场景
Spring AI RAG 检索增强生成:概念、实战与完整代码:
https://blog.csdn.net/BADAO_LIUMANG_QIZHI/article/details/161055108
基于之前的 RAG 示例,下面系统讲解如何将内存向量库 SimpleVectorStore
替换为生产级的持久化向量数据库,并提供完整集成方案。
Spring AI 支持的向量数据库概览
Spring AI 通过统一抽象的 VectorStore 接口,支持多种向量数据库,仅需更改依赖和配置即可切换,业务代码无需变动。
| 数据库 | 特点 | 适用场景 |
|---|---|---|
| PgVector | 基于 PostgreSQL,S QL 生态成熟,运维简单 | 已有 PostgreSQL 的生产环境 |
| Elasticsearch | 全文搜索 + 向量搜索,混合检索能力强 | 需要文本+向量混合查询的场景 |
| Milvus | 专为向量设计的云原生数据库,海量数据性能优秀 | 亿级向量相似度搜索 |
| Weaviate | 开源向量数据库,支持 GraphQL 和多模态 | 需要灵活 Schema 和快速原型 |
| Chroma | 轻量级,面向开发者体验,Python/JS 生态成熟 | 中小规模应用,快速开发 |
| Redis Stack | 基于 Redis,低延迟,内存+持久化 | 高并发实时检索 |
下面使用Milvus的方式。
在 Windows 上安装 Milvus
Milvus 官方推荐使用 Docker 安装,这是最简单、兼容性最好的方式
在 Windows 上除了使用 Docker 部署 Milvus ,还可以使用如下方式。
使用 milvus 包(Milvus Lite)极速部署:
准备工作:安装 Python 和管理环境
首先要确保有一个干净的 Python 环境。
强烈推荐用 conda 来管理,可以避免包版本冲突。
安装 Miniconda:
去 Miniconda 官网下载 Windows 安装包,
安装时记得勾选"Add Miniconda3 to my PATH environment variable"。
访问官网:打开
https://www.anaconda.com/download/
找到 Miniconda:在页面中向下滚动,找到 "Miniconda Installers" 部分
选择版本:点击 Windows 图标下的安装包即可下载。通常选择 64-Bit 版本。
开始安装:
下载完成后,双击 .exe 文件,按照安装向导的提示完成安装。
建议在安装过程中勾选 "Add Miniconda3 to my system PATH environment variable",
这样可以方便后续在命令行中直接使用 conda 命令
创建虚拟环境:安装完成后,打开终端(PowerShell 或 CMD)执行:
# 创建并激活一个名为 milvus_env 的环境,使用兼容稳定的 Python 3.10
conda create --name milvus_env python=3.10
conda activate milvus_env核心安装:三步完成服务部署
第一步:
安装核心库:在激活的 milvus_env 环境中执行,以安装轻量版的 Milvus 服务器程序。
pip install milvus第二步:
创建数据目录:在你的电脑上新建一个空文件夹,用于存放 Milvus 的所有数据(如 D:\milvus_data)。
第三步:
启动 Milvus 服务:在终端中执行以下命令,指定数据目录启动服务
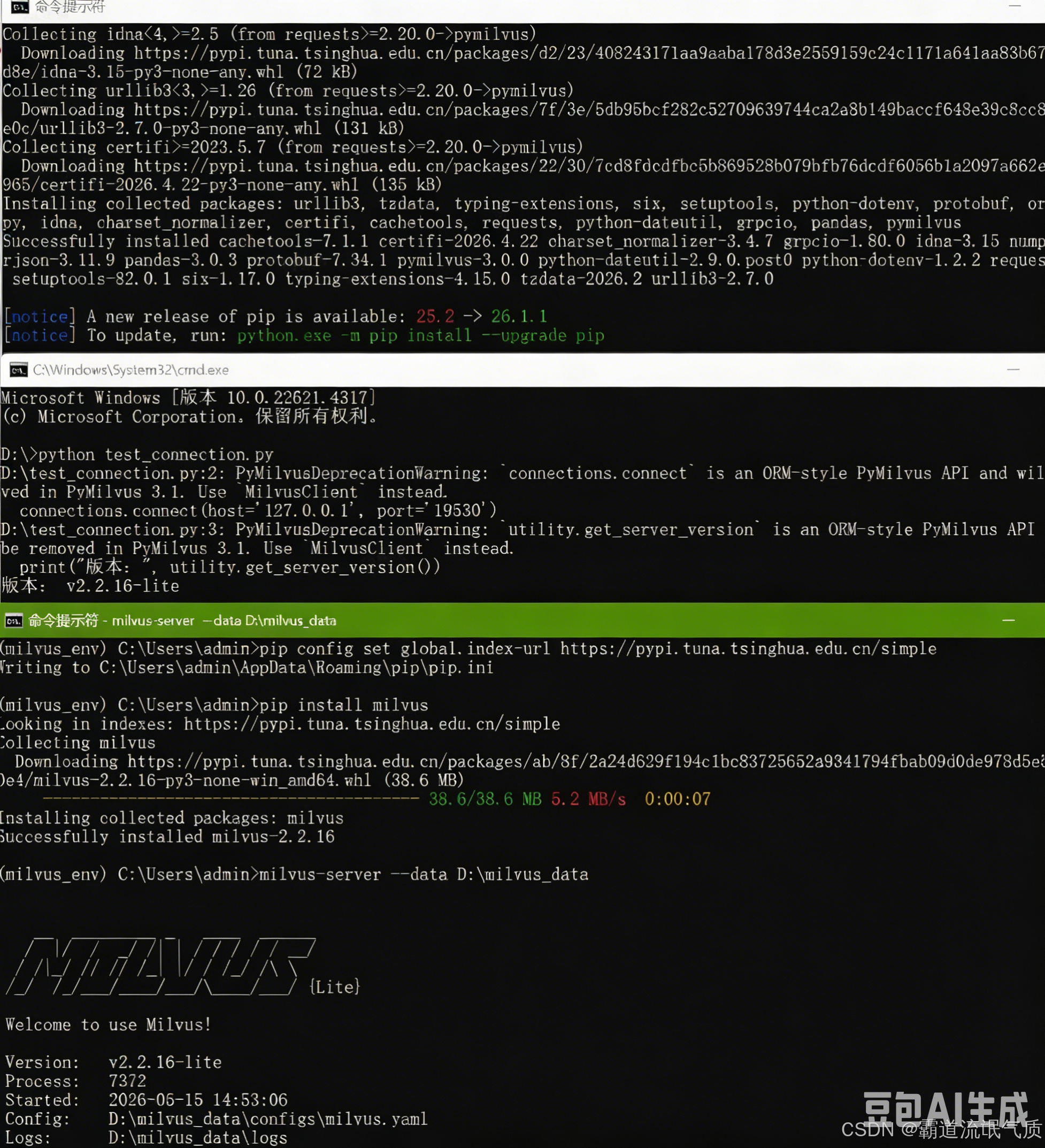
milvus-server --data D:\milvus_data看到类似 INFO:milvus_server:Server started 的日志输出,就表示服务已成功运行。
验证连接:安装客户端并测试
服务启动后,需要安装 Python 客户端 pymilvus 来验证连接。
安装客户端 SDK:新开一个终端窗口并激活 milvus_env 环境,执行:
pip install pymilvus运行测试脚本:
接着,创建一个 test_connection.py 文件,并将下方代码复制进去并运行。如果输出服务端版本信息,就代表一切就绪。
from pymilvus import connections, utility
try:
# 连接到本地运行的Milvus服务
connections.connect(host='127.0.0.1', port='19530')
print("成功连接到Milvus服务!")
# 获取并打印服务端版本信息
version = utility.get_server_version()
print(f"Milvus服务端版本: {version}")
except Exception as e:
print(f"连接Milvus服务失败: {e}")测试效果:
注:
博客:
https://blog.csdn.net/badao_liumang_qizhi
Spring AI 项目集成指南
添加依赖
在你的 pom.xml 中加入 Milvus 的 Starter。
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-milvus</artifactId>
</dependency>完整pom
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.4.5</version>
</parent>
<groupId>com.example</groupId>
<artifactId>spring-ai-ollama-es</artifactId>
<version>1.0</version>
<properties>
<java.version>17</java.version>
<spring-ai.version>1.1.2</spring-ai.version>
</properties>
<!-- 新增:使用 Spring AI BOM 统一管理所有模块版本 -->
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-bom</artifactId>
<version>${spring-ai.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!-- Spring AI Ollama 核心 -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-ollama</artifactId>
</dependency>
<!-- 【关键依赖】Spring AI Vector Store Advisor (提供 QuestionAnswerAdvisor) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-advisors-vector-store</artifactId>
</dependency>
<!-- Tika 文档读取器(支持 PDF、Word、TXT 等多种格式) -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>
<!-- 【核心】Milvus 向量存储 Starter -->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-milvus</artifactId>
</dependency>
</dependencies>应用配置
在 application.yml 中配置连接。milvus 包启动的服务同样在默认的 19530 端口工作。
server:
port: 886
spring:
ai:
ollama:
base-url: http://localhost:11434
chat:
model: qwen2.5:7b-instruct
options:
temperature: 0.3 # RAG 场景建议使用较低温度,减少幻觉
embedding:
model: nomic-embed-text # Embedding 模型(用于文档向量化)
options:
num-batch: 4 # 一次处理的文本数量
vectorstore:
milvus:
client:
host: localhost
port: 19530
database-name: default
collection-name: spring_ai_docs # 向量集合名
index-type: IVF_FLAT
metric-type: IP # 相似度计算方式
embedding-dimension: 768 # 务必与 nomic-embed-text 输出维度一致
initialize-schema: true # 首次启动自动创建 Collection
logging:
level:
org.springframework.ai.vectorstore.milvus: DEBUG
Java 配置代码
由于我们已经通过 Starter 引入了 Milvus 的自动配置,无需手动创建 VectorStore Bean,直接注入即可。
VectorStoreConfig.java
负责在应用启动时加载文档并写入向量库。
package com.badao.ai.config;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.ai.document.Document;
import org.springframework.ai.document.DocumentReader;
import org.springframework.ai.reader.tika.TikaDocumentReader;
import org.springframework.ai.transformer.splitter.TokenTextSplitter;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.CommandLineRunner;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.Resource;
import java.util.List;
@Configuration
public class VectorStoreConfig {
private static final Logger logger = LoggerFactory.getLogger(VectorStoreConfig.class);
@Value("classpath:knowledge-base/badao-internal.txt")
private Resource knowledgeResource;
@Bean
public CommandLineRunner loadDocuments(VectorStore vectorStore) {
return args -> {
// 1. 使用 Tika 读取文档(自动检测文件类型)
DocumentReader reader = new TikaDocumentReader(knowledgeResource);
List<Document> documents = reader.get();
logger.info("共读取到 {} 个文档", documents.size());
// 2. 文本分块(TokenTextSplitter 按语义切分,更适合中文)
TokenTextSplitter splitter = TokenTextSplitter.builder()
.withChunkSize(300) // 每个块最多 300 token
.withMinChunkSizeChars(50) // 最小块字符数,避免出现极短碎片(替代原来 minChunkSize 的功能)
.withMinChunkLengthToEmbed(5) // 保留默认,过滤极短内容
.withKeepSeparator(true) // 保留原文换行等分隔符
.build();
List<Document> chunks = splitter.apply(documents);
logger.info("文本切分为 {} 个片段", chunks.size());
// 3. 写入向量数据库(自动调用 EmbeddingModel 向量化)
vectorStore.add(chunks);
logger.info("向量化完成,向量库初始化成功!");
};
}
}RagConfig.java
负责创建绑定 RAG Advisor 的 ChatClient
package com.badao.ai.config;
import org.springframework.ai.chat.client.ChatClient;
import org.springframework.ai.chat.client.advisor.vectorstore.QuestionAnswerAdvisor;
import org.springframework.ai.chat.model.ChatModel;
import org.springframework.ai.vectorstore.SearchRequest;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class RagConfig {
@Bean
public ChatClient chatClient(ChatModel chatModel, VectorStore vectorStore) {
return ChatClient.builder(chatModel)
.defaultAdvisors(
QuestionAnswerAdvisor.builder(vectorStore)
.searchRequest(SearchRequest.builder()
.similarityThreshold(0.7) // 相似度阈值
.topK(3) // 返回前 3 个最相关文档
.build())
.build()
)
.build();
}
}RagService.java 与 RagController.java 保持不变,可直接沿用前述示例代码,无需任何改动。
运行测试
确保 Ollama 已启动,nomic-embed-text 和 qwen2.5:7b-instruct 模型已下载。
确保 Milvus Lite 服务已在终端保持运行状态。
启动 Spring Boot 应用,观察日志应输出"Milvus 向量库初始化成功"。
使用 curl 或 Postman 测试接口
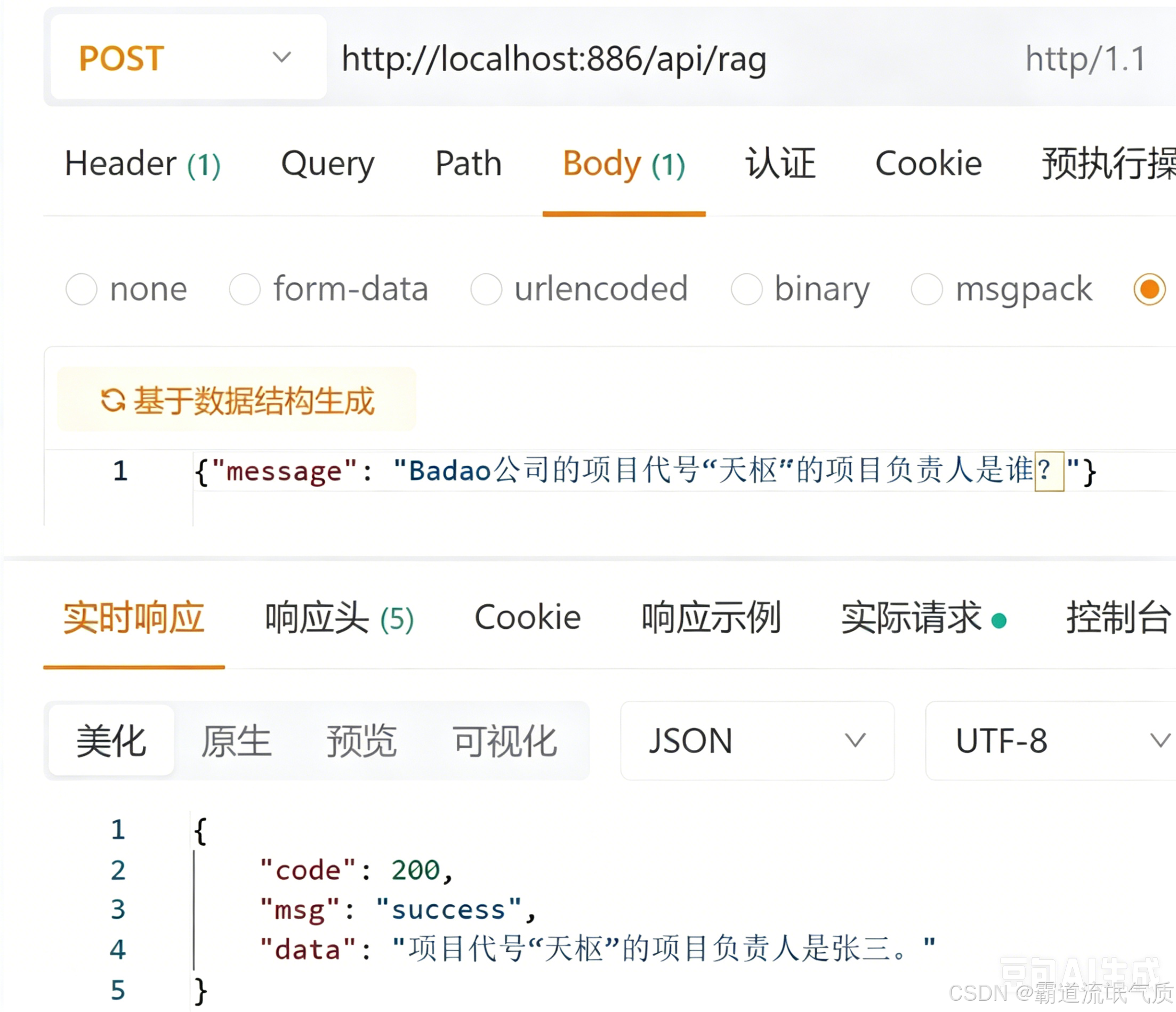
方案优势与注意事项
轻量便捷:
无需 Docker,无需复杂的环境配置,几行命令即可在 Windows 上运行。
兼容性强:
API 与生产级 Milvus 完全一致,后续如需迁移至集群版,只需修改 application.yml 中的连接地址。
持久化存储:
通过 --data 指定的目录保存数据,应用重启后知识库依然存在,无需重复加载文档。
注意事项:
Milvus Lite 仅适用于开发和测试,不建议直接用于生产环境。若需生产部署,
可将 milvus 包替换为标准版 Milvus (Standalone/Cluster),无需修改代码。