⚠️ 前排提醒:为了尽可能简单,本文只实现基本功能,不使用 langchain 等框架,包含无数不规范的写法,代码仅供参考。
1. 连接你和 Agent 的通道:飞书机器人
OpenClaw 对接飞书消息的途径是飞书机器人,所以我们要先创建一个机器人,按照飞书开放平台的指引创建应用和机器人并授权即可。
关于机器人的创建和授权可参考这篇官方文档的飞书机器人创建部分,这里只展示部分操作。
1.1 为机器人授权
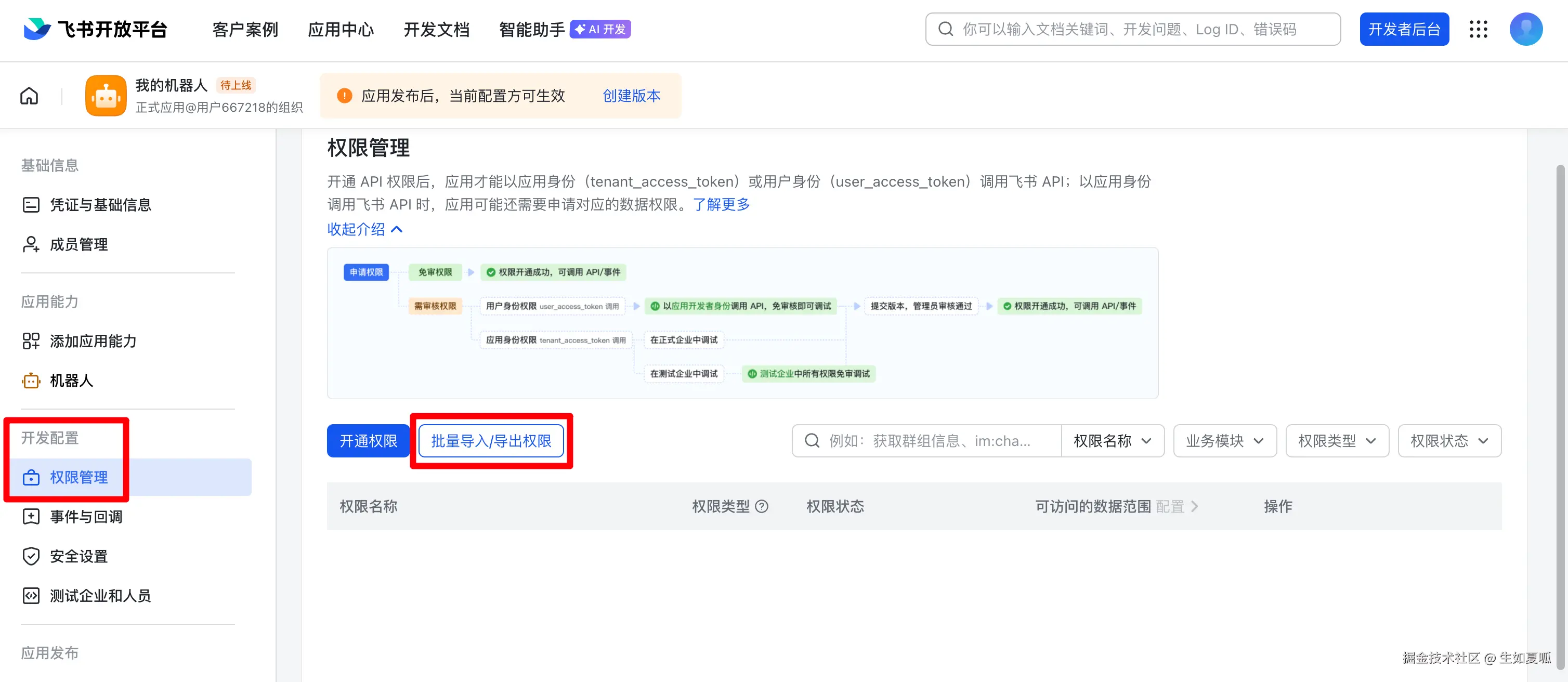
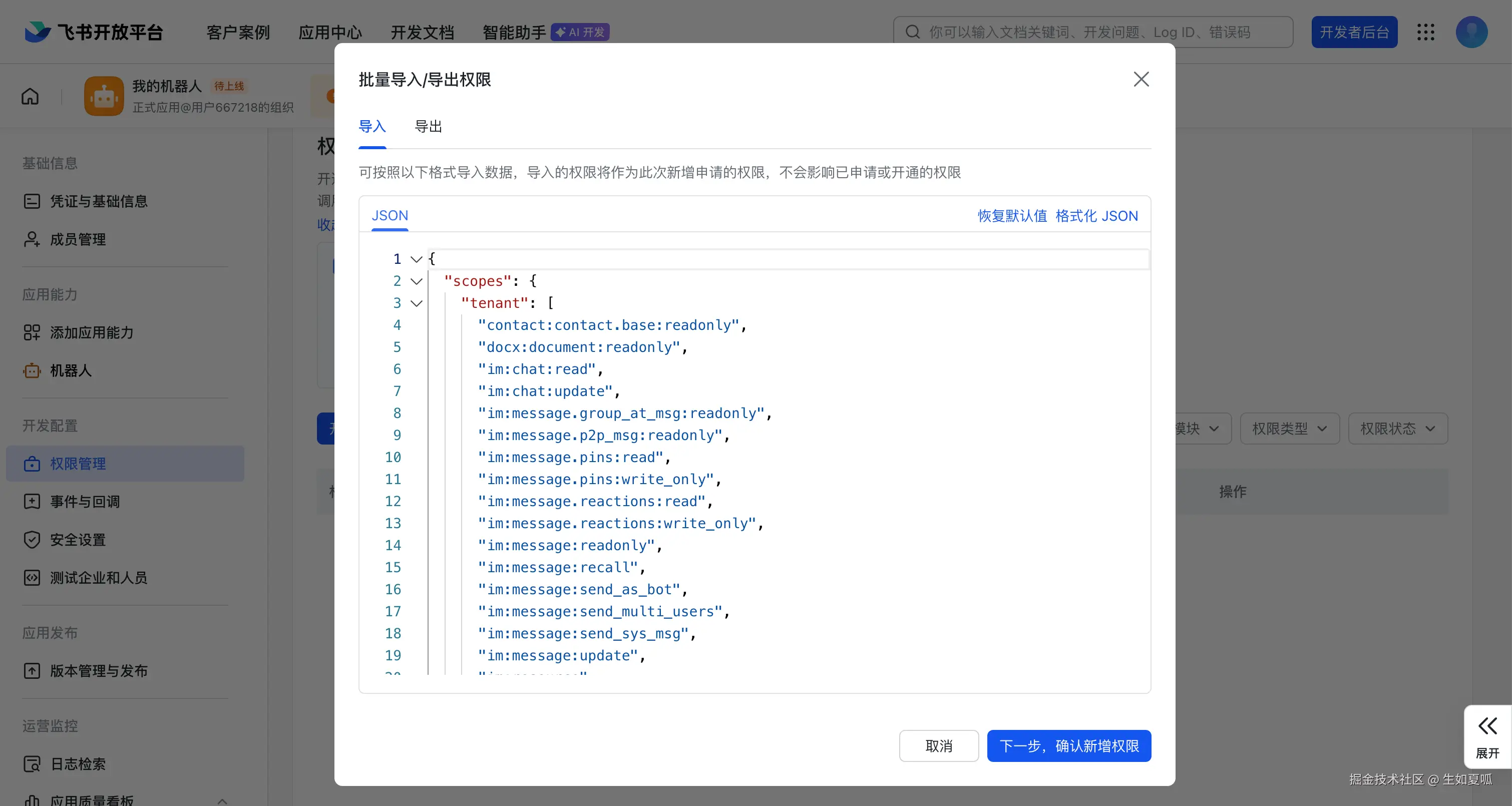
创建应用后在侧边栏「机器人」中点击创建机器人,然后进入「权限管理」添加权限,JSON 可从上面的连接中复制
1.2 发布机器人
最后发布应用,确保修改均已发布,如下图所示
现在我们在飞书中可以搜到刚刚创建的机器人
点击之后我们会发现没有聊天框,不用急,这是因为还没配置事件订阅,我们可以先写代码,运行起来才能配置。
2. 让小龙虾张嘴说话:回复消息
现在我们正式进入开发,首先安装一个非常好用且高性能的 Python 包管理器 uv,安装完成后运行 uv --version 可以看到当前的 uv 版本,没有的话可能是环境变量没有被正确配置,我们可以问 AI 解决。
我们创建一个空文件夹,如 my_claw, cd my_claw 进入目录,uv init 初始化工程,它的作用和 npm init 类似。现在我们可以得到如下图所示的目录结构

那么怎么才能让飞书机器人和我们的本地服务之间建立连接呢?这里不用问 AI,因为飞书官方给我们提供了一个示例代码,直接复制到 main.py 中。
Python
import lark_oapi as lark
from lark_oapi.api.im.v1 import *
import json
# 注册接收消息事件,处理接收到的消息。
# Register event handler to handle received messages.
# https://open.feishu.cn/document/uAjLw4CM/ukTMukTMukTM/reference/im-v1/message/events/receive
def do_p2_im_message_receive_v1(data: P2ImMessageReceiveV1) -> None:
res_content = ""
if data.event.message.message_type == "text":
res_content = json.loads(data.event.message.content)["text"]
else:
res_content = "解析消息失败,请发送文本消息\nparse message failed, please send text message"
content = json.dumps(
{
"text": f'收到你发送的消息:{res_content}\nReceived message:{res_content}'
}
)
if data.event.message.chat_type == "p2p":
request = (
CreateMessageRequest.builder()
.receive_id_type("chat_id")
.request_body(
CreateMessageRequestBody.builder()
.receive_id(data.event.message.chat_id)
.msg_type("text")
.content(content)
.build()
)
.build()
)
# 使用发送OpenAPI发送消息
# Use send OpenAPI to send messages
# https://open.feishu.cn/document/uAjLw4CM/ukTMukTMukTM/reference/im-v1/message/create
response = client.im.v1.message.create(request)
if not response.success():
raise Exception(
f"client.im.v1.message.create failed, code: {response.code}, msg: {response.msg}, log_id: {response.get_log_id()}"
)
else:
request: ReplyMessageRequest = (
ReplyMessageRequest.builder()
.message_id(data.event.message.message_id)
.request_body(
ReplyMessageRequestBody.builder()
.content(content)
.msg_type("text")
.build()
)
.build()
)
# 使用回复OpenAPI回复消息
# Use send OpenAPI to send messages
# https://open.larkoffice.com/document/server-docs/im-v1/message/reply
response: ReplyMessageResponse = client.im.v1.message.reply(request)
if not response.success():
raise Exception(
f"client.im.v1.message.reply failed, code: {response.code}, msg: {response.msg}, log_id: {response.get_log_id()}"
)
# 注册事件回调
# Register event handler.
event_handler = (
lark.EventDispatcherHandler.builder("", "")
.register_p2_im_message_receive_v1(do_p2_im_message_receive_v1)
.build()
)
# 创建 LarkClient 对象,用于请求OpenAPI, 并创建 LarkWSClient 对象,用于使用长连接接收事件。
# Create LarkClient object for requesting OpenAPI, and create LarkWSClient object for receiving events using long connection.
client = lark.Client.builder().app_id(lark.APP_ID).app_secret(lark.APP_SECRET).build()
wsClient = lark.ws.Client(
lark.APP_ID,
lark.APP_SECRET,
event_handler=event_handler,
log_level=lark.LogLevel.DEBUG,
)
def main():
# 启动长连接,并注册事件处理器。
# Start long connection and register event handler.
wsClient.start()
if __name__ == "__main__":
main()现在导入代码的地方肯定会飘红,因为我们还没有安装 lark_oapi 这个包,所以在项目中运行 uv add lark_oapi 即可,为了调试可以额外安装一个 uv add loguru.
同时,注意力惊人的 我们很容易注意到示例代码中没有正确填写 APP_ID 和 APP_SECRET,我们可以进入飞书应用主页找到它们并复制下来。
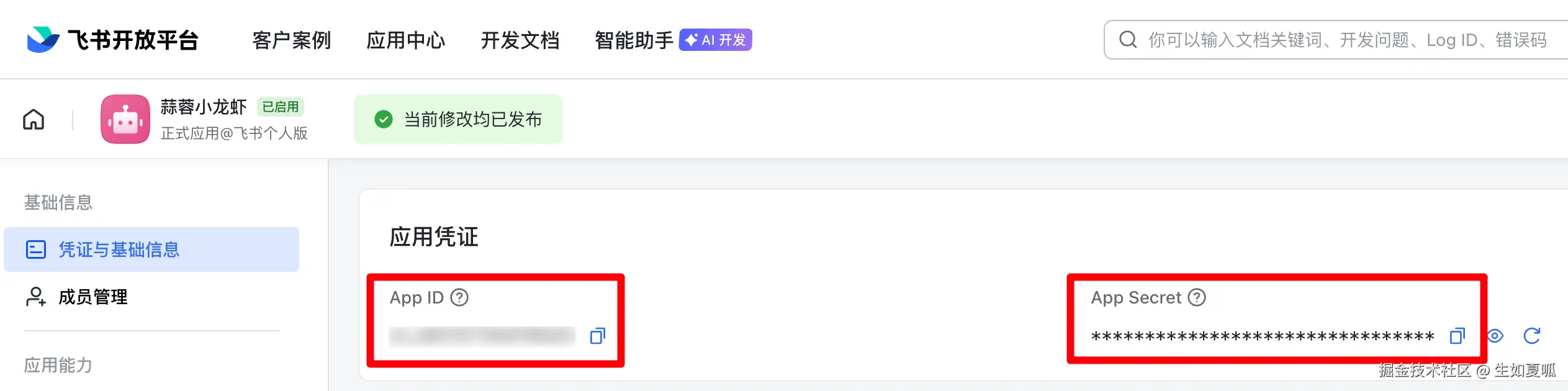
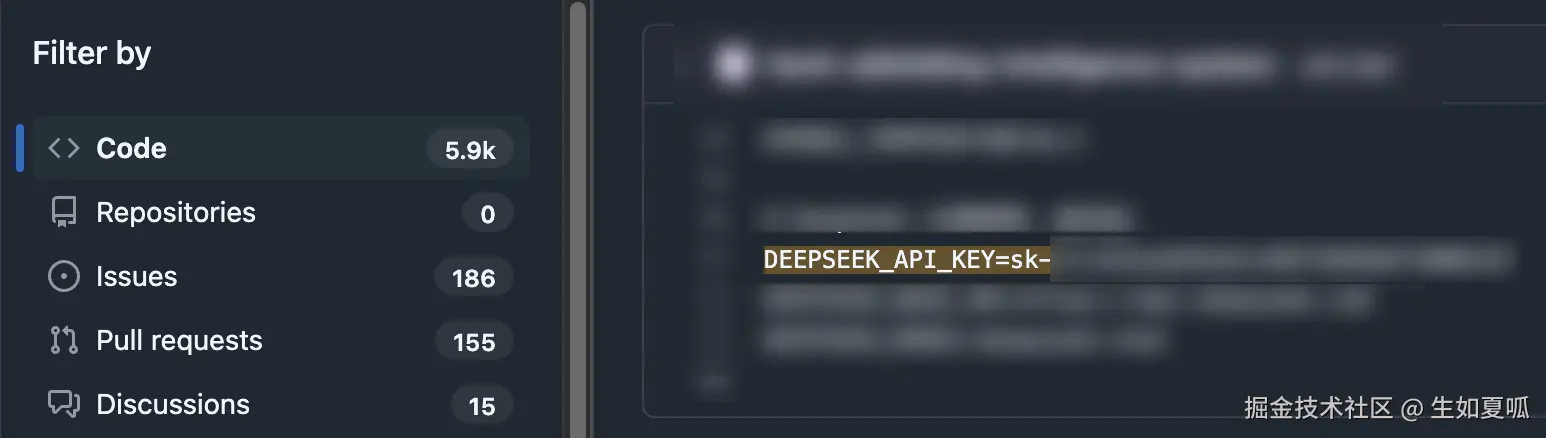
千万不要把这两个值直接明文复制到代码中, 为了防止出现 github 一搜 DEEPSEEK_API_KEY=sk- 就能搜出一大堆的情况😆,我们作为高级专业的开发者,当然应该使用环境变量。
首先在 .gitignore 文件里增加一行 .env 以防 push 到远端仓库,然后让我们创建一个 .env 文件,写上 APP_ID 和 APP_SECRET:

那么我们应该把它加载到环境变量里呢?好在 Python 有一个库 dotenv,顾名思义它和 .env 紧密相关,所以我们来安装一下 uv add dotenv,然后在 main.py 中加上:
Python
from dotenv import load_dotenv
import os
load_dotenv() # 把 .env 文件里的变量放到环境变量里
APP_ID = os.getenv("APP_ID") # os.getenv 获取环境变量,在 Node.js 中是 process.env.xx
APP_SECRET = os.getenv("APP_SECRET")
# 个人喜欢把创建 client 实例移动到顶部
client = lark.Client.builder().app_id(APP_ID).app_secret(APP_SECRET).build()
# 剩余其他代码...非常好,现在让我们来运行一下这段代码,uv run main.py,运行成功后回到飞书应用页面,在「事件与回调」页把「事件配置」和「回调配置」保存为 「长连接」 ,事件配置需要添加 「接收消息」。
⚠️注意,如果没有启动代码,此处无法选中!
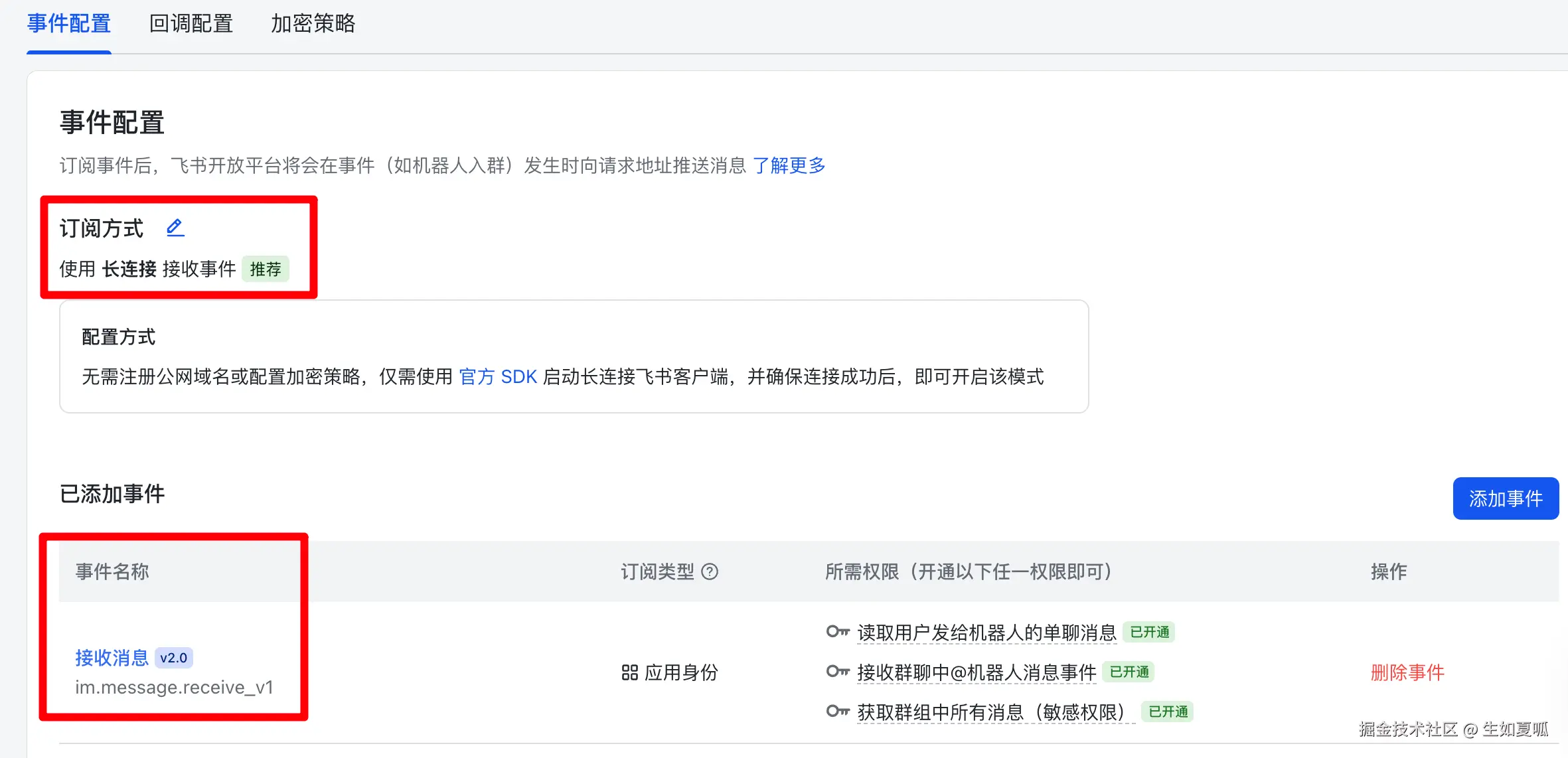
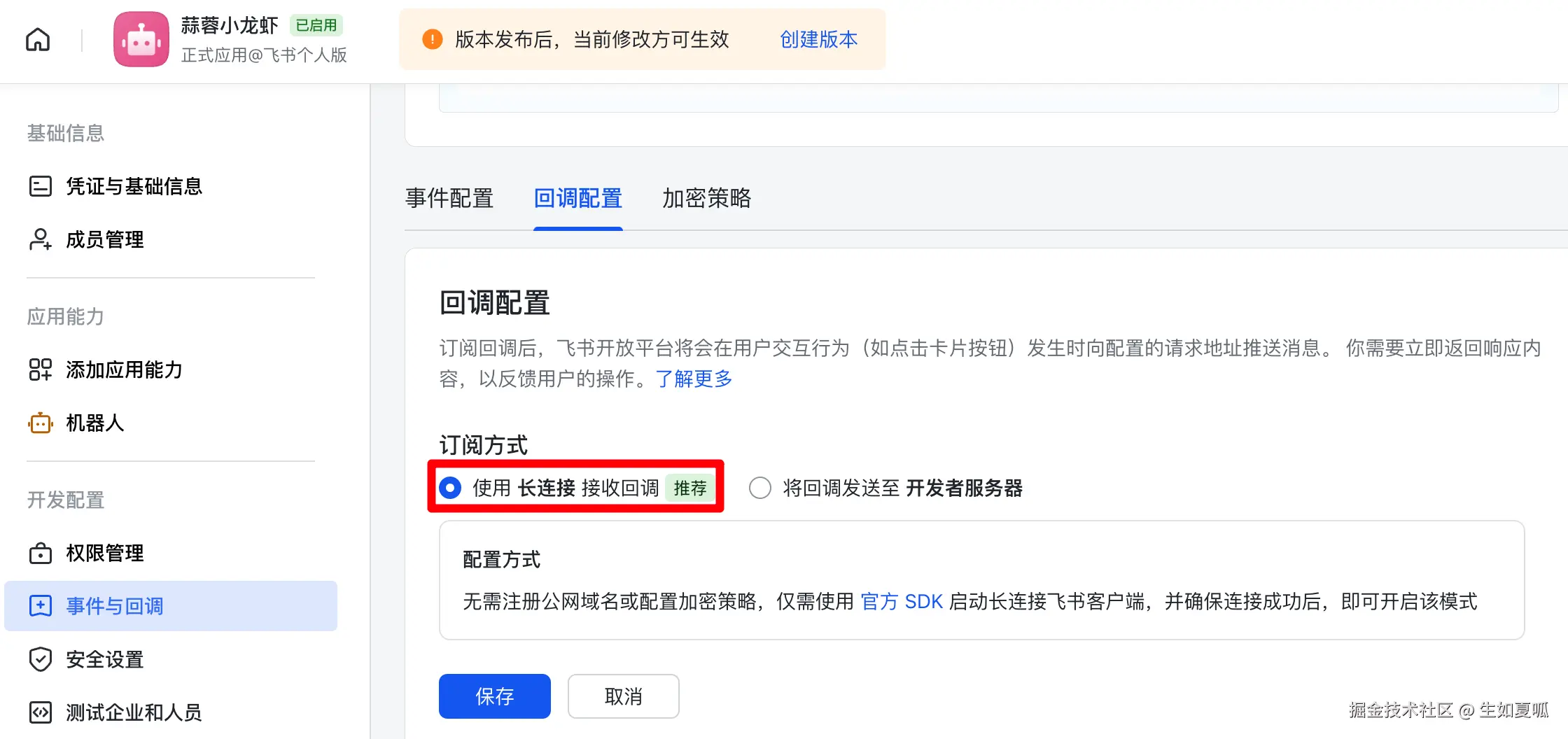
干得好,我们来发布一下:

回到飞书,发现机器人出现了输入框,说明一切正常。
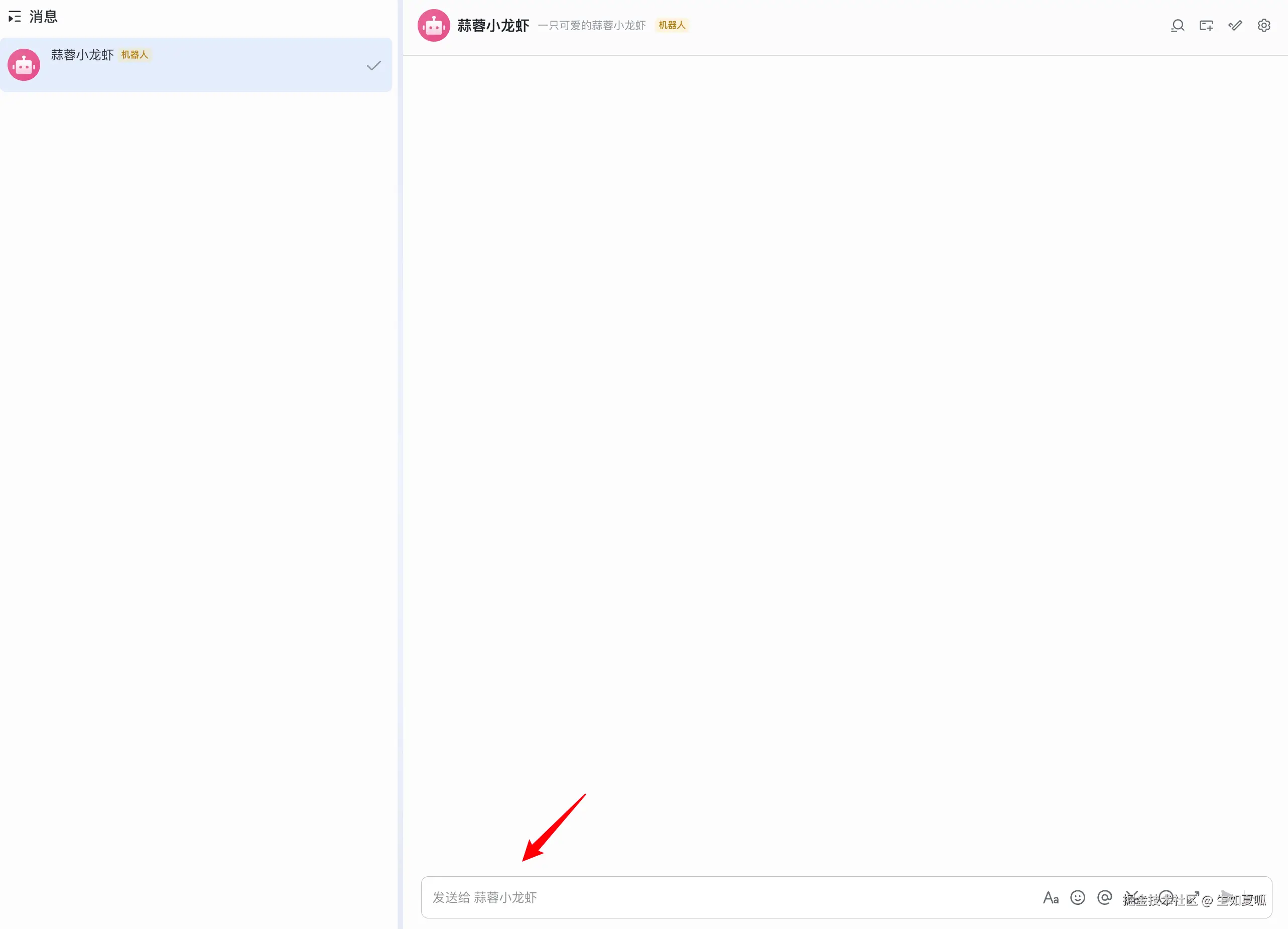
我们停止运行刚刚的代码,uv run main.py再次启动,一切顺利!
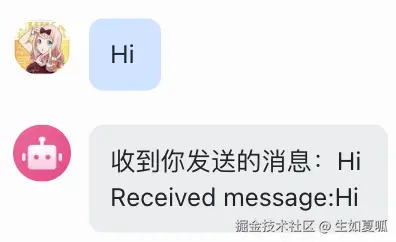
3. 让小龙虾变得聪明:接入 LLM
如上文所示,我们只能让机器人回复固定的消息,LLM 诞生以前,Siri、小爱同学一类的语音助手通过文本分类+实体识别+规则判断来决定自己的回复:
提问"帮我关闭卧室灯" -> 解析到"关闭""卧室""灯" -> 执行操作
LLM 诞生以后,它通过 Next Token Prediction 来进行文本的预测,在 Scaling law 的魔力下诞生了"智能"。现在我们把 LLM 接入到机器人里。
本文选取的模型是 DeepSeek,由于国产模型都很便宜,所以充十块钱可以体验很久,用不完还可以退回,你可以自行选择。我们进入到 Kimi/DeepSeek 的后台把 API Key 复制下来,写入到 .env 文件。
openai 库帮我们封装好了模型调用,所以安装它 uv add openai, 代码中导入并创建一个 openai 实例
Python
from openai import AsyncOpenAI
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY") # 根据实际情况写
llm_client = AsyncOpenAI(
api_key=DEEPSEEK_API_KEY,
base_url="https://api.deepseek.com" # 根据实际情况写
)然后改造一下消息接收函数(为了简单把处理非 p2p 消息的代码移除了):
Python
def do_p2_im_message_receive_v1(data: P2ImMessageReceiveV1) -> None:
res_content = ""
if data.event.message.message_type == "text":
###### 新增 ##########
response = llm_client.chat.completions.create(
model="deepseek-chat",
messages=[
{"role": "system", "content": "You are a helpful assistant"},
{"role": "user", "content": data.event.message.content},
],
stream=False,
)
res_content = response.choices[0].message.content
else:
res_content = "解析消息失败,请发送文本消息"
content = json.dumps({"text": res_content})
if data.event.message.chat_type == "p2p":
request = (
CreateMessageRequest.builder()
.receive_id_type("chat_id")
.request_body(
CreateMessageRequestBody.builder()
.receive_id(data.event.message.chat_id)
.msg_type("text")
.content(content)
.build()
)
.build()
)
response = client.im.v1.message.reply(request)
if not response.success():
raise Exception(
f"client.im.v1.message.create failed, code: {response.code}, msg: {response.msg}, log_id: {response.get_log_id()}"
)现在我们得到了一个能够使用 LLM 回复用户消息的机器人:
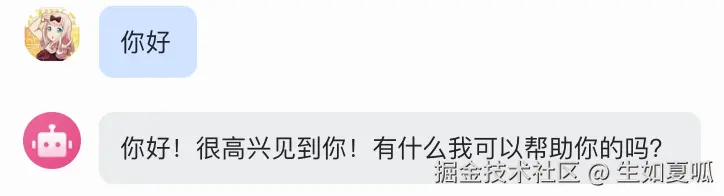
但是通过代码可以看出,每次发消息对于 LLM 来说都是新消息,也就是 llm_client.chat.completions.create 中的 messages 参数都会重新创建,所以我们得把上下文保存一下,那就使用一个全局列表变量吧。
Python
all_messages = [{"role": "system", "content": "You are a helpful assistant"}]
# 添加消息
def add_message(role: Literal["user", "assistant"], content: str):
all_messages.append({"role": role, "content": content})
def do_p2_im_message_receive_v1(data: P2ImMessageReceiveV1) -> None:
user_content = data.event.message.content
res_content = ""
if data.event.message.message_type == "text":
add_message(user_content) # 添加消息
response = llm_client.chat.completions.create(
model="deepseek-chat",
messages=all_messages,
stream=False,
)
res_content = response.choices[0].message.content
add_message("assistant", res_content) # 添加消息
logger.info(f"LLM response: {res_content}")
else:
res_content = "解析消息失败,请发送文本消息"
content = json.dumps({"text": res_content})
if data.event.message.chat_type == "p2p":
request = (
CreateMessageRequest.builder()
.receive_id_type("chat_id")
.request_body(
CreateMessageRequestBody.builder()
.receive_id(data.event.message.chat_id)
.msg_type("text")
.content(content)
.build()
)
.build()
)
response = client.im.v1.message.reply(request)
if not response.success():
raise Exception(
f"client.im.v1.message.create failed, code: {response.code}, msg: {response.msg}, log_id: {response.get_log_id()}"
)让我们重新运行测试一下:
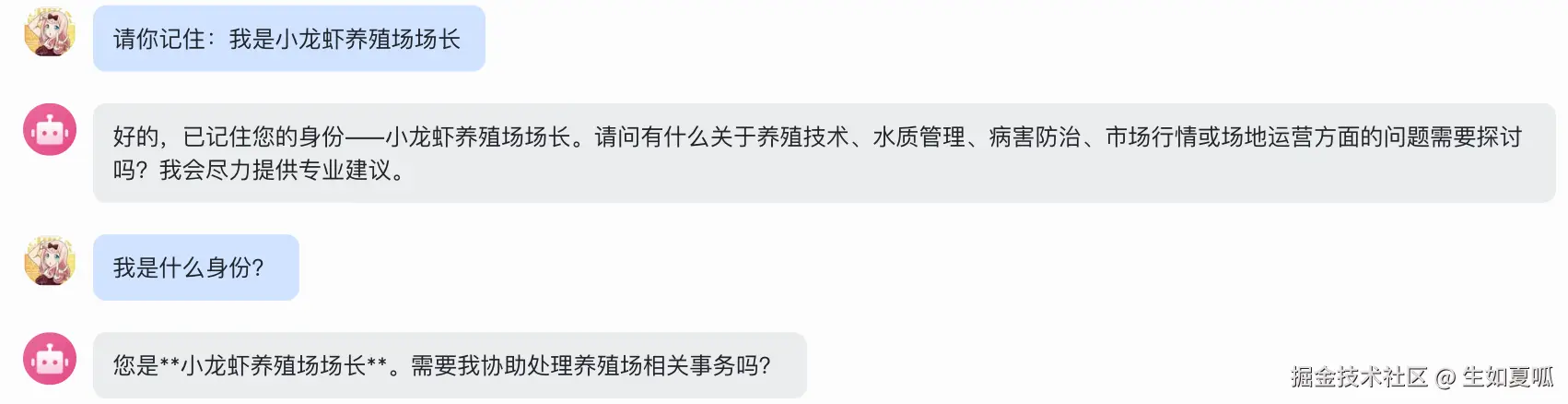
非常成功!如果你想关闭程序后依然恢复记忆,可以把上下文添加到一个 .jsonl 文件中,并且使用 langchain 之类的框架。此处为了简单不再展开。
4. 让虾钳拿起武器:准备工具
Claude Code 是2025年最火的 coding agent,没有之一。早些时候无论是 Copilot 还是 Cursor,都是在原有的 IDE GUI 的基础上做扩展,而 Claude Code 使用 TUI 作为开发者 Agent 之间的桥梁,重新定义了 AI 辅助软件开发。
如果你还不知道 Claude Code 的原理,可以参考这个仓库 learn-claude-code,它的核心就是工具调用+循环,这个过程通常被称作 agent loop,如下图所示。
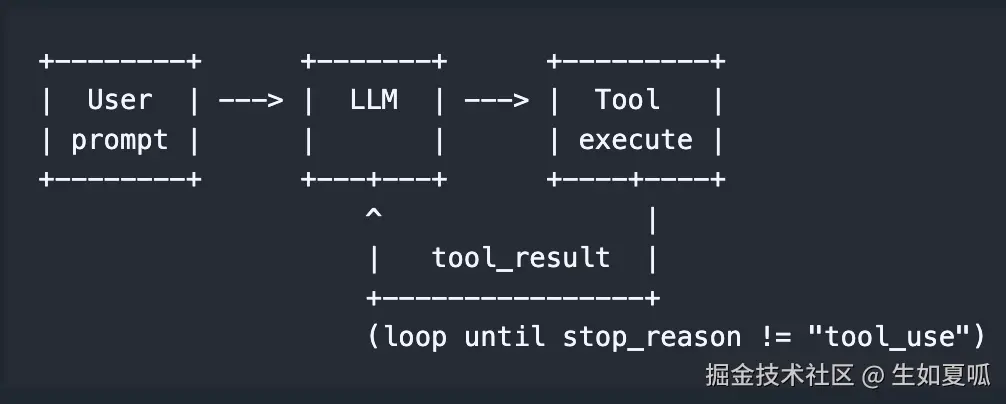
伪代码便于理解,可以写成
ini
# 初始化
current_message = lark_chat.user_message
final_reply = None
# 循环直到得到最终回复
while True:
llm_response = chat.completion(current_message)
# 如果 LLM 想调用工具,更新消息继续循环
if llm_response.use_tool:
current_message = llm_response.message
continue
# 如果 LLM 给出最终回复
if llm_response.final:
final_reply = llm_response.message
break # 结束循环
# 给用户回复
lark_chat.reply(final_reply)而我们只需要提供一个命令行工具 就能让 LLM 完成非常多的任务,比如创建文件 touch、查看文件 cat、修改文件 echo、定时任务 crontab 等,所以现在也有基于 Claude Code 的 OpenClaw 类似物实现,如 nanoclaw.
恰好 openai 的 completions 方法有一个参数叫 tools,接收的是一个列表,里面可以放一些我们提供的工具名和对应的描述、参数等,如果你还不是很了解,可以先阅读这个文档,它的用法如下:
Python
response = client.chat.completions.create(
messages=messages,
tools=[
{
"type": "function",
"name": "cmd_tool",
"description": "Run a shell command, e.g. `ls -l`",
"parameters": {
# 省略
}
}
] # 这里!
)我们开始编写这个工具,创建一个 cmd_tool.py,为了便于管理,将工具定义为一个类,需要有一个静态方法返回上面 openai 库需要的工具定义,还要有一个方法执行 LLM 需要执行的命令。
Python
import subprocess
class CmdTool:
def __init__(self):
pass
@staticmethod
def get_definition():
"""
OpenAI/DeepSeek 的 API 需要特定的格式:
{
"type": "function",
"function": {
"name": "...",
"description": "...",
"parameters": {...}
}
}
"""
return {
"type": "function",
"function": {
"name": "run_cmd",
"description": "Run a shell command, e.g. `ls -l`, `pwd`, `touch test.txt`",
"parameters": {
"type": "object",
"properties": {
"cmd": {
"type": "string",
"description": "The shell command to run",
}
},
"required": ["cmd"],
},
},
}
def execute(self, cmd: str):
result = subprocess.run(cmd, shell=True, capture_output=True, text=True)
return f"stdout: {result.stdout}\nstderr: {result.stderr}"创建一个 loop.py 文件,写上 agent loop 逻辑:
Python
import json
from cmd_tool import CmdTool
from openai import Client
from openai.types.chat.chat_completion import ChatCompletion
class AgentLoop:
def __init__(self, llm_client: Client, all_messages, max_iterations: int = 10):
self.used_tools = []
self.llm_client = llm_client
# all_messages 是列表,引用类型,可以直接在这里修改
self.all_messages = all_messages
# 最大迭代次数
self.max_iterations = max_iterations
# 本地存在的工具
self.toolsMap = {"run_cmd": CmdTool()}
# 工具定义,用于 openai 的 SDK
self.tools_definitions = [CmdTool.get_definition()]
# 记录LLM决定的调用
def add_assistant_message(
self, tool_call_id: str, tool_name: str, tool_arguments: dict
):
self.all_messages.append(
{
"role": "assistant",
"content": None,
"tool_calls": [
{
"id": tool_call_id,
"type": "function",
"function": {
"name": tool_name,
"arguments": json.dumps(tool_arguments),
},
}
],
}
)
# 记录调用结果
def add_tool_message(self, tool_call_id: str, result: str):
self.all_messages.append(
{
"role": "tool",
"content": result,
"tool_call_id": tool_call_id,
}
)
def add_user_message(self, content: str):
self.all_messages.append({"role": "user", "content": content})
def run(self, lark_user_content):
self.add_user_message(lark_user_content)
iteration = 0
while iteration < self.max_iterations:
iteration += 1
response: ChatCompletion = self.llm_client.chat.completions.create(
model="deepseek-chat",
messages=self.all_messages,
stream=False,
# 工具参数是一个列表,可以放多个,此处只放一个
tools=self.tools_definitions,
tool_choice="auto",
)
tool_calls = response.choices[0].message.tool_calls
content = response.choices[0].message.content
if response.choices[0].message.tool_calls and len(tool_calls) > 0:
for tool_call in tool_calls:
tool_name = tool_call.function.name
tool_arguments = json.loads(tool_call.function.arguments)
# 记录使用过的工具
self.used_tools.append(tool_name)
# 记录LLM决定的调用
self.add_assistant_message(tool_call.id, tool_name, tool_arguments)
# 执行工具
result = self.toolsMap[tool_name].execute(**tool_arguments)
# 记录工具执行结果
self.add_tool_message(tool_call.id, result)
else:
# 没有工具调用,直接返回
return content, self.used_tools然后改造一下 main.py 中回复消息函数:
Python
import lark_oapi as lark
from lark_oapi.api.im.v1 import *
import json
from dotenv import load_dotenv
from loguru import logger
import os
from openai import OpenAI
from typing import Literal
from loop import AgentLoop
load_dotenv()
APP_ID = os.getenv("APP_ID")
APP_SECRET = os.getenv("APP_SECRET")
DEEPSEEK_API_KEY = os.getenv("DEEPSEEK_API_KEY")
logger.info(f"APP_ID: {APP_ID}")
logger.info(f"APP_SECRET: {APP_SECRET}")
llm_client = OpenAI(api_key=DEEPSEEK_API_KEY, base_url="https://api.deepseek.com")
all_messages = [{"role": "system", "content": "You are a helpful assistant"}]
agent_loop = AgentLoop(llm_client, all_messages)
lark_messages_set = set()
# 注册接收消息事件,处理接收到的消息。
# Register event handler to handle received messages.
# https://open.feishu.cn/document/uAjLw4CM/ukTMukTMukTM/reference/im-v1/message/events/receive
def do_p2_im_message_receive_v1(data: P2ImMessageReceiveV1) -> None:
user_content = data.event.message.content
res_content = ""
if data.event.message.message_id in lark_messages_set:
logger.info(f"重复消息,message_id: {data.event.message.message_id}")
return
else:
lark_messages_set.add(data.event.message.message_id)
if data.event.message.message_type == "text":
res_content, used_tools = agent_loop.run(user_content)
else:
res_content = "解析消息失败,请发送文本消息"
content = json.dumps(
{"text": res_content + f" 已使用工具:{', '.join(used_tools)}"}
)
if data.event.message.chat_type == "p2p":
request = (
CreateMessageRequest.builder()
.receive_id_type("chat_id")
.request_body(
CreateMessageRequestBody.builder()
.receive_id(data.event.message.chat_id)
.msg_type("text")
.content(content)
.build()
)
.build()
)
response = client.im.v1.message.reply(request)
if not response.success():
raise Exception(
f"client.im.v1.message.create failed, code: {response.code}, msg: {response.msg}, log_id: {response.get_log_id()}"
)
# 注册事件回调
# Register event handler.
event_handler = (
lark.EventDispatcherHandler.builder("", "")
.register_p2_im_message_receive_v1(do_p2_im_message_receive_v1)
.build()
)
# 创建 LarkClient 对象,用于请求OpenAPI, 并创建 LarkWSClient 对象,用于使用长连接接收事件。
# Create LarkClient object for requesting OpenAPI, and create LarkWSClient object for receiving events using long connection.
client = lark.Client.builder().app_id(APP_ID).app_secret(APP_SECRET).build()
wsClient = lark.ws.Client(
APP_ID,
APP_SECRET,
event_handler=event_handler,
log_level=lark.LogLevel.DEBUG,
)
def main():
# 启动长连接,并注册事件处理器。
# Start long connection and register event handler.
wsClient.start()
if __name__ == "__main__":
main()现在让我们来看看,问两个问题:


太好了,大功告成,但是有的时候我们会遇到飞书消息重复推送的情况

我们可以按照官方文档处理一下,设置一个集合
Python
# 省略代码...
lark_messages_set = set()
def do_p2_im_message_receive_v1(data: P2ImMessageReceiveV1) -> None:
# 省略其他代码...
if data.event.message.message_id in lark_messages_set:
logger.info(f"重复消息,message_id: {data.event.message.message_id}")
return
else:
lark_messages_set.add(data.event.message.message_id)
# 省略其他代码...
其实定时任务也是一个工具,可以参考 nanobot 的实现,加载 SKILLS 也不难,就是把它的说明文件加载到 system prompt 中,例如
Python
parts.append(f"""
# Skills
The following skills extend your capabilities. To use a skill, read its SKILL.md file using the read_file tool.
Skills with available="false" need dependencies installed first - you can try installing them with apt/brew.
{skills_summary}""")这里就不过多赘述,现在我们就实现了一个能调用工具的 Agent,完结撒花 🎉