对于许多团队来说,有效的错误追踪是确保应用稳定性的起点。如今的开发者构建和维护的应用横跨前端、后端、浏览器和移动端------每一层都会产生可能影响性能和用户体验的错误。当这些信息分散在日志、APM 和 RUM 等多个工具中时,追踪和解决错误就变得极具挑战性:你需要手动关联 Trace ID、查找同一时间段的日志、确认影响的用户范围。碎片化的调试流程让开发者难以关联应用不同部分的问题,导致解决速度变慢、关键 Bug 被遗漏,以及停机时间增加。
真实场景:当 999+ 封报错邮件来袭
你的邮箱被报错邮件塞满:NullPointerException...Connection Timeout...TypeError: Cannot read property... 同一个 Bug 触发了上千次告警,你在不同系统间切换时发现:APM 里显示的错误堆栈不完整,日志里的错误缺少 Trace ID,RUM 里的用户报错又无法关联到后端异常。你花了 40 分钟在几个 Tab 之间玩拼图游戏,依然没搞清楚:这到底是同一个问题的重复告警,还是多个独立的故障?影响多少用户?该不该叫醒团队?
这是开发团队的日常。
为了解决这些挑战,观测云错误中心为团队提供了一个贯穿前后端系统的单一真实数据源。它自动汇总 APM、RUM 和日志中的错误,通过智能指纹算法聚类为错误根因(Issue),并关联完整的链路、日志和用户会话上下文。这让开发者能够快速识别关键问题、加速根因定位、防止已修复问题复发,真正将"修复关键错误"从混乱的救火变成标准化的流程。
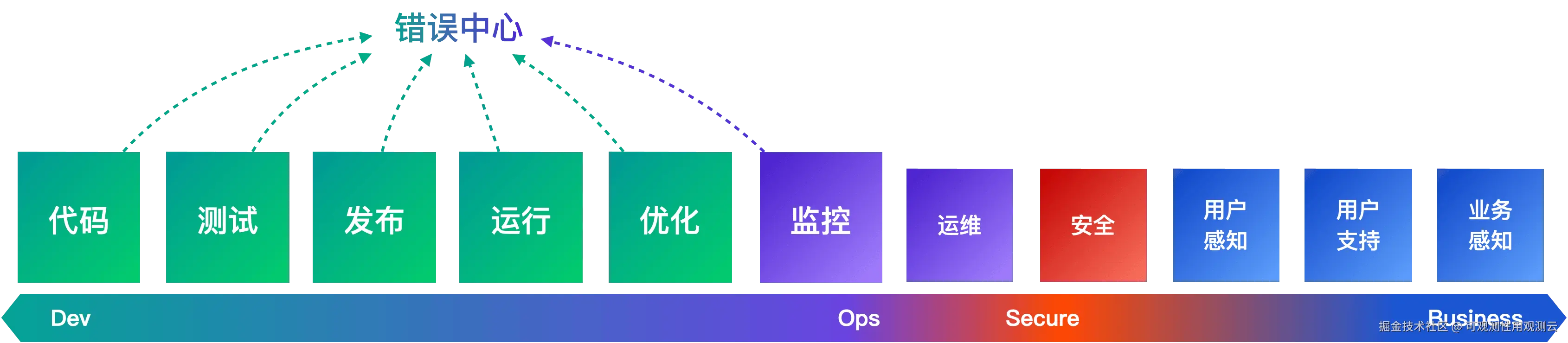
在本文中,我们将介绍观测云错误中心如何通过统一视图帮助团队处理应用和服务前后端的问题:
- 快速识别并优先处理最关键的错误
- 通过全栈可见性加速故障排查
- 主动检测并防止问题复发
01|快速识别并优先处理错误根因
需求背景
想象你开车时仪表盘亮起"发动机故障灯"------这就是错误 (Error),它告诉你车有问题,但可能还能开。在观测云里,Error 是具体的异常实例:后端抛出的 NullPointerException、前端报的 TypeError、或是日志里的 Connection Timeout。
特点:错误(Error)是持续的、重复的。同一个 Bug 可能每分钟触发 100 次 Error,但真正需要修复的根因(Issue)其实只有一个。
随着应用复杂度增加,开发者往往要面对前端、后端和移动端组件中越来越多的错误。如果没有区分次要问题和高影响问题的方法,团队就会在嘈杂的告警中浪费时间,而非处理真正重要的错误。当错误分散在多个工具中时,识别某个问题是新增、复发还是正在恶化就变得困难。
观测云解法
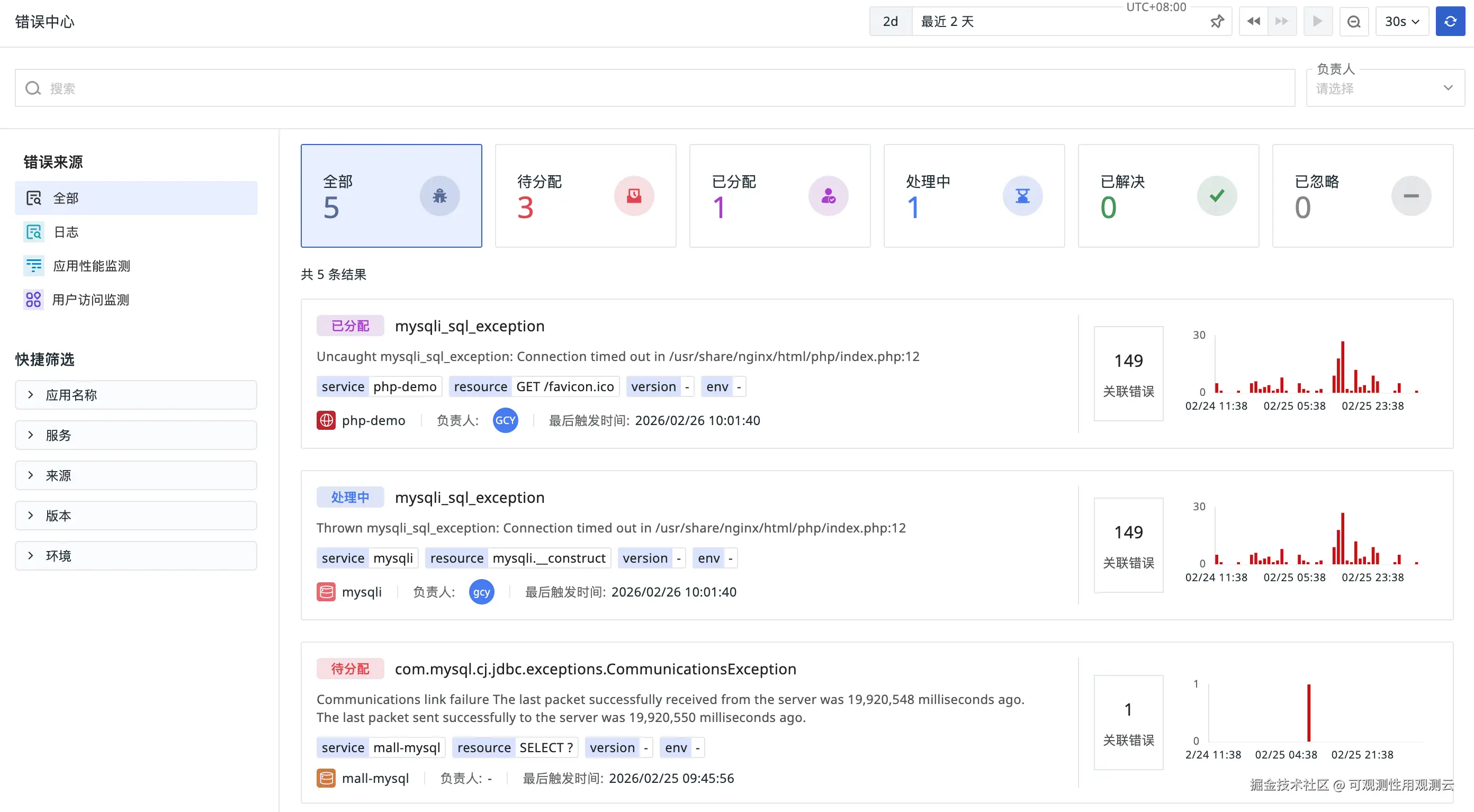
错误中心在你无需配置任何告警的情况下,自动采集全量 Error,并通过指纹(Fingerprint)算法智能聚类为错误根因(Issue):
- 智能降噪与分组:系统在计算指纹前,会先优化堆栈信息(error_stack),仅保留关键业务调用行,并自动过滤变量内容(如 UUID、时间戳、用户 ID)。基于错误类型、错误信息和堆栈特征计算指纹,自动将相同根源的错误归为一个 Issue。例如,因数据库连接池耗尽产生的 10000 次 Error,会被识别为同一个 Issue,显示为"累计 10000 次",而非 10000 个独立告警。这大幅减少了告警疲劳,让你能立即看出某个错误是新增、复发还是与最近的代码部署相关。
- 实时趋势与影响面分析:通过错误分布趋势图,你可以直观看到问题是部署后 API 失败的意外激增、与网络超时相关的移动端崩溃,还是与过期认证令牌相关的前端错误。识别这些跨应用栈的错误模式是修复工作的关键。
02|通过全面的上下文加速故障排查
需求背景
当复杂应用出现问题时, 精确定位根因可能非常耗时,尤其是当技术栈的不同部分以孤岛方式运行时。前端崩溃可能源于后端 API 失败,页面加载缓慢可能与数据库性能问题相关,或者移动端崩溃可能是由服务器端的配置错误导致的。如果没有集中且全面的上下文可见,开发者就只能拼凑来自不同监控工具的碎片化数据,拖慢解决速度并增加误诊风险。
观测云解法
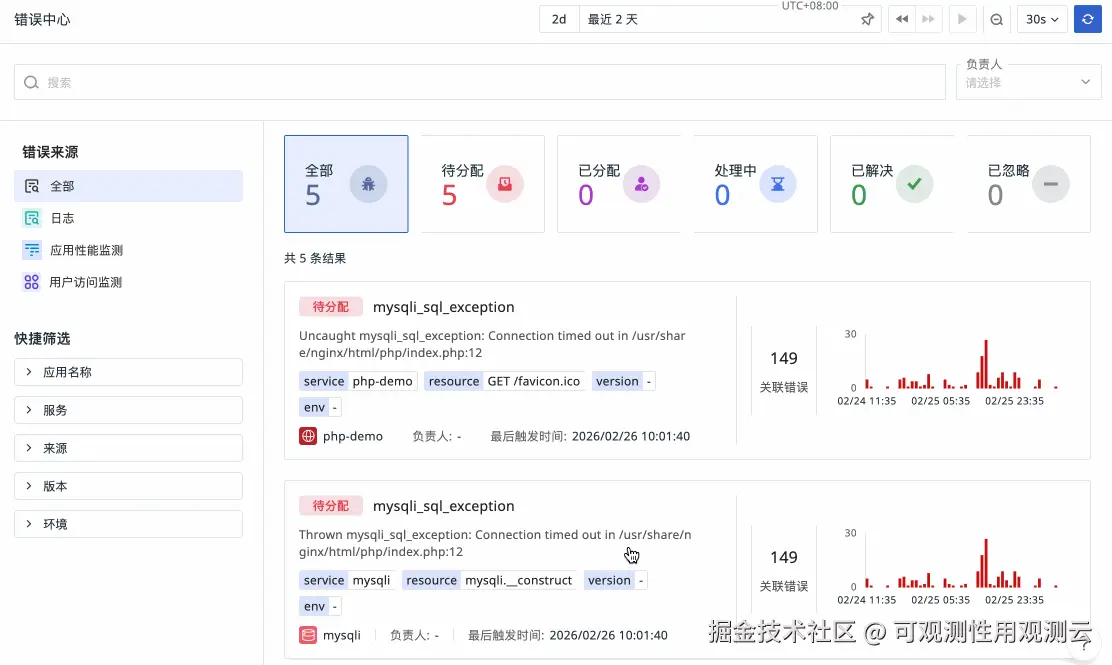
错误中心通过连接整个技术栈的错误消除了可见性盲区,在一个地方为开发者提供所需的所有上下文:
- 跨源统一汇聚:自动采集 APM(后端异常)、RUM(前端错误)、Logs(系统日志)中的错误,打破数据孤岛。当问题被检测到时,你可以从前端 UI 追踪到后端服务、数据库和网络请求。
- 完整堆栈跟踪与源码映射:提供完整的堆栈信息,如果是前端错误,SourceMap 自动映射到源码行列号。直接链接到相关源码让开发可以快速定位并解决错误。
- 用户会话关联:如果是 RUM 错误,可下钻查看触发错误的用户会话详情,通过关联的会话重放(Session Replay)查看错误发生前后的用户操作路径(如点击了哪个按钮、访问了哪些页面),帮助复现问题。
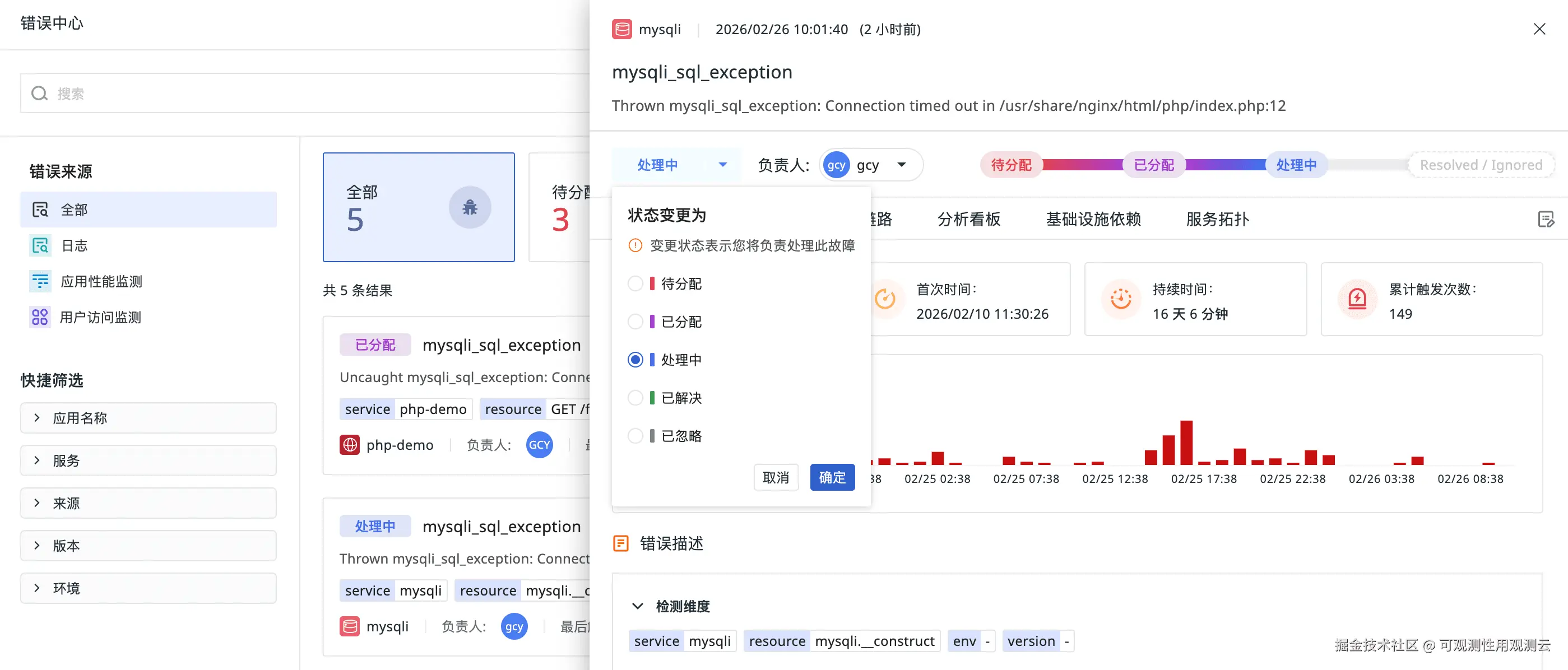
- 关联链路追踪:点击任一错误,无需手动复制 Trace ID 去搜索,完整的调用链(火焰图、Span 瀑布图)已自动关联呈现。
- 日志与指标关联 :与日志、链路追踪和基础设施指标都在单一平台中关联,帮助快速确定问题是否由特定部署、基础设施变更或依赖失败触发。
这种上下文关联让根因分析更加高效,开发者可以从错误跳转到相关日志、链路追踪和性能指标,无需在不同工具间切换。
03|主动检测并防止问题复发
需求背景
修复一次问题并不能必然防止它再次发生。如果没有对回归(Regression,即先前已修复的 Bug 或问题的意外复发)的追踪,团队可能在不知情的情况下重新引入旧问题。手动监控这些复发效率低下,团队需要一种主动方法在回归导致系统停机和用户的不良用户体验之前检测并解决它们。
观测云解法
错误中心通过状态流转机制,确保每一个 Issue 都有始有终:
- 生命周期状态管理:每个错误根因(Issue)拥有明确的状态流转:待分配(Triage)→ 已分配(Assigned)→ 处理中(Working)→ 已解决(Resolved)。团队可以优先处理未分配的高频 Issue,避免在已处理问题上重复投入。
- 自动回归检测:已标记为 Resolved 的 Issue,如果再次产生相同指纹的错误,状态会自动回退到 Triage(待分配),并高亮提示"问题复发"。这保留了所有历史上下文供复盘,防止"以为修复但实际未修复"的情况被忽略。
- 智能降噪:对于已确认无需修复的已知问题(如第三方 SDK 的非致命警告),可标记为 Ignored(已忽略),后续相同错误将不再产生干扰,让团队专注在值得修复的关键代码错误上。
场景示例
假设监控器检测到"支付服务不可用",同时错误中心显示一个 Issue 显示"数据库连接超时",累计发生 5000 次 Error,状态为待分配(Triage):
- 认领与优先级判断:开发负责人看到错误趋势图显示该 Issue 在昨天发版后激增,且影响多个用户,判断为高优先级,点击"分配给我",状态变为 Assigned。
- 全栈排查:进入详情页,关联链路自动展示最近一次错误的完整调用链,发现是新建连表的查询未加索引导致慢 SQL;关联日志显示同一时间段的连接池占满告警;用户会话显示部分用户在支付页面点击提交按钮后长时间无响应。
- 定位根因:通过 SourceMap 映射到源码,确认是第 142 行查询逻辑缺少索引;同时发现该 Issue 的发生时间与最近一次代码部署时间吻合。
- 修复与验证:提交修复代码后,标记 Issue 为 Resolved。系统持续监控,若该指纹的 Error 不再出现,保持 Closed 状态。
- 回归预警:三天后,相同指纹的 Error 再次出现,Issue 状态自动回退到 Triage,并通知原处理人:"疑似回归,请确认"。开发者快速比较新旧发生实例,发现是另一个服务也使用了相同的问题代码,立即批量修复,防止影响扩大。
总结
观测云错误中心 vs 传统方式
| 维度 | 传统方式 | 观测云错误中心 |
|---|---|---|
| 错误聚合 | 10000 次相同 Error = 10000 条告警/邮件 | 智能指纹聚合:1 个 Issue + error 发生次数,消除噪音 |
| 跨端关联 | 手动切换搜索 APM/RUM/Logs | 单一真实数据源:自动关联链路、日志、用户会话,一键下钻 |
| 上下文深度 | 堆栈信息不完整,无法查看用户操作 | 完整堆栈 + SourceMap 映射 + 用户会话关联,直达源码 |
| 状态管理 | 无状态流转,修复后无法跟踪是否复发 | 生命周期管理 :Triage → Resolved,自动检测回归 |
| 优先级判断 | 按报错次数人工判断,容易遗漏关键问题 | 影响面分析:自动统计影响用户数、发生趋势,优先处理高影响 Issue |
统一错误视图,直指错误根因
观测云错误中心,提供覆盖前端、后端、浏览器及移动端的统一错误管理视图。通过全栈可观测性,团队可以识别并优先处理最关键的错误,更快地进行故障排查和解决问题,并在回归对最终用户产生负面影响之前检测并防止它们,开发者们可以从繁琐的问题排查中解放出来,专注于真正的创新。