从零搭建本地 RAG 知识库
本文是使用手册------适合零基础读者,20 分钟搭建一个完全离线的 AI 文档问答系统。
想深入理解原理并亲手写出全部代码?请阅读配套教程:三、手把手教你从零写一个本地 RAG。
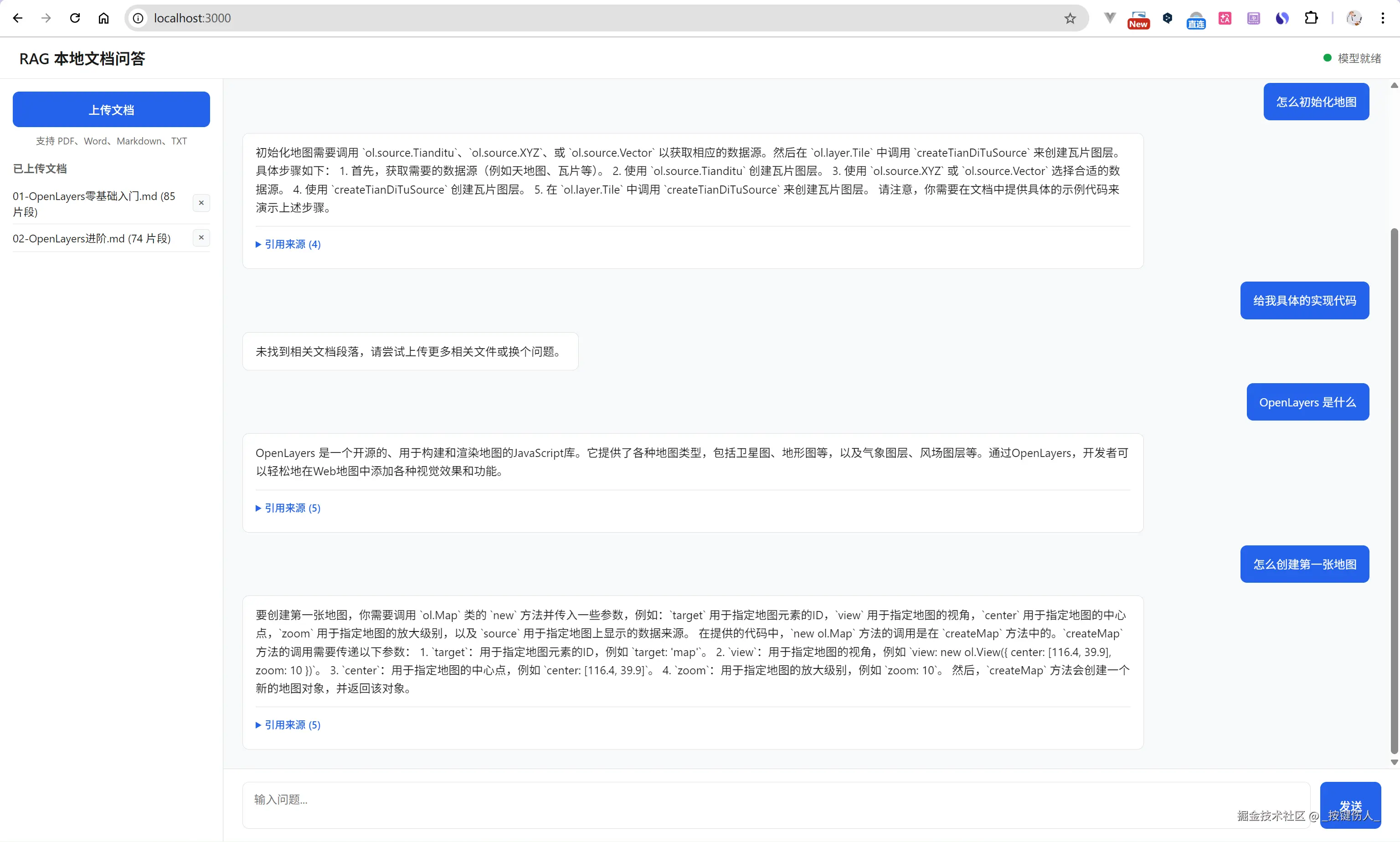
上图就是搭建完成后在浏览器中看到的界面------左侧上传文档、右侧提问、AI 流式回答并标注引用来源。
一、什么是 RAG?
RAG 是 Retrieval-Augmented Generation 的缩写,中文叫"检索增强生成"。
用大白话说:你有一堆文档(PDF、Word、Markdown),你想问 AI 这些文档里面讲了什么。但 ChatGPT 这类在线 AI 看不到你本地的文件。RAG 的做法是让 AI 先"翻书"再回答:
你的文档 → 切成小块 → 每块转成数学向量 → 存入向量数据库(翻书准备)
你提问题 → 问题也转成向量 → 在数据库里找最相似的文档块(翻书)
找到的文档块 + 你的问题 → 一起发给 AI → AI 基于文档内容回答(回答)这样 AI 就能"看懂"你的文档了,而且全程在你电脑上运行,不需要联网。
想更系统地理解 RAG 的 What/Why/How,以及向量、维度、相似度等核心概念?请阅读 一、理解 RAG:从概念到实践。
二、你需要准备什么
| 条件 | 说明 |
|---|---|
| 操作系统 | Windows 10/11(64 位) |
| 硬盘空间 | 至少 2GB(代码很少,主要是模型文件 ~500MB) |
| 内存 | 建议 4GB 以上 |
| 网络 | 首次安装时需要下载模型(后续完全离线) |
不需要:显卡(纯 CPU 就能跑)、Python、Docker、API Key。
三、一步步搭建
第 1 步:安装 Node.js
- 打开浏览器,访问 nodejs.org
- 下载左边的 LTS 版本
- 双击
.msi文件,一路 Next 安装 - 验证:按
Win + R,输入cmd回车,输入:
bash
node --version看到 v20.x.x 就安装成功了。
第 2 步:获取项目代码
把项目文件夹放到你喜欢的位置。打开命令行(在文件夹地址栏输入 cmd 回车),你应该在类似这样的路径:
makefile
D:\personal\AI\rag第 3 步:安装项目依赖
bash
# 安装依赖(跳过原生编译)
npm install --ignore-scripts
# 单独构建原生模块
npm rebuild sharp onnxruntime-node为什么分两步?
sharp是@xenova/transformers的间接依赖(处理图片用的),安装时需要从 GitHub 下载文件,国内网络经常超时导致整个npm install失败。--ignore-scripts先跳过所有原生编译,再用rebuild单独处理。
看到 rebuilt dependencies successfully 就成功了。
第 4 步:下载 AI 模型
bash
npm run setup这个命令会自动下载两个模型:
| 模型 | 作用 | 大小 |
|---|---|---|
| all-MiniLM-L6-v2 | 把文字转成数学向量(做搜索用) | ~80MB |
| Qwen2.5-0.5B | AI 大脑(生成回答用) | ~400MB |
小知识 :Qwen2.5-0.5B 的文件后缀是
.gguf------这是一种模型文件格式。下载完成后脚本会自动校验文件的"魔数"(文件头 4 个字节是否是 GGUF),确保文件没有在传输中损坏。
网络问题? 如果报ECONNREFUSED 127.0.0.1:443或ETIMEDOUT,通常是系统代理(翻墙工具等)干扰了下载。脚本已做了自动清代理 + 切换国内镜像(hf-mirror.com)+ 超时重试 3 次的处理。如果还是失败,见第五章"网络问题"。
下载成功后会看到:
css
[校验] 模型文件 GGUF 魔数校验通过
[Embedding] 模型文件下载完成
=== 设置完成!运行 npm start 启动应用 ===第 5 步:启动应用
bash
npm start第一次启动会慢一些(加载模型到内存,10~30 秒)。看到以下输出就成功了:
ini
[Embedding] 模型加载完成 (本地): Xenova/all-MiniLM-L6-v2
[LLM] llama-server 就绪
=== RAG 本地 Demo 已启动 ===
访问: http://localhost:3000
==========================打开浏览器,输入 http://localhost:3000 ,就能看到聊天界面了!
小提示:顶部状态栏会显示模型是否就绪------绿色圆点 = 一切正常。
四、怎么用
上传文档
- 点击左侧「上传文档」按钮
- 选择 PDF / Word / Markdown / TXT 文件
- 等待出现"已添加:xxx (N 片段)"提示
- 左侧文档列表出现文件名,说明上传成功
注意:扫描版 PDF(图片做成的)无法识别文字,会提示"无法从文档中提取文本内容"。请使用"可选择文字"的 PDF。
提问
- 在右侧输入框中输入问题
- 按 Enter 发送
- AI 会逐字输出回答
- 回答下方可展开「引用来源」,查看 AI 引用了哪些文档段落
删除文档
点击文档名右侧的 × 按钮即可删除(同时清理磁盘上的原始文件和向量库中的索引)。
实用技巧
- 跨文件提问:上传多个文档后,AI 会同时搜索所有文档
- 回答质量:取决于你上传的文档是否相关------文档越对口,回答越准确
- 模型限制:0.5B 参数是最小号模型,回答比较简洁,但检索能力是靠谱的
五、常见踩坑与解决
网络问题(最常遇到)
| 现象 | 原因 | 解决 |
|---|---|---|
npm install 卡在 sharp |
sharp 需从 GitHub 下载,国内慢 | 用 npm install --ignore-scripts 然后 npm rebuild sharp onnxruntime-node |
npm run setup 报 ECONNREFUSED 127.0.0.1:443 |
系统代理干扰 | 重启命令行窗口再试;脚本已自动清代理 |
npm run setup 报 ETIMEDOUT |
某个 CDN 节点连不上 | 重试即可(脚本自动重试 3 次,每次可能换不同节点) |
| 模型下载后校验失败 | 下载中断导致文件损坏 | 删除 models/llm/ 下的 .gguf 文件,重新 npm run setup |
启动问题
| 现象 | 原因 | 解决 |
|---|---|---|
Cannot find module sharp |
原生模块没构建 | npm rebuild sharp onnxruntime-node |
gguf_init_from_file_ptr: failed to read magic |
模型文件损坏(0 字节或半截) | 删除 models/llm/*.gguf,重新 npm run setup |
[Embedding] 加载失败: fetch failed |
模型文件路径不对或缺失 | 确认 models/embedding/Xenova/all-MiniLM-L6-v2/ 下有 4 个文件 |
| 端口 3000 被占用 | 3000 端口有别的程序在用 | Windows 命令行: set PORT=8080 && npm start |
上传问题
| 现象 | 原因 | 解决 |
|---|---|---|
| 上传报"不支持的文件类型" | 文件扩展名不在支持列表 | 确认文件是 .pdf .docx .md .txt 之一 |
| 上传后文件名乱码 | 编码问题(一些系统上的 multer bug) | 已修复------加了编码自动转换 |
| 上传后"无法提取文本内容" | PDF 是扫描版(图片),没有文字层 | 换用可选择文字的 PDF,或用 OCR 工具先识别 |
| 点击上传弹两次文件框 | label 和 JS 重复触发 | 已修复 |
使用问题
| 现象 | 原因 | 解决 |
|---|---|---|
| AI 回答和问题无关 | 文档内容不匹配 | 上传相关文档,或换个问法 |
页面报 JS 语法错误(Unexpected token '!' 或 ':') |
前端 JS 文件里写了 TypeScript 语法 | 检查是否误改了 public/ 下的 .js 文件 |
| 文档列表 500 错误 | LanceDB 空表状态异常 | 删除 data/lancedb/ 目录,重启 npm start |
| 页面刷新后聊天记录没了 | 这是设计行为------本地 demo 不持久化聊天 | 预期行为 |
六、系统是如何工作的
markdown
┌─────────── 文档入库(离线准备)────────────┐
│ │
│ PDF/Word/MD → 解析纯文本 → 切成小块 │
│ → 每块转成 384 维向量 → 存入 LanceDB │
│ │
└───────────────────────────────────────────┘
↓
┌─────────── 问答查询(在线回答)────────────┐
│ │
│ 你的问题 → 转成 384 维向量 │
│ → 在向量库找最相似的 5 个文档块 │
│ → 文档块 + 问题拼成 Prompt │
│ → llama-server (AI) 逐字生成回答 │
│ → 前端实时渲染 + 引用来源 │
│ │
└───────────────────────────────────────────┘核心组件速查:
| 组件 | 技术 | 干什么 |
|---|---|---|
| 文档解析 | pdf-parse / mammoth / marked | 把各种格式变成纯文本 |
| 文本切分 | 递归字符切分(512 token/块) | 把长文档切成小块,提高检索精度 |
| 向量化 | all-MiniLM-L6-v2(384 维) | 把文字映射到数学空间,含义相近的向量也相近 |
| 向量数据库 | LanceDB(嵌入式,零配置) | 存向量 + 做相似度搜索 |
| LLM 推理 | llama-server.exe + Qwen2.5-0.5B | 接收 Prompt,生成回答 |
| 前端渲染 | marked(Markdown → HTML) | 代码高亮、标题、列表视觉呈现 |
数据存在哪?
| 目录 | 内容 |
|---|---|
data/uploads/ |
你上传的原始文件 |
data/lancedb/ |
切分后的向量索引 |
models/ |
下载的 AI 模型(~480MB) |
bin/ |
llama.cpp 运行环境 |
删除 data/ 目录即可清空所有文档和索引(下次启动自动重建)。
对上面提到的向量、维度、余弦相似度、Embedding 模型等概念想深入了解?一、理解 RAG:从概念到实践 §四 用 8 个小节逐一拆解了这些核心概念。
想深入了解原理?
本文档是"使用手册"------帮你快速跑起来、知道怎么用、遇到问题怎么修。
如果你想理解每一行代码的设计原理 、亲手从零写出这个项目 、知道怎么把它升级为生产级系统,请阅读配套的深度教程:
| 你关心的事 | 在哪本书 |
|---|---|
| 怎么安装、怎么用、出错了怎么办 | 本文档(你正在看) |
| 逐行写出 15 个模块、每个代码为什么这样设计 | 手把手教程 第 2~14 章 |
| 为什么用策略模式做解析器、为什么 LLM 要用子进程管理 | 手把手教程 每章末尾"设计要点" |
| 生产环境怎么选 embedding 模型、向量库、LLM | 手把手教程 第 16 章(含架构图和决策树) |
| 如何评估 RAG 质量(Hit Rate、MRR、NDCG) | 手把手教程 第 16.8 节 |
两份文档互补:本文档让你 20 分钟用起来,手把手教程让你花半天搞懂原理。建议先用本文档跑起来,再读手把手教程加深理解。
八、扩展知识:在线 AI 的背后------不止一个模型在工作
8.1 DeepSeek、豆包、Kimi 是"单模型"吗?
很多人以为 DeepSeek、豆包、Kimi 这些 AI 助手就是"一个大模型在回答问题"。实际上,它们背后是一个复杂的增强系统,单个语言大模型(LLM)只是其中的一环。
以下是它们实际使用的技术组合:
scss
你输入一个问题
│
▼
┌─────────────────────────────────────┐
│ 路由 / 意图识别 │
│ "这个用户想问什么?需要联网吗?" │
│ (可能用一个轻量模型先分类) │
└──────────────┬──────────────────────┘
│
┌──────────┼──────────┬──────────────┐
▼ ▼ ▼ ▼
┌───────┐ ┌───────┐ ┌────────┐ ┌──────────┐
│联网搜索│ │RAG检索│ │调用工具│ │直接回答 │
│(时效性 │ │知识库 │ │计算器等│ │(常识类 │
│ 问题) │ │文档) │ │ │ │ 问题) │
└───┬───┘ └──┬────┘ └───┬────┘ └────┬─────┘
│ │ │ │
└────────┼──────────┼────────────┘
│ │
▼ ▼
┌──────────────────────────┐
│ 上下文组装 │
│ 搜索结果 + 文档 + 工具 │
│ + 历史对话 → Prompt │
└──────────┬───────────────┘
▼
┌──────────────────────────┐
│ 大语言模型 (LLM) │
│ 阅读上下文 + 生成回答 │
└──────────┬───────────────┘
▼
┌──────────────────────────┐
│ 后处理 / 引用 │
│ 添加上下文引用、格式化 │
└──────────────────────────┘核心要点:LLM 只是一个"阅读理解+写作"引擎,它本身没有记忆、不会搜索、不能查最新信息。 所有让它看起来"全知全能"的能力,都来自外围增强系统。
8.2 各家是怎么做的
以下基于公开信息和技术文档总结:
| 能力 | DeepSeek | 豆包 (字节跳动) | Kimi (月之暗面) |
|---|---|---|---|
| 联网搜索 | ✅ 手动开启 | ✅ 自动判断 | ✅ 默认开启 |
| RAG 知识库 | --- | ✅ 豆包支持上传文档问答 | ✅ Kimi+ 支持上传文件 |
| 长文档处理 | 128K 上下文 | 128K 上下文 | 200 万字上下文 |
| 多轮对话记忆 | ✅ | ✅ | ✅ |
| 工具调用 | ✅ 代码解释器 | ✅ 代码执行 | ✅ |
| 推理增强 | ✅ DeepSeek-R1 思维链 | --- | ✅ k1.5 思维链 |
| 多模态 | ❌ 纯文本 | ✅ 图片理解 | ✅ 图片/文件 |
长上下文 ≠ RAG:
Kimi 的"200 万字上下文"是把整个文档直接塞进 LLM 的输入窗口,让模型通读全文再回答。这样做的好处是不丢信息,但代价是推理极慢(读 200 万字要消耗大量计算)、成本高。
RAG 的做法是只检索相关段落喂给 LLM(而不是整本书),成本低、速度快,但可能会漏掉关键段落。
实际产品中两者经常混合使用------先用 RAG 快速筛出相关段落,再放在长上下文中让 LLM 仔细理解。
联网搜索也是 RAG 的一种:
你问"今天天气怎么样"→ 搜索引擎实时抓取网页 → 提取相关片段 → 喂给 LLM → LLM 用自然语言告诉你结果。这和本项目的文档 RAG 原理完全一样------区别只在于"知识来源"是本地的 PDF 文件还是互联网上的网页。
8.3 所以 RAG 的地位是什么
RAG 是 AI 产品的"标配组件",不是可选项。 原因很简单:
| 单靠 LLM | 加上 RAG |
|---|---|
| 只能回答训练数据里有的知识 | 能回答你文档里的专属知识 |
| 知识截止在训练日期(可能已过时一年) | 实时检索最新信息 |
| 容易幻觉------不懂也硬编 | 有源可查------每个回答都对应原文段落 |
| 无法处理私有/机密文档 | 数据不出本地,安全可控 |
这也正是你搭建这个本地 RAG Demo 的价值所在:它让你把 AI 的能力延伸到自己的文档上,而且全程离线、数据安全。
九、常见问答
Q: 能换更大的 AI 模型吗?
可以。去 HuggingFace 或 hf-mirror.com 下载任意 GGUF 格式的模型,放到 models/llm/ 目录,然后修改 src/pipeline/generator.ts 中的 MODEL_FILE 常量。推荐 Qwen2.5-1.5B(~1.5GB)或 3B(~2.4GB),回答质量会明显提升。
Q: 能支持更多文件格式吗?
可以。在 src/pipeline/parser.ts 中添加新的解析函数(如 .pptx、.epub),注册到 PARSERS 字典,并在 SUPPORTED_EXTENSIONS 中添加扩展名。
Q: 怎么让 AI 回答得更准确?
- 换更大的模型------Qwen2.5-1.5B 的回答质量比 0.5B 好很多
- 调整 Prompt 模板(在
src/prompt.ts中) - 调整检索参数:增加 Top-K 值(
src/routes/chat.ts)、降低相似度阈值(src/pipeline/retriever.ts的MIN_SIMILARITY)
Q: 回答太慢怎么办?
0.5B 模型已经很快了。换更大模型会稍慢。想加速:
- 用 GPU:修改
src/pipeline/generator.ts中spawn的-ngl 0为-ngl 99 - 换更强 CPU
Q: 想深入了解原理和代码实现?
项目里还有一份完整的手把手教程 :docs/手把手教你从零写一个本地RAG.md。它带你从空文件夹开始逐行写出这个项目的全部 1500+ 行代码,每行都有设计原理说明。最后还有一章讲解如何将 Demo 升级为生产级 RAG 系统(模型选型、向量库选型、分布式架构等)。
十、项目文件结构速查
bash
rag-local-demo/
├── package.json # 项目配置和依赖
├── README.md # 项目说明
├── docs/ # 文档(本文 + 手把手教程)
├── scripts/setup.ts # 模型下载脚本
├── src/
│ ├── server.ts # 服务器入口
│ ├── prompt.ts # AI Prompt 模板
│ ├── types.ts # 类型定义
│ ├── routes/ # API 路由(上传、对话、文档管理、健康检查)
│ ├── pipeline/ # RAG 核心管线(解析、切分、向量化、检索、生成)
│ └── store/ # 向量数据库操作
├── public/ # 前端页面(HTML + CSS + JS)
├── data/ # 运行时数据(上传文件 + 向量数据库)
├── models/ # AI 模型文件
└── bin/ # llama-server 可执行文件