本章涵盖以下内容
- 理解张量------PyTorch 中的基础数据结构
- 对张量进行索引与运算
- 与 NumPy 多维数组进行互操作
- 将计算迁移到 GPU 上以提升速度
在上一章中,我们概览了深度学习所能实现的众多应用。这些应用无一例外,都是以某种形式的数据作为输入------例如图像或文本------然后输出另一种形式的数据------例如标签、数值,或者更多的图像与文本。从这个角度来看,深度学习其实就是在构建一个系统,使它能够把数据从一种表示形式转换成另一种表示形式。驱动这种转换的,是系统通过大量样本发现我们想要实现的那种"输入到输出"的对应模式。比如,系统可能会注意到狗的大致轮廓,以及金毛猎犬常见的颜色。把这两种图像属性结合起来之后,系统就可以正确地把具有特定形状和颜色的图像映射为"golden retriever(金毛猎犬)"这个标签,而不是 "black lab(黑色拉布拉多)"------当然,也不是一只黄褐色的公猫。最终得到的系统,便能够处理大范围的相似输入,并为这些输入产出有意义的输出。
这个过程的起点,是把我们的输入转换成浮点数。在本章中,我们会讲到如何把图像像素转换成数值;但在此之前,我们需要先学习如何在 PyTorch 中借助张量来处理所有这些浮点数。张量是深度学习框架中的基础数据结构,而 PyTorch 为操作张量提供了丰富的 API,那么我们现在就开始吧。
3.1 以浮点数来理解世界
既然浮点数是网络处理信息的方式,那么我们就需要一种办法:先把我们想处理的现实世界数据编码成网络能够"消化"的形式,再把网络输出解码回我们能够理解、并能为自身目的所用的形式。
一个深度神经网络,通常会分阶段地学习把一种形式的数据转换成另一种形式。这意味着,在每一个阶段之间,那些被部分转换过的数据,可以被看作是一系列中间表示(intermediate representations),如图 3.1 所示。以图像识别为例,较浅层的表示可能是边缘检测结果,或者像毛发那样的某些纹理;更深层的表示,则可以捕捉更复杂的结构,例如耳朵、鼻子或者眼睛。
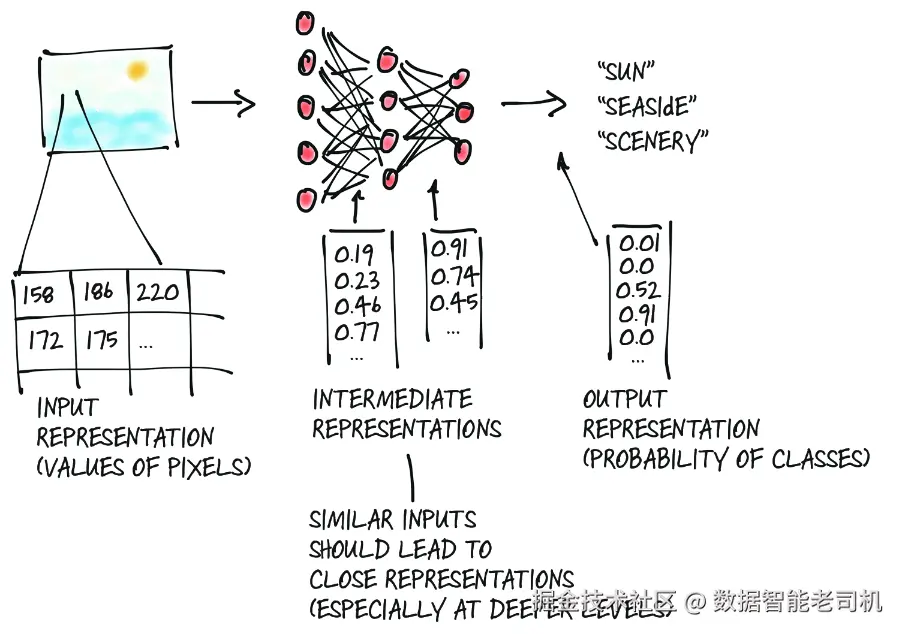
图 3.1 深度神经网络学习如何把输入表示转换为输出表示。注意:图中的神经元数量和输出数量并非按比例绘制。
一般来说,这些中间表示就是一组浮点数的集合,它们对输入进行刻画,并以一种有助于描述"神经网络如何将输入映射为输出"的方式来捕捉数据结构。这种刻画是与具体任务相关的,并且是通过相关样本学习得到的。正是这些浮点数组合,以及对它们的操作,构成了现代 AI 的核心------在本书中,我们会反复看到这方面的例子。
需要牢记的一点是,这些中间表示(例如图 3.1 第二步中展示的那些)是把输入与前一层神经元的权重相结合之后得到的结果。每一个中间表示,都是对其前面输入的独特响应。
在我们真正开始把数据转换成浮点数输入之前,首先必须扎实理解 PyTorch 是如何处理和存储数据的------无论这些数据是作为输入、中间表示,还是输出存在。本章将专门讨论这一点。
为此,PyTorch 引入了一种基础数据结构:tensor(张量) 。在第 2 章中,当我们在预训练网络上运行推理时,就已经接触过张量。如果你有数学或物理背景,也许你对 tensor 这个词有另一种理解;但在深度学习中,张量指的是向量和矩阵向任意维度的推广,如图 3.2 所示。与之对应的另一个名字是多维数组(multidimensional array) ;对于熟悉 NumPy 的人来说,它也可以叫作 ndarray 。张量的维数,等于我们用来索引其中标量值所需的索引个数。各个维度采用从 0 开始的编号方式,并且按照从左到右的顺序排列。例如,图中的那个三维张量包含四组 3 × 3 的数组,因此它的形状(shape)就是 (4, 3, 3)。我们把最左边那个大小为 4 的维度称为第 0 维 ,第二个大小为 3 的维度称为第 1 维,以此类推。
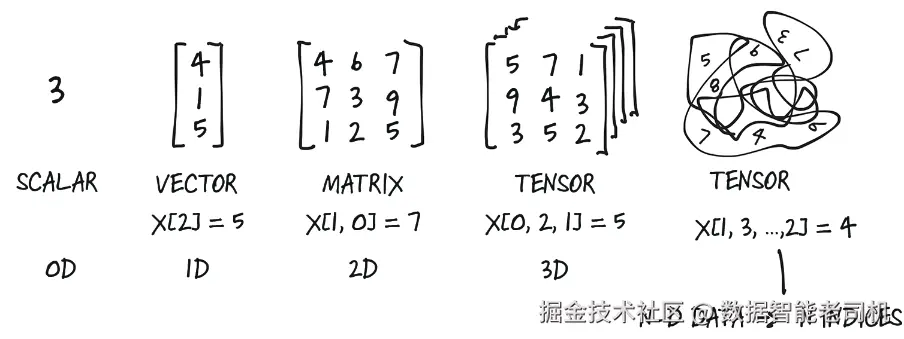
图 3.2 张量是 PyTorch 中用于表示数据的基本构件。标量、向量和矩阵,也都可以被视为张量。
PyTorch 并不是唯一处理多维数组的库。NumPy 是迄今为止最流行的多维数组库,流行到它几乎已经成为数据科学的"通用语言"。PyTorch 与 NumPy 之间具有无缝互操作能力,而这也让它能够与 Python 生态中的其他科学计算库实现一级集成,例如 SciPy(www.scipy.org/)、Scikit-learn(scikit-learn.org)以及 pandas(pandas.pydata.org)。
与 NumPy 数组相比,PyTorch 张量拥有一些"超能力",例如能够在图形处理器(GPU)上执行极快的运算、能够把运算分布到多个设备或多台机器上,以及能够追踪创建它们的计算图。这些都是实现现代深度学习库时非常关键的特性。
本章我们将从介绍 PyTorch 张量开始,为本书后续内容打下基础。首先,我们会学习如何使用 PyTorch 的张量库来操作张量,包括:数据在内存中是如何存储的、为什么某些操作可以在常数时间内作用于任意大的张量、前面提到的 NumPy 互操作能力,以及 GPU 加速。只有真正理解了张量的能力与 API,张量才会成为你编程工具箱中的常用工具。下一章中,我们就会把这些知识用起来,学习如何以适合神经网络学习的方式来表示多种不同类型的数据。
3.2 张量:多维数组
我们已经知道,张量是 PyTorch 中的基础数据结构。张量是一种数组------也就是说,它是一种用于存储一组数值的数据结构,其中每个数值都可以通过索引单独访问;而且,张量还可以通过多个索引来访问。
3.2.1 从 Python 列表到 PyTorch 张量
先来看看列表索引是如何工作的,这样我们就可以把它和张量索引进行对比。假设有一个包含三个数字的 Python 列表(code/p1ch3/1_tensors.ipynb):
ini
# In[1]:
a = [1.0, 2.0, 1.0]我们可以使用对应的、从 0 开始的索引来访问列表的第一个元素:
less
# In[2]:
a[0]
# Out[2]:
1.0
less
# In[3]:
a[2] = 3.0
a
# Out[3]:
[1.0, 2.0, 3.0]对于一些处理数字向量的简单 Python 程序------例如处理二维直线坐标------使用 Python 列表来存储这些向量并不罕见。正如我们将在下一章看到的那样,借助效率更高的张量数据结构,许多类型的数据------从图像到时间序列,甚至句子------都可以被表示出来。通过定义作用于张量的各种运算(本章会探索其中一些),我们既可以用富有表达力的方式切片和操作数据,又能保持高效;哪怕所使用的是像 Python 这样一种高级语言(而且它本身并不算快)。
3.2.2 构造我们的第一个张量
下面来构造我们的第一个 PyTorch 张量,看看它长什么样。暂时它还不会是一个特别有意义的张量,只是竖着排的三个 1:
ini
# In[4]:
import torch #1
a = torch.ones(3) #2
a
# Out[4]:
tensor([1., 1., 1.])
# In[5]:
a[1] #3
# Out[5]:
tensor(1.)
# In[6]:
float(a[1])
# Out[6]:
1.0
# In[7]:
a[2] = 2.0 #4
a
# Out[7]:
tensor([1., 1., 2.])
#1 导入 torch 模块
#2 创建一个大小为 3、并全部用 1 填充的一维张量
#3 从张量中索引出一个元素
#4 给张量中的某个元素赋一个新值在导入 torch 模块之后,我们调用了一个函数,创建了一个大小为 3、全部填充为 1.0 的(一维)张量。我们可以使用从 0 开始的索引访问其中的元素,也可以给某个元素赋一个新值。虽然从表面上看,这个例子与一个由数字对象组成的列表并没有太大区别,但在底层,它们其实完全不同。
3.2.3 张量的本质
由数字组成的 Python 列表或元组,本质上是一组 Python 对象的集合,这些对象会分别在内存中独立分配,如图 3.3 左侧所示。而 PyTorch 张量或 NumPy 数组,则是对一块(通常)连续内存区域的视图,这块内存中存放的是未经装箱的 C 数值类型,而不是 Python 对象。张量是同质的(homogeneous) ,也就是说,其中所有元素都具有相同的数据类型。在本例中,每个元素都是一个 32 位(4 字节)的浮点数,这一点可以从图右侧看出来。所以,存储一个包含 100 万个浮点数的一维张量,恰好需要 400 万个连续字节,再加上一点点元数据开销(例如维度信息和数值类型)。
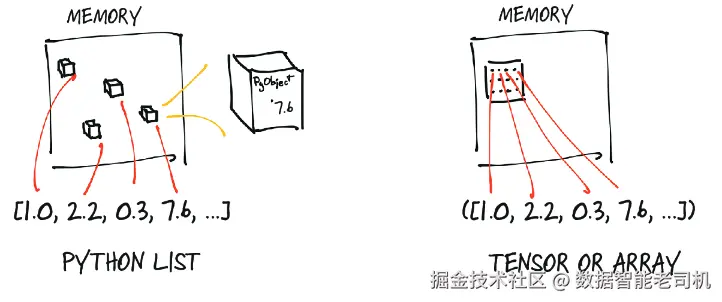
图 3.3 Python 对象(装箱)数值 vs. 张量(未装箱数组)数值
假设我们有一组坐标,想用来表示一个几何对象:比如一个二维三角形,它的三个顶点分别位于坐标 (4, 1)、(5, 3) 和 (2, 1)。这个例子和深度学习本身关系不大,但它很直观,容易跟上。与其像前面那样把坐标作为 Python 列表中的数字来存储,不如使用一个一维张量:把所有 X 坐标放在偶数索引处,把所有 Y 坐标放在奇数索引处,如下所示:
ini
# In[8]:
points = torch.zeros(6) #1
points[0] = 4.0 #2
points[1] = 1.0
points[2] = 5.0
points[3] = 3.0
points[4] = 2.0
points[5] = 1.0
#1 使用 .zeros 只是为了得到一个大小合适的数组。
#2 然后我们用自己想要的值覆盖这些 0。我们也可以直接把一个 Python 列表传给构造函数,效果是一样的:
ini
# In[9]:
points = torch.tensor([4.0, 1.0, 5.0, 3.0, 2.0, 1.0])
points
# Out[9]:
tensor([4., 1., 5., 3., 2., 1.])要获取第一个点的坐标,可以这样做:
bash
# In[10]:
float(points[0]), float(points[1])
# Out[10]:
(4.0, 1.0)这种写法当然可以工作,但如果第一个索引能直接对应一个二维点,而不是点的单个坐标,那会更实用。为此,我们可以使用一个二维张量:
lua
# In[11]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points
# Out[11]:
tensor([[4., 1.],
[5., 3.],
[2., 1.]])这里,我们向构造函数传入的是一个"列表的列表"。我们还可以向这个张量询问它的形状:
ini
# In[12]:
points.shape
# Out[12]:
torch.Size([3, 2])这会告诉我们:张量在每个维度上的大小分别是多少。我们也可以使用 zeros 或 ones 来初始化张量,并把尺寸作为参数传入:
ini
# In[13]:
points = torch.zeros(3, 2)
points
# Out[13]:
tensor([[0., 0.],
[0., 0.],
[0., 0.]])现在,我们就可以使用两个索引来访问张量中的某个单独元素:
ini
# In[14]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points
# Out[14]:
tensor([[4., 1.],
[5., 3.],
[2., 1.]])
# In[15]:
points[0, 1]
# Out[15]:
tensor(1.)这段代码返回的是我们数据集中第 0 个点的 Y 坐标。我们也可以像前面那样,只访问张量中的第一个元素,以获取第一个点的二维坐标:
ini
# In[16]:
points[0]
# Out[16]:
tensor([4., 1.])这里的输出仍然是另一个张量,只不过它是对同一底层数据的一种不同视图。这个新张量是一个大小为 2 的一维张量,引用的是 points 张量第一行中的那两个值。这是否意味着:系统新分配了一块内存,把数值复制进去,再把这块新内存包装成一个新的张量对象返回给我们?答案是否定的,因为那样会非常低效,尤其是在我们有数百万个点的时候。稍后在本章讲到第 3.8 节"张量视图"时,我们会回过头来详细讨论张量在内存中的存储方式。
3.3 张量索引
如果我们想得到一个包含"除第一个点之外所有点"的张量,该怎么办?这很容易,只需要使用区间索引(range indexing)记法即可;这种记法同样适用于标准 Python 列表。先快速回顾一下:
ini
# In[53]:
some_list = list(range(6))
some_list[:] #1
some_list[1:4] #2
some_list[1:] #3
some_list[:4] #4
some_list[:-1] #5
some_list[1:4:2] #6
#1 列表中的所有元素
#2 从元素 1(含)到元素 4(不含)
#3 从元素 1(含)到列表末尾
#4 从列表开头到元素 4(不含)
#5 从列表开头到倒数第一个元素之前
#6 从元素 1(含)到元素 4(不含),步长为 2为了实现我们的目标,我们可以对 PyTorch 张量使用完全相同的记法。而且,和 NumPy 及其他 Python 科学计算库一样,PyTorch 还允许我们对张量的每一个维度分别使用区间索引:
ini
# In[54]:
points[1:] #1
points[1:, :] #2
points[1:, 0] #3
points[None] #4
#1 第一行之后的所有行;列默认全部保留
#2 第一行之后的所有行;所有列
#3 第一行之后的所有行;第一列
#4 增加一个大小为 1 的维度;同样的效果也可以用 points.unsqueeze(dim=0) 实现除了使用区间之外,PyTorch 还支持一种强大的索引形式,叫作高级索引(advanced indexing);我们会在下一章中讨论它。
3.4 广播机制
PyTorch 张量支持的一项重要特性,是继承自 NumPy 的广播语义(broadcasting semantics)。广播是一种机制,它通过允许不同形状的张量之间进行高效的逐元素计算,从而简化复杂的张量运算。
在广播过程中,各维度会从右到左逐一比较。如果对应维度彼此兼容,那么这些张量就可以广播到一起。所谓兼容的维度,是指:
维度大小相等;
其中一个维度的大小为 1。
下面是一个用标量演示的例子。在这里,标量值会应用到张量中的所有元素上:
lua
张量 X: 标量 Y:
[[ 1 2 3 ]] + 10
结果(广播后的标量加法):
[[ 11 12 13 ]]另一方面,当一个 1 × 3 张量与一个 3 × 1 张量相乘时,我们逐个维度进行匹配,会发现它们是兼容的。第一个张量的第一个维度是 1,而第二个张量的第二个维度是 1。因此,这两个张量可以广播到一起,结果会是一个 3 × 3 张量:
lua
3 x 1
1 x 3
------
3 x 3
张量 A: 张量 B:
[[ 1 2 3 ]] [[10]
* [20]
[30]]
结果(广播后的乘法):
[[ 10 20 30 ]
[ 20 40 60 ]
[ 30 60 90 ]]当张量维度数不同的时候,我们会先把它们的形状按右侧对齐。若对应维度匹配,就按元素执行运算;若其中一个维度为 1,则可以把该维度上的数值理解为被"虚拟复制"了,以匹配更大的那个维度。来看一个 2 × 1 × 3 与 2 × 3 的例子:
lua
2 x 3
2 x 1 x 3
----------
2 x 2 x 3
矩阵 A: 张量 B:
[[ 1 2 3 ] [[[10 20 30]]
+
[ 4 5 6 ]] [[40 50 60]]]
结果(广播后的张量加法):
[[[ 11 22 33 ]
[ 44 55 66 ]]
[[ 41 52 63 ]
[ 44 55 66 ]]]我们这里只是快速走了一遍广播机制;到第 5 章时,我们还会进一步练习它。
3.5 命名张量
我们的张量维度(或者说轴)通常会索引诸如像素位置、颜色通道之类的内容。因此,当我们要对一个张量做索引时,就必须记住各个维度的排列顺序,并据此写出正确的索引方式。随着数据在多个张量之间不断变换,跟踪"到底哪个维度存放的是什么数据"就很容易出错。
为了把这个问题说得更具体一点,设想我们有一个像第 2.1.4 节中 img_t 那样的三维张量(为了简单起见,这里我们使用虚拟数据),并且我们想把它转换成灰度图。我们查到了一组常见的颜色权重,用来把 RGB 三个通道压缩成一个亮度值:
ini
# In[2]:
img_t = torch.randn(3, 5, 5) # 形状 [channels, rows, columns]
weights = torch.tensor([0.2126, 0.7152, 0.0722])与此同时,我们通常也希望代码具备一定的泛化能力。例如,从用二维张量(高度 × 宽度)表示的灰度图,推广到增加第三个通道维度的彩色图(如 RGB);或者从单张图像推广到一个图像 batch。在第 2.1.4 节中,我们曾在 batch_t 里额外引入一个 batch 维度;这里,我们假装自己有一个大小为 2 的 batch:
ini
# In[3]:
batch_t = torch.randn(2, 3, 5, 5) # 形状 [batch, channels, rows, columns]因此,有时候 RGB 通道位于第 0 维,有时候则位于第 1 维。但我们可以通过从末尾往前数来统一处理:它们总是位于第 -3 维,也就是倒数第三维。于是,那种偷懒的、未加权的平均就可以写成:
ini
# In[4]:
img_gray_naive = img_t.mean(-3)
batch_gray_naive = batch_t.mean(-3)
img_gray_naive.shape, batch_gray_naive.shape
# Out[4]:
(torch.Size([5, 5]), torch.Size([2, 5, 5]))但现在我们手里还有一组权重。回忆一下广播机制:PyTorch 允许我们相乘的对象既可以形状完全相同,也可以是在某个维度上其中一个操作数大小为 1 的形状。它还会自动在前面补上大小为 1 的缺失维度。形状为 (2, 3, 5, 5) 的 batch_t 与形状为 (3, 1, 1) 的 unsqueezed_weights 相乘,结果得到一个形状仍为 (2, 3, 5, 5) 的张量;然后我们再沿着倒数第三个维度(也就是那三个通道)求和:
ini
# In[5]:
unsqueezed_weights = weights.unsqueeze(-1).unsqueeze_(-1)
img_weights = img_t * unsqueezed_weights
batch_weights = batch_t * unsqueezed_weights
img_gray_weighted = img_weights.sum(-3)
batch_gray_weighted = batch_weights.sum(-3)
batch_weights.shape, batch_t.shape, unsqueezed_weights.shape
# Out[5]:
(torch.Size([2, 3, 5, 5]), torch.Size([2, 3, 5, 5]), torch.Size([3, 1, 1]))正如我们所看到的那样,如果不把整个计算过程倒推回去,单看张量本身,很难一眼看出这些维度到底分别表示什么。这种方式很容易出错,尤其是当张量的创建位置与使用位置在代码中相隔很远的时候。这个问题也引起了实践者的关注,于是有人提出,不妨直接给维度起上名字(参见 Sasha Rush 的文章 "Tensor Considered Harmful",Harvard NLP,nlp.seas.harvard.edu/NamedTensor)。
PyTorch 1.3 将命名张量 (named tensors)作为一个原型特性加入了框架中(参见 pytorch.org/docs/stable...)。像 tensor 和 rand 这样的张量工厂函数都接受一个 names 参数。这个 names 应该是一个字符串序列:
ini
# In[7]:
weights_named = torch.tensor([0.2126, 0.7152, 0.0722], names=['channels'])
weights_named
# Out[7]:
tensor([0.2126, 0.7152, 0.0722], names=('channels',))如果我们已经有了一个张量,并且只是想给它加上名字(而不改动已有名字),可以调用它的 refine_names 方法。与索引类似,省略号 ... 允许你省略任意数量的维度。借助它的姊妹方法 rename,你还可以覆盖已有名称,或者通过传入 None 来删除它们:
css
# In[8]:
img_named = img_t.refine_names(..., 'channels', 'rows', 'columns')
batch_named = batch_t.refine_names(..., 'channels', 'rows', 'columns')
print("img named:", img_named.shape, img_named.names)
print("batch named:", batch_named.shape, batch_named.names)
# Out[8]:
img named: torch.Size([3, 5, 5]) ('channels', 'rows', 'columns')
batch named: torch.Size([2, 3, 5, 5]) (None, 'channels', 'rows', 'columns')对于有两个输入的运算,除了原本那套维度检查规则------比如大小是否相同,或其中一个是否为 1 从而可以广播到另一个------之外,PyTorch 现在还会替我们检查名称是否匹配。不过,截至目前,它还不会自动对齐维度顺序,因此这一步我们仍需手动完成。align_as 方法会返回一个张量:它会补上缺失的维度,并把已有维度调整到正确顺序:
css
# In[9]:
weights_aligned = weights_named.align_as(img_named)
weights_aligned.shape, weights_aligned.names
# Out[9]:
(torch.Size([3, 1, 1]), ('channels', 'rows', 'columns'))那些接受维度参数的函数,例如 sum,现在也支持按名称指定维度:
bash
# In[10]:
gray_named = (img_named * weights_aligned).sum('channels')
gray_named.shape, gray_named.names
# Out[10]:
(torch.Size([5, 5]), ('rows', 'columns'))如果我们试图把名字不同的维度组合在一起,就会报错:
sql
gray_named = (img_named[..., :3] * weights_named).sum('channels')
RuntimeError: Error when
attempting to broadcast dims ['channels', 'rows',
'columns'] and dims ['channels']: dim 'columns' and dim 'channels'
are at the same position from the right but do not match.如果我们想在那些不支持命名张量的函数外部使用这些张量,就需要把名称去掉,也就是把它们重命名为 None。下面这一步会让我们重新回到"无名维度"的世界中:
ini
# In[12]:
gray_plain = gray_named.rename(None)
gray_plain.shape, gray_plain.names
# Out[12]:
(torch.Size([5, 5]), (None, None))考虑到这个特性在本书写作时仍然带有实验性质,而且为了避免在索引和对齐问题上绕来绕去,本书接下来的部分仍将使用无名张量。不过,命名张量确实有潜力消除很多对齐错误的来源;而如果 PyTorch 论坛上的讨论能说明什么,那就是这类错误确实经常令人头疼。命名张量未来能被多大范围地采用,会是一件很值得观察的事情。
3.6 张量元素类型
到目前为止,我们已经讲了张量如何工作的基本机制,但还没有真正涉及:一个 Tensor 里究竟可以存储哪些数值类型。正如我们在第 3.2 节中已经暗示过的,直接使用标准 Python 数值类型,在若干方面都不是最优选择:
Python 里的数字本质上是对象。比如,一个浮点数在计算机里也许只需要 32 位来表示,但 Python 会把它包装成一个完整的 Python 对象,附带引用计数等机制。这种操作称为装箱(boxing) 。如果我们只需要存储少量数字,这不是问题;但一旦要分配数百万个这样的对象,效率就会变得非常低。
Python 列表是为对象的顺序集合设计的。比如,列表并没有定义"高效地计算两个向量的点积"或"将两个向量相加"这类操作。此外,Python 列表也无法优化其内容在内存中的布局,因为它本质上只是一个可索引的指针集合,这些指针指向任意类型的 Python 对象,而不仅仅是数字。最后,Python 列表本身是一维的;虽然我们可以创建"列表的列表",但这种方式同样效率不高。
与经过优化并编译好的代码相比,Python 解释器是很慢的。对大规模数值数据集合执行数学运算时,如果改用 C 这类低级编译型语言编写的优化代码,速度往往会快得多。
正因如此,数据科学库通常要么依赖 NumPy,要么引入像 PyTorch 张量这样的专用数据结构:它们在底层提供高效的数值数据结构及其相关操作的实现,并在上层封装出一个易用的高级 API。为了支持这种结构,张量中的对象必须全部是同一种类型的数值,而 PyTorch 也必须跟踪这种数值类型。
3.6.1 使用 dtype 指定数值类型
张量构造函数(也就是像 tensor、zeros、ones 这样的函数)中的 dtype 参数,用来指定张量中所包含数值的数据类型(data type) 。数据类型决定了张量能够保存哪些值(例如整数还是浮点数),以及每个值占用多少字节(对于 uint8 这类类型,还涉及有符号还是无符号)。dtype 参数的设计刻意与 NumPy 中同名的标准参数保持一致。
PyTorch 支持 12 种不同的 dtype:
torch.float32 或 torch.float ------ 32 位浮点数
torch.float64 或 torch.double ------ 64 位双精度浮点数
torch.complex64 或 torch.cfloat ------ 64 位复数
torch.complex128 或 torch.cdouble ------ 128 位复数
torch.float16 或 torch.half ------ 16 位半精度浮点数
torch.bfloat16 ------ brain float 16 位、半精度浮点数(这是 Google 于 2019 年引入的一种新数据类型。它与 torch.float16 类似,但采用了不同的编码方式,能表示更大的数值范围;而 float16 在精度方面通常更有优势。)
torch.int8 ------ 有符号 8 位整数
torch.uint8 ------ 无符号 8 位整数
torch.int16 或 torch.short ------ 有符号 16 位整数
torch.int32 或 torch.int ------ 有符号 32 位整数
torch.int64 或 torch.long ------ 有符号 64 位整数
torch.bool ------ 布尔值
张量的默认数据类型是 32 位浮点数。
3.6.2 各得其所的 dtype
正如我们会在后续章节看到的,神经网络中的计算通常都是以 32 位浮点精度 执行的。更高精度(比如 64 位)并不会带来模型精度上的提升,反而会消耗更多内存和计算时间。如果有需要,也可以切换到 16 位半精度浮点数,从而降低神经网络模型的内存占用,而对精度的影响通常较小。
张量还可以被用作其他张量的索引。在这种情况下,PyTorch 期望作为索引的张量具有 64 位整型 数据类型。比如,用整数参数创建张量------例如 torch.tensor([2, 2]) ------默认得到的就是一个 64 位整数张量。因此,在大多数时候,我们主要会和 float32 与 int64 打交道。
最后,作用于张量的谓词表达式,例如 points > 1.0,会产生一个 bool 张量,用来表明每一个元素是否满足该条件。张量中的数值类型,概括起来大致就是这些。
3.6.3 管理张量的 dtype 属性
要分配一个正确数值类型的张量,我们可以直接在构造函数中用参数指定合适的 dtype。例如:
ini
# In[47]:
double_points = torch.ones(10, 2, dtype=torch.double)
short_points = torch.tensor([[1, 2], [3, 4]], dtype=torch.short)我们也可以通过访问相应属性来查看一个张量的 dtype:
bash
# In[48]:
short_points.dtype
# Out[48]:
torch.int16我们还可以先创建一个张量,再使用相应的类型转换方法,把它转换为正确的类型,例如:
ini
# In[49]:
double_points = torch.zeros(10, 2).double()
short_points = torch.ones(10, 2).short()或者使用更方便的 to 方法:
ini
# In[50]:
double_points = torch.zeros(10, 2).to(torch.double)
short_points = torch.ones(10, 2).to(dtype=torch.short)在底层,to 会先检查这种转换是否真的有必要;如果有必要,再执行转换。像 float 这类以 dtype 命名的类型转换方法,其实只是 to 的简写形式。不过,to 还能接受其他附加参数,我们会在第 3.9 节中讨论它们。
当运算中混用了不同输入类型时,输入会被自动转换为更大的类型。因此,如果我们希望整个计算保持在 32 位精度,就必须确保所有输入都至多是 32 位:
ini
# In[51]:
points_64 = torch.rand(5, dtype=torch.double) #1
points_short = points_64.to(torch.short)
points_64 * points_short
# Out[51]:
tensor([0., 0., 0., 0., 0.], dtype=torch.float64)
#1 rand 会把张量元素初始化为 0 到 1 之间的随机数。3.7 张量 API
到这里,我们已经知道 PyTorch 张量是什么,以及它们在底层是如何工作的。在结束之前,很值得看一看 PyTorch 为张量提供了哪些操作。当然,把所有操作逐一列在这里并没有太大意义。相反,我们更想建立一种对整体 API 的感觉,并顺带说明:当你需要具体信息时,应该去官方在线文档的什么位置寻找,网址是 pytorch.org/docs。
首先,绝大多数作用于张量或张量之间的操作,都既可以通过 torch 模块来调用,也可以作为张量对象的方法来调用。例如,transpose 函数既可以通过 torch 模块这样使用:
ini
# In[71]:
a = torch.ones(3, 2)
a_t = torch.transpose(a, 0, 1)
a.shape, a_t.shape
# Out[71]:
(torch.Size([3, 2]), torch.Size([2, 3]))也可以作为张量 a 的一个方法来调用:
ini
# In[72]:
a = torch.ones(3, 2)
a_t = a.transpose(0, 1)
a.shape, a_t.shape
# Out[72]:
(torch.Size([3, 2]), torch.Size([2, 3]))这两种写法没有任何区别,可以完全互换使用。
前面我们已经提到过在线文档(pytorch.org/docs)。它内容非常全面,而且组织得很好;其中张量操作被划分成若干类别:
Creation ops(创建操作) ------ 用于构造张量的函数,例如 ones 和 from_numpy
Indexing, slicing, joining, mutating ops(索引、切片、拼接、修改操作) ------ 用于改变张量形状、步幅或内容的函数,例如 transpose
Math ops(数学操作) ------ 用于通过计算来操作张量内容的函数
Pointwise ops(逐点操作) ------ 对每个元素独立应用某个函数,从而得到新张量的操作,例如 abs 和 cos
Reduction ops(归约操作) ------ 通过遍历张量来计算聚合值的函数,例如 mean、std 和 norm
Comparison ops(比较操作) ------ 用于对张量执行数值谓词判断的函数,例如 equal 和 max
Spectral ops(谱域操作) ------ 在频域中进行变换与运算的函数,例如 stft 和 hamming_window
Other operations(其他操作) ------ 一些作用于向量(如 cross)或矩阵(如 trace)的特殊函数
BLAS and LAPACK operations(BLAS 与 LAPACK 操作) ------ 遵循 Basic Linear Algebra Subprograms(BLAS)规范的函数,涵盖标量、向量---向量、矩阵---向量以及矩阵---矩阵运算
Random sampling(随机采样) ------ 从概率分布中随机采样生成数值的函数,例如 randn 和 normal
Serialization(序列化) ------ 用于保存和加载张量的函数,例如 load 和 save
Parallelism(并行) ------ 用于控制 CPU 并行执行线程数的函数,例如 set_num_threads
花一点时间自己动手探索一下通用张量 API,是很值得的。本章已经提供了所有前置知识,使这种交互式探索成为可能。随着本书继续推进,我们也会不断遇到各种张量操作------从下一章开始就是如此。
3.8 张量:存储之上的多种"风景视图"
现在,是时候更仔细地看看底层实现了。张量中的数值,实际上被分配在由 torch.Storage 实例管理的一块连续内存 中。所谓 storage,本质上就是一个一维数值数组------也就是说,它是一段连续的内存块,其中存放着某种给定类型的数值,例如 float(32 位,用来表示一个浮点数)或 int64(64 位,用来表示一个整数)。而一个 PyTorch Tensor 实例,则是这样一个 Storage 实例上的视图(view) ;它能够借助一个偏移量(offset)以及各维度上的步幅(stride),对这段 storage 进行索引。
注意 在未来的 PyTorch 版本中,Storage 也许不再能被直接访问;不过,我们这里展示的内容,依然能够帮助你建立一个关于"张量在底层是如何工作"的良好心智模型。
即便多个张量以不同方式索引同一段数据,它们依然可以共享同一个 storage。图 3.4 就展示了这样一个例子。事实上,在第 3.2 节里,当我们请求 points[0] 时,返回的其实就是另一个张量:它和 points 张量索引的是同一块 storage,只不过它没有索引全部数据,而且维度也不同(一个是一维,另一个是二维)。底层内存实际上只分配了一次,因此,不管 Storage 实例管理的数据有多大,创建这份数据的其他张量视图都可以非常快。
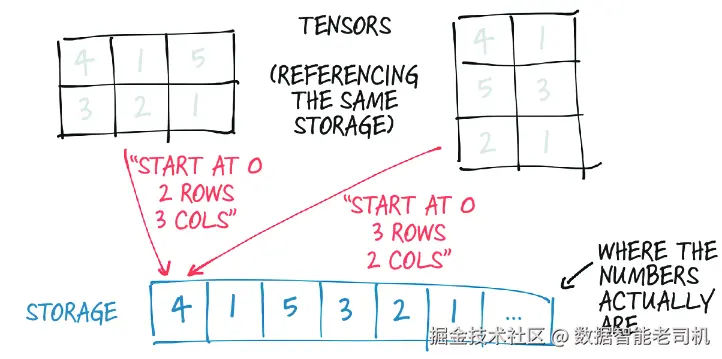
图 3.4 张量是某个 Storage 实例上的视图。
3.8.1 对 storage 进行索引
下面让我们用前面的二维 points 例子,实际看看 storage 索引是如何工作的。一个张量对应的 storage,可以通过 .storage 属性访问:
ini
# In[17]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points.storage()
# Out[17]:
4.0
1.0
5.0
3.0
2.0
1.0
[torch.FloatStorage of size 6]虽然这个张量对外表现为 3 行 2 列,但底层 storage 实际上只是一个大小为 6 的连续数组。从这个意义上说,张量所做的事情,不过就是知道如何把一对索引翻译成 storage 中的某个位置。
我们也可以手动对 storage 本身做索引。例如:
ini
# In[18]:
points_storage = points.storage()
points_storage[0]
# Out[18]:
4.0
ini
# In[19]:
points.storage()[1]
# Out[19]:
1.0对于一个二维张量的 storage,我们不能用两个索引来访问。无论引用它的张量是几维,storage 本身的布局始终都是一维的。
说到这里,你应该已经不会惊讶:修改 storage 中的值,也会改变引用它的张量内容:
ini
# In[20]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points_storage = points.storage()
points_storage[0] = 2.0
points
# Out[20]:
tensor([[2., 1.],
[5., 3.],
[2., 1.]])3.8.2 修改存储值:原地操作
除了上一节介绍过的那些张量运算之外,还有少数操作只以 Tensor 对象方法的形式存在。它们有一个很容易辨认的特征:方法名末尾带有一个下划线,比如 zero_。这个下划线表示:该方法会原地(in place) 操作,也就是直接修改输入本身,而不是创建一个新的输出张量再返回。例如,zero_ 方法会把输入中的所有元素全部置为 0。凡是没有这个尾随下划线的方法,都不会修改原始张量,而是会返回一个新的张量:
ini
# In[73]:
a = torch.ones(3, 2)
# In[74]:
a.zero_()
a
# Out[74]:
tensor([[0., 0.],
[0., 0.],
[0., 0.]])3.9 张量元数据:大小、偏移量与步幅
为了对 storage 做索引,张量依赖于几项关键信息;这些信息与 storage 一起,能够无歧义地定义一个张量:size(大小) 、offset(偏移量) 和 stride(步幅) 。图 3.5 展示了这些元素是如何相互配合的。size(在 NumPy 的术语里也叫 shape)是一个元组,用来指明张量在每个维度上各有多少个元素。storage offset 指的是:张量第一个元素在 storage 中所对应的索引位置。stride 则表示:沿着每个维度前进一步时,在 storage 中需要跳过多少个元素,才能到达下一个值。
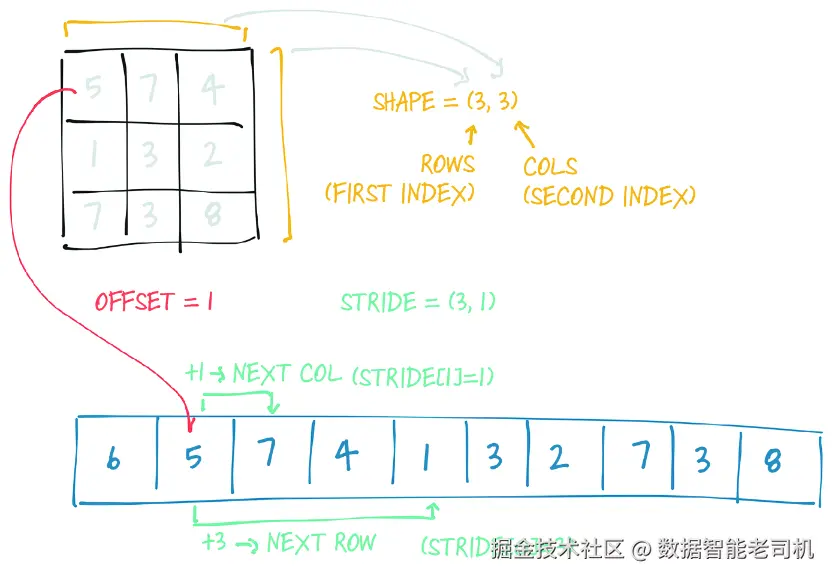
图 3.5 张量的 offset、size 与 stride 之间的关系。这里,这个张量是更大 storage 上的一个视图,例如这个 storage 可能是在创建更大张量时分配出来的。
3.9.1 另一个张量 storage 上的视图
我们可以通过给出相应索引,取出张量中的第二个点:
ini
# In[21]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
second_point = points[1]
second_point.storage_offset()
# Out[21]:
2
css
# In[22]:
second_point.size()
# Out[22]:
torch.Size([2])得到的这个张量在 storage 中的偏移量是 2(因为我们必须先跳过第一个点,而第一个点包含两个元素),而它的 size 是一个 Size 类实例,里面只有一个元素,因为这个张量是一维的。这里需要注意的是,这和张量对象的 shape 属性中包含的信息其实是一样的:
ini
# In[23]:
second_point.shape
# Out[23]:
torch.Size([2])stride 是一个元组,表示在每个维度上当索引增加 1 时,storage 中需要跳过多少个元素。例如,我们的 points 张量的 stride 是 (2, 1):
bash
# In[24]:
points.stride()
# Out[24]:
(2, 1)在一个二维张量中,访问元素 i, j,最终等价于访问 storage 中索引为
storage_offset + stride[0] * i + stride[1] * j
的那个元素。通常情况下 offset 是 0;但如果这个张量是一个更大张量所用 storage 上的视图,那么 offset 就可能是一个正数。
正是 Tensor 与 Storage 之间的这种间接层,使得某些操作的代价很低,比如转置一个张量,或者取出一个子张量,因为这些操作并不会导致内存重新分配。它们所做的,只不过是创建一个新的 Tensor 对象,并赋予它不同的 size、storage offset 或 stride 而已。
我们前面在索引某个具体点时,其实已经取出了一个子张量,并且也看到 storage offset 增加了。下面再看看 size 和 stride 会发生什么变化:
ini
# In[25]:
second_point = points[1]
second_point.size()
# Out[25]:
torch.Size([2])
bash
# In[26]:
second_point.storage_offset()
# Out[26]:
2
bash
# In[27]:
second_point.stride()
# Out[27]:
(1,)归根结底,这个子张量比原张量少了一个维度,这完全符合我们的预期;同时,它仍然索引的是与原始 points 张量相同的 storage。这也意味着,修改这个子张量,会对原始张量产生副作用:
ini
# In[28]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
second_point = points[1]
second_point[0] = 10.0
points
# Out[28]:
tensor([[ 4., 1.],
[10., 3.],
[ 2., 1.]])这种行为有时并不是我们想要的,所以我们也可以用 clone 把这个子张量复制成一个拥有自己独立 storage 的新张量:
ini
# In[29]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
second_point = points[1].clone()
second_point[0] = 10.0
points
# Out[29]:
tensor([[4., 1.],
[5., 3.],
[2., 1.]])3.9.2 不复制数据的转置
现在来试试转置。我们拿 points 张量来做实验:目前它的每一行表示一个点,而列表示 X、Y 坐标。现在我们把它转过来,让每一个点都出现在列里。顺便也借此引入 t 函数:它是 transpose 在二维张量上的一个简写形式。
lua
# In[30]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points
# Out[30]:
tensor([[4., 1.],
[5., 3.],
[2., 1.]])
ini
# In[31]:
points_t = points.t()
points_t
# Out[31]:
tensor([[4., 5., 2.],
[1., 3., 1.]])提示 为了真正建立起对张量内部机制的扎实理解,不妨拿出纸和笔,在跟着本节代码一步步走的时候,像图 3.5 那样自己画一些示意图。
我们很容易验证,这两个张量共享同一个 storage:
css
# In[32]:
id(points.storage()) == id(points_t.storage())
# Out[32]:
True而它们之间的区别,只在于 shape 和 stride:
bash
# In[33]:
points.stride()
# Out[33]:
(2, 1)
bash
# In[34]:
points_t.stride()
# Out[34]:
(1, 2)这段代码告诉我们:在 points 中,如果第一个索引增加 1,例如从 points[0,0] 变到 points[1,0],那么在 storage 中会向前跳过两个元素;而如果第二个索引增加 1,例如从 points[0,0] 变到 points[0,1],则只会向前跳过一个元素。换句话说,storage 中的元素是按"逐行顺序"依次存放的。
当我们把 points 转置成 points_t 时,如图 3.6 所示,本质上只是把 stride 中各元素的顺序调换了。这样一来,增加行索引(也就是张量的第一个索引)时,在 storage 中只会前进一个元素------这就和原来在 points 中沿列移动时的行为一样。这正是转置的定义。整个过程中没有分配任何新内存:转置只是通过创建一个新的 Tensor 实例,并赋予它与原张量不同的 stride 顺序来实现的。
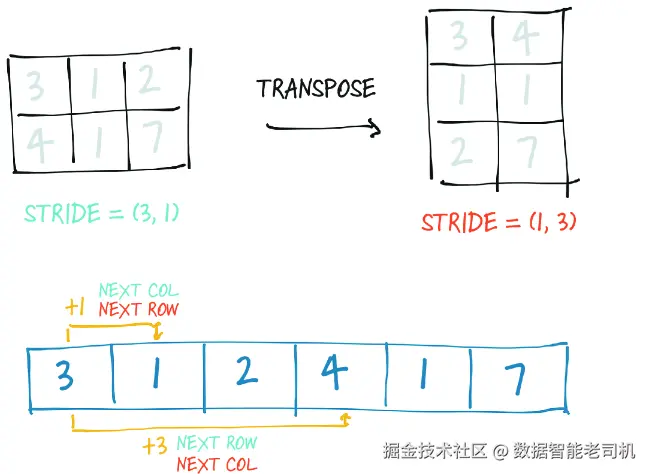
图 3.6 作用于张量的转置操作
3.9.3 更高维度上的转置
在 PyTorch 中,转置并不只限于矩阵。我们同样可以对一个多维数组做转置,只需要指定在哪两个维度之间进行转置(也就是交换 shape 和 stride)即可:
ini
# In[35]:
some_t = torch.ones(3, 4, 5)
transpose_t = some_t.transpose(0, 2)
some_t.shape
# Out[35]:
torch.Size([3, 4, 5])
ini
# In[36]:
transpose_t.shape
# Out[36]:
torch.Size([5, 4, 3])
bash
# In[37]:
some_t.stride()
# Out[37]:
(20, 5, 1)
bash
# In[38]:
transpose_t.stride()
# Out[38]:
(1, 5, 20)如果一个张量的值在 storage 中是按照"从最右边维度开始连续铺开"的方式排列的(对于二维张量来说,也就是按行连续排列),那么这个张量就被称为 contiguous(连续的) 。连续张量很方便,因为我们可以高效地按顺序访问它们,而不需要在 storage 中跳来跳去(改善数据局部性通常会带来更好的性能,这与现代 CPU 访问内存的方式有关)。当然,这种优势也取决于具体算法是如何遍历数据的。
3.9.4 连续张量
PyTorch 中有一些张量操作只能作用于连续张量,例如我们会在下一章遇到的 view。在这种情况下,PyTorch 会抛出一个信息明确的异常,并要求我们显式调用 contiguous。如果张量本来就已经是连续的,那么调用 contiguous 什么也不会做(而且也不会损害性能)。
在我们的例子里,points 是连续的,而它的转置 points_t 不是:
python
# In[39]:
points.is_contiguous()
# Out[39]:
True
python
# In[40]:
points_t.is_contiguous()
# Out[40]:
False我们可以用 contiguous 方法,从一个非连续张量得到一个新的连续张量。张量内容会保持不变,但 stride 会发生变化,因为本质上我们是在一块新的 storage 中重新排列这些值:
lua
# In[41]:
points = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]])
points_t = points.t()
points_t
# Out[41]:
tensor([[4., 5., 2.],
[1., 3., 1.]])
csharp
# In[42]:
points_t.storage()
# Out[42]:
4.0
1.0
5.0
3.0
2.0
1.0
[torch.FloatStorage of size 6]
bash
# In[43]:
points_t.stride()
# Out[43]:
(1, 2)
ini
# In[44]:
points_t_cont = points_t.contiguous()
points_t_cont
# Out[44]:
tensor([[4., 5., 2.],
[1., 3., 1.]])
bash
# In[45]:
points_t_cont.stride()
# Out[45]:
(3, 1)
csharp
# In[46]:
points_t_cont.storage()
# Out[46]:
4.0
5.0
2.0
1.0
3.0
1.0
[torch.FloatStorage of size 6]注意,此时 storage 已经被重新整理过了,元素会按照"逐行排列"的方式存放到新的 storage 中。stride 也随之改变,以反映这种新布局。
作为回顾,图 3.7 再次展示了我们在图 3.5 中最早引入的那张示意图。现在,在我们仔细看过张量究竟是如何构造出来之后,希望这一切都已经更清楚了。
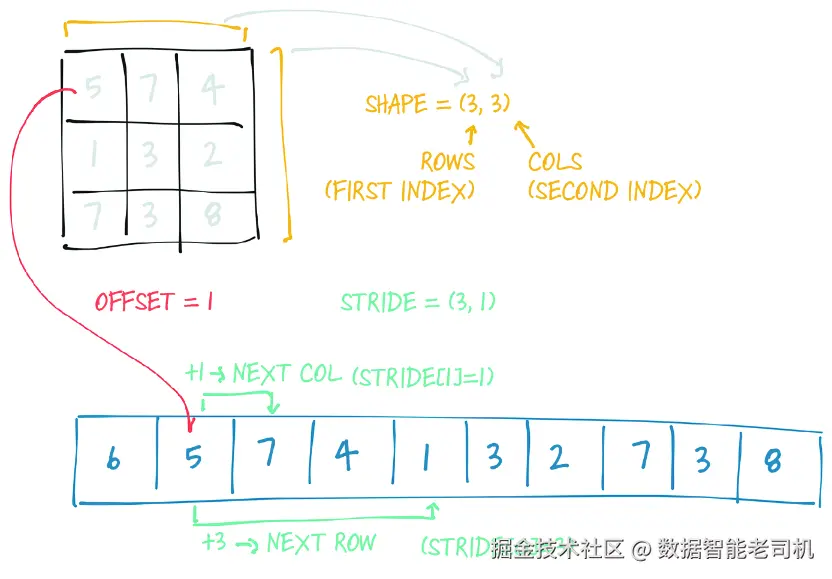
图 3.7 回忆一下,stride 为 (3, 1) 的含义是:移动到下一行时,需要在 storage 中跳过 3 个元素;而移动到下一列时,只需要跳过 1 个元素------这正是连续张量布局中的样子。
3.10 将张量移动到 GPU
到目前为止,在本章里我们提到 storage 时,指的都是 CPU 上的内存 。但 PyTorch 张量也可以存储在另一类处理器上:图形处理器(GPU) 。每一个 PyTorch 张量都可以被传输到(某一块)GPU 上,以执行大规模并行的高速计算。随后,所有作用于该张量的运算,都会通过 PyTorch 提供的、面向 GPU 的专用例程来完成。
PyTorch 对多种 GPU 的支持
截至 2025 年,PyTorch 已经显著扩展了自己的 GPU 加速能力。它现在同时支持 NVIDIA 的 CUDA GPU 和 AMD 的 ROCm 平台 。这两个平台都拥有原生支持,可以直接通过 pip 或 conda 安装,具体方式可参见 pytorch.org/get-started...。
对于使用 Apple Silicon Mac 的用户,PyTorch 提供了对 Metal Performance Shaders(MPS) 的支持,从而使张量能够在 Apple 集成 GPU 上得到加速。对 Google TPU(tensor processing unit) 的支持,则来自单独提供的 torch_xla 包(github.com/pytorch/xla)。类似地,对 Intel XPU 的支持可以通过 intel_extension_for_pytorch 获得(github.com/intel/intel...)。
PyTorch 的一项基本原则,是提供这样一种抽象:让新的硬件厂商能够无缝地为自己的硬件添加支持,而不需要现有用户为此修改代码。这种设计思路已经推动硬件生态不断扩展,而且这一趋势显然还会继续下去!
3.10.1 管理张量的 device 属性
除了 dtype 之外,PyTorch Tensor 还有另一个概念,叫作 device(设备) ,它表示张量数据在计算机中的存放位置。我们可以在构造张量时,通过指定相应参数,直接把张量创建在 GPU 上:
ini
# In[64]:
points_gpu = torch.tensor([[4.0, 1.0], [5.0, 3.0], [2.0, 1.0]],
device='cuda')我们也可以先在 CPU 上创建张量,再使用 to 方法把它复制到 GPU 上:
ini
# In[65]:
points_gpu = points.to(device='cuda')这会返回一个新的张量,它拥有和原张量相同的数值数据,但这些数据现在存放在 GPU 的显存中,而不再是普通的系统内存中。由于数据已经本地存放在 GPU 上,因此,当我们对这个张量执行数学运算时,就会开始看到前面提到过的那些速度提升。几乎在所有情况下,基于 CPU 的张量与基于 GPU 的张量,对用户暴露出来的 API 都是相同的;这使得编写"与底层计算到底跑在哪儿无关"的代码变得容易得多。
如果我们的机器上有不止一块 GPU,那么还可以通过传入一个从 0 开始的整数来指定把张量分配到哪一块 GPU 上,例如:
ini
# In[66]:
points_gpu = points.to(device='cuda:0')到了这一步,任何在这个张量上执行的操作------例如把所有元素都乘上一个常数------都会在 GPU 上进行:
ini
# In[67]:
points = 2 * points #1
points_gpu = 2 * points.to(device='cuda') #2
#1 乘法在 CPU 上执行
#2 乘法在 GPU 上执行在结果计算完成之后,points_gpu 这个张量并不会被自动搬回 CPU。上面这行代码中,实际发生的是:
points 张量先被复制到 GPU;
在 GPU 上分配出一个新的张量------也就是说,该张量的全部 storage 都位于 GPU 显存中;乘法的结果也同样保留在 GPU 显存中;
最后返回一个指向该 GPU 张量的句柄,使我们可以像操作普通变量一样,在程序中继续操作它。
因此,如果我们继续在这个结果之上再加一个常数:
ini
# In[68]:
points_gpu = points_gpu + 4那么这个加法仍然会在 GPU 上执行,并不会有任何信息流回 CPU(除非我们去打印或访问这个结果张量)。如果要把张量移回 CPU,就需要在 to 方法中把 device 指定为 cpu,例如:
ini
# In[69]:
points_cpu = points_gpu.to(device='cpu')我们也可以使用 cpu 和 cuda 这两个简写方法,而不必调用 to,达到相同效果:
ini
# In[70]:
points_gpu = points.cuda() #1
points_gpu = points.cuda(0)
points_cpu = points_gpu.cpu()
#1 默认使用索引为 0 的 GPU还值得一提的是,通过 to 方法,我们可以同时改变张量的存放位置 和数据类型 ,只需要同时传入 device 与 dtype 参数即可。
3.11 NumPy 互操作
前面我们已经多次提到 NumPy。虽然我们并不把 NumPy 当作阅读本书的前提条件,但还是强烈建议你熟悉 NumPy,因为它在 Python 数据科学生态中实在太普遍了。PyTorch 张量和 NumPy 数组之间可以非常高效地相互转换。借助这一点,我们就能够利用整个 Python 生态中围绕 NumPy 数组类型积累起来的大量功能。这种与 NumPy 数组之间的零拷贝互操作 之所以可行,是因为 storage 系统能够配合 Python 的 buffer protocol(docs.python.org/3/c-api/buf...)工作。
如果想从我们的 points 张量中得到一个 NumPy 数组,只需要调用:
ini
# In[55]:
points = torch.ones(3, 4)
points_np = points.numpy()
points_np
# Out[55]:
array([[1., 1., 1., 1.],
[1., 1., 1., 1.],
[1., 1., 1., 1.]], dtype=float32)它会返回一个大小、形状和数值类型都正确的 NumPy 多维数组。有意思的是,返回的这个数组与张量的 storage 共享同一个底层缓冲区 。这意味着,只要数据还位于 CPU 内存中,numpy 方法几乎可以说是零成本执行的。这也意味着,修改这个 NumPy 数组,也会导致原始张量发生变化。如果张量分配在 GPU 上,那么 PyTorch 会先把张量内容复制到 CPU 上,再生成一个分配在 CPU 上的 NumPy 数组。
反过来,我们也可以从一个 NumPy 数组得到一个 PyTorch 张量:
ini
# In[56]:
points = torch.from_numpy(points_np)这里采用的,也正是我们刚才描述过的那种共享缓冲区策略。
注意 虽然 PyTorch 中的默认数值类型是 32 位浮点数 ,但 NumPy 的默认数值类型却是 64 位浮点数 。正如我们在第 3.5.2 节讨论过的,通常我们更希望使用 32 位浮点数,因此在完成转换之后,需要确认得到的张量是否为 torch.float 类型。
3.12 广义张量依然是张量
对于本书的目的来说,以及对于绝大多数实际应用而言,张量就是我们在本章中看到的这种多维数组。但如果我们稍微窥视一下 PyTorch 的底层,会发现还有一个转折:底层数据如何存储,与我们在第 3.6 节中讨论的那套张量 API,其实是分离的。只要某种实现满足这套 API 所定义的约定,它就可以被视为一种张量!
无论我们的张量位于 CPU 还是 GPU,PyTorch 都会调用正确的计算函数。这是通过一种分发机制(dispatching mechanism) 来实现的;而这个机制同样可以支持其他种类的张量:它只需要把面向用户的 API 连接到正确的后端函数即可。确实,除了我们目前接触到的这种张量之外,还有其他类型的张量:有些是针对某类特定硬件设备设计的(例如 Google TPU);另一些则采用了与我们目前看到的稠密数组风格不同的数据表示方式。举例来说,稀疏张量(sparse tensor) 只存储非零元素以及相应的索引信息。图 3.8 左侧展示的 PyTorch dispatcher,其设计初衷就是可扩展的;而右侧为了适配各种不同数值类型所进行的后续切换,则属于每个后端内部写死的实现部分。
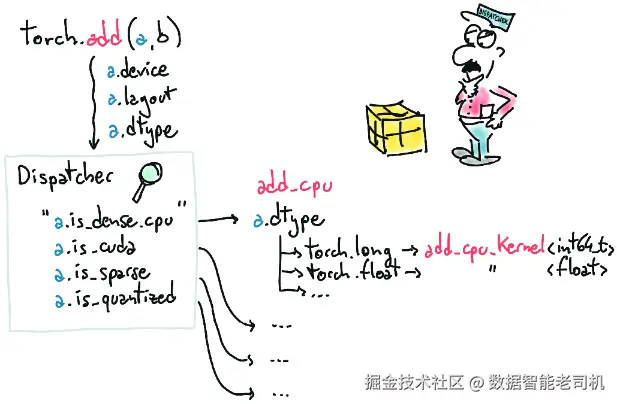
图 3.8 PyTorch 中的 dispatcher,是其基础设施中非常关键的一部分。
有时候,我们平常使用的这种张量会被称为 dense(稠密) 或 strided(带步幅) 张量,以便与那些采用其他内存布局的张量类型区分开来。
和很多事情一样,随着 PyTorch 对更广泛硬件与应用场景的支持不断增强,张量的种类也在不断增加。随着人们继续探索用 PyTorch 表达和执行计算的新方式,我们完全可以预期,还会有新的张量类型不断出现。
3.13 张量的序列化
在运行时临时创建一个张量当然很好,但如果其中的数据很有价值,我们终究会希望把它保存到文件里,并在之后某个时候再把它加载回来。毕竟,我们可不想每次启动程序时,都得从头重新训练一遍模型!PyTorch 使用 pickle 来序列化张量对象本身,同时为 storage 使用专门的序列化代码。下面是把我们的 points 张量保存到一个名为 ourpoints.t 的文件中的方式:
css
# In[57]:
torch.save(points, '../data/p1ch3/ourpoints.t')作为另一种写法,我们也可以不传入文件名,而是传入一个文件描述符:
python
# In[58]:
with open('../data/p1ch3/ourpoints.t','wb') as f:
torch.save(points, f)把 points 再加载回来,同样只需要一行代码:
ini
# In[59]:
points = torch.load('../data/p1ch3/ourpoints.t')或者,等价地,也可以这样写:
csharp
# In[60]:
with open('../data/p1ch3/ourpoints.t','rb') as f:
points = torch.load(f)如果我们只打算在 PyTorch 里重新加载这些张量,那么这种保存方式当然非常方便。但这种文件格式本身不具备互操作性:也就是说,我们不能用 PyTorch 之外的软件来读取这些张量。根据具体场景不同,这一点可能算限制,也可能不算;但为了应对那些确实需要互操作的场景,我们还是应该学会用可互通的方式保存张量。接下来我们就来看怎么做。
3.13.1 使用 h5py 序列化为 HDF5
每一种使用场景都不一样,但我们猜测:当你把 PyTorch 引入一个原本已经依赖其他库的既有系统时,需要以"可互操作"的方式保存张量会更常见。而对于全新的项目来说,这种需求通常不会那么频繁。
不过,在你确实需要的时候,可以使用 HDF5 格式及其配套库(www.hdfgroup.org/solutions/h...)。HDF5 是一种可移植、被广泛支持的格式,专门用于表示序列化后的多维数组;它以一种嵌套的键值字典结构来组织数据。Python 通过 h5py 库(www.h5py.org/)支持 HDF5,而 h5py 接收和返回的数据形式则是 NumPy 数组。
我们可以通过下面的命令安装 h5py:
ruby
$ conda install h5py到这里,我们就可以把 points 张量先转换成 NumPy 数组(正如前面提到的,这一步基本没有成本),再把它传给 create_dataset 函数来保存:
css
# In[61]:
import h5py
f = h5py.File('../data/p1ch3/ourpoints.hdf5', 'w')
dset = f.create_dataset('coords', data=points.numpy())
f.close()这里的 'coords' 是 HDF5 文件中的一个键。我们当然也可以有其他键,甚至是嵌套键。HDF5 一个很有意思的地方在于:我们可以在数据仍然位于磁盘上时,直接对数据集做索引,只访问自己感兴趣的那部分元素。假设我们只想加载数据集里的最后两个点:
ini
# In[62]:
f = h5py.File('../data/p1ch3/ourpoints.hdf5', 'r')
dset = f['coords']
last_points = dset[-2:]在文件被打开、或者数据集对象被取出来的时候,数据其实并不会立刻加载到内存中 。相反,数据会一直留在磁盘上,直到我们真正请求这个数据集中的倒数第二行和最后一行为止。此时,h5py 才会去访问那两行,并返回一个类似 NumPy 数组的对象,它封装了该数据集中对应区域,并且行为和 API 都与 NumPy 数组相同。
也正因为如此,我们可以把这个返回对象直接传给 torch.from_numpy,从而直接得到一个张量。此时,数据会被复制到该张量自己的 storage 中:
css
# In[63]:
last_points = torch.from_numpy(dset[-2:])
f.close()当数据加载完成之后,我们就把文件关闭。关闭这个 HDF5 文件之后,数据集对象就会失效;如果之后再试图访问 dset,就会抛出异常。只要我们按照这里展示的顺序来操作,就不会有问题;此时,我们已经可以继续使用 last_points 张量了。
3.14 结语
现在,我们已经掌握了把各种数据表示成浮点数所需的基础知识。后续在需要的时候,我们还会继续涉及张量的其他方面,例如:如何创建张量视图、如何用其他张量来对张量进行索引,以及广播机制------它可以简化不同大小或不同形状张量之间的逐元素运算。
在第 4 章中,我们将学习如何在 PyTorch 中表示真实世界数据。我们会先从简单的表格数据开始,然后逐步进入更复杂的内容。在这个过程中,我们也会进一步熟悉张量。
3.15 练习
-
从
list(range(9))创建一个张量a。先预测,再检查它的 size、offset 和 stride。 -
用
b = a.view(3, 3)创建一个新张量。view做了什么?检查a和b是否共享同一个 storage。 -
创建一个张量
c = b[1:,1:]。先预测,再检查它的 size、offset 和 stride。 -
任选一个数学运算,例如余弦或平方根。你能在
torch库中找到对应函数吗? -
这个函数是否有一个原地操作版本?
-
把这个函数按元素应用到
a上。它会报错吗? -
需要进行什么操作,才能让这个函数工作?
小结
-
神经网络会把一种浮点数表示转换成另一种浮点数表示。起点和终点的表示通常对人类是可解释的,但中间表示通常就没那么直观了。
-
神经网络所理解的这些浮点表示,是以张量的形式存储的。
-
张量是多维数组;它们是 PyTorch 中的基础数据结构。
-
张量的索引记法与 NumPy 数组相似,这使得我们可以访问张量的不同维度。
-
PyTorch 中的广播机制,允许不同形状的张量之间自动通过扩展较小张量的维度来进行逐元素运算,从而让这些运算变得兼容。
-
张量的数值类型可以通过
dtype指定,用来定义张量中数据的类型(例如整数、浮点数、布尔值),以及每个值占用的字节数(例如 8 位、16 位、32 位、64 位)。 -
PyTorch 提供了一套完整的张量标准库,用于张量创建、操作(例如索引、切片、拼接等)、数学运算、随机采样、序列化以及并行控制。
-
张量内部采用由 size、offset 和 stride 等元数据组成的存储表示方式,这使得我们可以在不复制底层数据的前提下访问和操作张量,从而大幅节省时间和内存。
-
PyTorch 中的所有张量操作,既可以在 CPU 上执行,也可以在 GPU 上执行,而代码本身无需修改。
-
PyTorch 使用函数名末尾的下划线来表示该函数会对张量执行原地操作 (例如
Tensor.sqrt_)。 -
张量可以被序列化到磁盘上,并在之后重新加载回来。