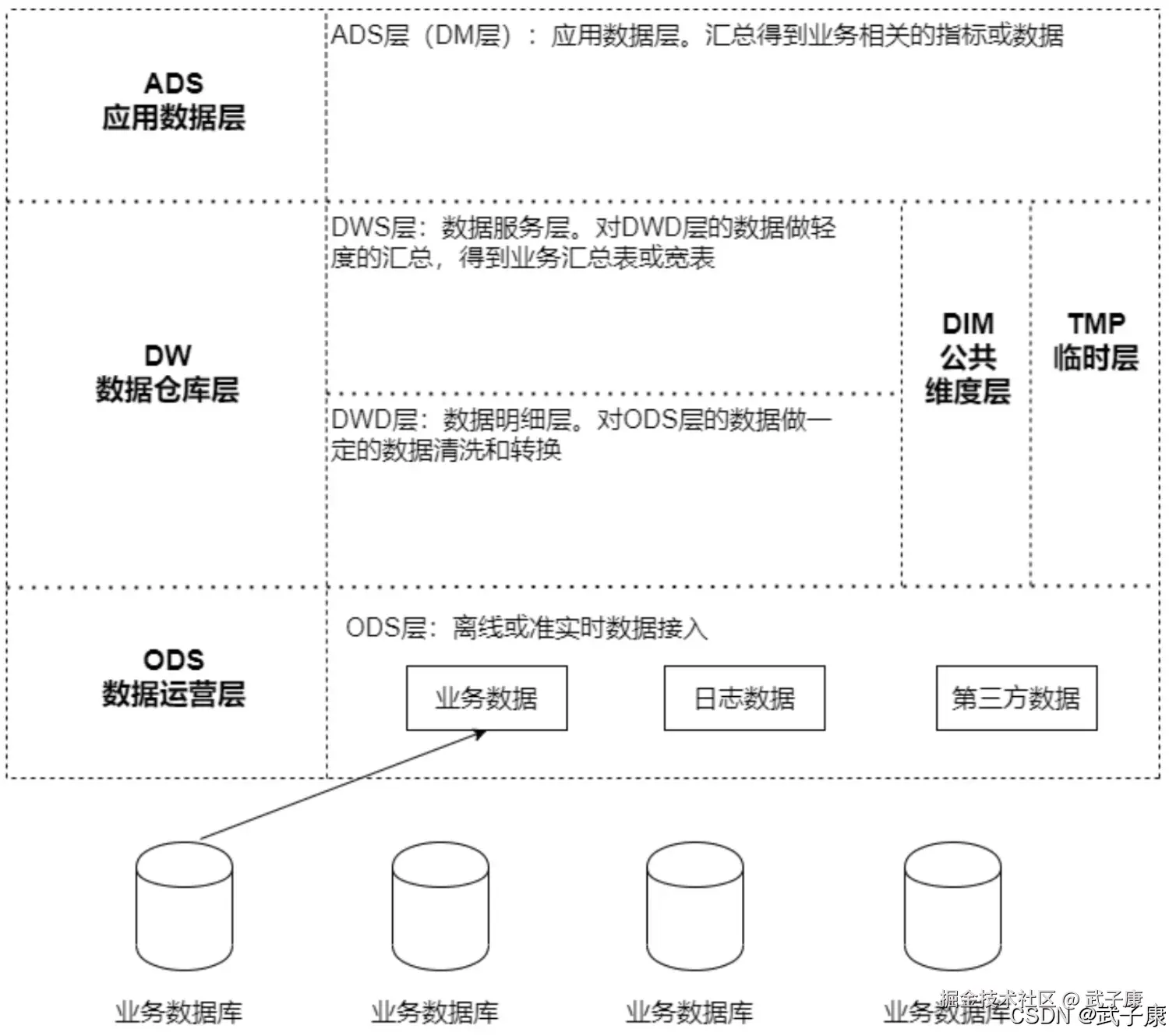
TL;DR
- 场景: 这是一篇离线数仓实战记录,覆盖会员主题数据测试、HDFS 导出、DataX 同步,以及广告业务从 ODS 到 ADS 的建模起点。
- 结论: 当前内容的价值在于"跑通链路",重点不是炫复杂建模,而是验证 Hive 分层、脚本执行、导出落库与广告指标口径是否闭环。
- 产出: 可直接沉淀为一篇偏工程验证型的大数据实战文,核心关键词集中在 Hive、DataX、离线数仓、会员分析、广告指标、ODS/DWD/ADS。

数据测试
活跃会员DWS
shell
sh dws_load_member_start.sh 2020-07-21
-- 依次执行其他的 过于重复 这里跳过执行结果如下图 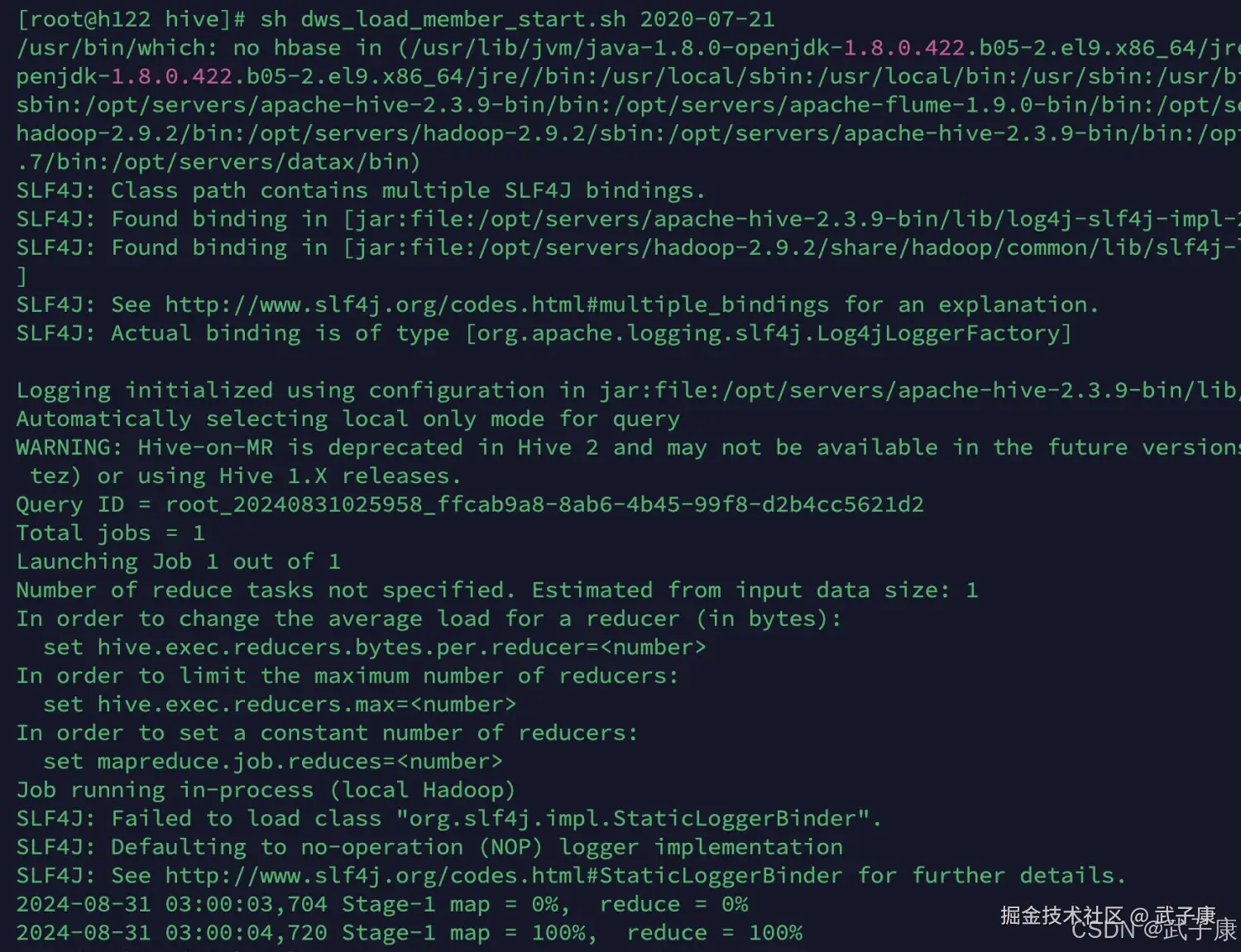
活跃会员ADS
(之前这里打错名称了,多打了字母m,大家根据实际情况修改)
shell
sh ads_load_member_active.sh 2020-07-21
-- 依次执行其他的 过于重复 这里跳过执行结果如下图: 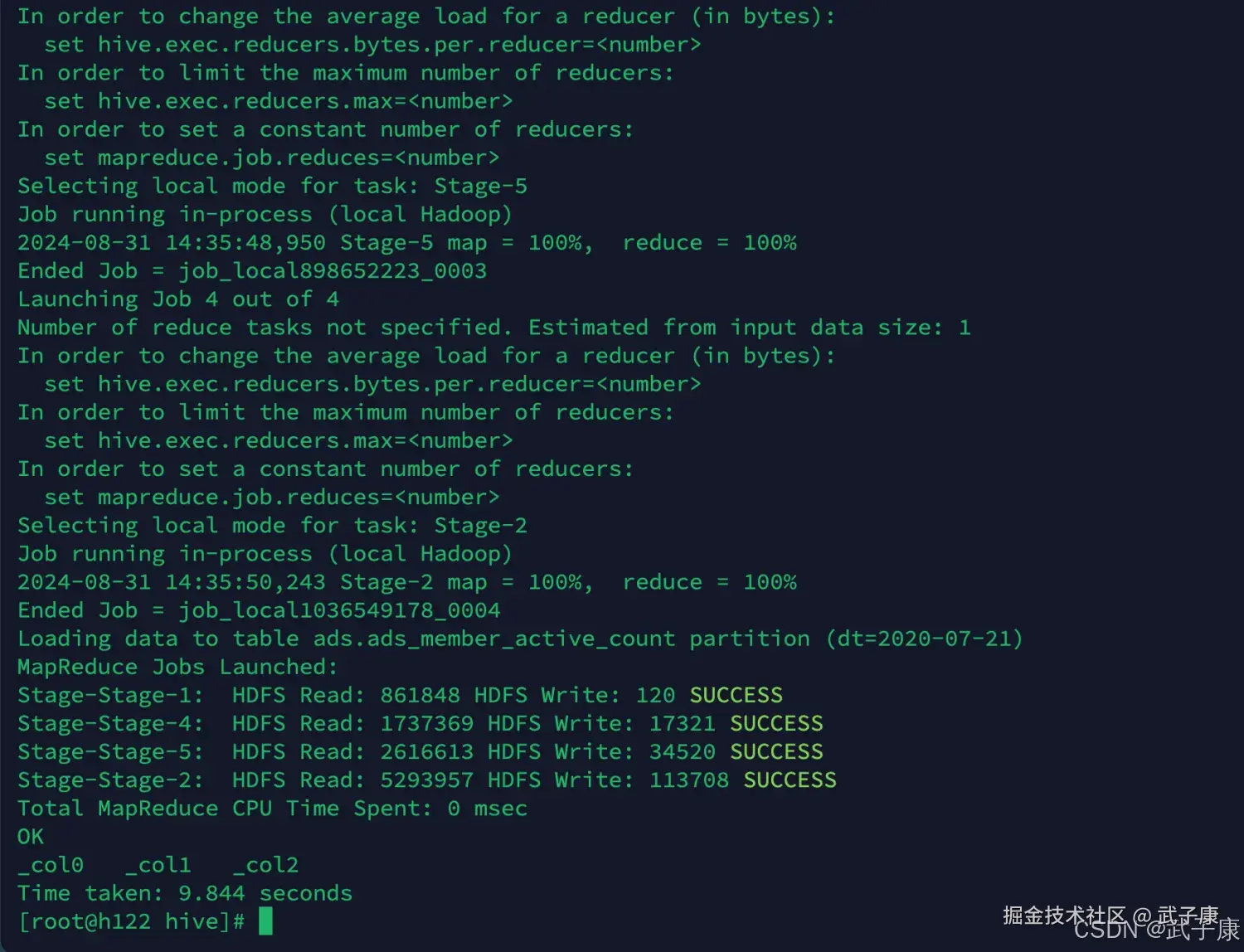
新增会员DWS
shell
sh dws_load_member_add_day.sh 2020-07-21
-- 依次执行其他的 过于重复 这里跳过执行结果如下图所示: 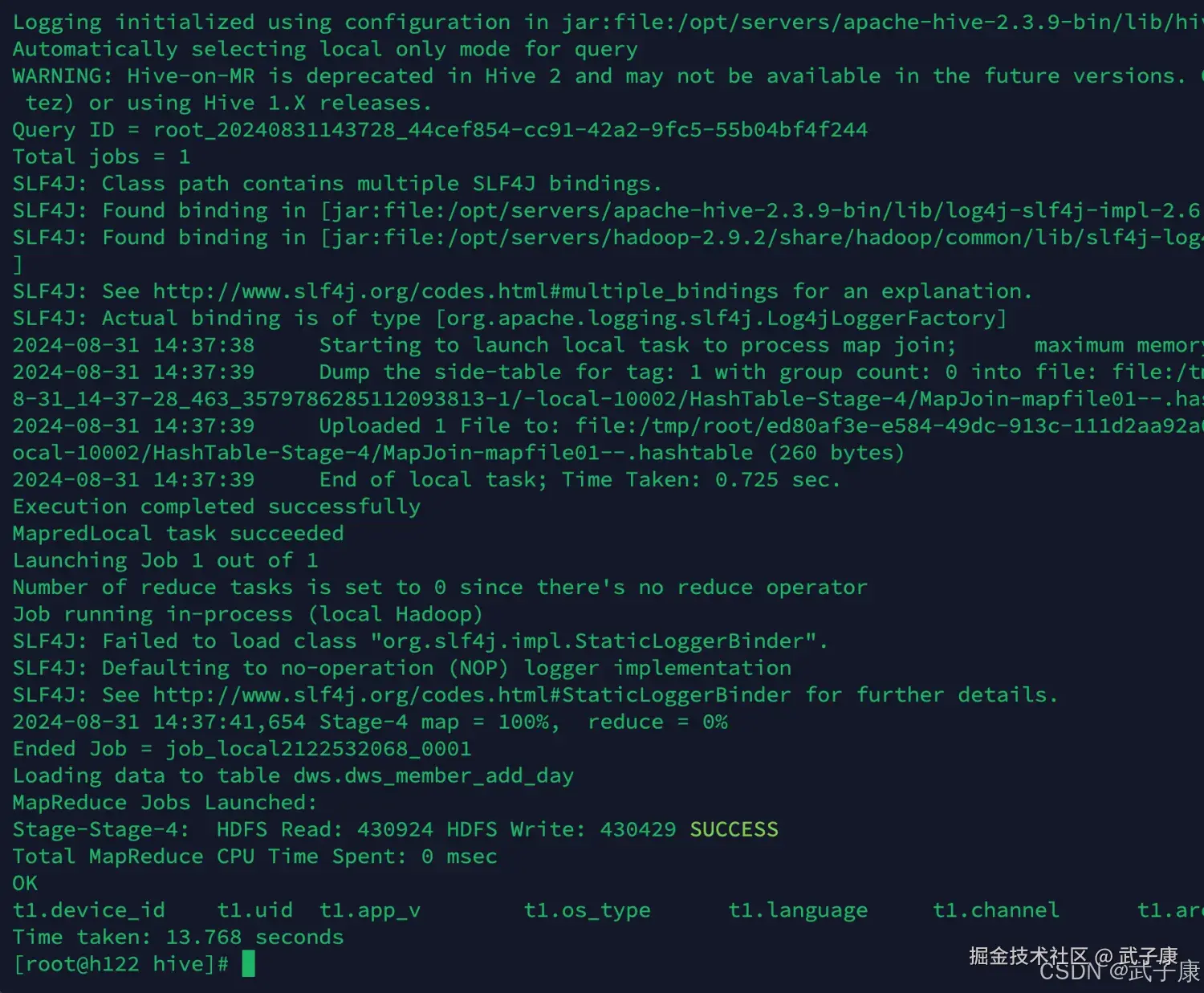
新增会员ADS
shell
sh ads_load_member_add.sh 2020-07-21
-- 依次执行其他的 过于重复 这里跳过执行结果如下图所示: 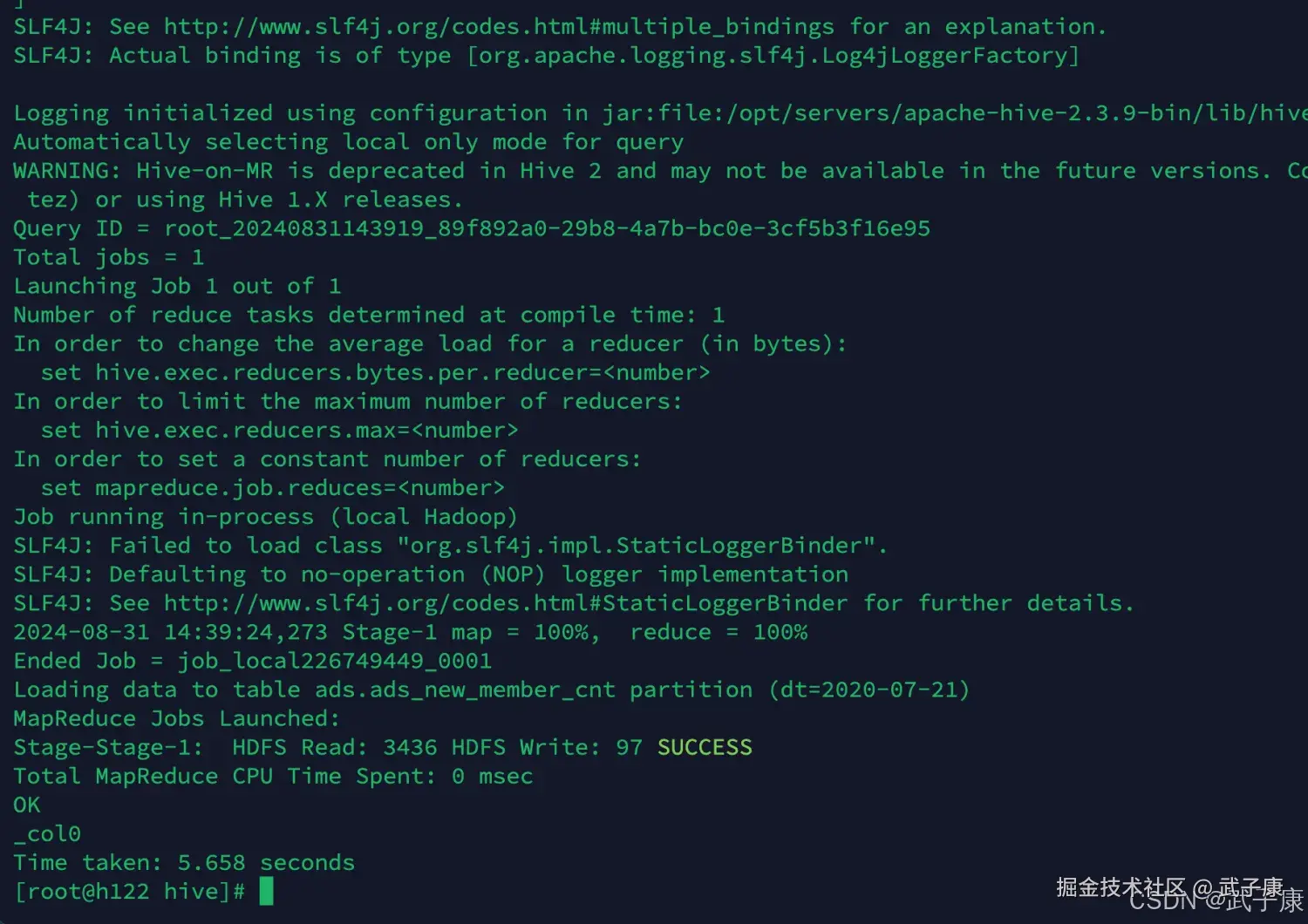
会员留存DWS
shell
sh dws_load_member_retention_day.sh 2020-07-21
-- 依次执行其他的 过于重复 这里跳过执行结果如下图所示: 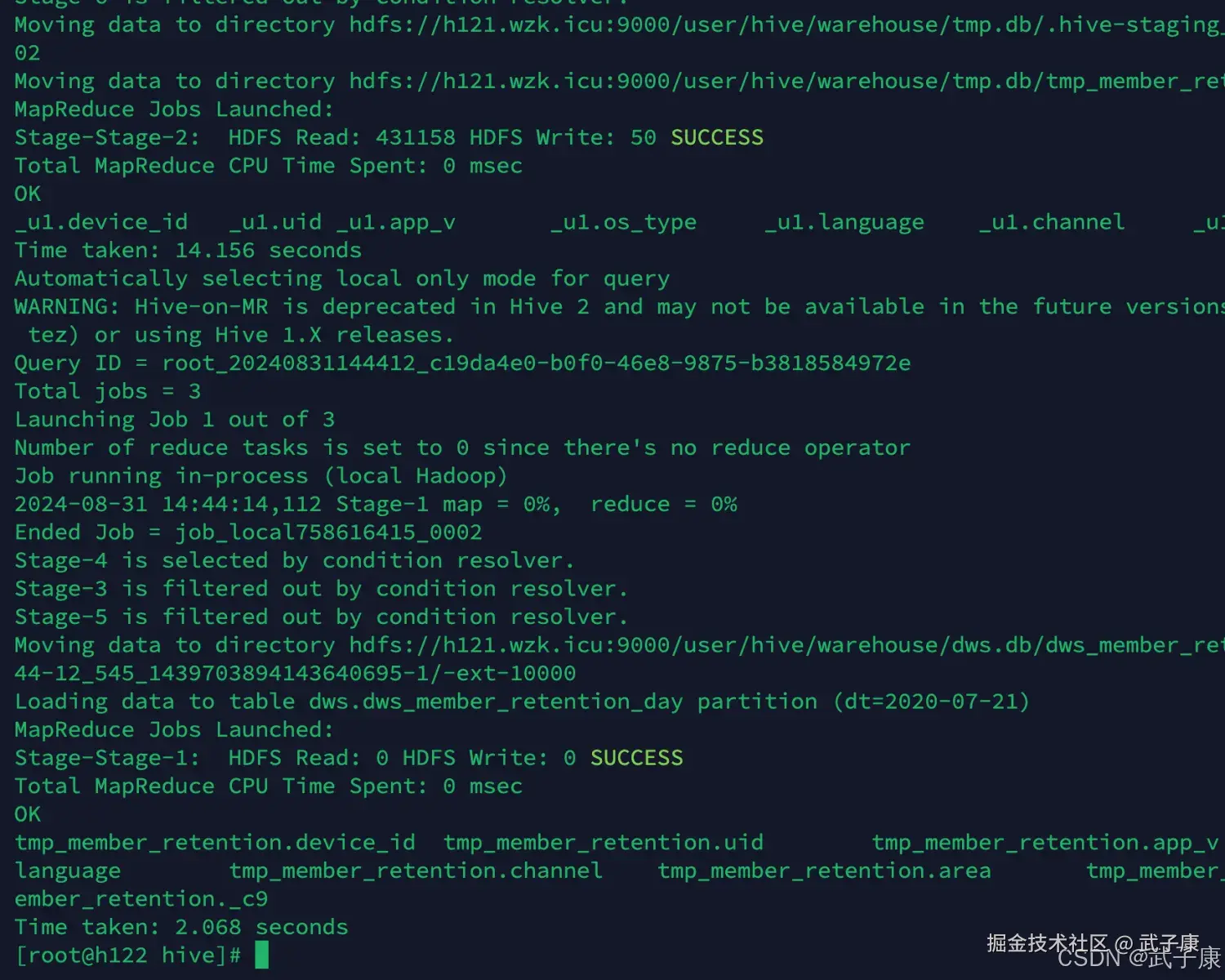
会员留存ADS
shell
sh ads_load_member_retention.sh 2020-07-21
-- 依次执行其他的 过于重复 这里跳过执行结果如下图所示: 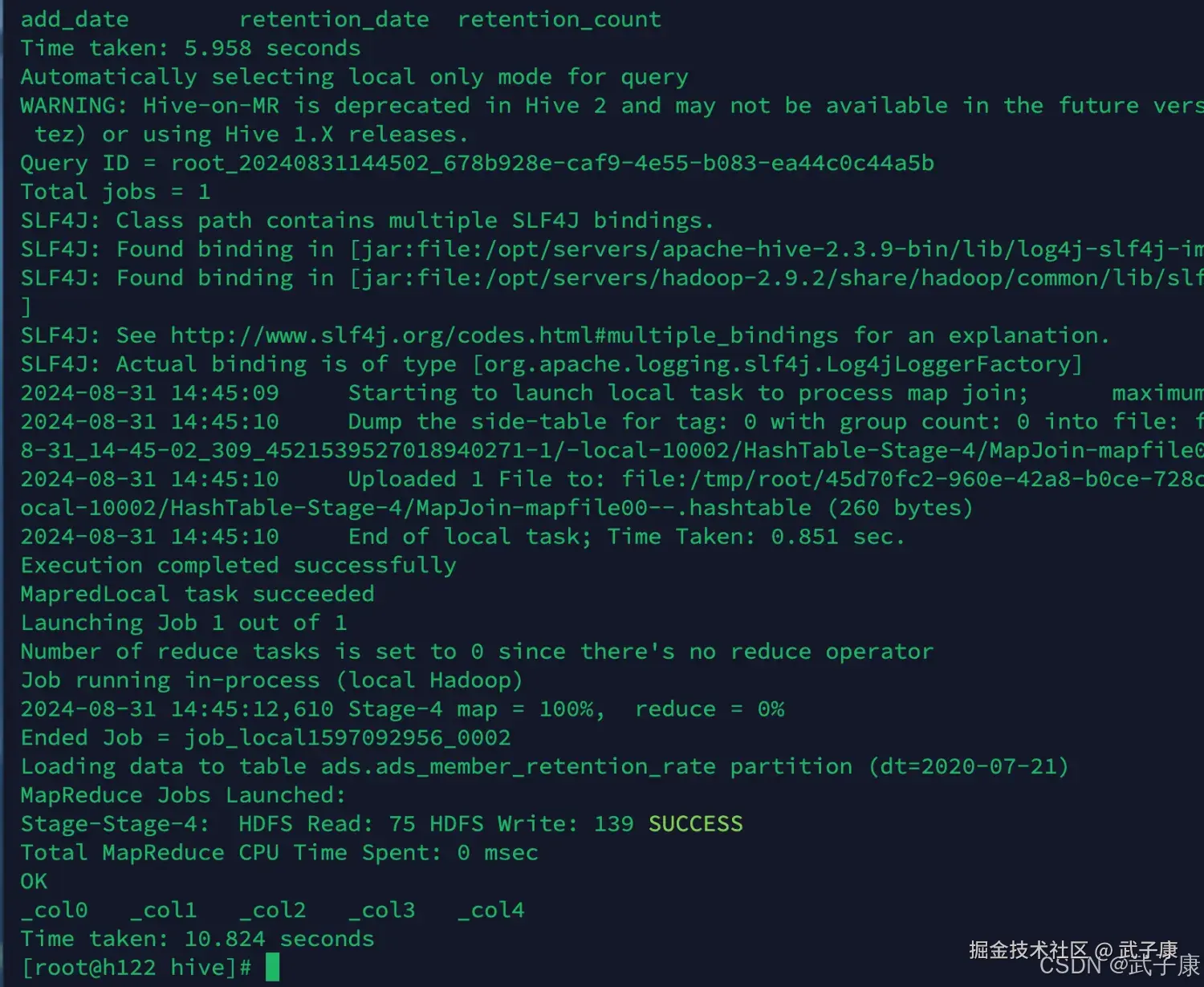
导出测试
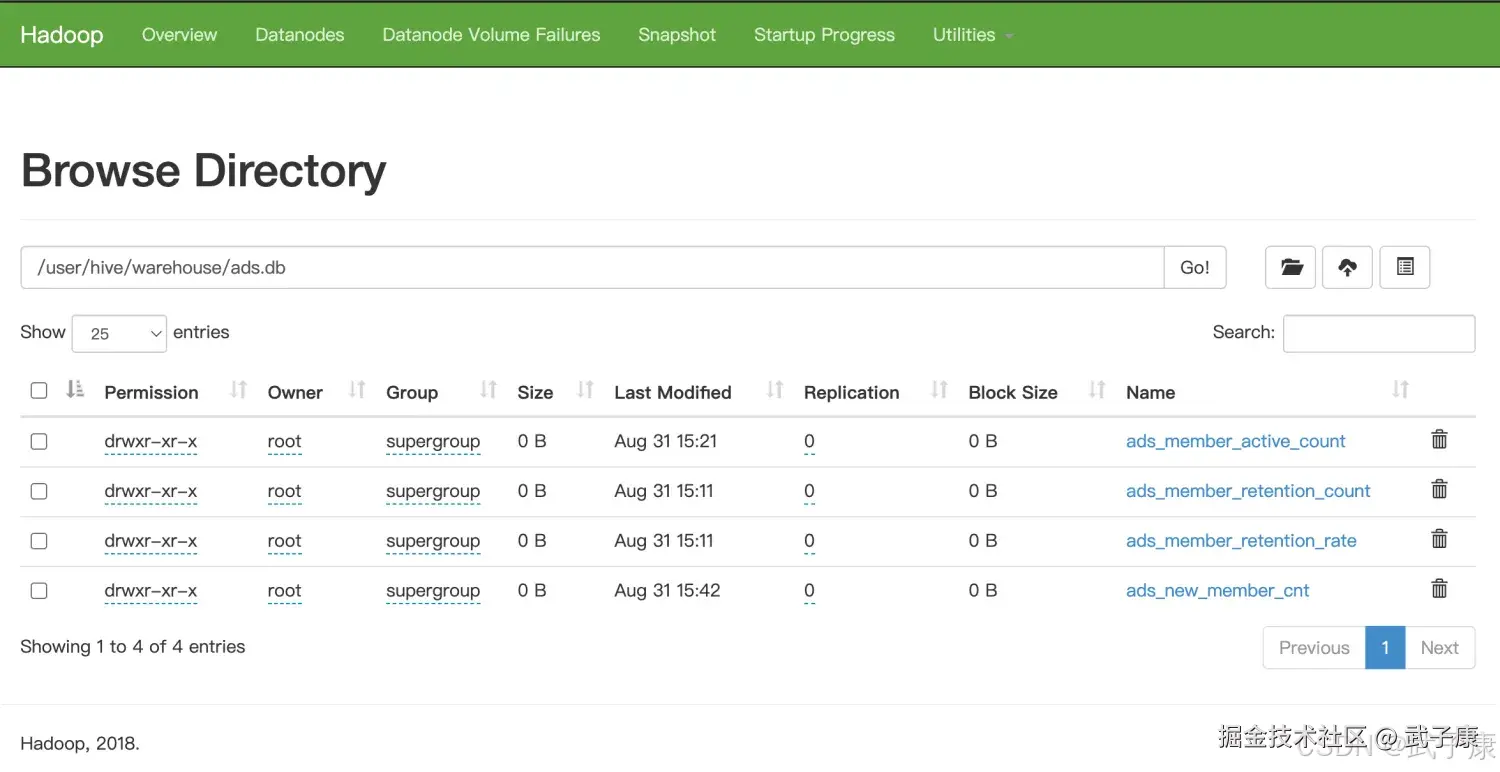
HDFS 现在数据有了,在我们的HDFS上,可以看到:
DataX
我们运行刚才的脚本:
shell
sh /opt/wzk/hive/export_member_active_count.sh 2020-07-21
-- 其他日期也执行一次,重复性高,这里略过运行结果如下图所示: 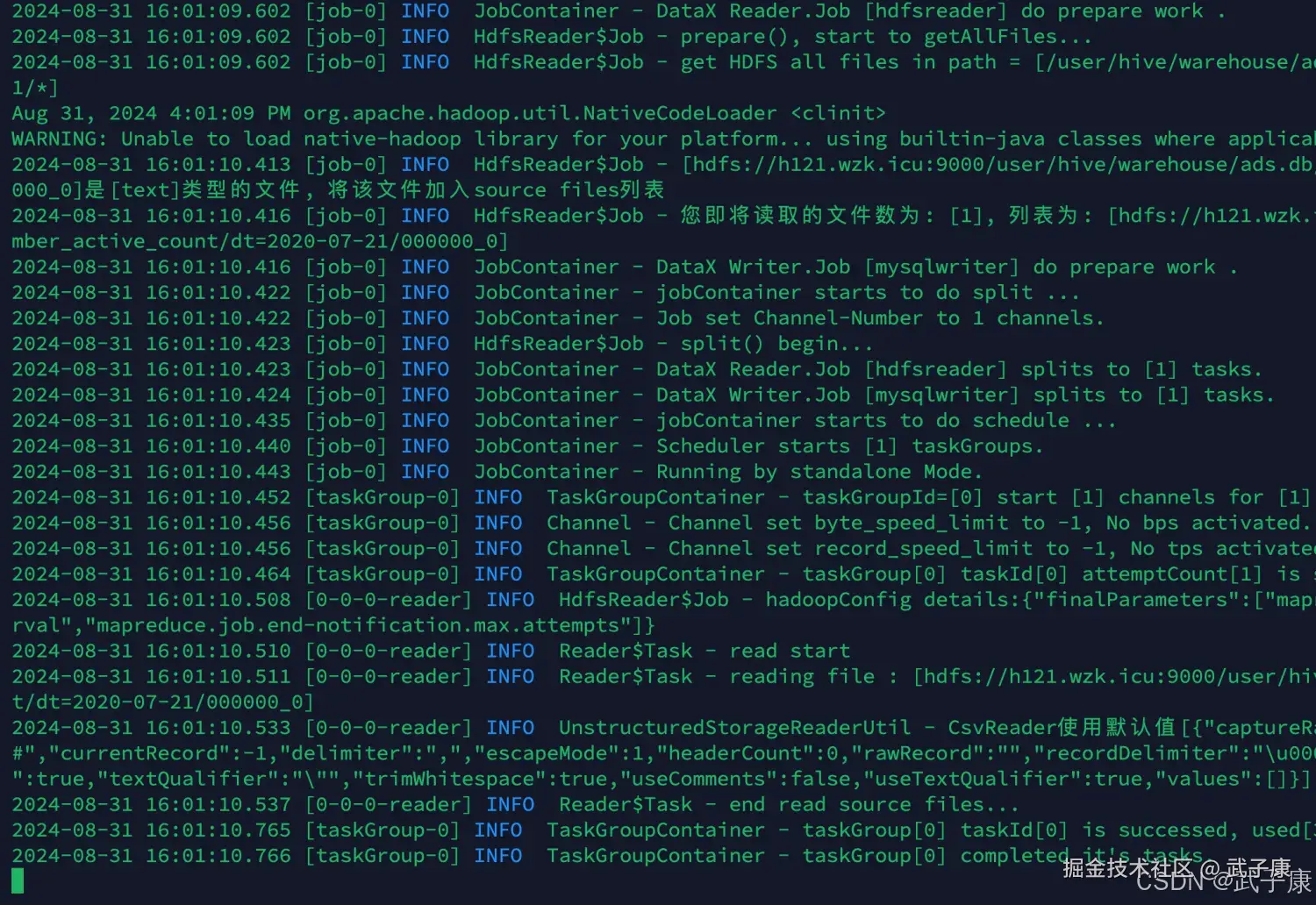 等待运行结束:
等待运行结束: 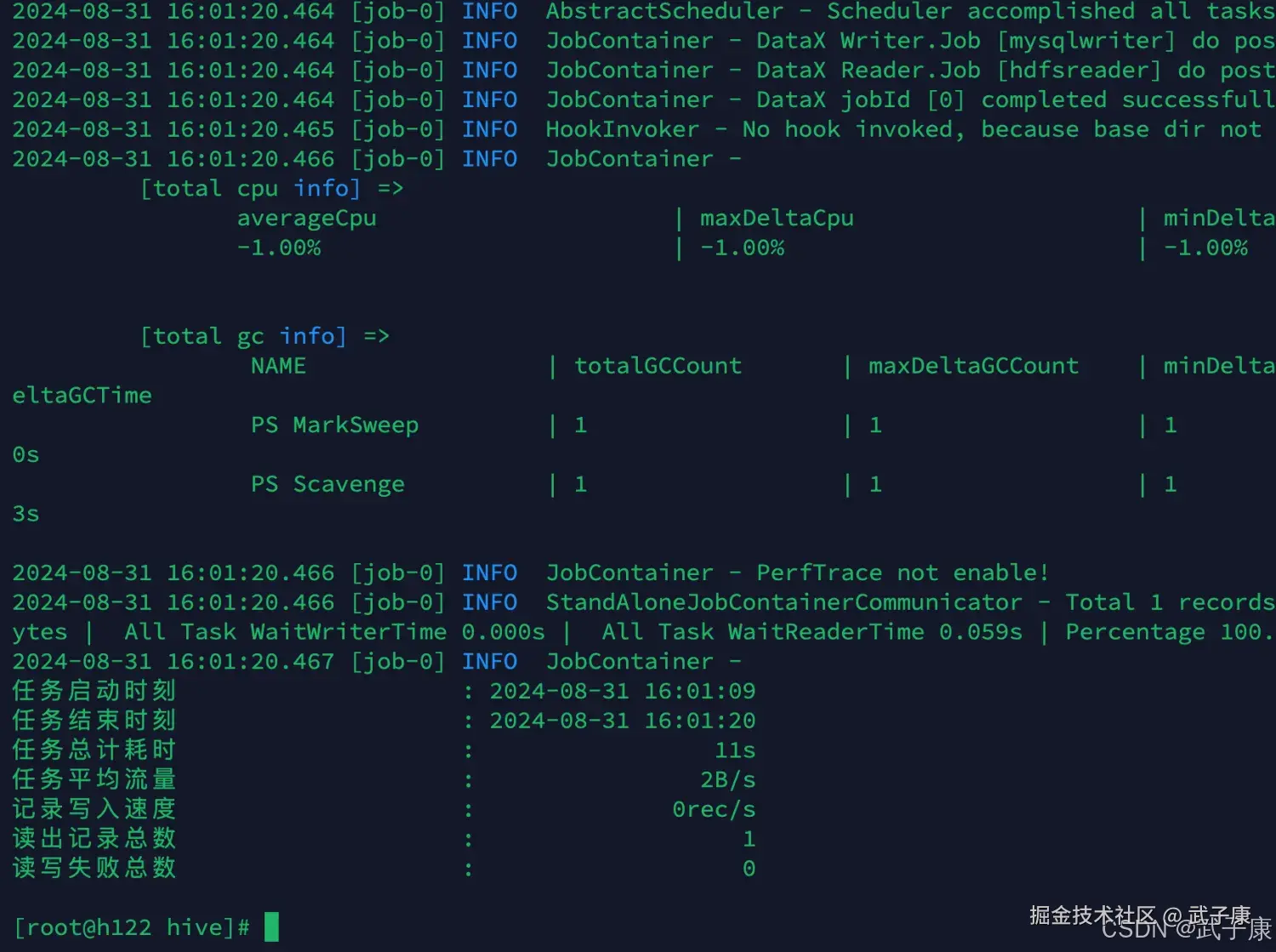
MySQL
这里我们运行了 07-21 到 07-31 的数据,我们查询数据库内容,可以看到如下的结果: 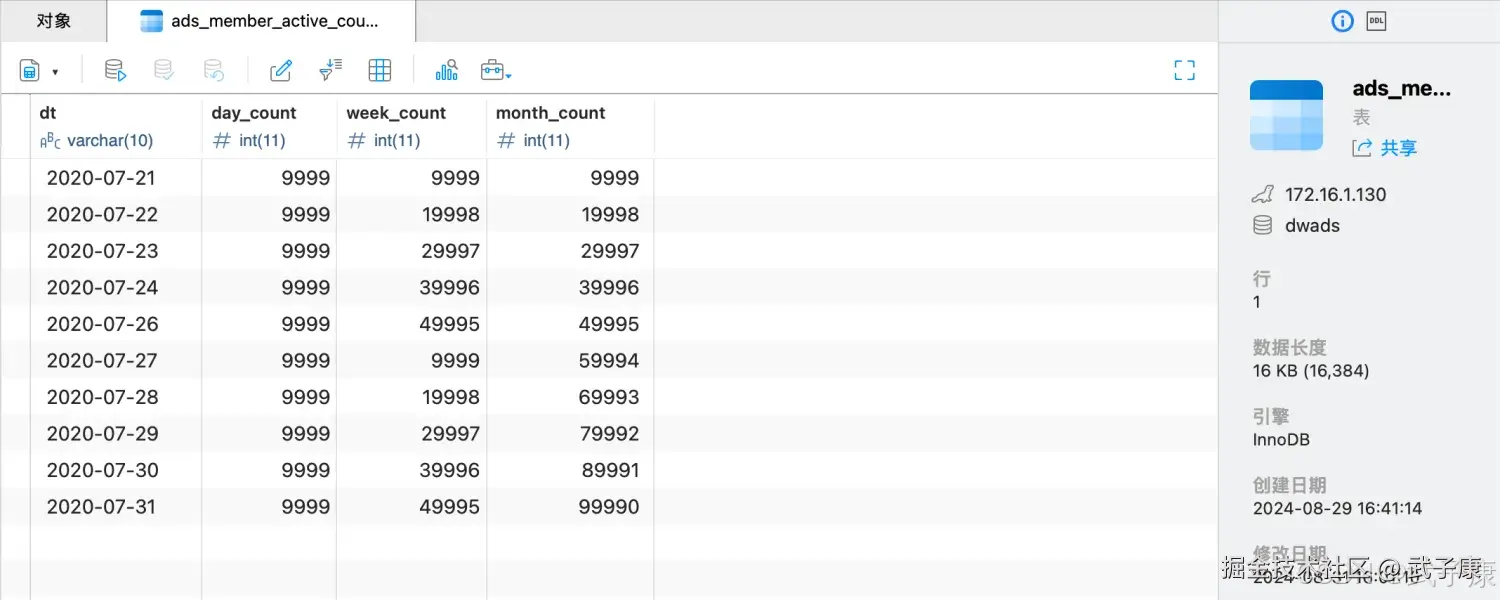
广告业务 ODS DWD ADS
基本介绍
互联网平台通行的商业模式是利用免费的基础服务来吸引大量用户,并利用这些用户开展广告或其他增值业务实现盈利从而反哺支撑免费服务的生存和发展。广告收入不仅成为互联网平台的重要收入之一,更决定了互联网平台的发展程度。 电商平台本身就汇聚了海量的商品、店铺的信息,天然适合进行商品的推广。对于电商和广告主来说,广告投放的目的无非就是吸引更多的用户,最终实现营销转换。因此非常关注不同位置的广告的曝光量、点击量、购买量、点击率、购买率。
需求分析
事件日志数据样例:
json
{
"wzk_event": [{
"name": "goods_detail_loading",
"json": {
"entry": "3",
"goodsid": "0",
"loading_time": "80",
"action": "4",
"staytime": "68",
"showtype": "4"
},
"time": 1596225273755
}, {
"name": "loading",
"json": {
"loading_time": "18",
"action": "1",
"loading_type": "2",
"type": "3"
},
"time": 1596231657803
}, {
"name": "ad",
"json": {
"duration": "17",
"ad_action": "0",
"shop_id": "786",
"event_type": "ad",
"ad_type": "4",
"show_style": "1",
"product_id": "2772",
"place": "placeindex_left",
"sort": "0"
},
"time": 1596278404415
}, {
"name": "favorites",
"json": {
"course_id": 0,
"id": 0,
"userid": 0
},
"time": 1596239532527
}, {
"name": "praise",
"json": {
"id": 2,
"type": 3,
"add_time": "1596258672095",
"userid": 8,
"target": 6
},
"time": 1596274343507
}],
"attr": {
"area": "拉萨",
"uid": "2F10092A86",
"app_v": "1.1.12",
"event_type": "common",
"device_id": "1FB872-9A10086",
"os_type": "4.1",
"channel": "KS",
"language": "chinese",
"brand": "xiaomi-2"
}
}采集的信息包括:
- 商品详情页加载:goods_detail_loading
- 商品列表:loading
- 消息通知:notification
- 商品评论:comment
- 收藏:favorites
- 点赞:praise
- 广告:ad
在广告的字段中,收集到的数据有:
- action 用户行为 0曝光 1曝光后点击 2购买
- duration 停留时长
- shop_id 商家id
- event_type "ad"
- ad_type 1JPG 2PNG 3GIF 4SWF
- show_style 0静态图 1动态图
- product_id 产品id
- place 广告位置 1首页 2左侧 3右侧 4列表页
- sort 排序位置
需求指标
点击次数统计(分时统计)
- 曝光次数、不同用户ID数、不同用户数
- 点击次数、不同用户ID数、不同用户数
- 购买次数、不同用户ID数、不同用户数
转化率-漏斗分析
- 点击率 = 点击次数/曝光次数
- 购买率 = 购买次数/点击次数
活动曝光效果评估 行为(曝光、点击、购买)、时间段、广告位、产品、统计对应的次数 时间段、广告位、商品,曝光次数最多的前N个
ODS层
建立新表
Hive启动之后,切换到 ods层,然后我们继续创建外部表,将数据映射到Hive中:
sql
use ods;
drop table if exists ods.ods_log_event;
CREATE EXTERNAL TABLE ods.ods_log_event(
`str` string
) PARTITIONED BY (`dt` string)
STORED AS TEXTFILE
LOCATION '/user/data/logs/event';执行结果如下图所示: 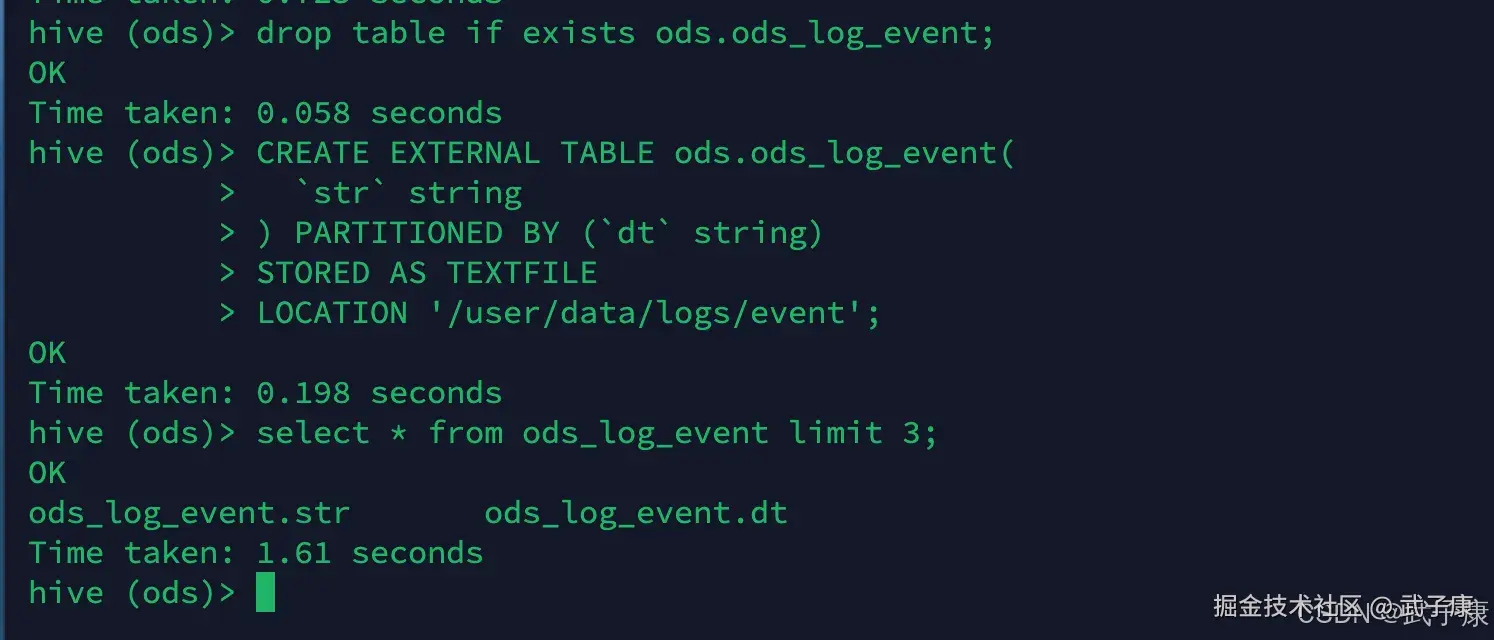
编写脚本
shell
vim /opt/wzk/hive/ods_load_event_log.sh编写脚本,写入内容如下:
sql
#!/bin/bash
source /etc/profile
if [ -n "$1" ]
then
do_date=$1
else
do_date=`date -d "-1 day" +%F`
fi
sql="
alter table ods.ods_log_event add partition (dt='$do_date');
"
hive -e "$sql"写入的内容如下所示: 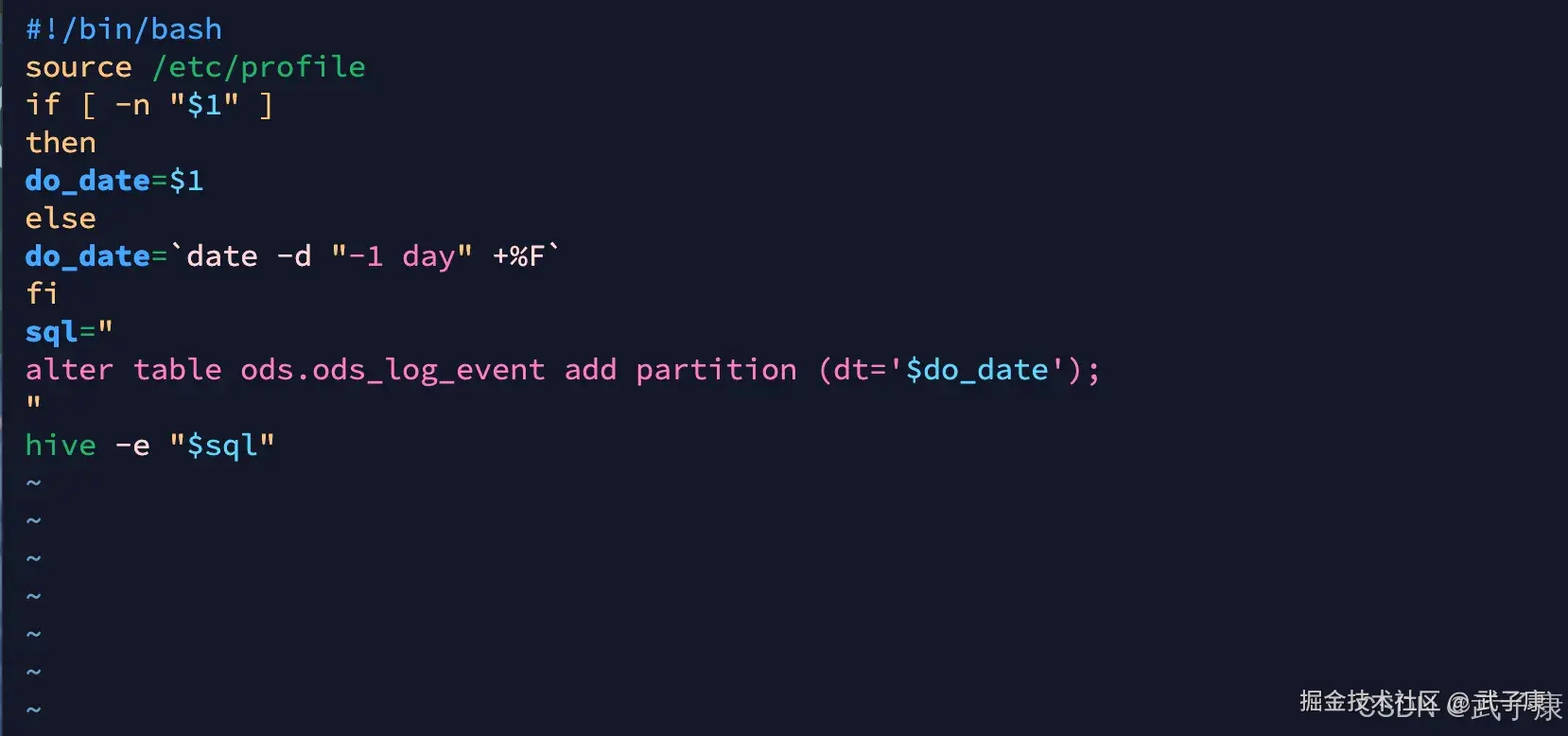
错误速查
| 症状 | 根因 | 定位 | 修复 |
|---|---|---|---|
| ADS 脚本名执行报错或找不到文件 | 脚本名称拼写错误,正文已注明曾多写字母 m | 对照 shell 命令与实际文件名 | 统一更正脚本名,确保文中命令与服务器脚本一致 |
| Hive 查询不到当天广告日志数据 | ODS 分区未添加,外部表未识别对应日期目录 | show partitions ods.ods_log_event; | 先执行 ods_load_event_log.sh 日期 补充分区 |
| DataX 执行成功但 MySQL 无数据 | 源路径无文件、日期参数不一致,或目标表映射配置错误 | 查 DataX 日志、核对 HDFS 文件与导出日期 | 统一 Hive 导出日期、HDFS 路径、DataX job 配置与目标表字段 |
| HDFS 有文件但 Hive/下游统计为空 | 上游脚本执行顺序不完整,只跑了部分日期或部分主题 | 对照各 shell 执行批次与目标日期区间 | 按日期补跑全量/增量脚本,确保依赖主题全部完成 |
| 广告指标口径对不上 | action 与文中"曝光/点击/购买"统计口径未在下游严格映射 | 核对事件字段 ad_action / action 的真实取值与 SQL CASE 逻辑 | 固化口径:0=曝光,1=点击,2=购买,并在 DWD 层统一清洗 |
| 广告位统计混乱 | 样例里 place 是字符串值(如 placeindex_left),说明文档却写成数字枚举 | 检查原始日志样本与字段字典 | 统一一套映射规则,先在 DWD 层标准化广告位编码 |
| 漏斗转化率异常(大于 1 或为 0) | 分母口径不一致,或曝光/点击/购买去重逻辑不同 | 检查明细聚合 SQL 的 group by 与去重字段 | 明确"次数"和"人数"分开统计,转化率只用同一口径分子分母 |
| 按天脚本补数错位 | 默认日期是前一天,手工补数时未显式传参 | 查看脚本中的 do_date 逻辑 | 补数一律显式传入日期参数,避免用默认值 |
| ODS 建表后看不到历史文件 | 外部表只建了目录映射,未补充分区元数据 | show partitions 与 HDFS 目录对比 | 为已有日期逐天 add partition,或批量修复元数据 |
| 内容可读性下降 | 工程截图多,但"版本、前置环境、适用范围"未前置声明 | 通读正文结构即可发现 | 在正文前部补充环境信息、脚本适用范围、验证边界,避免读者误判为通用生产方案 |
其他系列
🚀 AI篇持续更新中(长期更新)
AI炼丹日志-29 - 字节跳动 DeerFlow 深度研究框斜体样式架 私有部署 测试上手 架构研究 ,持续打造实用AI工具指南! AI研究-132 Java 生态前沿 2025:Spring、Quarkus、GraalVM、CRaC 与云原生落地 🔗 AI模块直达链接
💻 Java篇持续更新中(长期更新)
Java-218 RocketMQ Java API 实战:同步/异步 Producer 与 Pull/Push Consumer MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务已完结,Dubbo已完结,MySQL已完结,MongoDB已完结,Neo4j已完结,FastDFS 已完结,OSS已完结,GuavaCache已完结,EVCache已完结,RabbitMQ已完结,RocketMQ正在更新... 深入浅出助你打牢基础! 🔗 Java模块直达链接
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈! 大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解 🔗 大数据模块直达链接