【运维开发实战】从0到1搭建半导体初创公司内网智能知识库与运维助手
目录
- [1. 引言:从Nginx端口占用说起,我们为什么需要这个项目](#1. 引言:从Nginx端口占用说起,我们为什么需要这个项目)
- [2. 现状痛点:半导体初创公司运维的三大核心难题](#2. 现状痛点:半导体初创公司运维的三大核心难题)
- [2.1 故障排查效率低下:Nginx端口占用的惊魂时刻](#2.1 故障排查效率低下:Nginx端口占用的惊魂时刻)
- [2.2 知识沉淀缺失:员工不爱写文档,经验随人流失](#2.2 知识沉淀缺失:员工不爱写文档,经验随人流失)
- [2.3 新人上手困难:IP与服务器映射混乱,架构认知成本高](#2.3 新人上手困难:IP与服务器映射混乱,架构认知成本高)
- [3. 方案设计:内网智能知识库+AI运维助手的一体化架构](#3. 方案设计:内网智能知识库+AI运维助手的一体化架构)
- [3.1 核心定位:做公司的"数字大脑"与"知识管家"](#3.1 核心定位:做公司的“数字大脑”与“知识管家”)
- [3.2 技术栈选型:为什么选择Coze+本地大模型而非纯API](#3.2 技术栈选型:为什么选择Coze+本地大模型而非纯API)
- [3.3 整体架构图:数据层-能力层-应用层的三层闭环](#3.3 整体架构图:数据层-能力层-应用层的三层闭环)
- [4. MVP落地:我们已经完成的最小可行产品](#4. MVP落地:我们已经完成的最小可行产品)
- [4.1 前端交互页面:内网运维助手的可视化入口](#4.1 前端交互页面:内网运维助手的可视化入口)
- [4.2 后端工具脚本:CPU与内存查询的实时数据链路](#4.2 后端工具脚本:CPU与内存查询的实时数据链路)
- [4.3 核心价值验证:从"只能查指标"到"能解决问题"的跨越](#4.3 核心价值验证:从“只能查指标”到“能解决问题”的跨越)
- [5. 近期迭代:30天内完成的核心功能升级](#5. 近期迭代:30天内完成的核心功能升级)
- [5.1 服务器信息库:解决IP与服务器映射混乱的痛点](#5.1 服务器信息库:解决IP与服务器映射混乱的痛点)
- [5.2 端口与日志查询工具:精准定位Nginx启动失败等核心故障](#5.2 端口与日志查询工具:精准定位Nginx启动失败等核心故障)
- [5.3 自动文档生成:解决"不爱写文档"的流程化方案](#5.3 自动文档生成:解决“不爱写文档”的流程化方案)
- [6. 中长期规划:从智能助手到企业级可观测性平台](#6. 中长期规划:从智能助手到企业级可观测性平台)
- [6.1 与现有日志监控平台融合:让AI拥有"全链路视角"](#6.1 与现有日志监控平台融合:让AI拥有“全链路视角”)
- [6.2 告警自动诊断:从"被动告警"到"主动排障"](#6.2 告警自动诊断:从“被动告警”到“主动排障”)
- [6.3 权限与安全体系:满足企业级合规要求的分级管控](#6.3 权限与安全体系:满足企业级合规要求的分级管控)
- [7. 总结与思考:用最小成本撬动最大价值的初创实践](#7. 总结与思考:用最小成本撬动最大价值的初创实践)
1. 引言:从Nginx端口占用说起,我们为什么需要这个项目
前段时间,公司发生了一起典型的运维事故:Nginx服务器因端口被占用无法启动,运维团队花了近1小时才定位到是某个未记录的Java进程占用了80端口。幸运的是当时业务量不大,未造成严重影响,但这暴露了我们在故障排查、知识沉淀和新人上手方面的深层问题。
作为半导体初创公司,我们正处于快速迭代期,核心痛点集中在三个方面:故障排查效率低下、知识沉淀缺失、新人上手困难。本文将详细讲述我们如何从0到1搭建内网智能知识库与AI运维助手,通过MVP验证、迭代升级,最终解决这些核心问题,为企业级应用提供完整的可观测性与智能运维解决方案。
2. 现状痛点:半导体初创公司运维的三大核心难题
2.1 故障排查效率低下:Nginx端口占用的惊魂时刻
- 问题场景 :Nginx启动失败,报错"端口已被占用",运维团队需要手动执行
lsof、netstat等命令排查,耗时久且易出错。 - 核心影响:在业务高峰期,此类问题可能导致服务中断,造成不可估量的损失。
- 根本原因:缺乏实时数据查询与智能诊断能力,依赖人工经验排查,效率低下。
2.2 知识沉淀缺失:员工不爱写文档,经验随人流失
- 问题场景:员工解决问题后,很少主动编写文档,导致相同问题反复出现,新人接手时需要重新摸索。
- 核心影响:知识资产随人员流动流失,团队协作成本高,故障复现排查难度大。
- 根本原因:文档编写门槛高,缺乏流程化的知识沉淀机制。
2.3 新人上手困难:IP与服务器映射混乱,架构认知成本高
- 问题场景:实习生和新员工需要花费数周时间才能理清公司服务器IP与业务的对应关系,理解微服务架构。
- 核心影响:新人上手周期长,老员工需要花费大量时间答疑,影响核心工作效率。
- 根本原因:缺乏统一的内网知识库,信息分散在个人笔记和聊天记录中,无标准化入口。
3. 方案设计:内网智能知识库+AI运维助手的一体化架构
3.1 核心定位:做公司的"数字大脑"与"知识管家"
我们的项目定位为内网智能知识库+AI运维助手,核心使命是:
- 数字大脑:通过本地大模型与智能体,实现故障智能诊断、方案自动生成;
- 知识管家:沉淀公司运维经验与架构信息,解决"不爱写文档""新人上手慢"的痛点;
- 安全底座:全程内网部署,保障半导体公司核心数据安全。
3.2 技术栈选型:为什么选择Coze+本地大模型而非纯API
| 技术方案 | 优势 | 劣势 |
|---|---|---|
| 纯前后端API规则 | 实现简单,适合固定场景 | 覆盖能力有限,无法处理复杂自然语言需求 |
| 外网大模型API | 智能能力强,无需部署 | 数据安全风险高,不符合企业合规要求 |
| Coze开源版+本地大模型 | 私有化部署、智能能力强、开发成本低 | 需要基础部署配置 |
核心选型逻辑:我们选择Coze开源版作为智能体框架,搭配Ollama部署的DeepSeek-R1:8b本地大模型,既满足了数据安全要求,又通过可视化配置降低了开发复杂度,让我们能聚焦于业务价值实现。
3.3 整体架构图:数据层-能力层-应用层的三层闭环
┌─────────────────┐ ┌─────────────────┐ ┌─────────────────┐
│ 应用层 │ │ 能力层 │ │ 数据层 │
│ - 前端交互页面 │────▶│ - Coze 智能体 │────▶│ - 本地工具脚本 │
│ - 文档上传入口 │ │ - 本地大模型 │ │ - 运维知识库 │
│ - 新人引导模块 │ │ - 工具编排引擎 │ │ - 日志 / 监控数据│
└─────────────────┘ └─────────────────┘ └─────────────────┘
- 数据层:提供实时数据(脚本查询)与历史数据(日志/监控);
- 能力层:Coze负责意图理解、工具调用与知识检索,大模型负责推理与自然语言生成;
- 应用层:前端页面提供用户交互入口,支持自然语言提问、文档上传与新人引导。
4. MVP落地:我们已经完成的最小可行产品
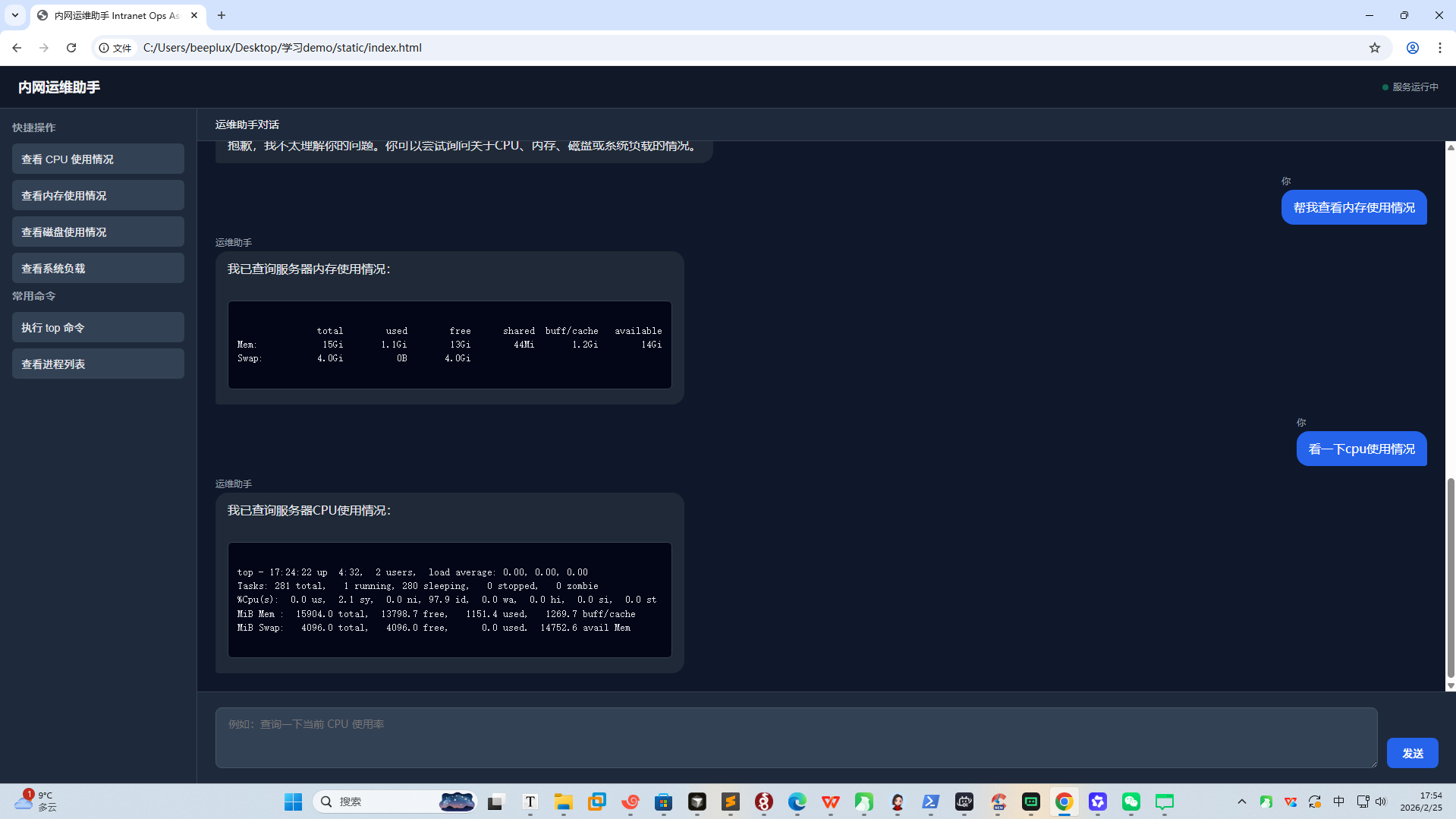
4.1 前端交互页面:内网运维助手的可视化入口
我们基于HTML+JavaScript开发了极简前端页面,核心功能包括:
- 自然语言输入框:支持用户用日常语言提问(如"帮我看一下当前CPU使用情况");
- 快捷操作按钮:一键查询CPU、内存、磁盘等核心指标;
- 结果展示区:以代码块形式展示工具执行结果,便于用户复制使用。
MVP前端截图 :
4.2 后端工具脚本:CPU与内存查询的实时数据链路
我们编写了两个核心Python脚本,作为MVP的"数据手脚":
- CPU查询脚本 (
cpu_check.py):
python
import subprocess
def get_cpu_usage():
try:
output = subprocess.check_output(
["top", "-b", "-n", "1"],
universal_newlines=True
)
for line in output.splitlines():
if line.startswith("%Cpu(s)"):
return line
return "无法获取CPU信息"
except Exception as e:
return f"执行失败: {str(e)}"
2.内存查询脚本 (memory_check.py):
```python
import subprocess
def get_memory_usage():
try:
output = subprocess.check_output(
["free", "-h"],
universal_newlines=True
)
return output
except Exception as e:
return f"执行失败: {str(e)}"前端通过 HTTP 请求调用后端 API,触发脚本执行,返回实时数据。
4.3 核心价值验证:从 "只能查指标" 到 "能解决问题" 的跨越
MVP 阶段,我们实现了:
实时数据查询:用户可快速获取服务器 CPU、内存使用情况;
自然语言交互:无需记忆命令,用日常语言即可完成操作;
链路验证:证明了 "前端→后端脚本→结果返回" 的可行性,为后续迭代奠定了基础。
- 近期迭代:30 天内完成的核心功能升级
5.1 服务器信息库:解决 IP 与服务器映射混乱的痛点
目标:建立标准化的服务器信息库,存储每台服务器的 IP、名称、用途、负责人、部署服务;
实现方式:
在 Coze 知识库中创建「服务器信息库」,录入核心服务器信息(如 "192.168.1.10:Nginx 负载均衡 LB1");
配置提示词,让 AI 能回答 "192.168.1.10 是哪台服务器?" 等问题;
前端页面增加 "服务器查询" 入口,支持按 IP、名称快速检索。
5.2 端口与日志查询工具:精准定位 Nginx 启动失败等核心故障
目标:新增端口占用查询、Nginx 日志查询工具,解决导师最关心的故障排查痛点;
新增脚本:
端口查询脚本 (port_check.py):执行lsof -i :{{port}},定位占用进程;
日志查询脚本 (log_check.py):执行tail -n 50 /var/log/nginx/error.log,快速查看错误日志;
智能联动:用户问 "Nginx 起不来",AI 自动调用端口 + 日志工具,定位根因。
5.3 自动文档生成:解决 "不爱写文档" 的流程化方案
目标:每次解决问题后,AI 自动生成《故障处理记录》,降低文档编写门槛;
标准模板:
# 故障处理记录:Nginx 80端口被占用
## 一、故障现象
Nginx启动失败,报错"Address already in use"
## 二、根因分析
被PID 12345的Java进程占用
## 三、解决步骤
1. 查询占用进程:`lsof -i :80`
2. 停止占用进程:`kill -9 12345`
3. 启动Nginx:`systemctl start nginx`
## 四、预防措施
配置端口占用检测脚本,提前预警流程优化:在前端页面增加 "一键上传到知识库" 按钮,员工无需手动编写文档。
- 中长期规划:从智能助手到企业级可观测性平台
6.1 与现有日志监控平台融合:让 AI 拥有 "全链路视角"
目标:将现有日志监控平台(Filebeat+Kafka+Elasticsearch+Prometheus)作为 AI 的数据源;
实现方式:
编写查询 Elasticsearch(日志)、Prometheus(监控)的脚本,注册为 Coze 工具;
配置提示词,让 AI 能回答 "昨天 Nginx 有多少 5xx 错误?""Kafka 消费延迟多少?" 等问题。
6.2 告警自动诊断:从 "被动告警" 到 "主动排障"
目标:日志平台的告警自动触发 AI 诊断,实现 "告警→定位→解决→沉淀" 的闭环;
实现方式:
修改告警系统,让告警信息调用 Coze API;
AI 根据告警信息,自动调用相关工具,定位根因并给出方案;
(可选)在确认安全的情况下,自动执行修复命令。
6.3 权限与安全体系:满足企业级合规要求的分级管控
目标:建立角色分级权限体系,保障数据安全与操作可追溯;
核心措施:
角色分级:实习生(仅查看)、运维工程师(可查询,高危操作需确认)、管理员(全权限);
操作审计:所有工具调用、文档上传记录到审计日志,仅管理员可查看;
高危拦截:禁止rm -rf等高危命令,确保生产环境安全。
- 总结与思考:用最小成本撬动最大价值的初创实践
本项目从解决 Nginx 端口占用的具体问题出发,逐步升级为覆盖 "故障诊断、知识沉淀、新人上手" 的内网智能基础设施。核心价值在于:
对公司:用最小成本解决了核心运维痛点,沉淀了知识资产,提升了团队效率;
对个人:通过 MVP 验证、迭代优化,将技术方案落地为可复用的企业级解决方案;
对未来:为后续与日志监控平台融合、实现全链路智能运维奠定了基础。
在半导体初创公司的资源约束下,我们的实践证明:技术方案不必追求完美,只要精准解决核心痛点,就能创造巨大价值。