MyBatisPlus入门案例与简介
MybatisPlus(简称MP)是基于MyBatis框架基础上开发的增强型工具,旨在简化开发、提高效率。
整合快速实现与映射链条
把SpringBoot整合MyBatisPlus来快速实现下,具体的实现步骤为:
1. 创建SpringBoot工程
创建SpringBoot项目 mybatisplus_01_quickstart
勾选配置使用技术:在Spring Initializr的依赖选择页面,搜索并勾选:
- Spring Web - Web应用开发
- MySQL Driver - MySQL数据库驱动
- Lombok - 代码简化工具(重要)
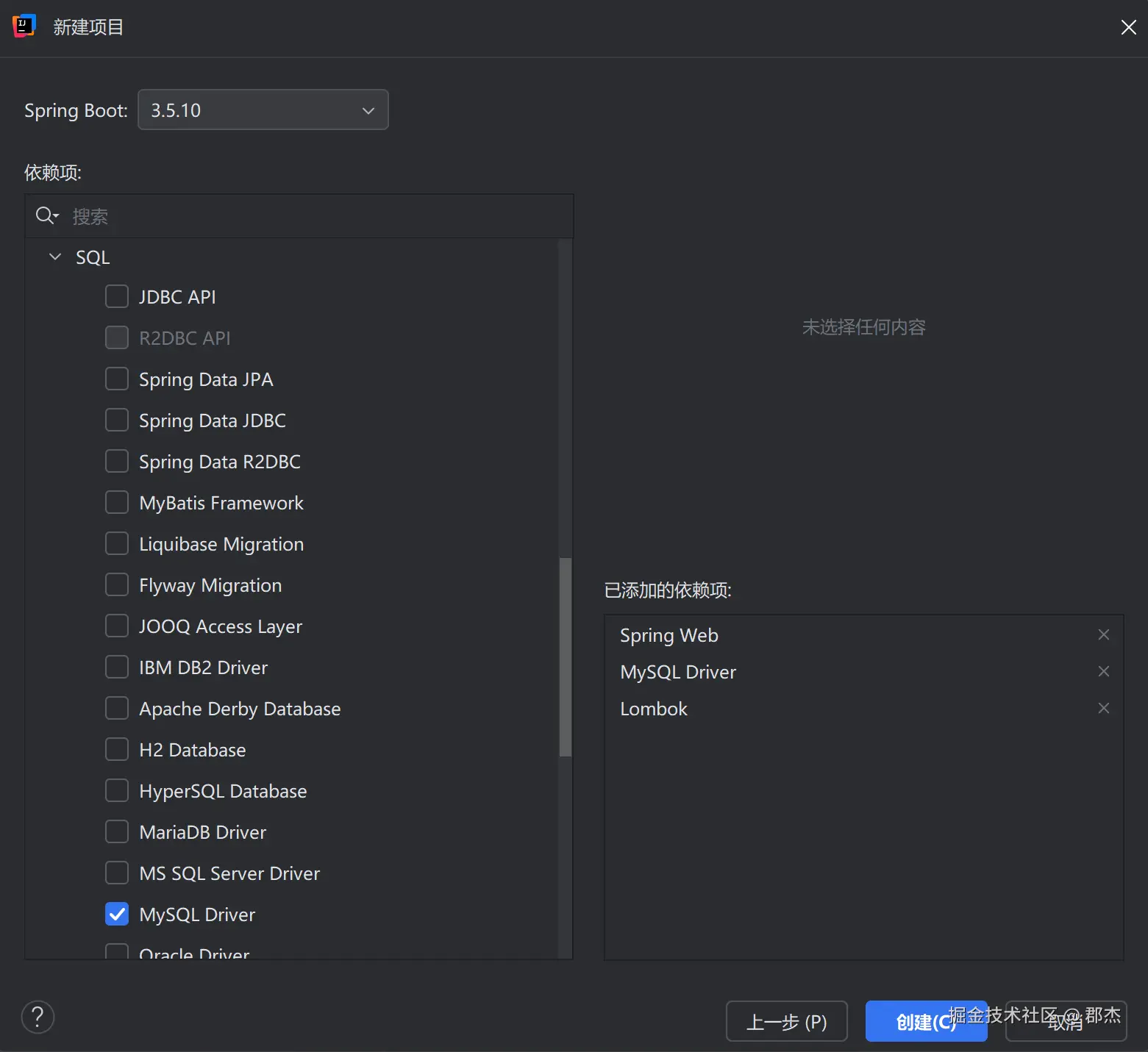
注意:MyBatisPlus未在官方依赖列表中,需后续手动添加。
2. 创建数据库及表
这里演示在IDEA Database工具中创建。
一、打开并配置Database工具
- 找到Database工具窗口
- 在IDEA中项目界面的最右侧边缘 ,找到并点击 "Database" 这个标签页(图标通常是一个圆柱形)。
- 建立一个新的数据库连接
- 在打开的"Database(数据库)"工具窗口的左上角,点击 + 号。
- 在弹出的菜单中,将鼠标移到 "Data Source(数据源)" 上。
- 在二级菜单里,找到并点击 "MySQL"。
- 填写数据库连接信息
- 此时会弹出一个新窗口 "Data Sources and Drivers(数据源与驱动程序)"。
- 在 "General(常规)" 标签页下,填写以下信息(请对照下图理解):
- Host(主机) :用鼠标点击输入框,输入
localhost - Port(端口) :输入
3306 - User(用户) :输入
root(这是最常见的默认用户名,如果你安装MySQL时改了别的,就输入你改的那个) - Password(密码) :用鼠标点击密码框,输入你安装MySQL时为
root用户设置的密码。 - Database(数据库) :这一栏先留空不填,我们稍后再指定。
- Host(主机) :用鼠标点击输入框,输入
- 点击 "Test Connection(测试连接)" 。
- 成功标志 :几秒钟后,你会看到一个绿色的提示框,写着 "Succeeded(成功)",并且出现绿色的对勾 ✅。
- 失败怎么办:如果失败(出现红色错误),检查MySQL服务是否启动,以及用户名密码是否正确。
- 应用并完成连接
- 测试连接成功后,点击窗口右下角的 "OK(确定)" 或 "Apply(应用)" 按钮。
完成以上步骤后,应该能在左侧的"Database"窗口看到一个名为 localhost 的新连接。
二、执行SQL创建库和表
现在,我们开始创建具体的数据库和表。
- 打开SQL执行窗口
- 在左侧Database面板,找到刚刚建立的
localhost连接。 - 用鼠标右键点击 这个连接的名字。
- 在弹出的右键菜单中,选择 "New(新建)" → "Query Console(查询控制台)"。
- 粘贴并执行SQL脚本
-
一个空白的SQL文件(通常是
console_1.sql)会在编辑区打开。 -
将以下完整的SQL代码全部选中并复制 ,然后粘贴 到这个空白文件中:
sqlcreate database if not exists mybatisplus_db character set utf8; use mybatisplus_db; CREATE TABLE user ( id bigint(20) primary key auto_increment, name varchar(32) not null, password varchar(32) not null, age int(3) not null , tel varchar(32) not null ); insert into user values(1,'Tom','tom',3,'18866668888'); insert into user values(2,'Jerry','jerry',4,'16688886666'); insert into user values(3,'Jock','123456',41,'18812345678'); insert into user values(4,'传智播客','itcast',15,'4006184000'); -
如何执行 :
- 方法一(推荐) :用鼠标选中所有SQL语句 (可以从头拖到尾),然后按下键盘快捷键
Ctrl + Enter(Windows) 。 - 方法二 :同样选中所有语句,然后在选中区域点击鼠标右键 ,选择 "Execute(执行)"。
- 方法一(推荐) :用鼠标选中所有SQL语句 (可以从头拖到尾),然后按下键盘快捷键
- 查看执行结果
- 执行成功后,在编辑器下方会弹出窗口。
- 你会看到每条SQL语句后面都跟着文字提示,比如
[2024-XX-XX XX:XX:XX] Completed in X ms,表示执行成功。 - 如果某条语句出错,会有红色错误信息,请检查SQL是否有拼写错误。
三、验证表是否创建成功
- 刷新并查看数据库
- 回到左侧的"Database"工具窗口。
- 找到
localhost连接,点击它左边的>图标展开。 - 你应该能看到一个名为
mybatisplus_db的数据库。如果没看到,在空白处点击鼠标右键 ,选择 "Refresh All(全部刷新)"。 - 点击展开
mybatisplus_db,再展开其下的 "Tables(表)" 目录。
- 查看表格数据
- 现在你应该能看到
user表了。 - 用鼠标双击
user这个表的名字。 - 一个新的标签页会在编辑区打开,里面会以表格的形式展示你刚刚插入的4条数据。这样就大功告成了!
3. pom.xml补全依赖
在项目的pom.xml文件中添加以下依赖:
xml
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
<!-- Druid连接池(可选) -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid-spring-boot-starter</artifactId>
<version>1.2.8</version>
</dependency>修改后要点击"同步 Maven 更改"图标。
依赖说明:
mybatis-plus-boot-starter已包含MyBatis、MyBatis-Spring等必要依赖- Druid是高性能数据库连接池,如不使用,SpringBoot会使用默认的HikariCP
4. 配置application.yml
resources中默认生成的是properties配置文件,可以创建一个yml文件替代它,并在文件中配置数据库连接的相关信息,application.yml:
yml
spring:
datasource:
# 使用Druid
type: com.alibaba.druid.pool.DruidDataSource # 如果不使用Druid,删除type配置即可
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatisplus_db?serverTimezone=Asia/Shanghai&characterEncoding=utf8&useSSL=false
username: root
password: 你的密码 # 替换为实际密码
# Druid连接池配置(可选)
druid:
initial-size: 5
min-idle: 5
max-active: 20
max-wait: 60000
# MyBatisPlus配置
mybatis-plus:
configuration:
# 控制台打印SQL日志(开发环境建议开启)
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
serverTimezone=Asia/Shanghai避免时区问题useSSL=false开发环境禁用SSL连接- 记得将
password替换为自己的MySQL密码
可选优化:减少日志输出
一、问题分析
测试运行时,控制台输出大量日志,主要包含:
- SpringBoot启动时的INFO日志
- MyBatisPlus启动图标(ASCII艺术字)
- SpringBoot启动图标(ASCII艺术字)
这些日志会影响查看核心的运行结果和SQL语句。
二、解决操作
- 取消Spring初始化日志
在 src/main/resources/ 目录下创建 logback.xml 文件
xml
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
</configuration>说明:
- 空的
logback.xml会覆盖SpringBoot默认的日志配置(优先级高),以减少启动时的INFO日志输出。- 使用空的
logback.xml,可能会使application.yml中配置的log-impl(SQL日志) 失效,意外关闭 SQL 日志。
- 关闭SpringBoot、MyBatisPlus启动图标
修改 application.yml 文件
yaml
# 数据库配置
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatisplus_db?serverTimezone=UTC
username: root
password: root
main:
banner-mode: off # 关闭SpringBoot启动图标
# MyBatisPlus配置
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl
global-config:
banner: off # 关闭MyBatisPlus启动图标三、重要说明
- 选择性优化:这些操作是可选的,不影响程序功能
- 关键日志保留:仍然保留了SQL执行日志,便于调试
- 开发阶段建议 :
- 调试时:保持当前配置,便于查看SQL
- 生产环境:应关闭SQL日志(移除
log-impl配置)
5. 创建实体类(建立 实体类↔表 映射)
com.itheima.domain(顶级包.实体类包)包下创建实体类:
java
// 1. 引入必要的 Lombok 注解
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.AllArgsConstructor;
// 2. 在类上使用注解,指令Lombok生成代码
@Data // 核心注解:生成getter, setter, toString, equals, hashCode
@NoArgsConstructor // 生成无参构造器(MyBatis等框架反射创建对象时需要)
@AllArgsConstructor // 生成全参构造器(方便测试)
public class User {
private Long id;
private String name;
private String password;
private Integer age;
private String tel;
}实体类与数据库表的映射关系:
- 类(Object) ↔ 表(Table) :默认情况下,MyBatisPlus 会根据实体类名
User映射到数据库的(转小写)user表。也可以用@TableName("表名")注解自定义,写在类声明的上一行,显式指定此类映射到数据库中的哪个表。 - 对象 (Object) ↔ 记录/行 (Row) :一个
User对象(包含多个字段属性)对应数据库user表中的一行记录。 - 属性 (Field) ↔ 列 (Column) :默认将属性名(如
Name)转换为小写(name)或下划线形式(可选,若属性是驼峰:userName↔user_name)来匹配列名。也可用@TableField("列名")注解自定义,写在字段声明的上一行,显式指定此字段映射到数据库中的哪个列。 - 方法调用 (Method) ↔ SQL :当你在测试类调用
userDao.insert(userObject)时,MyBatisPlus 会根据上述映射关系,自动生成INSERT INTO user (name, age, ...) VALUES (?, ?, ...)这样的 SQL 语句,并将userObject的属性值作为参数填入。
6. 创建Mapper接口(建立 接口↔实体类 绑定)
com.itheima.dao(顶级包.Mapper接口包)包下创建Mapper接口:
java
@Mapper // 标记为MyBatis的Mapper,会被Spring扫描到
public interface UserDao extends BaseMapper<User>{
// 无需编写任何方法,BaseMapper已提供基础的CRUD方法
// 包括:insert, deleteById, updateById, selectById, selectList等
}- 其中
BaseMapper<T>,T是要操作的实体类名。
含义 :显式声明这个UserDao接口的职责是专门操作User这个实体类对应的数据库表 。User就是项目中的那个实体类(User.java)。
BaseMapper提供的主要方法:
int insert(T entity)- 插入int deleteById(Serializable id)- 根据ID删除int updateById(T entity)- 根据ID更新T selectById(Serializable id)- 根据ID查询List<T> selectList(Wrapper<T> queryWrapper)- 条件查询- 更多方法查看BaseMapper源码
7. 配置启动类(生成代理对象 接口→Spring Bean)
com.itheima(顶级包)包下创建启动类:
java
@SpringBootApplication
// 使用@MapperScan批量扫描Mapper接口,生成接口的代理对象SpringBean
@MapperScan("com.itheima.dao")
public class Mybatisplus01QuickstartApplication {
// 固定写法:
// 以 Mybatisplus01QuickstartApplication 这个类作为配置核心,启动一个内嵌了Web服务器的、具有完整功能的Spring应用,并使其持续运行,等待处理请求。
public static void main(String[] args) {
SpringApplication.run(Mybatisplus01QuickstartApplication.class, args);
}
}Mapper扫描方式对比:
方式 优点 缺点 @Mapper注解直观,每个接口独立标注 每个Mapper接口都需要添加注解 @MapperScan批量扫描,一劳永逸 需要确保包路径正确
8. 编写测试类(使用时调用完整映射链条)
text下的com.itheima(与主启动类相同的逻辑包)包下创建测试类:
java
@SpringBootTest // 标记为SpringBoot测试类
class MpDemoApplicationTests {
@Autowired
private UserDao userDao; // 获取 Mapper接口实例
@Test
public void testGetAll() {
// 查询所有用户(null表示无条件)
List<User> userList = userDao.selectList(null);
System.out.println(userList);
}
}映射链条说明:
List<User> userList = userDao.selectList(null);
表面:调用Java方法
背后发生的映射链条:
- 用户自定义 Mapper 接口 调用方法:userDao.selectList(null)
→ MP 框架提供的通用 Mapper 父接口 调用方法:BaseMapper<User>.selectList(null) - BaseMapper的泛型是User
→ 找到User类映射的表user(@TableName("user")或 默认user表) - 扫描User类中所有属性(字段)
→ 找到所有需要查询的数据库列(如:id, name, password, age, tel) - 生成无条件查询SQL:
SELECT id, name, password, age, tel FROM user - 执行查询,将结果集的每一行映射回一个User对象
- 数据库列id → User.id属性
- 数据库列name → User.name属性
- ......
- 将所有映射好的User对象装入List<User>集合,返回给调用者
说明:
当你编写代码时,可能会看到:
java@Autowired private UserMapper userMapper; // IDEA可能在此处显示红色波浪线原因分析:
markdownUserMapper是接口 → 接口不能被直接实例化 → IDEA静态检查时找不到实现类 → 显示警告 ↓ 运行时Spring动态创建代理对象 → 实际可以正常工作初学者建议忽略警告直接运行,运行测试时,Spring会成功注入代理对象,不影响运行
跟之前整合MyBatis相比,你会发现我们不需要在DAO接口中编写CRUD的接口方法和SQL语句、无需编写XML映射文件,只需要继承BaseMapper接口即可,整体来说简化很多。
MybatisPlus简介
MyBatisPlus(简称MP)是基于MyBatis框架基础上开发的增强型工具,旨在简化开发、提高效率
与 MyBatis 关系
scss
MyBatis (基础框架)
↑
MyBatisPlus (增强工具)
"最佳搭档,配合使用"MP旨在成为MyBatis的最好搭档,而不是替换MyBatis,所以可以理解为MP是MyBatis的一套增强工具,它是在MyBatis的基础上进行开发的,我们虽然使用MP但是底层依然是MyBatis的东西,也就是说我们也可以在MP中写MyBatis的内容。
官网是学习 MP 的最佳资料库,里面有:
- 详细的入门教程
- 完整的 API 文档
- 丰富的代码示例
- 常见问题解答
MP 的核心特性(为什么选择它?)
- 无侵入:只做增强不做改变,不会对现有工程产生影响
- 强大的 CRUD 操作:内置通用 Mapper,少量配置即可实现单表CRUD 操作
- 支持 Lambda:编写查询条件无需担心字段写错
- 支持主键自动生成
- 内置分页插件
- ......
标准数据层开发
这一节学习数据层标准的CRUD(增删改查)的实现与分页功能。
标准CRUD使用
BaseMapper 是 MyBatisPlus 的核心接口,提供了完整的 CRUD 操作方法。只需要让你的 Mapper 接口继承它,就自动获得了数十个常用方法。
java
// 你的 Mapper 接口只需要这一行代码
public interface UserDao extends BaseMapper<User> {
// 不需要写任何方法,CRUD 功能全部自动拥有!
}BaseMapper 中的方法:
| 功能 | 自定义接口 | MP接口 |
|---|---|---|
| 新增 | boolean save(T t) | int insert(T t) |
| 删除 | boolean delete(int id) | int deleteById(Serializable id) |
| 修改 | boolean update(T t) | int updateById(T t) |
| 根据id查询 | T getById(int id) | T selectById(Serializable id) |
| 查询全部 | List<T> getAll() | List<T> selectList(Wrapper<T> queryWrapper) |
| 分页查询 | PageInfo<T> getAll(int page, int size) | IPage<T> selectPage(IPage<T> page, Wrapper<T> queryWrapper) |
| 按条件分页查询 | List<T> getAll(Condition condition) | IPage<T> selectPage(IPage<T> page, Wrapper<T> queryWrapper) |
用继承 BaseMapperr<T> 的 Mapper接口 调用这些方法,以操作T这个实体类对应的数据库表。
新增(Create)
java
int insert(T entity); // 插入一条记录T就是 Mapper 接口继承BaseMapperr<T>时传入的类型T,同时也与实体类的类型相同。
T entity就是类型为T的对象(一个对象对应一个行记录)。int:返回值类型,新增成功后返回1,没有新增成功返回0
在测试类中进行新增操作:
java
@SpringBootTest
class Mybatisplus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testSave() {
User user = new User();
user.setName("黑马程序员");
user.setPassword("itheima");
user.setAge(12);
user.setTel("4006184000");
userDao.insert(user);
}
}说明:
User user = new User();:因为 UserMapper 接口声明了它操作 User 类(类型),所以必须且只能 创建 User 对象。
- 特性-自动回填主键:插入成功后,实体对象的 ID 字段会自动被赋值为数据库生成的值
那数据中的主键ID是如何来的呢?这在后面 DML编程控制-ID生成策略控制 将要学到。
删除(Delete)
java
int deleteById(Serializable id); // 根据 ID 删除int:返回值类型,删除成功返回1,没有删除成功返回0。Serializable:参数类型,使方法可以接受任何类型的 id 值。
参数类型为什么使用 Serializable?
Serializable 是 Java 的序列化接口,常见的主键类型都是 Serializable 的子类:
javaObject └── Serializable ├── String // 字符串主键 └── Number ├── Integer // 整数主键 ├── Long // 长整数主键 └── ... // 其他数字类型优点 :
Serializable作为参数类型,可以接受任何类型的主键值,就像Object能接收任何对象一样,非常灵活。
在测试类中进行删除操作:
java
@SpringBootTest
class Mybatisplus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testDelete() {
// 根据 ID 删除
userDao.deleteById(1401856123725713409L);
}
}修改(Update)
java
int updateById(T entity); // 根据 ID 修改- 方法成分解释同"新增(Create)"。
- 在方法之前,要设置对象(记录行)id及其要修改的字段(列)的值,执行方法时,MP 只会更新对象中设置了值的字段,没有设置的字段不会更新。
在测试类中进行修改操作:
java
@SpringBootTest
class Mybatisplus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testUpdate() {
User user = new User();
user.setId(1L); // 关键:指定要修改的记录id
user.setName("Tom888"); // 只修改名字
user.setPassword("tom888"); // 只修改密码
// 注意:age 和 tel 没有设置,所以不会被更新
userDao.updateById(user);
}
}查询(Retrieve)
根据 ID 查询
java
T selectById (Serializable id)- 方法成分解释同"新增(Create)"、"删除(Delete)"。
在测试类中进行根据 ID 查询操作:
java
@SpringBootTest
class Mybatisplus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetById() {
User user = userDao.selectById(2L); // 查询 ID为2L 的单条记录
System.out.println(user);
}
}查询所有数据
java
List<T> selectList(Null)List:因为查询的是所有,所以返回的数据是一个集合对象。
返回的 List 集合包含:当前已连接的数据库里,调用这个方法的接口代理对象对应的那张表中,每一行都实例化为一个对象,每个对象都包含该行的所有字段数据。<T>:T 同前"新增(Create)"
在测试类中进行新增操作:
java
@SpringBootTest
class Mybatisplus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll() {
List<User> userList = userDao.selectList(null);
System.out.println(userList);
}
}批量 ID 查询
java
List<T> selectBatchIds(Collection<? extends Serializable> idList)List<T>:返回的数据是一个集合对象。
返回的 List 集合包含 :当前已连接的数据库里,调用这个方法的接口代理对象对应的那张表中,其主键ID值在传入的idList集合内的每一行记录,都实例化为一个对象,每个对象都包含该行的所有字段数据。<T>:T 同前"新增(Create)"。Collection<? extends Serializable> idList:一个包含主键ID值的集合,用于指定要查询哪些记录。且这些ID值的类型必须是Serializable的子类。
在测试类中进行批量 ID 查询操作:
java
@SpringBootTest
class Mybatisplus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testSelectBatchIds() {
// 1. 准备要查询的 ID 列表
List<Long> idList = Arrays.asList(1L, 2L, 3L);
// 2. 批量查询
List<User> userList = userDao.selectBatchIds(idList);
System.out.println(userList);
}
}我们所调用的方法都是来自于DAO接口继承的BaseMapper类中。里面的方法有很多,我们后面会慢慢去学习里面的内容。
Lombok
问题:实体类编写的"固定流程"
在没有Lombok之前,我们每写一个实体类都需要手动或通过IDEA生成以下内容:
- 私有属性
- setter/getter方法
- toString方法
- 构造函数
解决方案:Lombok
Lombok是一个Java库 ,通过注解的方式,在编译时自动生成这些重复的代码。你只需要写属性的定义,其他方法Lombok帮你生成。
核心思想:用注解代替重复代码
使用步骤
- 在 Spring Initializr 页面,在依赖搜索框中输入 Lombok 并勾选它。
- 检查注解处理启用(默认启用):File → Settings → Build, Execution, Deployment → 展开Compiler(编译器) → Annotation Processors(注解处理器) → 勾选 Enable annotation processing(启用注解处理)
- 编写实体类时,在实体类上使用 Lombok 注解。
核心注解
1. @Data(最常用,一键全包)
java
@Data
public class User {
private Long id;
private String name;
......
}@Data 实际上包含了:
@Getter:为所有字段生成getter方法@Setter:为所有非final字段生成setter方法@ToString:生成toString()方法@EqualsAndHashCode:生成equals()和hashCode()方法@RequiredArgsConstructor:为final字段生成构造函数
2. @NoArgsConstructor(无参构造)
java
@NoArgsConstructor
public class User {
// 编译后会生成:public User() {}
}用途:很多框架(如MyBatis、Spring)需要通过无参构造函数创建对象,然后通过setter方法设置值。
3. @AllArgsConstructor(全参构造)
java
@AllArgsConstructor
public class User {
private Long id;
private String name;
// 编译后会生成:
// public User(Long id, String name) {
// this.id = id;
// this.name = name;
// }
}推荐写法(覆盖90%场景)
java
import lombok.Data;
import lombok.AllArgsConstructor;
import lombok.NoArgsConstructor;
@Data // 生成getter、setter、toString等
@NoArgsConstructor // 无参构造:框架反射创建对象需要
@AllArgsConstructor // 全参构造:方便测试时快速创建对象
public class User {
private Long id;
private String name;
private String password;
private Integer age;
private String tel;
}Lombok 只是简化模型类的编写,我们之前的传统方法也能与之一起组合使用。
分页功能
分页查询方法
java
IPage<T> selectPage(IPage<T> page, Wrapper<T> queryWrapper)IPage<T> page:分页参数对象,包含页码、每页条数等信息Wrapper<T> queryWrapper:查询条件 ,无条件时传null- 返回值
IPage<T>:包含分页数据和分页信息的结果对象
创建IPage 接口对应的 Page 实现类的分页对象
java
// IPage 是接口,Page 是其实现类
IPage<User> page = new Page<>(当前页码, 每页显示条数);实现步骤
步骤1:调用方法传入参数获取返回值
在Mybatisplus01QuickstartApplicationTests测试类中写:
java
@SpringBootTest
class Mybatisplus01QuickstartApplicationTests {
@Autowired
private UserDao userDao;
//分页查询
@Test
void testSelectPage(){
//1 创建IPage分页对象,设置分页参数,1为当前页码,3为每页显示的记录数
IPage<User> page=new Page<>(1,3);
//2 执行分页查询
userDao.selectPage(page,null);
//3 获取分页结果
System.out.println("当前页码值:" + page.getCurrent()); // 获取当前页码
System.out.println("每页显示数:" + page.getSize()); // 获取每页条数
System.out.println("一共多少页:" + page.getPages()); // 获取总页数
System.out.println("一共多少条数据:" + page.getTotal()); // 获取总记录数
System.out.println("数据:" + page.getRecords()); // 获取当前页数据列表
}
}注意: selectPage() 方法会修改传入的 page 对象,将查询结果填充到其中。
步骤2:设置分页拦截器
分页功能需要配置拦截器才能正常工作。
- 在项目中创建配置类:
src/main/java/com/你的包名/config/MpConfig.java
- 位置规则:将配置类放在主启动类所在包下,或主启动类所在包下方的任意层级的子包内。
- 建议放在主启动类所在包下的
config包中,结构清晰。
配置类代码 :
固定写法,可自定义方法名、指定数据库类型:
java
@Configuration // 标记为配置类
public class MybatisPlusConfig {
@Bean // 将方法返回值注册为Spring Bean
// 方法名可自定义,但返回值类型必须是 MybatisPlusInterceptor
public MybatisPlusInterceptor mybatisPlusInterceptor() {
// 1. 创建拦截器对象
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 2. 添加分页拦截器
// 指定数据库类型,确保分页SQL正确生成
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));
// 3. 返回配置好的拦截器
return interceptor;
}
}说明:
-
如果需要MyBatisPlus的其他功能,可以在同一个方法中添加多个拦截器。
-
DbType.MYSQL :指定数据库类型为MYSQL,确保生成正确的分页SQL
DbType是 MyBatisPlus 定义的一个枚举类,包含了所有支持的数据库类型。java// 查看源码或文档,常用值包括: DbType.MYSQL // MySQL DbType.MARIADB // MariaDB DbType.ORACLE // Oracle // ......
查看执行的SQL语句
启用SQL日志
修改 application.yml 配置文件:
yaml
mybatis-plus:
configuration:
# 将SQL日志打印到控制台
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl查看分页SQL
启用日志后,执行分页查询时控制台会显示:
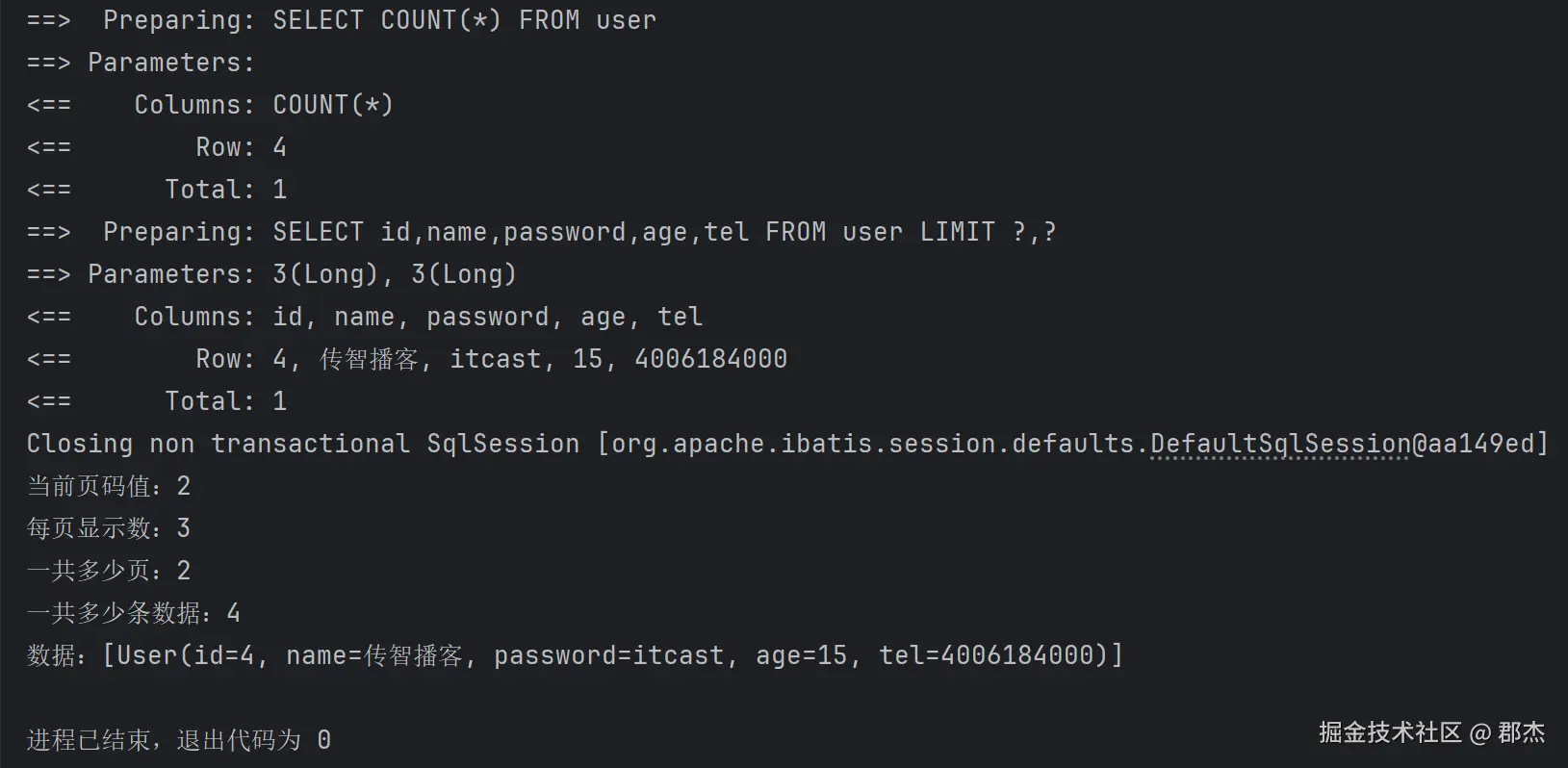
SQL解释:
- 先执行
COUNT(*)查询总记录数 - 再执行分页查询,使用
LIMIT关键字
调试完成后,记得注释或删除日志配置,避免性能影响和安全风险
IPage对象常用方法
| 方法名 | 返回值类型 | 说明 |
|---|---|---|
getCurrent() |
long |
当前页码(从1开始) |
getSize() |
long |
每页显示条数 |
getTotal() |
long |
总记录数 |
getPages() |
long |
总页数 |
getRecords() |
List<T> |
当前页的数据列表 |
setCurrent(long) |
void |
设置当前页码 |
setSize(long) |
void |
设置每页条数 |
DQL编程控制
增删改查四个操作中,查询是非常重要的也是非常复杂的操作,这块需要我们重点学习下,这节我们主要学习的内容有:
- 条件查询方式
- 查询投影
- 查询条件设定
- 字段映射与表名映射
条件查询
条件查询方法
java
List<T> selectList(Wrapper<T> queryWrapper)List:返回值是 封装所有查询到的记录的实体对象的列表对象。
返回的 List 集合包含:当前连接的数据库里,调用这个方法的接口代理对象对应的那张表中,满足 Wrapper 所设条件的每一行都实例化(映射)为一个泛型 T 指定的实体类对象,每个对象的属性都被填充为对应列的值(默认全部列)。如果无满足条件的记录,则返回空列表(empty list,不是 null)。<T>:T 同前"新增(Create)"- 参数
Wrapper<T> queryWrapper:一个封装了查询条件的对象(通常是QueryWrapper<T>或LambdaQueryWrapper<T>的实例),用于动态构建 SQL 的 WHERE 子句。传入null表示无条件,查询所有记录。
Wrapper 查询条件接口
Wrapper 是 MyBatisPlus 中用于动态构建查询条件的核心接口。由于是接口,我们需要通过实例化其具体实现类(如 QueryWrapper 或 LambdaQueryWrapper)来创建一个查询条件对象。通过操作此对象的方法,可以用编程的方式构建SQL的WHERE查询条件,从而替代手动拼接 SQL 语句。
环境构建
Wrapper构建条件查询之前的环境准备
- 创建SpringBoot项目
- pom.xml中添加对应的依赖
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.0</version>
</parent>
<groupId>com.itheima</groupId>
<artifactId>mybatisplus_02_dql</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- MyBatisPlus核心依赖 -->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
<!-- SpringBoot基础依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<!-- Druid连接池 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.16</version>
</dependency>
<!-- MySQL驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!-- SpringBoot测试依赖 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!-- Lombok简化代码 -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>- 核心代码实现
- 实体类(User.java)
java
@Data // Lombok注解,自动生成getter、setter、toString等方法
public class User {
private Long id;
private String name;
private String password;
private Integer age;
private String tel;
}- Mapper接口(UserDao.java)
java
@Mapper // 标记为MyBatis的Mapper接口
public interface UserDao extends BaseMapper<User> {
// 继承BaseMapper,获得基础的CRUD方法
}- 启动类(Mybatisplus02DqlApplication.java)
java
package com.itheima;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication // SpringBoot应用启动注解
public class Mybatisplus02DqlApplication {
public static void main(String[] args) {
SpringApplication.run(Mybatisplus02DqlApplication.class, args);
}
}- 配置文件(application.yml)
yaml
# 数据库连接配置
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatisplus_db?serverTimezone=UTC
username: root
password: 123456 # 根据实际修改
# MyBatisPlus配置
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 控制台打印SQL日志
global-config:
banner: off # 关闭MyBatisPlus启动图标
# SpringBoot配置
main:
banner-mode: off # 关闭SpringBoot启动图标注意: 将password值修改为你MySQL的实际密码。
- 测试类(Mybatisplus02DqlApplicationTests.java)
java
@SpringBootTest // 启用SpringBoot测试环境
class Mybatisplus02DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll() {
// 查询所有数据
List<User> userList = userDao.selectList(null);
System.out.println(userList);
}
}构建条件查询
在 MyBatisPlus 中构建查询条件,本质是创建并操作一个 Wrapper 接口的实现类对象。该对象本身就是一个封装查询条件的容器。
不同的实现类提供了不同的字段指定方式,主要分为以下三种模式:
常见的实现类包括 QueryWrapper、LambdaQueryWrapper、UpdateWrapper 等:
1. 基础 ------ QueryWrapper
- 核心类/方法 :
QueryWrapper - 构建示例 :
实现类泛型对象.lt("age", 18) - 主要特点 :直接使用数据库列名(字符串) 来构建条件。写法简单,但容易因拼写错误导致查询问题。
2. 过渡方案 ------ QueryWrapper 上使用 Lambda
- 核心类/方法 :
QueryWrapper+.lambda() - 构建示例 :
实现类泛型对象.lambda().lt(User::getAge, 10) - 主要特点 :在
QueryWrapper基础上,通过调用.lambda()后使用实体类的 getter 方法引用 (如User::getAge)来指代字段。避免了字段名拼写错误,但写法上多了一层调用。
3. 推荐方式 ------ LambdaQueryWrapper
- 核心类/方法 :
LambdaQueryWrapper - 构建示例 :
实现类泛型对象.lt(User::getAge, 10) - 主要特点 :专为 Lambda 设计 的类。直接使用实体类的 getter 方法引用来构建条件,兼具类型安全 (编译时检查)和写法简洁的优点。
假设我们要查询年龄小于一定值的用户,以下使用 LambdaQueryWrapper 演示 Wrapper 实现类构建查询的步骤写法:
java
@Test
void testLambdaQueryWrapper() {
// 创建QueryWrapper对象,,并指定泛型为<User>
// QueryWrapper<User> qw = new QueryWrapper<User>();
// 1. 创建 LambdaQueryWrapper 泛型对象,并指定泛型<User>,即查询条件构建器
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<>();
// 2. 使用 Lambda方法引用 构建查询条件,并添加到 发起调用的 查询条件对象中
lqw.lt(User::getAge, 10);
// 3. 把添加了查询条件的 查询条件对象作为selectList参数
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
}多条件查询构建
在实际开发中,查询通常不止一个条件,而是需要组合多个条件。MyBatisPlus 的 LambdaQueryWrapper 也提供了灵活的方式来构建多条件查询。
1. 默认逻辑:AND(与)
当我们在同一个 Wrapper 对象上连续调用多个条件方法 时,它们默认为AND 关键字连接。
需求示例 :查询年龄在 10 岁到 30 岁之间的用户(即 age > 10 AND age < 30)。
java
@SpringBootTest
class Mybatisplus02DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll(){
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<User>();
lqw.lt(User::getAge, 30).gt(User::getAge, 10);
// 相当于 ↓
// lqw.lt(User::getAge, 30);
// lqw.gt(User::getAge, 10);
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
}
}生成的 SQL:
sql
SELECT id,name,password,age,tel FROM user WHERE (age > ? AND age < ?)链式编程 :wrapper.gt(...).lt(...) 这种连续调用的写法称为链式编程,代码更简洁。
2. 切换逻辑:OR(或)
使用 OR 连接条件,在两个条件之间插入 .or() 方法。
需求示例 :查询年龄小于 10 岁 或 大于 30 岁的用户(即 age < 10 OR age > 30)。
java
@SpringBootTest
class Mybatisplus02DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll(){
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<User>();
lqw.lt(User::getAge, 10).or().gt(User::getAge, 30);
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
}
}生成的 SQL:
sql
SELECT id,name,password,age,tel FROM user WHERE (age < ? OR age > ?)3. 复杂逻辑组合:AND 与 OR 嵌套
有时需要更复杂的逻辑,比如 (条件1 AND 条件2) OR (条件3 AND 条件4)。此时可以使用 .and() 和 .or() 的嵌套写法。
需求示例 :查询年龄在 10-30 岁之间 并且 名字包含"张"的用户,或者 年龄大于 60 岁的用户。
java
@Test
void testNestedCondition() {
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
// 构建复杂条件:(age > 10 AND age < 30 AND name LIKE '%张%') OR (age > 60)
wrapper.and(w -> w.gt(User::getAge, 10)
.lt(User::getAge, 30)
.like(User::getName, "张"))
.or(w -> w.gt(User::getAge, 60));
List<User> users = userDao.selectList(wrapper);
System.out.println(users);
}理解:
当调用
wrapper.and(w -> w.gt(...).lt(...))时:
and方法内部会创建一个新的LambdaQueryWrapper实例 ,即w,然后把这个新实例作为参数传递给你的 Lambda 表达式(and()或or())。
生成的 SQL:
sql
SELECT ... FROM user
WHERE (age > ? AND age < ? AND name LIKE ?) OR (age > ?)语法格式:
java
外层Wrapper.and(内层Wrapper变量名 ->
内层Wrapper变量名.条件1(...)
.条件2(...)
.条件3(...)...) // .and()里面全部条件默认组合为一个"且"条件整体
.or(内层Wrapper变量名 ->
内层Wrapper变量名.条件1(...)
.条件2(...)
.条件3(...)...); // .or()里面全部条件默认组合为一个"且"条件整体,然后与外部条件为"或"关系null判定

在实际业务中,查询条件往往来自前端的表单,用户可能只填写部分条件。例如一个年龄范围查询,用户可能只输入最小值,或只输入最大值,或者都不输入。后端需要根据用户实际输入的值动态构建查询条件,如果简单拼接 SQL,很容易生成类似 age < null 的无效语句,导致查询错误。
MyBatisPlus 提供了优雅的解决方案:条件方法的重载版本支持一个 boolean condition 参数 ,只有当该参数为 true 时,才会将当前条件加入到查询中,否则忽略。
需求示例
假设前端传递了两个年龄值:ageMin(最小年龄)和 ageMax(最大年龄),我们需要实现:
- 如果只传入
ageMin,则查询年龄大于该值的用户(age > ageMin) - 如果只传入
ageMax,则查询年龄小于该值的用户(age < ageMax) - 如果两者都传入,则查询年龄在两者之间的用户(
age > ageMin AND age < ageMax)
1. 接收参数的实体类设计
为了不改动原 User 实体类,可以在同一层中创建一个继承 User 的查询专用类,增加 age2 属性用于接收第二个年龄值:
原User 类:
java
@Data
public class User {
private Long id;
private String name;
private String password;
private Integer age;
private String tel;
}继承 User类 的查询专用类:
scala
@Data
public class UserQuery extends User {
private Integer age2; // 用于接收第二个年龄值(如最大值)
}2. 传统方式:手动 if 判断
java
@Test
void testQueryByAgeRange() {
// 模拟前端传来的数据
UserQuery query = new UserQuery();
query.setAge(10); // 最小值
query.setAge2(30); // 最大值
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
// 手动判断每个字段是否为 null,再决定是否添加条件
if (query.getAge() != null) {
wrapper.gt(User::getAge, query.getAge()); // age > 最小值
}
if (query.getAge2() != null) {
wrapper.lt(User::getAge, query.getAge2()); // age < 最大值
}
List<User> users = userDao.selectList(wrapper);
System.out.println(users);
}这种方式虽然可行,但当条件很多时,代码会变得冗长且不易维护。
3. MyBatisPlus 优化:使用带 condition 参数的条件方法
MyBatisPlus 的所有条件方法都提供了重载版本,第一个参数为 boolean condition,只有参数condition为 true 时,该条件方法才会被转换加入到 SQL 中。
例如,MyBatisPlus框架中,
lt方法的定义为:
javalt(boolean condition, R column, Object val)
利用这个特性,我们可以将 null 判断直接内联到方法调用中,使代码更加简洁:
java
@Test
void testQueryByAgeRangeWithCondition() {
UserQuery query = new UserQuery();
query.setAge(10);
query.setAge2(30);
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
// 只有当 age 不为 null 时,才添加这个 gt 条件
wrapper.gt(query.getAge() != null, User::getAge, query.getAge());
// 只有当 age2 不为 null 时,才添加这个 lt 条件
wrapper.lt(query.getAge2() != null, User::getAge, query.getAge2());
List<User> users = userDao.selectList(wrapper);
System.out.println(users);
}这样,无论前端传入多少个条件,我们只需一行代码就能处理一个条件的添加与否,大大简化了动态查询的代码量。
更多示例
java// 模糊查询:只有当 name 不为空时才添加 like 条件 wrapper.like(StringUtils.isNotBlank(name), User::getName, name); // 范围查询:只有当 minPrice 和 maxPrice 都不为 null 时才添加 between 条件 wrapper.between(minPrice != null && maxPrice != null, User::getPrice, minPrice, maxPrice);
查询投影
查询投影是指只查询表中指定的字段,而不是返回记录(行)的所有字段的数据。这在某些场景下可以提升查询效率,减少数据传输量。
查询指定字段
MyBatisPlus 提供了 select 方法,用于设置要查询的字段列表。
方式一:使用 Lambda 表达式(推荐)
java
@SpringBootTest
class Mybatisplus02DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll(){
LambdaQueryWrapper<User> lqw = new LambdaQueryWrapper<User>();
// 只查询 id、name、age 三个字段
lqw.select(User::getId,User::getName,User::getAge);
List<User> userList = userDao.selectList(lqw);
System.out.println(userList);
}
}-
select方法参数为实体类的方法引用,可以传入多个。 -
生成的 SQL:
sqlSELECT id, name, age FROM user
方式二:使用普通 QueryWrapper(字段名写成字符串)
java
@SpringBootTest
class Mybatisplus02DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testGetAll() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
// 手动指定字段名(字符串形式)
wrapper.select("id", "name", "age", "tel");
List<User> users = userDao.selectList(wrapper);
System.out.println(users);
}- 这种方式需要直接写数据库列名,容易拼写错误,但灵活性更高(例如支持聚合函数等)。
聚合查询
聚合查询用于统计数据,如总记录数、最大值、最小值、平均值、总和等。
由于聚合查询的结果不是实体对象,而是一个个数值,因此需要使用 selectMaps 方法,返回的结果类型为 List<Map<String, Object>>,每个 Map 对应一行聚合结果。
java
@SpringBootTest
class Mybatisplus02DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testAggregation() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
// 查询总记录数,并将结果列命名为 count
wrapper.select("count(*) as count");
// 使用selectMaps 方法根据上面的查询条件查询结果
List<Map<String, Object>> countResult = userDao.selectMaps(wrapper);
System.out.println("总记录数:" + countResult);
// 查询最大年龄,并将结果列命名为 maxAge
wrapper.select("max(age) as maxAge");
List<Map<String, Object>> maxResult = userDao.selectMaps(wrapper);
System.out.println("最大年龄:" + maxResult);
// 查询最小年龄,并将结果列命名为 minAge
wrapper.select("min(age) as minAge");
List<Map<String, Object>> minResult = userDao.selectMaps(wrapper);
System.out.println("最小年龄:" + minResult);
// 查询平均年龄,并将结果列命名为 avgAge
wrapper.select("avg(age) as avgAge");
List<Map<String, Object>> avgResult = userDao.selectMaps(wrapper);
System.out.println("平均年龄:" + avgResult);
// 查询年龄总和,并将结果列命名为 sumAge
wrapper.select("sum(age) as sumAge");
List<Map<String, Object>> sumResult = userDao.selectMaps(wrapper);
System.out.println("年龄总和:" + sumResult);
}
}注意 :聚合查询无法使用 Lambda 表达式 ,因为聚合函数针对的是列的计算结果,不是实体类的某个属性。因此必须使用 QueryWrapper 并通过字符串指定列名。
分组查询
分组查询用于按某个字段分组后,对每组进行聚合统计。同样需要使用 QueryWrapper 和 selectMaps。
java
@Test
void testGroupBy() {
QueryWrapper<User> wrapper = new QueryWrapper<>();
// 按电话号码分组,统计每组人数
wrapper.select("count(*) as count", "tel");
wrapper.groupBy("tel");
List<Map<String, Object>> result = userDao.selectMaps(wrapper);
System.out.println("每个电话号码的人数:" + result);
}代码解释:
wrapper.select("count(*) as count", "tel")
count(*):这是 SQL 的聚合函数,用来统计每组有多少行(即每组人数)。as count:给这个统计结果起一个名字叫count,方便后面取数据。"tel":这是分组依据的字段,也就是你要按哪个字段分组。所以这一行相当于告诉 MyBatisPlus:我要查询两个东西 ------ 分组字段
tel,以及每组的人数(起名为count)。
wrapper.groupBy("tel")
- 指定按
tel字段进行分组。这对应 SQL 里的GROUP BY tel。
userDao.selectMaps(wrapper)
- 为什么不用
selectList?因为selectList会把查询结果自动封装成User对象 ,但这里查询的不是完整的User字段,而是tel和统计值,没法封装成User对象。- 所以用
selectMaps,它会把每一行结果转换成一个Map,Map 的键是列名(或别名),值是对应的数据。生成的 SQL:
sqlSELECT count(*) as count, tel FROM user GROUP BY tel
重要提示
- 无法使用 Lambda 的情况 :聚合查询(如 count、max)和分组查询(group by)由于涉及数据库函数,不能通过实体类的方法引用表达,因此只能使用
QueryWrapper和字符串形式。 - 返回类型 :聚合和分组查询的结果往往不是完整的实体对象,因此使用
selectMaps方法返回List<Map<String, Object>>,每个 Map 的 key 为查询时指定的别名(如count、maxAge),value 为计算结果。 - 扩展性:MyBatisPlus 只是对 MyBatis 的增强,如果遇到它无法满足的复杂查询,可以在 DAO 接口中直接使用 MyBatis 的原生方式(通过注解或 XML 编写 SQL)。
查询条件
等值查询
-
核心方法 :
eq(等于=) -
典型需求:根据用户名和密码查询单个用户。
-
代码示例 :
javaLambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); wrapper.eq(User::getName, "Jerry") .eq(User::getPassword, "jerry"); // 因为结果是单个用户,用 selectOne User user = userDao.selectOne(wrapper); -
说明 :
eq方法对应 SQL 中的=。如果需要查询单个结果,使用selectOne方法;如果可能返回多个结果,则应使用selectList。
范围查询
-
核心方法 :
gt(>),ge(>=),lt(<),le(<=),between(BETWEEN ? AND ?) -
典型需求:查询年龄在 10 到 30 岁之间的用户。
-
代码示例 :
javaLambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); // 方法一:使用 between wrapper.between(User::getAge, 10, 30); // 方法二:使用 gt 和 lt 组合 // wrapper.gt(User::getAge, 10).lt(User::getAge, 30); List<User> users = userDao.selectList(wrapper); -
说明 :
between方法是包含边界 的,即age BETWEEN 10 AND 30等价于age >= 10 AND age <= 30。
模糊查询
-
核心方法 :
like(%值%,包含指定值),likeLeft(%值,以指定值结尾),likeRight(值%,以指定值开头) -
典型需求:查询名字以 "J" 开头的用户。
-
代码示例 :
javaLambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>(); // 右模糊:J% wrapper.likeRight(User::getName, "J"); List<User> users = userDao.selectList(wrapper); -
说明 :理解区分这三个方法的关键是看百分号
%的位置。likeRight对应 SQL 的'值%',用于查询以指定值开头的数据。
排序查询
在 MyBatisPlus 中,排序查询通过 orderBy 系列方法实现,让查询结果按指定字段升序或降序排列。
核心方法 :orderBy(通用灵活), orderByAsc(升序 排序), orderByDesc(降序排序)
1. 使用 orderBy 方法(通用,可动态控制)
java
LambdaQueryWrapper<User> wrapper = new LambdaQueryWrapper<>();
// 按 id 降序排列
wrapper.orderBy(true, false, User::getId);- 参数说明 :
orderBy(condition, isAsc, columns)condition:是否生效(true添加排序,false忽略)isAsc:是否为升序(true升序,false降序)columns:要排序的字段(可多个,逗号,隔开)
2. 使用 orderByAsc / orderByDesc(简洁,推荐)
java
// 按 id 降序(推荐)
wrapper.orderByDesc(User::getId);
// 按年龄升序、id 降序(多字段)
wrapper.orderByAsc(User::getAge).orderByDesc(User::getId);orderByAsc:指定字段升序orderByDesc:指定字段降序- 支持单个或多个字段,多字段时按调用顺序依次排序。
- 如果排序条件固定且简单,优先使用
orderByAsc/orderByDesc,代码更简洁。- 若需根据条件动态决定是否排序或排序方向,可使用带
condition的orderBy方法。
除了上面介绍的这几种查询条件构建方法以外还会有很多其他的方法,比如isNull,isNotNull,in,notIn等等方法可供选择,具体参考官方文档的条件构造器来学习使用,具体的网址为: 条件构造器 | MyBatis-Plus
映射匹配兼容性
在使用 MyBatisPlus 时,实体类与数据库表之间的映射关系默认遵循一定的规则(如类名驼峰转下划线表名,属性名驼峰转下划线列名)。但在实际开发中,可能会遇到各种不一致的情况,导致数据无法正确封装或查询失败。MyBatisPlus 提供了 @TableField 和 @TableName 注解来解决这些问题。
问题1:表字段名与实体类属性名不一致
现象 :数据库表的列名与实体类的属性名发生不一致,导致查询结果无法封装到实体对象中。
解决方案 :使用 @TableField 注解的 value 属性指定下一个数据库字段名。
java
@Data
public class User {
private Long id;
private String userName;
@TableField("pwd") // 指定下一个数据库字段名为 pwd
private String password;
private Integer age;
private String tel;
}问题2:实体类中定义了数据库表中不存在的字段
现象 :实体类中存在数据库表不存在的字段(例如:实体类中用于接收前端参数的额外字段),导致生成的 SQL 语句中会查询该字段,报错 Unknown column 'xxx' in 'field list'。
解决方案 :使用 @TableField 注解的 exist 属性,设置 exist = false 表示下一个字段在数据库中不存在,生成 SQL 时会忽略该字段。
java
@Data
public class User {
private Long id;
private String name;
private String password;
private Integer age;
private String tel;
@TableField(exist = false) // 该字段在数据库表中不存在
private Integer online; // 用于接收前端额外参数
}问题3:不希望查询某些敏感字段
现象 :默认查询所有字段,可能将敏感数据(如密码、手机号)返回给前端。
解决方案 :使用 @TableField 注解的 select 属性,设置 select = false 表示默认不查询该字段,需要时再手动指定查询。
java
@Data
public class User {
private Long id;
private String name;
@TableField(select = false) // 默认查询时不返回该字段
private String password;
private Integer age;
private String tel;
}说明 :
select = false只是默认不查询,如果你在某个查询中需要该字段,可以通过wrapper.select(...)手动指定查询。
问题4:表名与实体类名不一致
现象 :数据库表名与实体类名不同(例如:表名为 tb_user,实体类名为 User),导致查询时提示表不存在。
解决方案 :使用 @TableName 注解指定数据库表名。
java
@TableName("tbl_user") // 指定数据库表名为 tbl_user
@Data
public class User {
private Long id;
private String name;
private String password;
private Integer age;
private String tel;
}DML 编程控制
主键 ID 生成策略控制
在新增数据时,主键 ID 的生成方式有很多种。不同的业务场景可能需要不同的 ID 生成策略,例如:
- 日志记录:通常使用数据库自增长 ID(如 1,2,3,...),简单有序。
- 购物订单 :可能需要包含业务信息的特殊规则订单号(如
FQ202403021234)。 - 外卖订单:可能希望 ID 包含地区、日期等信息。
- 关系表:有时可以省略主键,直接使用联合主键。
MyBatisPlus 提供了灵活的主键生成策略控制,通过 @TableId 注解即可轻松实现。
@TableId 注解
| 属性 | 说明 |
|---|---|
value |
指定数据库表中的主键列名,当实体类属性名与表主键列名不一致时使用。 |
type |
指定主键生成策略,取值来自 IdType 枚举。 |
IdType 枚举常用值
| 策略 | 值 | 说明 |
|---|---|---|
| AUTO | 0 |
数据库 ID 自增,依赖于数据库的自增特性。使用前必须确保数据库表设置了自增主键。 |
| NONE | 1 |
未设置主键类型,跟随全局配置(若全局未配置则默认雪花算法)。 |
| INPUT | 2 |
用户手动设置主键值,插入时必须赋值。 |
| ASSIGN_ID | 3 |
分配 ID,使用雪花算法生成 64 位长整型数字,主键类型需为 Long,默认策略。 |
| ASSIGN_UUID | 4 |
分配 UUID,生成 32 位 UUID 字符串(不含中划线),主键类型需为 String。 |
注意 :
ASSIGN_ID和ASSIGN_UUID是 MyBatisPlus 3.3.0 以上版本推荐使用的策略,它们会通过雪花算法或 UUID 自动生成 ID,无需数据库支持。实体类中定义主键属性的数据类型,必须与数据库表中主键字段定义的数据类型保持一致或兼容,建议的不同策略类型匹配:
生成策略 Java 实体类主键类型 数据库主键字段类型 ASSIGN_ID(雪花算法)LongbigintASSIGN_UUIDStringvarchar(32)(或char(32))AUTO(数据库自增)Long(或Integer,Short)bigint(或int,smallint)
环境构建
在学习 DML(增删改)编程控制之前,我们需要搭建一个测试环境。
1. 创建 SpringBoot 项目
2. 添加依赖
3. 编写实体类
在 com.itheima.domain 包下创建 User.java:
java
@Data
@TableName("tbl_user") // 指定数据库表名为 tbl_user(如果类名与表名不一致)
public class User {
private Long id;
private String name;
@TableField(value = "pwd", select = false)
// value:数据库字段名为 pwd(属性名 password 与数据库列名不一致)
// select = false:默认查询时不返回该字段(例如密码字段不希望被查询)
private String password;
private Integer age;
private String tel;
@TableField(exist = false) // 该字段在数据库表中不存在,仅用于接收额外数据
private Integer online;
}4. 编写 Mapper 接口
在 com.itheima.dao 包下创建 UserDao.java:
java
@Mapper // 让 Spring 扫描到该接口并生成代理对象
public interface UserDao extends BaseMapper<User> {
// 继承 BaseMapper 即可获得基础的增删改查方法
}5. 编写配置文件
在 src/main/resources 下创建 application.yml:
yaml
spring:
datasource:
type: com.alibaba.druid.pool.DruidDataSource # 使用 Druid 连接池
driver-class-name: com.mysql.cj.jdbc.Driver
url: jdbc:mysql://localhost:3306/mybatisplus_db?serverTimezone=UTC
username: root
password: root # 请修改为你的 MySQL 密码
mybatis-plus:
configuration:
log-impl: org.apache.ibatis.logging.stdout.StdOutImpl # 打印 SQL 日志到控制台,方便调试6. 编写启动类
在 com.itheima 包下创建启动类:
java
@SpringBootApplication
public class Mybatisplus03DmlApplication {
public static void main(String[] args) {
SpringApplication.run(Mybatisplus03DmlApplication.class, args);
}
}7. 编写测试类
在 src/test/java/com/itheima 下创建测试类,测试基础 CRUD 操作:
java
@SpringBootTest
public class Mybatisplus03DmlApplicationTests {
@Autowired
private UserDao userDao;
// 测试新增
@Test
void testSave() {
User user = new User();
user.setName("黑马程序员");
user.setPassword("itheima");
user.setAge(12);
user.setTel("4006184000");
userDao.insert(user);
System.out.println("新增成功,主键 ID:" + user.getId());
}
// 测试删除
@Test
void testDelete() {
// 根据 ID 删除,ID 需要替换为你数据库中的真实 ID
userDao.deleteById(1401856123925713409L);
}
// 测试修改
@Test
void testUpdate() {
User user = new User();
user.setId(3L); // 要修改的记录 ID
user.setName("Jock666"); // 只修改 name 字段
userDao.updateById(user); // 动态 SQL:只更新有值的字段
}
}AUTO策略
设置表的生成策略为 AUTO
在实体类的主键字段上添加 @TableId(type = IdType.AUTO):
java
@Data
@TableName("tbl_user")
public class User {
@TableId(type = IdType.AUTO) // 使用数据库自增
private Long id;
private String name;
@TableField(value = "pwd", select = false)
private String password;
private Integer age;
private String tel;
@TableField(exist = false)
private Integer online;
}关键点:
IdType.AUTO表示主键由数据库自动生成(自增)。- 使用此策略前,必须确保数据库表的主键字段已经设置为自增。
MySQL中,主键id字段定义中包含
AUTO_INCREMENT关键字,即已设置为自增。 如 `id` bigint(20) NOT NULL AUTO_INCREMENT
INPUT 策略
IdType.INPUT 表示主键 ID 的值完全由用户手动指定,MyBatisPlus 不会自动生成,也不会依赖数据库的自增功能。你需要自己在代码中给实体对象的 ID 字段赋值。
使用场景
- 当你需要保留业务中已有的 ID(例如从旧系统导入数据,希望保留原来的主键)。
- 当 ID 的生成规则由其他系统或代码逻辑控制,而不是由数据库或 MyBatisPlus 决定时。
设置表的生成策略为 INPUT
在实体类的主键字段上添加 @TableId(type = IdType.INPUT):
java
@Data
@TableName("tbl_user")
public class User {
@TableId(type = IdType.INPUT) // 主键由用户手动输入
private Long id;
private String name;
@TableField(value = "pwd", select = false)
private String password;
private Integer age;
private String tel;
@TableField(exist = false)
private Integer online;
}确保数据库表的主键不自增
因为我们要自己提供 ID,所以必须移除数据库表主键的自增属性。否则数据库可能会尝试生成自增值,与你手动设置的值冲突。
操作方法 :使用数据库管理工具(如 Navicat、MySQL Workbench)修改表结构,取消主键字段的
AUTO_INCREMENT勾选;或者执行 SQL:
sqlUSE mybatisplus_db; ALTER TABLE user MODIFY id BIGINT NOT NULL; -- 去掉 AUTO_INCREMENT在 IntelliJ IDEA 中,通过图形界面操作 或执行 SQL 命令 两种方式来修改表结构,取消主键字段的
AUTO_INCREMENT属性的操作:方法一:图形界面操作(推荐初学者)
- 打开 Database 工具窗口
- 找到目标表
- 打开表设计器
- 右键点击该表,在菜单中选择 "Modify Table...(修改 表...)"。
- 或者在选中表后,按快捷键
Ctrl+F6。- 取消自增勾选
在打开的表设计器窗口中:
- 找到
id字段所在的行。- 找到 "Auto increment(自动递增)" 列的复选框,取消勾选。
- 保存修改
点击窗口底部的 "OK(确定)" 按钮,IDEA 会生成并执行对应的ALTER TABLE语句,完成修改。方法二:执行 SQL 命令(更通用)
如果你更喜欢直接写 SQL,或者想更清楚地看到修改过程,可以通过查询控制台执行
ALTER TABLE语句。
- 打开查询控制台
在 Database 工具窗口中,右键点击你的数据库连接,选择 "New(新建)" → "Query Console(查询控制台)"。
快捷键:选中连接后按
F4。
- 编写并执行 SQL
在打开的编辑器中输入 SQL 命令(在SQL操作命令之前,先执行USE 数据库名;切换到正确的数据库)。
然后点击工具栏的绿色 "Execute" 按钮(▶️),或按快捷键Ctrl+Enter执行 。验证修改是否生效
修改完成后,可以执行以下 SQL 查看表结构,确认
id字段已没有auto_increment属性:
sqlSHOW CREATE TABLE user;如果返回的建表语句中
id字段后不再有AUTO_INCREMENT关键字,说明修改成功。
编写插入数据代码,手动设置 ID
在插入数据时,必须给 id 字段赋值 ,而且需要确保手动设置的 id 在表中不重复:
java
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testSave() {
User user = new User();
user.setId(666L); // 手动指定主键值
user.setName("黑马程序员");
user.setPassword("itheima");
user.setAge(12);
user.setTel("4006184000");
userDao.insert(user);
}
}ASSIGN_ID 策略
ASSIGN_ID 是 MyBatisPlus 提供的一种主键生成策略,它使用 雪花算法(Snowflake) 自动生成一个全局唯一的、趋势递增的 64 位长整型数字作为主键 ID。你不需要手动设置 ID,也不需要依赖数据库的自增功能。
特点:
- 自动生成,无需人工干预。
- 生成的 ID 是数字类型(
Long),长度较长(如1401856123925713409),适合分布式系统,避免多服务器间 ID 冲突。 - 趋势递增,但不是严格连续递增。
设置表的生成策略为 ASSIGN_ID
在实体类的主键字段上添加 @TableId(type = IdType.ASSIGN_ID):
java
@Data
@TableName("tbl_user")
public class User {
@TableId(type = IdType.ASSIGN_ID) // 使用雪花算法自动生成 ID
private Long id; // 注意:类型必须为 Long
private String name;
@TableField(value = "pwd", select = false)
private String password;
private Integer age;
private String tel;
@TableField(exist = false)
private Integer online;
}编写插入数据代码,不要手动设置 ID
在插入数据时,不要给 id 字段赋值,让 MyBatisPlus 自动生成:
java
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testSave() {
User user = new User();
user.setName("黑马程序员");
user.setPassword("itheima");
user.setAge(12);
user.setTel("4006184000");
// 注意:没有设置 user.setId(...)
userDao.insert(user);
System.out.println("插入成功,自动生成的 ID = " + user.getId());
}
}关键点:
- 主键字段的类型必须是
Long(或long)- 最好确保数据库表的主键不自增(
AUTO_INCREMENT),也不要求手动赋值。- 手动设置 ID 会覆盖:如果在代码中手动给
id赋值(例如user.setId(888L)),则 MyBatisPlus会使用你设置的值,而不会自动生成。这可以让你在某些特殊场景下强制指定 ID。
ASSIGN_UUID 策略
ASSIGN_UUID 是 MyBatisPlus 提供的一种主键生成策略,它会自动生成一个 32 位的 UUID 字符串(通用唯一识别码)作为主键 ID。UUID 在全球范围内都是唯一的,适合分布式系统,但它是无序的字符串类型。
特点:
- 自动生成,无需人工设置。
- 生成的 ID 是长度为 32 位的 字符串 (如
"f47ac10b58cc4372a5670e02b2c3d479",MyBatisPlus 生成的 UUID 默认不含横线,横线不计入字符串位数)。 - 全局唯一,即使在不同服务器上同时生成也不会重复。
- 无序性,不适合作为数据库索引(插入性能可能不如自增数字)。
设置表的生成策略为 ASSIGN_UUID
在实体类的主键字段上添加 @TableId(type = IdType.ASSIGN_ID),并将主键字段类型设置为 String:
java
@Data
@TableName("tbl_user")
public class User {
@TableId(type = IdType.ASSIGN_UUID) // 使用 UUID 策略
private String id; // 注意:类型必须是 String
private String name;
@TableField(value = "pwd", select = false)
private String password;
private Integer age;
private String tel;
@TableField(exist = false)
private Integer online;
}修改数据库表及其属性
因为要存储 32 位的 UUID 字符串,数据库表的主键字段必须能够容纳足够长的字符。
- 使用数据库管理工具(如 Navicat、IDEA Database)修改表结构,将
id字段的类型改为varchar(32)或char(32)(建议varchar(32),节省空间)。 - 如果表之前有自增属性(
AUTO_INCREMENT),一定要取消自增,因为 UUID 是字符串,不能自增。 - 确保字段不允许为空(
NOT NULL)。
示例 SQL(以 MySQL 为例):
sqlALTER TABLE tbl_user MODIFY id VARCHAR(32) NOT NULL;
编写插入数据代码,不要手动设置 ID
在插入数据时,不要给 id 字段赋值,让 MyBatisPlus 自动生成 UUID:
java
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testSave() {
User user = new User();
user.setName("黑马程序员");
user.setPassword("itheima");
user.setAge(12);
user.setTel("4006184000");
// 注意:没有设置 user.setId(...)
userDao.insert(user);
System.out.println("插入成功,自动生成的 ID = " + user.getId());
}
}关键点:
- 主键字段的类型必须是
String- 最好确保数据库表的主键不自增(
AUTO_INCREMENT),也不要求手动赋值。- 手动设置 ID 会覆盖:如果在代码中手动给
id赋值(例如user.setId(888L)),则 MyBatisPlus会使用你设置的值,而不会自动生成。这可以让你在某些特殊场景下强制指定 ID。
拓展知识:分布式 ID、策略的选择
分布式 ID
当系统数据量非常大时,单台数据库服务器可能无法存储所有数据,需要分库分表(将数据分散到多台服务器)。此时,如果仍然使用数据库自增主键,不同服务器上生成的主键可能会重复,导致冲突。
因此需要一个全局唯一 的 ID,即使在不同服务器上生成,也不会重复。这种 ID 称为分布式 ID。
常见的分布式 ID 生成算法:
- 雪花算法(Snowflake):Twitter 开源的算法,生成一个 64 位整数,包含时间戳、机器 ID、序列号等,趋势递增,性能高。
- UUID:通用唯一标识符,生成 32 位字符串,全球唯一,但无序且长度较长,不适合作为数据库索引。
- 数据库号段模式 、Redis 自增 等。
MyBatisPlus 的 ASSIGN_ID 正是基于雪花算法的实现,适合分布式环境。
策略的选择
- 如果你开发的是一个简单的单机项目 (例如个人博客、公司内部小系统):优先使用
AUTO,简单省事。 - 如果你的项目是分布式系统 ,需要全局唯一的数字 ID,且对性能要求较高:
ASSIGN_ID是最佳选择,也是 MyBatisPlus 的默认策略。 - 如果外部接口要求主键必须是字符串 ,或者你有特殊需要(如隐藏数据量) :可以考虑
ASSIGN_UUID。 - 如果你需要手动控制 ID (比如从旧系统导入数据保留原 ID) :使用
INPUT,并自行确保唯一性。
简化配置
在前面的学习中,我们为了处理实体类与数据库表的映射关系,以及主键生成策略,需要在每个实体类上都添加注解,例如:
java
@TableName("tbl_user")
public class User {
@TableId(type = IdType.ASSIGN_ID)
private Long id;
// ... 其他字段
}如果项目中有几十个实体类,每个都要写 @TableName 和 @TableId,会显得非常繁琐。MyBatisPlus 提供了全局配置 的方式,让我们可以在 application.yml 中统一设置,大大简化代码。
全局主键策略配置
痛点 :每个实体类的主键字段上都要写 @TableId(type = IdType.ASSIGN_ID),重复劳动。
解决方案:在配置文件中设置全局默认的主键生成策略。
yaml
mybatis-plus:
global-config:
db-config:
id-type: assign_id # 设置全局主键生成策略为 ASSIGN_ID配置之后,所有实体类的主键都会默认使用 ASSIGN_ID 策略,你不需要再在每个实体类的 id 字段上添加 @TableId 注解。
注意 :如果想为某个表指定其他ID生成策略,你仍然可以在该实体类上使用 @TableId 特殊指定,局部配置会覆盖全局。
主键列名的指定 :如果数据库主键列名不是
id(例如user_id),你仍需要在字段上使用@TableId("user_id")来指定,全局策略只影响生成方式,不影响字段名映射。
全局表名前缀配置
痛点 :如果数据库中的所有表都以 tbl_ 开头(例如 tbl_user、tbl_order),那么每个实体类上都要写 @TableName("tbl_xxx"),非常麻烦。
解决方案:配置全局表名前缀,MyBatisPlus 会自动将前缀 + 实体类名(首字母小写)组合成表名。
yaml
mybatis-plus:
global-config:
db-config:
table-prefix: tbl_ # 设置数据库表名前缀配置后,对于实体类 User,MyBatisPlus 会自动寻找表名为 tbl_user 的数据库表;对于 Order 类,找 tbl_order 表。这样,你无需在每个实体类上写 @TableName。
注意 :如果某个表名不符合这个规则,你仍然可以在该实体类上使用 @TableName 特殊指定,局部配置会覆盖全局。
多记录操作(批量删除与批量查询)
在实际开发中,我们经常需要一次性操作多条数据,例如购物车中的批量删除、根据多个ID查询用户信息等。如果每次都只操作一条,不仅效率低,代码也会变得冗余。MyBatisPlus 提供了方便的批量操作方法,让我们可以轻松处理这类需求。
批量删除
场景引入 :假设你在购物车中添加了多件商品,后来又不想要了。如果一个个点击删除会很慢,通常网站会提供复选框,让你可以一次性勾选多个商品,然后点击"批量删除"按钮。这个功能对应的就是数据库的批量删除操作。
API 方法
MyBatisPlus 的 BaseMapper 中提供了以下方法用于批量删除:
java
int deleteBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);- 方法名解释 :
deleteBatchIds= delete(删除) + Batch(批量) + Ids(多个ID) - 参数 :
Collection<? extends Serializable> idListCollection是集合接口,常见实现类有List、Set等。? extends Serializable表示集合中的元素必须是Serializable(可序列化)的子类,通常我们的主键类型(如Long、Integer、String)都满足这个条件。- 参数是一个 元素是主键类型 的集合
- 返回值 :
int表示成功删除的记录条数。
代码示例:
假设我们要根据多个用户 ID 删除对应的用户记录:
java
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowired
private UserDao userDao; // 注入 Mapper 接口
@Test
void testDeleteBatch() {
// 1. 准备要删除的 ID 集合
List<Long> idList = new ArrayList<>();
idList.add(1402551342481838081L);
idList.add(1402553134049501186L);
idList.add(1402553619611430913L);
// 2. 调用批量删除方法
int rows = userDao.deleteBatchIds(idList);
// 3. 输出结果
System.out.println("成功删除 " + rows + " 条记录");
}
}执行后生成的 SQL(可以在控制台看到日志):
sqlDELETE FROM user WHERE id IN (1402551342481838081, 1402553134049501186, 1402553619611430913)
批量查询
场景引入:有时我们需要根据多个 ID 一次性查询出对应的用户信息,比如在前端展示选中用户的详情。如果循环查询,会多次访问数据库,影响性能。批量查询可以一次完成。
API 方法
BaseMapper 中对应的批量查询方法如下:
java
List<T> selectBatchIds(@Param(Constants.COLLECTION) Collection<? extends Serializable> idList);- 方法名解释 :
selectBatchIds= select(查询) + Batch(批量) + Ids(多个ID) - 参数:与批量删除相同,是一个存放多个 ID 的集合。
- 返回值 :
List<T>,包含查询到的实体对象列表(注意:如果某个 ID 不存在,结果集中不会包含它)。
代码示例:
根据多个 ID 查询用户信息:
java
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testSelectBatch() {
// 1. 准备要查询的 ID 集合
List<Long> idList = new ArrayList<>();
idList.add(1L);
idList.add(3L);
idList.add(4L);
// 2. 调用批量查询方法
List<User> userList = userDao.selectBatchIds(idList);
// 3. 遍历输出结果
System.out.println("查询到的用户数量:" + userList.size());
for (User user : userList) {
System.out.println(user);
}
}
}生成的 SQL:
sqlSELECT id,name,password,age,tel FROM user WHERE id IN (1,3,4)
逻辑删除
问题引入:
先来看一个实际业务场景:
- 员工表(employee)和合同表(contract)是一对多的关系,一个员工可以签多个合同。
- 假设员工"张三"离职了,按照常规做法,我们可能会执行
DELETE操作将张三从员工表中删除。 - 但如果数据库设置了外键约束,为了保证数据完整性,还得把张三签的所有合同也一并删除。
- 问题来了:过段时间公司要统计所有合同的总金额,却发现张三的合同数据都没了,统计结果就不准确了。
反过来,如果只删除员工而不删除合同,那些合同的"员工编号"字段就变成了一个不存在的人,产生"无主数据",以后查起来都不知道是谁签的。
这个矛盾怎么解决?
最好的办法是:数据不真正删除,而是标记为"已删除"。这样既能保留历史数据,又能区分在职和离职员工。
什么是逻辑删除?
- 物理删除 :用
DELETE语句把数据从数据库中彻底移除,数据无法恢复。 - 逻辑删除 :在表中增加一个字段(比如
deleted),用该字段的值来标记这条数据是否有效。删除时只是将这个字段的值改为"已删除"状态(例如1),数据本身还在数据库中。查询时只查出未被删除的记录。
逻辑删除的本质是 修改操作(UPDATE),而不是真正的删除。
逻辑删除的实现步骤
步骤 1:为数据库表增加逻辑删除列
以 user 表为例,新增一个字段(列),用来标记是否删除。字段名可以自定义,比如 deleted,类型可以是整型(推荐 tinyint),并设置默认值为 0(表示未删除)。
sql
ALTER TABLE user ADD COLUMN deleted int(1) DEFAULT 0 COMMENT '逻辑删除:0-未删除,1-已删除';步骤 2:在实体类中添加对应属性并使用 @TableLogic 注解
java
@Data
public class User {
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private String name;
private String password;
private Integer age;
private String tel;
// 逻辑删除字段
@TableLogic(value = "0", delval = "1")
private Integer deleted;
}value = "0":表示该字段值为0时,数据为正常(未删除)。delval = "1":表示执行删除操作时,将该字段值改为1。
步骤 3:测试删除操作
java
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testDelete() {
userDao.deleteById(1L); // 逻辑删除 ID 为 1 的用户
}
}执行后观察控制台输出的 SQL:
sql
UPDATE user SET deleted=1 WHERE id=1 AND deleted=0可以发现,MP 没有执行 DELETE,而是执行了 UPDATE,将 deleted 字段改为了 1。
逻辑删除对查询的影响
当你执行查询操作时,MP 会自动在查询条件中加入 deleted=0(或你定义的其他"未删除"值),只返回未被删除的数据。
java
@Test
void testSelect() {
List<User> users = userDao.selectList(null); // 查询全部
System.out.println(users);
}运行测试,会发现打印出来的sql语句中会多一个查询条件:
sql
SELECT id,name,password,age,tel,deleted FROM user WHERE deleted=0也就是说,MP的逻辑删除会将所有的查询都添加一个 未被删除 的条件,也就是已经被删除的数据是不应该被查询出来的。
如果确实需要查询已删除的数据怎么办?
可以在 Mapper 接口中自定义方法,用 @Select 注解手写 SQL:
java
@Mapper
public interface UserDao extends BaseMapper<User> {
@Select("select * from user")
List<User> selectAllIncludeDeleted();
}
@Select("select * from user"):这是 MyBatis 提供的注解,括号内的字符串就是要执行的原生 SQL 语句。它告诉 MyBatis:当调用下面的方法时,就执行这段 SQL。
List<User> selectAllIncludeDeleted();:这是方法签名,定义了方法名、参数(这里没有)、返回值类型。
- 方法名可以任意取(但要有意义),这里叫
selectAllIncludeDeleted表示"查询所有包含已删除的用户"。- 返回值
List<User>表示查询结果会被 MyBatis 自动封装成User对象的列表。注解和方法签名绑定在一起 ------当你在代码中调用
userDao.selectAllIncludeDeleted()时,MyBatis 就会执行@Select中指定的 SQL 语句,并将查询结果映射为List<User>返回。
全局配置逻辑删除
如果每个实体类都要加 @TableLogic 注解,还是有点麻烦。MP 支持在配置文件中进行全局配置:
yaml
mybatis-plus:
global-config:
db-config:
logic-delete-field: deleted # 全局逻辑删除字段名
logic-not-delete-value: 0 # 未删除的值
logic-delete-value: 1 # 已删除的值配置后,实体类上就不需要再写 @TableLogic 了,但实体类中仍需定义对应的 deleted 属性(字段名必须与 logic-delete-field 一致)。
乐观锁
先来看一个典型的并发场景:秒杀。
假设有 100 件商品正在抢购,必须保证每件商品只能被一个人成功购买,不能出现"超卖"(即卖出的数量超过 100)。当大量用户同时发起购买请求时,如果程序处理不当,就可能出现多个请求同时读到库存为 1,然后各自"成功"扣减库存,导致最终库存变成负数。
要解决这类并发更新数据的问题,最直接的想法是加锁。但在一台服务器上用锁是有效的,如果系统部署了多台服务器(分布式),传统的单机锁就失效了。这时就需要一种能在分布式环境下保证数据一致性的机制。
乐观锁就是针对这种场景的一种轻量级解决方案。
官方文档:乐观锁插件 | MyBatis-Plus
接下来介绍的这种方式是针对于小型企业的解决方案,因为数据库本身的性能就是个瓶颈,如果对其并发量超过2000以上的就需要考虑其他的解决方案了。
实现思路
乐观锁的名字很形象:它乐观地认为数据在更新时不会被别人同时修改,所以不会像悲观锁那样一开始就加锁。但它会在更新数据的那一刻进行"检查":如果在我读取数据之后,有别人已经修改过了,那我的这次更新就失败,需要重试或放弃。
这个"检查"通常通过一个版本号字段来实现。基本流程如下:
-
给数据加一个版本号 :在数据库表中增加一个字段(比如叫
version),初始值一般为 1。 -
读取数据时,同时读取版本号 :例如,线程 A 读到一条数据,它的
version = 1。 -
更新数据时,带上版本号条件 :线程 A 要更新这条数据,它会执行类似这样的 SQL:
sqlUPDATE table SET column = 新值, version = version + 1 WHERE id = 某值 AND version = 1这条语句的意思是:
把table表中id = 某值且version = 1的那一行,将column字段改为新值,同时把这一行的version字段增加 1(变成 2)。 -
检查更新是否成功:如果这条 SQL 影响的行数为 1,说明在 A 读取数据后,没有别人修改过(版本号没变),更新成功。如果影响行数为 0,说明版本号已经变了(别人已经更新过),A 的更新失败,需要根据业务决定是重试还是放弃。
这样,通过版本号机制,就能保证并发更新时只有一个线程能成功。
实现步骤
步骤1:数据库表添加 version 列
在需要乐观锁的表中增加一个整数类型的字段,例如 version,并设置默认值为 1(或其他起始值)。
sql
ALTER TABLE user ADD COLUMN version INT DEFAULT 1;步骤2:实体类中添加 @Version 注解的属性
在对应的实体类中增加一个 Integer 类型的 version 属性,并用 @Version 注解标记。
java
@Data
//@TableName("tbl_user") 配置了全局配置可以不写
public class User {
@TableId(type = IdType.ASSIGN_ID)
private Long id;
private String name;
// ... 其他字段
@Version // 标记这是乐观锁版本字段
private Integer version;
}步骤3:配置乐观锁拦截器
乐观锁功能需要 MyBatisPlus 的拦截器支持,在配置类中添加:
java
@Configuration // 1.固定:标记这是一个配置类
public class MybatisPlusConfig { // 2.类名可以自定义,但建议见名知意
@Bean // 3.固定:将方法返回值注册为Spring的Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() { // 4.方法名可以自定义,但建议用这个
// 5.创建MybatisPlusInterceptor对象(固定),变量名可以自定义
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
// 6.添加乐观锁拦截器(固定)
interceptor.addInnerInterceptor(new OptimisticLockerInnerInterceptor());
// 如果你以后需要添加其他拦截器(如分页插件),也在这里继续添加
// interceptor.addInnerInterceptor(new PaginationInnerInterceptor());
return interceptor; // 7.返回配置好的拦截器(固定)
}
}这个拦截器会在执行更新操作时,自动为我们处理版本号的检查和递增。
步骤4:执行更新操作
使用乐观锁时,一定要先查询出要修改的数据(获取到当前的 version),然后再进行更新。
正确的做法:
java
@SpringBootTest
class Mybatisplus03DqlApplicationTests {
@Autowired
private UserDao userDao;
@Test
void testUpdate() {
// 1. 先查询出要修改的数据,此时 user 对象中包含了当前的 version 值
User user = userDao.selectById(3L);
// 2. 修改需要更新的字段
user.setName("Jock888");
// 3. 执行更新,MP 会自动拼接 version 条件并递增
userDao.updateById(user);
}
}执行时,MP 生成的 SQL 大致是:
sql
UPDATE user SET name = 'Jock888', version = version + 1 WHERE id = 3 AND version = 1错误的做法(不携带 version):
如果直接创建一个新对象设置 ID 和要修改的字段,但没有设置 version,则乐观锁不会生效,因为 MP 不知道当前的版本号是多少。
javaUser user = new User(); user.setId(3L); user.setName("Jock666"); userDao.updateById(user); // 不会触发乐观锁检查,version 也不会自动递增
模拟并发场景
我们可以用代码模拟一下两个线程同时尝试更新同一条数据的情况:
java
@Test
void testConcurrentUpdate() {
// 线程1 先查询出数据
User user1 = userDao.selectById(3L); // 假设此时 version = 1
// 线程2 也查询出同一条数据
User user2 = userDao.selectById(3L); // 也得到 version = 1
// 线程2 先更新
user2.setName("Jock aaa");
userDao.updateById(user2); // 更新成功,数据库中的 version 变为 2
// 线程1 再更新
user1.setName("Jock bbb");
userDao.updateById(user1); // 更新失败,因为此时的 SQL 条件 WHERE id=3 AND version=1 找不到记录
}执行结果:
- 线程2 的更新成功,版本号变成 2。
- 线程1 的更新因为版本号不匹配而失败,实现了乐观锁的预期效果。
快速开发:代码生成器原理
代码生成器原理分析
在实际开发中,我们会发现很多代码具有相似的结构。例如,每当我们创建一个新的数据表(如 user、book、order),都需要编写对应的实体类、Mapper接口、Service等,这些代码除了表名和字段名不同,其他部分几乎一样。
举个例子 :我们之前写的 UserDao 接口:
java
@Mapper
public interface UserDao extends BaseMapper<User> {
}如果现在要开发 Book 模块,对应的 BookDao 接口会是这样:
java
@Mapper
public interface BookDao extends BaseMapper<Book> {
}可以看到,这两段代码的结构完全一样 ,只是把 User 换成了 Book。我们把这种不变的结构称为模板 ,把变化的部分(如 User、Book)称为参数。通过模板 + 参数,就可以快速生成不同模块的代码,就像语文中的"造句填词":
- 模板:
[A] 是一位 [B] - 填入参数:
张三、学生→ 得到句子:张三是一位学生
同理,代码生成器的核心思想就是:根据数据库表结构,自动填充预设的模板,生成对应的实体类、Mapper、Service等代码。
代码生成三要素
要实现自动生成代码,需要以下三要素:
-
模板
即代码的固定结构。MyBatisPlus 已经为我们提供了现成的模板(如实体类模板、Mapper接口模板等),我们无需自己编写。当然,也可以自定义模板,但通常用官方提供的就够了。
-
数据库相关配置
代码生成器需要连接到数据库,读取表的结构(有哪些表、表名、字段名、字段类型等)。例如,根据表
user生成User实体类,根据字段name、age生成对应的属性。 -
开发者自定义配置
开发者可以指定一些个性化选项,例如:
- 主键生成策略(
AUTO、ASSIGN_ID等) - 是否使用 Lombok
- 包名、输出路径
- 要生成的表名(可以指定生成哪些表的代码)
- 主键生成策略(
代码生成器实现
步骤 1:创建一个 Maven 项目
- 操作:使用 IDE(如 IDEA)新建一个普通的 Maven 项目(或 SpringBoot 项目),用于存放生成器的代码和生成的产物。
- 目的:将代码生成器与你的业务项目分离,避免依赖混乱。
步骤 2:导入必要的依赖jar包
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.5.1</version>
</parent>
<groupId>com.itheima</groupId>
<artifactId>mybatisplus_04_generator</artifactId>
<version>0.0.1-SNAPSHOT</version>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!--spring webmvc-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--mybatisplus-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-boot-starter</artifactId>
<version>3.4.1</version>
</dependency>
<!--druid-->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<version>1.1.16</version>
</dependency>
<!--mysql-->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<!--test-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<!--lombok-->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.12</version>
</dependency>
<!--代码生成器-->
<dependency>
<groupId>com.baomidou</groupId>
<artifactId>mybatis-plus-generator</artifactId>
<version>3.4.1</version>
</dependency>
<!--velocity模板引擎-->
<dependency>
<groupId>org.apache.velocity</groupId>
<artifactId>velocity-engine-core</artifactId>
<version>2.3</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>- 注意:代码生成器和模板引擎是必须的,其他依赖可根据实际项目需求增减。
步骤 3:编写 SpringBoot 引导类(可选)
您提供的引导类是一个标准的 SpringBoot 应用入口。如果您仅仅为了运行代码生成器,其实可以不需要 这个引导类,因为生成器通常在一个独立的 main 方法中运行。但保留它也不会影响运行。
java
@SpringBootApplication
public class Mybatisplus04GeneratorApplication {
public static void main(String[] args) {
SpringApplication.run(Mybatisplus04GeneratorApplication.class, args);
}
}可选 :如果只是一个普通的 Maven Java 项目(或只包含生成器代码),只想用代码生成器,可以省略这个引导类,只需保证有正确的依赖和 CodeGenerator 类即可。
只要有 CodeGenerator 类并正确配置了依赖,直接运行它的 main 方法,代码生成器依然可以正常工作。
步骤 4:创建并配置代码生成器主类
这是最核心的一步。创建一个普通的 Java 类(例如 CodeGenerator),并在 main 方法中进行配置:
java
public class CodeGenerator {
public static void main(String[] args) {
// 1. 创建代码生成器对象
AutoGenerator autoGenerator = new AutoGenerator();
// ---------- 2. 数据库配置 ----------
DataSourceConfig dataSource = new DataSourceConfig();
dataSource.setDriverName("com.mysql.cj.jdbc.Driver");
dataSource.setUrl("jdbc:mysql://localhost:3306/mybatisplus_db?serverTimezone=UTC");
dataSource.setUsername("root");
dataSource.setPassword("root"); // 请修改为你的密码
autoGenerator.setDataSource(dataSource);
// ---------- 3. 全局配置 ----------
GlobalConfig globalConfig = new GlobalConfig();
// 设置代码输出目录 (user.dir 是当前项目根路径)
globalConfig.setOutputDir(System.getProperty("user.dir") + "/mybatisplus_04_generator/src/main/java");
globalConfig.setOpen(false); // 生成后是否打开文件夹
globalConfig.setAuthor("黑马程序员"); // 设置作者
globalConfig.setFileOverride(true); // 是否覆盖已有文件
globalConfig.setMapperName("%sDao"); // Mapper接口名模板,%s 替换为实体名,如 UserDao
globalConfig.setIdType(IdType.ASSIGN_ID); // 全局主键生成策略
autoGenerator.setGlobalConfig(globalConfig);
// ---------- 4. 包名配置 ----------
PackageConfig packageInfo = new PackageConfig();
packageInfo.setParent("com.aaa"); // 父包名,生成的代码都在此包下
packageInfo.setEntity("domain"); // 实体类子包名
packageInfo.setMapper("dao"); // Mapper接口子包名
// 还可以设置 service, controller 等子包名
autoGenerator.setPackageInfo(packageInfo);
// ---------- 5. 策略配置 ----------
StrategyConfig strategyConfig = new StrategyConfig();
strategyConfig.setInclude("tbl_user"); // 要生成的表名(可多个,如 "user", "book")
strategyConfig.setTablePrefix("tbl_"); // 表前缀,生成实体时会去除,如 tbl_user → User
strategyConfig.setRestControllerStyle(true); // 生成 @RestController 控制器
strategyConfig.setVersionFieldName("version"); // 乐观锁字段名
strategyConfig.setLogicDeleteFieldName("deleted"); // 逻辑删除字段名
strategyConfig.setEntityLombokModel(true); // 启用 Lombok
autoGenerator.setStrategy(strategyConfig);
// 6. 执行生成
autoGenerator.execute();
}
}说明:
globalConfig.setMapperName("%sDao")
- 作用 :设置 Mapper 接口(数据访问层接口)的命名模板。
- 理解 :
%s是一个占位符,会被替换为实体类的简单名称 (不含包名)。例如:- 如果实体类叫
User,那么生成的 Mapper 接口名就是UserDao。 - 如果你改成
"%sMapper",则会生成UserMapper。
- 如果实体类叫
- 目的 :统一项目中数据层接口的命名风格(比如有些项目喜欢用
XxxDao,有些喜欢用XxxMapper)。
strategyConfig.setTablePrefix("tbl_")
- 作用 :指定数据库表的公共前缀,生成实体类时会自动去掉这个前缀。
- 理解 :如果你的数据库表名都以
tbl_开头(例如tbl_user、tbl_order),设置这个前缀后:- 表
tbl_user→ 生成实体类User(不再包含tbl_)。 - 表
tbl_order→ 生成实体类Order。
- 表
- 好处:让实体类名更简洁、更符合 Java 的类命名习惯,同时保留了数据库表的规范前缀。
strategyConfig.setRestControllerStyle(true)
- 作用 :控制生成的 Controller 类是否使用 REST 风格。
- 理解 :
- 如果设置为
true,生成的 Controller 类上会添加@RestController注解。这意味着类中所有方法的返回值都会直接作为 HTTP 响应体返回(适合前后端分离的 API 开发)。 - 如果设置为
false(或不设置),则会生成@Controller注解,通常配合视图解析器返回页面(适合传统 MVC 应用)。
- 如果设置为
- 示例 :
true:@RestController public class UserController { ... }false:@Controller public class UserController { ... }
步骤 5:运行程序
- 操作 :直接运行
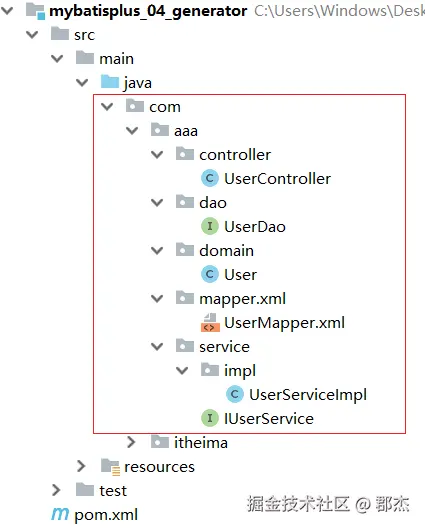
CodeGenerator类的main方法。 - 结果 :控制台会输出生成过程,并在您指定的目录下(例如
.../src/main/java/com/aaa/...)生成以下代码结构:
包名配置PackageConfig 详解
PackageConfig 是一个专门用来设置生成代码的包名 的配置类。通过它,你可以自定义代码的包结构,使生成的代码符合你项目的分层规范。
核心方法解释
| 方法 | 作用 | 示例值 | 含义 |
|---|---|---|---|
setParent("com.aaa") |
设置父包名 | "com.aaa" |
所有生成的代码都将在 com.aaa 包及其子包下。 |
setEntity("domain") |
设置实体类子包名 | "domain" |
实体类会放在 com.aaa.domain 包中。 |
setMapper("dao") |
设置Mapper接口子包名 | "dao" |
Mapper接口会放在 com.aaa.dao 包中。 |
(未展示) setService("service") |
设置Service接口子包 | "service" |
会放在 com.aaa.service 包。 |
(未展示) setServiceImpl("service.impl") |
设置Service实现类子包 | "service.impl" |
放在 com.aaa.service.impl。 |
(未展示) setController("controller") |
设置Controller子包 | "controller" |
放在 com.aaa.controller。 |
(未展示) setXml("mapper") |
设置Mapper XML文件子包 | "mapper" |
放在 com.aaa.mapper(针对XML文件)。 |
上面示例中,最终生成的包结构示例
按照示例中的配置:
- 父包:
com.aaa - 实体包子包:
domain - Mapper接口子包:
dao
假设生成针对表 tbl_user 的代码,最终的文件位置如下:
text
src/main/java
└── com
└── aaa
├── domain // 实体类包
│ └── User.java
└── dao // Mapper接口包
└── UserDao.java如果还配置了 service、controller,则会有相应的子包。
MP 中 Service 层的 CRUD 简化
官方文档:持久层接口 | MyBatis-Plus
在传统的业务层(Service)开发中,我们通常需要自己编写接口和实现类,然后在实现类中注入 Mapper,并调用其方法来完成业务操作。例如:
java
// 传统 Service 接口
public interface UserService {
public List<User> findAll();
}
// 传统 Service 实现类
@Service
public class UserServiceImpl implements UserService {
@Autowired
private UserDao userDao;
public List<User> findAll() {
return userDao.selectList(null);
}
}这些代码在每一个 Service 中都非常相似:几乎都是简单的增删改查方法。于是 MyBatisPlus 为我们提供了一个通用的 Service 层基础实现,让我们能够省去这些重复劳动。
MP 提供的 Service 基础接口和实现类
MyBatisPlus 提供了两个核心的 Service 层基础组件:
IService<T>:一个通用的 Service 接口,定义了常用的 CRUD 方法。ServiceImpl<M extends BaseMapper<T>, T>:IService接口 的实现类,实现了所有通用方法,并注入了对应的 Mapper。
ServiceImpl的两个泛型:第一个是对应的 Mapper 接口类型(如UserDao),第二个是实体类类型(如User)。
我们自己的 Service 只需要继承这些基础组件,就能直接获得大量现成的方法。
改造后的代码
java
// 自定义 Service 接口,继承 IService,泛型为实体类
public interface UserService extends IService<User> {
// 这里可以额外定义自己的业务方法
}
// 自定义 Service 实现类,继承 ServiceImpl,并实现自己的接口
@Service
public class UserServiceImpl extends ServiceImpl<UserDao, User> implements UserService {
// 不需要再写基础的 CRUD 方法,它们已经由父类提供
}改造后的好处:
- 无需再手动编写基础 CRUD :
IService中已经定义了save、remove、update、get、list、page等一系列方法,可以直接通过userService调用。- 代码更简洁:实现类中不再需要注入 Mapper 并编写简单的调用代码,减少了冗余。
- 易于扩展:自己的业务方法仍然可以在接口中定义,在实现类中实现,与 MP 提供的方法共存。
测试示例
配置好环境后,可以直接在测试类中使用:
java
@SpringBootTest
class Mybatisplus04GeneratorApplicationTests {
@Autowired
private UserService userService; // 注入自定义的 Service
@Test
void testFindAll() {
// 使用 IService 提供的 list() 方法查询所有
List<User> list = userService.list();
System.out.println(list);
}
}注意:mybatisplus_04_generator项目中对于MyBatis的环境是没有进行配置,如果想要运行,需要提取将配置文件中的内容进行完善后在运行。
在MP封装的Service层中的方法
IService 提供了非常丰富的方法,例如:
- 增 :
save(T entity)、saveBatch(Collection<T> entityList) - 删 :
removeById(Serializable id)、removeByMap(Map<String, Object> columnMap) - 改 :
updateById(T entity)、update(T entity, Wrapper<T> updateWrapper) - 查单条 :
getById(Serializable id)、getOne(Wrapper<T> queryWrapper) - 查列表 :
list()、list(Wrapper<T> queryWrapper) - 分页 :
page(IPage<T> page) - 计数 :
count()
注意:在MP封装的Service层中的方法的方法名与 Mapper 层略有不同,但功能类似,具体可以参考官方文档。