等AI回消息的间隙,你是切出去刷了个短视频,还是盯着屏幕数它蹦出来的字?现在的GPT、Claude、Gemini,看着聪明,骨子里其实都是老式打字员------一个字接一个字往外敲,前一个不落地,后一个就得干等着。这叫自回归,串行干活。问简单问题还行,一旦需要它多绕几个弯思考,比如解道数学题、做个多步规划,动辄让你等上半分钟。耐心就是这么磨没的。
有没有想过,让AI换种活法?

斯坦福、UCLA和康奈尔那几个学者攒了个局,叫Inception Labs 。他们搞出来的Mercury 2 ,路子有点野------把生成图像那套扩散模型的逻辑,硬搬到了语言模型里。结果呢?速度飙到每秒1000个token ,是Claude 4.5 Haiku的11倍,GPT-5 mini的14倍。更气人的是,它端到端跑一趟只要1.7秒,成本只有别人的六分之一,在AIME 2025数学基准上还能拿91.1分。
这不叫改良,这是换了条赛道。
Chat体验: chat-mercury2.inceptionlabs.ai/
API接入: platform.inceptionlabs.ai
它为什么不"打字"了?
自回归那条路,其实早就走到头了。
你可以把GPT们想象成一个人在写长信,写一个字,看一眼,再写下一个。不管GPU堆多猛,一次只能干一个token的活儿。这不是努力能解决的问题,是架构决定的死穴。
Mercury 2换了个思路。它更像一个编辑,而不是打字员。
自回归是这么干的:我 → 认为 → 答案 → 是 → 42(每一步都眼巴巴等着上一步)
扩散是这么干的:先把一整段话的草稿拍在那儿,甭管好坏------然后,所有位置一起动手,同时修改、同时优化。几轮迭代下来,草稿变成精品。
这套逻辑在图像领域早就跑通了,Stable Diffusion、Sora都是这么玩的。难点在于,图像是连续信号,可以一点点去噪;语言是离散的,词就是词,"猫"不能是0.7只"猫"。怎么在离散空间里定义"噪声"和"去噪",是个挺棘手的理论题。
Inception Labs能把这事儿做到商用级别,说明他们确实啃下了这块硬骨头。官方给这新架构起了个名:面向实时推理的扩散技术。它不再一个字一个字地挤,而是并行优化------同时生成多个token,几步迭代就收敛。结果呢?生成速度提升5倍以上,体验完全不一样。
快、便宜,还准?这数据有点意思
先看一张表,数字不会撒谎:
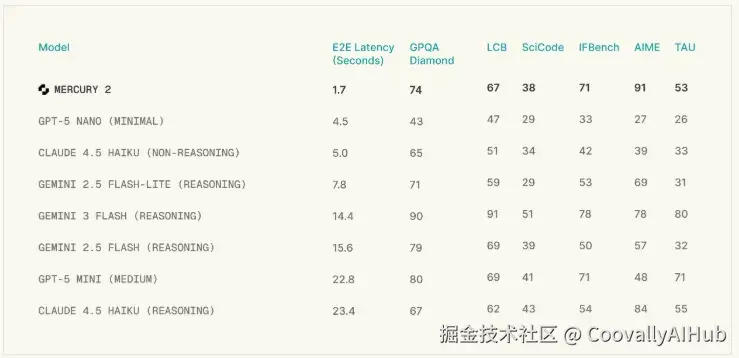
1.7秒 vs 20多秒。这不是快了一星半点,这是从"我去倒杯水"到"我眨个眼"的区别。
吞吐量更夸张,Mercury 2能干到每秒1000个token,而Claude Haiku和GPT-5 Mini只有可怜的90个上下。换算成钱的话,Mercury 2每百万输入tokens收0.25美元,输出0.75美元------大概是GPT-5 Mini的四成,Claude Haiku 4.5的六分之一。
速度快10倍,成本砍一半,这对做实时语音助手、搜索引擎、代码补全或者多Agent系统的开发者来说,简直是降维打击。
NVIDIA那边也有人出来站台:"Inception的Mercury 2,展示了新架构和NVIDIA基础设施结合能爆发出什么。在NVIDIA GPU上破每秒1000token,说明我们平台在各种AI负载下的性能、扩展性和适应性,确实够硬。" ------ Shruti Koparkar,NVIDIA加速计算产品组高级产品经理。

当然,有人会嘀咕:这么快,质量能看吗?
实测数据倒挺打脸。AIME 2025数学拿了91.1分,GPQA Diamond(研究生级别的科学问答)74分,指令遵循的IFBench表现也不赖。扩散模型的迭代机制,反而因为能全局纠错,在某些时候生成的内容比逐字敲出来的更连贯。
不只是个好看的Demo
Mercury 2在工程上也做得挺实诚。
128K上下文窗口 ,够你塞一部长文档进去聊天了。工具调用 和JSON输出都支持,这意味着它能直接扔进现有的Agent工作流里干活,不用你二次开发。
这三板斧凑齐,基本上就把生产级应用的门槛给踩平了。尤其适合那些需要高吞吐推理的多Agent系统、RAG检索,或者对延迟敏感的实时交互场景。
官方特别强调,他们优化的是用户能真实感知到的速度:高并发下的P95延迟、对话过程中的稳定输出、系统忙时的吞吐不跳水。
上手玩了玩,有点意思
他们有个参数叫 reasoning_effort(推理力度) ,让你在速度和深度之间自己掂量。
我随手扔了个问题:"洗车店离我50米,应该步行还是开车去?"
低推理模式下,回答干脆利落:走路呗,这么近,省油,几分钟就到。
高推理模式下,它开始琢磨了------等一下,洗车店是什么类型的?如果是那种drive-in的自动洗车,你得开车进去才行;如果是自助洗车,步行也无妨。最后给出的建议是:大多数情况下,还是开车稳妥。
这个小细节其实挺能说明问题:给模型更多"思考时间",它确实能挖出更深层的逻辑。这不就是推理模型该干的事儿吗?
又试了篇长文摘要,扔了篇近万字的技技术文章过去,要求按章节总结、润色语气、强化开头结尾。结果三秒不到,活儿全干完了。同样的任务扔给ChatGPT,光思考就得25秒,再花10秒生成,加起来奔着35秒去了。
12倍的差距,在批量处理的时候,就是实打实的效率和成本优势。
它在生产环境里能干什么
官方列举了几个Mercury 2特别擅长的场景,都是对延迟敏感、用户体验至上的活儿。
- 编程与代码编辑
自动补全、下一步编辑建议、代码重构、交互式助手------这些需要人全程盯着的流程,卡一下,思路就断了。
"它的建议快到让你感觉像自己脑子里的想法,根本不用等。" ------ Max Brunsfeld,Zed联合创始人
- 智能体循环
Agent工作流里,每个任务都得串几十次模型调用。减少单次延迟,省的不只是时间,而是决定了你能在规定时间内跑多少步,最终结果能好多少。
"我们用最新的Mercury模型,大规模优化广告投放。实时洞察加动态增强,跑出了更强的性能、更高的效率,广告生态也更有韧性。" ------ Adrian Witas,Viant公司高级副总裁兼首席架构师
"我们一直在测Mercury 2,这低延迟和高品质,对实时转录清理和交互式人机界面太珍贵了。目前还真没见过能跟Mercury拼速度的。" ------ Sahaj Garg,Wispr Flow首席技术官兼联合创始人
"对我们来说,Mercury 2至少比GPT-5.2快一倍,完全是颠覆性的。" ------ Suchintan Singh,Skyvern首席技术官兼联合创始人
- 实时语音与交互
语音接口对延迟的要求,是AI领域最苛刻的。Mercury 2让推理级别的质量,能在自然的对话节奏里跑起来。
"我们做的是能跟真人实时对话的AI虚拟形象。低延迟不是加分项,是地基。Mercury 2是我们语音栈的大突破:它又快又稳的文本生成,让整个交互保持住了那种自然和人性。" ------ Max Sapo,Happyverse AI首席执行官兼联合创始人
"Mercury 2质量很硬,低延迟让语音Agent的反应快了一大截。" ------ Oliver Silverstein,OpenCall首席执行官兼联合创始人
- 搜索与RAG流程
多跳检索、重排序、摘要,这些步骤的延迟会迅速叠加上去。Mercury 2让你在不突破延迟预算的前提下,把推理能力塞进搜索流程。
"跟Inception的合作,让我们的搜索产品能实时用上AI。不管是客户支持、合规风控、数据分析还是电商,每个SearchBlox客户,都能从对自己数据的亚秒级智能分析里拿到好处。" ------ SearchBlox团队
扩散这条路,能走多远?
说实话,自回归统治语言模型快七年了。从GPT-2开始,所有人都在沿着同一条路狂奔------更大的模型、更长的上下文、更复杂的提示词。Mercury 2的意义在于,它证明了LLM不止这一条路。
在速度、质量、成本这个不可能三角里,扩散范式找到了一个新的生态位。
当然,它也不是没有短板。
- 生态还是太嫩。 开发者工具链、微调支持、社区积累,跟GPT和Claude没法比。真要落地到复杂业务里,可能会踩不少坑。
- 复杂推理的天花板也还有待验证。 GPQA Diamond上,Mercury 2拿74分,但Gemini 3 Flash(Reasoning)能到90分。对于那些需要极深推理链的任务,扩散这种并行优化的机制,能不能打赢自回归的步步为营,还得看后续迭代。
- 长文本生成的质量,以及在创意写作、多语言这些领域的泛化能力,也还需要更多人拿真金白银的业务去试。
AI的未来,可能不用等那么久
Mercury 2算不上完美,但它确实撕开了一个口子。它用扩散取代自回归,把速度提了10倍,成本砍了大半,质量还没掉链子。
把这几个亮点再捋一遍:
- 范式换了: 从"打字员"到"编辑",全球第一批商用的扩散LLM
- 速度确实快: 1000 tokens/秒,端到端1.7秒,比主流快一个数量级
- 成本确实低: 0.25美元/百万输入tokens,大概是竞品的零头
- 质量没缩水: AIME 2025数学91.1分,GPQA Diamond 74分
- 拿来就能用: 128K上下文、工具调用、JSON输出,部署不折腾
对那些正在折腾实时AI应用、多Agent系统,或者被推理延迟折磨得头疼的开发者来说,Mercury 2提供了一个挺诱人的新选项。
往后看,语言模型的世界可能会变成"自回归"和"扩散"两条腿走路------就像当年CNN和Transformer在视觉领域打来打去,最后谁也干不掉谁,反而共存成了常态。
说实话,AI要是能少"思考"一会儿,也挺好。
相关信息
模型名称:Mercury 2 Reasoning Model
开发团队:Inception Labs(斯坦福、UCLA、康奈尔学者联合创立)