现在的 AI 术语满天飞:一会儿是 Model、Agent,一会儿又是 RAG、MCP、Vibe Coding 还有最近大火的 Skills。
但看了这么多文章和视频,你有没有发现一个问题:绝大多数内容都在死磕 "名词解释",却没告诉你 "为什么会有它"。概念之间逻辑性很弱。
所以,这篇文章的目标很简单:不堆砌晦涩的术语,只讲前因后果和保证逻辑清晰。
同时,我们公众号还特别服务于面试前端开发或者前端ai全栈岗位的的同学,在我开发的前端面试真题网站上,发现近期已经出现了相关考点,例如:
- 美团(2026.02.28): "聊聊 MCP 和 Skills 的底层原理?"
- 字节跳动(2026.01.30): "MCP 的概念是什么?它和传统的 Function Call 有什么区别?"
然后,上一篇 《ai 全栈开发》系列文章 - AI 是如何进化到大模型的,从宏观层面,讲述了 AI 的发展史。为了让本篇文章有一个宏观的背景铺垫(所有微观的概念,都是宏观思想的延伸与落地。)
因此,在进入新的术语之前,我先带你回顾一下之前文章介绍的 ai 宏观的历史。
第一章:缘起--从"想要智能"开始
人工智能的本质:当"推理"变成"计算"
计算机诞生之初,其实是个极度"偏科"的天才。它天生擅长算数,无论多复杂的数字,它都能在极短的时间算出结果。
既然机器可以精准地模拟人类的"计算"能力,那么它是否也能模拟人类最引以为傲的"推理"能力?
所以人工智能的目标就是:智能如何被形式化,也就是智能如何表达为逻辑公式或者数学模型,如果可以的话,那么计算机就能实现智能!
初代尝试------被规则锁死的"教条"
既然想让计算机像人一样思考,最直观的办法就是:把人类的经验,翻译成机器能听懂的逻辑。
逻辑的起点:If(如果)...Then(那么)... 。
当时的科学家觉得,人类的智慧不就是一套复杂的规则吗?
- If(如果) 今天乌云密布 + 湿度大于百分之 70
- Then(那么) 结论:可能会下雨。
而这就是最早的 "规则引擎" 。只要规则给得够多,机器看起来就像有了 "脑子"
但人类世界的复杂是"无限"的,程序员写的代码永远是"有限"的。既然"穷举不了",那我们就得换个思路,可不可以让机器自己去"学"?这就是 机器学习 的概念。
机器学习------从"死记硬背"到"自找公式"
在计算机眼里,万物皆可"公式化"。拿"分辨这只动物是不是猫"为例,我们先给机器一个基础公式:f(x) = w * x + b
- x:一张图片(输入数据)
- w、b:可以反复微调的参数。w(权重)表示这个特征有多重要,b(偏置)是基础修正。
- f(x): 机器算出的"是猫程度有多少"
机器学习的过程,本质如下图
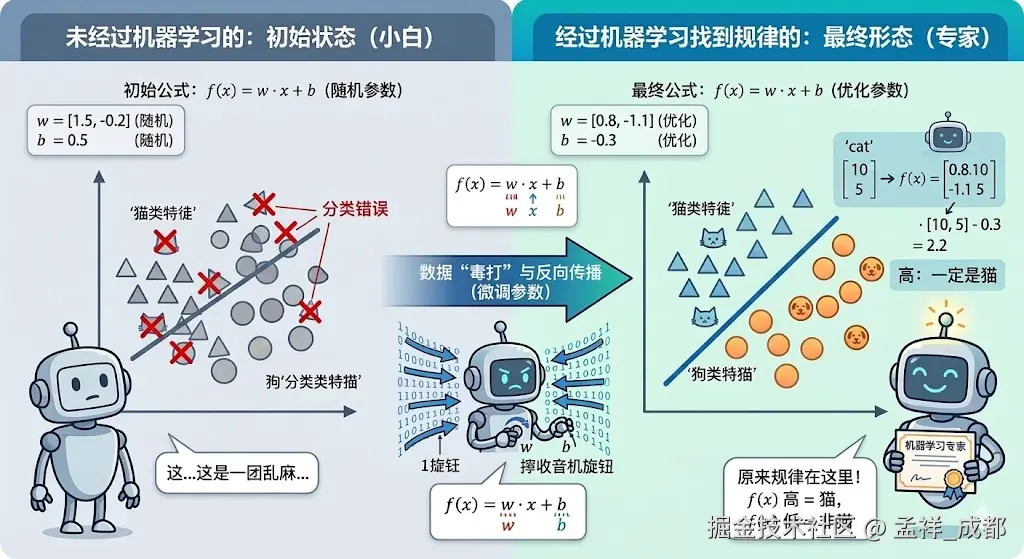 机器学习的进化过程:
机器学习的进化过程:
- 初始状态:机器是个小白,公式里的参数都是随机生成的。它画出的那条"分界线"乱七八糟,把很多狗看成了猫(出现了错误标记)。
- 数据"毒打":每当预测错误,机器就会通过反向传播算法,计算出 w 和 b 偏离了多少,然后像拧收音机旋钮一样精确微调。
- 最终形态:经过海量迭代,机器找到了最完美的参数,那条线精准地划开了"猫"与"非猫"的界限。这就是机器学习最朴素的含义------让机器从数据中总结规律,而不是靠人手写规则
进化 ------ 机器开始"模仿大脑"
虽然公式能画分界线,但现实很残酷:猫长得太复杂了! 只看"耳朵尖不尖"显然不够。猫有花纹、有尾巴、有瞳孔变化......如果把所有特征都写进一个公式,这个公式会变得冗长且低效。
于是,科学家模仿人类大脑,玩了一场"乐高积木"的游戏:他们发现,上面那个 f(x) = w * x + b 的公式,其实非常像大脑里的一个神经元。
我们不妨让一个神经元不要做判断"一张图是否是猫"这样复杂的逻辑。尝试让一个神经元负责一些小事,例如判断像素是什么,或者形状是什么。把他们联合起来后:
- 基层员工(第一层神经元): 只看局部,认出线条和色块。
- 中层干部(第二层神经元): 汇总线条,认出耳朵、眼睛的形状。
- 高层老板(输出层神经元): 结合所有特征,拍板判定:"这就是一只猫!"
而千上万个神经元排列组合,就构成了 神经网络,从而实现更复杂的功能。
既然堆叠能产生智慧,那如果把这个工厂盖得更高、层数更多呢?
这就是 深度学习(Deep Learning) 。"深"字代表的就是神经网络的层数。
阵痛------当"工厂"太深带来的难题
然而,要把这栋"摩天大楼"盖起来并运转顺畅,科学家们碰到了一个巨大的技术天花板。
我们知道,深度学习的过程就是"预测---纠偏---迭代"。当最终结果发现预测错了,它需要通过一套叫 "反向传播" 的算法,把错误信息往回传,告诉前面每一层的神经元:"嘿,你的参数 w 和 b 调得不对,得改改!"
但在早期的尝试中(比如传统的 RNN 循环神经网络),出现了一个致命的问题:消失的信号(梯度消失)。
想象你在玩一个 100 人的 "传声筒游戏":
队尾的教官喊了一句:"反馈错误:参数调大 0.5!"
信息往回传时,每经过一个人的耳朵,声音都会损耗一点。
传到第 50 个人时,声音变成了蚊子叫;传到第 10 个人时,由于损耗累积(数学上的连乘效应),信号彻底归零。
这种"前路漫漫,后路无声"的尴尬,让深度神经网络在很长一段时间里无法处理超长的数据(比如超长的句子)。
直到一个被称为 "Transformer" 的天才架构出现,彻底解决了这个问题......
从"接力赛"到"上帝视角"------Transformer 与大模型的诞生
它不仅解决了信号传不远的"心碎"问题,还顺手解决了一个让所有程序员头疼的效率难题:"死板的顺序"。
在 Transformer 之前,AI 读文章像小学生,必须从左往右一个字一个字读(这叫串行);而 Transformer 像是一眼十行的天才,它能同时处理整篇文章(这叫并行),并且通过大名鼎鼎的 "注意力机制(Attention)" ,一眼就能抓出词与词之间跨越千山万水的联系。
正是因为 Transformer 的出现,人类发现"摩天大楼"不仅可以盖得很高,而且盖得飞快。
于是,科学家们做了一个疯狂的决定:
不再只喂它几万张图片,而是把整个人类互联网的文本、代码、书籍全塞进去。
不再只让它判断"一张图片是否世茂",而是让它在这片星辰大海般的数据里,寻找人类语言的终极公式。
"大力出奇迹" - 大模型诞生了
由于这栋"楼"层数极深(训练数据大)、规模极大(参数量动辄千亿级)、并且计算量大,它有了一个震慑人心的新名字:大语言模型(Large Language Model,简称 LLM)。
这下面试官再问你什么是大语言模型的大到底是什么,咋们就能跟他好好聊聊了。好的,废了这么大力气终于把背景说清楚了,如果觉得不错,感谢你的关注转发和点赞哦!
第二章:内功------大模型如何从"数字"练就"思维"?
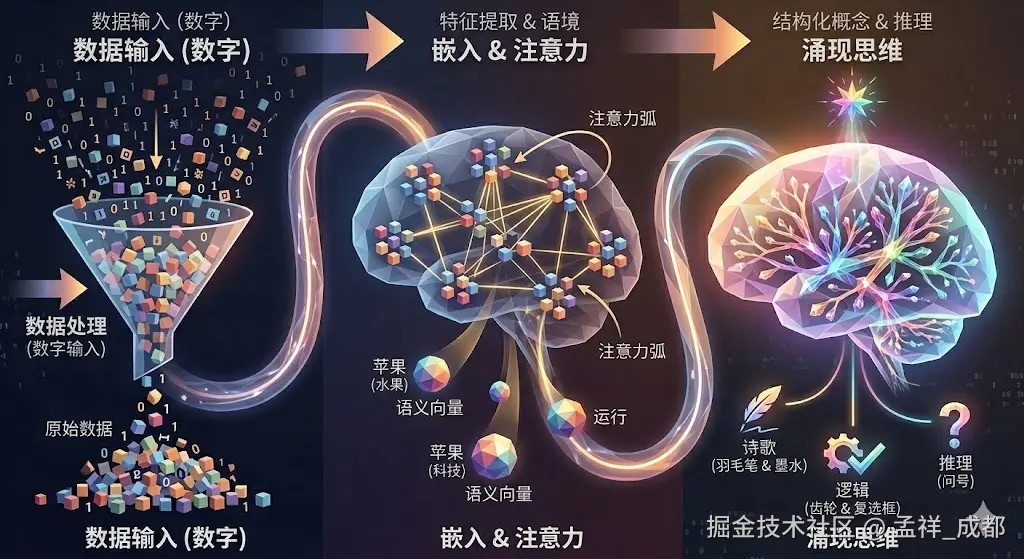
我们上面仍然没有解释一个问题,LLM 学习后的回答的结果,为什么看起来就像它会思考呢?其实,要解开这个谜题,我们得先剥开它"文科生"的外表,看看它"理科生"的内核。
背景问题:计算机怎么可能懂"诗词歌赋"?
计算机本质上只是一个超级计算器,它只认识数字。如果你直接给电脑发一个词"苹果",它并不理解这是水果还是手机,它只会看到一串毫无意义的二进制代码。
本质: 计算机无法理解文本,它只能处理数字。所以,第一步就是把人类语言"翻译"成机器能算的数字。
解决方案:给万物画"多维画像"(嵌入 Embedding) 要把文字变成数字,最关键的技术叫 嵌入(Embedding)。
你可以把"嵌入"理解为:给每一个词画一张极其精细的"多维画像"。
此时向量这个出现在很多科普文章中关键概念出现了,我会用更通俗易懂的方式来解释。举例:描述一个人,可以用四个维度:性别(0是女生,1是男生), 身高, 体重, 年龄
-
"男人" → 1, 175, 70, 30
-
"女人" → 0, 165, 50, 25
这里的 1, 175, 70, 30 在数学上就叫 向量(Vector)。而把"男人"这个词映射到这串数字的过程,就叫 嵌入(Embedding) 。
核心思想:在数学空间里产生"思维"
如果 4 个维度能描述一个人,那么大模型会用成千上万个维度(比如:褒贬、生命体、具体/抽象、科技术语等)来给每一个词画画像。
当所有的词都被打分并转化成"嵌入向量"后,神奇的事情发生了:这些词不再是孤立的符号,而是变成了多维空间里的一个点。
在这个数学空间里:
- 距离代表关系: 意思相近的词(如"开心"和"快乐"),它们的画像数字非常接近,在空间里的距离也极短。
- 逻辑可以计算: 因为每个词都是一组数字,它们竟然可以像加减法一样运算。
科学家们发现了一个震惊世界的现象:
"国王"的向量 - "男人"的向量 + "女人"的向量 ≈ "女王"的向量
换句话说: "嵌入"技术不仅把文字变成了数字,还把文字背后的逻辑关系也一并平移到了数学世界里。这是大模型能够"思考"的物理基础。
既然我们已经通过 Embedding(嵌入) 把文字变成了原材料,那么 AI 是如何把这些原材料组合起来,玩起"完形填空"并最终觉醒思维的呢?
我们接下来聊聊:无限练习------预测下一个词(预训练)
无限练习:预测下一个字(预训练)
有了画像(嵌入)还不够,因为画像是死的。真正让词与词之间产生复杂逻辑关系的(虽然坐标近的词可能意思相近,但它无法理解语境。比如"苹果"的坐标是固定的,它没法区分是"好吃的苹果"还是"好用的苹果手机"),所以还需要 "预训练" 。
训练方法:把全人类的知识,变成一场无限的"完形填空"。
想象一下大模型的特训过程:
- 输入: "今天天气真__" → 目标输出: "好"
- 输入: "人工智能是__" → 目标输出: "未" → 接着猜: "来"
- 输入: "我喜欢吃苹果和__" → 目标输出: "香蕉"
本质是: 大模型并不真的"理解"苹果是什么味道,它在预训练中只做一件事:计算概率。它在数万亿次练习中,记住了词与词之间跨越时空的权重关系(即 注意力机制)。
换句话说: 它通过"猜词"掌握了人类语言的底层密码。当它猜得足够多、模型足够大,它表现出来的逻辑能力就越像是在"思考"。
第三章:沟通的协议 ------ Prompt 与 Token
既然这个"概率天才"已经练成了,我们该如何指挥它干活呢?这就涉及到了我们每天都在用、面试也必考的两个词:Prompt 与 Token。
Promp ------ 下达"任务说明书"
当你打开 AI 聊天框,输入:
"帮我规划一下去东莞的旅游攻略"
这句话就是 提示词(Prompt)。
本质是: Prompt 是你给这个概率机器提供的 "初始线索"。既然大模型是靠"预测下一个字"工作的,你的 Prompt 就是在帮它限定范围,引导它往正确的概率轨道上走。
Token ------ AI 世界的"最小货币单位"
有趣的是,AI 收到你的 Prompt 后,并不是直接阅读整句话。在进入大脑处理之前,它会先通过 分词器(Tokenizer) 把你的话切成碎片。
这些碎片就叫 Token。
这里就涉及到一个重要的问题为什么不直接按"字数"算?
因为在 AI 眼里,没有"字"这种概念。
它不能直接读:
帮我规划一下去东莞的旅游攻略
它真正看到的流程是:
人类语言 → Tokenizer 切分 → Token → 转成数字编号 → 模型计算
比如这句话,可能会被拆成:
帮\] \[我\] \[规划\] \[一下\] \[去\] \[东莞\] \[的\] \[旅游\] \[攻略
每一个 Token 都会变成一个数字编号,比如:
1023 8742 5561 ...
模型真正计算的,其实是这些数字。例如上面的 1023 就是这个 token 编号,对应的就是我们之前说的向量,这才是用 token 的核心,因为最终大模型搜索的基础资料是向量,token 只是指向向量的一个标识符。
第四章:从"概率机器"到"智能体" ------ AI Agent 的觉醒
到这里,大模型已经能很好地回答一个提问了。但请注意,仅仅是 "一个" 提问。
从模型的视角来看,每一次调用都是完全独立的。大模型的本质,就是一个训练完毕、参数确定的静态数据集。你可以把它想象成一张存储了全人类知识的、巨大的、确定的 Excel 表------你只能在已有的单元格里搜索,它无法产生新的记忆,更不会自动更新。
这里跟专业人士补充一下,大模型本质是擅长处理非结构化数据,就是自然语言,而平时我们开发的程序,往往数据库存储和程序处理的都是结构化的数据,例如 JSON 格式,并且定义了每个字段的含义
那为什么我们平时使用 ChatGPT、Claude 或豆包时,它们好像能记住之前的对话,甚至能帮你查最新的新闻呢?
核心认知: 大模型(LLM)本身没有记忆,也没有手脚。我们平时使用的产品,本质上是 AI Agent(智能体应用)。
AI Agent = 大模型(大脑) + 各种外挂功能(记忆、手脚、感官) 。
为了让这个"静态数据表"变得像一个有生命、有能力的助手,开发者必须解决单纯大模型存在的几个致命问题:
- 记忆的缺失(No Memory)
正如前面所说,大模型是"秒忘"的天才。如果不依靠 Agent 系统在后台不断地把你之前的对话历史(Context)重新打包发给模型,它根本无法维持长期的逻辑连贯性。
- 信息的时效性(Knowledge Cutoff)
大模型的知识停留在它训练结束的那一天。它就像一个被关在图书馆里的天才,如果不给它"外接"互联网,它永远不知道昨天的天气或者今天最新的面试真题。
- 逻辑的"幻觉" (Hallucination)
由于大模型本质上是根据概率预测下一个字,当它面对超出自己知识范围的问题时,为了完成"补全"任务,它会一本正经地胡说八道。在数据表里找不到答案时,它会自己"编"一个单元格。
- 无法与现实世界交互 (No Action)
大模型只能处理非结构化的文本。它能写出一份精美的订餐代码,但它自己没法按下那个"下单"按钮,因为它无法直接驱动那些只认结构化指令(API)的计算机系统。
所以你会发现,后面我们要讲的那些概念------Context Window、RAG、Function Calling、MCP 其实并不神秘。它们不是某种"新魔法",而是用来解决我们前面一步步拆解出来的问题。
- 模型没有记忆能力 - Context Window 解决
- 模型不知道最新知识或者特定你想给他了解的知识 → RAG 解决
- 模型只能说不会做 → Function Calling 解决
- 工具越来越多需要统一协议 → MCP 解决
(Skill 的差异我们会在后面单独展开。)
当你带着"问题意识"去看这些名词时,
你会发现 ------ 它们不再是术语,
而是答案。 如果这一套拆解思路,让你对大模型的理解更清晰了一点,也欢迎给个点赞、转发或者收藏。
第五章:记忆的错觉 ------ Context(上下文)
很多人在和 AI 聊天时会觉得:"哇,它记得我上一句话说了什么,它是有记忆的!"
但真相可能会让你大吃一惊:大模型(LLM)本身其实是个"秒忘"的生物,它并没有人类那种持久的、存储式的记忆。
真相: 每次你发新消息,程序都会把你之前的对话记录全抓出来,拼成一串超长的文本,重新喂给模型。这就是 Memory(记忆)。
所以面试官问你:"什么是 Agent 的 Memory 机制?" 你心里想的是:"就是把对话记录塞进 Prompt 里。" 但你嘴上要说:"Memory 是指通过维持 Context 的连贯性,赋予 LLM 跨轮次的上下文感知能力。"(你看,身价瞬间涨了。)
但实际上大模型并不能无限制塞文字给他,是有限度的。我们之前说的 Transformer 有个很厉害的功能,就是自注意力机制,虽然厉害,但也有瓶颈:
因为 Transformer 的计算复杂度是 O(N²)。简单来说,就是每一个 Token 都要和剩下的所有 Token 计算相关性,总计算量就是 N × N。而 N,就是 Context 里的 Token 数量。
Context 就是一个模型能一次性容纳的 token 数量,我们称之为 Context Window(上下文窗口)。 所以当我们看到很多模型注明 8k,32k,128k 的时候,其实表示的就是上下文窗口,这也是为什么Context 越大越贵,因为训练量会暴涨。
但随着聊得越来越深,Context Window 很快就满了。Token 越来越贵,反应也越来越慢。这时,一个想法出现在脑海:
操作: 把那堆又臭又长的对话历史,先丢给大模型说:"嘿,帮我把这段话总结成 50 个字!"
结果: 这 50 个字的"摘要"替换掉了原来的 500 个字。
核心思想: 这就是 Memory Summarization(记忆总结)。用大模型来"精简"大模型的记忆,从而节省昂贵的 Context 空间。这也是很多 AI Agent 拥有"记忆能力"的秘密。
当你发现"伪造记忆"能让 AI 聊天更顺畅时,你开始产生一个大胆的想法:既然我能把对话历史拼进去,那我能不能把外部的资料也拼进去?
第五章:给模型"外接大脑" ------ RAG
大模型虽然博学,但它本质上是一个 "闭卷考试" 的选手。所有的知识都压缩在它的参数里。如果知识更新了,或者涉及你公司的内部文档,它就抓瞎了。
一旦问题超出"记忆范围",它就只能猜。
所以本质问题不是模型不够聪明,而是它没有最新的资料,那么如果我们提前把这些最新资料存储到外部数据库呢?这样每次大模型处理问题时,先去这个数据库查询是否有相关资料,然后在拼接到用户的 prompt 后,不就解决了吗?
RAG 的逻辑其实极其简单:把"闭卷考试"变成"开卷考试"。
第一步:整理资料(索引) 你把成千上万的文档切成小块,用我们前面讲过的 Embedding 技术,把这些文字块变成一组组数字坐标(向量),存进一个专门的仓库------向量数据库。
第二步:找参考书(检索) 当你问:"美团 2026 年的面试题有哪些?" 系统先不去问大模型,而是把你的问题也变成数字坐标,去仓库里比对。由于意思相近的词距离近,系统能瞬间抓取到那几篇相关的面试文章。
第三步:打小抄(增强) 系统把抓取到的文章内容,和你的问题拼在一起,变成一个新的 Prompt:
"已知参考资料:美团 2026.02.28 题目...。请根据这些资料回答:美团面试题是什么?"
第四步:念答案(生成) 大模型看着手里的"小抄",底气十足地回答出了准确答案。
AI Agent 本身就是一个运行在物理设备上的程序(你可以假设是 Python语言编写的)。既然 AI Agent 是用 Python 等语言写的,它就拥有了编程语言的上下文。这些编程语言天生就擅长:连接网络、读写数据库、执行计算。所以 RAG 简单说来就是 Python 查了一个向量数据库的内容,然后返回相关信息给大模型而已
一句话总结 RAG: 不是让模型去"背"所有知识,而是在它回答之前,先帮它去图书馆翻翻书。
第六章:从"只会说"到"开始做" ------ Function Calling
如果说 RAG 让 AI 成了"百晓生",那么 Function Calling(函数调用) 则让 AI 拿起了"工具箱"。
痛点:AI 是个"只会动嘴"的面试官
你问 AI:"今天北京天气怎么样?" 如果没有 RAG,它会说:"对不起,我不知道实时天气。" 即便有了 RAG,如果你没给它准备天气的文档,它还是不知道。 更重要的是,如果你想让 AI "帮我把这段代码部署到服务器"或者"给老板发封邮件",RAG 也无能为力,因为 RAG 只能读取,不能执行。
逻辑递进:给 AI 一个"操作手册"
为了让 AI 能干活,我们给它设计了一套协议:Function Calling。
- 定义工具: 程序员给 AI 一份清单,告诉它:"我这里有个工具叫 get_weather,你需要传入 city 参数,它就能返回天气。"
- 识别意图: 当用户说"帮我查查北京的天气"时,大模型发现自己回答不了,但它对比了工具清单,发现 get_weather 很合适。
- 输出指令: 注意!AI 此时并不亲自运行代码。它只是吐出一串结构化的指令(通常是 JSON):{ "tool": "get_weather", "args": { "city": "Beijing" } }
- 程序执行: 你的前端或后端代码接收到这个 JSON,替 AI 去调用真正的天气 API,拿到结果后再喂回给 AI。
- 总结呈现: AI 拿到结果,转换成自然语言告诉你:"北京今天晴,25°C。" 所以,Function Calling 的本质是: 大模型不再直接输出"答案",而是输出 "调用工具的结果"。
Function Calling 的本质
再次强调:AI Agent 本身就是一个运行在物理设备上的程序(你可以假设是 Python语言编写的)。既然 AI Agent 是用 Python 等语言写的,它就拥有了编程语言的上下文。这些编程语言天生就擅长:连接网络、读写数据库、执行计算。
所以编程语言执行一个函数调用是再简单不过的事情了,Function Calling(函数调用)就是这么简单一个东西而已。白话的流程上面已经介绍了,如下属于更专业一点的 Function Calling 调用流程。
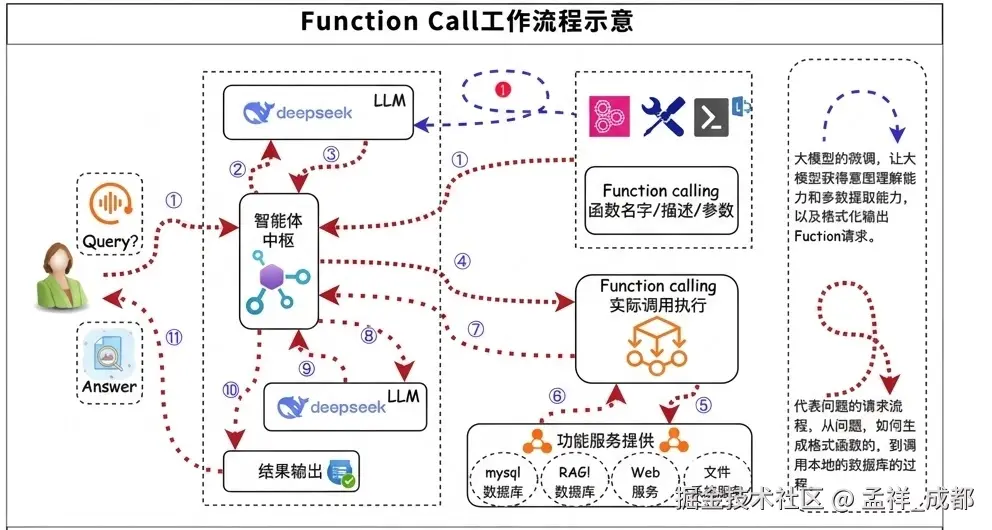
- 第一阶段:能力构建(前提条件)
-
大模型的微调:这是流程启动前必须完成的工作。通过微调,大模型获得了以下核心能力:
-
意图理解能力:能准确判断用户的问题是否需要调用外部工具。
-
参数提取能力:能从非结构化的对话中提取出函数执行所需的特定参数。
-
格式化输出能力:能生成符合规范的 Function 请求,从而实现从文本到系统指令的转换。
- 工具注册与下放 (Tool Registration):
-
开发者在 智能体中枢 (AI Agent) 中定义工具的 JSON Schema(包含函数名、功能描述、入参类型)。
-
在发起请求时,这些工具定义会随用户问题一起 下放(注入) 给大模型(作为 System Prompt 或专用 Tools 字段)。
-
没有这一步,大模型即使有识别能力,也不知道当前环境下有哪些具体工具可用。
- 第二阶段:实际运行调用流程 在具备了上述微调后的能力后,系统才能理解用户请求中对对应 Function Calling 的请求。
-
用户提问 (Query):用户发起初始请求。
-
注入与识别: Agent 将用户问题 + 注册的工具定义一并传给 LLM。
-
意图识别:LLM 发现当前问题在已注册的工具范围内,输出 call: { function_name: "...", arguments: "..." }。
-
路由解析:Agent 中枢解析 LLM 的输出,在本地映射表中找到对应的真实函数。
-
实际调用执行:嵌入大模型的 AI Agent 根据指令,在自己的编程上下文,例如 Python 环境中调用函数,无论该函数是在本地内存中运行、执行复杂的数学计算,还是通过 HTTP 请求访问远程微服务,对模型而言都是透明且无感知的。
-
注意,虽然执行过程对模型透明,但 输入(请求)与输出(响应) 必须严格符合预定义的协议格式。例如必须有唯一的函数名,清晰的描述(用来给大模型识别),参数等等。
结果整合与输出:将获取的数据再次提交给 LLM,由其整合生成最终答案并返回给用户。
本质就是大语言模型擅长处理自然语言,而我们人类传统编程应用程序擅长处理结构化的数据(例如 JSON 格式),所以我们就需要一个桥梁或者机制打通自然语言和传统应用,这就是 Function Calling 的最大作用。
第七章:工具世界的"USB接口" ------ MCP
在传统计算机世界里,我们已经见过类似的问题。比如早期的电脑:
- 打印机一个接口
- 鼠标一个接口
- 键盘一个接口
后来人类发明了一个伟大的东西:USB。只要是 USB 设备,电脑都能识别。AI 世界也遇到了同样的问题。
于是 Model Context Protocol(MCP) 诞生了。MCP 的核心思想其实非常简单:
让所有工具都用统一的协议,暴露给 AI。
这样一来:
- 数据库可以变成 MCP 工具
- GitHub 可以变成 MCP 工具
- 浏览器可以变成 MCP 工具
- 本地文件系统也可以变成 MCP 工具
对 AI 来说,它面对的就不再是各种乱七八糟的 API。
所以本质上 MCP 就是借助 Function Calling 的机制,对外提供一个服务,让既有的系统快速集成到 LLM 中,通常一个 MCP Server 有很多工具,而不是一种。
那 MCP 跟 Function Calling 是什么关系呢?这是网上大多数文章都有问题的地方,它们是协作关系!我们简单叙述一下流程:
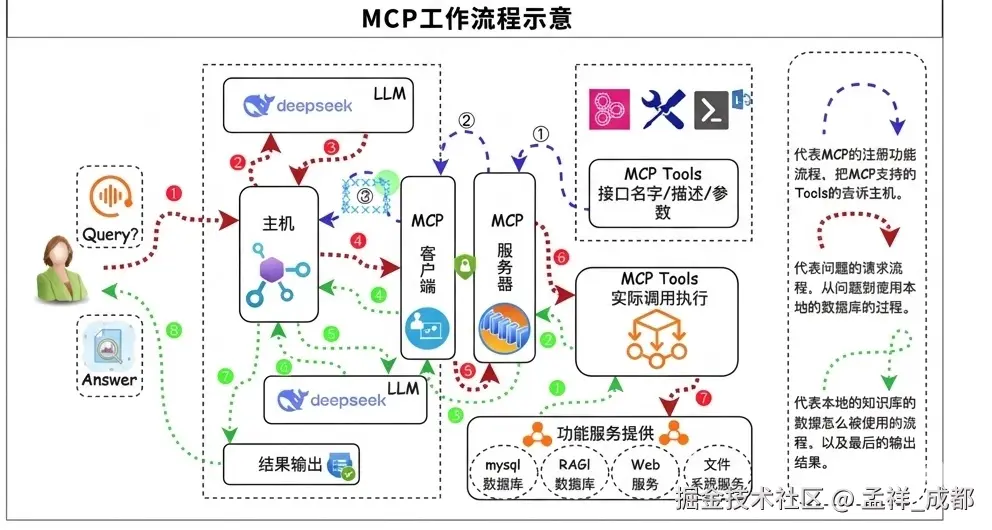
- 第一阶段:能力构建与协议初始化(前提条件)
-
大模型的微调 (Foundation):通过微调使 LLM 获得核心能力,也就是能理解 MCP 标准的格式化请求。这个本质上跟训练如何识别 Function Calling 是一样的,所以有人说 MCP 就是基于 Function Calling 的。
-
MCP 动态注册 (MCP Registration):AI Agent 启动的时候,同时会启动在 Agent 里的 MCP client 客户端,MCP Client 客户端回拿到的数据返回给 AI Agent,然后 AI Agent 根据之前大模型训练好的如何接收 MCP 标准的格式化请求的要求,将这些动态获取的工具定义会随用户问题一起注入大模型
- 第二阶段:实际运行与协议化调用
- 用户提问 (Query):后续用户发起请求给 AI Agent
- 注入与识别:Agent 将"用户问题"与"从 MCP Server 拿到的工具定义"一并下发给 LLM
- 意图识别与决策:LLM 匹配工具集,识别出调用需求,输出符合 MCP 协议的指令,例如:call: { function_name: "...", arguments: "..." }
- 路由解析与分发:Agent 中枢解析指令,通过 MCP 客户端 将执行请求精确路由至对应的 MCP 服务器。
- 协议化执行:MCP Server 在其编程上下文(如本地数据库、Python 环境或 HTTP 远程服务)中执行函数。
MCP Client 将返回的结果再次返回给 AI Agent, Agent 将获取的数据再次请求大模型, 最终返回给用户结果。
第八章:任务变复杂 ------ Workflow 的出现
当工具越来越多时,你会发现:很多任务 不是调用一个工具就能完成的。
比如一个真实任务:帮我分析今天 GitHub 仓库的 issue,并生成日报发到 Slack。"这个任务其实包含多个步骤:
- 查询 GitHub issue
- 汇总数据
- 生成总结
- 发送 Slack
也就是说:AI 需要执行一整条流程。这就产生了一个新的概念:Workflow(工作流),而 Workflow 落地的可视化项目你必定听过 coze,没错就是扣子,当然 n8n,dify等等加入了大模型节点的 Workflow 也是一样的。
可以看下图,可视化的 Coze Workflow 是什么样的。
第九章:能力沉淀 ------ Skills 的诞生
什么是 Skills?
当 Workflow(工作流程)被频繁使用后,你会发现一个规律:很多流程会被反复用到。 比如:
- 写周报
- 分析问题反馈
- 整理会议记录
- 总结文档内容
- 自动生成演示文稿
如果每次都从头写一遍完整流程,效率会特别低。 于是工程师做了一件很自然的事:把常用的 Workflow 打包、封装起来。 这就诞生了:Skills(技能) Skill 的本质非常简单: Skill = 可复用的 Workflow
Skills 的核心:基于 Function Calling 的巧妙封装
Skills 并不是凭空创造的新能力,它实际上是 Function Calling(函数调用) 机制的高级应用。其运行逻辑如下:
- 初始化/发现: 模型启动时加载所有 Skill 的元数据(名称和描述)。
- 触发决策: 模型根据用户请求,判断是否需要调用某个 Skill。
- 动态加载: 通过 Function Calling 调用 load_skill(skill_name),将详细的 SKILL.md 指令注入当前上下文。
- 按需执行: 依照指令执行任务,过程中可继续通过 Function Calling 调用脚本或读取资源。。。
所以 Function Calling 可以算是 AI Agent 的基础能力了,任何跟外界返回结构化数据的程序打交道,都要需要这个能力。所以 Skill 跟 Function Calling 属于协作关系。
那么 Sklls 和 MCP 属于什么关系呢?我认为既有竞争关系也有合作关系,你想想看,当市面上能把一些 MCP 功能封装为 Skills 的时候,是不是 Skills 加载要简单的多,但是问题也来了,当某个 Skill 特别复杂,我们计算机本地很难提供这个 Skill 所依赖的环境和数据的时候,这时候 MCP 仍然是有价值的。
最后我们简单创建的一个 Skill 帮助我们彻底知道 Skill 到底是什么。 感谢你的耐心解读,也感谢你的点赞收藏和转发,我们下期不见不散!
帮助理解:简单创建一个 Skill
一个标准的 Skill 目录结构如下:
bash
commit-message-helper/
├── SKILL.md # 核心指令(必需)
├── scripts/ # 可执行脚本 (Optional)
└── references/ # 参考资料 (Optional)编写 SKILL.md 这是 Skill 的灵魂,必须包含 YAML frontmatter:
yaml
---
name: commit-message-helper
description: 当用户要求提交代码或编写 Git Commit 时使用。遵循 Conventional Commits 规范。
---
# Commit Message Helper
编写 Commit 时请遵循以下格式:
<type>(<scope>): <subject>
## 类型规范
- feat: 新功能
- fix: 修复 Bug
- docs: 文档变更
...关键点: description 描述得越具体(包含触发场景),模型调用的准确率就越高。
如果你使用的是 curosr 可以将上面的内容放在 .cursorrules 文件(trae 的话,放在到 .traerules 文件),然后在跟大模型 chat 的时候,就会触发对应的 skill