基础环境版本:hadoop 3.3.4 + hive3.1.3 + tez0.9.2
使用的jdk环境需为1.8(hadoop、yarn、hive都需要1.8),需要启动HDFS、YARN.
1. 下载 tez-0.9.2安装包并解压,并配置环境变量
powershell
export JAVA_HOME=/opt/jdk1.8.0_471
export PATH=$JAVA_HOME/bin:$PATH
export HADOOP_HOME=/opt/hadoop-3.3.4
export CLASS_PATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native
export ZOOKEEPER_HOME=/opt/zookeeper-3.8.4
export HIVE_HOME=/opt/apache-hive-3.1.3-bin
export TEZ_HOME=/opt/apache-tez-0.9.2-bin
export TEZ_CONF_DIR=/opt/apache-tez-0.9.2-bin/conf
export HADOOP_CLASSPATH==$HADOOP_CLASSPATH:$TEZ_CONF:$TEZ_HOME/lib/*:$TEZ_HOME/*
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin:$ZOOKEEPER_HOME/bin:$HIVE_HOME/bin:$TEZ_HOME2. 上传tez到hdfs
powershell
cd /opt/apache-tez-0.9.2-bin/share
#解压 tez.tar/gz
tar -zxvf tez.tar.gz
#删除里面的sl4j日志包
rm -f lib/slf4j-log4j12-1.7.10.jar
#重新打包tez.tar.gz,先删除就得tez.tar.gz
tar -zcvf tez.tar.gz /opt/apache-tez-0.9.2-bin/share
#上传到hdfs
hadoop fs -mkdir /user/tez
hadoop fs -put tez.tar.gz /user/tez
#授权,保证所有用户可以访问
hadoop fs -chmod -R 777 /user/tez3. 配置tez-site.xml (注意是中划线)
在hive的conf目录下创建tez-site.xml,添加如下内容(根据实际情况修改ip及路径)。
xml
<configuration>
<!-- 指定在hdfs上的tez包文件 -->
<property>
<name>tez.lib.uris</name>
<value>hdfs://ip:9000/user/tez/tez.tar.gz</value>
</property>
<!-- 使用集群Hadoop库减少部署包大小 -->
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>
<!-- Native库路径配置 -->
<property>
<name>tez.am.launch.cluster-default.env</name>
<value>LD_LIBRARY_PATH=/opt/hadoop-3.3.4/lib/native</value>
</property>
</configuration>同时在hadoop每个节点目录下的etc/hadoop下,创建tez-site.xml
4. hive-site.xml 调整
xml
<!--指定hive引擎 -->
<property>
<name>hive.execution.engine</name>
<value>tez</value>
</property>
<!--指定tez的jar目录 -->
<property>
<name>tez.lib.uris</name>
<value>hdfs://ip:9000/user/tez/tez.tar.gz</value>
</property>
<property>
<name>tez.conf.dir</name>
<value>/opt/apache-tez-0.9.2-bin/conf</value>
</property>
<!-- Hadoop3.x 必配:复用集群Hadoop依赖,避免包冲突 -->
<property>
<name>tez.use.cluster.hadoop-libs</name>
<value>true</value>
</property>5. hive-env.sh
添加如下内容
powershell
export JAVA_HOME=/opt/jdk1.8.0_471
export TEZ_HOME=/opt/apache-tez-0.9.2-bin/
export TEZ_JARS=""
for jar in `ls $TEZ_HOME |grep jar`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/$jar
done
for jar in `ls $TEZ_HOME/lib`; do
export TEZ_JARS=$TEZ_JARS:$TEZ_HOME/lib/$jar
done6. yarn-site.xml 配置
xml
<property>
<name>yarn.resourcemanager.proxy.api.enable</name>
<value>true</value>
</property>
<!-- 2. 配置AM动态端口范围 -->
<property>
<name>yarn.app.mapreduce.am.job.client.port-range</name>
<value>30000-40000</value>
</property>
<!-- 3. 绑定IPv4 -->
<property>
<name>yarn.resourcemanager.address</name>
<value>0.0.0.0:8032</value>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>2048</value>
</property>7. mapred-site.xml
修改 mapreduce.framework.name 为 yarn-tez
xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn-tez</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.4</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.4</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/hadoop-3.3.4</value>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
/opt/hadoop-3.3.4/etc/hadoop,
/opt/hadoop-3.3.4/share/hadoop/common/*,
/opt/hadoop-3.3.4/share/hadoop/common/lib/*,
/opt/hadoop-3.3.4/share/hadoop/hdfs/*,
/opt/hadoop-3.3.4/share/hadoop/hdfs/lib/*,
/opt/hadoop-3.3.4/share/hadoop/mapreduce/*,
/opt/hadoop-3.3.4/share/hadoop/mapreduce/lib/*,
/opt/hadoop-3.3.4/share/hadoop/yarn/*,
/opt/hadoop-3.3.4/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>8. hadoop-env.sh 添加 export JAVA_HOME=/opt/jdk1.8.0_471
9. 修改 example.sh
在/opt/hadoop-3.3.4/etc/hadoop/shellprofile.d/example.sh 添加如下内容
powershell
hadoop_add_profile tez
function _tez_hadoop_classpath
{
hadoop_add_classpath "$HADOOP_HOME/etc/hadoop" after
hadoop_add_classpath "/opt/apache-tez-0.9.2-bin/*" after
hadoop_add_classpath "/opt/apache-tez-0.9.2-bin/lib/*" after
}10. 验证tez和yarn
powershell
hadoop jar /opt/apache-tez-0.9.2-bin/tez-examples-0.9.2.jar orderedwordcount /tez/test/input /tez/test/output1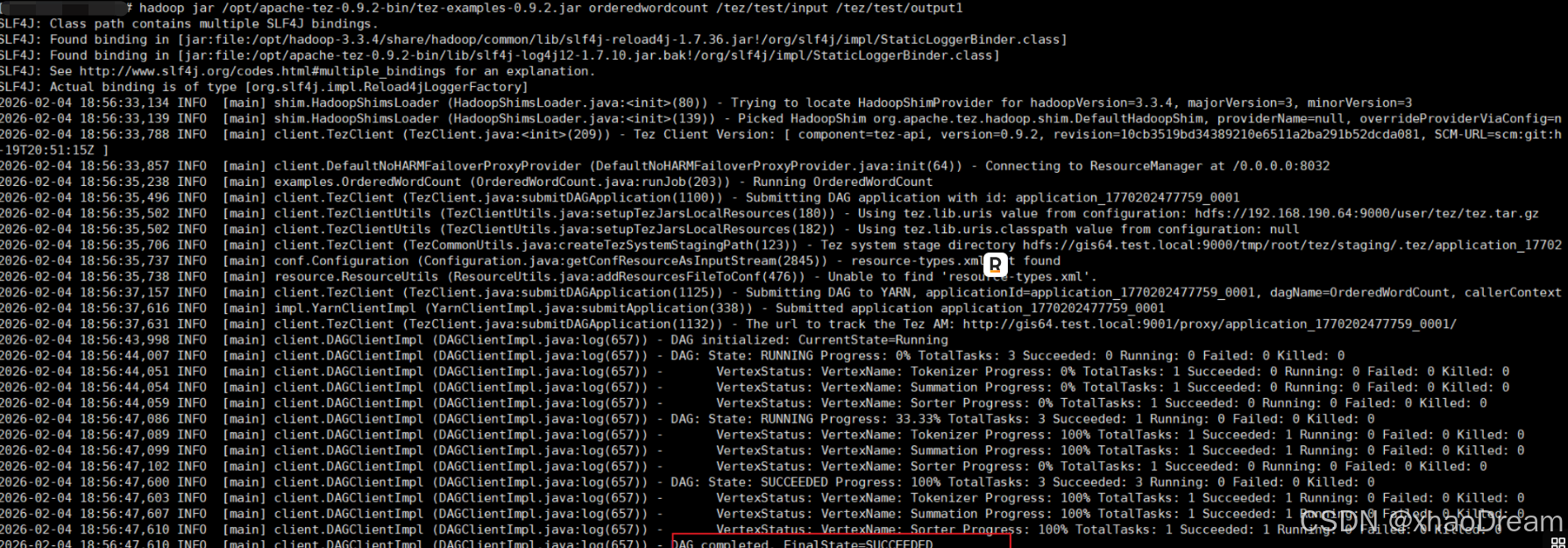
Hadoop 目录 /tez/test/output1 有输出结果
11. 验证hive
启动hive
powershell
nohup hive --service metastore > /opt/apache-hive-3.1.3-bin/log/metastore.log 2>&1 &
nohup hive --service hiveserver2 > /opt/apache-hive-3.1.3-bin/log/hiveServer2.log 2>&1 &
powershell
beeline -u jdbc:hive2://IP:10000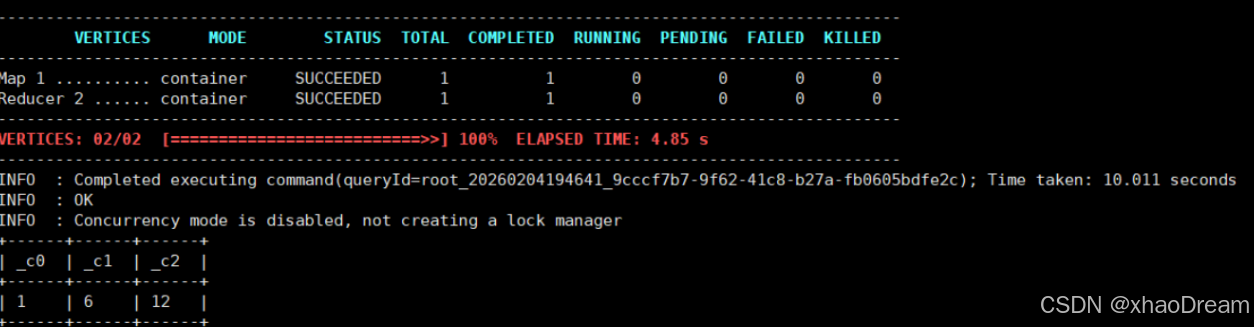
部署成功。