目录
[4.1.3 应用层面上传参和返回值](#4.1.3 应用层面上传参和返回值)
[5. 分离线程:](#5. 分离线程:)
[6. C++ thread VS pthread](#6. C++ thread VS pthread)
[7. 认识和理解线程库](#7. 认识和理解线程库)
[7.1 理解线程的源码](#7.1 理解线程的源码)
[7.2 线程栈](#7.2 线程栈)
[8. 线程的封装](#8. 线程的封装)
[9. 页表和页表项](#9. 页表和页表项)
4.1.3 应用层面上传参和返回值
cpp
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>
void *start_routine(void *args)
{
std::string name = static_cast<const char *>(args);
while (true)
{
std::cout << "我是一个新线程," << pthread_self() << "threadname is :" << name << std::endl;
sleep(1);
break;
}
return (void*)11;
}
int main()
{
pthread_t tid; // 未来pthread库中,表明线程控制块的起始地址
pthread_create(&tid, nullptr, start_routine, (void *)"thread-1");
void *ret = nullptr;
// void * 也是要占用空间的,void本身是不能来定义变量的,会报错,因为void的大小是不明确的
// 但是void*大小是明确的,32位大小是4字节,64位大小是8字节
pthread_join(tid, &ret);
std::cout << "join sucess: "<< (long long int)(ret) << std::endl;
}运行结果:

参数是void *,意味着可以传递任意类型,结构体对象也是可以传递的
cpp
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>
class Task
{
public:
Task():_x(0), _y(0), _result(0), _code(0)
{}
Task(int x, int y):_x(x), _y(y), _result(0), _code(0)
{}
void Div()
{
if(_y == 0)
{
_code = 1; //表示除0了
return;
}
_result = _x / _y;
}
void Print()
{
std::cout << "result: " << _result << " [code:" << _code << "]" << std::endl;
}
private:
int _x;
int _y;
int _result; //表示计算结果
int _code; //表示结果是否可信:1不可信,0可信
};
void *start_routine(void *args)
{
Task *t = static_cast<Task*>(args);
t->Div();
sleep(2);
// return (void *)11; // 给线程返回??
return t;
}
int main()
{
pthread_t tid; // 未来pthread库中,表明线程控制块的起始地址
// 给线程传参
Task *t = new Task(30, 5);
pthread_create(&tid, nullptr, start_routine, t);
void *ret = nullptr;
// void * 也是要占用空间的,void本身是不能来定义变量的,会报错,因为void的大小是不明确的
// 但是void*大小是明确的,32位大小是4字节,64位大小是8字节
pthread_join(tid, &ret);
Task *result = (Task*)ret;
std::cout << "join sucess: " << (long long int)(ret) << std::endl;
result->Print();
return 0;
}运行结果:

可以看见,code为0,说明这个计算结果是可信的,
cpp
Task *t = new Task(30, 0);
可以看见,code为1,说明这个结算结果是不可信的。
上面的代码,说明给线程传参的时候不一定传递内置类型,传递类、结构体这样的对象都是可以的,返回的值也不一定是内置类型,结构体对象也是可以的。

5. 分离线程:
- **默认情况下,新创建的线程是joinable的,线程退出后,需要对其进行pthread_join操作,否则无法释放资源,从而造成系统泄露。**类似的僵尸进程的问题,注意没有僵尸线程这样的问题,因为僵尸进程是在内核中这样的概念,因为线程没有在内核里,而是在库当中。
- 创建一个线程,在该线程是可以创建线程的 。又因为线程不是由另一个线程创建的 (线程A之所以能创建线程B,不是因为线程A自己有"资格",而是因为线程A属于这个进程),线程是由进程创建的。所有线程是进程内部的一个执行分支,任何线程都是可以创建其它线程的。线程的归属是进程,而不是创建它的那个线程。(了解,但是不提倡线程创建线程,因为会很混乱)
- 如果不关心线程的返回值,join是一种负担,这个时候,我们可以告诉系统,当线程退出时,自动释放线程资源。
pthread_detach():
可以是线程组内其它线程对目标线程进行分离,也可以是线程自己分离,一旦分离了就不要pthread_join() 了,即使pthread_join() 了,pthread_join() 也会失败:
cpp
pthread_detach(pthread_self());joinable 和 分离式是冲突的,一个线程不能既是joinable又是分离的。
cpp
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>
void *start_routine(void *args)
{
pthread_detach(pthread_self());
std::string name = static_cast<const char *>(args);
while (true)
{
std::cout << "我是一个新线程," << pthread_self() << "threadname is :" << name << std::endl;
sleep(1);
break;
}
sleep(2);
return (void *)11; // 给线程返回??
}
int main()
{
pthread_t tid; // 未来pthread库中,表明线程控制块的起始地址
pthread_create(&tid, nullptr, start_routine, (void*)"thread-1");
sleep(2); //保证先让新线程分离之后,再join
void *ret = nullptr;
int n = pthread_join(tid, &ret);
std::cout << "join sucess: " << (long long int)(ret) << " n: " << n << std::endl;
return 0;
}运行结果:


join() 失败了的。
cpp
std::cout << "join sucess: " << (long long int)(ret) << " n: " << n << ", "<< strerror(n)<< std::endl;
注意:线程分离,不需要join()。上面的分离之后又join()的原因是为了告诉我们:线程分离,不需要join()。因为join()会报错。
cpp
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>
#include <cstring>
void *start_routine(void *args)
{
// pthread_detach(pthread_self());
std::string name = static_cast<const char *>(args);
while (true)
{
std::cout << "我是一个新线程," << pthread_self() << "threadname is :" << name << std::endl;
sleep(1);
break;
}
sleep(2);
return (void *)11; // 给线程返回??
}
int main()
{
pthread_t tid; // 未来pthread库中,表明线程控制块的起始地址
pthread_create(&tid, nullptr, start_routine, (void*)"thread-1");
pthread_detach(tid);
return 0;
}线程分离的场景:
- 主线程是处理某种任务的死循环
- 分离线程的时候可以是主线程分离新线程,也可以是新线程自己把自己分离
创建的新线程处于死循环,不结束,主线程:pthread_cancel();
cpp
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>
#include <cstring>
void *start_routine(void *args)
{
std::string name = static_cast<const char *>(args);
while (true)
{
std::cout << "我是一个新线程," << pthread_self() << "threadname is :" << name << std::endl;
sleep(1);
}
// t->Div();
sleep(2);
return (void *)11; // 给线程返回??
}
int main()
{
pthread_t tid; // 未来pthread库中,表明线程控制块的起始地址
pthread_create(&tid, nullptr, start_routine, (void*)"thread-1");
sleep(2);
pthread_cancel(tid);
void *ret = nullptr;
std::cout << "join sucess: " << (long long int)(ret) << " n: " << n << ", "<< strerror(n)<< std::endl;
return 0;
}
证明了,一个线程默认是joinable的,即便是在线程被取消的情况下,也是可以被 join 成功的,join 成功对应的返回值ret是 -1。所以如果一个线程被取消,线程的退出信息类似就被设置为 -1。
cpp
PTHREAD_CANCELED;
//转到定义:
#define PTHREAD_CANCELED ((void *) -1)一个线程是被取消的,线程库会自动将该线程的退出码设置为 -1,也就是这个宏值:PTHREAD_CANCELED; 最终被表明取消了。
3.3 C++11 thread vs pthread 的区别
将系统知识和语言知识相结合:
C++如何实现多线程:
cpp
#include <iostream>
#include <string>
// #include <pthread.h>
#include <thread>
#include <unistd.h>
#include <cstring>
void run()
{
while(true)
{
std::cout << "我是一个新线程" << std::endl;
sleep(1);
}
}
int main()
{
std::thread t(run);
t.join();
return 0;
}
在Linux当中运行C++的库,必须得引用pthread库,代码才能够编过
运行结果:
用的是C++的多线程:
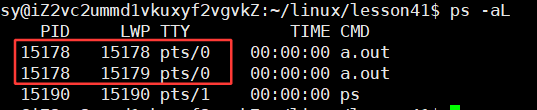
C++用到的多线程本质上在Linux中,也是两个轻量级的进程。
6. C++ thread VS pthread

C++ 要在Linux中跑的话,必须对pthread库做封装!!!因为OS不提供所谓的线程接口,只提供轻量级接口。
C++既然在Linux当中对线程做了封装,macos下呢???unix下呢???windows???C++多线程 vs 平台支持多线程??


7. 认识和理解线程库
7.1 理解线程的源码
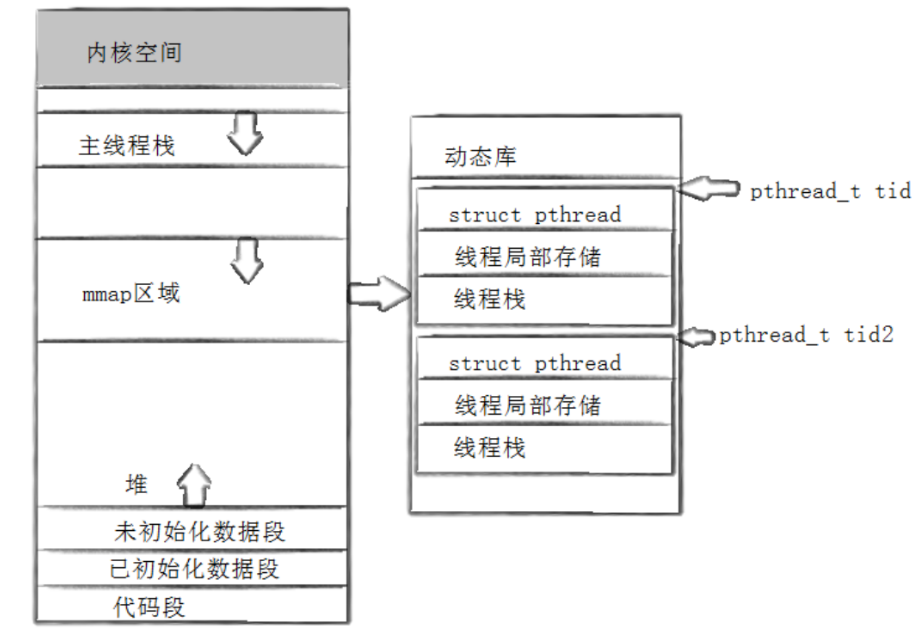
mmap是用来做地址空间映射的一个函数。

将指定的文件打开,从指定的偏移量处,映射指定的长度到一个虚拟地址。将动态库建立好之后,使用mmap这样的函数将动态库映射到地址空间里。
- 线程必须在库当中体现出来。2. 库必须先描述,再组织。将所有的线程给维护起来。
宏观:
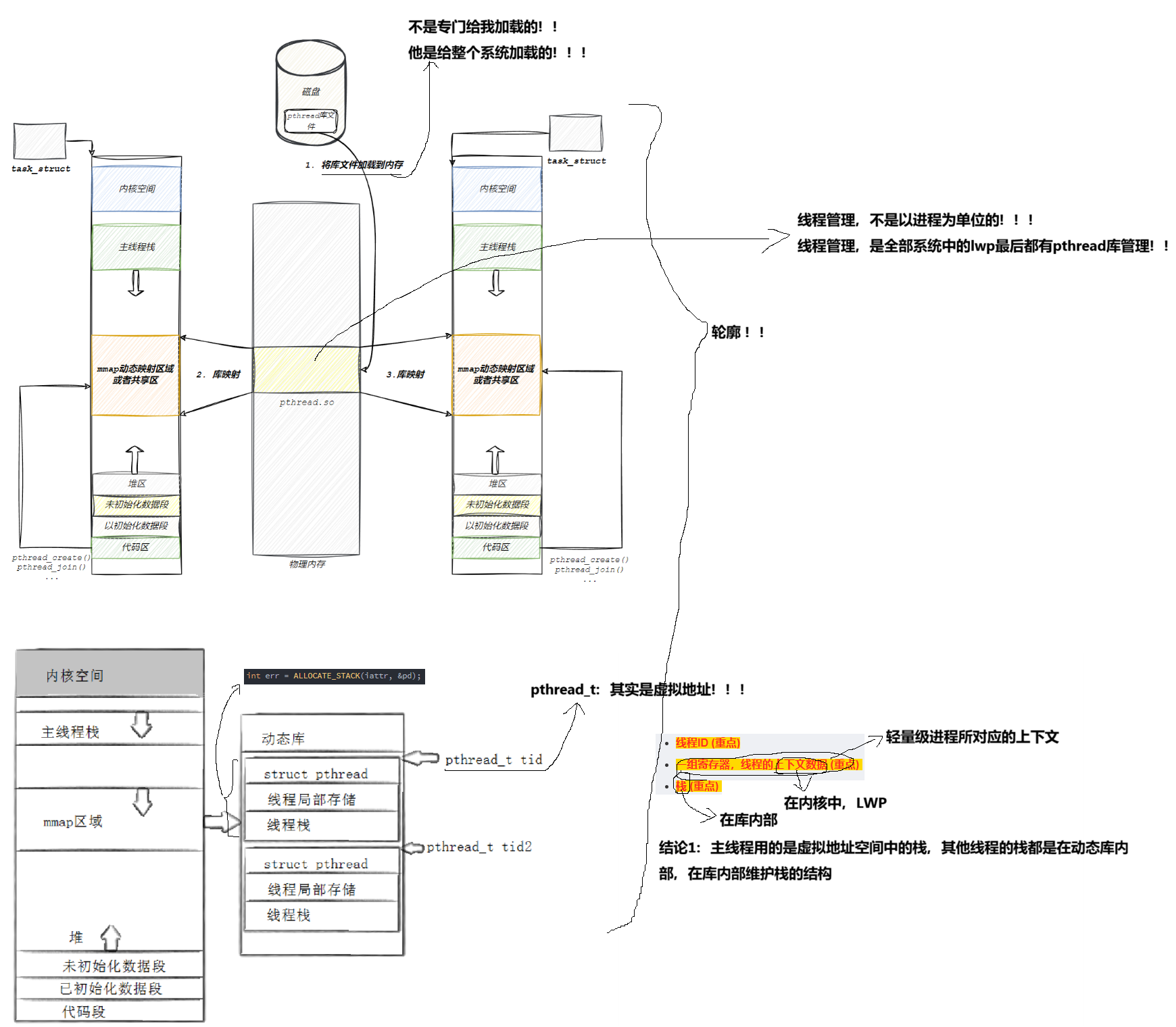
细节:
以下是 glibc-2.4 中 pthread 源码相关内容:
路径: nptl/pthread_create.c
cpp
int __pthread_create_2_1(newthread, attr, start_routine, arg)
pthread_t *newthread;
const pthread_attr_t *attr;
void *(*start_routine)(void *);
void *arg;
{
STACK_VARIABLES;
// 重点1: 线程属性,虽然我们不设置,但是不妨碍我们了解
const struct pthread_attr *iattr = (struct pthread_attr *)attr;
if (iattr == NULL)
/* Is this the best idea? On NUMA machines this could mean
accessing far-away memory. */
iattr = &default_attr;
// 重点2:传说中的原⽣线程库中的⽤来描述线程的tcb
struct pthread *pd = NULL;
// 重点3: ALLOCATE_STACK会在先申请struct pthread对象,当然其实是申请⼀⼤块空间,
// struct pthread在空间的开头,⼀会追
int err = ALLOCATE_STACK(iattr, &pd);
if (__builtin_expect(err != 0, 0))
/* Something went wrong. Maybe a parameter of the attributes is
invalid or we could not allocate memory. */
versioned_symbol return err;
/* Initialize the TCB. All initializations with zero should be
performed in 'get_cached_stack'. This way we avoid doing this ifthe stack freshly allocated with 'mmap'. */
#ifdef TLS_TCB_AT_TP
/* Reference to the TCB itself. */
pd->header.self = pd;
/* Self-reference for TLS. */
pd->header.tcb = pd;
#endif
/* Store the address of the start routine and the parameter. Since
we do not start the function directly the stillborn thread will
get the information from its thread descriptor. */
// 重点4:向线程tcb中设置未来要执⾏的⽅法的地址和参数
pd->start_routine = start_routine;
pd->arg = arg;
/* Copy the thread attribute flags. */
struct pthread *self = THREAD_SELF;
pd->flags = ((iattr->flags & ~(ATTR_FLAG_SCHED_SET | ATTR_FLAG_POLICY_SET)) | (self->flags & (ATTR_FLAG_SCHED_SET | ATTR_FLAG_POLICY_SET)));
/* Initialize the field for the ID of the thread which is waiting
for us. This is a self-reference in case the thread is created
detached. */
pd->joinid = iattr->flags & ATTR_FLAG_DETACHSTATE ? pd : NULL;
/* The debug events are inherited from the parent. */
pd->eventbuf = self->eventbuf;
/* Copy the parent's scheduling parameters. The flags will say what
is valid and what is not. */
pd->schedpolicy = self->schedpolicy;
pd->schedparam = self->schedparam;
/* Copy the stack guard canary. */
#ifdef THREAD_COPY_STACK_GUARD
THREAD_COPY_STACK_GUARD(pd);
#endif
/* Copy the pointer guard value. */
#ifdef THREAD_COPY_POINTER_GUARD
THREAD_COPY_POINTER_GUARD(pd);
#endif
// ⼀堆参数设定,我们不关⼼
/* Determine scheduling parameters for the thread. */
if (attr != NULL && __builtin_expect((iattr->flags & ATTR_FLAG_NOTINHERITSCHED) != 0, 0) && (iattr->flags & (ATTR_FLAG_SCHED_SET | ATTR_FLAG_POLICY_SET)) != 0)
{
INTERNAL_SYSCALL_DECL(scerr);
/* Use the scheduling parameters the user provided. */
if (iattr->flags & ATTR_FLAG_POLICY_SET)
pd->schedpolicy = iattr->schedpolicy;
else if ((pd->flags & ATTR_FLAG_POLICY_SET) == 0)
{
pd->schedpolicy = INTERNAL_SYSCALL(sched_getscheduler, scerr, 1, 0);
pd->flags |= ATTR_FLAG_POLICY_SET;
}
if (iattr->flags & ATTR_FLAG_SCHED_SET)
memcpy(&pd->schedparam, &iattr->schedparam,
sizeof(struct sched_param));
else if ((pd->flags & ATTR_FLAG_SCHED_SET) == 0)
{
INTERNAL_SYSCALL(sched_getparam, scerr, 2, 0, &pd->schedparam);
pd->flags |= ATTR_FLAG_SCHED_SET;
}
/* Check for valid priorities. */
int minprio = INTERNAL_SYSCALL(sched_get_priority_min, scerr, 1,
iattr->schedpolicy);
int maxprio = INTERNAL_SYSCALL(sched_get_priority_max, scerr, 1,
iattr->schedpolicy);
if (pd->schedparam.sched_priority < minprio || pd -
> schedparam.sched_priority > maxprio)
{
err = EINVAL;
goto errout;
}
}
/* Pass the descriptor to the caller. */
// 重点5:把pd(就是线程控制块地址)作为ID,传递出去,所以上层拿到的就是⼀个虚拟地址
*newthread = (pthread_t)pd;
/* Remember whether the thread is detached or not. In case of an
error we have to free the stacks of non-detached stillborn
threads. */
// 重点6: 检测线程属性是否分离,这个很好理解
bool is_detached = IS_DETACHED(pd);
/* Start the thread. */
err = create_thread(pd, iattr, STACK_VARIABLES_ARGS); // 重点函数
if (err != 0)
{
/* Something went wrong. Free the resources. */
if (!is_detached)
{
errout:
__deallocate_stack(pd);
}
return err;
}
return 0;
}
// 版本确认信息,意思就是如果⽤的库是GLIBC_2_1,pthread_create函数就是__pthread_create_2_1
versioned_symbol(libpthread, __pthread_create_2_1, pthread_create, GLIBC_2_1);线程属性:
cpp
struct pthread_attr
{
/* Scheduler parameters and priority. */
struct sched_param schedparam;
int schedpolicy;
/* Various flags like detachstate, scope, etc. */
int flags;
/* Size of guard area. */
size_t guardsize;
/* Stack handling. */
void *stackaddr;
size_t stacksize;
/* Affinity map. */
cpu_set_t *cpuset;
size_t cpusetsize;
};线程tcb:
cpp
/* Thread descriptor data structure. */
struct pthread
{
union
{
#if !TLS_DTV_AT_TP
/* This overlaps the TCB as used for TLS without threads (see tls.h). */
tcbhead_t header;
#else
struct
{
int multiple_threads;
} header;
#endif
/* This extra padding has no special purpose, and this structure layout
is private and subject to change without affecting the official ABI.
We just have it here in case it might be convenient for some
implementation-specific instrumentation hack or suchlike. */
void *__padding[16];
};
/* This descriptor's link on the `stack_used' or `__stack_user' list. */
list_t list; //pthread用链表连接起来
/* Thread ID - which is also a 'is this thread descriptor (and
therefore stack) used' flag. */
pid_t tid;
/* Process ID - thread group ID in kernel speak. */
pid_t pid;
/* List of robust mutexes the thread is holding. */
#ifdef __PTHREAD_MUTEX_HAVE_PREV
__pthread_list_t robust_list;
#define ENQUEUE_MUTEX(mutex) \
do \
{ \
__pthread_list_t *next = THREAD_GETMEM(THREAD_SELF, robust_list.__next);
next->__prev = &mutex->__data.__list;
mutex->__data.__list.__next = next;
mutex->__data.__list.__prev = &THREAD_SELF->robust_list;
THREAD_SETMEM(THREAD_SELF, robust_list.__next, &mutex->__data.__list);
} while (0)
#define DEQUEUE_MUTEX(mutex) \
do \
{ \
mutex->__data.__list.__next->__prev = mutex->__data.__list.__prev;
mutex->__data.__list.__prev->__next = mutex->__data.__list.__next;
mutex->__data.__list.__prev = NULL;
mutex->__data.__list.__next = NULL;
}
while (0)
#else
__pthread_slist_t robust_list;
#define ENQUEUE_MUTEX(mutex) \
do \
{ \
mutex->__data.__list.__next = THREAD_GETMEM(THREAD_SELF, robust_list.__next); \
THREAD_SETMEM(THREAD_SELF, robust_list.__next, &mutex->__data.__list);
} while (0)
#define DEQUEUE_MUTEX(mutex) \
do \
{ \
__pthread_slist_t *runp = THREAD_GETMEM (THREAD_SELF,
robust_list.__next);
if (runp == &mutex->__data.__list)
THREAD_SETMEM(THREAD_SELF, robust_list.__next, runp->__next);
else
{
while (runp->__next != &mutex->__data.__list)
runp = runp->__next;
runp->__next = runp->__next->__next;
mutex->__data.__list.__next = NULL;
}
}
while (0)
#endif
/* List of cleanup buffers. */
struct _pthread_cleanup_buffer *cleanup;
/* Unwind information. */
struct pthread_unwind_buf *cleanup_jmp_buf;
#define HAVE_CLEANUP_JMP_BUF
/* Flags determining processing of cancellation. */
int cancelhandling;
/* Bit set if cancellation is disabled. */
#define CANCELSTATE_BIT 0
#define CANCELSTATE_BITMASK 0x01
/* Bit set if asynchronous cancellation mode is selected. */
#define CANCELTYPE_BIT 1
#define CANCELTYPE_BITMASK 0x02
/* Bit set if canceling has been initiated. */
#define CANCELING_BIT 2
#define CANCELING_BITMASK 0x04
/* Bit set if canceled. */
#define CANCELED_BIT 3
#define CANCELED_BITMASK 0x08
/* Bit set if thread is exiting. */
#define EXITING_BIT 4
#define EXITING_BITMASK 0x10
/* Bit set if thread terminated and TCB is freed. */
#define TERMINATED_BIT 5
#define TERMINATED_BITMASK 0x20
/* Bit set if thread is supposed to change XID. */
#define SETXID_BIT 6
#define SETXID_BITMASK 0x40
/* Mask for the rest. Helps the compiler to optimize. */
#define CANCEL_RESTMASK 0xffffff80
#define CANCEL_ENABLED_AND_CANCELED(value) \
(((value) & (CANCELSTATE_BITMASK | CANCELED_BITMASK | EXITING_BITMASK
| CANCEL_RESTMASK | TERMINATED_BITMASK)) == CANCELED_BITMASK)
#define CANCEL_ENABLED_AND_CANCELED_AND_ASYNCHRONOUS(value) \
(((value) & (CANCELSTATE_BITMASK | CANCELTYPE_BITMASK | CANCELED_BITMASK
\
| EXITING_BITMASK | CANCEL_RESTMASK | TERMINATED_BITMASK)) \
== (CANCELTYPE_BITMASK | CANCELED_BITMASK))
/* We allocate one block of references here. This should be enough
to avoid allocating any memory dynamically for most applications. */
struct pthread_key_data
{
/* Sequence number. We use uintptr_t to not require padding on
32- and 64-bit machines. On 64-bit machines it helps to avoid
wrapping, too. */
uintptr_t seq;
/* Data pointer. */
void *data;
} specific_1stblock[PTHREAD_KEY_2NDLEVEL_SIZE];
/* Two-level array for the thread-specific data. */
struct pthread_key_data *specific[PTHREAD_KEY_1STLEVEL_SIZE];
/* Flag which is set when specific data is set. */
bool specific_used;
/* True if events must be reported. */
bool report_events;
/* True if the user provided the stack. */
bool user_stack; //用户栈
/* True if thread must stop at startup time. */
bool stopped_start;
/* Lock to synchronize access to the descriptor. */
lll_lock_t lock;
/* Lock for synchronizing setxid calls. */
lll_lock_t setxid_futex;
#if HP_TIMING_AVAIL
/* Offset of the CPU clock at start thread start time. */
hp_timing_t cpuclock_offset;
#endif
/* If the thread waits to join another one the ID of the latter is
stored here.
In case a thread is detached this field contains a pointer of the
TCB if the thread itself. This is something which cannot happen
in normal operation. */
struct pthread *joinid;
/* Check whether a thread is detached. */
#define IS_DETACHED(pd) ((pd)->joinid == (pd))
/* Flags. Including those copied from the thread attribute. */
int flags;
/* The result of the thread function. */
// 线程运⾏完毕,返回值就是void*, 最后的返回值就放在tcb中的该变量⾥⾯
// 所以我们⽤pthread_join获取线程退出信息的时候,就是读取该结构体
// 另外,要能理解线程执⾏流可以退出,但是tcb可以暂时保留,这句话
void *result;
/* Scheduling parameters for the new thread. */
struct sched_param schedparam;
int schedpolicy;
/* Start position of the code to be executed and the argument passed
to the function. */
// ⽤⼾指定的⽅法和参数
void *(*start_routine)(void *);
void *arg;
/* Debug state. */
td_eventbuf_t eventbuf;
/* Next descriptor with a pending event. */
struct pthread *nextevent;
#ifdef HAVE_FORCED_UNWIND
/* Machine-specific unwind info. */
struct _Unwind_Exception exc;
#endif
/* If nonzero pointer to area allocated for the stack and its
size. */
// 线程⾃⼰的栈和⼤⼩
void *stackblock;
size_t stackblock_size;
/* Size of the included guard area. */
size_t guardsize;
/* This is what the user specified and what we will report. */
size_t reported_guardsize;
/* Resolver state. */
struct __res_state res;
/* This member must be last. */
char end_padding[];
#define PTHREAD_STRUCT_END_PADDING \
(sizeof(struct pthread) - offsetof(struct pthread, end_padding))
}
__attribute((aligned(TCB_ALIGNMENT)));create_thread:
cpp
tatic int
create_thread(struct pthread *pd, const struct pthread_attr *attr,
STACK_VARIABLES_PARMS)
{
#ifdef TLS_TCB_AT_TP
assert(pd->header.tcb != NULL);
#endif
/* We rely heavily on various flags the CLONE function understands:
CLONE_VM, CLONE_FS, CLONE_FILES
These flags select semantics with shared address space and
file descriptors according to what POSIX requires.
CLONE_SIGNAL
This flag selects the POSIX signal semantics.
CLONE_SETTLS
The sixth parameter to CLONE determines the TLS area for the
new thread.
CLONE_PARENT_SETTID
The kernels writes the thread ID of the newly created thread
into the location pointed to by the fifth parameters to CLONE.
Note that it would be semantically equivalent to use
CLONE_CHILD_SETTID but it is be more expensive in the kernel.
CLONE_CHILD_CLEARTID
The kernels clears the thread ID of a thread that has called
sys_exit() in the location pointed to by the seventh parameter
to CLONE.
CLONE_DETACHED
No signal is generated if the thread exists and it is
automatically reaped.
The termination signal is chosen to be zero which means no signal
is sent. */
int clone_flags = (CLONE_VM | CLONE_FS | CLONE_FILES | CLONE_SIGNAL | CLONE_SETTLS | CLONE_PARENT_SETTID | CLONE_CHILD_CLEARTID | CLONE_SYSVSEM
#if __ASSUME_NO_CLONE_DETACHED == 0
| CLONE_DETACHED
#endif
| 0);
if (__builtin_expect(THREAD_GETMEM(THREAD_SELF, report_events), 0))
{
/* The parent thread is supposed to report events. Check whether
the TD_CREATE event is needed, too. */
const int _idx = __td_eventword(TD_CREATE);
const uint32_t _mask = __td_eventmask(TD_CREATE);
if ((_mask & (__nptl_threads_events.event_bits[_idx] | pd->eventbuf.eventmask.event_bits[_idx])) != 0)
{
/* We always must have the thread start stopped. */
pd->stopped_start = true;
/* Create the thread. We always create the thread stopped
so that it does not get far before we tell the debugger. */
int res = do_clone(pd, attr, clone_flags, start_thread,
STACK_VARIABLES_ARGS, 1);
if (res == 0)
{
/* Now fill in the information about the new thread in
the newly created thread's data structure. We cannot let
the new thread do this since we don't know whether it was
already scheduled when we send the event. */
pd->eventbuf.eventnum = TD_CREATE;
pd->eventbuf.eventdata = pd;
/* Enqueue the descriptor. */
do
pd->nextevent = __nptl_last_event;
while (atomic_compare_and_exchange_bool_acq(&__nptl_last_event,
pd, pd->nextevent) != 0);
/* Now call the function which signals the event. */
__nptl_create_event();
/* And finally restart the new thread. */
lll_unlock(pd->lock);
}
return res;
}
}
#ifdef NEED_DL_SYSINFO
assert(THREAD_SELF_SYSINFO == THREAD_SYSINFO(pd));
#endif
/* Determine whether the newly created threads has to be started
stopped since we have to set the scheduling parameters or set the
affinity. */
bool stopped = false;
if (attr != NULL && (attr->cpuset != NULL || (attr->flags &
ATTR_FLAG_NOTINHERITSCHED) != 0))
stopped = true;
pd->stopped_start = stopped;
/* Actually create the thread. */
int res = do_clone(pd, attr, clone_flags, start_thread,
STACK_VARIABLES_ARGS, stopped);
if (res == 0 && stopped)
/* And finally restart the new thread. */
lll_unlock(pd->lock);
return res;
}do_clone:
cpp
static int
do_clone(struct pthread *pd, const struct pthread_attr *attr,
int clone_flags, int (*fct)(void *), STACK_VARIABLES_PARMS,
int stopped)
{
#ifdef PREPARE_CREATE
PREPARE_CREATE;
#endif
if (stopped)
/* We Make sure the thread does not run far by forcing it to get a
lock. We lock it here too so that the new thread cannot continue
until we tell it to. */
lll_lock(pd->lock);
/* One more thread. We cannot have the thread do this itself, since it
might exist but not have been scheduled yet by the time we've returned
and need to check the value to behave correctly. We must do it before
creating the thread, in case it does get scheduled first and then
might mistakenly think it was the only thread. In the failure case,
we momentarily store a false value; this doesn't matter because there
is no kosher thing a signal handler interrupting us right here can do
that cares whether the thread count is correct. */
atomic_increment(&__nptl_nthreads);
// 执⾏特性体系结构下的clone函数
if (ARCH_CLONE(fct, STACK_VARIABLES_ARGS, clone_flags,
pd, &pd->tid, TLS_VALUE, &pd->tid) == -1)
{
atomic_decrement(&__nptl_nthreads); /* Oops, we lied for a second. */
/* Failed. If the thread is detached, remove the TCB here sincethe caller cannot do this. The caller remembered the thread
as detached and cannot reverify that it is not since it must
not access the thread descriptor again. */
if (IS_DETACHED(pd))
__deallocate_stack(pd);
return errno;
}
/* Now we have the possibility to set scheduling parameters etc. */
// 下⾯是调⽤相关系统调⽤,设置轻量级进程的调度参数和⼀些异常处理,不关⼼
if (__builtin_expect(stopped != 0, 0))
{
INTERNAL_SYSCALL_DECL(err);
int res = 0;
/* Set the affinity mask if necessary. */
if (attr->cpuset != NULL)
{
res = INTERNAL_SYSCALL(sched_setaffinity, err, 3, pd->tid,
sizeof(cpu_set_t), attr->cpuset);
if (__builtin_expect(INTERNAL_SYSCALL_ERROR_P(res, err), 0))
{
/* The operation failed. We have to kill the thread. First
send it the cancellation signal. */
INTERNAL_SYSCALL_DECL(err2);
err_out:
#if __ASSUME_TGKILL
(void)INTERNAL_SYSCALL(tgkill, err2, 3,
THREAD_GETMEM(THREAD_SELF, pid),
pd->tid, SIGCANCEL);
#else
(void)INTERNAL_SYSCALL(tkill, err2, 2, pd->tid, SIGCANCEL);
#endif
return (INTERNAL_SYSCALL_ERROR_P(res, err)
? INTERNAL_SYSCALL_ERRNO(res, err)
: 0);
}
}
/* Set the scheduling parameters. */
if ((attr->flags & ATTR_FLAG_NOTINHERITSCHED) != 0)
{
res = INTERNAL_SYSCALL(sched_setscheduler, err, 3, pd->tid, pd->schedpolicy, &pd->schedparam);
if (__builtin_expect(INTERNAL_SYSCALL_ERROR_P(res, err), 0))
goto err_out;
}
}
/* We now have for sure more than one thread. The main thread might
not yet have the flag set. No need to set the global variable
again if this is what we use. */
THREAD_SETMEM(THREAD_SELF, header.multiple_threads, 1);
return 0;
}
cpp
#define ARCH_CLONE __clone
// __clone是glibc⽤汇编封装的⼀个调⽤clone系统调⽤的函数,所以
// __clone的实现就是汇编,贴⼀份代码(sysdeps unix / sysv / linux / x86_64): ENTRY(BP_SYM(__clone))
ENTRY (BP_SYM (__clone))
/* Sanity check arguments. */
movq $-EINVAL,%rax
testq %rdi,%rdi /* no NULL function pointers */
jz SYSCALL_ERROR_LABEL
testq %rsi,%rsi /* no NULL stack pointers */
jz SYSCALL_ERROR_LABEL
/* Insert the argument onto the new stack. */
subq $16,%rsi
movq %rcx,8(%rsi)
/* Save the function pointer. It will be popped off in the
child in the ebx frobbing below. */
movq %rdi,0(%rsi)
/* Do the system call. */
movq %rdx, %rdi
movq %r8, %rdx
movq %r9, %r8
movq 8(%rsp), %r10
movl $SYS_ify(clone),%eax // 获取系统调⽤号
/* End FDE now, because in the child the unwind info will be
wrong. */
cfi_endproc;
syscall // 陷⼊内核(x86_32是int 80),要求内核创建轻量级进程
testq %rax,%rax
jl SYSCALL_ERROR_LABEL
jz L(thread_start)
// 这部分代码了解即可。下⾯我们看⼀下空间申请: int err = ALLOCATE_STACK(iattr, &pd);
cpp
// 源码路径:nptl / allocatestack.c
// 空间申请的函数,其实就是⼀个宏
#define ALLOCATE_STACK(attr, pd) \
allocate_stack(attr, pd, &stackaddr, &stacksize)
static int
allocate_stack(const struct pthread_attr *attr, struct pthread **pdp,
ALLOCATE_STACK_PARMS)
{
struct pthread *pd;
size_t size;
size_t pagesize_m1 = __getpagesize() - 1;
void *stacktop;
assert(attr != NULL);
assert(powerof2(pagesize_m1 + 1));
assert(TCB_ALIGNMENT >= STACK_ALIGN);
/* Get the stack size from the attribute if it is set. Otherwise we
use the default we determined at start time. */
size = attr->stacksize ?: __default_stacksize; // 获取栈⼤⼩,⽤⼾没设置就默认
/* Get memory for the stack. */
// 如果已经⽤⼾已经在线程属性⾥⾯设置了空间,就直接⽤,我们是默认,这部分代码直接不看
if (__builtin_expect(attr->flags & ATTR_FLAG_STACKADDR, 0))
{
uintptr_t adj;
/* If the user also specified the size of the stack make sure it
is large enough. */
if (attr->stacksize != 0 && attr->stacksize < (__static_tls_size +
MINIMAL_REST_STACK))
return EINVAL;
/* Adjust stack size for alignment of the TLS block. */
#if TLS_TCB_AT_TP
adj = ((uintptr_t)attr->stackaddr - TLS_TCB_SIZE) & __static_tls_align_m1;
assert(size > adj + TLS_TCB_SIZE);
#elif TLS_DTV_AT_TP
adj = ((uintptr_t)attr->stackaddr - __static_tls_size) &
__static_tls_align_m1;
assert(size > adj);
#endif
/* The user provided some memory. Let's hope it matches the
size... We do not allocate guard pages if the user provided
the stack. It is the user's responsibility to do this if it
is wanted. */
#if TLS_TCB_AT_TP
pd = (struct pthread *)((uintptr_t)attr->stackaddr - TLS_TCB_SIZE - adj);
#elif TLS_DTV_AT_TP
pd = (struct pthread *)(((uintptr_t)attr->stackaddr - __static_tls_size -
adj) -
TLS_PRE_TCB_SIZE);
#endif
/* The user provided stack memory needs to be cleared. */
memset(pd, '\0', sizeof(struct pthread));
/* The first TSD block is included in the TCB. */
pd->specific[0] = pd->specific_1stblock;
/* Remember the stack-related values. */
pd->stackblock = (char *)attr->stackaddr - size;
pd->stackblock_size = size;
/* This is a user-provided stack. It will not be queued in the
stack cache nor will the memory (except the TLS memory) be freed. */
pd->user_stack = true;
/* This is at least the second thread. */
pd->header.multiple_threads = 1;
#ifndef TLS_MULTIPLE_THREADS_IN_TCB
__pthread_multiple_threads = *__libc_multiple_threads_ptr = 1;
#endif
#ifdef NEED_DL_SYSINFO
/* Copy the sysinfo value from the parent. */
THREAD_SYSINFO(pd) = THREAD_SELF_SYSINFO;
#endif
/* The process ID is also the same as that of the caller. */
pd->pid = THREAD_GETMEM(THREAD_SELF, pid);
/* List of robust mutexes. */
#ifdef __PTHREAD_MUTEX_HAVE_PREV
pd->robust_list.__prev = &pd->robust_list;
#endif
pd->robust_list.__next = &pd->robust_list;
/* Allocate the DTV for this thread. */
if (_dl_allocate_tls(TLS_TPADJ(pd)) == NULL)
{
/* Something went wrong. */
assert(errno == ENOMEM);
return EAGAIN;
}
/* Prepare to modify global data. */
lll_lock(stack_cache_lock);
/* And add to the list of stacks in use. */
list_add(&pd->list, &__stack_user);
lll_unlock(stack_cache_lock);
}
else
{
// 下⾯的都是库内部⾃⼰做的,我们关⼼的
/* Allocate some anonymous memory. If possible use the cache. */
size_t guardsize;
size_t reqsize;
void *mem;
const int prot = (PROT_READ | PROT_WRITE | ((GL(dl_stack_flags) & PF_X) ? PROT_EXEC : 0));
#if COLORING_INCREMENT != 0
/* Add one more page for stack coloring. Don't do it for stacks
with 16 times pagesize or larger. This might just cause
unnecessary misalignment. */
if (size <= 16 * pagesize_m1)
size += pagesize_m1 + 1;
#endif
/* Adjust the stack size for alignment. */
size &= ~__static_tls_align_m1; // 设置空间对⻬
assert(size != 0);
/* Make sure the size of the stack is enough for the guard and
eventually the thread descriptor. */
guardsize = (attr->guardsize + pagesize_m1) & ~pagesize_m1;
if (__builtin_expect(size < ((guardsize + __static_tls_size +
MINIMAL_REST_STACK + pagesize_m1) &
~pagesize_m1),
0))
/* The stack is too small (or the guard too large). */
return EINVAL;
/* Try to get a stack from the cache. */
// 先尝试从pthread缓存中申请空间
reqsize = size;
pd = get_cached_stack(&size, &mem);
if (pd == NULL)
{
/* To avoid aliasing effects on a larger scale than pages we
adjust the allocated stack size if necessary. This way
allocations directly following each other will not have
aliasing problems. */
#if MULTI_PAGE_ALIASING != 0
if ((size % MULTI_PAGE_ALIASING) == 0)
size += pagesize_m1 + 1;
#endif
// 缓存申请失败,就在堆空间申请私有的匿名内存空间,这⾥mmap类似malloc
// 当然他也可以作为共享内存的实现,类似原理我们接触过,这个功能和当前⽆关
mem = mmap(NULL, size, prot,
MAP_PRIVATE | MAP_ANONYMOUS | ARCH_MAP_FLAGS, -1, 0);
if (__builtin_expect(mem == MAP_FAILED, 0))
{
#ifdef ARCH_RETRY_MMAP
mem = ARCH_RETRY_MMAP(size);
if (__builtin_expect(mem == MAP_FAILED, 0))
#endif
return errno;
}
/* SIZE is guaranteed to be greater than zero.
So we can never get a null pointer back from mmap. */
assert(mem != NULL);
#if COLORING_INCREMENT != 0
/* Atomically increment NCREATED. */
unsigned int ncreated = atomic_increment_val(&nptl_ncreated);
/* We chose the offset for coloring by incrementing it for
every new thread by a fixed amount. The offset used
module the page size. Even if coloring would be better
relative to higher alignment values it makes no sense to
do it since the mmap() interface does not allow us to
specify any alignment for the returned memory block. */
size_t coloring = (ncreated * COLORING_INCREMENT) & pagesize_m1;
/* Make sure the coloring offsets does not disturb the alignment
of the TCB and static TLS block. */
if (__builtin_expect((coloring & __static_tls_align_m1) != 0, 0))
coloring = (((coloring + __static_tls_align_m1) & ~(__static_tls_align_m1)) & ~pagesize_m1);
#else
/* Unless specified we do not make any adjustments. */
#define coloring 0
#endif
/* Place the thread descriptor at the end of the stack. */
// 下⾯的代码其实就是此篇文章中的图,这⾥是在申请的空间中确定struct
thread(tcb) 的地址
#if TLS_TCB_AT_TP
pd = (struct pthread *)((char *)mem + size - coloring) - 1;
#elif TLS_DTV_AT_TP
pd = (struct pthread *)((((uintptr_t)mem + size - coloring -
__static_tls_size) &
~__static_tls_align_m1) -
TLS_PRE_TCB_SIZE);
#endif
/* Remember the stack-related values. */
// 记录下来整个空间的地址和⼤⼩
pd->stackblock = mem;
pd->stackblock_size = size;
/* We allocated the first block thread-specific data array.
This address will not change for the lifetime of this
descriptor. */
pd->specific[0] = pd->specific_1stblock;
/* This is at least the second thread. */
pd->header.multiple_threads = 1;
#ifndef TLS_MULTIPLE_THREADS_IN_TCB
__pthread_multiple_threads = *__libc_multiple_threads_ptr = 1;
#endif
#ifdef NEED_DL_SYSINFO
/* Copy the sysinfo value from the parent. */
THREAD_SYSINFO(pd) = THREAD_SELF_SYSINFO;
#endif
/* The process ID is also the same as that of the caller. */
// 获取线程对应进程的pid
pd->pid = THREAD_GETMEM(THREAD_SELF, pid);
/* List of robust mutexes. */
#ifdef __PTHREAD_MUTEX_HAVE_PREV
pd->robust_list.__prev = &pd->robust_list;
#endif
pd->robust_list.__next = &pd->robust_list;
/* Allocate the DTV for this thread. */
if (_dl_allocate_tls(TLS_TPADJ(pd)) == NULL)
{
/* Something went wrong. */
assert(errno == ENOMEM);
/* Free the stack memory we just allocated. */
(void)munmap(mem, size);
return EAGAIN;
}
/* Prepare to modify global data. */
lll_lock(stack_cache_lock);
/* And add to the list of stacks in use. */
list_add(&pd->list, &stack_used);
lll_unlock(stack_cache_lock);
/* There might have been a race. Another thread might have
caused the stacks to get exec permission while this new
stack was prepared. Detect if this was possible and
change the permission if necessary. */
if (__builtin_expect((GL(dl_stack_flags) & PF_X) != 0 && (prot &
PROT_EXEC) == 0,
0))
{
int err = change_stack_perm(pd
#ifdef NEED_SEPARATE_REGISTER_STACK
,
~pagesize_m1
#endif
);
if (err != 0)
{
/* Free the stack memory we just allocated. */
(void)munmap(mem, size);
return err;
}
}
/* Note that all of the stack and the thread descriptor is
zeroed. This means we do not have to initialize fields
with initial value zero. This is specifically true for
the 'tid' field which is always set back to zero once the
stack is not used anymore and for the 'guardsize' field
which will be read next. */
}
/* Create or resize the guard area if necessary. */
if (__builtin_expect(guardsize > pd->guardsize, 0))
{
#ifdef NEED_SEPARATE_REGISTER_STACK
char *guard = mem + (((size - guardsize) / 2) & ~pagesize_m1);
#else
char *guard = mem;
#endif
if (mprotect(guard, guardsize, PROT_NONE) != 0)
{
int err;
mprot_error:
err = errno;
lll_lock(stack_cache_lock);
/* Remove the thread from the list. */
list_del(&pd->list);
lll_unlock(stack_cache_lock);
/* Get rid of the TLS block we allocated. */
_dl_deallocate_tls(TLS_TPADJ(pd), false);
/* Free the stack memory regardless of whether the size
of the cache is over the limit or not. If this piece
of memory caused problems we better do not use it
anymore. Uh, and we ignore possible errors. There
is nothing we could do. */
(void)munmap(mem, size);
return err;
}
pd->guardsize = guardsize;
}
else if (__builtin_expect(pd->guardsize - guardsize > size - reqsize,
0))
{
/* The old guard area is too large. */
#ifdef NEED_SEPARATE_REGISTER_STACK
char *guard = mem + (((size - guardsize) / 2) & ~pagesize_m1);
char *oldguard = mem + (((size - pd->guardsize) / 2) & ~pagesize_m1);
if (oldguard < guard && mprotect(oldguard, guard - oldguard, prot) != 0)
goto mprot_error;
if (mprotect(guard + guardsize,
oldguard + pd->guardsize - guard - guardsize,
prot) != 0)
goto mprot_error;
#else
if (mprotect((char *)mem + guardsize, pd->guardsize - guardsize,
prot) != 0)
goto mprot_error;
#endif
pd->guardsize = guardsize;
}
/* The pthread_getattr_np() calls need to get passed the size
requested in the attribute, regardless of how large the
actually used guardsize is. */
pd->reported_guardsize = guardsize;
}
/* Initialize the lock. We have to do this unconditionally since the
stillborn thread could be canceled while the lock is taken. */
pd->lock = LLL_LOCK_INITIALIZER;
/* We place the thread descriptor at the end of the stack. */
// ⼆级指针,返回struct thread的地址,其实就是⼀个堆快的地址,对⽐之前的⽰意图
*pdp = pd;
#if TLS_TCB_AT_TP
/* The stack begins before the TCB and the static TLS block. */
stacktop = ((char *)(pd + 1) - __static_tls_size);
#elif TLS_DTV_AT_TP
stacktop = (char *)(pd - 1);
#endif
#ifdef NEED_SEPARATE_REGISTER_STACK
*stack = pd->stackblock;
*stacksize = stacktop - *stack;
#else
*stack = stacktop;
#endif
return 0;
}
// 所以,在创建线程的时候,其实就是在pthread库内部,创建好描述线程的结构体对象,填充属性
// 第⼆步就是调⽤clone,让内核创建轻量级进程,并执⾏传⼊的回调函数和参数
// 其实,库提供的⽆⾮就是未来操作线程的API,通过属性设置线程的优先级之类,⽽真正调度的
// 过程,还是内核来的。
// 但是如果我们⾃⼰在上层,设计⼀些让线程暂停出让CPU,然后我们上次⾃定义队列,让线程的tcb进⾏排队
// 那么我们其实也可以基于内核,在⽤⼾层实现线程的调度,很多更⾼级的语⾔,可能会做这个⼯作。7.2 线程栈
虽然 Linux 将线程和进程不加区分的统⼀到了 task_struct ,但是对待其地址空间的 stack 还是有些区别的。
- 对于 Linux 进程或者说主线程,简单理解就是main函数的栈空间,在fork的时候,实际上就是复制了⽗亲的 stack 空间地址,然后写时拷⻉(cow)以及动态增⻓。如果扩充超出该上限则栈溢出会报段错误(发送段错误信号给该进程)。进程栈是唯⼀可以访问未映射⻚⽽不⼀定会发⽣段错误⸺超出扩充上限才报。
- 然⽽对于主线程⽣成的⼦线程⽽⾔,其 stack 将不再是向下⽣⻓的,⽽是事先固定下来的。线程栈⼀般是调⽤glibc/uclibc等的 pthread 库接⼝ pthread_create 创建的线程,在⽂件映射区(或称之为共享区)。其中使⽤ mmap 系统调⽤,这个可以从 glibc 的nptl/allocatestack.c 中的 allocate_stack 函数中看到:
mem = mmap ( NULL , size, prot,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_STACK, -1 , 0 );
此调⽤中的 size 参数的获取很是复杂,你可以⼿⼯传⼊stack的⼤⼩,也可以使⽤默认的,⼀般⽽⾔就是默认的 8M 。这些都不重要,重要的是,这种stack不能动态增⻓,⼀旦⽤尽就没了,这是和⽣成进程的fork不同的地⽅。在glibc中通过mmap得到了stack之后,底层将调⽤ sys_clone 系统调⽤:
cpp
int sys_clone(struct pt_regs *regs)
{
unsigned long clone_flags;
unsigned long newsp;
int __user *parent_tidptr, *child_tidptr;
clone_flags = regs->bx;
// 获取了mmap得到的线程的stack指针
newsp = regs->cx;
parent_tidptr = (int __user *)regs->dx;
child_tidptr = (int __user *)regs->di;
if (!newsp)
newsp = regs->sp;
return do_fork(clone_flags, newsp, regs, 0, parent_tidptr,
child_tidptr);
}因此,对于⼦线程的 stack ,它其实是在进程的地址空间中map出来的⼀块内存区域,原则上是线程私有的,但是同⼀个进程的所有线程⽣成的时候,是会浅拷⻉⽣成者的 task_struct 的很多字段,如果愿意,其它线程也还是可以访问到的,⼀定要注意。
线程局部存储:
cpp
#include <iostream>
#include <string>
// #include <pthread.h>
#include <thread>
#include <unistd.h>
#include <cstring>
std::string ToHex(void *addr)
{
char addrbuffer[64];
snprintf(addrbuffer, 64, "%p", addr);
return addrbuffer;
}
int gval = 0;
void *start_routine(void *args)
{
std::string name = static_cast<const char *>(args);
while (true)
{
std::cout << "我是一个新线程," << pthread_self() << "threadname is: " << name
<< ",gval: " << gval << "," << "&gval: " << ToHex(&gval) << std::endl;
gval++;
sleep(1);
// break;
}
sleep(2);
return (void *)11; // 给线程返回??
}
int main()
{
pthread_t tid; // 未来pthread库中,表明线程控制块的起始地址
pthread_create(&tid, nullptr, start_routine, (void *)"thread-1");
sleep(2);
while (true)
{
sleep(1);
std::cout << "我是一个主线程," << pthread_self() << "threadname is : main"
<< ",gval: " << gval << "," << "&gval: " << ToHex(&gval) << std::endl;
}
void *ret = nullptr;
int n = pthread_join(tid, &ret); // 线程被取消,返回值是-1,#define PTHREAD_CANCELED ((void *) -1)
std::cout << "join sucess: " << (long long int)(ret) << " n: " << n << ", " << strerror(n) << std::endl;
return 0;
}运行结果:
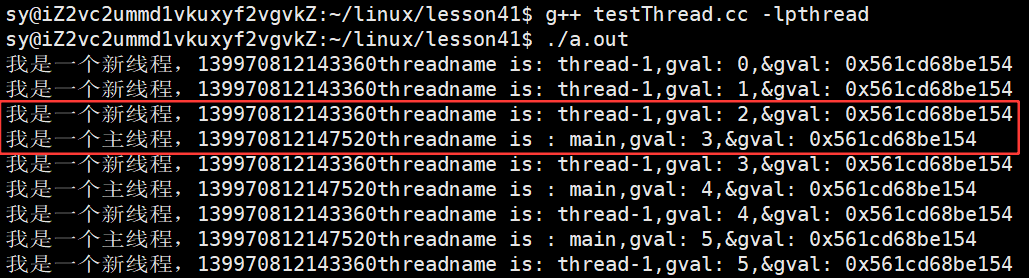
主线程和新线程访问的是同一个全局变量!
cpp
std::string ToHex(void *addr)
{
char addrbuffer[64];
snprintf(addrbuffer, 64, "%p", addr);
return addrbuffer;
}
__thread int gval = 0; //全局变量,给每个线程都是各自私有的,但是每个线程会以全局方式访问这个全局变量
//需求:新线程也想要自己的"全局变量",只想自己看到
void *start_routine(void *args)
{
// pthread_detach(pthread_self());
std::string name = static_cast<const char *>(args);
// Task *t = static_cast<Task*>(args);
while (true)
{
std::cout << "我是一个新线程," << pthread_self() << "threadname is: " << name
<< ",gval: " << gval << "," << "&gval: " << ToHex(&gval) << std::endl;
gval++;
sleep(1);
// break;
}
// t->Div();
sleep(2);
return (void *)11; // 给线程返回??
// return t;
}运行结果:

从运行结果中可以看出,在语法上确实是全局的!此变量貌似有两个了,用到了不同的虚拟地址!!说明其实gval在编译时,已经被拆成两个了。
__thread : 属于gcc/g++编译器的提供的编译的修饰符,内置选项,让gval成为每一个线程的局部存储!!!是编译器做的!!
所有的全局变量其实根本就没有申请空间,我们理解的是在内存中申请,程序都没加载到内存中,内存都没加载好是申请不了空间的,其实全局变量申请空间都会转换为汇编语句,加载内存时,加载内存时在内存中就会将空间开辟好,这就是为什么全局变量全局有效,加载的时候就创建了。将全局变量给每一个线程都拷贝一份,存储在线程局部存储中。变量名最终都会变为地址。
线程局部存储往往是用来保存内置类型的数据!!

系统调用号:

cpp
#include <iostream>
#include <string>
// #include <pthread.h>
#include <thread>
#include <unistd.h>
#include <cstring>
#include <sys/syscall.h>
#define get_lwp_id() syscall(SYS_gettid)
std::string ToHex(void *addr)
{
char addrbuffer[64];
snprintf(addrbuffer, 64, "%p", addr);
return addrbuffer;
}
//__thread : 属于gcc/g++编译器的提供的编译的修饰符,内置选项,让gval成为每一个线程的局部存储!!!是编译器做的!!
__thread int lwpid = 0; //全局变量,给每个线程都是各自私有的,但是每个线程会以全局方式访问这个全局变量
//需求:新线程也想要自己的"全局变量",只想自己看到
void *start_routine(void *args)
{
lwpid = get_lwp_id();
std::string name = static_cast<const char *>(args);
while (true)
{
std::cout << "我是一个新线程," << pthread_self() << "threadname is: " << name
<< ",lwpid: " << lwpid << "," << "&gval: " << ToHex(&lwpid) << std::endl;
sleep(1);
}
sleep(2);
return (void *)11; // 给线程返回??
}
int main()
{
lwpid = get_lwp_id();
pthread_t tid; // 未来pthread库中,表明线程控制块的起始地址
pthread_create(&tid, nullptr, start_routine, (void *)"thread-1");
// pthread_detach(tid);
while (true)
{
sleep(1);
std::cout << "我是一个主线程," << pthread_self() << "threadname is : main"
<< ",lwpid: " << lwpid << "," << "&gval: " << ToHex(&lwpid) << std::endl;
}
return 0;
}运行结果:
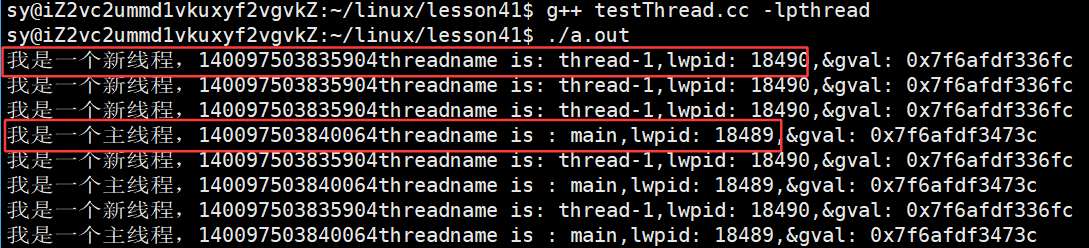

8. 线程的封装
以面向对象的方式来控制线程

类类成员函数,包含一个当前对象的this指针。
static 去掉了this指针。
单线程:
cpp
//Thread.hpp
#ifndef __THREAD_HPP
#define __THREAD_HPP
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>
#include <functional>
#include <sys/syscall.h>
#define get_lwp_id() syscall(SYS_gettid)
using func_t = std::function<void()>;
const std::string threadnamedefault = "None-name";
class Thread
{
public:
Thread(func_t func, const std::string &name = threadnamedefault):_name(name),_func(func), _isrunning(false)
{
}
static void *start_routine(void *args)
{
Thread *self = static_cast<Thread*>(args);
self->_isrunning = true;
self->_lwpid = get_lwp_id();
self->_func();
pthread_exit((void*)0);
}
void Start()
{
int n = pthread_create(&_tid, nullptr, start_routine, this);
if(n == 0)
{
std::cout << "create thread success" << std::endl;
}
}
//Join() --- 检测线程结束并且回收的功能
void Join()
{
if(!_isrunning)
return;
int n = pthread_join(_tid, nullptr);
if(n == 0)
{
std::cout << "pthread_join success" << std::endl;
}
}
~Thread()
{}
private:
bool _isrunning;
pthread_t _tid;
pid_t _lwpid;
std::string _name;
func_t _func;
};
#endif
cpp
//testThread.cc
#include <iostream>
#include <vector>
#include "Thread.hpp"
void test()
{
int cnt = 5;
while(cnt--)
{
std::cout << "新线程运行了" << std::endl;
sleep(1);
}
}
int main()
{
//单个线程
Thread t(test,"Thread-1");
t.Start();
t.Join();
}运行结果:
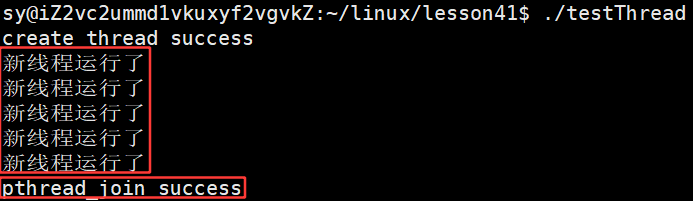
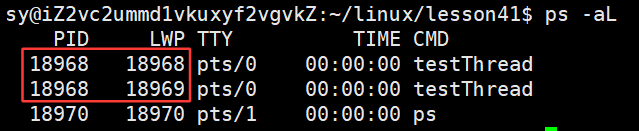
多线程:
cpp
//Thread.hpp
#ifndef __THREAD_HPP
#define __THREAD_HPP
#include <iostream>
#include <string>
#include <pthread.h>
#include <unistd.h>
#include <functional>
#include <sys/syscall.h>
#define get_lwp_id() syscall(SYS_gettid)
using func_t = std::function<void()>;
const std::string threadnamedefault = "None-name";
class Thread
{
public:
Thread(func_t func, const std::string &name = threadnamedefault):_name(name),_func(func), _isrunning(false)
{
std::cout << "create obj thread success" << std::endl;
}
static void *start_routine(void *args)
{
Thread *self = static_cast<Thread*>(args);
self->_isrunning = true;
self->_lwpid = get_lwp_id();
self->_func();
pthread_exit((void*)0);
}
void Start()
{
int n = pthread_create(&_tid, nullptr, start_routine, this);
if(n == 0)
{
std::cout << "run thread success" << std::endl;
}
}
//Join() --- 检测线程结束并且回收的功能
void Join()
{
if(!_isrunning)
return;
int n = pthread_join(_tid, nullptr);
if(n == 0)
{
std::cout << "pthread_join success" << std::endl;
}
}
~Thread()
{}
private:
bool _isrunning;
pthread_t _tid;
pid_t _lwpid;
std::string _name;
func_t _func;
};
#endif
cpp
//testThread.cc
#include <iostream>
#include <vector>
#include "Thread.hpp"
void test()
{
int cnt = 5;
while (cnt--)
{
std::cout << "新线程运行了" << std::endl;
sleep(1);
}
}
int main()
{
// 多个线程,管理线程:先描述,再组织!
std::vector<Thread> threads;
for (int i = 0; i < 5; i++)
{
std::string name = "thread-";
name += std::to_string(i + 1);
Thread t(test, name);
threads.push_back(t);
}
for (auto &thread : threads)
{
thread.Start();
}
for (auto &thread : threads)
{
thread.Join();
}
}运行结果:
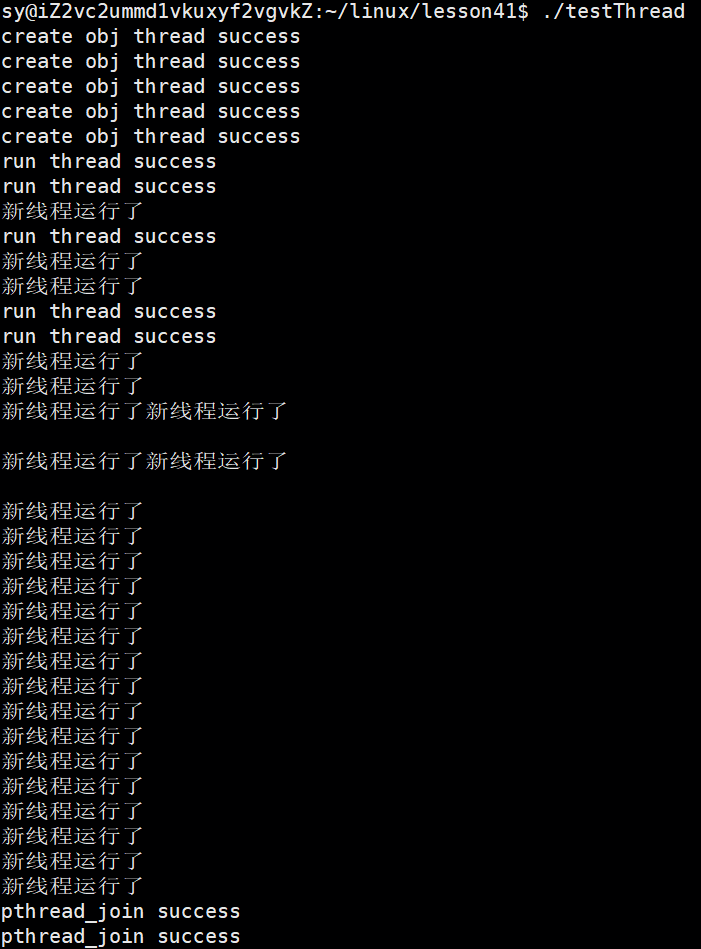
9. 页表和页表项
cpp
* We keep two sets of PTEs - the hardware and the linux version.
* This allows greater flexibility in the way we map the Linux bits
* onto the hardware tables, and allows us to have YOUNG and DIRTY
* bits.
*
* The PTE table pointer refers to the hardware entries; the "Linux"
* entries are stored 1024 bytes below.
*/
// ⻚表标志位
#define L_PTE_PRESENT (1 << 0)
#define L_PTE_FILE (1 << 1) /* only when !PRESENT */
#define L_PTE_YOUNG (1 << 1)
#define L_PTE_BUFFERABLE (1 << 2) /* matches PTE */
#define L_PTE_CACHEABLE (1 << 3) /* matches PTE */
#define L_PTE_USER (1 << 4)
#define L_PTE_WRITE (1 << 5)
#define L_PTE_EXEC (1 << 6)
#define L_PTE_DIRTY (1 << 7)
#define L_PTE_COHERENT (1 << 9) /* I/O coherent (xsc3) */
#define L_PTE_SHARED (1 << 10) /* shared between CPUs (v6) */
#define L_PTE_ASID (1 << 11) /* non-global (use ASID, v6) */
// ⻚表是?
typedef struct { unsigned long pte; } pte_t; // ⻚表项 --- 无符号长整数
typedef struct { unsigned long pgd; } pgd_t; // ⻚全局⽬录项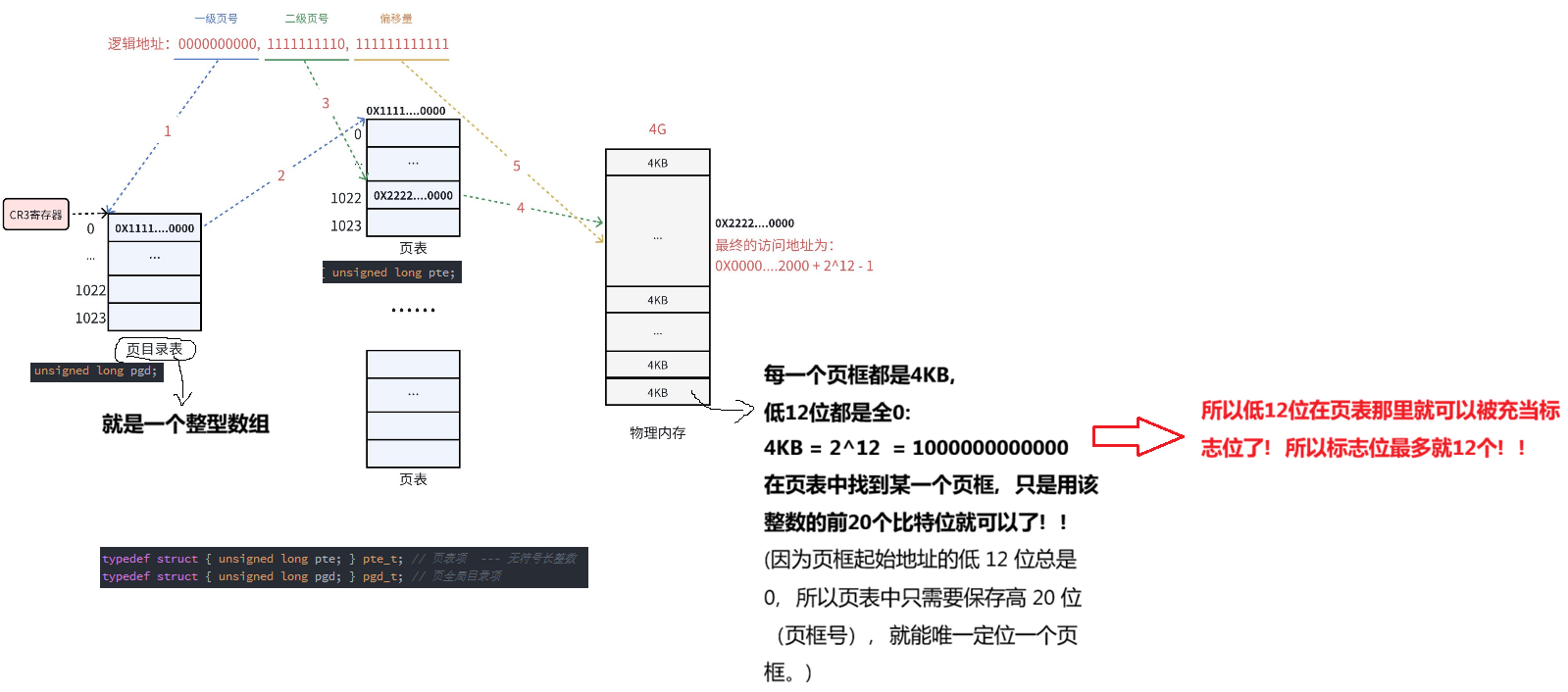
页目录表和页表时1024的整型数组,1024的整型数组就是4KB,所以页目录表和页表最终每一种表结构占用一个页框!!!页目录表全部指向下一级的页表的起始地址,页表内每一项20个比特位表示页框地址,剩下12个标记位保证对应的页表指向页框的属性了。
虚拟地址中的低12位是做偏移量。页表内并不会存储,不需要在页表当中存储。
总结:
页目录表和页表都是4KB的,表项都是无符号长整数的,页目录表会保存所有页表的起始地址,页表的前20位比特位用来表示页框地址的,后12位作为标记位,表示页框的状态。
struct page不是已经表示了页框的状态了嘛?struct page先申请空间时,就将属性填充好了。而后12位作为标记位,表示页框的状态就是从page中来的。为什么还要在页框中再写一份呢?这种权限审核,状态审核呀!都可以通过软硬件统一来完成,保存在页表中,转换的时候,因为有很多功能是由硬件来完成的,所以效率会比较高!!!如果只保存在page中,就只能通过软件来完成了。所以也在页表中维护,是为了增加效率!!!
cpp
pgd_t*
pgd_alloc(struct mm_struct* mm)
{
pgd_t* ret, * init;
ret = (pgd_t*)__get_free_page(GFP_KERNEL | __GFP_ZERO);
init = pgd_offset(&init_mm, 0UL);
if (ret) {
#ifdef CONFIG_ALPHA_LARGE_VMALLOC
memcpy(ret + USER_PTRS_PER_PGD, init + USER_PTRS_PER_PGD,
(PTRS_PER_PGD - USER_PTRS_PER_PGD - 1) * sizeof(pgd_t));
#else
pgd_val(ret[PTRS_PER_PGD - 2]) = pgd_val(init[PTRS_PER_PGD - 2]);
#endif
/* The last PGD entry is the VPTB self-map. */
pgd_val(ret[PTRS_PER_PGD - 1])
= pte_val(mk_pte(virt_to_page(ret), PAGE_KERNEL));
}
return ret;
}
pte_t*
pte_alloc_one_kernel(struct mm_struct* mm, unsigned long address)
{
pte_t* pte = (pte_t*)__get_free_page(GFP_KERNEL | __GFP_REPEAT | __GFP_ZERO);
return pte;
}
struct mm_struct {
struct vm_area_struct* mmap; /* list of VMAs */
struct rb_root mm_rb;
struct vm_area_struct* mmap_cache; /* last find_vma result */
unsigned long (*get_unmapped_area) (struct file* filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
void (*unmap_area) (struct mm_struct* mm, unsigned long addr);
unsigned long mmap_base; /* base of mmap area */
unsigned long task_size; /* size of task vm space */
unsigned long cached_hole_size; /* if non-zero, the largest hole
below free_area_cache */
unsigned long free_area_cache; /* first hole of size
cached_hole_size or larger */
pgd_t* pgd; // ⻚⽬录起始地址
}