开篇
多智能体系统比单 Opus 4 强 90.2%。
这不是我瞎编的,是 Anthropic 官方说的。同一个 AI 模型,为什么换了个架构就能强这么多?
答案藏在四个字里:分工协作。
第一章:Claude Agent Teams 是什么
Claude Agent Teams 是什么?
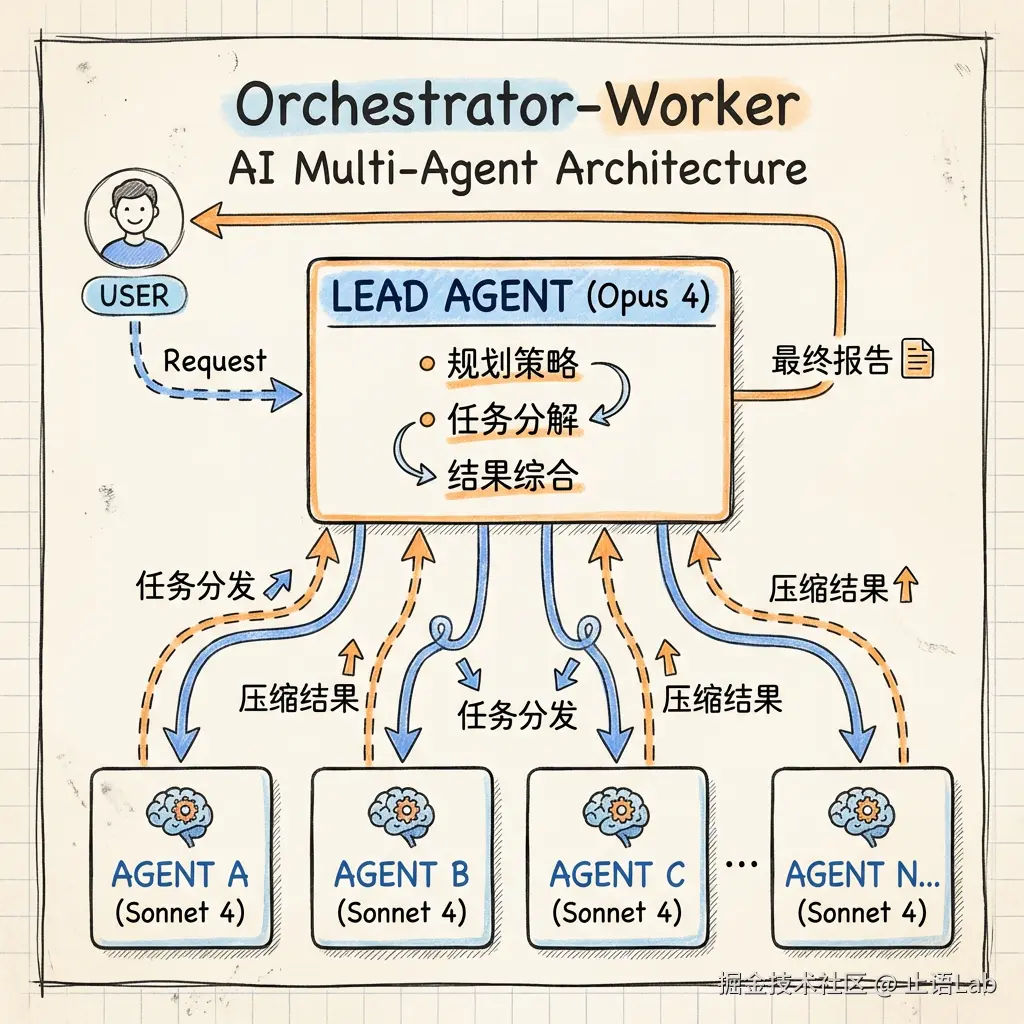
一个"领导"带一帮"小工"干活的架构。
你可能觉得这听起来像在说公司。没错,就是这个意思。它的正式名字叫 Orchestrator-Worker(编排者-执行者模式) ------一个编排者统筹全局,多个执行者并行干活。
不是产品,是范式
Claude Agent Teams 不是 Anthropic 的某个单一产品。它是一种架构范式------就像"微服务"不是一个产品,而是一种架构思路。
你在这些地方能看到它:
- Claude Research 模式:Claude 内置的深度研究功能,背后就是多智能体架构
- Claude Agent SDK:Anthropic 官方 SDK,让你自己构建多智能体系统
- Claude Code:代码助手工具,也用到了多智能体协调
感兴趣的话,可以查看 Claude Agent SDK 文档自己动手搭一个。
核心角色
这套架构有两个核心角色:
Lead Agent(领导) :用 Claude Opus 4 担任。负责接收任务、制定策略、分配工作、综合结果。它不干具体活,只管统筹。
Sub-Agent(小工) :用 Claude Sonnet 4 担任。负责执行具体子任务。每个 Sub-Agent 有独立的上下文窗口------可以理解为 AI 的"短期记忆",每个 Agent 只记自己的事,互不干扰。
为什么 Lead 用 Opus 4、Sub-Agent 用 Sonnet 4?因为统筹需要更强的推理能力,执行则更看重成本效率。用 Opus 4 干所有事太贵,用 Sonnet 4 统筹又不太放心。
关键数据
Anthropic 在官方博客里给了两个关键数据1:
- 性能提升 90.2% :多智能体系统比单 Opus 4 在内部评测中强 90.2%。注意,这是内部 benchmark,不是公开数据集------但量级是可信的。
- Token 消耗约 15 倍:Token 可以理解为 AI 的"字数"。多智能体系统消耗的 Token 是普通聊天的 15 倍。成本是现实约束,用之前要算账。
你只需要知道:Claude Agent Teams 是一种"领导+小工"的架构范式,比单 AI 强 90%,但成本也高 15 倍。Lead 用 Opus 4 统筹,Sub-Agent 用 Sonnet 4 执行。
第二章:为什么多 Agent 比单 Agent 强
90% 的性能提升从哪来?这背后是四个机制的叠加。
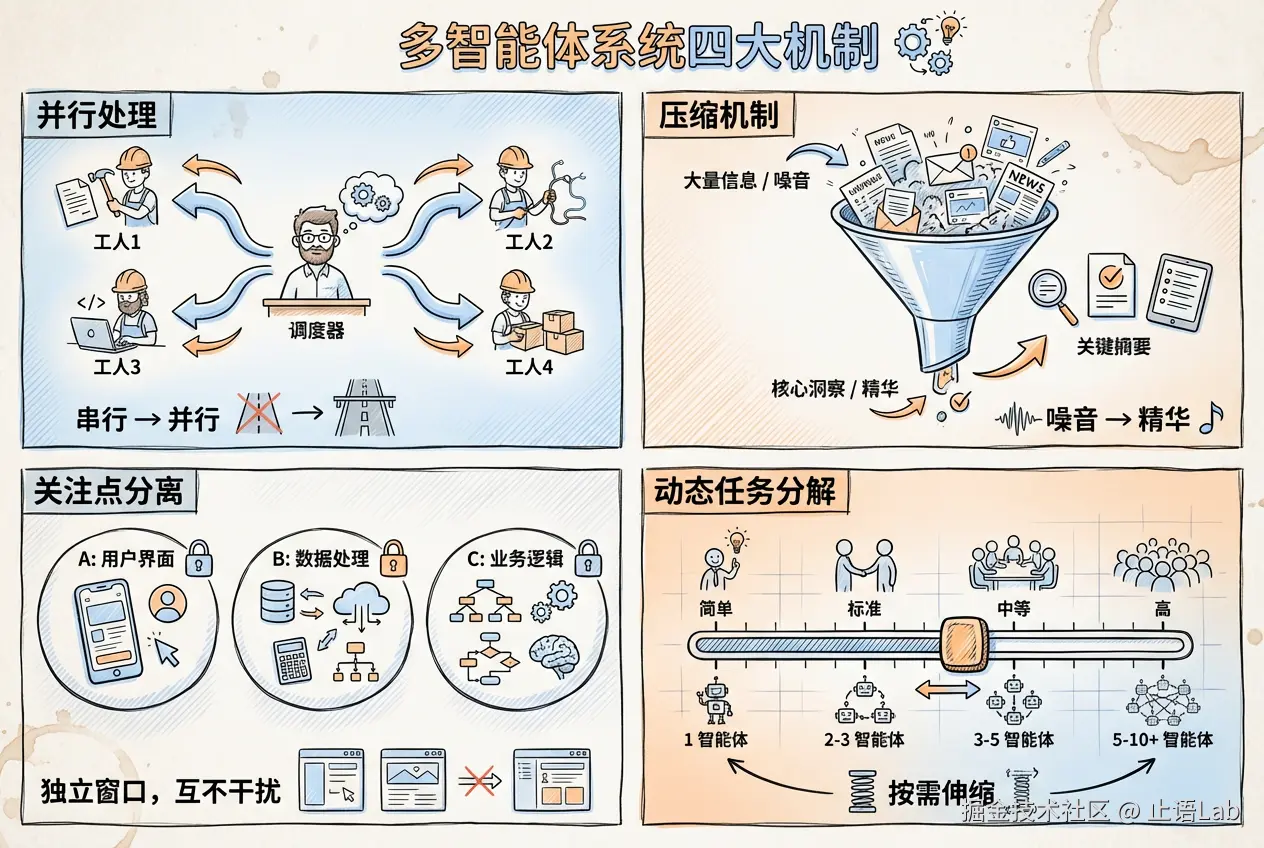
机制一:并行处理
单 Agent 一次只能干一件事。让它找 10 份资料,它得一份一份看,看完第一份可能已经忘了最后一份说了啥。
多 Agent 不一样。Lead Agent 把任务拆成 10 份,同时派给 10 个 Sub-Agent。大家同时看,同时返回。
时间从"串行累加"变成"最长那个子任务的时间"。
举个例子:你要调研 AI 编程工具市场。
单 Agent 的做法:先搜"AI 编程工具评测",读完;再搜"AI 编程工具市场份额",读完;再搜"GitHub Copilot vs Cursor",读完......假设每个搜索+阅读要 2 分钟,10 个主题就是 20 分钟。
多 Agent 的做法:Lead Agent 同时派 10 个 Sub-Agent 各自搜一个主题。2 分钟后,所有结果一起返回。时间从 20 分钟变成 2 分钟。
机制二:压缩机制
每个 Sub-Agent 看完自己的部分,只返回核心发现。
就像每个研究员看完自己的资料后,只汇报核心发现给项目组长------不是把原始材料全部塞给领导,而是提炼后的结果。
这是多智能体系统最聪明的设计之一:Sub-Agent 在各自的上下文窗口里处理大量信息,然后压缩成几百字返回。Lead Agent 不需要处理原始材料的噪音。
机制三:关注点分离
每个 Sub-Agent 有独立的上下文窗口。
什么意思?Agent A 在研究"市场规模",Agent B 在研究"竞争格局",它们互不干扰。Agent A 不会突然把市场数据塞到 Agent B 的脑子里。
这在单 Agent 里很难做到------所有信息都挤在一个上下文里,容易"串台"。你让它同时关注市场规模和竞争格局,它可能会把两个问题混在一起回答。
机制四:动态任务分解
Lead Agent 不是死板地按固定模式拆任务。它会根据问题复杂度动态调整:
| 问题复杂度 | Sub-Agent 数量 | 示例 |
|---|---|---|
| 简单 | 1 个 | "今年税收截止日期是什么?" |
| 标准 | 2-3 个 | 需要多角度的问题 |
| 中等 | 3-5 个 | 需要不同方法论的问题 |
| 高 | 5-10 个(最多 20 个) | 广泛多部分查询 |
就像项目经理根据项目大小决定团队规模,而不是什么项目都拉 20 个人。
单 Agent vs 多 Agent 速览
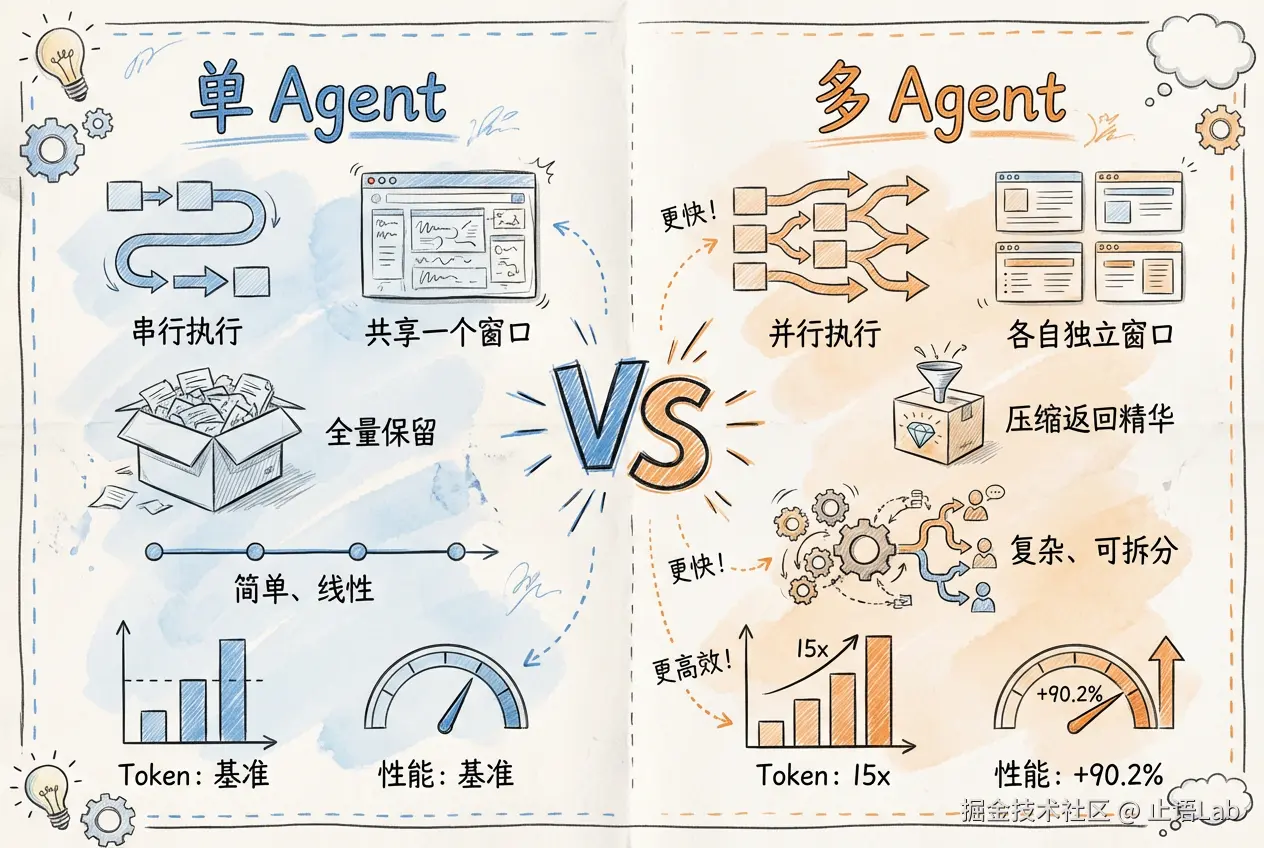
你只需要知道:多 Agent 强在并行、压缩、分离、动态分解。核心是"分工"------让对的人干对的事。
第三章:七步工作流------从问题到答案
具体怎么干活?Anthropic 给了一个七步流程:
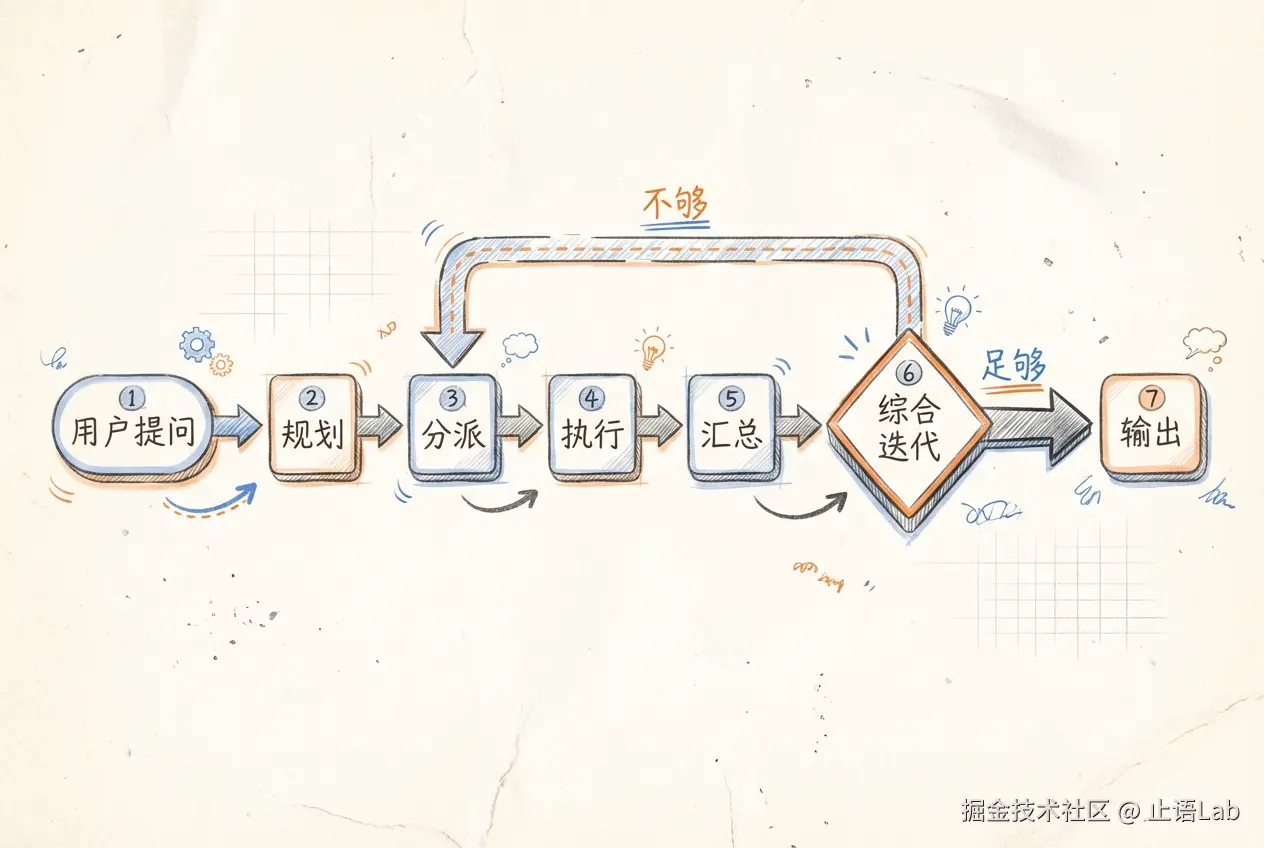
1. 用户提问
你把问题扔给系统。
比如:"帮我分析一下 2025 年 AI 编程工具的市场格局"。
2. 规划
Lead Agent 接收问题,制定策略。
它会想:这个问题需要哪些信息?从哪找?分几步?然后把计划存到外部记忆------防止上下文太长被截断。
外部记忆是多智能体系统的关键设计。Lead Agent 把研究计划存进去,随时可以回看,不用担心上下文窗口溢出。
3. 分派
Lead Agent 创建 Sub-Agent,分配任务。
比如:
- Sub-Agent A:搜索技术博客,找 AI 编程工具评测
- Sub-Agent B:搜索投资报告,找市场数据
- Sub-Agent C:搜索 GitHub,找开源项目热度
每个 Sub-Agent 收到的是清晰、独立的子任务。
4. 执行
每个 Sub-Agent 独立干活。
它们各自搜索、调用工具、读文档。关键是交错思考(Interleaved Thinking) ------不是机械执行,而是边做边调整。搜到一个结果,评估质量,不够就换关键词继续搜。
这是 Sub-Agent 和简单脚本的差别:它能判断结果好不好,然后优化下一步。
5. 汇总
Sub-Agent 把发现返回给 Lead Agent。
不是原始材料,是压缩后的核心发现。比如:"从 5 篇博客中找到 12 个主流工具,其中 Copilot 和 Cursor 被提及最多,市场份额数据缺失"。
6. 综合迭代
Lead Agent 整合所有发现,判断是否足够。
如果不够,它会再派 Sub-Agent 补充调查。可能迭代几轮,直到信息充分。
7. 输出
Lead Agent 生成最终报告,包含引用来源。
Anthropic 还有一个专门的 CitationAgent,负责检查引用是否准确、来源是否可靠。
你只需要知道:七步流程是"提问→规划→分派→执行→汇总→综合→输出"。关键是 Lead Agent 的统筹和 Sub-Agent 的独立执行。
第四章:什么任务适合多智能体
多智能体是工具,不是银弹。用对了事半功倍,用错了就是"杀鸡用牛刀"。

快速判断
你的任务适合多智能体吗?问自己一个问题:
能不能拆成独立子任务并行执行?
- 能 → 适合
- 不能 → 不适合
再补充一个问题:这个任务值不值得花 15 倍 Token 成本?
- 值得 → 可以用
- 不值得 → 用单 Agent 更划算
你只需要知道:适合"高价值、可并行、信息量大"的任务。不适合"简单、高依赖、需要全局视角"的任务。用之前算算账。
第五章:八条实用法则------让 Agent 更好用
Anthropic 在官方文章里总结了八条实用法则。我挑最实用的四条:
法则一:像你的 Agent 一样思考
在让 Agent 干活之前,先在 Claude Console 里模拟一遍。
假装你是 Agent,看看你会怎么理解任务、会调用什么工具、会遇到什么问题。这样能提前发现 prompt 里模糊的地方。
举个例子:你让 Agent"帮我调研 AI 编程工具"。
模拟一下:Agent 收到这个指令,会怎么理解?"AI 编程工具"指哪些?Copilot 算不算?Cursor 算不算?要调研市场、技术、还是用户评价?
发现模糊点后,把 prompt 改成:"帮我调研 2025 年主流 AI 代码助手工具,包括 GitHub Copilot、Cursor、Claude Code、Codeium,重点关注市场份额、用户评价、技术架构"。
清晰多了。
法则二:工具设计至关重要
Agent 的能力边界由工具决定。
工具描述要清晰:告诉 Agent 这个工具能干嘛、不能干嘛、什么时候用。最好加几条启发式规则------比如"如果搜索结果少于 3 条,换关键词"。
模糊的工具描述是 Agent 瞎干活的主要原因。
反面例子:
scss
search(query): 搜索网络信息Agent 不知道什么时候用、返回什么格式、结果不可靠怎么办。
正面例子:
diff
search(query): 搜索网络信息,返回前 10 条结果的标题、摘要、链接。
适用场景:需要最新信息、事实性内容、实时数据。
启发式规则:
- 如果结果少于 3 条,尝试换关键词重新搜索
- 如果结果质量不高,在 query 后加 site: 限定来源
- 如果需要学术资料,加 site:arxiv.org法则三:根据复杂度伸缩投入
简单任务用简单方案。
"今天税收截止日期是什么"------派 1 个 Sub-Agent 就够,没必要搞 10 个。
复杂任务才需要多 Agent。不要"杀鸡用牛刀",也不要"牛刀杀鸡"。
Anthropic 官方博客提到,任务完成时间和 Token 消耗高度相关。过度设计多智能体,既浪费时间又浪费钱。
法则四:并行工具调用
有两层并行:
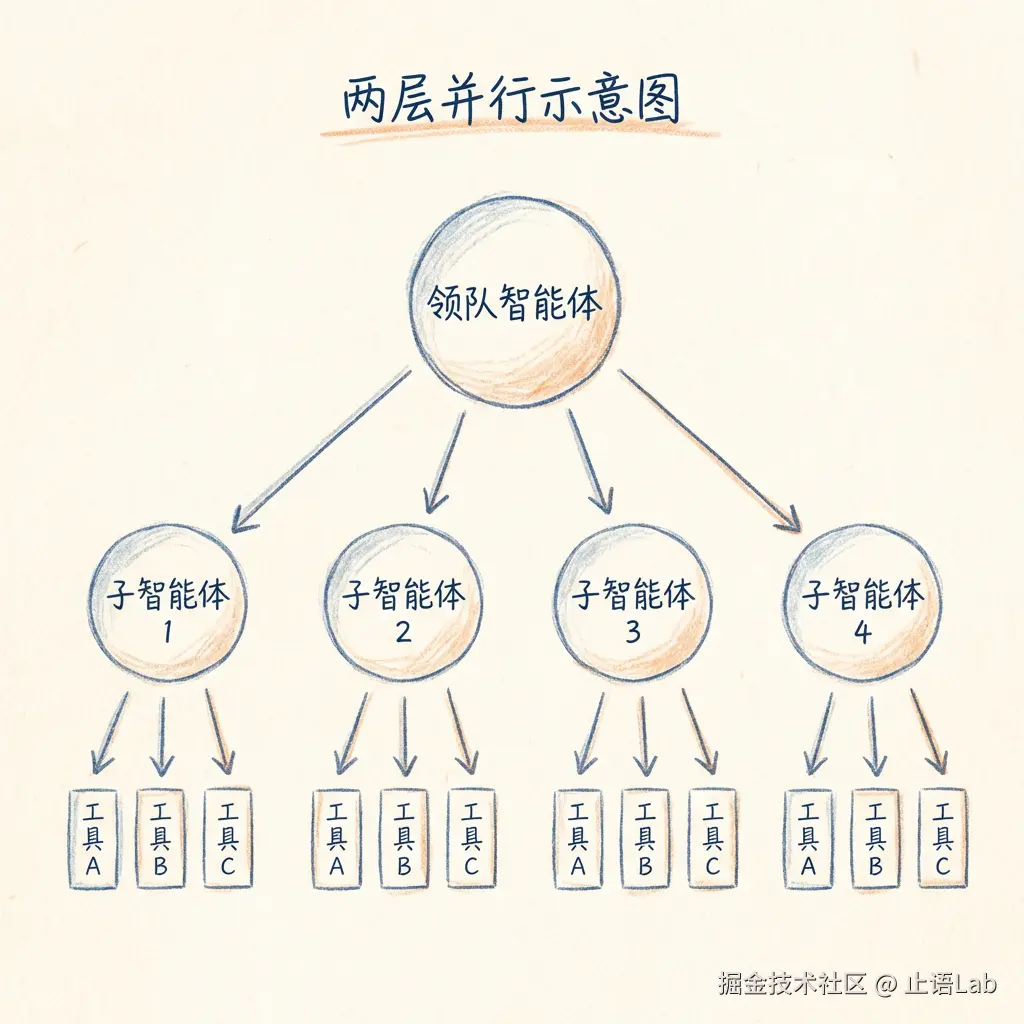
Anthropic 提到,并行工具调用可以把复杂查询的耗时减少 90%。
你只需要知道:核心是"像 Agent 一样思考"和"工具设计清晰"。这两条做对了,大部分问题都能避免。并行调用能大幅节省时间。
第六章:MCP------Agent 的万能接口
多智能体系统需要调用各种工具:搜索、数据库、API、文件系统......
问题来了:每个工具都有自己的接口。Agent 要学每个工具的"方言"。
MCP(Model Context Protocol)就是来解决这个问题的。
MCP 是什么
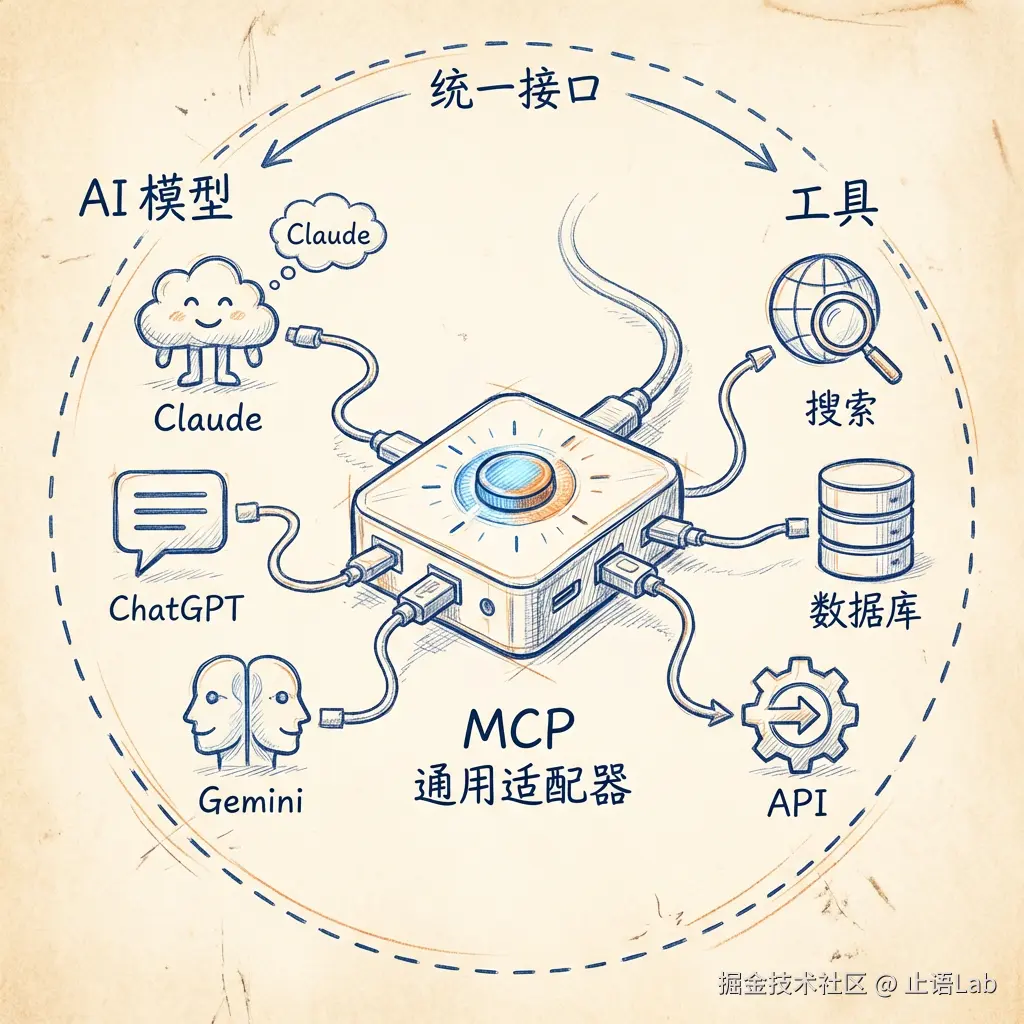
MCP(Model Context Protocol,模型上下文协议) ------一个标准化协议,让 AI 能用统一的方式调用各种工具。
类比一下:MCP 对 AI Agent 的意义,就像 REST 对 Web API 的意义------不是唯一方案,但正在成为事实标准。
再换个类比:MCP 就像 AI Agent 的"万能充电器接口"。以前每个工具都有自己的接口,AI 要学每个工具的"方言"。MCP 统一了接口------AI 只需要学一种"普通话",就能和所有工具对话。
为什么重要
一次构建,多处使用。你按 MCP 协议写一个工具,所有支持 MCP 的 AI 都能用------Claude、ChatGPT、Gemini......
不用为每个 AI 单独写集成。开发一次,到处运行。
采用情况
MCP 由 Anthropic 开发,现在移交 Linux Foundation 管理,成为开放标准。这很重要------避免了被单一厂商锁定。
据 CNCF 报道2,多家主流 AI 公司已采用或正在评估 MCP。具体采用程度因公司而异,但趋势是明确的:MCP 正在成为行业基础设施。
云原生视角
KubeCon Europe 2026(3 月 23-26 日,阿姆斯特丹)专门设了 Agentics Day,讨论 MCP 在生产环境的应用。
这说明一件事:多智能体系统已经不是实验室玩具,而是企业正在认真对待的生产技术。
Kubernetes + MCP 的组合正在成为主流方案:Kubernetes 提供可扩展性、安全性、可观测性,MCP 提供工具连接标准。
CNCF CTO Chris Aniszczyk 说得好:"Kubernetes 的弹性、Istio 的安全、OpenTelemetry 的可观测性------Agent 不需要重新发明这些轮子。"
你只需要知道:MCP 是 AI 工具连接的标准协议,正在成为行业基础设施。你写的工具按 MCP 协议来,就能被各种 AI 使用。云原生基础设施已经解决了 Agent 的可扩展性问题。
结尾:不是所有任务都需要多智能体
多智能体系统很强大,但不是万能的。
简单任务用单 Agent 就够。你问"今天天气怎么样",不需要派 10 个 Sub-Agent 并行调研天气 App、气象局网站、历史数据......
复杂任务才需要多 Agent。关键是判断:这个任务能不能拆成独立子任务并行执行?
还有一个现实问题:成本。多智能体消耗的 Token 是普通聊天的 15 倍。用之前算算账------这个任务的产出值不值得这个成本?
你的任务适合多智能体吗?
如果不确定,可以先问自己:如果这是一个人来干,需要多少人?
一个人能干完的,可能就不需要多智能体。需要团队协作的,才值得考虑多智能体架构。
参考资料
- How we built our multi-agent research system --- Anthropic 官方博客:核心数据来源
- KubeCon Europe 2026 Agentics Day --- CNCF 博客:MCP 协议和云原生实践
- Agentic Engineering Patterns --- Simon Willison:ReAct 模式和 Agent 工程实践