0. 概念
0.1 为什么需要批处理
LLM以自回归方式进行decode,而decode阶段是典型的数据密集型的计算方式,如果GPU调度时每次只计算一个Sequence,只生成一个token,那简直就是对GPU核心的浪费。所以必须要以Batch的方式去使用GPU,也就是一次处理多个请求。
0.2 批处理
0.2.1 Static Batching
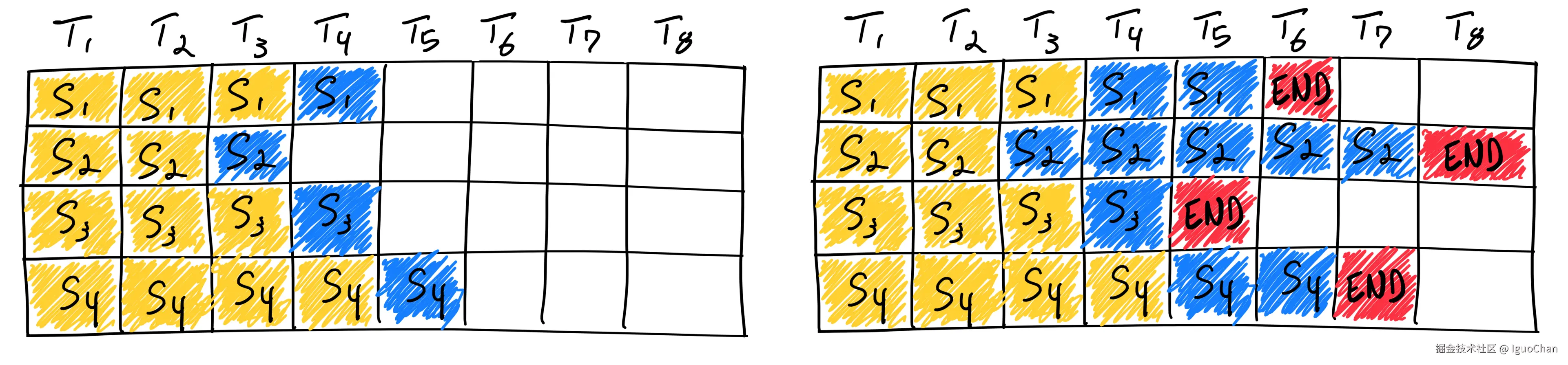
所谓Static Batch,其本质上是 request-level的组Batch逻辑,也就是说一次组装多个Sequence进行并行处理,只有当这个batch中的所有Sequence都处理完成了,这次处理才结束,然后进行下一次推理。可以说这个过程还是不可避免存在某些时间片上GPU核心的空闲,特别是当存在某个超长token的请求在这个批次里的时候,那浪费更甚!
0.2.2 Continuous Batching
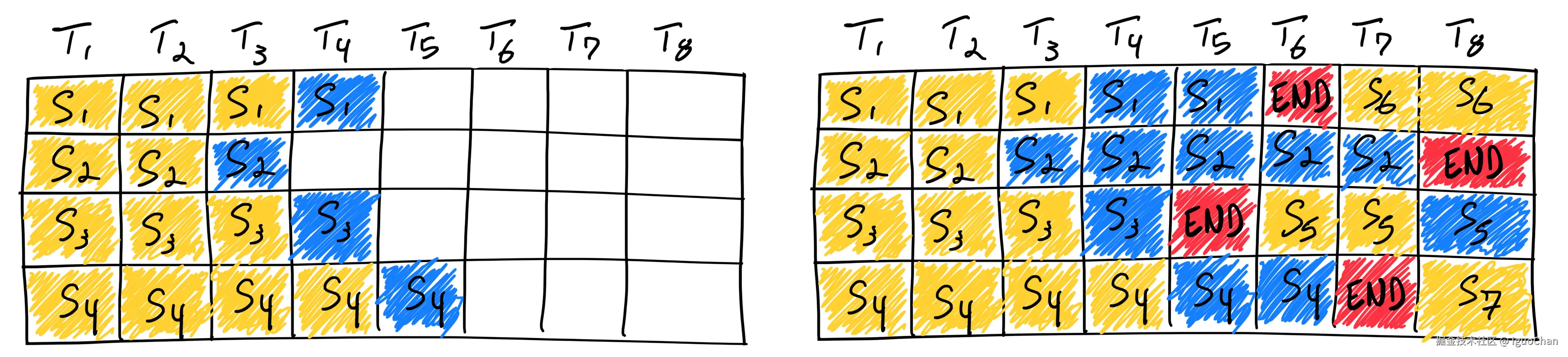
在0. nano-vllm:大模型推理原理和流程中我们讲过,Decode阶段是自回归的,一个token一个token的生成,这就特别适合将组Batch能力设计成如上图所示的形式,在每次生成token后都判断一下这个seq是否结束,如果结束,立马在batch中加入另一个队列来进行处理,从而保证在每次GPU核心处理中都保证batch中处理的Sequence数相同,极大利用GPU核心数。
以上图为例,Batch数为4:
- T1-T4时刻,Batch同时处理Seq1~Seq4;
- 当T5时刻,Seq3生成完了最后一个token,结束请求;
- T6时刻Seq5立马加入Batch进行处理;此时Seq1也正好生成完最后一个token,结束请求;
- T7时刻S6立马加入到Batch处理中。
保证每时每刻Batch都是满的。
注:和现在nano-vllm实现的略有差别的是,上图中黄色部分看起来应该是prefill阶段,而nano-vllm不支持Chunked Prefill,所以prefill和decode不会出现在同一个batch中。
0.3 Chunked Prefill
从以上分析可以看出来,在prefill阶段,小批量的batch就可以很有效地占据GPU计算资源,因为prefill阶段会大批量处理整个Prompt,所以较小的batch就可以有效利用GPU。从论文《SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills》可知,在 A6000 GPU 上,对于 LLaMA13B 模型,即使批处理大小仅为 1,序列长度为 512 个Token的Prefill也会使 GPU 计算达到饱和。
但是,Continuous Batching 本身是一种调度策略 ,它允许动态进出批次,解决了 Decode 阶段的"一人慢,全家等"问题。但它没有改变 Prefill 阶段的计算模式 。在Prefill阶段,咱们还是要等所有的Seq的Prefill结束,即超长的Prompt的Seq还是拉长其他短Prompt请求的TTFT时间。
而在decode阶段,因为KV Cache的存在,每次生成一个token时GPU只需要进行很小的计算,此时要想使得GPU利用率打满,则需要 batch size 非常大才有可能占满 GPU,但这么大的 batch size 会因为 KV Cache 读写开销太大而变得不现实,
所以,在常规分开处理prefill和decode的机制中,无论是prefill还是decode阶段,都因为各种原因很难真正让GPU利用率得到真正的提升。为了能最大化利用GPU,论文《SARATHI: Efficient LLM Inference by Piggybacking Decodes with Chunked Prefills》提出了Chunked Prefill。
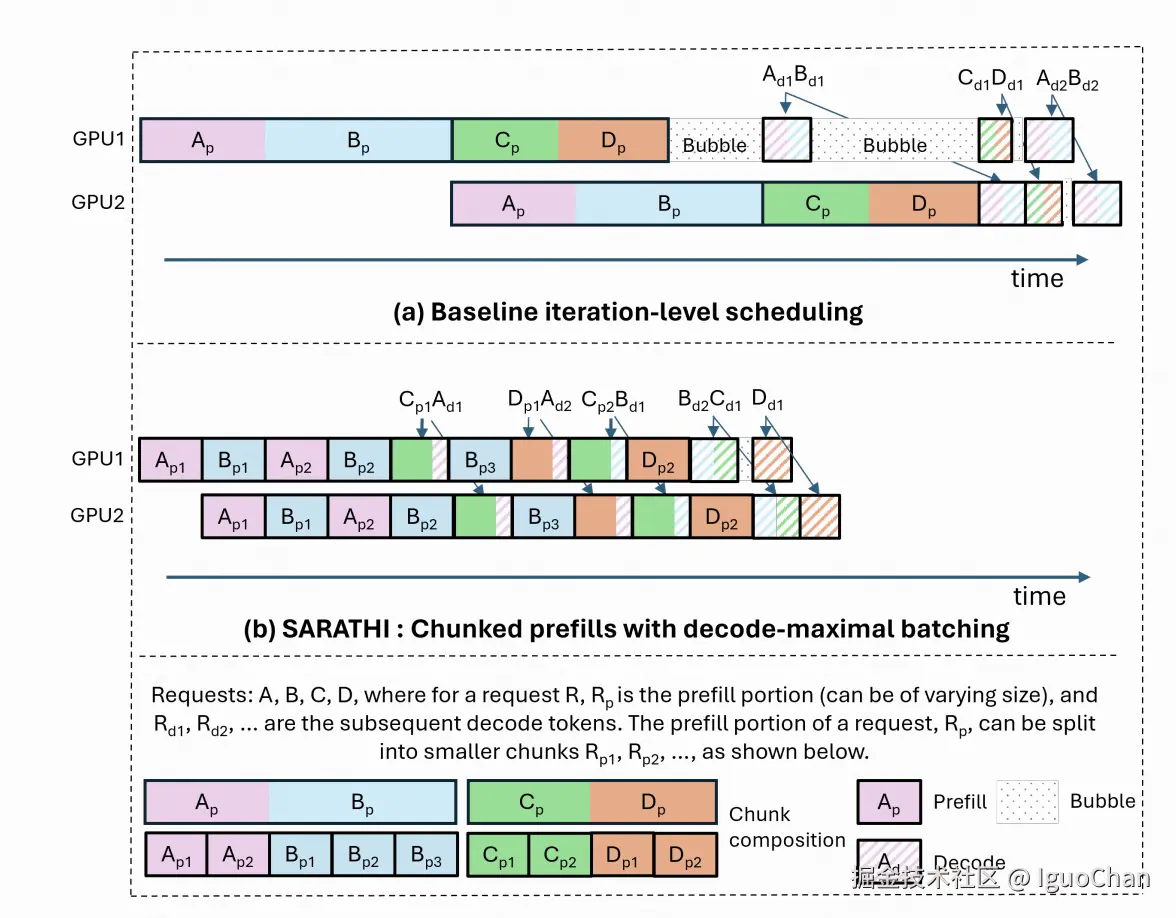
首先将长短不一的 prompts 拆分为长短一致的 chunks 进行 prefill;其次这些 chunks 间的气泡可以插入/捎带(piggyback)其他完成了 prefill 的 prompts 的 decode 需求。
目前 vLLM 的V1已经支持Chunked Prefill,需要通过参数开启;而sglang默认支持切开启Chunked Prefill。
0.4 PD分离
在以上Chunked Prefill过程中,存在两个问题:
-
隔离干扰 :在没有PD分离的混合调度中,Prefill阶段(计算密集,需要读写整个序列的KV Cache)和Decode阶段(内存密集,需要读取全部KV Cache并写入一个新Token的Cache)会交替并随机地竞争显存带宽。这种竞争是激烈且不可预测的,导致Decode的访存延迟波动很大。
-
局部性差 : GPU高速缓存(Cache)的利用效率低下 上。缓存依赖于时间局部性 (同一数据短期内被多次使用)和空间局部性(使用相邻的数据)来加速访问。混合调度破坏了这两种局部性。
前面我们一直提到,prefill阶段和decode阶段的资源需求并不相同:
- prefill阶段:计算密集型,在流量较大或者Prompt较长时,prefill的计算压力很大。完成KV Cache之后,prefill阶段本身并无保留这些缓存的需求;
- decode阶段:存储密集型,由于逐token生成,需要频繁访问KV Cache,因此需要尽可能多的保留缓存数据以保障推理效率。
在论文《DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving》中,通过将大型语言模型的prefill和decode阶段分离,将其分配到不同的GPU上,消除了互相干扰,并针对每个阶段的特定需求进行资源和并行策略的优化,从而提高每个GPU的有效吞吐量。
在现今的生产实现上(vLLM & sglang),PD分离大部分都是按照节点(Node)维度进行分离的,比如说:
- prefill节点:通常配置高速案例的GPU(比如H200),专门处理计算密集型的prefill任务;
- decode节点:通常配置大显存,但是计算能力稍弱的GPU(比如A800),处理内存密集的decode任务。
1. nano-vllm的实现
nano-vllm中并没有实现Chunked Prefill和PD分离,仅仅只是实现了Continuous Batching。
1.1 step函数
step函数是实现Continuous Batching的核心执行循环:
py
def step(self):
seqs, is_prefill = self.scheduler.schedule()
token_ids = self.model_runner.call("run", seqs, is_prefill)
self.scheduler.postprocess(seqs, token_ids)
outputs = [(seq.seq_id, seq.completion_token_ids) for seq in seqs if seq.is_finished]
num_tokens = sum(len(seq) for seq in seqs) if is_prefill else -len(seqs)
return outputs, num_tokens其中第一行返回的seqs长度就是每次调度的batch大小。而在组了batch之后,就是通过调用ModelRunner模块执行当前阶段(prefill or decode);然后通过postprocess进行后处理。所以一个Continuous Batching的简单实现就呈现了。
1.2 schedule函数
1.2.1 prefill
py
def schedule(self) -> tuple[list[Sequence], bool]:
# prefill
scheduled_seqs = []
num_seqs = 0
num_batched_tokens = 0
while self.waiting and num_seqs < self.max_num_seqs:
seq = self.waiting[0]
if num_batched_tokens + len(seq) > self.max_num_batched_tokens or not self.block_manager.can_allocate(seq):
break
num_seqs += 1
self.block_manager.allocate(seq)
num_batched_tokens += len(seq) - seq.num_cached_tokens
seq.status = SequenceStatus.RUNNING
self.waiting.popleft()
self.running.append(seq)
scheduled_seqs.append(seq)
if scheduled_seqs:
return scheduled_seqs, True在prefill阶段,序列数有三重限制:
- 序列数限制 :
num_seqs < self.max_num_seqs - Token数限制 :
num_batched_tokens + len(seq) > self.max_num_batched_tokens - 内存限制 :
self.block_manager.can_allocate(seq)
1.2.2 decode
py
def schedule(self) -> tuple[list[Sequence], bool]:
# ...
# decode
while self.running and num_seqs < self.max_num_seqs:
seq = self.running.popleft()
while not self.block_manager.can_append(seq):
if self.running:
self.preempt(self.running.pop())
else:
self.preempt(seq)
break
else:
num_seqs += 1
self.block_manager.may_append(seq)
scheduled_seqs.append(seq)
assert scheduled_seqs
self.running.extendleft(reversed(scheduled_seqs))
return scheduled_seqs, FalseDecode阶段的双重限制条件:
- 序列数限制 :
num_seqs < self.max_num_seqs - 内存限制 :
self.block_manager.can_append(seq)
关键差异:Decode阶段没有token数限制,因为每个序列只生成1个token。