前馈神经网络(Feedforward Neural Network,FNN)是深度学习中最基础的一类神经网络结构。它的核心特点是:信息只沿一个方向逐层传播,从输入层进入,经过一个或多个隐藏层,最后到达输出层,网络中没有循环反馈连接。
在理解单层感知器与多层感知器之后,可以进一步看到:单层感知器只能学习线性决策边界,而多层感知器通过隐藏层和非线性激活函数扩展了模型表达能力。本文将把这一思想放入更完整的前馈神经网络框架中,重点讨论神经网络如何完成前向传播、如何计算损失、如何通过反向传播更新参数,以及如何用 PyTorch 实现一个完整训练流程。
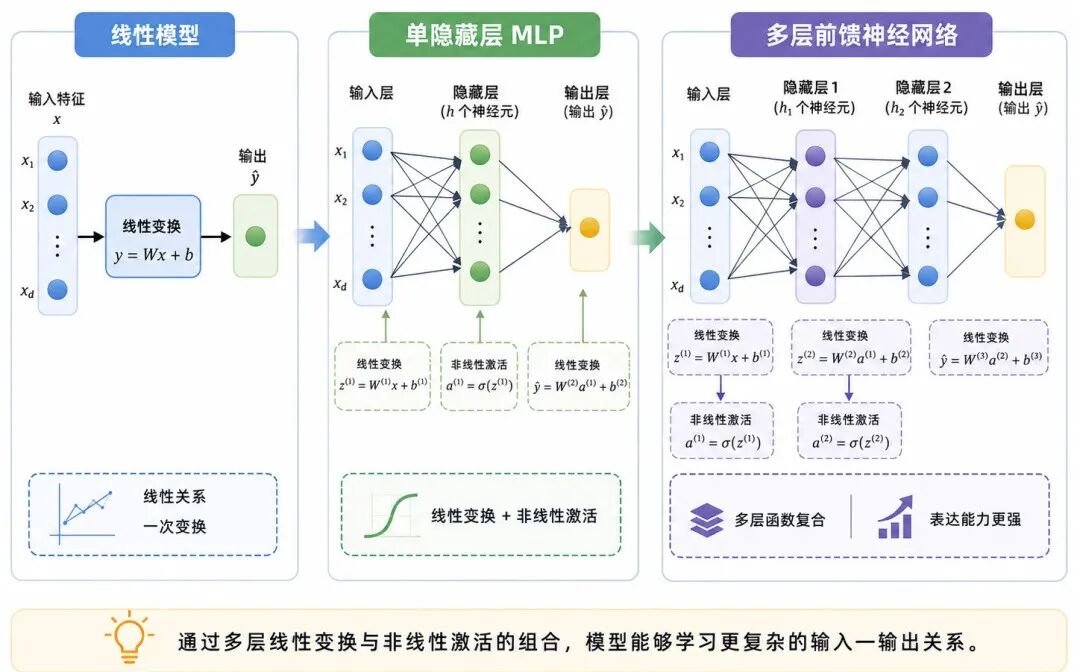
图 1:从线性模型到前馈神经网络
严格来说,前馈神经网络是一个较宽泛的结构概念。只要信息从前向后逐层传播、不存在循环反馈连接,都可以看作前馈结构。多层感知机(Multilayer Perceptron,MLP)则是其中最典型、最基础的一类全连接前馈网络。
一、前馈神经网络的基本定位
前馈神经网络可以理解为一种可训练的参数化函数。它接收输入数据,通过多层"线性变换 + 非线性激活"的组合,最终输出预测结果。
从机器学习角度看,模型的目标不是简单模仿生物神经系统,而是学习一个从输入到输出的映射关系:
其中:
• x 表示输入样本
• ŷ 表示模型预测结果
• f 表示由多层计算组成的函数
• θ 表示网络中的所有可训练参数
θ 通常包含所有层的权重和偏置。训练神经网络的过程,本质上就是寻找一组合适的 θ,使模型预测结果尽量接近真实结果。
如果只使用一次线性变换,模型可以写为:
其中:
• x 表示输入特征
• W 表示权重
• b 表示偏置
• ŷ 表示模型预测结果
这种模型表达的是线性关系。它清晰、稳定、容易解释,但难以刻画复杂的非线性映射。
前馈神经网络在此基础上引入多层结构:
其中:
• h 表示隐藏层输出
• W₁、b₁ 表示输入层到隐藏层的权重和偏置
• W₂、b₂ 表示隐藏层到输出层的权重和偏置
• f 表示隐藏层激活函数
• g 表示输出层变换
• ŷ 表示模型输出
从这个角度看,前馈神经网络的本质不是"多画几层神经元",而是通过多层函数复合学习更复杂的输入---输出关系。
二、前馈神经网络的分层结构
典型前馈神经网络通常包含三类层:
• 输入层
• 隐藏层
• 输出层
输入层负责接收原始特征。隐藏层负责对特征进行逐层变换。输出层负责生成最终预测结果。
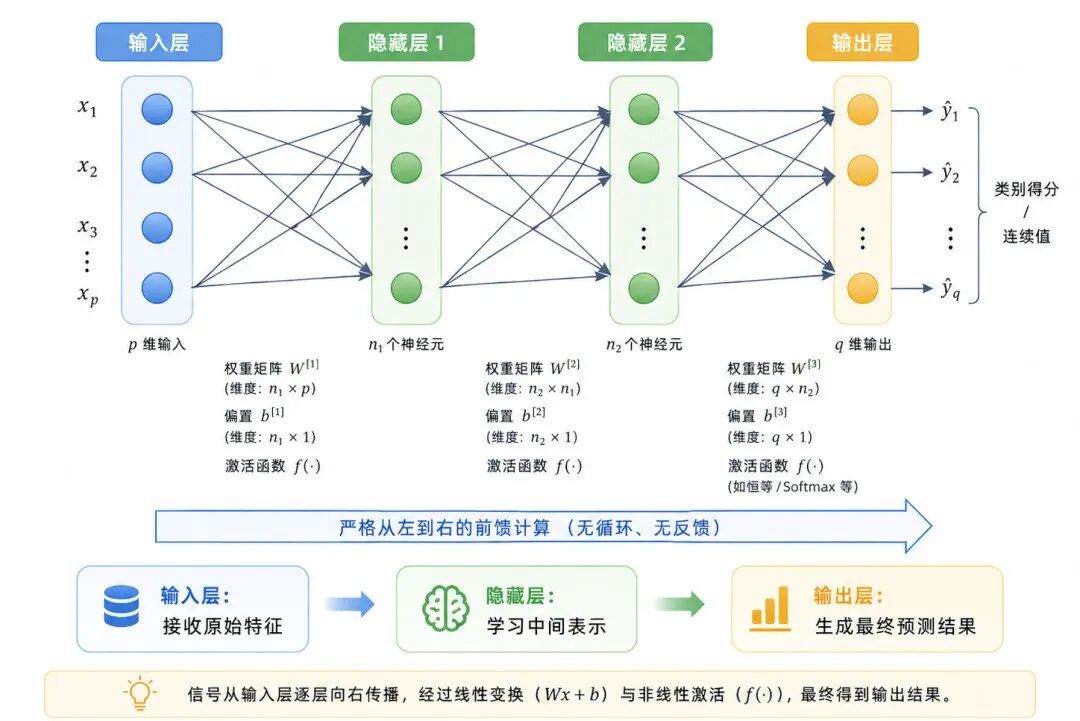
图 2:前馈神经网络的基本结构
1、输入层
输入层接收样本特征。
如果一个样本有 p 个特征,可以表示为:
其中:
• x 表示一个输入样本
• x₁、x₂、...、xₚ 表示不同输入特征
• p 表示特征数量
如果共有 n 个样本,则样本矩阵可以写为:
其中:
• X 表示样本矩阵
• n 表示样本数量
• p 表示特征数量
• 每一行表示一个样本
• 每一列表示一个特征
对于表格数据,输入层接收的通常就是特征向量。对于图像、文本等数据,如果直接使用普通 MLP,通常需要先把数据转换为固定长度向量。
2、隐藏层
隐藏层位于输入层和输出层之间,用于学习中间表示。
一层全连接网络通常可以写为:
其中:
• X 表示输入矩阵
• W 表示权重矩阵
• b 表示偏置向量
• Z 表示线性变换结果
• f 表示激活函数
• A 表示激活后的输出
隐藏层的作用,不只是增加计算量,而是把原始特征逐层转换为更适合任务的中间表示。
例如,在分类任务中,前面的隐藏层可能学习简单特征组合,后面的隐藏层可以继续组合这些中间特征,形成更有判别力的表示。
3、输出层
输出层负责产生最终预测结果。
不同任务对应不同输出形式:
• 回归任务中,输出层通常给出连续数值
• 二分类任务中,输出层通常给出一个 logit 或概率
• 多分类任务中,输出层通常给出 K 个类别得分
需要特别注意:在现代深度学习框架中,输出层是否显式添加 Sigmoid 或 Softmax,取决于所使用的损失函数。
以 PyTorch 为例:
• 二分类任务中,常让模型直接输出 logits,再交给 BCEWithLogitsLoss()
• 多分类任务中,常让模型直接输出 logits,再交给 CrossEntropyLoss()
• 回归任务中,通常直接输出连续值,再交给 MSE 或 MAE 类损失函数
这里的 logits 指的是未经 Sigmoid 或 Softmax 转换的原始得分。理解 logits 与概率的区别,是正确使用深度学习框架的重要基础。
三、前向传播:逐层计算预测结果
前向传播(Forward Propagation)指的是输入数据从输入层开始,依次经过隐藏层和输出层,最终得到预测结果的过程。
假设一个前馈神经网络包含两个隐藏层,则前向传播可以写为:
其中:
• X 表示输入特征矩阵
• W⁽¹⁾、W⁽²⁾、W⁽³⁾ 表示不同层的权重
• b⁽¹⁾、b⁽²⁾、b⁽³⁾ 表示不同层的偏置
• Z⁽¹⁾、Z⁽²⁾ 表示隐藏层线性变换结果
• A⁽¹⁾、A⁽²⁾ 表示隐藏层激活后的输出
• f₁、f₂ 表示隐藏层激活函数
• g 表示输出层变换
• ŷ 表示模型预测结果
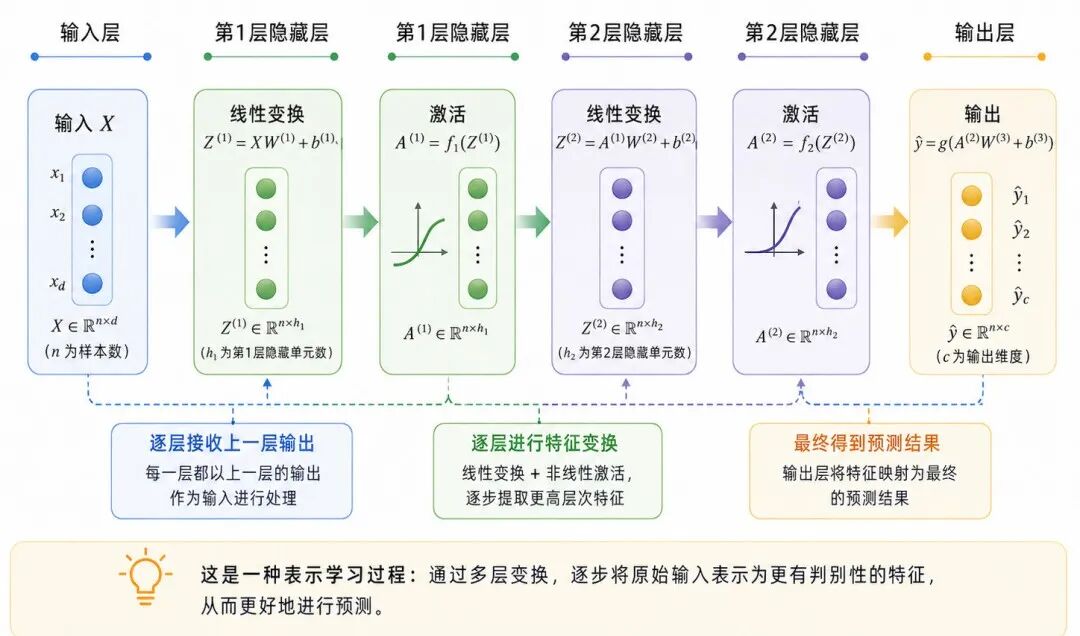
图 3:前向传播过程
从这个过程可以看出,前馈神经网络不是一次性从输入跳到输出,而是逐层进行特征变换。每一层接收上一层的输出,并生成新的表示。
这也是深度学习中"表示学习"(Representation Learning)的核心思想:模型不只是学习最终预测规则,也在学习如何把原始输入转换成更适合任务的中间表示。
四、激活函数、输出层与损失函数
激活函数和损失函数不能孤立理解。实际建模时,隐藏层激活函数、输出层形式和损失函数必须与任务类型匹配。
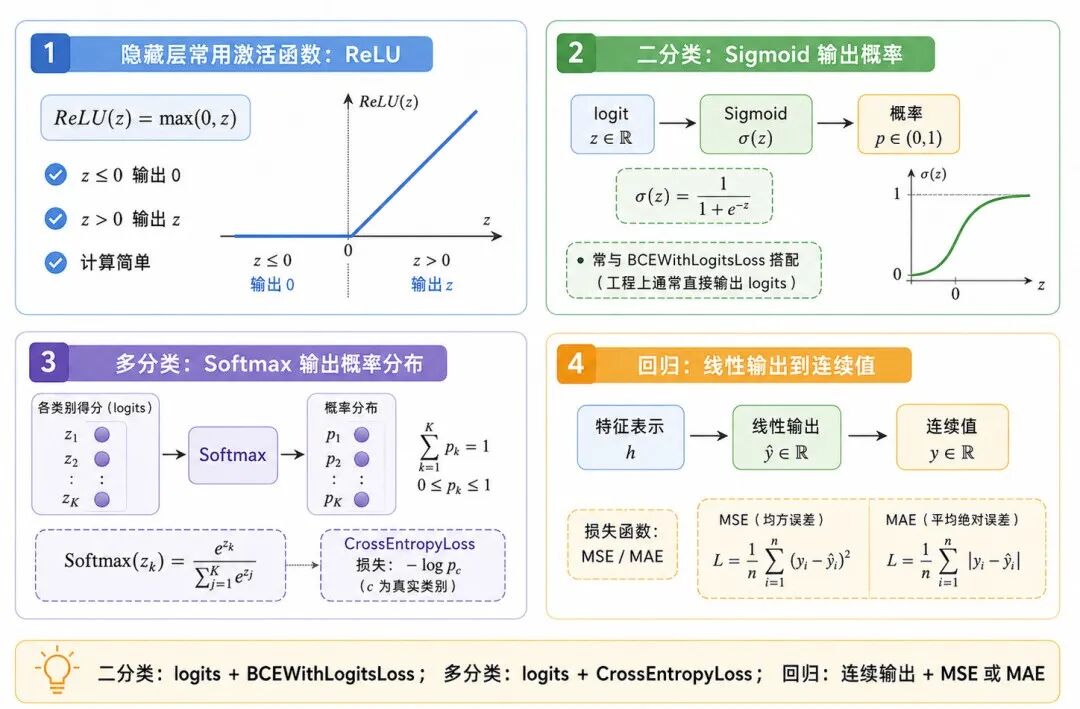
图 4:隐藏层激活函数与输出层设计
1、隐藏层常用 ReLU
ReLU(Rectified Linear Unit)是前馈神经网络中最常用的隐藏层激活函数之一。
其中:
• z 表示线性得分
• z ≤ 0 时,ReLU(z) = 0
• z > 0 时,ReLU(z) = z
ReLU 的优点是计算简单,在正半轴梯度不容易饱和,通常有助于缓解深层网络中的梯度消失问题,并加快训练速度。
不过,ReLU 也可能出现"死亡 ReLU"问题。也就是说,部分神经元可能长期输出 0,几乎不再参与有效学习。因此,在更复杂的模型中,也可能使用 Leaky ReLU、GELU 等变体。
2、二分类:logit、Sigmoid 与二元交叉熵
二分类任务中,模型通常需要判断样本属于正类的概率。
概念上,可以用 Sigmoid 函数把输出得分转换为 0 到 1 之间的概率:
其中:
• z 表示模型输出的原始得分
• σ(z) 表示 Sigmoid 输出
• σ(z) 的取值范围是 0 到 1
二分类常用二元交叉熵损失:
其中:
• L 表示损失
• n 表示样本数量
• yᵢ 表示第 i 个样本的真实标签,通常取 0 或 1
• ŷᵢ 表示模型预测第 i 个样本为正类的概率
• log 表示对数函数
在 PyTorch 中,二分类任务通常不建议手动写成:
nginx
sigmoid + BCELoss更常见、更稳定的写法是:
go
nn.BCEWithLogitsLoss()这意味着模型最后一层直接输出 logit,损失函数内部会自动完成 Sigmoid 与二元交叉熵计算。这样数值稳定性更好,也更符合 PyTorch 的常见实践。
3、多分类:Softmax 与交叉熵
多分类任务中,模型通常输出 K 个类别得分。Softmax 可以把这些得分转换为概率分布:
其中:
• zₖ 表示第 k 个类别的得分
• K 表示类别数量
• Softmax(zₖ) 表示第 k 个类别的预测概率
• ∑ 表示对所有类别得分求和
如果真实类别为 c,单个样本的多分类交叉熵损失可以写为:
其中:
• c 表示真实类别
• p_c 表示模型分配给真实类别 c 的预测概率
• −log p_c 表示真实类别对应的负对数损失
• p_c 越接近 1,损失越小
• p_c 越接近 0,损失越大
在 PyTorch 中,多分类任务通常使用:
go
nn.CrossEntropyLoss()此时模型输出层通常直接输出 logits,不需要手动添加 Softmax。因为 CrossEntropyLoss() 内部已经包含 LogSoftmax 与负对数似然损失。
4、回归:线性输出与均方误差
回归任务中,模型通常直接输出连续值,不需要 Sigmoid 或 Softmax。
常用损失函数是均方误差(Mean Squared Error,MSE):
其中:
• L 表示损失
• n 表示样本数量
• yᵢ 表示第 i 个样本的真实值
• ŷᵢ 表示第 i 个样本的预测值
• yᵢ − ŷᵢ 表示预测误差
可以简单记住:
• 二分类:logits + BCEWithLogitsLoss()
• 多分类:logits + CrossEntropyLoss()
• 回归:连续输出 + MSE 或 MAE
五、反向传播、自动微分与参数更新
前向传播只能得到预测结果。要让模型逐渐变好,还需要知道:
• 当前预测错得有多严重
• 每个参数应该朝哪个方向调整
• 每次调整多少比较合适
这就需要损失函数、反向传播、自动微分和优化器共同完成。
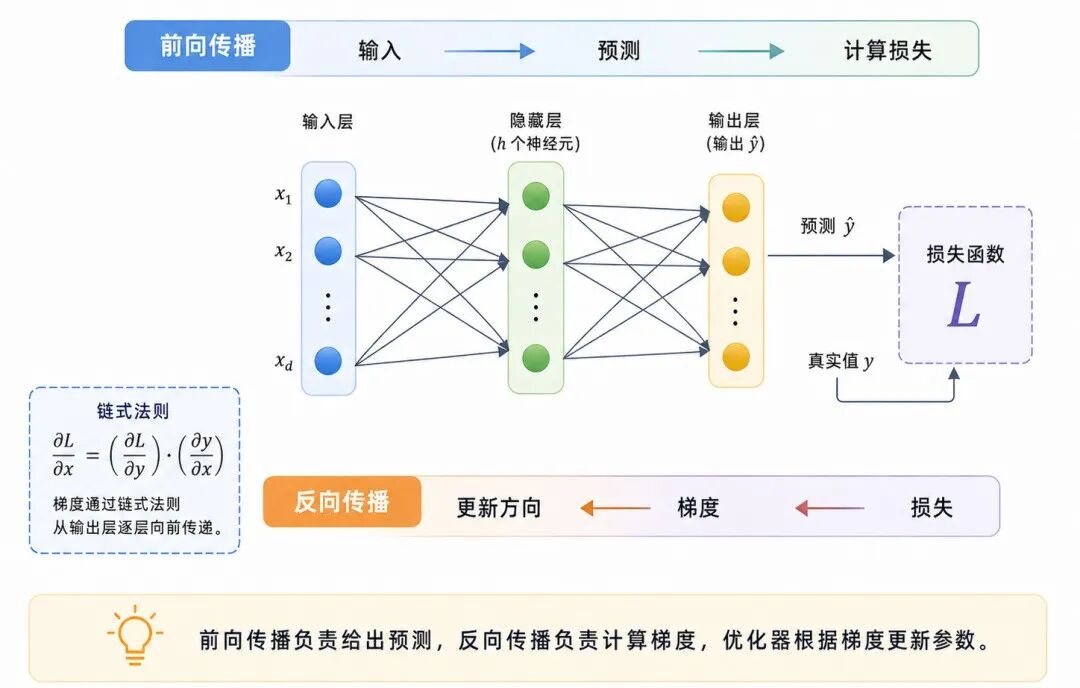
图 5:前向传播与反向传播的关系
1、损失函数告诉模型错多少
损失函数衡量预测结果与真实结果之间的差距。损失越大,说明预测越差;损失越小,说明预测越接近真实结果。
训练神经网络的目标,就是让损失尽可能下降。
2、反向传播计算参数梯度
反向传播(Backpropagation)的核心思想是:从损失函数出发,沿计算图反向传播误差信号,逐层计算各参数的梯度。
梯度可以理解为:损失函数相对于某个参数的变化方向与变化速度。
例如:
其中:
• L 表示损失
• w 表示某个参数
• ∂L/∂w 表示损失 L 对参数 w 的梯度
如果 ∂L/∂w 为正,增大 w 往往会使损失增大;如果 ∂L/∂w 为负,增大 w 往往会使损失减小。梯度绝对值越大,说明该参数对当前损失的影响越明显。
反向传播依赖链式法则。若 y 依赖 x,L 又依赖 y,则可以写为:
其中:
• x 表示前一层变量
• y 表示后一层变量
• L 表示最终损失
• ∂L/∂x 表示损失对 x 的梯度
• ∂L/∂y 表示损失对 y 的梯度
• ∂y/∂x 表示 y 对 x 的梯度
在神经网络中,后一层的输入依赖前一层的输出,最终损失又依赖最后一层输出。因此,链式法则使模型能够把输出层误差逐层传回前面的隐藏层,并计算每个参数应该如何调整。
3、梯度下降更新参数
得到梯度后,可以使用梯度下降更新参数:
其中:
• w 表示待更新参数
• η 表示学习率
• ∂L/∂w 表示损失 L 对 w 的梯度
• ← 表示用右侧新值更新左侧参数
这个公式的含义是:沿着让损失下降的方向调整参数。
学习率 η 控制每次更新的步长:
• η 过大,训练可能震荡甚至发散
• η 过小,训练速度可能很慢
• 合适的 η 有助于模型稳定收敛
在实际深度学习中,常用优化器包括 SGD、Adam、AdamW 等。它们本质上都是根据梯度信息调整参数,只是更新策略有所不同。
4、PyTorch 如何自动计算梯度
在现代深度学习框架中,开发者通常不需要手动推导每一层的梯度。
以 PyTorch 为例,当前向传播产生损失后,只需要调用:
go
loss.backward()PyTorch 就会沿计算图自动反向计算梯度,并把每个参数的梯度保存到对应参数的 .grad 属性中。
然后调用:
go
optimizer.step()优化器就会根据这些梯度更新参数。
一个标准训练步骤通常是:
bash
optimizer.zero_grad() # 清空旧梯度loss.backward() # 自动计算新梯度optimizer.step() # 根据梯度更新参数其中 zero_grad() 非常重要。因为 PyTorch 中梯度默认会累积,如果不清空旧梯度,新一轮梯度会叠加到上一轮梯度上,导致参数更新异常。
六、训练流程:深度学习的最小闭环
一个完整的前馈神经网络训练过程可以概括为:
准备数据 → 构建模型 → 定义损失函数 → 定义优化器 → 前向传播 → 计算损失 → 反向传播 → 更新参数 → 评估模型
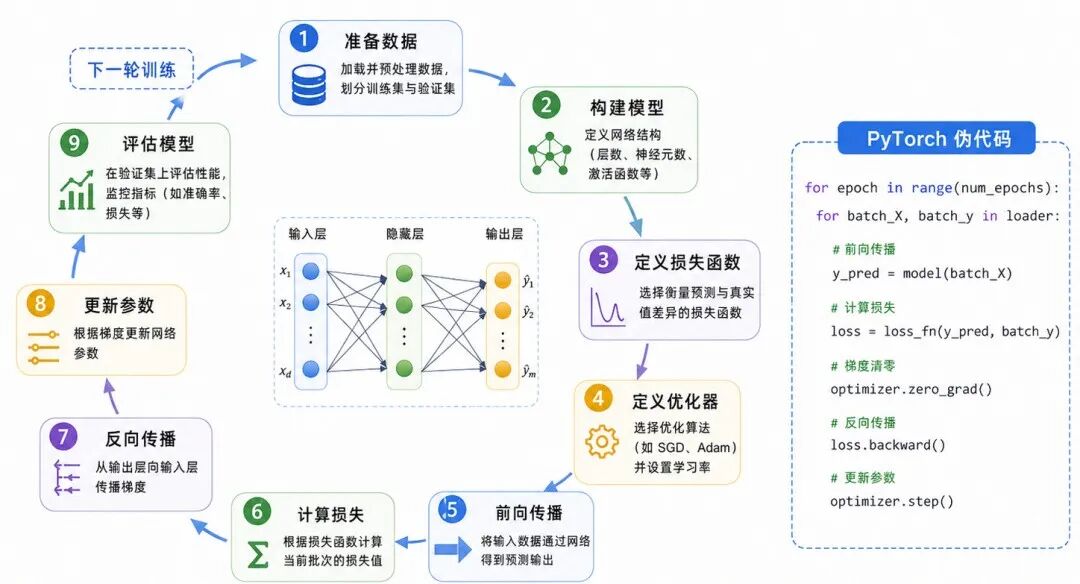
图 6:前馈神经网络训练闭环
用 PyTorch 伪代码表示如下:
css
for epoch in range(num_epochs): for batch_X, batch_y in train_loader: y_pred = model(batch_X) loss = loss_fn(y_pred, batch_y) optimizer.zero_grad() loss.backward() optimizer.step()其中:
• epoch 表示完整遍历训练数据的一轮
• batch_X 表示当前小批量输入数据
• batch_y 表示当前小批量真实标签
• model(batch_X) 表示前向传播
• loss_fn 表示损失函数
• backward() 表示自动计算梯度
• step() 表示更新参数
在真实训练中,通常不会每次都使用全部训练样本更新参数,而是把数据分成若干小批量(Mini-Batch)。这种方式既能提高训练效率,也能让梯度更新具有一定随机性,是深度学习中非常常见的训练方式。
七、Python 实现:二分类前馈神经网络
下面使用 PyTorch 构建一个简单的前馈神经网络,完成二维非线性二分类任务。
示例使用 make_moons 生成月牙形数据。这个数据集不是一条直线可以完全分开的,因此适合展示前馈神经网络学习非线性分类边界的能力。
1、导入库并生成数据
python
import numpy as npimport torchimport torch.nn as nnimport matplotlib.pyplot as plt
from torch.utils.data import TensorDataset, DataLoaderfrom sklearn.datasets import make_moonsfrom sklearn.model_selection import train_test_splitfrom sklearn.preprocessing import StandardScaler
# 设置随机种子,便于复现实验结果torch.manual_seed(42)np.random.seed(42)
# 根据操作系统选择中文字体(二选一,取消注释对应行)plt.rcParams["font.sans-serif"] = ["Microsoft YaHei"] # Windows# plt.rcParams["font.sans-serif"] = ["Songti SC"] # macOSplt.rcParams["axes.unicode_minus"] = False # 解决负号显示问题
# 1. 生成二维非线性分类数据(两个半月形,二分类)X, y = make_moons( n_samples=500, noise=0.20, random_state=42)
# 2. 划分训练集和测试集(测试集25%,分层采样)X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42, stratify=y)
# 3. 标准化特征(均值为0,方差为1)scaler = StandardScaler()X_train = scaler.fit_transform(X_train)X_test = scaler.transform(X_test)
# 4. 转换为 PyTorch 张量,标签变为列向量X_train = torch.tensor(X_train, dtype=torch.float32)X_test = torch.tensor(X_test, dtype=torch.float32)y_train = torch.tensor(y_train, dtype=torch.float32).view(-1, 1)y_test = torch.tensor(y_test, dtype=torch.float32).view(-1, 1)这里完成了四件事:
• 生成非线性二分类数据
• 划分训练集和测试集
• 对特征进行标准化
• 将 NumPy 数组转换为 PyTorch 张量
标准化在神经网络训练中很常见。它可以让不同特征处于相近尺度,有助于模型更稳定地训练。
2、构建 DataLoader
makefile
# 构建训练数据集(张量组合)train_dataset = TensorDataset(X_train, y_train)
# 使用 Mini-Batch 方式加载数据(批量大小32,打乱顺序)train_loader = DataLoader( train_dataset, batch_size=32, shuffle=True)其中:
• TensorDataset 用于把特征和标签打包成数据集
• DataLoader 用于按小批量读取数据
• batch_size=32 表示每次取 32 个样本
• shuffle=True 表示每轮训练前打乱训练数据
Mini-Batch 训练比一次性使用全部样本更接近真实深度学习训练流程。
3、定义前馈神经网络模型
ruby
class FeedforwardNet(nn.Module): def __init__(self): super().__init__()
self.net = nn.Sequential( nn.Linear(2, 16), # 输入层到隐藏层:2 个输入特征,16 个神经元 nn.ReLU(), # 隐藏层激活函数 nn.Linear(16, 8), # 第二个隐藏层:16 到 8 nn.ReLU(), # 隐藏层激活函数 nn.Linear(8, 1) # 输出层:输出 1 个 logit )
def forward(self, x): return self.net(x)
model = FeedforwardNet()这个模型包含:
• 输入层:接收 2 个特征
• 第一个隐藏层:16 个神经元
• 第二个隐藏层:8 个神经元
• 输出层:输出 1 个 logit
这里最后一层没有使用 Sigmoid。原因是后面会使用 BCEWithLogitsLoss(),它内部已经包含 Sigmoid 和二元交叉熵计算。
4、定义损失函数和优化器
ini
loss_fn = nn.BCEWithLogitsLoss()optimizer = torch.optim.Adam(model.parameters(), lr=0.01)其中:
• BCEWithLogitsLoss 适用于二分类任务
• Adam 是常用优化器
• lr=0.01 表示学习率
• model.parameters() 表示把模型中所有可训练参数交给优化器
对于二分类任务,BCEWithLogitsLoss() 通常比"手动 Sigmoid + BCELoss"更稳定,也更符合 PyTorch 的常见写法。
5、训练模型
apache
num_epochs = 500loss_history = []
for epoch in range(num_epochs): model.train()
epoch_loss = 0.0
for batch_X, batch_y in train_loader: # 1. 前向传播 logits = model(batch_X) loss = loss_fn(logits, batch_y)
# 2. 反向传播与参数更新 optimizer.zero_grad() loss.backward() optimizer.step()
# 3. 累计当前批次损失 epoch_loss += loss.item() * batch_X.size(0)
# 4. 计算当前 epoch 的平均损失 epoch_loss = epoch_loss / len(train_loader.dataset) loss_history.append(epoch_loss)
if (epoch + 1) % 100 == 0: print(f"Epoch {epoch + 1}, Loss: {epoch_loss:.4f}")这段代码体现了神经网络训练的核心闭环:
• 前向传播得到 logits
• 计算 logits 与真实标签之间的损失
• 清空旧梯度
• 反向传播计算新梯度
• 优化器更新参数
• 重复多轮训练
其中 model.train() 表示进入训练模式。虽然这个示例中没有 Dropout 或 BatchNorm,但保留这一写法更符合规范训练流程。
6、评估模型
css
model.eval()
with torch.no_grad(): test_logits = model(X_test) test_probs = torch.sigmoid(test_logits) test_pred = (test_probs >= 0.5).float()
accuracy = (test_pred == y_test).float().mean()
print(f"测试集准确率:{accuracy.item():.4f}")其中:
• model.eval() 表示进入评估模式
• torch.no_grad() 表示评估时不计算梯度
• torch.sigmoid() 把 logit 转换为概率
• test_probs ≥ 0.5 表示以 0.5 为阈值判断类别
• accuracy 表示测试集准确率
训练阶段需要计算梯度,评估阶段不需要。因此,评估时使用 torch.no_grad() 可以减少额外计算开销。
7、绘制损失变化曲线
apache
plt.figure(figsize=(8, 5))plt.plot(loss_history)plt.title("前馈神经网络训练损失变化")plt.xlabel("训练轮次")plt.ylabel("损失值")plt.show()输出示意图:
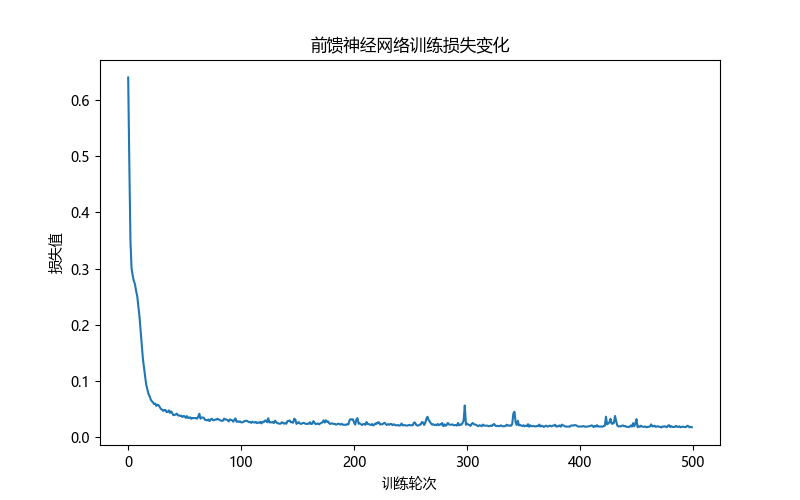
图 7:训练损失变化曲线
如果模型正常训练,通常可以看到损失值整体下降。不过,损失下降并不一定意味着模型泛化能力一定变好,因此实际任务中还需要观察验证集或测试集表现。
8、可视化非线性分类边界
为了更直观地观察模型学到的分类规则,可以绘制分类边界。
python
# 1. 构造二维网格x_min, x_max = X_test[:, 0].min().item() - 1, X_test[:, 0].max().item() + 1y_min, y_max = X_test[:, 1].min().item() - 1, X_test[:, 1].max().item() + 1
xx, yy = np.meshgrid( np.linspace(x_min, x_max, 300), np.linspace(y_min, y_max, 300))
grid = np.c_[xx.ravel(), yy.ravel()]grid_tensor = torch.tensor(grid, dtype=torch.float32)
# 2. 预测网格中每个点的类别model.eval()
with torch.no_grad(): logits = model(grid_tensor) probs = torch.sigmoid(logits) Z = (probs >= 0.5).float().numpy().reshape(xx.shape)
# 3. 绘制分类边界plt.figure(figsize=(8, 5))plt.contourf(xx, yy, Z, levels=[-0.5, 0.5, 1.5], alpha=0.3)plt.scatter( X_test[:, 0].numpy(), X_test[:, 1].numpy(), c=y_test.view(-1).numpy(), edgecolors="k")plt.title("前馈神经网络学习到的非线性分类边界")plt.xlabel("特征 1")plt.ylabel("特征 2")plt.show()输出示意图:
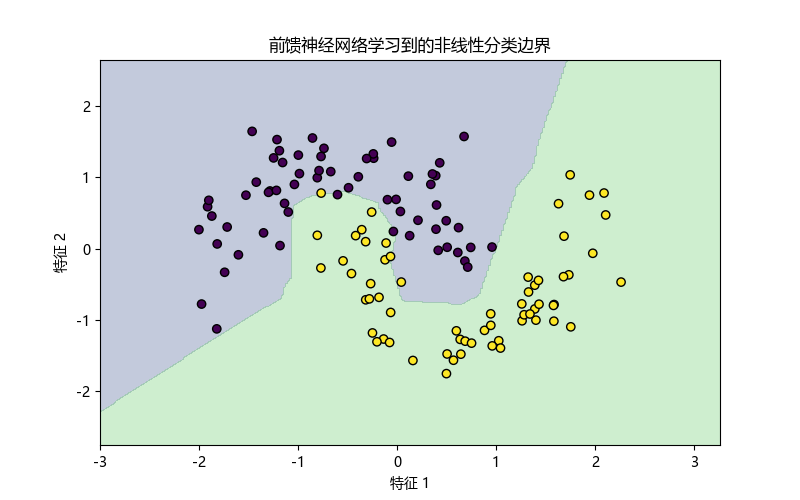
图 8:前馈神经网络学习到的非线性分类边界
从图中可以看到,前馈神经网络并不局限于学习直线边界。通过隐藏层和非线性激活函数,它可以学习弯曲的、非线性的分类边界。
这正是前馈神经网络相比简单线性模型更强的地方。
八、前馈神经网络的适用场景、局限与扩展方向
前馈神经网络是深度学习中最基础的模型之一。它结构清晰、实现简单,适合用来理解深度学习的核心训练机制。
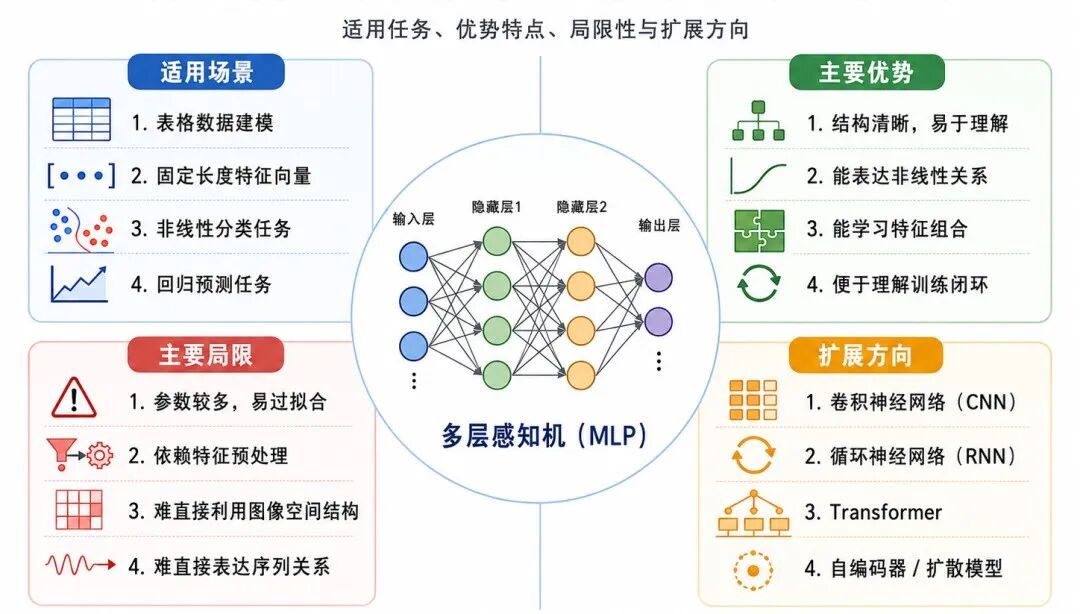
图 9:前馈神经网络的适用场景、局限与扩展方向
1、适用场景
前馈神经网络较适合处理已经表示为固定长度向量的数据,尤其适用于存在非线性关系的分类和回归任务。
典型场景包括:
• 表格数据分类
• 表格数据回归
• 用户流失预测
• 信用风险评估
• 低维非线性分类
• 已经提取特征后的多分类任务
• 作为复杂神经网络中的基础模块
对于小规模、低维或已经提取好特征的任务,MLP 可以作为一个基础模型。
2、主要优势
前馈神经网络的主要优势包括:
• 结构清晰,容易理解
• 能表达非线性关系
• 可用于分类和回归任务
• 能自动学习特征组合
• 与 PyTorch 等深度学习框架结合紧密
• 是理解 CNN、RNN、Transformer 等复杂模型的基础
尤其重要的是,前馈神经网络展示了深度学习最核心的训练机制:
前向传播 → 损失计算 → 反向传播 → 参数更新
理解了这个闭环,就更容易理解后续更复杂的深度学习模型。
3、主要局限
前馈神经网络也有明显局限:
• 对特征尺度较敏感
• 参数较多时容易过拟合
• 训练效果依赖学习率、网络结构等超参数
• 对图像、文本、序列等结构化模式利用不充分
• 可解释性通常弱于线性模型和决策树
• 小数据场景下不一定优于传统机器学习方法
例如,在图像任务中,普通 MLP 通常会把图像像素展平成一维向量,这会破坏图像的空间结构。因此,卷积神经网络更适合处理原始图像。
在文本和时间序列任务中,普通 MLP 也难以直接表达顺序关系。因此,循环神经网络、Transformer 等结构更适合处理序列和上下文关系。
4、扩展方向
前馈神经网络是许多复杂模型的基础。
与普通 MLP 相比:
• 卷积神经网络更擅长处理图像和空间结构
• 循环神经网络更强调序列中的时间依赖关系
• Transformer 更擅长建模长距离依赖和上下文关系
• 自编码器常用于表示学习、降维和重构任务
• 扩散模型常用于生成式任务
因此,学习前馈神经网络并不是只学习一个模型,而是在学习深度学习的基本工作方式。
📘 小结
前馈神经网络通过多层"线性变换 + 非线性激活"学习复杂映射,并以"前向传播---损失计算---反向传播---参数更新"构成训练闭环。MLP 是其典型形式,PyTorch 则通过自动微分和优化器简化了模型训练过程,是继续学习 CNN、RNN、Transformer 的重要基础。

"点赞有美意,赞赏是鼓励"