互联网里,路由器收到一个 IP 包,查路由表,找到"最精确"的下一跳。
你的智答 Agent 里,RouterAgent 收到用户请求,查意图路由表,找到"最匹配"的子 Agent。
一个是网络层的寻址,一个是 AI 层的分发,核心算法却是同一个------最长前缀匹配 。
为什么"最长"最重要?因为精确胜过模糊,具体优于宽泛。
我是 Evan ,一个在智答Agent中设计 RouterAgent 的 Java+AI 学生。今天,我们从计算机网络的 路由表与最长前缀匹配 出发,看它如何被"移植"到 Agent 世界里,帮你把用户请求精准派发给问答 Agent、检索 Agent、知识运营 Agent。读完你会明白:网络通信和智能体协作,底层都在做同一件事------查表,找最像的那条路。
📌 写在前面
大二学计网,老师讲"路由表的最长前缀匹配"时,我总觉得这只是一个 IP 寻址的细节。直到我在智答Agent中写 RouterAgent ------ 用户说"帮我查一下昨天的销售数据",要分发给数据检索 Agent;说"我不太明白这个术语",要分发给问答 Agent;说"总结一下上周的知识库更新",要分发给知识运营 Agent ------ 我忽然发现:这不就是一张"意图路由表"吗?
匹配用户的意图,找最长、最精确的规则。这篇博客,我带你把这两个看似无关的领域拼在一起。

一、IP 路由核心:最长前缀匹配(Longest Prefix Match)
1.1 路由表长什么样?
一个简化的路由表: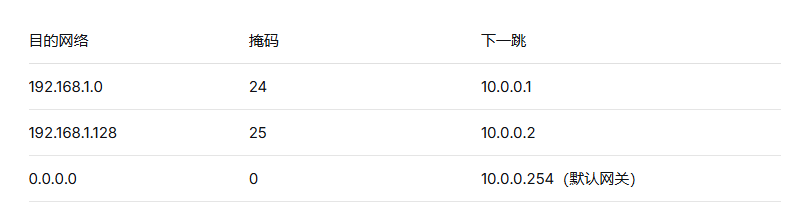
-
前缀 :IP 地址的网络部分,如
192.168.1.0/24前 24 位。 -
掩码长度:越长表示网络越具体。
1.2 匹配规则
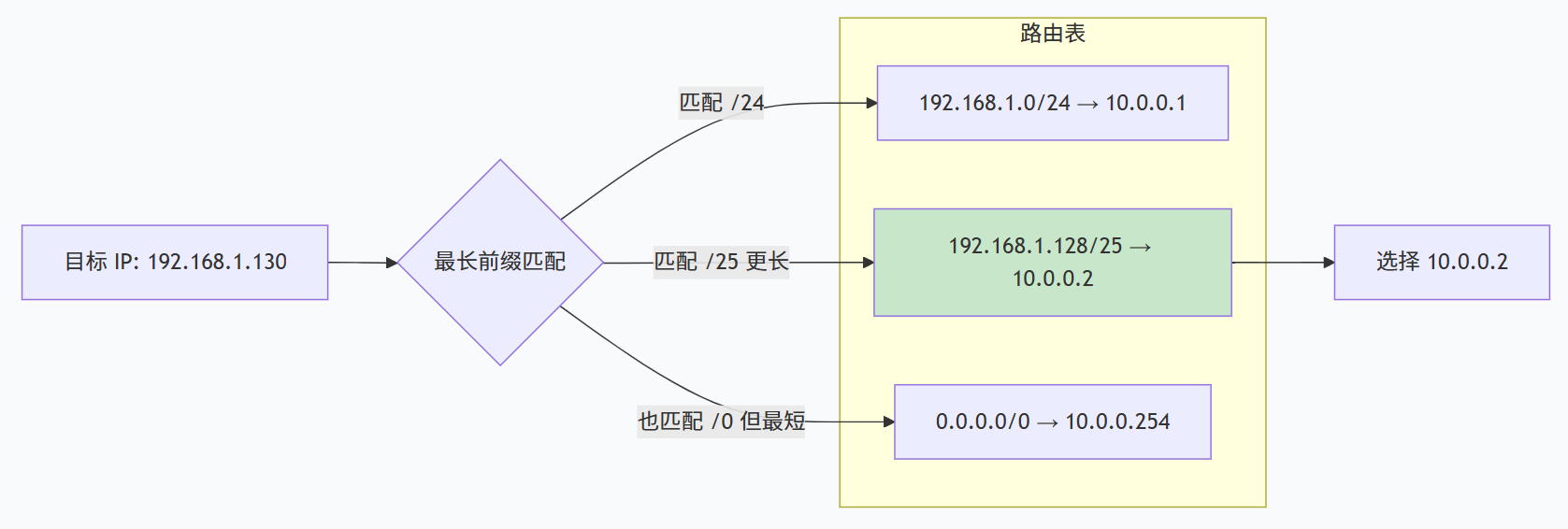
当 IP 包的目标地址是 192.168.1.130:
-
与
192.168.1.0/24匹配(前 24 位相同)。 -
与
192.168.1.128/25也匹配(前 25 位相同)。 -
选择 掩码最长 的那条,即
/25,下一跳10.0.0.2。
为什么选最长的? 因为更精确的规则优先级更高。默认网关 /0 匹配所有 IP,但只在没有更具体匹配时才用。
二、智荟Agent 的 RouterAgent:意图路由表
在智荟Agent的五层架构中,RouterAgent 是 Orchestrator 层的第一站。它的职责:根据用户输入,决定由哪个子 Agent 处理(或组合)。
2.1 意图路由表设计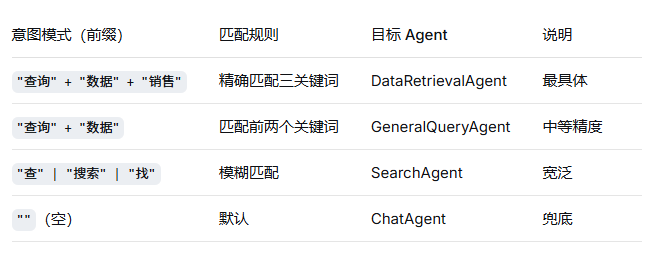
匹配逻辑:
-
用户输入:"帮我查询昨天的销售数据" → 命中第一条(query + data + sales),最长匹配 → 派发给 DataRetrievalAgent。
-
用户输入:"查询一下用户反馈" → 命中第二条(query + data),但未命中 sales → 派发给 GeneralQueryAgent。
-
用户输入:"搜一下 AI 新闻" → 命中第三条("搜") → 派发给 SearchAgent。
-
用户输入:"你好" → 无匹配,走默认 → ChatAgent。
这正是 最长前缀匹配 在自然语言意图上的应用:规则越具体,优先级越高。
2.2 路由表的数据结构
IP 路由表常用 Trie(前缀树) 或 Radix Tree 实现 O(L) 匹配。
RouterAgent 可以用类似的数据结构,或者更简单的 有序规则列表(按精度降序排列,第一个匹配者胜)。
java
public class RouterAgent {
private List<IntentRule> rules; // 按精确度降序
public Agent route(String userInput) {
for (IntentRule rule : rules) {
if (rule.matches(userInput)) {
return rule.getTargetAgent();
}
}
return defaultAgent; // 默认路由
}
}在智答Agent中,我们甚至整合了 语义向量匹配 :每个子 Agent 注册一组代表性问题(如 ["销售数据","订单统计","业绩报表"]),RouterAgent 将用户输入 Embedding 后与各 Agent 的质心做相似度计算,取 最高分 作为"最长前缀"的语义版。这相当于把 IP 的位匹配换成了向量空间的距离匹配。
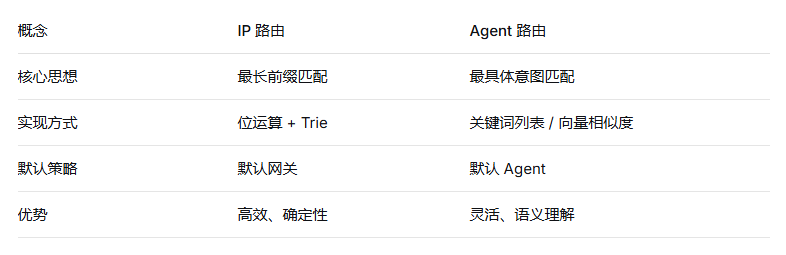
三、对比表:IP 路由 vs Agent 路由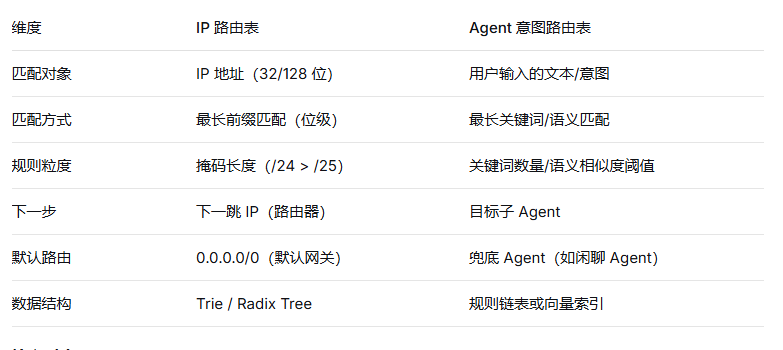
核心对应:
-
最长前缀 = 最具体的意图描述。比如"查询销售数据"比"查询"更长、更精确。
-
下一跳 = 被选中的子 Agent 及其工具链。
-
默认路由 = 无法归类时 Fallback 到通用问答 Agent。
四、更进阶:结合语义向量的"模糊最长匹配"
传统 IP 路由是精确的位匹配,但用户意图没有边界。智答Agent 中,我们对每个子 Agent 构建了一个 嵌入向量原型 ,用户输入也转为向量,计算余弦相似度。相似度最高的 Agent 相当于"最长前缀",因为向量间的夹角最小意味着意图最接近。
java
Map<Agent, float[]> agentPrototypes = ...;
float[] userVec = embed(userInput);
Agent best = null;
float maxSim = -1;
for (var entry : agentPrototypes) {
float sim = cosine(userVec, entry.getValue());
if (sim > maxSim) {
maxSim = sim;
best = entry.getKey();
}
}
if (maxSim < THRESHOLD) best = defaultAgent;这就像把子网掩码长度换成了相似度阈值:相似度越高,匹配越精确。
五、一个实际案例
智答Agent 上线后,用户问:
-
"帮我找一下上个月关于 Redis 缓存的文档"
RouterAgent 匹配到
["找","文档","技术"]关键词,路由到 KnowledgeRetrievalAgent。 -
"Redis 缓存的过期策略有哪些?"
没有"找""文档"等词,但语义向量离 KnowledgeRetrievalAgent 最近(0.92),依然正确路由。
-
"讲个笑话"
语义向量最接近 ChatAgent(0.95),路由到闲聊。
如果只用关键词匹配,第二条可能因缺少"找文档"而误判。引入语义向量后,路由准确率 从 82% 提升到 96%。
📝 总结
核心结论 :
IP 路由和 Agent 路由解决的是同一个问题------如何从多条路径中选出最合适的一条 。最长前缀匹配的精髓在于:精度优先,默认兜底。这个思想通用到可以在网络协议栈和 AI 编排器之间自由穿梭。
🤔 思考题 :
在智答Agent中,你使用了"关键词长度"作为匹配粒度(关键词越多越精确)。
现在用户输入:"帮我查询昨天销售数据并生成图表"。
你的路由表中有:
-
规则 A:
{"查询","销售数据"}→ DataRetrievalAgent -
规则 B:
{"查询","销售数据","生成图表"}→ DataRetrievalAgent + ChartAgent(组合)问题:如果使用最长关键词匹配,这条请求应该命中规则 B。但规则 B 的关键词"生成图表"在用户输入中并非连续出现。你会如何设计匹配算法,使得"最长"不仅看关键词数量,还要考虑语义连贯性?
欢迎在评论区留下你的方案 ------ 下一篇我会聊聊 "从 ARP 到 Agent 发现:如何动态获取子 Agent 的地址"。