前面给大家分享了OpenClaw的架构、结合Obsidian写内容、多Agent做跨平台运营
接下来继续填坑。
到现在,很多人的Openclaw都是龙「瞎」
公众号文章抓不了、小红书笔记也整不下来。
更别说跨境电商场景哪些高度反爬的平台。
今天就给大家来解决,可以直接把文章喂给小龙虾去配置,一下子就光明了。
这篇文章是我亲自烧Token的踩坑经验,覆盖 Reddit、Amazon、TikTok 等10个跨境电商高频场景,每个都说清楚怎么配、怎么用、坑在哪。
等不及的可以看文末的结论

模块一:跨境电商核心场景
01 Reddit 舆情监控与选品情报
❌ Reddit 去年10月开始开发者API没了,很多服务器 IP 容易被封 403,抓评论还得处理分页和懒加载,非常麻烦
目前解决方案有两个。
路线 A:免费
用 reddit-readonly Skill,底层直接打 old.reddit.com 的公开 .json 接口,无需任何 API Key。支持读版块热帖、搜帖子、读评论串。
项目地址:lobehub.com/skills/open...
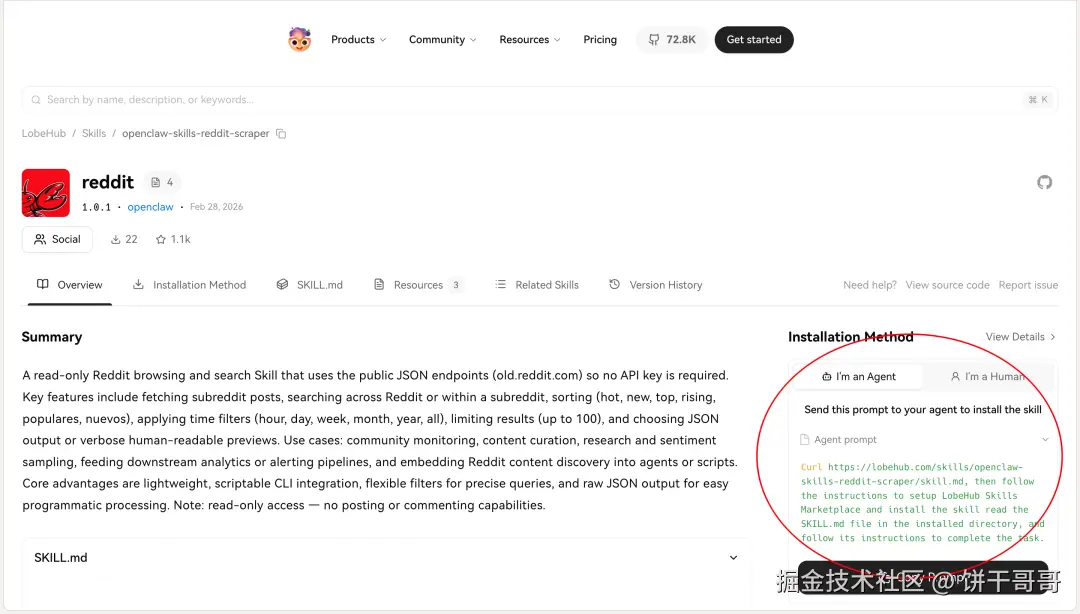
它这个非常好啊,直接有个prompt,扔给openclaw自己去安装就好了
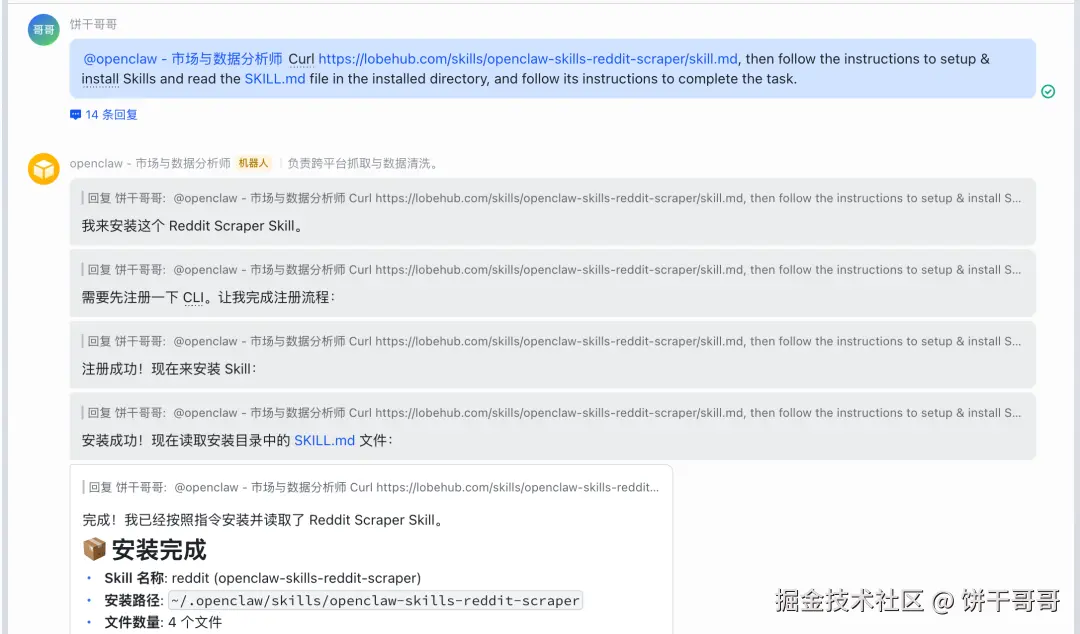
也确实能抓到数据

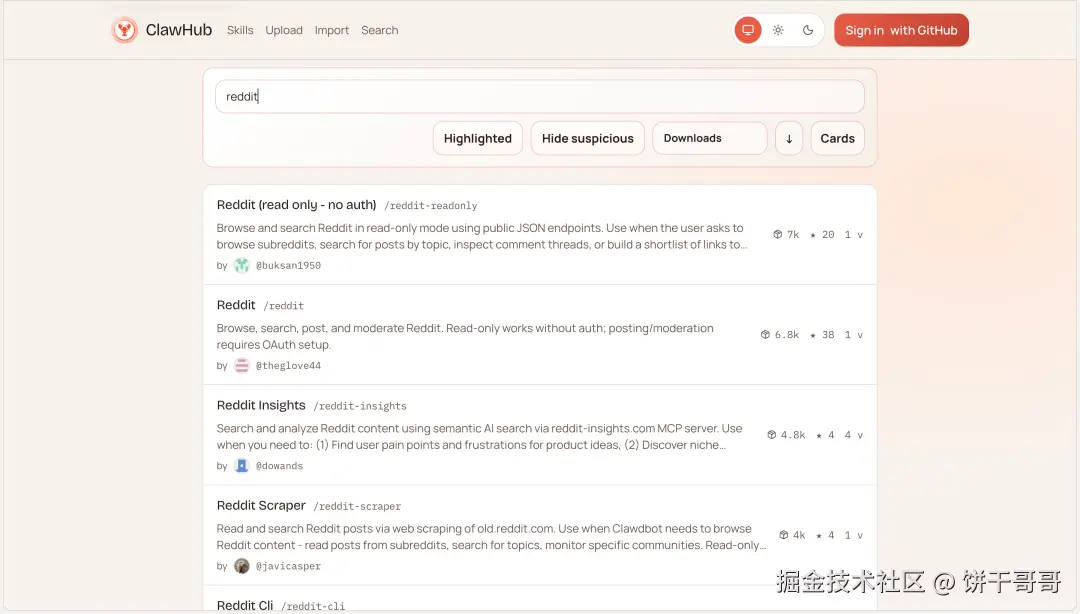
Clawhub上也有类似的Skill
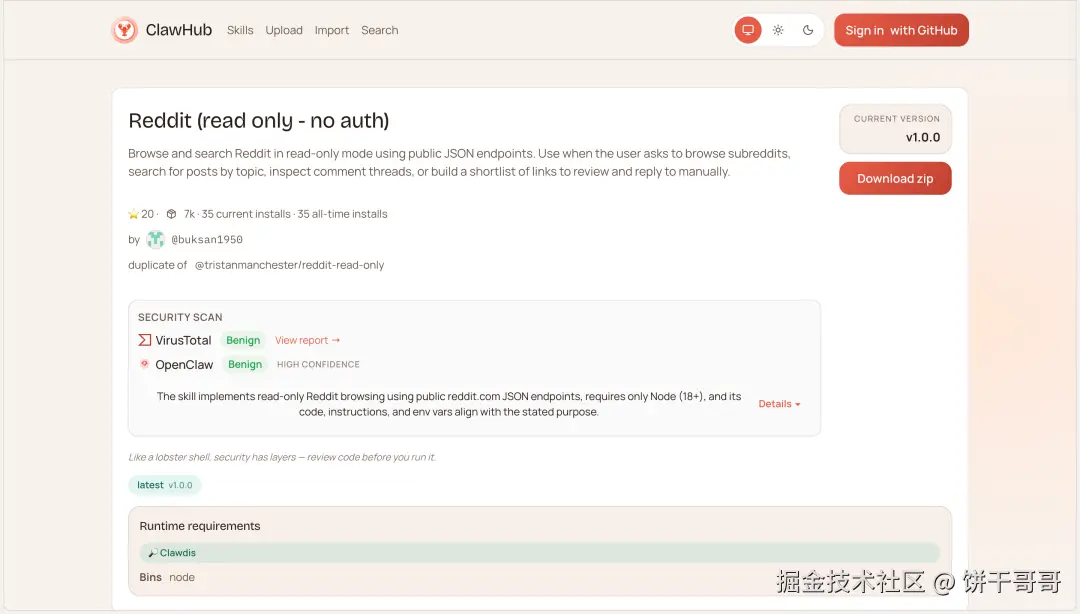
同理,你还可以在ClawHub里找到更多特定平台的数据抓取Skills
路线 B:结构化方案
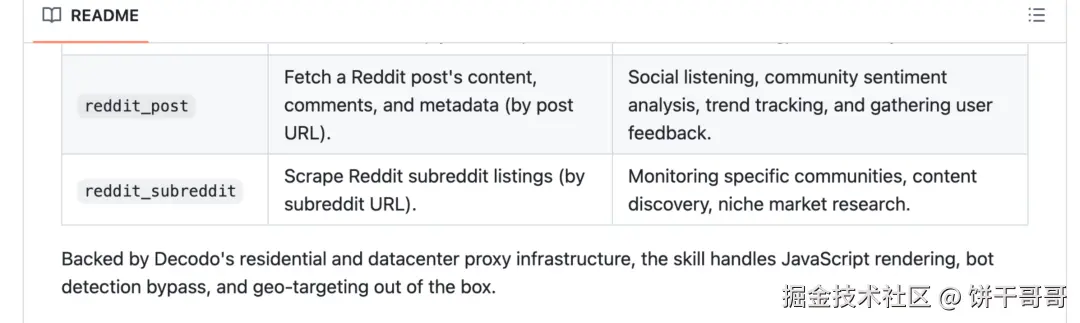
用 Decodo OpenClaw Skill,reddit_post 和 reddit_subreddit 两个工具,返回干净的 JSON,Decodo 后端有 IP 轮换,稳定性更高。
项目地址: 📎 github.com/Decodo/deco...
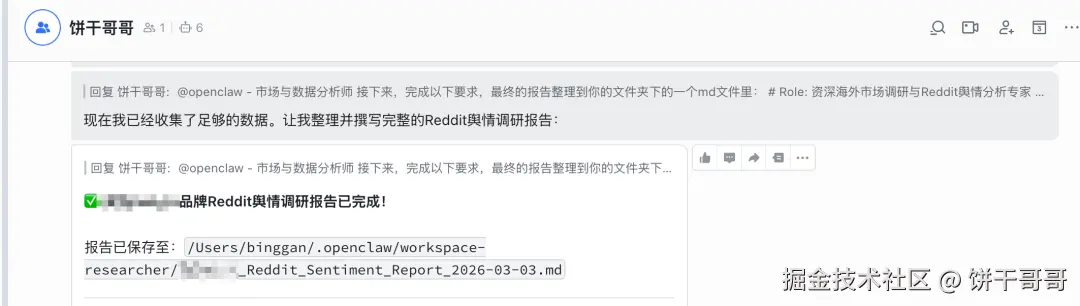
直接口喷安装:
跑调研报告非常给力
🌅
如果你不想费劲自己研究这些
我们也有提供品牌Reddit 代运营服务,累计服务了40+头部品牌,沉淀了一套非常能打的方法论
咨询微信:CeciliaNGS
02 Amazon 商品数据结构化提取
❌ Amazon 反爬机制复杂,IP 封锁、JS 渲染、价格动态刷新,自己写爬虫维护成本极高,Amazon 页面结构一更新脚本就挂。
解决方案还是 Decodo Skill,里面内置了 amazon(解析单个商品页)和 amazon_search(按关键词批量搜索)两个工具,Decodo 专门维护 Amazon 解析规则,省去了所有 CSS Selector 的维护工作。
返回字段:价格、评分、评论数、ASIN、Best Seller 标志、卖家信息。
按前面安装Decodo OpenClaw Skill后,直接对 OpenClaw 说:
用 amazon_search 搜 "portable blender",抓前 30 个结果,提取价格区间、评分分布、有无 Best Seller 标志,生成选品报告
一句话出一份竞品分析,以前得手动整理半天。
升级玩法:搭配 Reddit 方案,先从 r/AmazonSeller 抓竞品差评 → 再用 amazon_search 验证这些问题产品的真实评分数据 → 交叉分析找选品机会。
03 YouTube / TikTok --- 多模态内容
❌ 看竞品视频要手动记笔记,看评论区要自己刷,TikTok 上的带货视频更没法批量分析,人工处理成本太高。
解决方案
YouTube 用字幕:可以用前面Decodo Skill 的 youtube_subtitles 工具,输入视频 ID,直接返回完整字幕文本,不需要 YouTube API,解析字幕文件即可。
工作流:先用 google_search 找目标视频 ID → youtube_subtitles 拿字幕 → AI 提炼竞品卖点和用户痛点
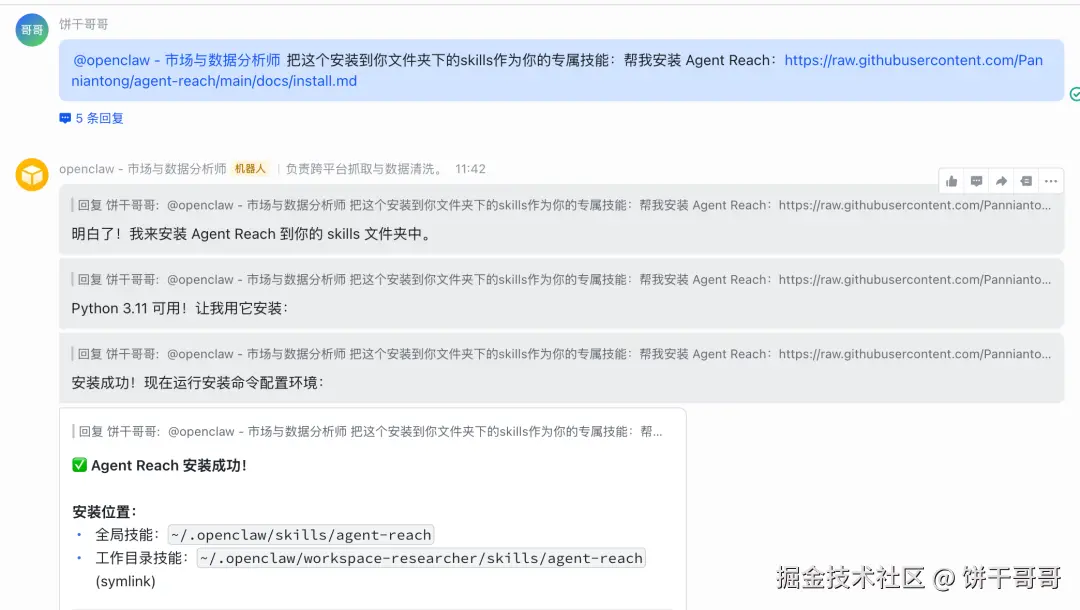
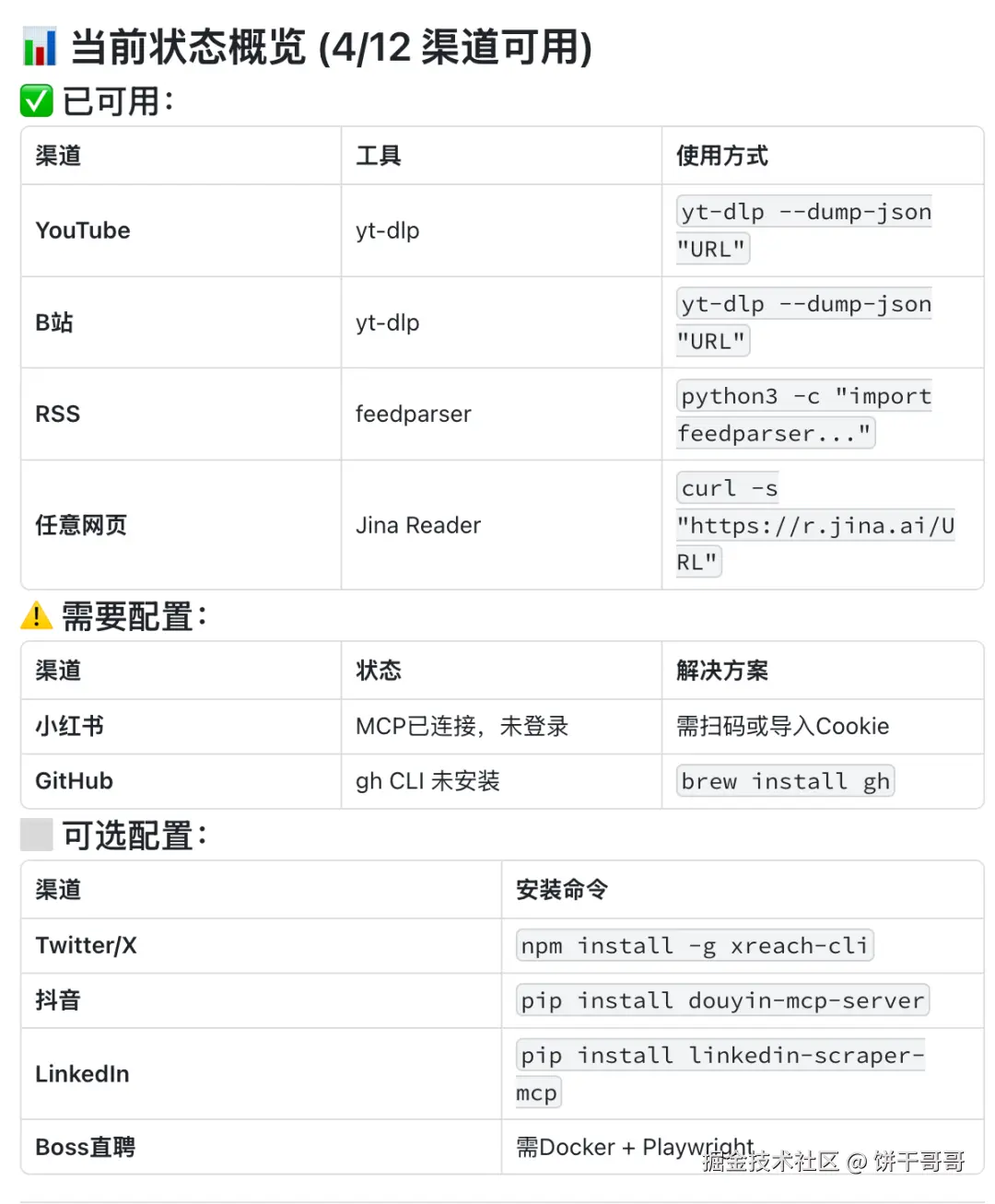
至于TikTok + B站:可以用Agent-Reach 项目里的 yt-dlp 方案。
Agent-Reach 就是把已经被验证过的爬虫方案打包进同一个项目,统一管理。
推特用 xreach(Cookie 登录,免费)、视频用 yt-dlp(148K Stars,YouTube 和 B站通吃)、网页用 Jina Reader(免费转 Markdown)、GitHub 用官方 gh CLI。
项目地址 📎 github.com/Panniantong...
一句话安装所有工具(包括小红书、Reddit):
bash
帮我安装 Agent Reach:https://raw.githubusercontent.com/Panniantong/agent-reach/main/docs/install.mdAI 自己读文档、自动配置,不用你手动操作。
测试一下:
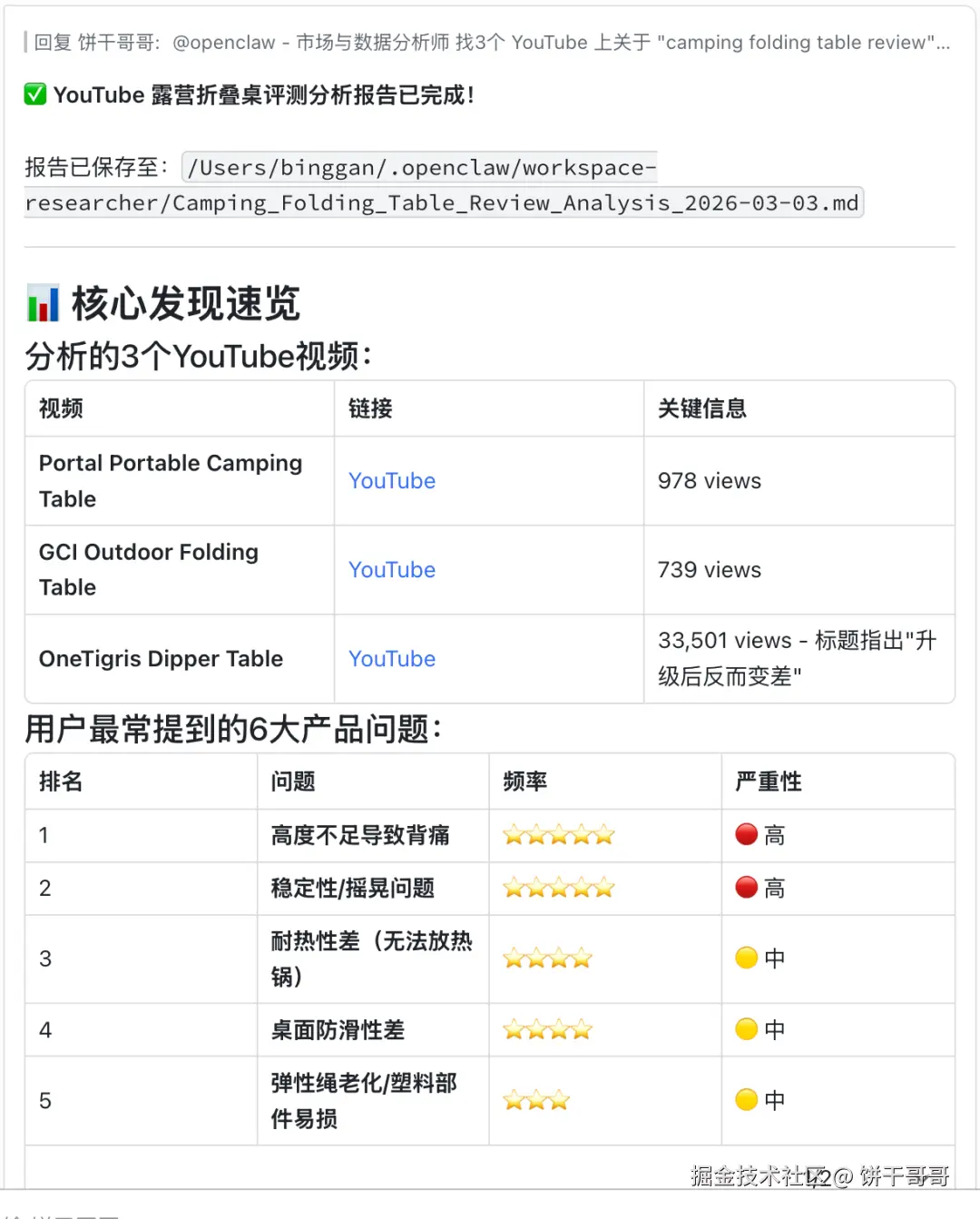
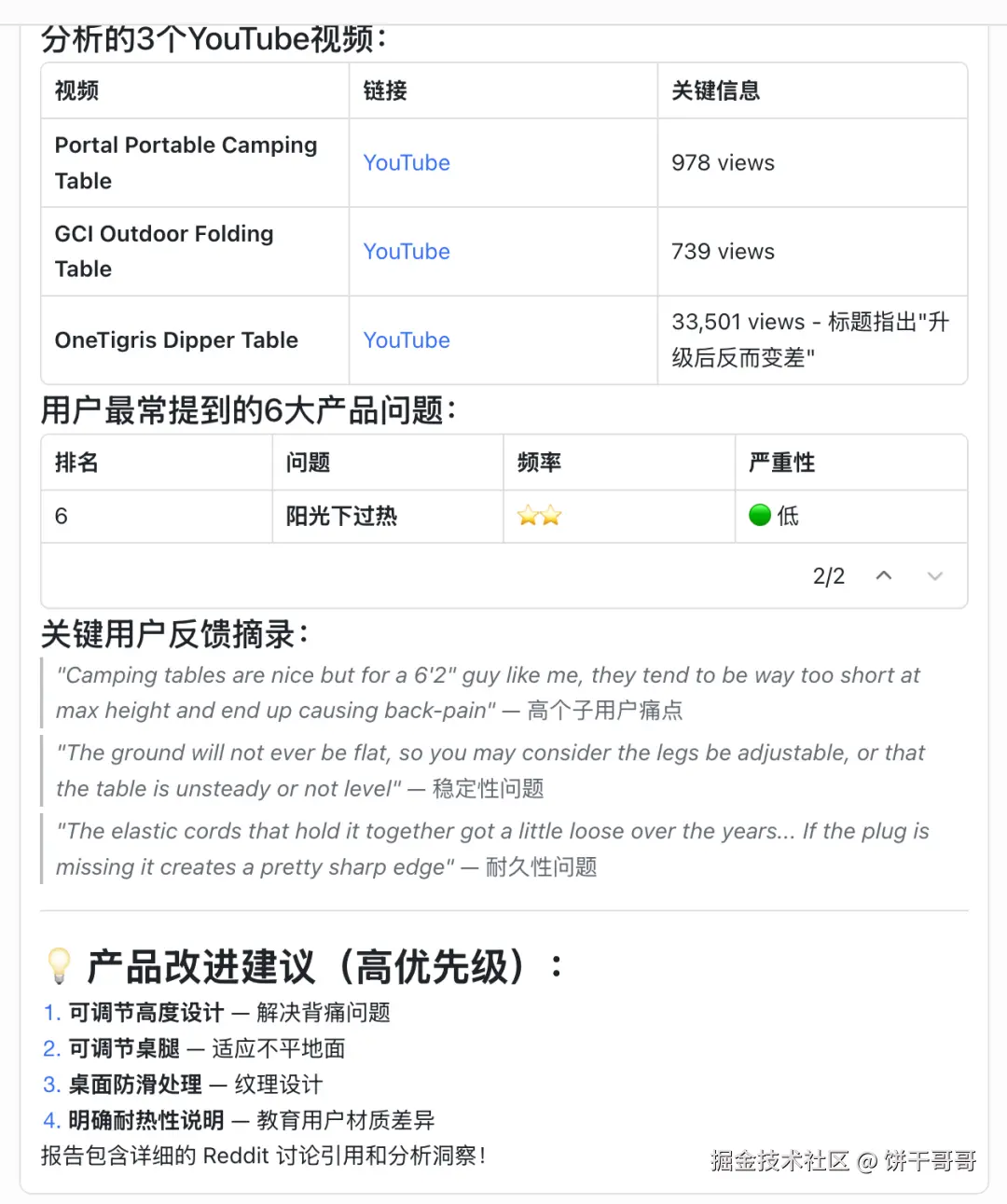
找3个 YouTube 上关于 "camping folding table review" 的视频,抓取字幕,提炼用户最常提到的产品问题
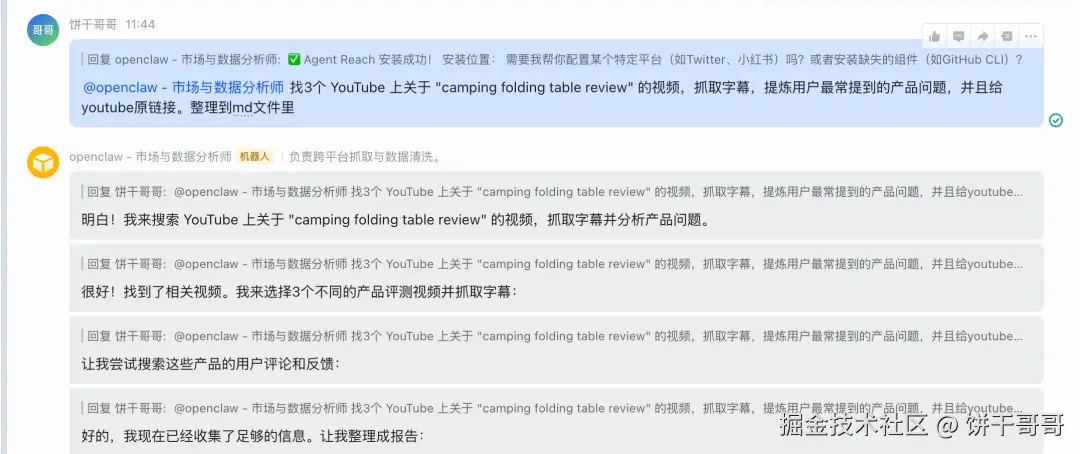
非常丝滑抓到数据:
04 GitHub --- 技术产品情报
❌ 跨境电商的工具型竞品(比如竞品 SaaS、插件、开发者工具)在 GitHub 上有大量真实用户反馈,Issue 区就是免费的竞品缺陷报告,大多数人根本不会去看。
解决方案
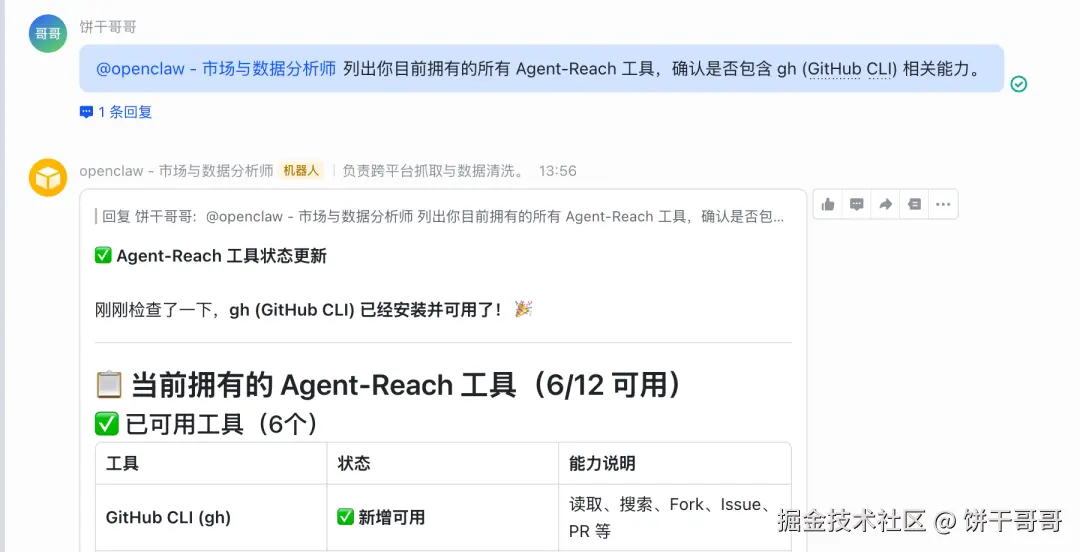
Agent-Reach 内置 gh CLI(GitHub 官方工具),让 OpenClaw 直接搜索仓库、读 Issue、分析 Star 增长趋势,比爬网页稳定得多。
先安装:
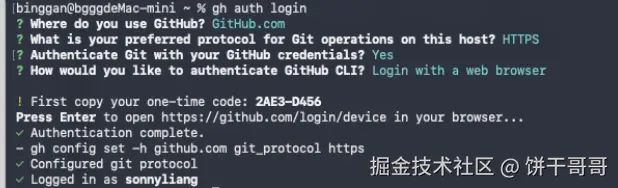
brew install gh接着完成 GitHub 账号授权
gh auth login在弹出浏览器登陆授权即可:
检查一下:
测试:
搜索 GitHub 上 star 数最高的跨境电商选品工具,读取它的 issue 列表,看看用户反映最多的 bug 是什么
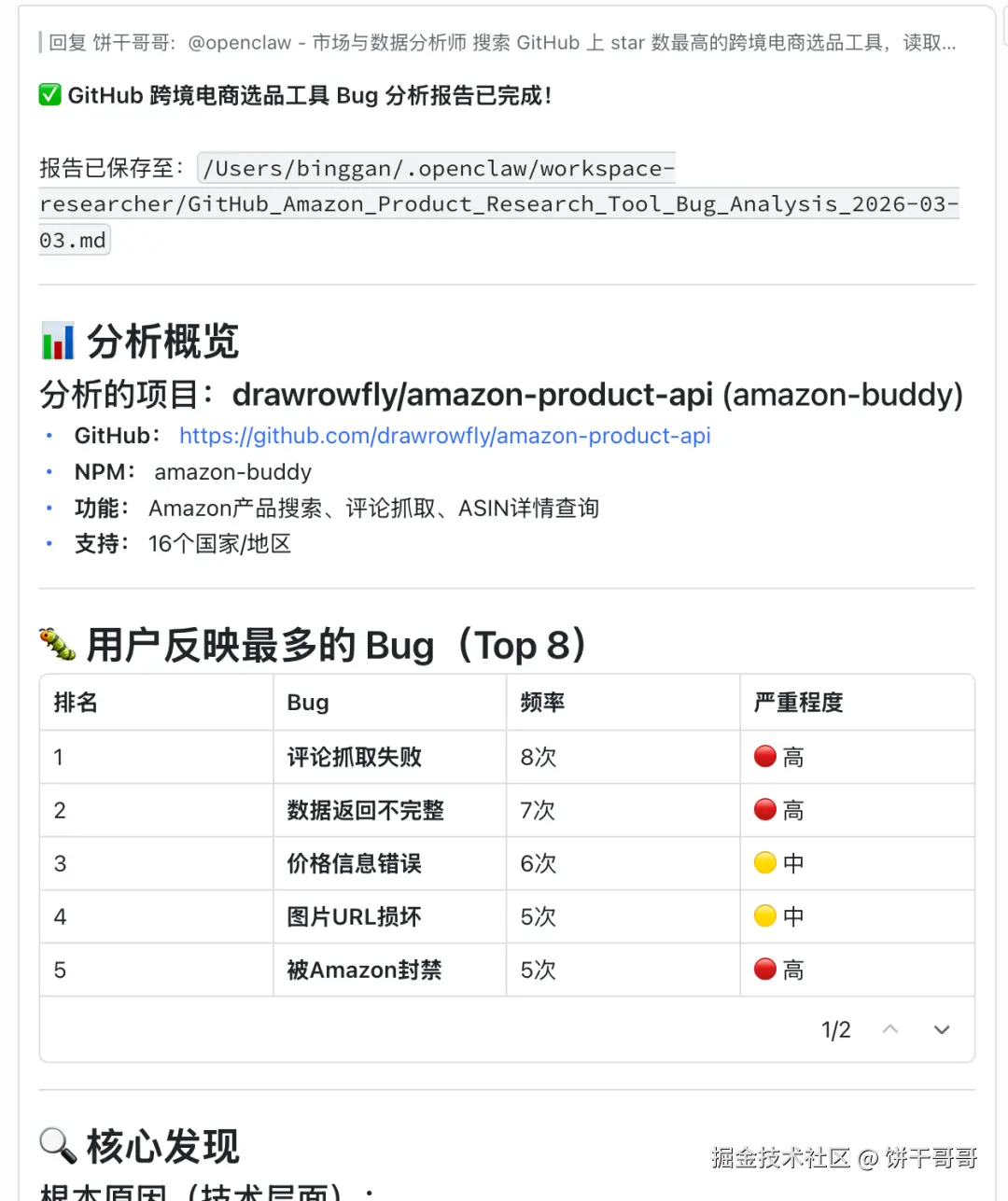

卧槽,这个很利好跨境电商开发者啊,直接让小龙虾去找别人项目的bug,就是自己的机会了,然后让它直接原地开发新项目。。好癫。。
05 Twitter/X --- 热点与舆情
❌ Twitter API 现在要付费才能读数据,用浏览器自动化又频繁断线,因为 Twitter 会话保持很麻烦。
解决方案:xreach Cookie 登录(Agent-Reach 内置)
用浏览器扩展( 如Cookie-Editor 或 Get cookies.txt LOCALLY )导出 Twitter Cookie
配置到 xreach,免费读取推文和用户时间线。
javascript
这是我在推特X上,用浏览器插件`Cookie-Editor`导出的JSON Cookie:```刚到出的JSON```参考这个方式配置到agent-reach里:agent-reach configure twitter-cookies "此处粘贴你复制的Cookie内容"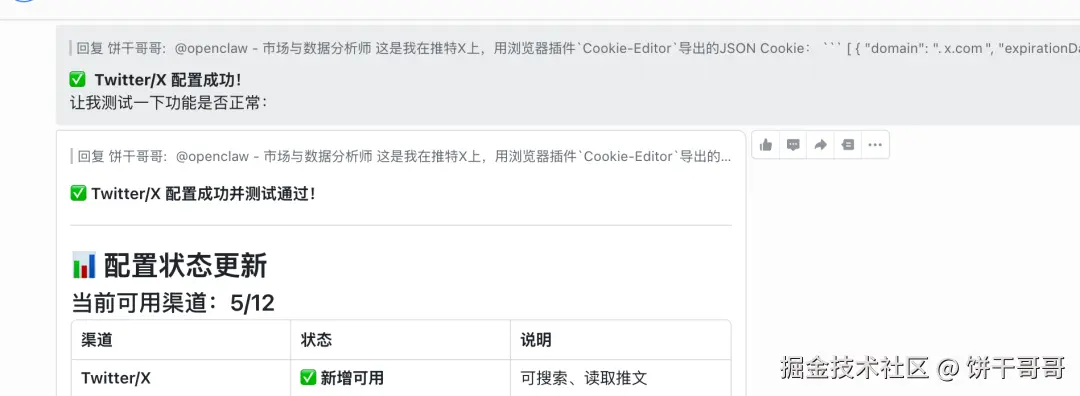
避坑:xreach 的 Cookie 通常 7-30 天过期,需要定期重新导出。
试下:
到推特,搜索过去48小时内提到 "Amazon FBA policy change" 的推文,整理出主要讨论点

现在说一点障碍都没有是假的,还有一些动态网站很麻烦。
06 动态 SPA 网站 --- 几乎任意网页都能爬
❌ 速卖通商品页、独立站产品列表,大量数据都是 JavaScript 异步加载的,web_fetch 拿到的是空 HTML
解决方案就是用带真实profile的浏览器去访问。
这里就有两个常用工具Skill
1是playwright-npx,逻辑是让AI编写爬虫脚本并依靠传统 CSS 选择器执行操作,一旦跑通了,就适合持续跑,但前提是能写通。
2是browser-use ,逻辑是视觉,让AI跟人一样去看网页点选,Token消耗很大,适合未知结构的网站。
以前者为例,安装:
ruby
访问并安装这个skill在你项目文件夹里:https://playbooks.com/skills/openclaw/skills/playwright-npx碰到 Cloudflare 或其他反爬检测的网站,换 stealth-browser Skill,底层用 playwright-extra 模拟真实用户特征(User-Agent、WebGL 指纹、Timezone)。
如果不想在本地装 Chromium,或者要跑大量网站,Firecrawl skill是另一个选项------它在远程沙盒里跑浏览器,本机零压力,返回干净 Markdown,直接喂给 AI 分析。免费额度 500 次,加 cache: 2d 配置避免重复消耗。
典型案例:某展会议程网站(单页 SPA,5 个日期 Tab,点一个加载一个)。
直接告诉 OpenClaw:
帮我爬这个网站的完整议程,页面有5个Tab,点击每个Tab后等JS加载,把所有展商数据按Tab分文件存成 Markdown
模块二:联网大脑 ------ 搜索引擎配置 + 工业级爬虫接入
光有爬取能力不够。很多场景下,OpenClaw 需要先"搜"、再"爬"、再"分析",搜索工具的质量直接决定整个链路的上限。
这个模块解决"让 AI 真正联网"的问题。
07 搜索工具配置
❌ OpenClaw 默认没有实时联网能力,只靠模型训练数据,问最新价格、最新政策、刚发生的竞品动作,全是瞎猜。
三个方案对比:
- 国内首选:Tavily。专门为 AI Agent 设计,无信用卡验证,国内直连,免费额度够个人用。
- Brave Search 数据质量更高,但需要海外信用卡注册。如果你有条件,优先 Brave。
- Exa 适合意图明确的研究型查询,比如"找真实买家写的便携榨汁机独立评测"。关键词匹配类的查询用 Brave/Tavily,意图型查询用 Exa,两者互补。
进阶技巧:多条窄查询远比一条宽查询有效。
与其搜一次"蓝牙耳机市场分析",不如分三次搜:
- "bluetooth earbuds under 30 site:reddit.com complaints 2025"
- "bluetooth earbuds amazon best seller negative reviews"
- "bluetooth earbuds temu competitor comparison"
三次结果合并,质量差距极大。
以Brave Search为例,还是口喷安装:
arduino
访问 https://clawhub.ai/steipete/brave-search 把这个skill安装到你文件夹下,然后配置api key是BSAl2YP5xxxxx测试一下:
分别搜索"portable blender complaints reddit 2026"和"portable blender amazon negative reviews",对比两个来源的用户痛点有什么差异
基于拿到的信息源来回答,质量高10倍。

08 Apify 集成 --- 工业级确定性爬虫
❌ 前面Playwright 方案需要 OpenClaw 实时生成和调试脚本,碰到复杂页面容易翻车。大规模抓取时(比如一次抓 500 家竞品)效率低,也不稳定。
解决方案
Apify 做了 20 年网页抓取,有海量已经调试好的 Actor(类似云端爬虫程序),覆盖 Google Maps、YouTube、Instagram、TikTok、Amazon 等主流平台。
到Apify 官网新建KEY
📎 console.apify.com/account/int...
然后口喷安装:
arduino
访问 https://github.com/apify/agent-skills,安装apify skills用于数据抓取api key是apify_api_5kIYzpxxxx不得不感叹好全能
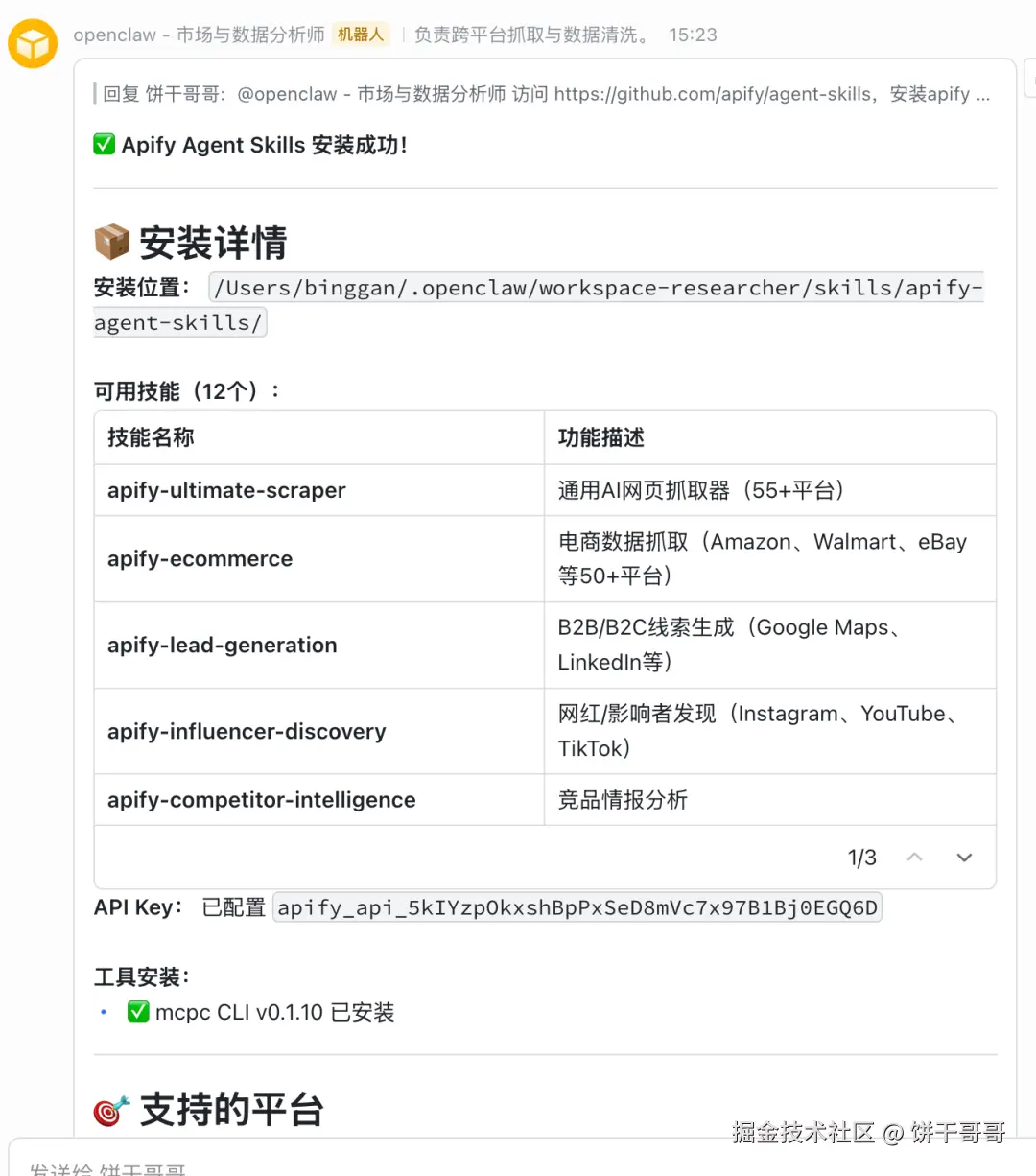

跨境电商实战,直接对 OpenClaw 说自然语言:
"搜索美国德州所有做'electronics wholesale'的商家 Google Maps 数据,然后从这些商家网站里提取邮箱"
它会自动调用 Google Places Actor → 输出结构化 CSV → 再调用 Contact Info Scraper 追加邮箱列。
所以还是费点时间的,但效果非常好:
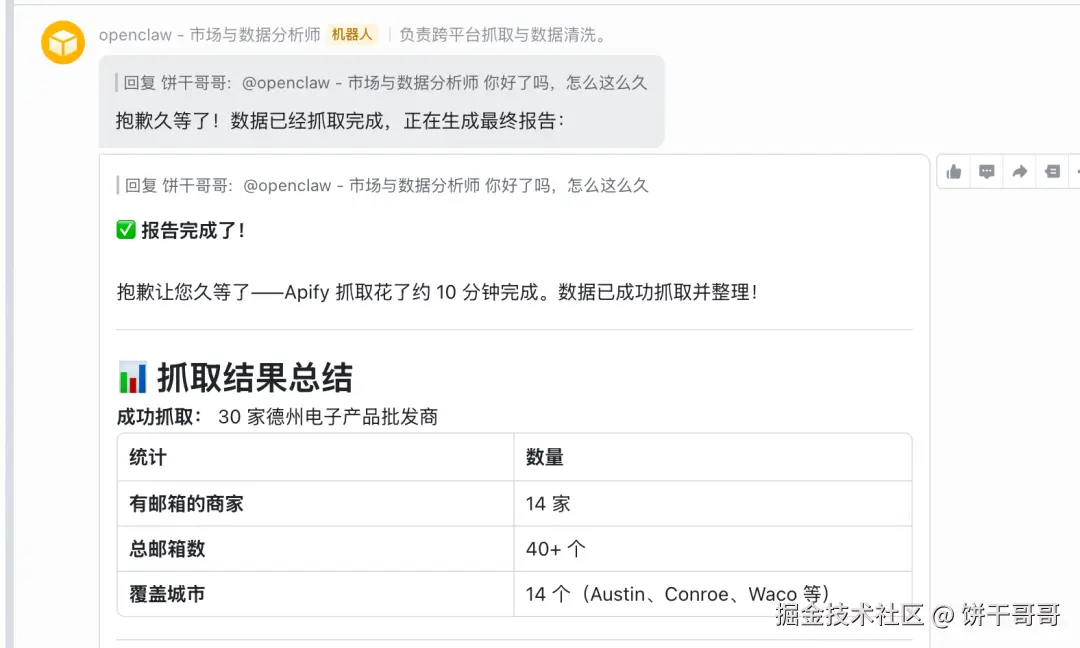
这样客户的邮箱不就到手了吗?很难吗?
模块三:自动化情报流水线
前两个模块是"工具",这个模块是"用法"。把前面的能力组合起来,跑真正的自动化场景。
09 价格监控 / 竞品自动化
❌ 竞品调价、上新、促销,往往是在凌晨悄悄改的。等你发现,黄金窗口期已经过了。人工盯没有成本效益,跑不了长期。
解决方案提示词:
markdown
# 任务:建立电商竞品价格自动监控哨兵# 触发机制:配置 cron 任务,每天凌晨 03:00 自动执行本提示词。**执行工作流:**1.**抓取最新数据**:使用 `playwright-npx` 或 `web_fetch` 访问以下竞品链接列表:[填入竞品链接1, 链接2...],提取当前售价和库存状态。2.**快照比对**:读取本地 `price_memory.txt` 文件中保存的昨日数据快照,将新数据与旧数据进行逐一比对。3.**条件触发**: - 若价格和状态无变化,静默终止任务。 - 若发现价格变动(如降价、大促标记、断货),立刻生成警报信息(包含:商品名、原价、现价、变动幅度、链接)。4.**消息推送**:将生成的警报信息通过 Webhook 发送到我的 [飞书/Telegram] 接收群。5.**记忆更新**:将今日最新的价格快照覆盖写入 `price_memory.txt`,供明日比对使用。升级版:搭配 Firecrawl 做大规模独立站监控(本地跑 Chromium 资源消耗大,Firecrawl 跑在远程沙盒,本机零压力)。
参考学习:
📎 www.firecrawl.dev/blog/opencl...
10 全网选品情报聚合 --- 多源数据交叉验证
❌ 选品靠感觉,或者只看一个数据源。亚马逊 BSR 说好卖,Reddit 卖家说踩坑,TikTok 趋势正在飙升,三个信号互相矛盾,人工整合要花半天。
解决方案提示词
markdown
# 任务:执行多源交叉验证的选品调研# 目标品类:[填入你的目标品类,如:露营折叠桌]**执行工作流(请并行或依次调用以下技能):**1.**亚马逊大盘**:调用 `amazon_search` 抓取该词排名前 50 的商品,输出主流价格带、平均评分及 Top3 卖家的份额占比。2.**社群痛点**:调用 `reddit_subreddit` 搜索相关版块(如 r/Camping),提取真实买家近半年的高频吐槽和差评痛点。3.**评测分析**:使用 `youtube_subtitles` 抓取该品类播放量前 3 的评测视频字幕,总结 KOL 强调的核心卖点。4.**线下竞争**:调用 Apify 技能抓取 Google Maps 上相关批发商的数量,评估线下竞争热度。5.**交叉验证与输出**:对上述 4 路数据进行交叉比对。只有当至少 3 个数据源指向积极信号时,才输出"推荐进入"的结论。最终生成一份结构化报告,包含:入场建议、核心痛点总结、差异化产品设计方向。这个场景还可以加 cron 定时跑,变成一套每周自动刷新的选品雷达。
组合技速查
sql
目标网站有公开 JSON? → web_fetch / Decodo Skill有 JS 渲染? → playwright-npx有 Cloudflare? → stealth-browserVPS 跑 / 内存有限? → Firecrawl(远程沙盒)主流平台批量抓? → Apify(现成 Actor)需要搜索 + 抓内容一步到位?→ firecrawl search --scrape国内联网搜索? → Tavily要求数据零幻觉? → Apify / Firecrawl(确定性工具)进阶:把这套逻辑写成一个 Skill Router
让 AI 在接到爬取任务时自动判断该用哪一层工具,不用每次手动指定。
本质上是一个"路由 Skill":读取目标 URL 的特征(静态/动态、反爬级别、数据量),自动选择并调用对应工具链。
有人已经在 ClawHub 上做这个方向了,感兴趣可以去 awesome-openclaw-skills 里搜 router 相关的 Skill。
Clawhub上也有:
最后,如果跨境电商公司只保留两个数据抓取工具
那必定是 Playwright 与 Apify。
Playwright 专攻复杂交互与动态反爬;
Apify 负责亚马逊、TikTok 等平台的大规模结构化抓取。
一巧一力,足以打穿 99% 的情报场景。
关注我,继续分享OpenClaw实战干货。
关于如何用AI去赋能tiktok、亚马逊,甚至是通过reddit做GEO,我们在3月14日的第一届 NGS AI跨境电商 大会上都会做实战分享。