背景
本人一直在做会议系统相关的内容,但我们自己的会议模块里,之前一直缺少一个比较完整的自动会议纪要能力。这个功能其实并不新。像钉钉、飞书、腾讯会议这类成熟会议产品,早在几年前就已经上线了 AI 会议纪要。我们去年也曾经排过相关计划,但因为业务需求一直在迭代,我个人手上的事情也比较多,最终这个功能就暂时搁置了下来。最近的一次发版之后,有了空余时间,遂研究了一番。
目前已经初步实现了这样的功能,虽然和大厂的产品还有差距,但也算是跑通了的mvp,这篇文章主要记录一下这次AI会议纪要的实现过程。这篇文章主要是从需求出发,到整体实现,最终的效果放到了结尾,最后会说明一下后续会向哪个方向继续拓展。
技术栈: langchain4j + milvus + qwen的embedding模型 + deepseek的chat模型
需求
首先,我们进行需求整理。
会议纪要的本质是,中途入会时,或者会议结束后用户不想翻找几个小时的会议的上下文、语音转写等各种信息,所以我们需要提供一种结构化的能力,可以让用户知道这场会议的核心内容,包括摘要 、结论要点 、待办 、风险点 、 发言统计等内容。
那么会议纪要信息的来源就可以是:
- 会议基本信息
- 语音转写、字幕
- 人员信息
- 会议描述,如果会议创建时填写了说明,那么需要作为AI总结上下文
其中最为核心的其实就是语音转录的内容,对话内容作为会议最重要的资产,语音转录就是会议纪要的主要来源,会议纪要应该从中分析出我们要的结构化的结果。
经过分析,由字幕转录出的会议纪要会存在以下问题:
- 内容可能很长,比如三到四个小时的会议,字幕数很容易达到上千。
- 字幕是口语化的,中间由插话、重复、停顿、上下文跳跃。
很明显,针对于长会议,我们无法一次将所有的内容直接发给大模型,而是要拆成多个chunk,于是我们可以参考langchain的 mapReduceDocument来解决这个问题
MapReduce
MapReduce 这个词听起来可能比较像大数据里的概念,但放到 AI 会议纪要这里,其实很好理解。
我们可以把一场长会议看成一篇非常长的文档。如果这个文档很短,那么直接交给大模型总结就可以。但是如果这个文档非常长,比如一场会议持续一两个小时,字幕有上千条,那么直接把全部内容塞给大模型就会遇到几个问题:
- 上下文长度可能不够。
- 单次请求 token 太多,响应时间会很长。
- 请求失败以后重试成本很高。
- 模型容易关注后半段内容,遗漏中间的议题。
- 即使模型能处理,也不一定能保证每个阶段的信息都被总结到。
所以我们需要先把长会议拆成多个小片段,每个小片段单独总结,最后再把这些小片段的总结合并成一份完整纪要。
这就是 MapReduce 的基本思路。
简单来说:
- Map:把长会议拆成多个 chunk,每个 chunk 单独生成摘要
- Reduce:把所有 chunk 的摘要合并,再生成最终会议纪要
对应到会议纪要就是:
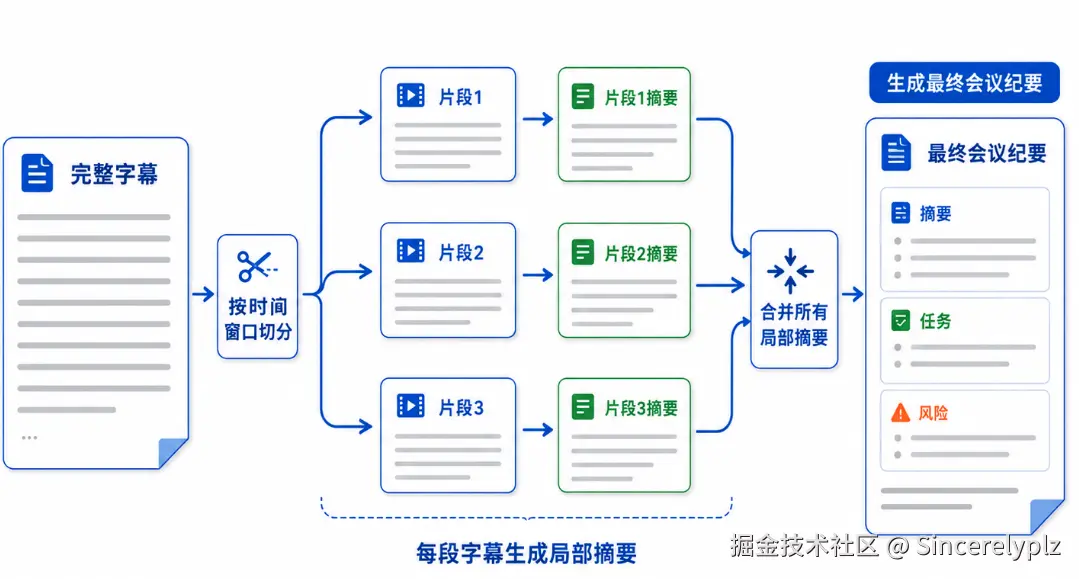
这里我们没有直接使用 LangChain 的 MapReduceDocumentsChain,但整体思路是一致的。LangChain 里的 MapReduceDocumentsChain 本质上也是先对多个 document 分别执行 llm_chain,然后再把 map 的结果交给 reduce chain 做最终汇总。
官方文档里对这个类的描述是:
Combining documents by mapping a chain over them, then combining results.
也就是先 map,再 reduce。
放到我们的场景里,可以这样对应:
LangChain 概念 AI 会议纪要里的实现 Document 一段会议字幕 chunk map chain 对单个字幕 chunk 生成局部摘要 reduce chain 汇总所有局部摘要生成最终纪要 recursive reduce 超长会议时分层合并 metadata 会议标题、成员、时间、字幕行号 这里有一个细节,会议字幕的切分不能只按字符数切。
因为会议是有时间线的,用户后面查看关联发言、章节时间线、任务来源时,都需要回到原始发言的时间点。所以我们更适合按照时间窗口切,比如每 8 分钟作为一个 chunk,并且在相邻 chunk 之间保留一点 overlap。
保留 overlap 是为了避免一句话刚好被切在两个 chunk 中间。
比如:
makefile
00:07:58 张三:这个接口如果周五前还没联调完
00:08:02 李四:就会影响下周验收如果严格按 8 分钟切,第一句话在前一个 chunk,第二句话在后一个 chunk,模型在总结单个 chunk 时可能就无法理解完整语义。
所以切分时需要保留一小段重叠内容,让上下文不要断得太生硬。
第一版实现时,整个生成流程大概是这样:
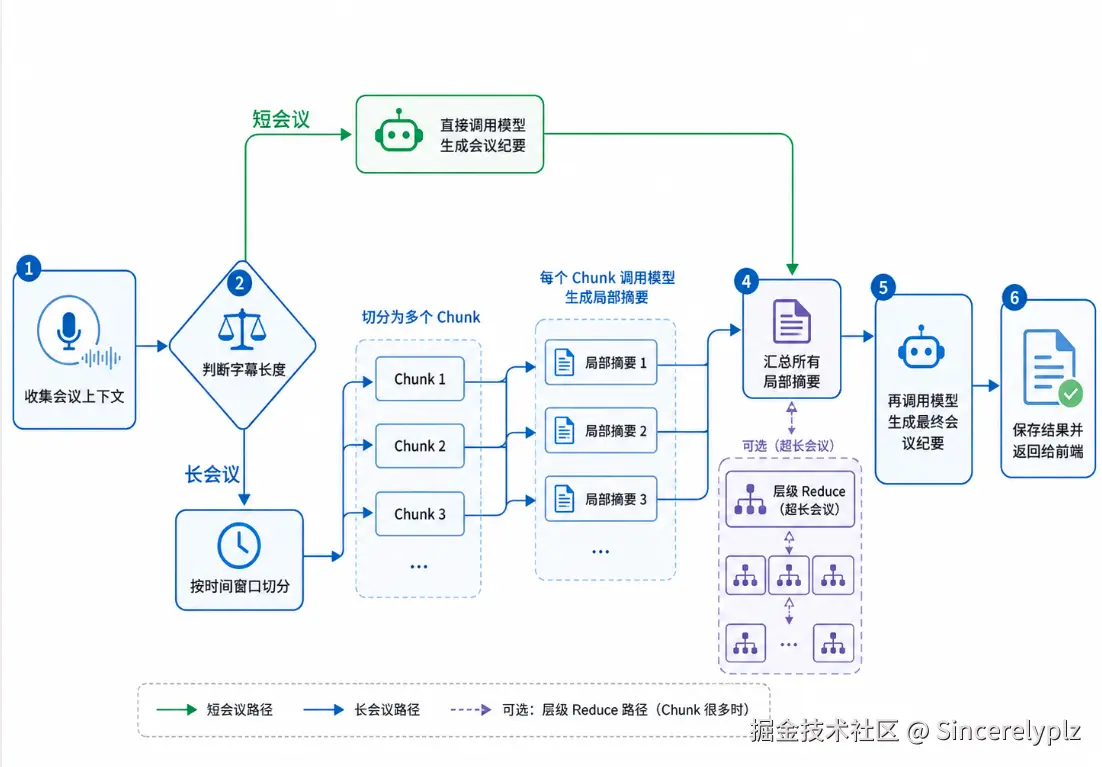
比如有 40 个 chunk,如果直接把 40 个 chunk 的摘要全部交给最终 Reduce,仍然可能太长。这时可以先每 8 个摘要合并一次,得到 5 个中间摘要,然后再用这 5 个中间摘要生成最终纪要。
也就是:
rust
40 个 chunk
-> 40 个局部摘要
-> 每 8 个合并成 1 个中间摘要
-> 5 个中间摘要
-> 最终会议纪要这样做的好处是,每一步输入都在可控范围内,失败以后也可以只重试某一段,而不是整场会议全部重来。
当然,MapReduce 也不是没有问题。
它最大的问题是:Map 阶段已经做了一次压缩,压缩以后很多细节可能会丢失。
比如原始字幕里有这样几句话:
- 张三:这个接口现在还没有联调。
- 李四:如果周五前没有完成,会影响下周验收。
- 王五:那这个风险先记录下来,我来跟进。
Map 阶段可能总结成:讨论了接口联调延期可能影响验收的问题,并安排人员跟进。
这个摘要作为最终纪要的一部分是够用的,但如果用户想知道"是谁说的 ""原话是什么 ""风险是怎么得出来的",尤其是第一个chunk中的结论,可能在第三个chunk中就被推翻了,只靠这个摘要就不够了。这也是后面要引入 RAG 的原因。
引入RAG
其实我一开始并不想把会议纪要做的很重,如果引入向量库,其实是将问题变的更加复杂了,需要调用的东西很多,很影响实时输出的等待时间。但是考虑到会议中的对话的字幕作为会议核心资产,后续肯定需要将其纳入向量库中,所以故此,直接先做一部分rag,可以将其作为证据补充。
而且引入向量库也有一个好处,就是将rag中召回的内容一起丢给大模型,这样可以让大模型输出的结论是有证据可依靠的,一定程度上解决模型的幻觉问题。
prompt中添加输出管理?
引发一个问题,为什么不直接在提示词中说明,需要指出对应的结论的原文,这样是不是就不需要rag?
这个方案在短会议里是可行的。因为短会议的字幕可以完整放进上下文,模型确实有机会一边总结,一边引用原文。
但一旦会议变长,这个方案就会遇到几个问题。
- MapReduce 之后,Reduce 阶段看到的不是原始字幕,而是 Map 阶段生成的摘要。
也就是说,长会议最终生成纪要时,模型手里已经没有完整原文了。它只能基于分片摘要生成最终结果。
如果原始字幕没有进入最终 Reduce prompt,那么即使你要求模型"给出原文",它也只能引用 Map 摘要里的内容,甚至可能凭印象补一段看起来像原文的话。
这时所谓的"原文依据"就不是真正的原文,而是模型加工后的二手内容。
- 就算把原始字幕都放进 prompt,模型也不一定能稳定引用准确行号。
模型擅长概括,但不擅长做严格的索引定位。尤其是字幕有几百条、上千条时,它可能引用错行、漏行,或者把多个人的发言混在一起。尤其是我们要做的是溯源,这要求我们的溯源的准确度应该很高,而不是依靠模型。
- 关联补充可能发生在生成之后
在第一个小时生成的内容,可能在第二个小时也有人进行补充,新的发言也应该作为关联,关联到第一个小时的结论中去。
会议纪要生成的数据流转
会议纪要的触发时机是用户手动点击生成,或者会议结束后自动触发,后端首先会进入生成主链路。
于是我们可以产出一个这样的数据链路图(以下这个图是chatgpt-image2生成的)
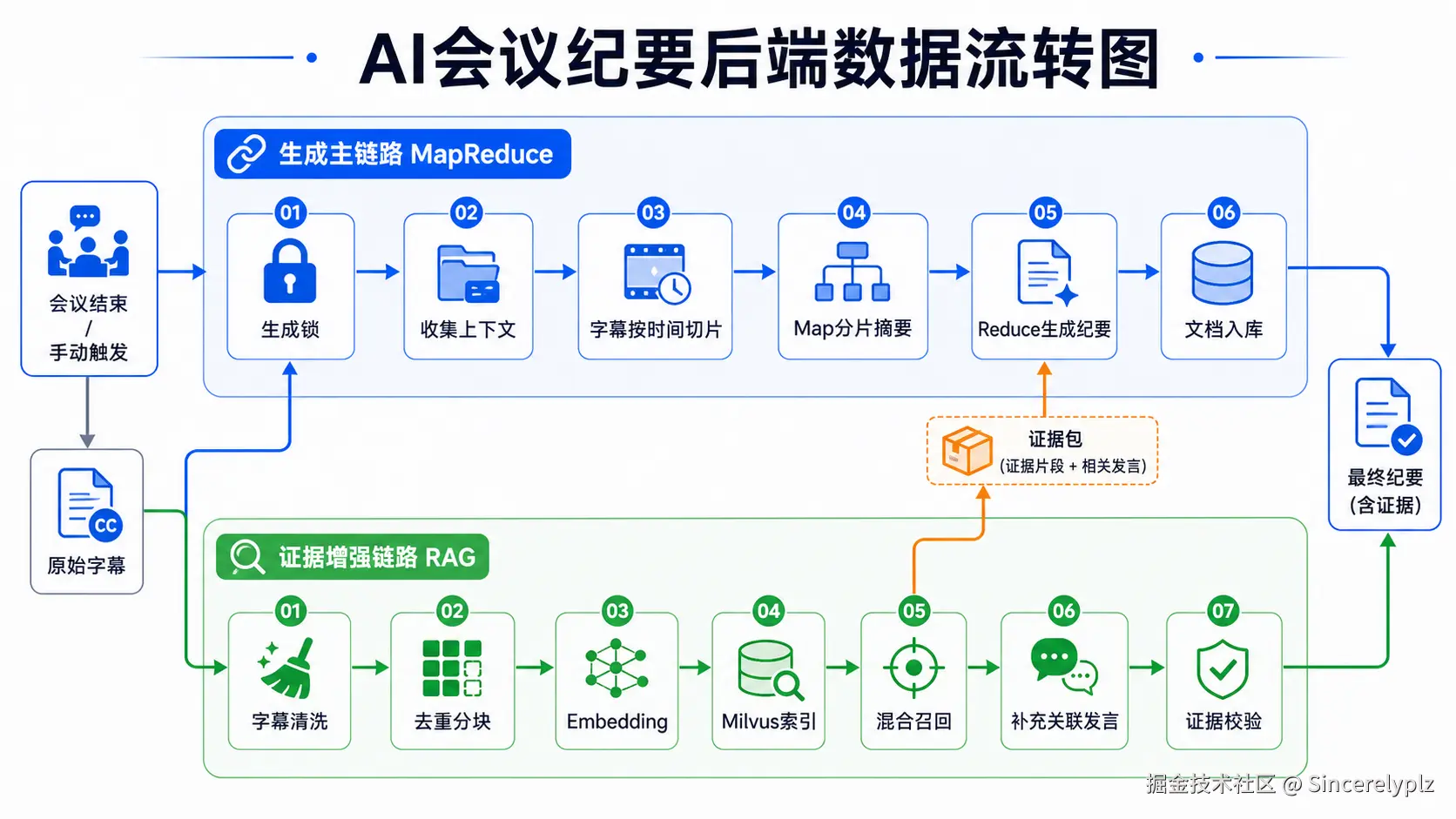
我们按照这个图进行讲解:
加锁
这个锁主要是为了避免同一场会议被重复生成。比如用户连续点击多次生成,或者会议结束后自动任务和手动生成同时触发,如果没有锁,就可能出现多个生成任务同时跑,最后互相覆盖结果。
上下文查询
拿到锁以后,后端会收集上下文。
上下文主要包括:
- 会议基础信息。
- 会议成员。
- 原始字幕。
- 会议说明。
- 已有的会议文档内容。
这里最重要的还是原始字幕。 因为 AI 会议纪要的主要信息来源就是字幕。会议标题、成员、说明这些更多是辅助上下文,用来帮助模型知道这场会议的背景。
上下文收集完成后,系统会判断会议长度。 如果会议比较短,就可以直接把完整字幕交给模型生成。 如果会议比较长,就进入 MapReduce。
切片
这里按时间切片,而不是简单按字符数切,是因为会议天然有时间线。后续无论是章节时间线,还是关联发言定位,都依赖原始字幕的时间信息。 每个切片会先独立生成一个分片摘要。 这些分片摘要再进入 Reduce,生成最终会议纪要。 如果切片数量特别多,还可以继续做层级 Reduce。也就是先把多个分片摘要合并成中间摘要,再用中间摘要生成最终纪要。 这样可以避免最终 Reduce 阶段输入过长。
字幕清洗与去重
前面这里的清洗不是音频识别,也不是用模型判断哪里有音乐、噪音或者听不清。后端拿到的已经是转写文本,所以清洗主要是做文本规范化。比如 空白处理 、 重复标点压缩 、 低价值短句过滤 、 显式噪音标记兼容清理。去重是为了减少重复内容进入索引。
分块
清洗之后,下一步是分块。
为什么不直接把每一条字幕作为一个向量存进去?
因为单条字幕通常太短,很多语义是不完整的。
比如:
- 张三:这个接口现在还没联调。
- 李四:如果周五前没完成,会影响验收。
- 王五:那我这边先把风险记录下来。
如果单独看每一句,它们的信息都不完整。
- 第一句只说接口没联调。
- 第二句说会影响验收,但不一定知道是什么没完成。
- 第三句说记录风险,但不知道是什么风险。
所以更合理的方式是把相邻字幕组成一个 chunk,让它保留一段上下文。
一个 chunk 可能长这样:
- 张三 10:05 这个接口现在还没联调。
- 李四 10:08 如果周五前没完成,会影响验收。
- 王五 10:12 那我这边先把风险记录下来。
这样做 embedding 的时候,模型看到的是一段完整上下文,而不是孤立的一句话。
分块时主要考虑几个因素:
- 最大字符数:避免 chunk 太长。
- 时间间隔:如果两句话间隔很久,可能已经换话题了。
- 语义转场:比如"接下来""下面看下一个问题"。
- overlap:让相邻 chunk 有一点重叠,避免上下文被切断。
这里的 overlap 和前面 MapReduce 的 overlap 类似,都是为了解决边界问题。
证据补充:一定程度上解决模型幻觉问题
这里注意的是,向量库并不是在最终结果生成后才补充关联数据!!
在 Reduce 生成最终纪要之前,RAG 链路可以先构建一个证据包。这个证据包里会包含一些和会议重点相关的原始字幕片段,比如:任务相关发言、 风险相关发言、 决策相关发言、 未决问题相关发言、 章节主题相关发言。
然后这个证据包会被放进 Reduce prompt 里。 这样最终生成纪要时,模型看到的不只是 Map 阶段压缩后的分片摘要,还能看到一部分原始证据。这样的好处是,最终合并的结果,模型获取的数据一定参考了字幕中的实际数据。 这对长会议很重要。 因为 Map 摘要是压缩过的,压缩以后细节可能会丢。RAG 证据包可以把一部分关键原文重新补回 Reduce 阶段。
输出
最后的reduce阶段,将多个chunk的结论进行汇总,并且结合rag中获取的证据包,总结出整场会议的会议纪要,并且使用流式输出。
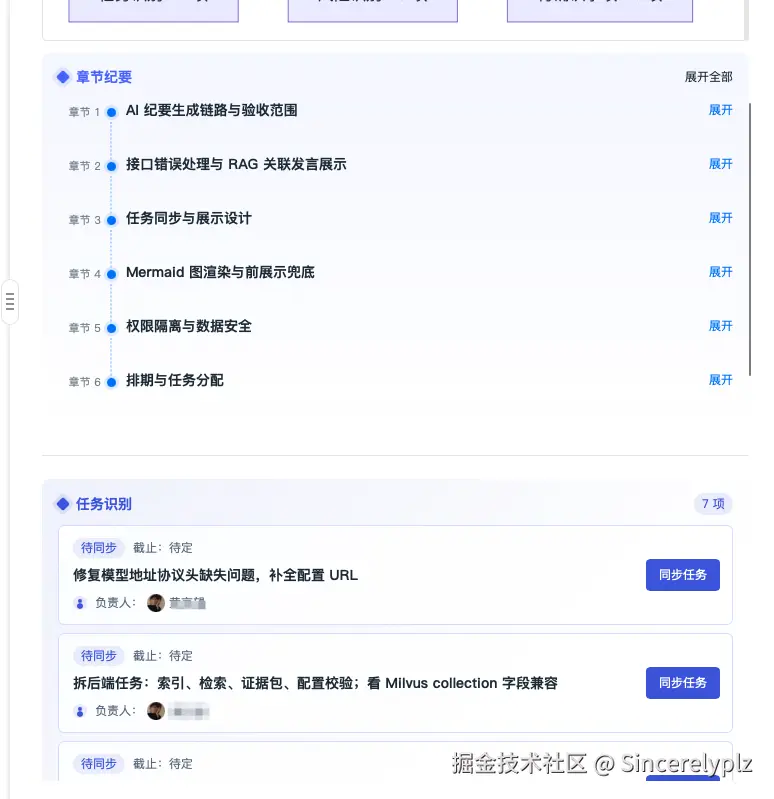
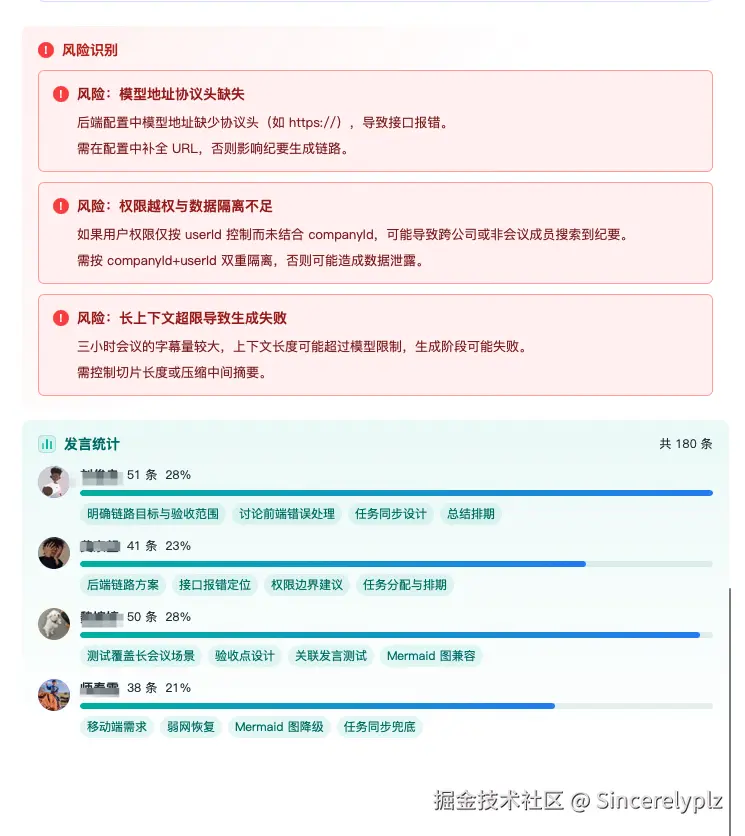
结构化输出
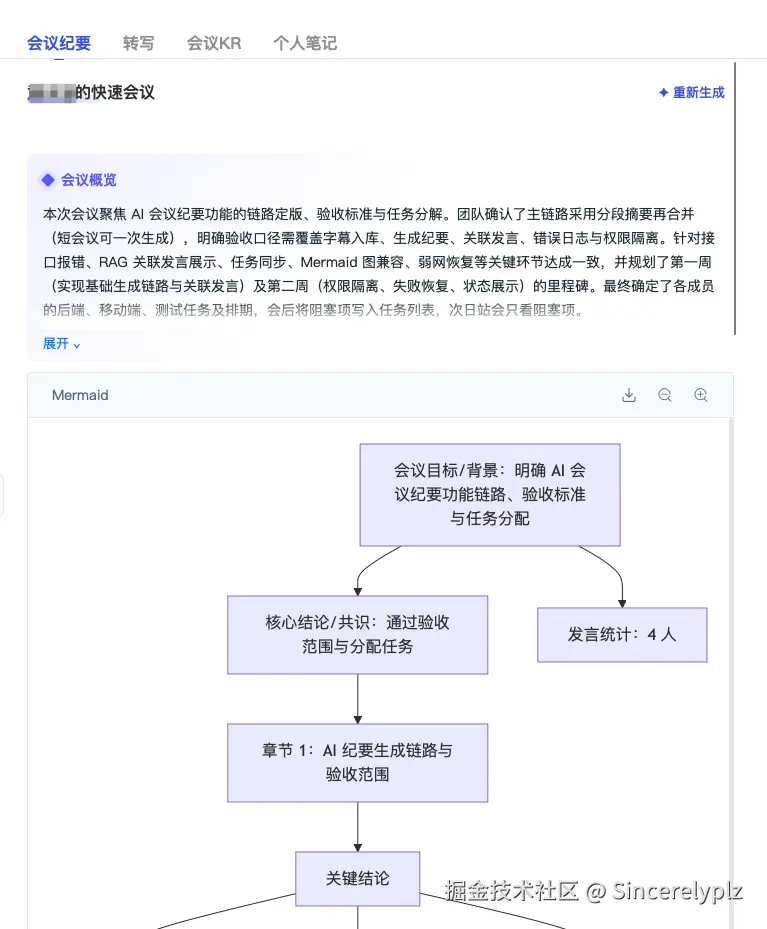
后端输出的是 Markdown 格式的流式内容,前端则用我们产品内部的文档库来承载最终纪要。
这一点比较省事的是,我们的文档库本身支持把 Markdown 转成内部文档格式。所以前端可以先把流式 Markdown 展示出来,让用户看到内容正在生成;等生成完成后,再把其中的摘要、任务、风险、关联发言等内容转换成自定义卡片,最终形成结构化的会议纪要。(大家不要觉得丑,这个是我自己验证的页面,设计,前端都是我自己做的,手动狗头)
下一步计划
目前的效果仅仅是达到了基本的效果。后期还有很多考虑的重点。
声纹识别
语音转录作为纪要的核心数据,需要提高准确度,并且可以尽量分清人员,所以声纹识别就变的很重要,但是目前我们还不支持声纹识别,我们使用的aliyun的百炼模型,准确度还可以,但是在多人同麦的情况下不能区分人员,后续需要找到可以声纹识别的厂商或者方案。
生成结果有待优化
目前的实现,虽然结论有有据可依,但是每次生成的结果都不一样,比如有时会将多个风险合并为一个风险,有时也会将一个任务拆成多个任务,如何约束也有待优化。
其他模块联动
相比与其他产品,我直接设计了任务模块,可以在会议纪要这里直接创建任务,但是任务的联动性不足,比如是否结合此人的历史任务记录,未来的排期计划,来推算任务的时间,任务的负责人,优先级,这都是需要考虑的内容。
总结
其实在做这个之前,rag的相关文章已经看了不少,但是实际做了一遍之后,才能对其中的很多概念深入了解,本文中其实有很多东西也没有过于详细的去说明,比如我还用到了召回,重排之类的,更多的是思路上的一些总结。这次做的ai会议纪要,个人认为还是比较粗糙的,后续也将不断优化。