展,就会水到渠成!