前言
大家好!作为一个 C++ 初学者,最近我打算用 C++ 来挑战 Leetcode ,在干中学,从而提升自己的编程和算法能力。今天我完成了第一道题,就是极其经典的两数之和,整个过程下来,我感觉收获很大,在克服重重困难之后也算是对 C++ 的一些特性有了比较浅显的理解。
本篇文章旨在记录我的学习过程,作为笔记我还会记录一些 C++ 的知识点,同时也希望和我一样正在学习 C++ 的初学者朋友们看到后能够有所收获。
1. 理解问题
我们首先来看一下题目,这里我只简略描述一下题目。
给定一个整数数组 nums 和一个整数目标值 target,请你在该数组中找出和为目标值 的那两个 整数,并返回它们的数组下标 ,只会存在一个有效答案。
示例: 输入:nums = [2, 7, 11, 15],target = 9 输出:[0, 1] 解释:因为 nums[0] + nums[1] == 9
2. 暴力解法
作为一个初学者,第一反应往往是最简单朴素的暴力解法,我也不例外。
暴力解法的思路如下:
- 我们先拿着数组中第一个元素;
- 我们再依次拿起数组中除第一个元素之外的每一个元素;
- 第二步拿起的每一个元素都与第一步拿起的元素相加,看看是否等于目标值,如果等于目标值,直接返回两个元素的下标;
- 如果都不等于目标值,我们再拿起第二个元素,再和第二个元素之后的每一个元素相加并与目标值比较,以此类推。
我之前一直是使用 C 语言的,但我相信学习过任何一种编程语言的都能看出来,这个思路转换成代码其实就是两层for循环。
具体实现如下:
cpp
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
for(int i=0; i<nums.size(); i++)
{
for(int j=i+1; j<nums.size(); j++)
{
if(nums[i] + nums[j] == target)
{
return {i,j};
}
}
}
return {};
}
};这段代码虽然成功通过了,但是正如前面所说,这种方法是暴力解法,它简单明了,但并不是最高效的解法,如果数组中的元素非常多,那么双层循环的劣势就会极其明显,程序的运行时间会急剧加快。
知识点我会放在最后统一讲,下面先介绍另一种解法。
3. 哈希表解法
想要对暴力解法进行优化,我们首先要意识到暴力解法究竟慢在哪里。
对于 nums[i],我们需要再用一个循环去数组里找 target - nums[i],也就是说,在拿到一个数之后,它在寻找另一个数这个环节中的效率太低。
这就引出了我们第二种解法------哈希表高效解法。它能让我们瞬间知道 target - nums[i]是否在数组里或者在数组的那个位置,这是一种用空间换时间的策略。
于是,我们又有了新的思路:
- 创建一个哈希表,用于记录我们已经遍历过的数组元素和它的下标。
- 开始用
for循环遍历数组,先拿到数组的第一个元素nums[0]。 - 我们需要找到它的另一半
target - nums[0],我们去哈希表中查一下是否有这个数,现在当然是没有的,因为我们还没有往哈希表中存任何内容,哈希表还是空的。 - 由于我们没找到
target - nums[0],于是我们把nums[0]和它的数组下标 0 存入哈希表。 - 继续
num[1],重复上面过程。
这个过程中只需要遍历一次数组,每次查询哈希表的速度都接近 O(1),所以总的时间复杂度降到了 O(n),这是一个巨大的提升。
哈希表解法的具体实现如下:
cpp
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
unordered_map<int,int> values;
for(int i=0; i<nums.size(); i++)
{
int complement = target - nums[i];
if(values.find(complement) != values.end())
{
return {values[complement],i};
}
values[nums[i]] = i;
}
return {};
}
};到现在为止,两种解法的思路和具体实现都已经介绍完了,其实最重要的是思路。
我们拿到一道题目,首先要在大脑中构建出这道题目的解决思路,然后才能根据需要使用相应的工具来解决这个问题。
下一章我将具体介绍上面代码涉及到的 C++ 知识点,以及我作为一个 C++ 初学者的一些理解。
4. C++知识点梳理
由于我之前主要接触的是 C 语言,所以在刚开始用 C++ 写这道题时,遇到了不少新鲜的概念。借着这道题,我把代码中涉及到的 C++ 核心知识点做了一个详细的梳理。
4.1 类的基本概念
在 Leetcode 中,我们提交的代码通常是被包裹在一个类(class)里面的,大家在 Leetcode 上面做题时应该也有观察到这一点。如下:
cpp
class Solution {
public:
vector<int> twoSum(vector<int>& nums, int target) {
//函数代码
}
};在 C 语言中,我们习惯直接写一个个独立的函数。但在 C++ 这种面向对象 的语言中,函数通常作为方法 存在于类之中。
C++ 中的类是面向对象编程的核心概念之一,它把数据 和操作这些数据的方法封装在一起。
类的访问控制主要通过三种访问限定符来实现:分别是public,private和protected。这三个关键字决定了类的成员能被谁访问。
class 默认访问权限是 private,而 struct 默认是 public。
下面我列表总结一下三种访问权限的特点:
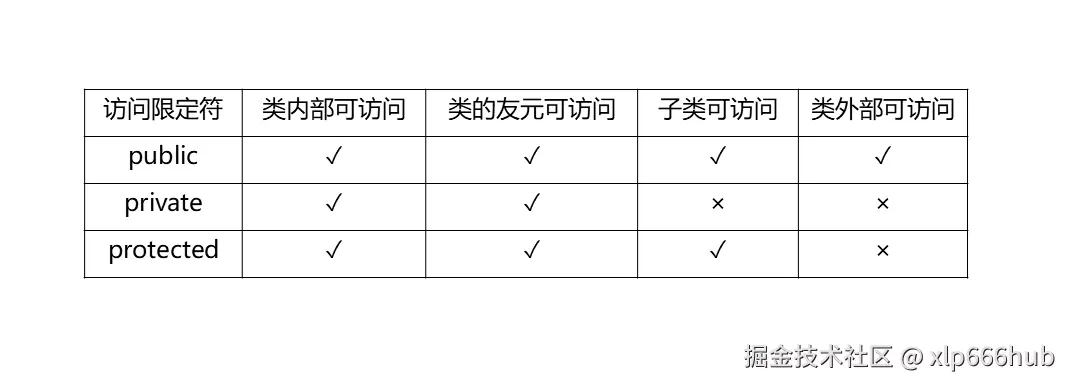
public经常用于函数接口,对外暴露的功能。
private经常用于内部实现细节,以及需要严格隐藏的数据。
protected经常用于给子类用的半公开成员。
4.2 vector及其常用操作
在 C 语言中,数组的长度一旦定义就固定死了,比如 int arr[10]。而 vector 是 C++ 标准模板库 STL 提供的一种动态数组,它可以根据需要自动伸缩,用起来极其方便。
在 C++ 中,vector 实例化出来的变量,比如题目中的 nums 就是一个对象 。对象内部自带了很多现成的函数,我们可以通过在一个对象变量后面加上一个点(.) ,来调用这些函数。
下面列举几个比较常见的操作:
cpp
vector<int> nums;//创建一个空的整形动态数组
//往数组末尾塞数据
nums.push_back(10);
nums.push_back(20);//现在数组是[10,20]
//获取数组长度
int len = nums.size();//现在len的值为2
//判断数组是否为空
bool isEmpty = nums.empty();//false,因为数组里面有数据
//像普通数组一样通过下标访问
int n = nums[0];在这道题的暴力解法中,我们正是利用了 nums.size() 来作为 for 循环的边界,再也不用像 C 语言那样需要额外传一个 int length 参数进来了。
4.3 引用传递&
C++ 中的引用传递是现代 C++ 中最常用、最推荐的函数参数传递方式之一。
下面我将通过列表来对比值传递 ,指针传递 以及引用传递三者的特点,以便更好地区分与理解他们:
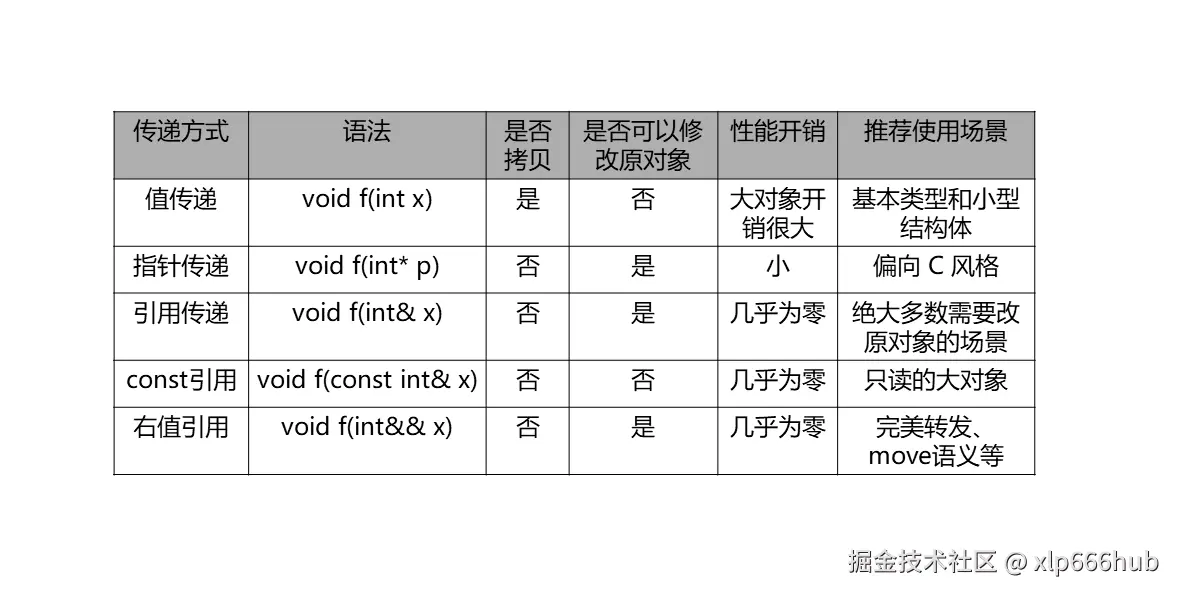
我们仔细看上面程序中函数的参数:vector<int>& nums。这里面有一个非常关键的符号 &。如果不加这个符号,哪怕逻辑全对,在 Leetcode 上也可能因为运行超时而失败。由上表中我们可以看到,值传递是需要拷贝的,而引用传递不需要拷贝。如果我们不加 & 符号,Leetcode 的测试程序在调用twoSum函数时,就会将原本的nums数组再拷贝一份进行操作,试想一下,假如nums数组中有一万个元素,会是怎样的后果?
除此之外,还需要再严格区分一下引用 与指针。引用本质上只是一个别名,不占据独立的内存,但是修改这个别名就是修改原始的数据。而指针是占据独立内存的。
4.4 列表初始化返回
当我们在暴力解法中找到答案时,我直接写了 return {i, j};
但是最初,我是按照 C 语言的思维,用 C++ 的方式来写的,如下:
cpp
vector<int> result;//先创建一个空的vector对象
result.push_back(i);//把i塞进去
result.push_back(j);//把j塞进去
return result;但在现代 C++ 中,引入了列表初始化 。因为编译器预先知道这个函数的返回值类型是 vector<int>,所以当写下 {i, j} 时,编译器会在底层自动完成上面那 4 步繁琐的操作。
同理,当找不到答案时,直接 return {}; 就会返回一个空的 vector,非常简洁。
4.5 C++中的哈希表
在 C++ 里,哈希表叫 unordered_map,字面意思是无序映射。
字典的目录应该可以算做一种哈希表。如果字典没有目录,我们在查询单词abandon时,就需要一页一页去找。但是我们完全可以多花费几页纸,来做一个目录,列出某些单词与页码的对应关系,从而加快查找速度。这就是用空间换时间。
哈希表存的是键值对:
cpp
//unordered_map<键, 值> 哈希表名称
unordered_map<int, int> values;前一个 int 是键 Key :用来存数组里实际的数字大小。
后一个 int 是值 Value :用来存这个数字对应的数组下标。
在哈希表中找东西的操作如下:
cpp
if(values.find(complement) != values.end())依然是对象加点的操作。
values.find(目标数字):这个函数去哈希表里找目标数字。如果找到了,它会返回一个迭代器Iterator,它指向了哈希表中存有那个数字的具体位置。
values.end():它代表哈希表的末尾的下一个空气位置。
综合起来看,这行代码就是 C++ 中判断哈希表里是否存在某个数的最标准写法。
然后我们再来看哈希表的插入与访问。
在没找到配对的数字时,我们需要把当前的数字记录到哈希表里:
cpp
values[nums[i]] = i;熟悉 C 语言数组的人可能会和我最初一样觉得疑惑,哈希表又不是普通数组,怎么也能用中括号 []这样操作?
这就是 C++ 中括号 运算符对哈希表的强大重载。这个简单的等式兼具了两种功能:
- 如果
nums[i]在哈希表里不存在 ,它会自动创建一个新的键值对 ,把键设为nums[i],把值设为i。 - 如果数字
nums[i]已经存在 于哈希表中了,它不会报错,而是会直接把旧的下标覆盖掉,更新为现在的下标i。
在这道题里,我们就是利用了它的自动创建能力,一边遍历数组,一边把不满足条件的数字记录在哈希表里,供后面的数字随时查询。
5. 总结
虽然只是 Leetcode 的第一题,但我花了比预期更多的时间去查资料、理解面向对象思维、熟悉哈希表的底层逻辑以及 C++ 的各种语法逻辑。但我想这也许就是"万事开头难"这句话的现实体现吧。
希望这篇详细到有些啰嗦的记录,也能帮助到正在看文章并且同为 C++ 初学者的你。C++ 学习之路道阻且长,有缘的话我们下一题见!