****论文题目:****XLNet: Generalized Autoregressive Pretraining for Language Understanding(语言理解的广义自回归预训练)
会议:NeurIPS 2019
****摘要:****由于具有双向上下文建模的能力,BERT等基于去噪自编码的预训练方法比基于自回归语言建模的预训练方法具有更好的性能。然而,依赖于用掩码破坏输入,BERT忽略了掩码位置之间的依赖关系,并遭受了预训练-微调差异。鉴于这些优点和缺点,我们提出了XLNet,这是一种广义的自回归预训练方法,它(1)通过最大化分解顺序的所有排列的期望似然来学习双向上下文,(2)由于其自回归公式克服了BERT的局限性。此外,XLNet将Transformer-XL(最先进的自回归模型)的思想集成到预训练中。从经验上看,在可比较的实验设置下,XLNet在20个任务上的表现优于BERT,而且通常以很大的优势优于BERT,包括问题回答、自然语言推理、情感分析和文档排序。
预训练模型和代码可在https://github.com/zihangdai/xlnet上获得。
导读:为什么需要 XLNet?
2018 年,Google 推出 BERT,凭借双向 Transformer 在 NLP 各项任务上大幅刷新了纪录。然而,BERT 的自编码(AE)预训练方式存在两个根本缺陷:
- MASK 引发的预训练-微调不一致:预训练时大量使用 MASK 占位符,微调和推断时却从未出现,导致严重的分布偏移。
- 独立性假设:BERT 假设所有被 mask 的 token 相互独立,忽略了它们之间的高阶依赖。例如,预测"New York"时,BERT 将 New 和 York 视为独立预测,无法捕捉二者的强相关性。
另一方面,传统自回归(AR)语言模型(如 GPT)只能单向建模,无法利用双向上下文。
XLNet 的出发点就是:既要 BERT 的双向上下文建模能力,又要 AR 模型的无独立假设特性。为此,作者提出了一套全新的预训练范式。
1. 背景:AR vs AE 的优劣
1.1 自回归语言模型(AR)
AR 模型将序列概率分解为单向乘积:
log p(x) = Σ log p(x_t | x_{<t}) (前向)
****优点:****天然满足概率乘法法则,预测目标之间无独立假设,且不存在预训练--微调分布偏移。
****缺点:****只能利用单向上下文(前向或后向),无法深层融合双向信息。
1.2 自编码模型(AE)--- 以 BERT 为例
BERT 将序列中约 15% 的 token 替换为 MASK,然后训练模型还原:
log p(x̄ | x̂) ≈ Σ m_t · log p(x_t | x̂)
****优点:****Transformer 可以同时看到左右两侧上下文,双向建模能力强。
****缺点 1------独立性假设:****公式中的约等号揭示了 BERT 的妥协:它假设所有被 mask 的 token 之间相互独立,丢失了目标 token 之间的依赖关系。
缺点 2------预训练--微调不一致:MASK 只在预训练时出现,下游任务中完全缺失,造成分布偏移。
|----------------------------------------------------------------------------------|
| 核心矛盾 AR 拥有严格的概率建模能力但只能单向;AE 可以双向建模但引入了人工噪声和独立假设。XLNet 的目标是在同一框架内兼顾两者的优点。 |
2. XLNet 的核心方法
2.1 排列语言模型(Permutation Language Modeling)
对长度为 T 的序列,共有 T! 种分解顺序。XLNet 最大化所有分解顺序上的期望对数似然:
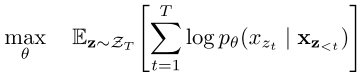
其中 Z_T 是长度 T 的所有排列的集合,z_t 是某排列中第 t 个位置,z_{<t} 是其前 t-1 个位置。
****关键洞见:****参数 θ 在所有排列上共享。这意味着在期望意义上,每个位置 x_t 都能看到序列中其他所有位置的信息,从而实现双向上下文建模------而整个框架仍是 AR 的,无需 MASK,也无独立假设。
重要注意: 排列的是分解顺序(factorization order),而非输入序列的实际顺序。实际序列顺序不变,位置编码也对应原始位置,仅通过 Transformer 的注意力掩码来实现不同的分解顺序。
|------------------------------------------------------------------------------------------------------|
| 类比理解 想象同一段文字,我们训练模型用城市→是→一→纽约的顺序预测约克,也用是→城市→约克→纽的顺序预测,模型最终学会从任意上下文推断任意词,等效于双向建模。 |
2.2 双流自注意力(Two-Stream Self-Attention)
****问题所在:****若用标准 Transformer 直接实现上述目标,会产生歧义------隐状态 h(x_{z<t}) 不依赖目标位置 z_t,导致不同位置的预测分布完全相同(详见论文附录 A.1 的具体反例)。
为解决这一问题,XLNet 提出目标感知的预测分布:
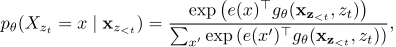
其中新引入的表示 g_θ 需要同时满足两个矛盾的条件:
- ****预测 x_{z_t} 时,****不能使用 x_{z_t} 自身的内容(否则目标泄露,任务退化)。
- ****预测其他位置 x_{z_j}(j > t)时,****必须能访问 x_{z_t} 的内容(提供完整上下文)。
为此,XLNet 维护两套并行的隐状态:
|-----------|-------------|----------------------|------------------|
| 流 | 初始化 | Key/Value 来自 | 能否看到自身内容 |
| 内容流 h | 词嵌入 e(x_i) | z ≤ t 的内容表示 | ✓ 可以 |
| 查询流 g | 可学习向量 w | z < t 的内容表示(不含自身) | ✗ 不可以 |
微调时,只需丢弃查询流,直接使用内容流,与标准 Transformer-XL 完全一致,无额外开销。
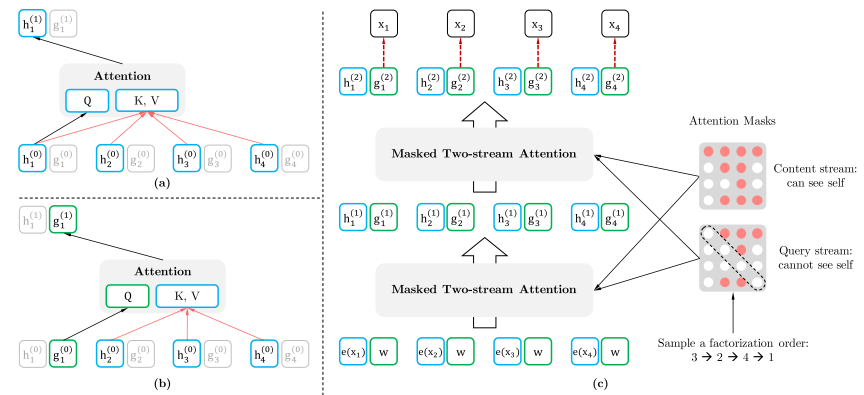
(a) 内容流注意力掩码,(b) 查询流注意力掩码,(c) 双流注意力整体结构概览
2.3 融合 Transformer-XL
XLNet 将 Transformer-XL 的两项关键技术引入预训练:
- ****片段循环机制(Segment Recurrence):****将前一片段的内容表示缓存为记忆(memory),在处理后续片段时复用,有效扩展上下文长度,特别有助于需要理解长文本的任务(如 RACE)。
- ****相对位置编码(Relative Positional Encoding):****使用相对位置而非绝对位置进行编码,在与记忆结合时无需知道前一片段的分解顺序,泛化能力更强。
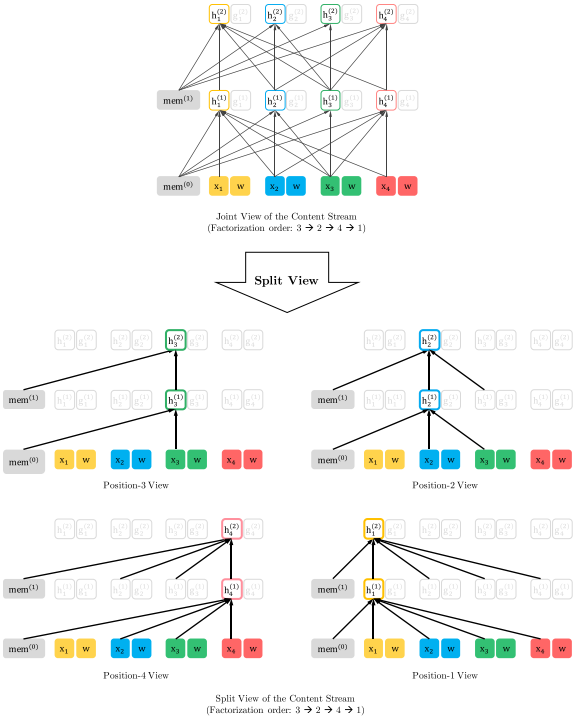
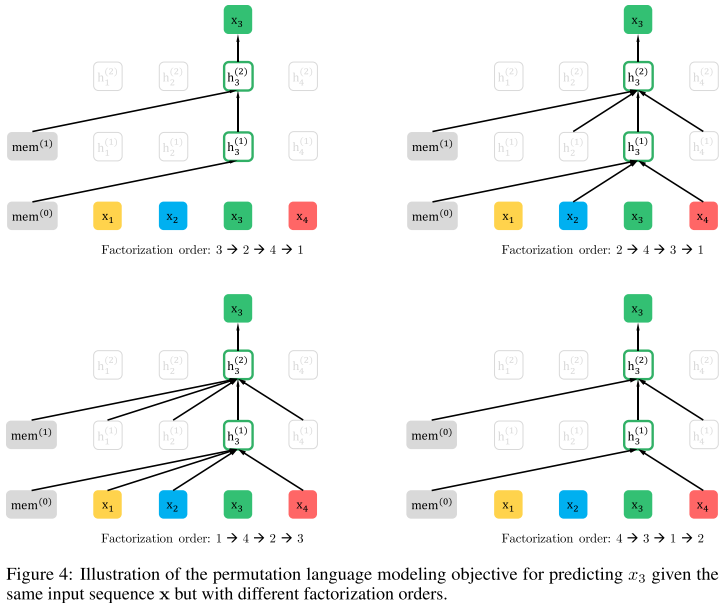
Fig.5:在分解顺序3,2,4,1下,基于长度-4序列的联合视图和分割视图的所提出目标的内容流的详细说明。注意,如果我们忽略查询表示,则该图中的计算只是标准的自注意力机制,尽管使用了特殊的注意掩码。
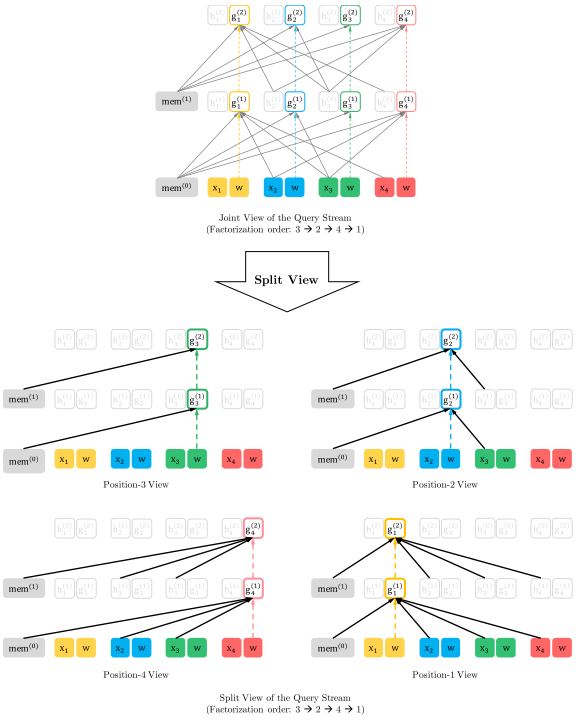
Fig.6:详细说明了在分解顺序3,2,4,1下,基于长度-4序列的联合视图和分割视图的所提出目标的查询流。破折号箭头表示查询流不能访问同一位置的令牌(内容),只能访问位置信息。
2.4 部分预测与其他设计细节
****部分预测(Partial Prediction):****由于全序列排列使优化极为困难,XLNet 只预测分解顺序末尾约 1/K 的 token(K 为超参数,默认 6),其余位置无需计算查询流,节省计算资源并降低优化难度。
多段输入: 沿用 BERT 的 CLS, A, SEP, B, SEP 格式,但使用相对片段编码代替 BERT 的绝对片段嵌入:仅区分两个位置是否来自同一片段,而非它们来自哪个片段,既提升泛化性,又支持超过两段的下游任务。
****Next Sentence Prediction(NSP):****XLNet 去掉了 NSP 目标,消融实验证明其对 XLNet 没有持续改善效果。
3. 预训练设置
XLNet-Large 与 BERT-Large 架构参数相同(24 层,隐层 1024,16 头注意力),训练数据规模远超 BERT:
|---------------------|----------------|---------------|
| 数据集 | 规模(GB) | 词片(B) |
| Wikipedia | ~3.5 | 1.09 |
| BooksCorpus | ~9.5 | 2.78 |
| Giga5 | 16 | 4.75 |
| ClueWeb 2012-B(过滤后) | 19 | 4.30 |
| Common Crawl(过滤后) | 110 | 19.97 |
| 合计 | ~158 | 32.89 |
在 512 块 TPU v3 上训练 500K 步,batch size 8192,约耗时 5.5 天。训练结束时模型仍处于欠拟合状态,说明数据规模的提升空间巨大。
4. 实验结果
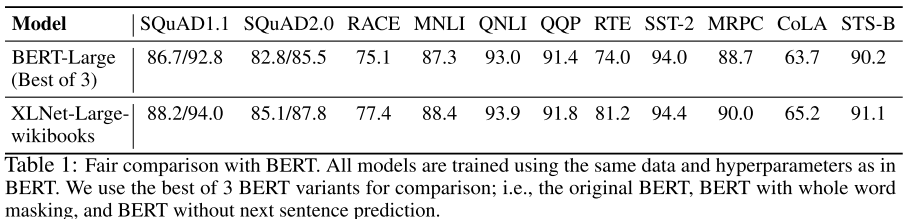
4.1 与 BERT 的公平对比
为了排除数据量的干扰,作者训练了只使用 Wikipedia + BooksCorpus 的 XLNet-Large-wikibooks,与三个 BERT-Large 变体的最优结果对比:
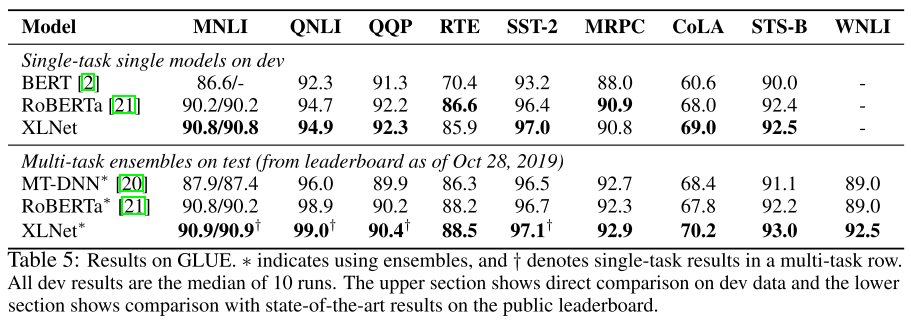
4.2 与 RoBERTa 全量数据对比
使用全量数据后,XLNet 在多类任务上持续超越 RoBERTa:
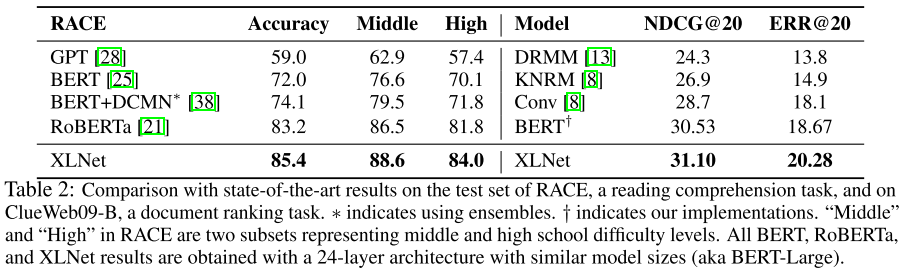
RACE 数据集平均段落长度超过 300,对长文本理解能力要求极高,XLNet 的 Transformer-XL 骨干在此体现出优势。
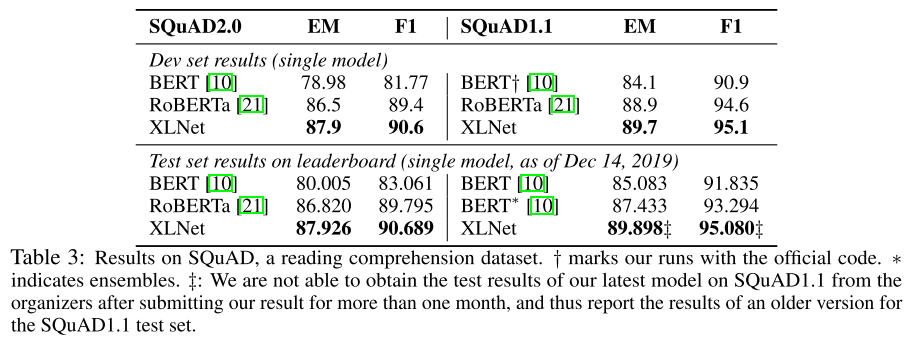
机器阅读理解 SQuAD
文本分类(错误率↓)
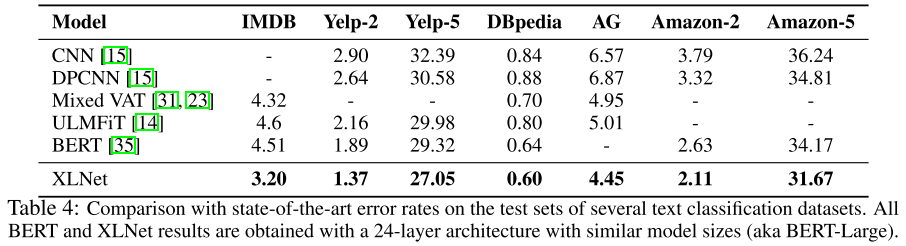
值得注意的是,即便在 MNLI(>39 万条)、Yelp(>56 万条)、Amazon(>300 万条)等已有大量监督样本的任务上,XLNet 仍能带来显著提升,说明其预训练质量本身更高,而非仅靠数据量取胜。
GLUE 综合评测
5. 消融实验
作者在 XLNet-Base-wikibooks 上进行了系统性消融,测试了四个任务:RACE、SQuAD 2.0、MNLI、SST-2。
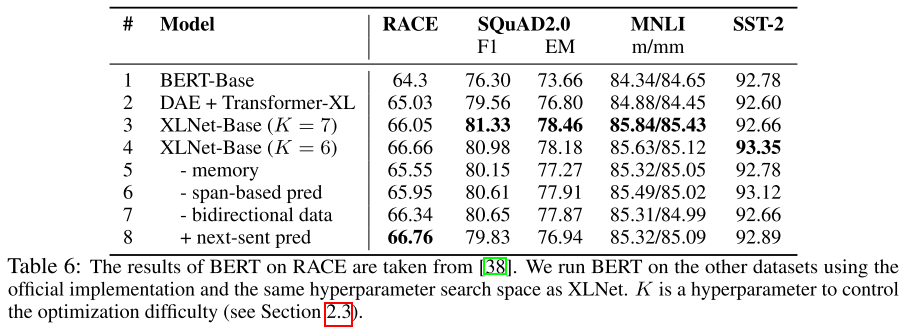
消融结果揭示了以下规律:
- ****排列 LM 目标本身有效(行 1→3):****仅将目标从 DAE 换为排列 LM,各任务均显著提升,证明排列建模的有效性。
- ****Transformer-XL 骨干有效(行 2 vs 3):****在相同排列 LM 目标下,Transformer-XL 比标准 Transformer 有进一步提升,尤其在长文本的 RACE 上。
- ****记忆机制至关重要(行 4→5):****去掉片段记忆后,RACE 从 66.66 降至 65.55,因为 RACE 段落最长,最依赖长程上下文。
- ****Span 预测和双向输入有帮助(行 6、7):****两者去掉后均有下降,贡献中等。
- ****NSP 目标反而有害(行 8):****加入 NSP 后 SQuAD 2.0 和 MNLI 均有下降,因此 XLNet 不使用 NSP。
6. 理论分析:XLNet 为何更强?
论文附录 A.5 给出了更严格的分析。以序列 New, York, is, a, city 为例,假设两个模型都选择预测 New, York,XLNet 采样到分解顺序 is, a, city, New, York,则:
J_BERT = log p(New | is a city) + log p(York | is a city)
J_XLNet = log p(New | is a city) + log p(York | New, is a city)
XLNet 在预测 York 时能利用 New 的信息,而 BERT 的独立假设使其做不到这一点。一般结论是:XLNet 总是能覆盖 BERT 所能覆盖的所有依赖对,同时还能覆盖 BERT 无法覆盖的跨目标依赖,因此包含更密集的有效训练信号。
7. 总结与启发
7.1 XLNet 的贡献
- 提出排列语言模型目标,在 AR 框架内实现双向上下文建模,从根源上解决 BERT 的独立假设和预训练--微调不一致问题。
- 设计双流自注意力机制,解决排列目标下的预测歧义,且微调时无额外开销。
- 将 Transformer-XL 的循环记忆机制首次引入预训练,显著提升长文本理解能力。
- 在 20 个任务上全面超越 BERT,多项任务上超越 RoBERTa,确立了当时的最优水平。
7.2 局限与后续
- ****计算代价高:****双流注意力几乎将计算量翻倍;大规模训练需要 512 块 TPU v3 运行 5.5 天。
- ****仍在欠拟合:****500K 步训练结束时模型仍未收敛,说明更大规模训练可能进一步提升。
- ****后续工作:****ALBERT(参数共享)、ELECTRA(替换 token 检测)等进一步探索预训练目标的设计空间;GPT-3 等大模型则走向纯 AR 路线,通过规模弥补单向建模的不足。