背景
最近国内的大模型百花齐放,DeepSeek V4系列,Mimo 2.5系列,Kimi2.6,Qwen3.6,Hy3.0...不在一一列举;
为了雨露均沾,充分薅...啊不,充分利用各个模型的优势能力,我们可以在自己的AI助手(OpenClaw,CC,CodeX等),甚至业务系统里一些正在开发或者测试的AI类功能,轮番使用这些国产模型作为基座。注意,我们这样做,不仅仅是为了薅xx,还能测试出哪个国产模型更适配我们的使用场景,毕竟兴趣驱动阶段,一切都是非常高效的。
那为了实现实现这个目的,除了一次次在项目或者AI助手里修改模型配置参数,能不能更自动化的来做这个事?
哎,这就是我们要聊到的AI网关要做的事情了,目前社区内,AI网关类的产品里,LiteLLM绝对是当红炸子鸡,影响力极大。
介绍
关于LiteLLM,还是先给出文档地址;
中文文档:docs.litellm.com.cn/docs/
简单来说,LiteLLM 的核心价值在于:它把上百种不同的 LLM API 统一封装成了 OpenAI 的格式,有以下几点优势;
- 统一接口: 无论你使用的是 GPT系列、Claude系列、Gemini还是DeepSeek等,你只需要写一套 OpenAI SDK 风格的代码,剩下的桥接工作全部由 LiteLLM 完成
- 代理服务 :这是它最强大的功能之一。你可以启动一个本地服务器,将所有模型挂载在它后面。你的应用程序只需要连接到这个本地 Proxy,就能实现负载均衡、自动重试和备选方案。比如,我们可以配置策略,优先用DeepSeek,如果响应慢或者崩了,自动切换到Qwen等其他模型,实现高可用。(文档传送门:docs.litellm.com.cn/docs/routin...)。
- **# 背景
最近国内的大模型百花齐放,DeepSeek V4系列,Mimo 2.5系列,Kimi2.6,Qwen3.6,Hy3.0...不在一一列举;
为了雨露均沾,充分薅...啊不,充分利用各个模型的优势能力,我们可以在自己的AI助手(OpenClaw,CC,CodeX等),甚至业务系统里一些正在开发或者测试的AI类功能,轮番使用这些国产模型作为基座。注意,我们这样做,不仅仅是为了薅xx,还能测试出哪个国产模型更适配我们的使用场景,毕竟兴趣驱动阶段,一切都是非常高效的。
那为了实现这个目的,除了一次次在项目或者AI助手里修改模型配置参数,能不能更自动化的来做这个事?
哎,这就是我们要聊到的AI网关要做的事情了,目前社区内,AI网关类的产品里,LiteLLM绝对是当红炸子鸡,影响力极大。
介绍
关于LiteLLM,还是先给出文档地址;
中文文档:docs.litellm.com.cn/docs/
简单来说,LiteLLM 的核心价值在于:它把上百种不同的 LLM API 统一封装成了 OpenAI 的格式,有以下几点优势;
- 统一接口: 无论你使用的是 GPT系列、Claude系列、Gemini还是DeepSeek等,你只需要写一套 OpenAI SDK 风格的代码,剩下的桥接工作全部由 LiteLLM 完成
- 代理服务 :这是它最强大的功能之一。你可以启动一个本地服务器,将所有模型挂载在它后面。你的应用程序只需要连接到这个本地 Proxy,就能实现负载均衡、自动重试和备选方案。比如,我们可以配置策略,优先用DeepSeek,如果响应慢或者崩了,自动切换到Qwen等其他模型,实现高可用。(文档传送门:docs.litellm.com.cn/docs/routin...)。
- 成本跟踪 :它内置了消费统计功能,可以记录每个 API Key 的 Token 使用情况,并支持设置预算上限,非常适合团队开发使用(传送门:docs.litellm.com.cn/docs/proxy/...)。
- 轻量化:正如其名,它非常轻量,技术门槛也很低,只要懂点配置就能跑起来。
- ...
好了,更多的特性,大家可以翻看官方文档,或者自行GPT
上手
好了,接下来我们在本地环境实际部署一个LiteLLM网关,测试一下
我这里的环境还是WSL,其他的依赖就是docker,其他环境,或者你只是验证一下效果,可以直接使用python脚本来安装,这个官方文档有说明,很简单,我这里不在赘述;
准备环境
进入wsl环境后,创建个临时目录,写入以下配置文件
- litellm-config.yaml
这个文件是litellm的大脑,定义模型如何映射
yaml
model_list:
# 1. DeepSeek
- model_name: deepseek
litellm_params:
model: deepseek/deepseek-chat
api_key: "os.environ/DEEPSEEK_API_KEY"
# 2. 通义千问 (Qwen)
- model_name: qwen
litellm_params:
model: dashscope/qwen-max
api_key: "os.environ/DASHSCOPE_API_KEY"
# 核心策略:如果 DeepSeek 挂了,自动切到 Qwen
router_settings:
routing_strategy: simple-shuffle
enable_fallbacks: true
fallbacks: [{"deepseek": ["qwen"]}]
general_settings:
master_key: sk-admin-123456 # 你的网关管理密钥- docker-compose.yaml
这个就是部署文件,常用docker的小伙伴都熟悉了
yaml
services:
litellm:
image: ghcr.io/berriai/litellm:main-latest
ports:
- "4000:4000"
volumes:
- ./litellm-config.yaml:/app/config.yaml
environment:
# 替换为你真实的 API Key
- DEEPSEEK_API_KEY=sk-your-deepseek-key
- DASHSCOPE_API_KEY=sk-your-qwen-key
command: [ "--config", "/app/config.yaml", "--detailed_debug" ]
restart: always好了,快速上手的话,需要准备的文件就这些
一键启动
进入当前路径,一键执行即可
bash
docker-compose up -d不出意外的话会看到一下输出

然后,我们可以使用LiteLLM的健康检查接口
bash
curl http://localhost:4000/health/readiness输出如下
json
{
"status": "healthy",
"db": "Not connected",
"cache": null,
"litellm_version": "1.82.6",
"success_callbacks": [
"sync_deployment_callback_on_success",
"SkillsInjectionHook",
"_PROXY_VirtualKeyModelMaxBudgetLimiter",
"_PROXY_MaxBudgetLimiter",
"_PROXY_MaxParallelRequestsHandler_v3",
"_PROXY_CacheControlCheck",
"ResponsesIDSecurity",
"_PROXY_MaxIterationsHandler",
"_PROXY_MaxBudgetPerSessionHandler",
"_PROXY_LiteLLMManagedFiles",
"_PROXY_LiteLLMManagedVectorStores",
"ServiceLogging"
],
"use_aiohttp_transport": true,
"log_level": "DEBUG",
"is_detailed_debug": true
}
看到status: healthy,表示部署完成;
测试接入
部署完成后,可以直接在Windows宿主机上使用curl或任何API测试工具(如Postman)发送请求
bash
curl --request POST \
--url http://localhost:4000/v1/chat/completions \
--header 'Authorization: Bearer sk-admin-123456' \
--header 'Content-Type: application/json' \
--data '{
"model": "deepseek",
"messages": [{"role": "user", "content": "你好"}]
}'不出意外的话,相应内容如下
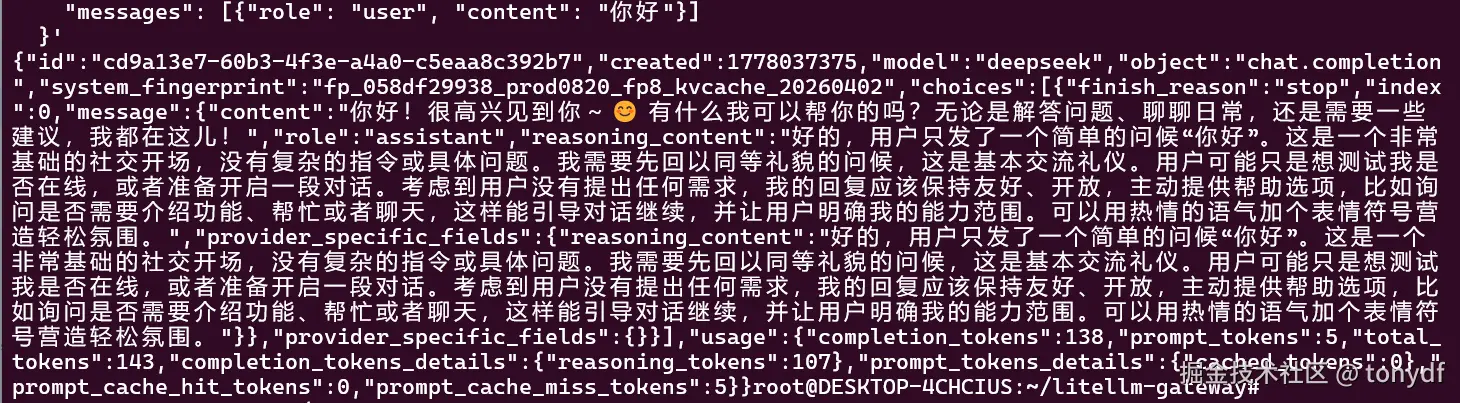
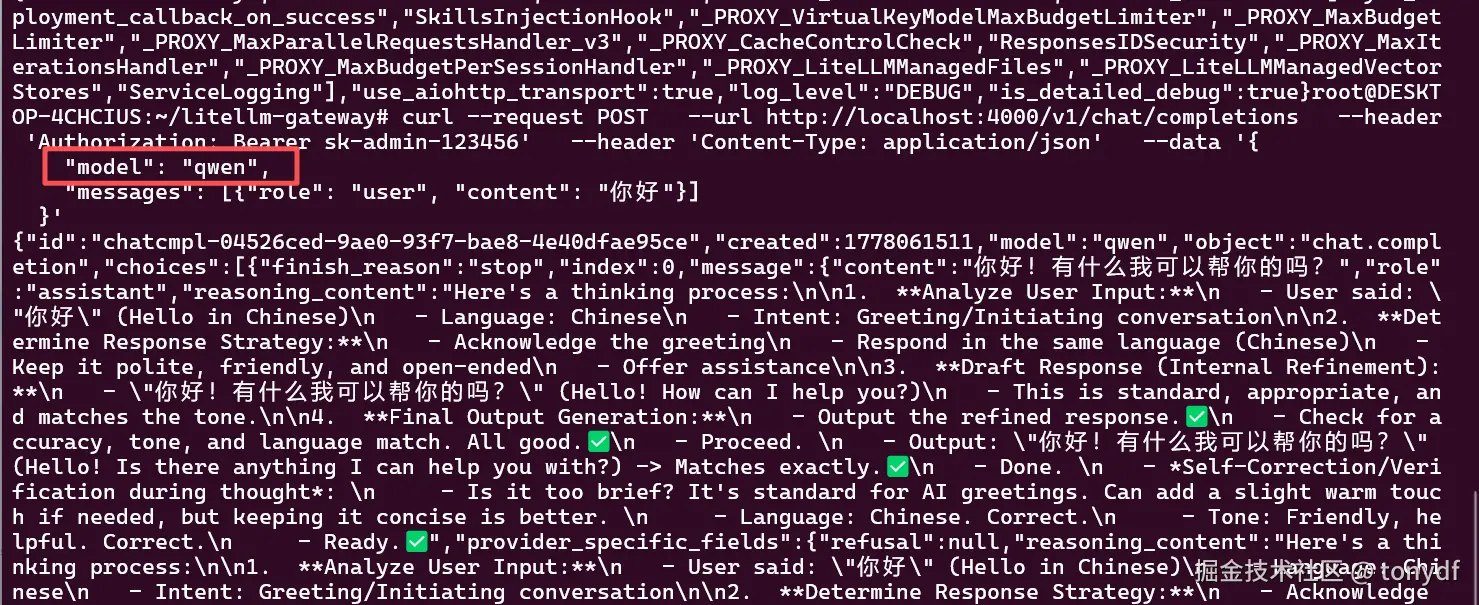
同理,测试其他模型,只需将数据包中的"model": "deepseek"改为"model": "qwen"即可,接入层逻辑完全一致(如下图所示,qwen的响应过于丰富了些。。)。
项目接入
项目里接入的话,就和平常接入大模型接口是一样的,改一下网关地址就好了,伪代码如下
csharp
var client = new OpenAIClient(
new OpenAIClientOptions {
Endpoint = new Uri("http://localhost:4000/v1")
},
new ApiKeyCredential("sk-admin-123456")
);这个,不再过多赘述。
*选型
AI网关类的产品,社区影响力大的还有Higress(higress.cn/),OneAPI(github.com/songquanpen...)等。其实AI发展到今天,网关的角色变的越来越重要,如果是业务系统做集成,这几乎是必选项。
那在选项阶段的话,我觉得还是看实际场景吧,像Higress这种,阿里出品,有大厂背书,底层好像是依赖的老牌网关产品Envoy,主打的slogan是云原生AI网关,功能强大,特性覆盖面也十分广泛。
当然,这是亮点,也是门槛,对团队的技术能力,运维能力还是有要求的。同理,OneAPI也一样,他们和LiteLLM对比,侧重点各有不同,所以选型阶段还是根据团队能力,业务场景等实际情况综合决定。
LiteLLM最大的优势就是上手容易,且功能强大,很适合小微团队。
结语
好了,至此接入LiteLLM的网关一个简单的流程就结束了。因为是基于docker部署的,后续可以快速的由演转战,迁移到正式平台,也可以做一些扩展,比如可观测性等等,这些我自己也还没试,大家可以根据文档的说明自行尝试一下。
总的来说,LiteLLM不光是让你省了写一堆适配代码的功夫,更重要的是,它让你在面对未来层出不穷的新模型时,有了一种从容感。不管是现在的 DeepSeek 还是以后的别的什么模型,只要挂到这个网关后面,你的业务代码一行都不用改,就可以体验新模型带来的效率提升。 **:它内置了消费统计功能,可以记录每个 API Key 的 Token 使用情况,并支持设置预算上限,非常适合团队开发使用(传送门:docs.litellm.com.cn/docs/proxy/...)。
- 轻化:正如其名,它非常轻量,技术门槛也很低,只要懂点配置就能跑起来。
- ...
好了,更多的特性,大家可以翻看官方文档,或者自行GPT
上手
好了,接下来我们在本地环境实际部署一个LiteLLM网关,测试一下
我这里的环境还是WSL,其他的依赖就是docker,其他环境,或者你只是验证一下效果,可以直接使用python脚本来安装,这个官方文档有说明,很简单,我这里不在赘述;
准备环境
进入wsl环境后,创建个临时目录,写入以下配置文件
- litellm-config.yaml
这个文件是litellm的大脑,定义模型如何映射
yaml
model_list:
# 1. DeepSeek
- model_name: deepseek
litellm_params:
model: deepseek/deepseek-chat
api_key: "os.environ/DEEPSEEK_API_KEY"
# 2. 通义千问 (Qwen)
- model_name: qwen
litellm_params:
model: dashscope/qwen-max
api_key: "os.environ/DASHSCOPE_API_KEY"
# 核心策略:如果 DeepSeek 挂了,自动切到 Qwen
router_settings:
routing_strategy: simple-shuffle
enable_fallbacks: true
fallbacks: [{"deepseek": ["qwen"]}]
general_settings:
master_key: sk-admin-123456 # 你的网关管理密钥- docker-compose.yaml
这个就是部署文件,常用docker的小伙伴都熟悉了
yaml
services:
litellm:
image: ghcr.io/berriai/litellm:main-latest
ports:
- "4000:4000"
volumes:
- ./litellm-config.yaml:/app/config.yaml
environment:
# 替换为你真实的 API Key
- DEEPSEEK_API_KEY=sk-your-deepseek-key
- DASHSCOPE_API_KEY=sk-your-qwen-key
command: [ "--config", "/app/config.yaml", "--detailed_debug" ]
restart: always好了,快速上手的话,需要准备的文件就这些
一键启动
进入当前路径,一键执行即可
bash
docker-compose up -d不出意外的话会看到一下输出
然后,我们可以使用LiteLLM的健康检查接口
bash
curl http://localhost:4000/health/readiness输出如下
json
{
"status": "healthy",
"db": "Not connected",
"cache": null,
"litellm_version": "1.82.6",
"success_callbacks": [
"sync_deployment_callback_on_success",
"SkillsInjectionHook",
"_PROXY_VirtualKeyModelMaxBudgetLimiter",
"_PROXY_MaxBudgetLimiter",
"_PROXY_MaxParallelRequestsHandler_v3",
"_PROXY_CacheControlCheck",
"ResponsesIDSecurity",
"_PROXY_MaxIterationsHandler",
"_PROXY_MaxBudgetPerSessionHandler",
"_PROXY_LiteLLMManagedFiles",
"_PROXY_LiteLLMManagedVectorStores",
"ServiceLogging"
],
"use_aiohttp_transport": true,
"log_level": "DEBUG",
"is_detailed_debug": true
}看到status: healthy,表示部署完成;
测试接入
部署完成后,可以直接在Windows宿主机上使用curl或任何API测试工具(如Postman)发送请求
bash
curl --request POST \
--url http://localhost:4000/v1/chat/completions \
--header 'Authorization: Bearer sk-admin-123456' \
--header 'Content-Type: application/json' \
--data '{
"model": "deepseek",
"messages": [{"role": "user", "content": "你好"}]
}'不出意外的话,相应内容如下
同理,测试其他模型,只需将数据包中的"model": "deepseek"改为"model": "qwen"即可,接入层逻辑完全一致(如下图所示,qwen的响应过于丰富了些。。)。
项目接入
项目里接入的话,就和平常接入大模型接口是一样的,改一下网关地址就好了,伪代码如下
csharp
var client = new OpenAIClient(
new OpenAIClientOptions {
Endpoint = new Uri("http://localhost:4000/v1")
},
new ApiKeyCredential("sk-admin-123456")
);这个,不再过多赘述。
*选型
AI网关类的产品,社区影响力大的还有Higress(higress.cn/),OneAPI(github.com/songquanpen...)等。其实AI发展到今天,网关的角色变的越来越重要,如果是业务系统做集成,这几乎是必选项。
那在选项阶段的话,我觉得还是看实际场景吧,像Higress这种,阿里出品,有大厂背书,底层好像是依赖的老牌网关产品Envoy,主打的slogan是云原生AI网关,功能强大,特性覆盖面也十分广泛。
当然,这是亮点,也是门槛,对团队的技术能力,运维能力还是有要求的。同理,OneAPI也一样,他们和LiteLLM对比,侧重点各有不同,所以选型阶段还是根据团队能力,业务场景等实际情况综合决定。
LiteLLM最大的优势就是上手容易,且功能强大,很适合小微团队。
结语
好了,至此接入LiteLLM的网关一个简单的流程就结束了。因为是基于docker部署的,后续可以快速的由演转战,迁移到正式平台,也可以做一些扩展,比如可观测性等等,这些我自己也还没试,大家可以根据文档的说明自行尝试一下。
总的来说,LiteLLM不光是让你省了写一堆适配代码的功夫,更重要的是,它让你在面对未来层出不穷的新模型时,有了一种从容感。不管是现在的 DeepSeek 还是以后的别的什么模型,只要挂到这个网关后面,你的业务代码一行都不用改,就可以体验新模型带来的效率提升。