
本文介绍基于 鸢尾花分类 的 MATLAB 机器学习小项目示例,涵盖数据预处理、模型训练、评估及可视化全流程,适合入门学习。
文章目录
项目目标
使用鸢尾花数据集(Iris Dataset),训练一个分类模型,根据花萼和花瓣的尺寸(4个特征)预测花的类别(3种:Setosa, Versicolor, Virginica)。
代码说明
运行结果
数据加载与探索:
- 使用内置的
fisheriris数据集,包含150个样本和4个特征。 - 绘制前两个特征的分布图,直观展示类别可分性。
数据预处理:
- 将文本标签转换为数值 ( 1 , 2 , 3 ) (1, 2, 3) (1,2,3)。
- 按7:3比例划分训练集和测试集。
- 可选特征标准化(若特征尺度差异大)。
模型训练
- SVM :使用
fitcecoc训练多类分类模型。 - 决策树 :使用
fitctree作为对比模型。
模型评估
- 计算测试集准确率。
- 使用5折交叉验证评估模型稳定性。
- 绘制混淆矩阵分析分类细节。
完整代码
matlab
%% 鸢尾花分类机器学习示例
% 作者:matlabfilter(v同号,接MATLAB代码定制和讲解)
% 2025-02-08/Ver1
%% 1. 加载数据与探索
clear; clc; close all;
% 加载内置鸢尾花数据集
load fisheriris; % 数据包含meas(特征)和species(标签)
% 显示数据信息
fprintf('数据集维度: %d样本 x %d特征\n', size(meas));
fprintf('类别标签: %s, %s, %s\n', unique(species));
% 可视化特征分布
figure;
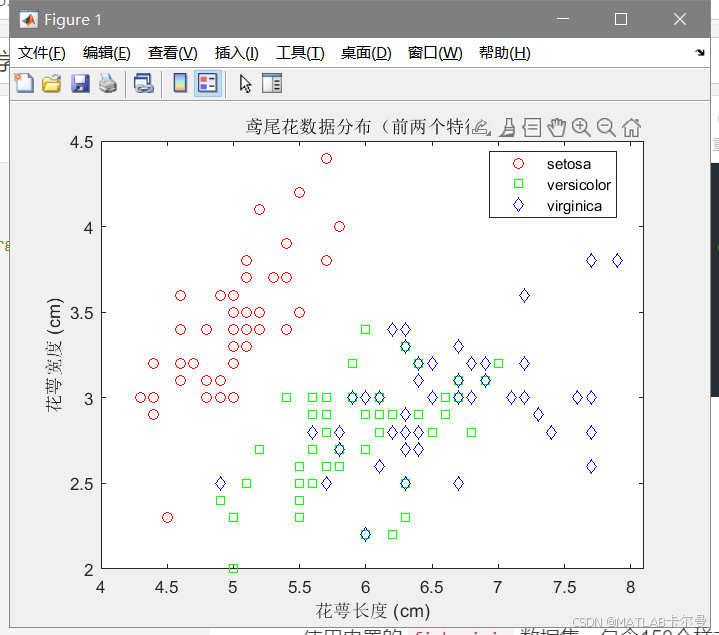
gscatter(meas(:,1), meas(:,2), species, 'rgb', 'osd');
xlabel('花萼长度 (cm)');
ylabel('花萼宽度 (cm)');
title('鸢尾花数据分布(前两个特征)');
%% 2. 数据预处理
% 将类别标签转换为数值(1,2,3)
[~, ~, labels] = unique(species);
% 划分训练集和测试集(70%训练,30%测试)
rng(1); % 固定随机种子
cv = cvpartition(labels, 'HoldOut', 0.3);
X_train = meas(cv.training,:);
y_train = labels(cv.training);
X_test = meas(cv.test,:);
y_test = labels(cv.test);
% 特征标准化(可选:若特征尺度差异大)
% [X_train, mu, sigma] = zscore(X_train);
% X_test = (X_test - mu) ./ sigma;
%% 3. 训练分类模型
% 使用支持向量机(SVM)
svm_model = fitcecoc(X_train, y_train, ...
'Learners', 'svm', ...
'Coding', 'onevsone');
% 使用决策树(对比)
tree_model = fitctree(X_train, y_train);
%% 4. 模型评估
% 预测测试集
y_pred_svm = predict(svm_model, X_test);
y_pred_tree = predict(tree_model, X_test);
% 计算准确率
accuracy_svm = sum(y_pred_svm == y_test) / numel(y_test);
accuracy_tree = sum(y_pred_tree == y_test) / numel(y_test);
% 交叉验证评估(更稳健)
cv_svm = crossval(svm_model, 'KFold', 5);
cv_accuracy_svm = 1 - kfoldLoss(cv_svm, 'Mode', 'individual');
cv_tree = crossval(tree_model, 'KFold', 5);
cv_accuracy_tree = 1 - kfoldLoss(cv_tree, 'Mode', 'individual');
% 输出结果
fprintf('SVM测试集准确率: %.2f%%\n', accuracy_svm*100);
fprintf('决策树测试集准确率: %.2f%%\n', accuracy_tree*100);
fprintf('SVM交叉验证平均准确率: %.2f%%\n', mean(cv_accuracy_svm)*100);
fprintf('决策树交叉验证平均准确率: %.2f%%\n', mean(cv_accuracy_tree)*100);
% 混淆矩阵可视化
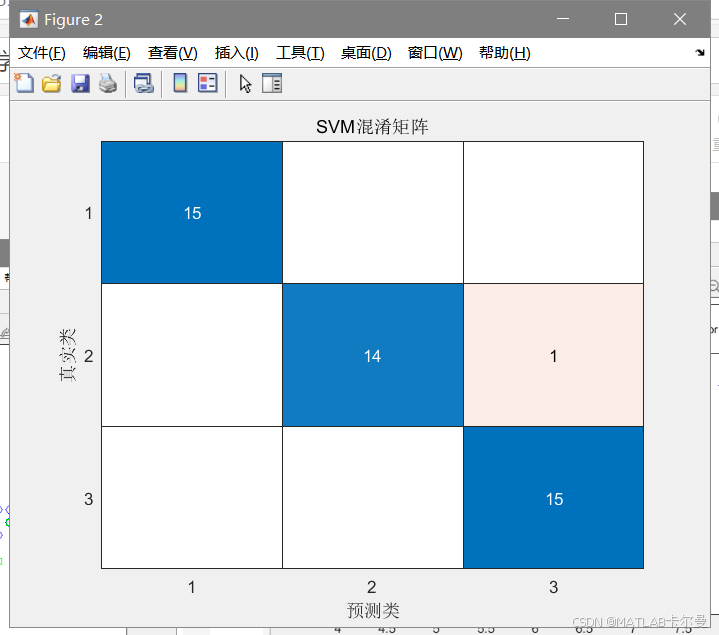
figure;
confusionchart(y_test, y_pred_svm);
title('SVM混淆矩阵');
figure;
confusionchart(y_test, y_pred_tree);
title('决策树混淆矩阵');
%% 5. 可视化决策边界(以两个特征为例)
% 选择两个特征:花萼长度和花瓣长度
X_2d = meas(:, [1,3]);
svm_2d_model = fitcecoc(X_2d, labels, 'Learners', 'svm');
% 生成网格点
h = 0.02;
[x1, x2] = meshgrid(min(X_2d(:,1)):h:max(X_2d(:,1)), ...
min(X_2d(:,2)):h:max(X_2d(:,2)));
X_grid = [x1(:), x2(:)];
% 预测网格点类别
y_grid = predict(svm_2d_model, X_grid);
y_grid = reshape(y_grid, size(x1));
% 绘制决策区域
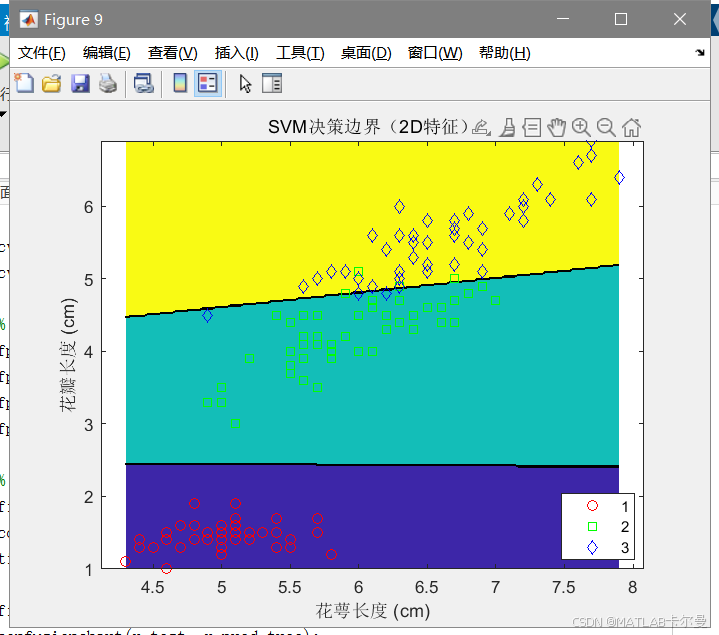
figure;
contourf(x1, x2, y_grid);
hold on;
gscatter(X_2d(:,1), X_2d(:,2), labels, 'rgb', 'osd');
xlabel('花萼长度 (cm)');
ylabel('花瓣长度 (cm)');
title('SVM决策边界(2D特征)');扩展方向
此代码可向如下方向扩展
- 尝试其他算法 :如随机森林 (
fitensemble)、K近邻 (fitcknn)。 - 特征工程 :添加新特征(如长宽比)或使用 P C A PCA PCA降维。
- 调参优化 :使用
hyperparameters函数优化SVM的核函数或决策树的深度。 - 部署模型 :通过
saveLearnerForCoder导出模型用于嵌入式系统。
此项目完整覆盖机器学习核心流程,适合作为入门练习。
如需代码一对一讲解、定制,可通过下方卡片联系我