作者:vivo 互联网项目团队- Ding Junjie
摘要:作者通过使用Vibe Coding和Claude Code等AI编程工具的实践经验,分享了与AI协作的方法和技巧。文章探讨了当前AI工具与理想中"贾维斯"智能助手的差距,包括缺少持续记忆、意图理解需反复对齐、决策点过于依赖人工等问题。作者提出了通过模板化常见场景、记录决策过程、优化沟通方式等方法来改进人机协作模式,并构想了一个包含记忆层、执行层、学习层的AI组织者系统,为实现更智能的人机协作提供了思路和方向。
1分钟看图掌握核心观点👇
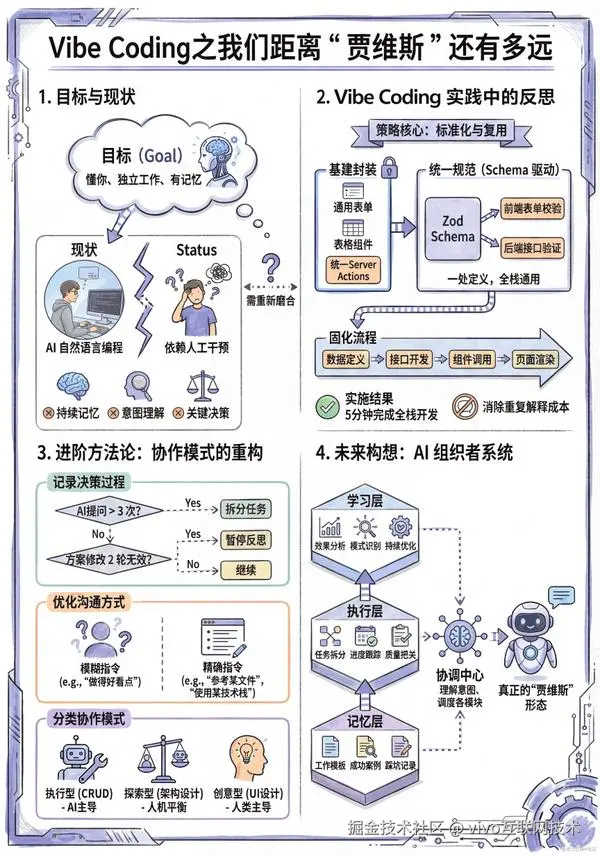

图1 VS 图2,您更倾向于哪张图来辅助理解全文呢?欢迎在评论区留言。
一、前言
Vibe Coding 一年多了,最近试了 Claude Code。现在这个场景变得特别常见:我可以边做饭边写代码,顺便还能撸个猫。
听起来很玄?其实就是这样:我只要把想法说清楚------比如"做个用户登录页面",AI就会自己去翻项目文件、理解代码结构、查看接口文档,然后一步步把功能实现出来。我完全不用一直盯着屏幕,去倒杯水、拿个快递,回来就能看到能跑的代码。
这种体验让我想起了《钢铁侠》里的贾维斯------一个真正懂你、能独立工作的智能助手。虽然现在的 AI Agent 主要还是在编程领域,但我相信这种"协作模式"会扩展到更多场景。

图片来源于漫威电影片段截图
也许每个人都会有自己的"贾维斯"。想象一下:设计师只需要说"我想要一个温暖的品牌形象",贾维斯就能从市场调研到视觉设计全套搞定;医生描述症状,贾维斯瞬间整合全球病例数据给出诊断建议;老师说想让学生更好理解量子物理,贾维斯就设计出沉浸式的教学方案...
这篇文章想分享一下我的体验和思考。即使你不写代码,这些协作的思路也许对你有用。
二、我是怎么和 AI 协作的?
**开场先讲清三件事:**目标是什么、背景信息在哪、有什么限制条件。信息越清楚,执行效果越好。这样 AI 就知道边界在哪,不会跑偏。
**任务大小动态调整:**我不会一开始就把任务切得很细,而是先给一个相对大的目标。如果 AI 卡住了或者理解偏了,我就分析原因,把任务拆得更具体。这个过程很像项目管理------需要判断是需求不清楚、信息不够,还是执行思路有问题。
**执行中的关键决策点:**AI 工作过程中会遇到很多选择:用什么方案、怎么处理异常情况、如何平衡各种因素。这些地方它会主动问我,或者我看到结果不对会及时纠正。这种反复对齐想法的过程,其实是整个协作的核心。
**基于反馈的迭代:**每个阶段性成果都是一次反馈。不是按时间切分,而是按"能否验证"来切分。做出来了、能用了、效果出来了,这些都是天然的检查点。
用了这套方法后,效率确实提高了很多。但用得越多,我越发现离真正的贾维斯还有明显差距。
三、距离贾维斯,我们还差什么?
仔细想想贾维斯和现在AI的区别:贾维斯不需要托尼每次都详细解释背景,它"记得"之前所有的项目、偏好和决策模式。而我现在每次还得从头描述上下文,重新磨合工作习惯。
差距1:缺少持续记忆
每次协作都要重新"磨合"。即使是做过很多次的任务,我还是得重新解释背景、重新设定边界。AI没有"工作记忆"。
差距2:意图理解还需反复对齐
传统的聊天模式很低效------你说一大段,AI理解偏了,再纠正,来回好几轮。虽然也能解决问题,但这个过程还是很"手工"。
差距3:决策点太依赖人工
真正有挑战的不是让AI干具体的活,而是那些需要人来决策的地方:
- 什么时候该把大任务拆小?拆到什么程度?
- 不同阶段需要什么背景资料?
- AI的输出质量如何?是继续还是调整方向?
- 业务在变化,如何让系统的"记忆"保持新鲜?
能不能把这些痛点系统化解决?
四、一口吃不成胖子,但是一定有向前探索的路径
先找到重复的操作,把这些重复的协作模式"重构"一下
实战案例:我给 AI 搭了条"流水线"
我在一个 Next.js 全栈项目里,我做了一套标准化的工作流
**效果:**现在 AI 可以在 5 分钟内从数据库到后端到前端完成一个完整的 业务功能。
**小科普:**Next.js 是一个全栈框架,可以在一个项目里同时写前端和后端。它的 Server Actions 功能让你可以直接在前端调用后端函数,就像调用普通函数一样,不需要写传统的 API 接口(也可以写接口)。
核心是三件事:
1. 基础能力已经封装好,直接用
- 支持配置的表单组件(输入框、下拉框、富文本编辑器、等等)
- 支持配置的表格组件(支持排序、筛选、分页)
- 统一的 Server Actions 客户端(封装了authActionClient,负责权限校验,actionClient无校验,都记录日志)
2. 定义统一规范
- 数据结构定义一次,前后端共用(借助zod的schema)
- 前端校验表单、后端验证接口,用的是同一套规则
- 类型安全贯穿全栈,改一处同步生效
3. 固化工作流程
- 数据定义 → 后端接口 → 前端组件 → 页面
- 每一步都有明确的规范,AI 照着走就行
举个例子,我说:"做一个景点管理功能,包括增删改查。"
AI 就按照固定的流程开始工作了:
1. Schema 定义 (数据的"身份证",只写一次,前后端都用)
css
// 表单用的 schema - 定义用户要填什么
const attractionFormSchema = z.object({
name: z.string().min(1, '名称不能为空'),
cityId: z.string().min(1, '请选择城市'),
minDays: z.coerce.number().int().positive(),
imagePaths: z.array(z.string()).optional()
});
// 列表用的 schema - 定义展示什么数据
const serializableAttractionSchema = attractionFormSchema.extend({
id: z.string(),
createdAt: z.date(),
city: z.object({ id: z.string(), name: z.string() }),
images: z.array(z.object({ path: z.string() }))
});2. Server Actions (后端函数,注意这里用了同一个 attractionFormSchema)
kotlin
// 创建景点的后端函数
exportconst createAttraction = authActionClient // 需要登录才能调用
.inputSchema(attractionFormSchema) // ← 和前端用的是同一个 schema!
.action(async ({ parsedInput }) => {
// parsedInput 已经过校验,类型安全
const attraction = await prisma.attraction.create({
data: parsedInput
});
return { success: true, data: attraction };
});3. 前端表单 (同样也用 attractionFormSchema)
php
const form = useForm({
resolver: zodResolver(attractionFormSchema), // ← 还是这个 schema!前端自动校验
defaultValues: { name: '', cityId: '', minDays: 1 }
});
const onSubmit = async (values) => {
// 直接调用后端函数 createAttraction,就像调用本地函数一样
await createAttraction(values);
};4. 数据表格 (列配置 + 数据,配置化表格直接渲染)
bash
const columns = [
{ id: 'name', header: '景点名称', enableSorting: true },
{ id: 'city', header: '所在城市', enableSorting: true },
{ id: 'minDays', header: '建议游玩天数', enableSorting: true }
];为什么这么快?
因为我不需要每次都解释"怎么做表单校验"、"怎么调用接口"、"怎么展示列表"。这些基础能力都已经封装好了,AI 只需要:
- 定义一次 schema(数据结构即规则)
- 前后端都用这个 schema(前端校验表单,后端校验接口,改一次同步生效)
- 配置表单和表格(组件直接用,Schema 驱动)
上面的代码,attractionFormSchema 这个变量:
- 在前端的 zodResolver(attractionFormSchema) 里用了
- 在后端的 .inputSchema(attractionFormSchema) 里也用了
- 同一个定义,确保前后端的校验逻辑完全一致
这就像搭乐高:
- 积木块(基础组件)都是现成的
- 说明书(工作流程)是标准的
- 图纸(Schema)定义了要搭什么
**更关键的是可复用:**这套标准适用于任何 CRUD 场景。做"用户管理"、"订单管理"、"商品管理",流程完全一样,只是改改 schema 字段。
**我只需要告诉 AI "要管理什么数据",剩下的都是标准化执行。**这就是"模板化"的价值------把重复的协作模式提炼成标准流程,让 AI 可以直接套用。
上面的 CRUD 只是一个例子。要想真正建立起这套协作模式,需要在几个方面持续积累:
4.1 记录决策过程
那些关键的决策点------什么时候需要拆分任务、什么时候该换思路、哪些反馈信号最有效。这些"套路"可能比具体的执行技巧更有价值。
我总结的几个决策规则:
- 任务拆分信号:当 AI 连续问了 3 个以上的澄清问题,说明任务太大了,该拆分了。
- **方向调整信号:**如果一个方案改了 2 轮还不对,不是继续修,而是停下来重新思考方向(checkPointer)。
- **文档同步规则:**每次修改数据库 schema,AI 会自动提醒"是否需要更新 API 文档?"这是我之前踩坑总结出来的。
**这些决策规则就像"编程规范",**一旦记录下来,AI 每次遇到类似情况都能按规则处理,不需要我反复提醒。
4.2 优化沟通方式
观察哪些任务描述效果好,哪些容易让 AI 理解偏。
效果好的描述方式:
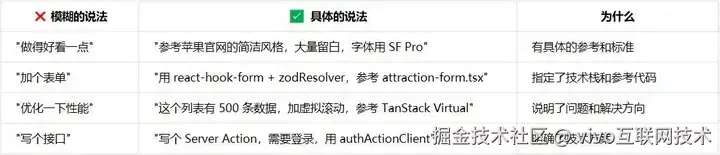
我的沟通技巧:
- 指向具体文件:"参考 attraction-action.ts 的写法",比"写一个增删改查接口"清楚得多。
- 提供边界条件:"表单字段不超过 10 个"、"列表支持排序和搜索,不需要高级筛选"。
- 说明优先级:"先做基础功能,图片上传放后面"。
沟通的本质是降低理解成本,越具体的描述,AI 的执行越准确。
4.3 分类协作模式
不同类型的工作,人机协作的方式是不同的。我把协作模式分成了几类:
执行型任务(AI 主导)
- 特征:有明确的标准和规范
- 例子:CRUD 开发、代码重构、bug 修复
- 协作方式:我提供规范 + 验收标准,AI 执行 + 我检查结果
探索型任务(人机平衡)
- 特征:需要尝试多个方案
- 例子:性能优化、算法选型、架构设计
- 协作方式:AI 给出 3-5 个方案 + 优缺点分析,我决策后 AI 执行
创意型任务(人类主导)
- 特征:需要创新和审美判断
- 例子:UI 设计、产品定位、文案撰写
- 协作方式:我提供灵感和方向,AI 提供素材和具体实现
学习型任务(双向互动)
- 特征:我不熟悉的技术领域
- 例子:学习新框架、理解复杂代码
- 协作方式:AI 解释概念 + 提供示例,我提问 + AI 补充
**关键发现:**执行型任务标准化程度越高,AI 效率越高。这也是为什么 CRUD 这种重复性工作最适合用 AI。
**一次提炼,多次复用,**这才是标准化协作模式的真正价值。
这让我想到一个有趣的可能性:如果有一个系统能够:
- 统一管理工作的背景资料和相关文档
- 记录每次的任务拆分和决策过程
- 分析哪些协作模式效果最好
- 甚至基于用户的工作习惯进行学习和优化
这不就是贾维斯的初级形态吗?
markdown
🤔 贾维斯初级版:AI 组织者系统
如果要设计这样一个系统,也许需要这几个部分:
📚 记忆层 🎯 执行层 📊 学习层
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ 工作模板? │◄───────►│ 任务拆分? │◄──────►│ 效果分析? │
│ 成功案例? │ │ 进度跟踪? │ │ 模式识别? │
│ 踩坑记录? │ │ 质量把关? │ │ 持续优化? │
└─────────────┘ └─────────────┘ └─────────────┘
▲ ▲ ▲
│ │ │
└────────────────────────┼───────────────────────┘
▼
┌─────────────────────┐
│ 🤖 协调中心? │
│ │
│ 这里应该做什么?? │
│ • 理解用户意图? │
│ • 调度各个模块? │
│ • 整合反馈信息? │
└─────────────────────┘这样的系统可能比单纯的 AI 工具更有价值。它不只是帮你干活,还能帮你总结经验、优化流程。
五、写在最后
分享这些体验,主要是想抛砖引玉。我相信很多人都有类似的感受,也有自己的协作技巧。
如果把这些个人经验汇聚起来,会不会产生一些有趣的化学反应?比如:
- 不同人的任务拆分策略有什么共性?
- 哪些决策点是最关键的?
- 如何设计一个既能学习又能适应的协作系统?
- 人机协作的最佳实践是什么?
我觉得这些问题比单纯提升 AI 能力更有意思。毕竟,真正的贾维斯不只是一个更强的助手,而是一个懂你的协作伙伴。
这一天,可能比我们想象的更近。关键是要找到正确的路径。
*本文仅分享作者基于个人技术实践的思考和主观观点,不构成决策依据。