背景与概述
分类器无关指导(Classifier-Free Guidance, CFG)是一种在扩散模型和流匹配(Flow Matching, FM)模型中广泛用于可控生成的技术。尽管CFG在实践中取得了成功,但它依赖于启发式的线性外推法,对指导尺度(guidance scale) 非常敏感。该研究从优化的角度对CFG提供了一种原理性解释,揭示了流匹配中的速度场对应于一系列平滑距离函数的梯度,这些梯度引导潜在变量趋向于缩放后的目标图像集。
核心方法和理论基础
CFG的优化解释
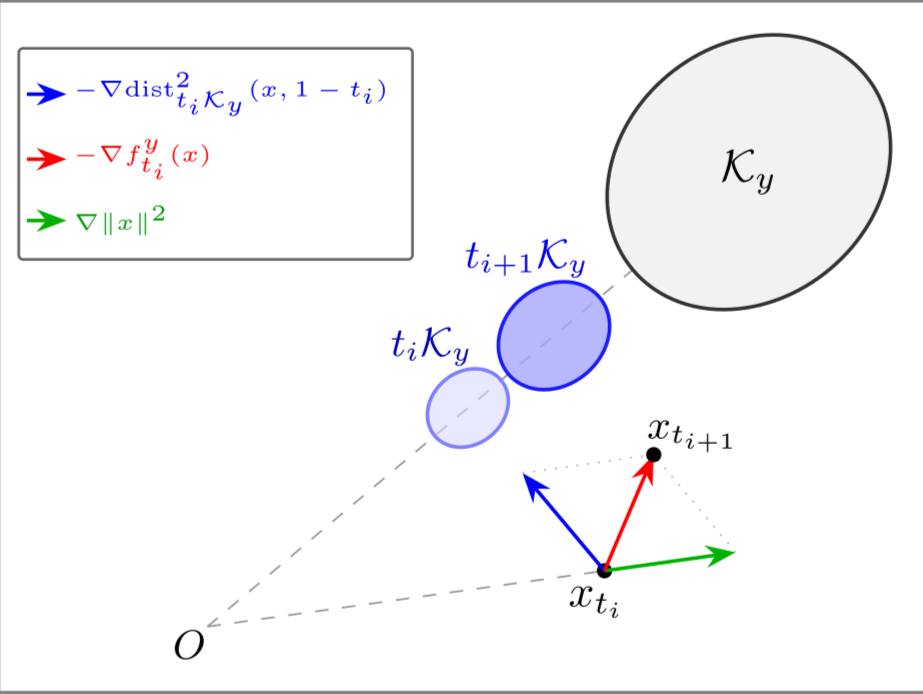
研究表明,理想的条件速度场 可以表示为一系列正则化距离目标函数梯度的负值。具体而言,对于条件
,理想速度场
满足关系:
其中,
是到条件图像集 的平滑平方距离函数。
这个视角表明,标准的CFG公式:
实际上是对这个梯度场的近似。
CFG的采样过程可以被重新解释为一个同伦优化(homotopy optimization)过程,旨在最小化目标图像集 的距离函数。每个采样步骤
实际上是在一个平滑的中间目标函数:
上执行一步梯度下降。
近似误差的理论分析
研究正式定义了最优指导尺度 为近似误差的最小化器。
近似误差:
被分解为两项:
第一项是不可避免的模型固有误差项,另一项与
成正比。
第二项中的
被称为"预测差距"(prediction gap)。这个分解理论上解释了预测差距越大,近似误差对指导尺度 的敏感度越高,从而验证了消除预测差距可以提高鲁棒性和降低对指导尺度敏感性的经验观察。
CFG-MP(Manifold Projection)
为了消除预测差距,该研究引入了一个流形约束:
采样被重新公式化为一个带有流形约束的同伦优化问题,这需要一个流形投影步骤。
流形 被定义为一个势函数
的驻点集,其中
与预测差距相关。为了将采样点投影
到 ,研究采用了一种迭代的增量梯度下降方案。
具体地,在每个采样步骤中,更新规则为:
,
近似为:
迭代投影通过一个操作符 实现,其表达式为:
在每次采样迭代中,通过对 进行
次固定点迭代来执行流形投影。
CFG-MP+(Anderson Acceleration):
为了提高CFG-MP中迭代投影的计算效率和稳定性,研究进一步引入了Anderson加速(Anderson Acceleration, AA)。
AA通过构建对过去迭代的线性外推来加速固定点迭代的收敛,以最小化残差范数。这在不增加额外模型评估次数的情况下显著提升了收敛速度和稳定性。
实验结果
研究在多项基准测试中验证了所提出方法的有效性,包括类别条件图像生成(在ImageNet数据集上使用DiT-XL-2-256模型)和文本到图像生成(使用SD3.5和Flux-dev模型)。
- 图像生成质量: CFG-MP/MP+在FID(Fréchet Inception Distance)和IS(Inception Score)等指标上显著优于现有方法,尤其在更高的指导尺度和较少的函数评估次数(NFE)下表现出更强的鲁棒性。定性结果显示,生成图像在锐度、纹理细节、对比度和色彩饱和度方面均有提升,并有效消除了基线方法中常见的模糊纹理和过度平滑现象。
- 文本到图像生成: 在CLIP score、ImageReward score、PickScore和HPSv2 score等指标上,CFG-MP/MP+持续超越基线,表明其在人类偏好对齐方面有显著改进。在GenEval等细粒度评估框架下,CFG-MP/MP+在物体计数、颜色归因和空间定位等复合任务中表现出色,验证了其卓越的语义对齐能力,并有效缓解了属性泄漏和几何变形等常见失败。
- 加速方案分析 : 实验表明,Anderson加速版本的
操作符相比普通的固定点迭代,能更稳定且快速地降低预测差距。
- 消融研究 : 对Anderson加速的超参数(迭代次数
总结
该研究通过优化视角对CFG进行了深入的理论阐释,揭示了其与平滑距离函数梯度的联系,并首次从理论上阐明了预测差距与指导尺度敏感性之间的关系。基于此,提出了CFG-MP和CFG-MP+方法,通过引入流形投影和Anderson加速,在推理过程中有效地减少了预测差距,无需重新训练模型,显著提升了流匹配生成模型的生成保真度、提示对齐能力和对指导尺度的鲁棒性。尽管理论分析主要针对流匹配模型,但其中关于预测差距敏感性的见解可能对扩散模型同样适用,为未来的研究提供了方向。