原文链接:NameServer 极简设计的哲学
RocketMQ 里有个很有意思的组件------NameServer,它干的事情说起来很简单:维护整个 Broker 集群的路由信息,让生产者和消费者知道该往哪发消息、从哪拉消息。
但它的设计思路,和大多数分布式注册中心完全不一样。没有主从选举,没有 Raft,没有 Paxos,节点之间甚至不互相通信。
这篇文章就来聊聊,RocketMQ 为什么要这么设计,以及这种极简背后要解决的真实问题。
RocketMQ 的技术架构
这里先把整个架构过一遍,不然后面讲 NameServer 的时候容易没有上下文。
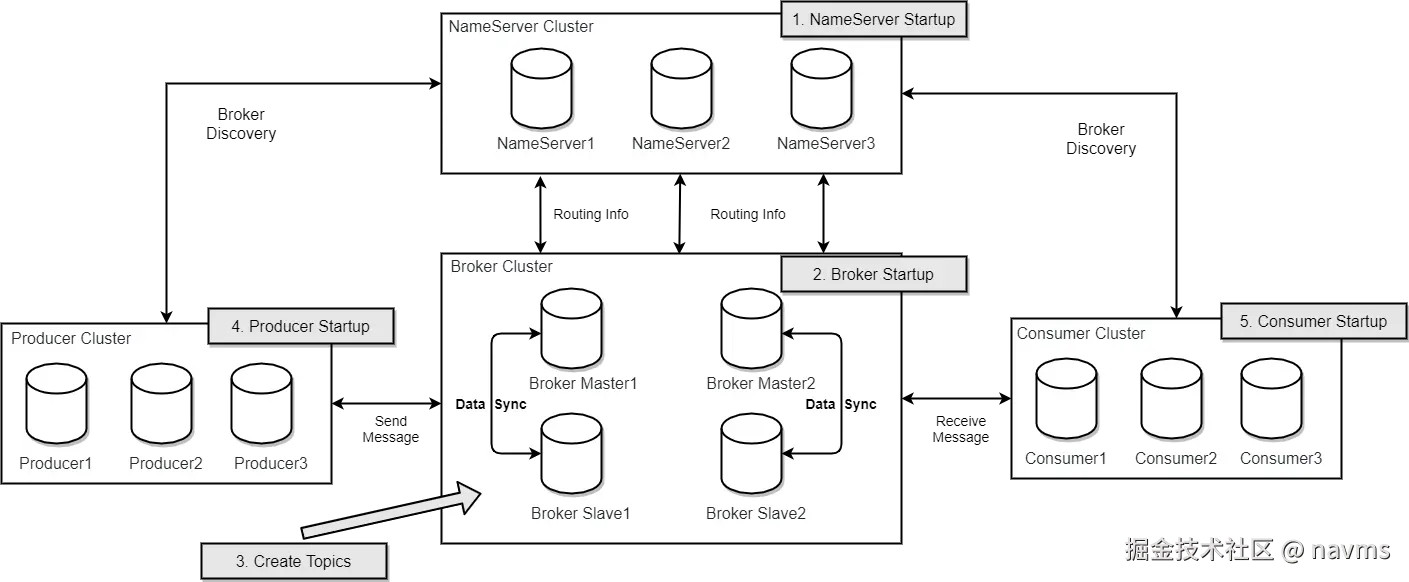
RocketMQ 的核心角色就四个:Producer、Consumer、Broker、NameServer。
Producer(生产者) 负责发消息,支持集群部署。它不直接知道消息该往哪发,发送前要先从 NameServer 拿到这个 Topic 对应的队列列表,然后用负载均衡的方式轮询选一个队列,再和这个队列所在的 Broker 建立连接,把消息打过去。整个过程支持快速失败,延迟很低。
Consumer(消费者) 负责消费消息,同样支持集群部署。它支持 push 和 pull 两种消费模式,同时支持集群消费和广播消费。启动时也是先从 NameServer 拿路由,然后同时和 Master、Slave 建立长连接。有意思的是,Consumer 既可以从 Master 拉,也可以从 Slave 拉------Master 在响应拉取请求时,会根据当前的消费偏移量、积压量等情况,建议客户端下次该从 Master 还是 Slave 拉,相当于 Broker 自己做了一层读流量的调度。
Broker 是消息真正存储和处理的地方,也是这四个角色里内部最复杂的一个。在部署架构上分 Master 和 Slave。一个 Master 可以挂多个 Slave,但一个 Slave 只能对应一个 Master,通过相同的 BrokerName + 不同的 BrokerId 来区分------BrokerId = 0 是 Master,非 0 是 Slave。Broker 启动后会和所有 NameServer 节点建立长连接,定时发送心跳,把自己的 IP、端口以及负责的 Topic 队列信息全部上报上去。
NameServer 就是一个极简的路由注册中心,存的就是 Broker 上报的这些映射关系。Producer 和 Consumer 来查,它就把路由表返回出去,仅此而已。
整个集群的启动顺序也很关键,理解了这个,后面的问题就更容易看清楚:
首先是 NameServer 启动,监听端口,等 Broker、Producer、Consumer 来连,相当于先把"路由中心"拉起来。
然后 Broker 启动,主动和所有 NameServer 节点建立长连接,开始定时发心跳注册自己的路由信息。
Producer 启动时,随机选一台 NameServer 建立长连接,拉取当前要发的 Topic 的路由信息,然后直接和对应的 Broker Master 建立连接开始发消息。
Consumer 启动逻辑类似,也是随机选一台 NameServer 拿路由,但它会同时和 Master、Slave 都建立连接,根据 Broker 的建议决定从哪边拉消息。
听起来很常规,但 NameServer 这个注册中心的实现,和 ZooKeeper、Eureka、Nacos 这些比起来,简单得有点出乎意料。
NameServer 到底有多简单
用一句话概括:NameServer 集群里每个节点都是独立运行的,节点之间没有任何通信,没有数据同步,没有选主,什么都没有。
每个 NameServer 节点维护的是自己独立的一份路由表。Broker 启动的时候,会向配置里所有的 NameServer 节点分别注册,而不是只注册一个然后靠集群同步。
你可以理解成:同一份路由信息,Broker 会交给每个 NameServer 保存。
这就是所谓的「无状态」设计。节点之间没有共享状态,没有一致性协议,所以也不存在脑裂、选举超时、网络分区这些分布式系统的经典难题。
相比之下,ZooKeeper 用的是 ZAB 协议,Raft 系的注册中心要搞 Leader 选举,这些实现复杂,出了问题排查起来也麻烦。RocketMQ 在最初设计的时候就决定:注册中心只做路由存储,把复杂性降到最低。
这个决定背后的逻辑其实很清晰------注册中心本质上是个读多写少的系统,数据强一致性的代价远大于收益,用最终一致性加上客户端容错来兜底,已经够用了。
无状态设计在分布式场景下可能的问题
极简的设计带来了极低的复杂度,但同时也绕不开两个问题。
第一个问题:NameServer 节点自己挂了怎么办?
因为节点之间不互相感知,一个节点挂掉,它不会通知其他节点,也不会有什么故障切换的逻辑。
这个时候生产者和消费者怎么办?
第二个问题:Broker 挂了,路由信息没有及时清掉怎么办?
Broker 是通过心跳上报信息的,默认 30 秒发一次。如果 Broker 突然宕机,心跳就断了,但 NameServer 里保存的路由信息还在,还会有一段时间把流量往挂掉的 Broker 路由。
这段时间内,生产者拿到的路由是过期的,发出去的消息可能就打到了一个已经死掉的机器上。
这两个问题如果解决不好,整个消息链路就会出现不可用的情况。
解决方案概要
这两个问题,RocketMQ 靠的是「多副本 + 本地缓存 + 自动重试」这套组合拳。
NameServer 节点故障:靠多副本和客户端重试
生产者和消费者在启动的时候,会把所有 NameServer 的地址都配进来,连接的时候随机选一个。如果这个节点挂了,客户端会自动切换到下一个节点重试。
这件事对调用方几乎是透明的。只要 NameServer 集群里还有一个节点活着,路由查询就不会失败。
而且客户端拿到路由信息之后,会缓存在本地,默认每 30 秒刷新一次。就算 NameServer 全挂了,本地缓存里的路由还能撑一段时间。
所以 NameServer 的高可用,靠的不是节点之间的协调,而是多副本加上客户端自己的容错能力。
Broker 宕机,路由信息没及时清:靠心跳超时 + 生产者重试
Broker 默认每 30 秒向 NameServer 发一次心跳。NameServer 这边有个后台线程每 10 秒扫一次,把超过 120 秒没有收到心跳的 Broker 从路由表里踢掉。
也就是说,从 Broker 宕机到路由信息被清除,最多可能有将近 2 分钟的窗口期。
这段时间内,生产者如果拿到了过期路由,打到已挂 Broker 上的消息会失败。这个失败 RocketMQ 是通过发送重试来兜底的:默认重试 2 次,重试的时候会换一个队列,也就是有机会路由到另一台正常的 Broker 上。
同时,Broker 本身支持主从架构(Master-Slave),Master 挂掉之后,Consumer 可以自动切换到 Slave 继续消费,虽然这期间 Slave 不接受写入,但至少消费侧不会中断。
这里面有一个设计取舍值得注意:RocketMQ 接受了短暂的路由不一致,用重试机制在业务层兜底,而不是在注册中心层面追求强一致性。
这个思路和很多分布式系统的设计是一脉相承的------在 CAP 里选 AP,牺牲短暂的一致性,换来更高的可用性和更低的系统复杂度。
源码层次的深度解读
前面概要讲了两条解决思路,接下来我们进源码,验证这些设计在代码里是怎么落地的。
NameServer 的核心逻辑几乎全在 RouteInfoManager 这一个类里。它用六张 HashMap 存储所有路由数据:
java
// 1. Topic → Queue 信息表
// topic 下每个 broker 上有几个读队列、几个写队列
private final Map<String/* topic */, Map<String/* brokerName */, QueueData>> topicQueueTable;
// 2. Broker 名称 → 地址表
// 一个 brokerName 对应一组主从实例,brokerId=0 是 Master,非 0 是 Slave
private final Map<String/* brokerName */, BrokerData> brokerAddrTable;
// 3. 集群 → Broker 名称集合
// 用来支持按集群维度查询,比如运维看某个集群下有哪些 Broker
private final Map<String/* clusterName */, Set<String/* brokerName */>> clusterAddrTable;
// 4. Broker 地址 → 存活信息(心跳核心)
// 每次心跳都会刷新 lastUpdateTimestamp,超时就踢
private final Map<BrokerAddrInfo/* clusterName+brokerAddr */, BrokerLiveInfo> brokerLiveTable;
// 5. Broker 地址 → FilterServer 列表
// 消息过滤服务器,用于消费端的服务端过滤
private final Map<BrokerAddrInfo, List<String>> filterServerTable;
// 6. 静态 Topic 的队列映射(Topic 迁移用)
private final Map<String/* topic */, Map<String/* brokerName */, TopicQueueMappingInfo>> topicQueueMappingInfoTable;其中最关键的是 brokerLiveTable,它的 value BrokerLiveInfo 存着心跳时间戳和超时阈值------后面两条解决方案的核心逻辑都依赖它。
java
class BrokerLiveInfo {
private long lastUpdateTimestamp; // 最后一次收到心跳的时间戳
private long heartbeatTimeoutMillis; // 超时阈值,默认 120s
private DataVersion dataVersion; // Broker 的 Topic 配置版本号
private Channel channel; // 对应的 Netty 连接 Channel
private String haServerAddr; // HA 服务地址,Slave 同步数据用
}注意超时阈值是每条记录各自存一份,不同 Broker 可以配不同的值,而不是全局一刀切。
六张表和 BrokerLiveInfo 理解了,下面跟着解决方案的脉络走。
解决方案一:NameServer 节点故障,客户端如何容错
概要说的是:客户端随机选一台 NameServer,挂了自动切,本地还有缓存兜底。
我们来看代码里是怎么做的。
客户端定时拉路由,随机挑 NameServer
MQClientInstance 里有一个定时任务,默认每 30 秒触发一次:
java
this.scheduledExecutorService.scheduleAtFixedRate(() -> {
MQClientInstance.this.updateTopicRouteInfoFromNameServer();
}, 10, this.clientConfig.getPollNameServerInterval(), TimeUnit.MILLISECONDS);updateTopicRouteInfoFromNameServer 会把所有 Producer 发布的、Consumer 订阅的 topic 全收集起来,逐个向 NameServer 发 GET_ROUTEINFO_BY_TOPIC 请求:
java
// invokeSync 第一个参数 addr 传 null,底层会随机挑一台可用的 NameServer
RemotingCommand response = this.remotingClient.invokeSync(null, request, timeoutMillis);null 这个参数就是"随机选"的实现:底层维护着所有 NameServer 的连接,传 null 就是从可用节点里随机取一个。如果这台节点挂了,底层会把它从可用列表里摘掉,下次自动换另一台。
拿到路由后缓存在本地,有变化才更新
java
// 和旧缓存比较
TopicRouteData old = this.topicRouteTable.get(topic);
boolean changed = topicRouteData.topicRouteDataChanged(old);
if (changed) {
// 更新本地 brokerAddrTable
for (BrokerData bd : topicRouteData.getBrokerDatas()) {
this.brokerAddrTable.put(bd.getBrokerName(), bd.getBrokerAddrs());
}
// 更新发送路由
impl.updateTopicPublishInfo(topic, publishInfo);
// 更新订阅路由
impl.updateTopicSubscribeInfo(topic, subscribeInfo);
// 刷新缓存
this.topicRouteTable.put(topic, new TopicRouteData(topicRouteData));
}路由信息存在 topicRouteTable 里。就算 NameServer 短时间内全挂了,这份缓存还在,Producer 和 Consumer 仍然能用上一次的路由继续工作。
NameServer 路由查询走独立线程池
NameServer 服务端处理 GET_ROUTEINFO_BY_TOPIC 的是 ClientRequestProcessor,它用的是一个独立的线程池 ,和处理 Broker 注册等其他请求的 defaultExecutor 完全隔离。
java
// NamesrvController 初始化时,路由查询和 Broker 注册等其他请求用两个独立的线程池
this.remotingServer.registerProcessor(RequestCode.GET_ROUTEINFO_BY_TOPIC,
clientRequestProcessor, this.clientRequestExecutor); // ← 独立线程池
this.remotingServer.registerDefaultProcessor(new DefaultRequestProcessor(this), this.defaultExecutor);这样即便出现大规模 Broker 重启、注册请求打满 defaultExecutor,客户端的路由查询也不会被阻塞。
查询本身用的是读锁,允许多个客户端请求并发进来:
java
public TopicRouteData pickupTopicRouteData(final String topic) {
this.lock.readLock().lockInterruptibly();
// 从 topicQueueTable 取队列信息
// 从 brokerAddrTable 取 Broker 地址(深拷贝,防并发修改)
this.lock.readLock().unlock();
}总结:NameServer 节点故障这条路,完全靠客户端侧解决------随机选节点 + 本地缓存 + 独立线程池保证查询不受注册影响。NameServer 集群本身不需要做任何协调。
解决方案二:Broker 宕机,路由信息如何及时清理
概要说的是:Broker 定时发心跳,NameServer 超时扫描踢掉,发送失败靠重试兜底。源码里这条链路稍微复杂一点,分三段来看。
第一段:Broker 怎么发心跳
BrokerController 里有一个定时任务,间隔在 10s ~ 60s 之间,默认 30s:
java
scheduledFutures.add(this.scheduledExecutorService.scheduleAtFixedRate(new AbstractBrokerRunnable(this.getBrokerIdentity()) {
@Override
public void run0() {
try {
if (System.currentTimeMillis() < shouldStartTime) {
BrokerController.LOG.info("Register to namesrv after {}", shouldStartTime);
return;
}
if (isIsolated) {
BrokerController.LOG.info("Skip register for broker is isolated");
return;
}
BrokerController.this.registerBrokerAll(true, false, brokerConfig.isForceRegister());
} catch (Throwable e) {
BrokerController.LOG.error("registerBrokerAll Exception", e);
}
}
}, 1000 * 10, Math.max(10000, Math.min(brokerConfig.getRegisterNameServerPeriod(), 60000)), TimeUnit.MILLISECONDS));registerBrokerAll 里有个优化,在 needRegister 方法中:不是每次都强制发。如果 dataVersion 没变(Topic 配置没改过),且 forceRegister=false,这次心跳可以跳过,减少不必要的网络开销。
真正发出去的逻辑在 BrokerOuterAPI.registerBrokerAll,用 CountDownLatch 并发向所有 NameServer 注册:
java
final CountDownLatch countDownLatch = new CountDownLatch(nameServerAddressList.size());
for (final String namesrvAddr : nameServerAddressList) {
brokerOuterExecutor.execute(new AbstractBrokerRunnable(brokerIdentity) {
@Override
public void run0() {
try {
RegisterBrokerResult result = registerBroker(namesrvAddr, oneway, timeoutMills, requestHeader, body);
if (result != null) {
registerBrokerResultList.add(result);
}
LOGGER.info("Registering current broker to name server completed. TargetHost={}", namesrvAddr);
} catch (Exception e) {
LOGGER.error("Failed to register current broker to name server. TargetHost={}", namesrvAddr, e);
} finally {
countDownLatch.countDown();
}
}
});
}
try {
if (!countDownLatch.await(timeoutMills, TimeUnit.MILLISECONDS)) {
LOGGER.warn("Registration to one or more name servers does NOT complete within deadline. Timeout threshold: {}ms", timeoutMills);
}
} catch (InterruptedException ignore) {
}并发注册,CountDownLatch 等所有节点响应,这是"Broker 自己把同一份路由复制给每台 NameServer"的代码实现。
第二段:NameServer 接收心跳,更新时间戳
心跳到了 NameServer 这边,DefaultRequestProcessor 接收,调用 RouteInfoManager.registerBroker(),这个方法拿写锁。
最核心的一步就是刷新心跳时间戳:
java
BrokerLiveInfo prevBrokerLiveInfo = this.brokerLiveTable.put(brokerAddrInfo,
new BrokerLiveInfo(
System.currentTimeMillis(),
timeoutMillis == null ? DEFAULT_BROKER_CHANNEL_EXPIRED_TIME : timeoutMillis, // 默认 120s
topicConfigWrapper == null ? new DataVersion() : topicConfigWrapper.getDataVersion(),
channel,
haServerAddr));心跳的本质就这一行:每次注册请求到来,把 lastUpdateTimestamp 刷成当前时间。
除此之外,registerBroker 还有几个值得注意的细节:
- 去重 :同一个 IP:Port 只能登记一个
brokerId,防止主从切换时同一地址被重复注册为不同角色。 - 版本检测 :如果这次注册的
stateVersion比已有的低,直接拒绝,防止网络乱序导致旧数据覆盖新数据。 - 只有 Master 才同步 Topic 配置 :普通 Slave 的注册不更新
topicQueueTable,只有brokerId=0的 Master,或 Acting Master 模式下brokerId最小的 Slave(PrimeSlave),才有资格写队列配置。
第三段:Broker 宕机后,路由怎么被清掉
这里有两条独立的路径,形成双重保障。
路径一:定时扫描
NamesrvController 启动时起一个独立的 scanExecutorService,默认每 5 秒扫一次:
java
this.scanExecutorService.scheduleAtFixedRate(NamesrvController.this.routeInfoManager::scanNotActiveBroker,
5, this.namesrvConfig.getScanNotActiveBrokerInterval(), TimeUnit.MILLISECONDS);scanNotActiveBroker 遍历 brokerLiveTable,逐条检查:
java
for (Entry<BrokerAddrInfo, BrokerLiveInfo> next : this.brokerLiveTable.entrySet()) {
long last = next.getValue().getLastUpdateTimestamp();
long timeoutMillis = next.getValue().getHeartbeatTimeoutMillis(); // 默认 120s
if ((last + timeoutMillis) < System.currentTimeMillis()) {
RemotingHelper.closeChannel(next.getValue().getChannel()); // 先关 Channel
log.warn("The broker channel expired, {} {}ms", next.getKey(), timeoutMillis);
this.onChannelDestroy(next.getKey()); // 再触发注销
}
}onChannelDestroy 不会直接注销,而是把请求丢给 BatchUnregistrationService 异步处理,避免扫描线程被写锁阻塞住。
路径二:Netty Channel 事件
BrokerHousekeepingService 实现了 ChannelEventListener,直接监听 Netty 的底层 TCP 事件:
java
public void onChannelClose(String remoteAddr, Channel channel) {
this.namesrvController.getRouteInfoManager().onChannelDestroy(channel);
}
public void onChannelException(String remoteAddr, Channel channel) {
this.namesrvController.getRouteInfoManager().onChannelDestroy(channel);
}
public void onChannelIdle(String remoteAddr, Channel channel) {
this.namesrvController.getRouteInfoManager().onChannelDestroy(channel);
}如果 TCP 连接在网络层直接断掉,Netty 会立刻感知,不需要等下一次定时扫描。这条路径的响应速度比轮询快得多。
两条路径最终都走到 unRegisterBroker,把这个 Broker 从四张表里清掉(brokerLiveTable、brokerAddrTable、clusterAddrTable、topicQueueTable)。
补充:Acting Master 让消费者无感知切换
Broker Master 宕机后,上文我们还提到 Consumer 可以切到 Slave 继续消费。这个切换的触发点在 pickupTopicRouteData 里:
java
// Master(brokerId=0)不在了,把 brokerId 最小的 Slave 伪装成 Master 返回
boolean needActingMaster = false;
for (final BrokerData brokerData : topicRouteData.getBrokerDatas()) {
if (!brokerData.getBrokerAddrs().isEmpty()
// Master 不在了
&& !brokerData.getBrokerAddrs().containsKey(MixAll.MASTER_ID)) {
needActingMaster = true;
break;
}
}
if (!needActingMaster) {
return topicRouteData;
}
for (final BrokerData brokerData : topicRouteData.getBrokerDatas()) {
final HashMap<Long, String> brokerAddrs = brokerData.getBrokerAddrs();
if (brokerAddrs.isEmpty() || brokerAddrs.containsKey(MixAll.MASTER_ID) || !brokerData.isEnableActingMaster()) {
continue;
}
// No master
for (final QueueData queueData : topicRouteData.getQueueDatas()) {
if (queueData.getBrokerName().equals(brokerData.getBrokerName())) {
if (!PermName.isWriteable(queueData.getPerm())) {
// 把 brokerId 最小的 Slave 伪装成 Master 返回
final Long minBrokerId = Collections.min(brokerAddrs.keySet());
final String actingMasterAddr = brokerAddrs.remove(minBrokerId);
brokerAddrs.put(MixAll.MASTER_ID, actingMasterAddr);
}
break;
}
}
}客户端拿到的路由里,那台 PrimeSlave 的地址被替换成 brokerId=0 返回出去了。客户端不需要感知"现在谁是主",只管往 brokerId=0 的地址发请求,NameServer 在查询层面就把切换做掉了。
解决方案三:Producer 发消息失败,如何自救
前面两个解决方案都在 NameServer 和 Broker 侧。但有一个核心问题还没讲:Broker 刚挂,路由还没来得及清,Producer 这边怎么办?
这才是 Producer 侧容错机制要解决的问题。它比你想象的复杂得多,分三层来看:路由缓存、发送重试、故障规避。
路由缓存:Producer 侧有一套独立的数据结构
MQClientInstance 里存的是从 NameServer 拉来的原始路由数据 TopicRouteData,但 Producer 实际用的不是它,而是经过加工的 TopicPublishInfo,存在 DefaultMQProducerImpl.topicPublishInfoTable 里:
java
private final ConcurrentMap<String/* topic */, TopicPublishInfo> topicPublishInfoTable =
new ConcurrentHashMap<>();TopicPublishInfo 长这样:
java
public class TopicPublishInfo {
private boolean orderTopic = false;
private boolean haveTopicRouterInfo = false;
private List<MessageQueue> messageQueueList = new ArrayList<>(); // 所有可写队列的展开列表
private volatile ThreadLocalIndex sendWhichQueue = new ThreadLocalIndex(); // 线程本地的轮询计数器
private TopicRouteData topicRouteData; // 原始数据的引用
}topicRouteData 里是 Broker 维度的路由,messageQueueList 是已经展开成一条条 MessageQueue 的列表。举个例子,假设有 broker-a 和 broker-b 各 4 个写队列,messageQueueList 里就是 8 条记录,按 Broker 顺序排列。
这个转换在 topicRouteData2TopicPublishInfo 里完成,有一个很关键的过滤条件:
java
for (QueueData qd : qds) {
if (PermName.isWriteable(qd.getPerm())) { // 只取有写权限的队列
BrokerData brokerData = null;
for (BrokerData bd : route.getBrokerDatas()) {
if (bd.getBrokerName().equals(qd.getBrokerName())) {
brokerData = bd;
break;
}
}
if (null == brokerData) {
continue;
}
// 没有 Master 的 Broker 直接跳过
if (!brokerData.getBrokerAddrs().containsKey(MixAll.MASTER_ID)) {
continue;
}
for (int i = 0; i < qd.getWriteQueueNums(); i++) {
MessageQueue mq = new MessageQueue(topic, qd.getBrokerName(), i);
info.getMessageQueueList().add(mq);
}
}
}没有 Master 的 Broker 在转换阶段就被过滤掉了。 这是第一道故障规避,在路由数据转换层面就把不可用的 Broker 排除出去。
发送入口:sendDefaultImpl 的重试循环
发消息的主逻辑在 DefaultMQProducerImpl.sendDefaultImpl,它在发之前先拿路由,拿不到时有两级降级:
java
private TopicPublishInfo tryToFindTopicPublishInfo(final String topic) {
TopicPublishInfo topicPublishInfo = this.topicPublishInfoTable.get(topic);
if (null == topicPublishInfo || !topicPublishInfo.ok()) {
// 缓存里没有,立刻去 NameServer 拉一次
this.topicPublishInfoTable.putIfAbsent(topic, new TopicPublishInfo());
this.mQClientFactory.updateTopicRouteInfoFromNameServer(topic);
topicPublishInfo = this.topicPublishInfoTable.get(topic);
}
if (topicPublishInfo.isHaveTopicRouterInfo() || topicPublishInfo.ok()) {
return topicPublishInfo;
} else {
// NameServer 也没有这个 Topic,用默认 Topic(TBW102)的路由兜底
// 这是 Topic 自动创建的入口
this.mQClientFactory.updateTopicRouteInfoFromNameServer(topic, true, this.defaultMQProducer);
return this.topicPublishInfoTable.get(topic);
}
}拿到路由之后是一个 for 循环:
java
// 同步:1 + retryTimes(默认共 3 次);异步/单向:只发 1 次,不在这里重试
int timesTotal = communicationMode == CommunicationMode.SYNC
? 1 + this.defaultMQProducer.getRetryTimesWhenSendFailed() : 1;
int times = 0;
for (; times < timesTotal; times++) {
String lastBrokerName = null == mq ? null : mq.getBrokerName();
boolean resetIndex = times > 0; // 重试时重置轮询索引
MessageQueue mqSelected = this.selectOneMessageQueue(topicPublishInfo, lastBrokerName, resetIndex);
// ... 发送,记录结果,决定是否 continue
}每次循环都会把上一次用的 BrokerName 传进去(lastBrokerName),让队列选择器知道"上次用了哪个 Broker,这次尽量别选它"。
四种异常的处理方式各不相同,这里是源码里最值得仔细看的地方:
java
} catch (MQClientException e) {
endTimestamp = System.currentTimeMillis();
// isolation=false, reachable=true:按实际耗时查隔离表,不标记不可达
this.updateFaultItem(mq.getBrokerName(), endTimestamp - beginTimestampPrev, false, true);
exception = e;
continue; // 继续重试
} catch (RemotingException e) {
endTimestamp = System.currentTimeMillis();
if (this.mqFaultStrategy.isStartDetectorEnable()) {
// 开启了探活线程:isolation=true, reachable=false,标记不可达,由探活线程恢复
this.updateFaultItem(mq.getBrokerName(), endTimestamp - beginTimestampPrev, true, false);
} else {
// 没有探活线程:isolation=true, reachable=true,只隔离,不标记不可达
this.updateFaultItem(mq.getBrokerName(), endTimestamp - beginTimestampPrev, true, true);
}
exception = e;
continue; // 继续重试
} catch (MQBrokerException e) {
endTimestamp = System.currentTimeMillis();
// isolation=true, reachable=false:固定 10s 隔离,标记不可达
this.updateFaultItem(mq.getBrokerName(), endTimestamp - beginTimestampPrev, true, false);
exception = e;
if (this.defaultMQProducer.getRetryResponseCodes().contains(e.getResponseCode())) {
continue; // 特定错误码才重试
} else {
if (sendResult != null) {
return sendResult; // 上一次循环已经发成功过,返回那个结果
}
throw e; // 没有任何成功结果,才抛出
}
} catch (InterruptedException e) {
endTimestamp = System.currentTimeMillis();
// isolation=false, reachable=true:按耗时查表,但不影响这里直接抛出
this.updateFaultItem(mq.getBrokerName(), endTimestamp - beginTimestampPrev, false, true);
throw e; // 线程被中断,不重试,直接抛出
}把这四种异常的行为整理成一张表看会更清楚:
| 异常类型 | isolation | reachable | 是否重试 |
|---|---|---|---|
MQClientException |
false | true | 是,continue |
RemotingException(有探活线程) |
true | false | 是,continue |
RemotingException(无探活线程) |
true | true | 是,continue |
MQBrokerException(retryResponseCodes 内) |
true | false | 是,continue |
MQBrokerException(retryResponseCodes 外) |
true | false | 否,返回或抛出 |
InterruptedException |
false | true | 否,直接抛出 |
有几个细节值得单独说:
RemotingException** 的 reachable 取决于有没有探活线程。** 开启探活线程(isStartDetectorEnable())时,标记 reachable=false,让选队列的第二层过滤(reachableFilter)也把它排除掉,等探活线程探测到可达后才恢复。没有探活线程时,只能标记 reachable=true,因为没有线程来恢复它,标 false 会导致这个 Broker 永远选不到。
MQBrokerException** 不重试时,不是直接 throw。** 它先检查 if (sendResult != null)------如果上一次循环发成功过(拿到了 sendResult),就直接返回那个结果,而不是把这次的异常抛出去。只有从来没发成功过,才真正 throw。
InterruptedException** 也调了 updateFaultItem ,只是参数是 isolation=false, reachable=true。** 按耗时查表,< 550ms 通常不会产生隔离,不影响后续其他 Producer 的发送。
而FLUSH_DISK_TIMEOUT、FLUSH_SLAVE_TIMEOUT 这类状态码,消息其实已经到 Broker 了,只是持久化或同步有问题,此时要不要重试发到另一台 Broker,取决于 retryAnotherBrokerWhenNotStoreOK 开关(默认关闭),因为重试会导致消息重复。
故障规避:MQFaultStrategy 的三层降级
说完了重试,再说每次重试怎么选队列,这才是容错机制里最精巧的部分。
入口是 MQFaultStrategy.selectOneMessageQueue,根据是否开启 sendLatencyFaultEnable(默认关闭),走不同的路径。
未开启(默认行为):两层降级
java
// 第一优先:选不是 lastBrokerName 的队列
MessageQueue mq = tpInfo.selectOneMessageQueue(brokerFilter);
if (mq != null) return mq;
// 兜底:不过滤,轮询(宁可再选到失败的 Broker,也不能返回 null)
return tpInfo.selectOneMessageQueue();选队列的底层是一个 ThreadLocalIndex 计数器,每次 incrementAndGet() 然后对列表长度取模,实现轮询。BrokerFilter 就是把轮询到 lastBrokerName 的跳过,遍历一圈都满足不了就返回 null,触发兜底。
开启(生产环境推荐):三层降级
这时会维护一张 FaultItem 表,记录每个 Broker 的发送延迟和隔离状态:
java
class FaultItem {
private final String name; // Broker 名称
private volatile long currentLatency; // 最近一次发送耗时
private volatile long startTimestamp; // 隔离到期时间戳
private volatile boolean reachableFlag; // 探活线程判定是否可达
public boolean isAvailable() {
return System.currentTimeMillis() >= startTimestamp; // 隔离期过了就恢复
}
}选队列时三层依次降级:
java
// 第一层:选 available(隔离期已过)且不是上次失败 Broker 的队列
MessageQueue mq = tpInfo.selectOneMessageQueue(availableFilter, brokerFilter);
if (mq != null) return mq;
// 第二层:选 reachable(探活可达)且不是上次失败 Broker 的队列
mq = tpInfo.selectOneMessageQueue(reachableFilter, brokerFilter);
if (mq != null) return mq;
// 第三层:兜底,不过滤,随机轮询
return tpInfo.selectOneMessageQueue();第三层的存在很重要------就算所有 Broker 都在隔离期内,也要选一个出来发,否则消息就永远发不出去了。宁可碰壁再重试,不能直接放弃。
隔离时长是怎么算的
每次发送结束(无论成功还是失败),都会调用 updateFaultItem 记录这次发送的情况:
java
public void updateFaultItem(final String brokerName, final long currentLatency,
boolean isolation, final boolean reachable) {
if (this.sendLatencyFaultEnable) {
// isolation=true 时,固定用 10000ms 来查表,得到 10s 隔离时长
long duration = computeNotAvailableDuration(isolation ? 10000 : currentLatency);
this.latencyFaultTolerance.updateFaultItem(brokerName, currentLatency, duration, reachable);
}
}computeNotAvailableDuration 根据耗时查下面这张对应表:
java
// 耗时区间 隔离时长
// < 550ms → 0ms(不隔离)
// 550ms ~ 1.8s → 2000ms(隔 2 秒)
// 1.8s ~ 3s → 5000ms(隔 5 秒)
// 3s ~ 5s → 6000ms(隔 6 秒)
// 5s ~ 15s → 10000ms(隔 10 秒)
// ≥ 15s → 30000ms(隔 30 秒)
private long[] latencyMax = {50L, 100L, 550L, 1800L, 3000L, 5000L, 15000L};
private long[] notAvailableDuration = {0L, 0L, 0L, 2000L, 5000L, 6000L, 10000L, 30000L};发生网络异常或 Broker 异常时,isolation=true,固定传入 10000ms,查表得到 10s 的隔离时长,同时把 reachableFlag 置为 false。
这里有个细节:FaultItem.updateNotAvailableDuration 采用"只增不减"策略
java
public void updateNotAvailableDuration(long notAvailableDuration) {
// 新的隔离结束时间更晚,才覆盖;否则维持原有的隔离期
if (notAvailableDuration > 0 && System.currentTimeMillis() + notAvailableDuration > this.startTimestamp) {
this.startTimestamp = System.currentTimeMillis() + notAvailableDuration;
}
}假设一个 Broker 被判定隔离 30 秒,30 秒内又来了一次耗时 200ms 的成功请求,查表得 0ms,不会把 30 秒的隔离提前解除。这防止了偶发成功把正确的隔离状态破坏掉。
resetIndex:随机打散重试起点
最后一个细节:重试循环里的 resetIndex。
第一次发送时 resetIndex=false,正常递增轮询;重试时 resetIndex=true,会先调用 tpInfo.resetIndex(),它的实现是:
java
// TopicPublishInfo.resetIndex()
public void resetIndex() {
this.sendWhichQueue.reset();
}
// ThreadLocalIndex.reset()
public void reset() {
int index = Math.abs(random.nextInt(Integer.MAX_VALUE));
this.threadLocalIndex.set(index); // 随机设置一个新起点
}注意,这里不是把计数器归零、从队列头部重新开始,而是随机设置一个新的起点 。下次 incrementAndGet() 会在这个随机值的基础上 +1,再对队列数取模,选到哪个位置完全是随机的。
为什么是随机而不是归零?想象一下多线程并发发送都遇到了失败,如果都 reset 到 0,所有线程下次都从队列第 0 位开始遍历,很可能同时打到同一个队列,造成瞬时热点。随机化可以把重试流量打散到不同队列上,负载更均匀。
当然,即便 reset 后随机到的起点碰巧还是落在失败 Broker 的队列上,BrokerFilter 也会把它跳过,遍历一圈直到找到另一个 Broker 的队列------或者实在找不到,触发兜底的无过滤轮询。所以 reset 的目的是"打散",过滤逻辑才是真正的"规避"。
把整条 Producer 容错链路串起来就是:
plain
发消息
└─ tryToFindTopicPublishInfo
├─ 本地缓存命中 → 直接用
├─ 缓存没有 → 立即去 NameServer 拉一次
└─ NameServer 也没有 → 用默认 Topic(TBW102)路由兜底(Topic 自动创建入口)
└─ for (times = 0; times < 1 + retryTimes; times++) // SYNC 默认共 3 次,ASYNC/ONEWAY 只有 1 次
│
├─ [times > 0] resetIndex → ThreadLocalIndex.reset() 随机设置新起点,打散并发重试热点
│
├─ selectOneMessageQueue(lastBrokerName, resetIndex)
│ └─ MQFaultStrategy
│ ├─ [sendLatencyFaultEnable=false,默认]
│ │ ├─ BrokerFilter:跳过 lastBrokerName 的队列
│ │ └─ 兜底:无过滤轮询
│ └─ [sendLatencyFaultEnable=true]
│ ├─ availableFilter + BrokerFilter:隔离期已过 且 非上次失败 Broker
│ ├─ reachableFilter + BrokerFilter:探活可达 且 非上次失败 Broker
│ └─ 兜底:无过滤轮询(宁可碰壁,不能返回 null)
│
├─ sendKernelImpl(实际网络发送)
│
└─ 发送结果处理
├─ 成功(SEND_OK)
│ └─ updateFaultItem(isolation=false, reachable=true) → 按耗时查表,< 550ms 不隔离
│
├─ MQClientException
│ └─ updateFaultItem(isolation=false, reachable=true) → continue 重试
│
├─ RemotingException
│ ├─ [有探活线程] updateFaultItem(isolation=true, reachable=false) → 固定 10s 隔离,标记不可达
│ ├─ [无探活线程] updateFaultItem(isolation=true, reachable=true) → 固定 10s 隔离,不标不可达
│ └─ continue 重试
│
├─ MQBrokerException
│ ├─ updateFaultItem(isolation=true, reachable=false) → 固定 10s 隔离,标记不可达
│ ├─ [错误码在 retryResponseCodes 内] → continue 重试
│ └─ [错误码不在] → 有 sendResult 则返回,否则 throw
│
└─ InterruptedException
└─ updateFaultItem(isolation=false, reachable=true) → 直接 throw,不重试一句话总结 :路由缓存保证 NameServer 抖动时 Producer 不受影响;重试循环保证单次发送失败有机会补救;resetIndex 打散并发重试热点,BrokerFilter 规避已失败的 Broker,FaultItem 隔离持续故障的节点。三层机制合在一起,才撑起了 Producer 侧的高可用。
最后
NameServer 的设计,说白了就是一个字:省。
省掉了分布式协议,省掉了节点间通信,省掉了选主逻辑。它只做一件事:存路由表,提供查询。
复杂性被分摊到了 Broker(主动上报心跳)和客户端(本地缓存、自动重试、故障切换)两端去承担。
这种设计不是偷懒,而是一种经过取舍的务实选择。在消息中间件这个场景下,注册中心的短暂数据延迟,比引入复杂的一致性协议带来的工程代价,代价要小得多。
理解了这一点,也就理解了 RocketMQ 整体设计里的一种思维方式:把复杂性放在最值得放的地方,其余的尽量简单。