DeepAgents框架详解
DeepAgents 是 LangChain 团队 在 LangChain 和 LangGraph 之上推出的 第三个独立开源项目 ,是一个 "开箱即用"的深度智能体框架,指能够在较长时间范围内完成复杂、开放式任务的深度智能体。该框架已作为Python包开源发布,整合了深度智能体的四大核心要素:规划工具、文件系统访问、子智能体委托和详细提示词。
1. 核心架构设计
DeepAgents采用主-子智能体(MainAgent-SubAgents)架构 。主Agent作为系统入口和总指挥,接收初始任务,以ReAct方式调用工具完成任务,并负责任务协调与结果呈现;主Agent可通过task.spawn()方法动态创建具有独立上下文窗口的子Agent。SubAgents负责执行具体、独立的子任务,与MainAgent上下文独立,即使子Agent崩溃也不会影响主进程。
Deep Agents 并非颠覆性技术创新,而是将业界验证过的最佳实践打包成开箱即用的框架。它的灵感来源于 Claude Code、Deep Research、Manus 等成功应用,这些应用证明了四个关键点:
•Agent 需要规划能力------ 不能上来就开干,得先拆解任务
•Agent 需要文件系统------ 长对话中,得有地方放中间结果,需要加载本地环境
•Agent 需要子 Agent------ 单体 Agent 会被上下文撑爆
•Agent 需要子 Skills------ Agent 功能可以弹性扩展,并且支持模块化开发。
LangChain 团队的想法很简单:既然这些经验都验证过了,为什么不打包成一个库?于是就有了 Deep Agents。
2. 核心技术能力
(1)结构化规划引擎
框架内置write_todos和read_todos工具,强制要求智能体在执行前生成任务清单。这一设计借鉴了项目管理中的WBS(工作分解结构)理论,将抽象任务转化为可执行的子任务序列,有效避免因随机探索导致的执行失败。
规划机制采用两阶段设计:全局规划阶段使用LLM生成高层次任务分解,局部优化阶段基于执行反馈动态调整任务顺序。实验数据显示,该机制可使复杂任务完成效率提升40%。
(2)持久化文件系统
DeepAgents提供完整的文件系统抽象层,包含6类核心操作:read_file/write_file/edit_file(文件读写)、ls/mkdir/rm(目录管理)、glob/grep/find(内容检索)。
在DeepAgents 0.2版本中,该文件系统进一步升级为可插拔后端 架构。内置后端包括:LangGraph State(内存存储)、LangGraph Store(跨线程持久化)、实际本地文件系统。还引入了复合后端概念,允许将不同子目录映射到不同存储后端,例如将/memories/目录映射到S3对象存储,实现跨会话的长期记忆。
测试数据显示,在10K tokens的长对话场景中,使用文件系统的智能体推理准确率比纯内存存储高27%。
(3)子智能体协作网络
框架采用主-子架构,主Agent负责任务分配和全局协调,子Agent池包含数据清洗、统计分析、可视化等多类专精智能体。动态调度机制基于实时负载和技能匹配度进行任务分配。在金融风控场景测试中,包含5个子Agent的协作网络可在8分钟内完成传统方案需2小时的风险评估流程。
每个子Agent拥有独立的上下文窗口和工具集,支持并行执行多个子Agent,大幅提升复杂任务处理效率。
(4)上下文与成本优化
DeepAgents内置多项优化机制:当工具返回结果超过设定token阈值时自动转存至文件系统,避免上下文窗口被大型结果占据;当对话历史token用量过大时自动压缩早期对话内容;若工具调用在执行前被中断或取消,自动修复消息历史。这些机制显著降低token成本并保持任务执行效率。
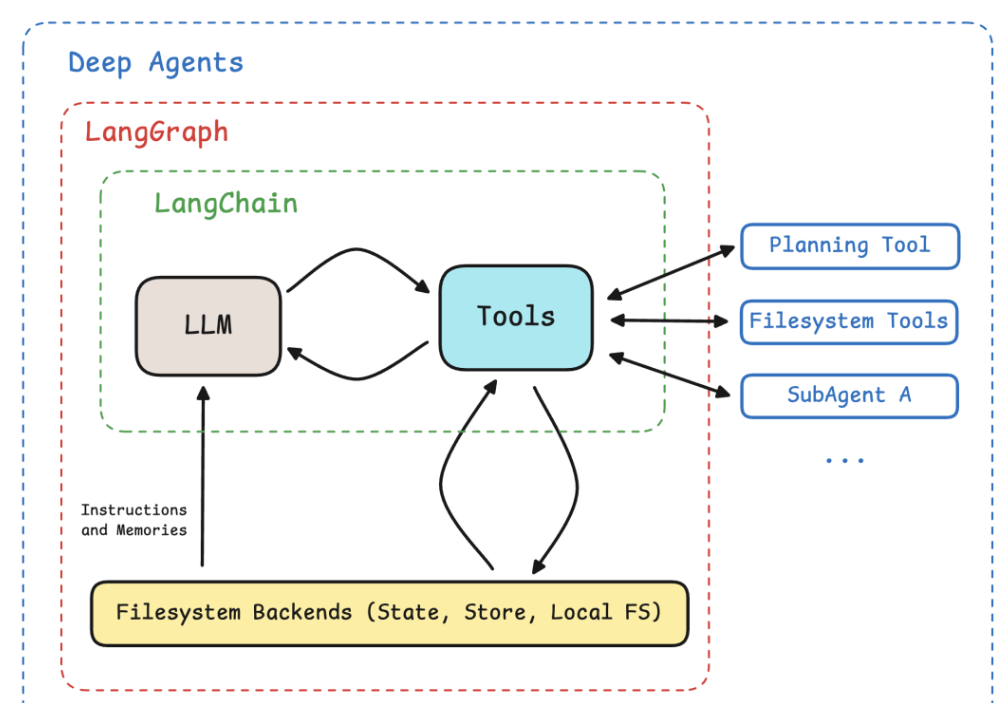
3. 技术栈定位
DeepAgents构建在LangChain的智能体抽象层之上,而LangChain的智能体抽象层又基于LangGraph的智能体运行时环境开发,形成清晰的三层架构:
-
LangGraph(底层运行时引擎):提供原子级控制能力,负责流程执行与状态管理
-
LangChain(中间层应用框架):封装常用组件,提供工具集成和快速组装能力
-
DeepAgents(顶层Agent构建器):实现开箱即用的智能体构建,聚焦复杂自主任务
LangChain将三者分别定义为:DeepAgents是"Agent Harness(智能体工具)",LangChain是"Agent Framework(智能体框架)",LangGraph是"Agent Runtime(智能体运行时环境)"
4.与传统多智能体框架对比

5.DeepAgents的核心优势
DeepAgents的核心理念是"为复杂问题提供系统化的工程解决方案"。它不是简单地将多个Agent堆叠在一起,而是通过四大支柱(规划引擎、文件系统、子Agent协作、提示词工程)从根本上解决了传统多智能体系统的核心痛点:
-
从不可控到确定性:将传统Agent的"黑箱探索"转化为基于规划工具的结构化执行
-
从上下文爆炸到持久化管理:用文件系统解耦信息存储与推理,突破LLM的上下文窗口限制
-
从手动编排到开箱即用:预置规划模板、文件操作工具和多Agent协作框架,大幅降低开发门槛
-
从串联到并行:支持子Agent独立执行和计算隔离,实现真正的分布式协作
因此,DeepAgents特别适合需要处理复杂、多步骤、长期运行任务的场景,如自动化研究、数据分析流水线、智能客服系统等。对于需要精确控制执行顺序、对实时性要求极高的场景(如金融风控系统),LangGraph是更合适的选择;而对于需要快速验证AI能力、实现简单工具调用链的场景,LangChain则更具优势。
6.Harness Engineering
1、什么是 Harness Engineering(驾驭工程)?
• Prompt Engineering(2022-2024 主流)主要优化单次交互的质量,重点是 "一句提示词该怎么写,模型才更容易给出想要的结果"
• Context Engineering(2025 年2月后兴起)则动态构建知识、记忆、RAG,解决 "模型看什么" 的问题,减少幻觉、提高检索命中率
• Harness Engineering(当前阶段)重点构建整个运行环境,解决 "模型怎么把长链路任务稳定做完" 的系统级问题。
Harness Engineering 是当前 AI Agent 开发领域的一个核心范式转变。它不再仅仅关注如何通过提示词(Prompt Engineering)或上下文管理(Context Engineering)来"优化模型输出",而是聚焦于构建包裹在模型之外的一整套系统化基础设施 ,旨在将大语言模型(LLM)那种"不稳定、非确定性"的智能,转化为能够稳定、可靠、长时间执行复杂任务的工作引擎。
-
核心定义 :Harness(马具/缰绳)指的是除了模型本身之外的所有东西------工具、记忆、规划、安全护栏、执行循环、状态管理等。LangChain 团队将其精炼为公式:Agent = Model + Harness。
-
模型(Model):负责思考和决策
-
驾驭层(Harness):负责把思考变成稳定执行,决定Agent能访问什么、能调用什么、能走到哪一步、什么时候停下、出了错怎么回退、结果如何校验
-
-
解决的问题:传统 Agent 在应对长周期、多步骤的复杂任务时,常面临上下文窗口爆炸、状态丢失、工具调用混乱、缺乏规划、无法从失败中恢复等工程难题。Harness Engineering 正是为了解决这些"工程上的'稳'的问题"而生的。
2.DeepAgents 中全面采用 Harness Engineering:
- DeepAgents 框架本身就是 Harness Engineering 思想的具体实现。DeepAgents 可以看作是 Harness Engineering 理念的一个具体技术实现,它通过内置能力,为 Agent 提供了稳定运行的"内核",让开发者无需从零搭建复杂系统,只需通过配置即可获得一个功能完备的深度智能体。
7.开发建议和agent封层
-
底层框架 (如LangChain)解决通用性问题。提供
create_agent,tool, LLM调用等高层抽象和标准组件。- 简单、直接的任务 → 使用
LangChain的create_agent。
- 简单、直接的任务 → 使用
-
专项框架(如LangGraph for 多Agent, DeepAgents for 长任务)在通用框架上针对特定场景做深度优化。
-
LangGraph:提供最底层的状态管理、工作流编排。需要完全自定义、复杂控制流的工作流 → 使用
LangGraph从底层构建。 -
DeepAgents:专为 "重任务" 设计,不适合简单聊天机器人,需要处理复杂、多步骤、长时间运行的"深度"任务 → 选择
DeepAgents。其典型场景包括:
-
深度研究与报告撰写:自动进行多轮搜索、阅读、分析并生成长篇报告。
-
全栈代码生成与重构:在沙箱中编写、测试、调试和重构整个代码库。
-
复杂数据分析流水线:连接数据库、执行查询、处理中间文件并生成可视化图表。
-
自动化运维与业务流程:操作文件、执行命令、编排需要多角色协作的复杂工作流。
-
-
案例
import asyncio
import uuid
from deepagents import CompiledSubAgent, create_deep_agent
from langchain.agents import create_agent
from langchain_core.messages import HumanMessage
from langchain_mcp_adapters.client import MultiServerMCPClient
from agent.my_llm import llm
bazi_mcp_server_config = {
"transport": "streamable_http",
"url": "https://mcp.api-inference.modelscope.net/3d52f9994fce47/mcp"
}
my12306_mcp_server_config = {
"transport": "sse",
"url": "https://mcp.api-inference.modelscope.net/a6e1af0f976b4f/sse"
}
mcp_client = MultiServerMCPClient({
"bazi": bazi_mcp_server_config,
"12306": my12306_mcp_server_config,
})
system_prompt = '''
# 角色与核心目标
你是主协调智能体,负责高效处理用户请求。你的首要任务是分析用户问题,若其属于预设的专门领域,则分配给相应的子智能体处理;否则,由你亲自解答。
# 任务分配规则
请严格依据以下关键词和领域描述,决定是否进行任务分配:
## 八字智能体负责领域
- **负责内容**:提供精准的八字数据,助力性格分析、命运预测等应用。
- **触发关键词**:八字,命运,命理,玄学。
## 12306铁路查询子智能体负责领域
- **负责内容**:一切与中国铁路客运相关的问题,特别是车票查询和预订。
- **触发关键词**:火车、高铁、动车、车次、车票、票价、余票、时刻表、火车站、车站、12306、订票、购票、抢票、列车、站台、正晚点、检票口。
# 工作流程
1. **分析请求**:仔细阅读用户问题,识别其中的核心意图和关键词。
2. **匹配领域**:将识别出的关键词与上述"负责领域"进行匹配。
- 如果问题**明确且主要**属于某一个子领域(例如,问题中同时包含"八字"和"命理"),则毫不犹豫地将任务分配给对应的子智能体。
- 如果问题**同时涉及**两个子领域(例如,"帮我查一下去上海的火车票,并规划一下从家到火车站的地铁路线"),这是一个需要协调的复杂任务。当前版本请你直接处理,向用户说明这是一个复杂请求,并尝试分步骤给出建议或优先处理其中一个最明确的需求。
- 如果问题**不属于**上述任何子领域,则由你亲自回答。
3. **执行与响应**:一旦做出分配决定,即调用相应的子智能体,并将其回复完整地呈现给用户。若是你亲自回答,请确保回应清晰、准确、有帮助。
# 通用行为规范
- 你的回答应保持专业、友好和乐于助人的态度。
- 如果无法确定用户意图,或问题模糊,应主动询问澄清。
- 对于超出你知识范围或工具能力的问题,如实告知,不要编造信息。
'''
async def create_my_agent():
bazi_tools = await mcp_client.get_tools(server_name="bazi")
railway_tools = await mcp_client.get_tools(server_name="12306")
gaode_assistant = create_agent(
model=llm,
tools=bazi_tools,
system_prompt="您是一位命理八字的子Agent,提供精准的八字数据,助力性格分析、命运预测等应用"
)
gaode_subagent = CompiledSubAgent(name="gaode_assistant", description="提供精准的八字数据,助力性格分析、命运预测等应用的智能体", runnable=gaode_assistant)
railway_assistant = create_agent(
model=llm,
tools=railway_tools,
system_prompt="您是一位12306铁路查询的子Agent,负责查询火车站、高铁站的信息和查询各种火车、高铁票。"
)
railway_subagent = CompiledSubAgent(
name="railway_assistant",
description="专门查询火车站、高铁站的信息和查询各种火车、高铁票的智能体",
runnable=railway_assistant
)
subagents = [gaode_subagent, railway_subagent]
return create_deep_agent(model=llm, subagents=subagents, system_prompt=system_prompt)
#deep_agent = asyncio.run(create_my_agent())
async def run_agent():
deep_agent = await create_my_agent()
config = {
"configurable": {
"thread_id": str(uuid.uuid4())
}
}
res = await deep_agent.ainvoke(
#input={'messages': [HumanMessage(content='明天2026年5月15日,我需要从长沙到北京出差,我要做高铁到北京西站,帮我查一下高铁票,并且帮我推荐一下北京西站附近3公里返回内的3家酒店')]},
input={'messages': [HumanMessage(content='我是男生出生于1990年3月19日,帮我查一下八字')]},
config=config
)
print(res["messages"][-1].content)
asyncio.run(run_agent())文件后端(Backend)系统
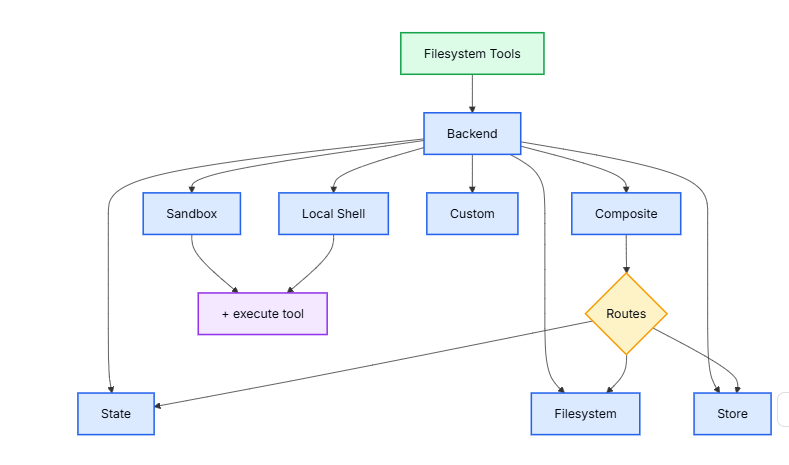
后端是智能体(Agent)文件系统工具的底层实现,它决定了Agent可以访问哪些存储介质(如内存、本地磁盘、数据库等)以及如何访问。
DeepAgents 通过一套文件系统工具(如 ls, read_file, write_file等)为Agent提供与外界存储交互的能力。这些工具并不直接操作存储,而是通过一个可插拔的后端 (Backend)来执行实际的操作。后端是一个遵循特定协议(BackendProtocol)的组件。
Agent的文件系统工具调用后端,后端再根据配置将操作路由到不同的具体存储实现,DeepAgents 提供了多种开箱即用的后端,适用于不同场景。例如:
-
状态存储 (
StateBackend): 存储在 LangGraph 状态中,单次会话有效。 -
本地磁盘 (
FilesystemBackend): 访问宿主机的真实文件系统。 -
持久化存储 (
StoreBackend): 使用 LangGraph 的BaseStore实现跨会话持久化。 -
沙盒/本地Shell (
Sandbox,LocalShellBackend): 提供隔离或非隔离的执行环境。 -
复合后端 (
CompositeBackend): 作为路由器,将不同路径的请求分发到不同的后端。
默认后端是 StateBackend ,它将文件存储在Agent的运行时状态中,仅在一次执行线程内有效。
1、StateBackend (临时状态后端)
-
工作原理 :将文件数据存储在 LangGraph 的Agent状态(
runtime.state)中。这些数据在同一个执行会话(thread)的多次调用间是持久的,但线程(会话)结束后即消失。当然:如果有Checkpointer快照机制,那么也能恢复。 -
最佳用途:作为Agent的草稿纸,用于暂存中间结果。也用于上下文的自动剪裁(offload)大文件输出。
注意:必须提供具体的Checkpointer。部署到LangSmith时可省略,平台会自动提供。
在没有Checkpointer的情况下,是看不到刚刚创建的文件的。 子Agent与主Agent共享此状态后端,子Agent创建的文件对主Agent可见。
import uuid
from deepagents import create_deep_agent
from deepagents.backends import StateBackend
from langgraph.checkpoint.memory import InMemorySaver
from agent.my_llm import zhipuai_client, llm
from langchain_core.tools import tool
@tool
def search(query):
"""网络搜索工具"""
try:
response = zhipuai_client.web_search.web_search(search_engine="search_pro", search_query=query)
if response.search_result:
return "\n\n".join([result.content for result in response.search_result])
return "没有搜素到任何内容"
except Exception as e:
print(e)
return "搜索出现错了"
checkpointer = InMemorySaver()
agent = create_deep_agent(
model=llm,
tools=[search],
checkpointer=checkpointer,
system_prompt="你是一个智能助手,请根据用户输入的指令,进行相应的操作",
#backend=StateBackend() #默认是StateBackend, 不用配置
)
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
resp = agent.invoke(input={"messages":[{"role": "user", "content": "请创建一个文件/plan.txt,内容是项目启动计划"}]}, config=config)
print(resp["messages"][-1].content)
resp = agent.invoke(input={"messages":[{"role": "user", "content": "读取/plan.txt内容"}]}, config=config)
print(resp["messages"][-1].content)2、FilesystemBackend (本地磁盘后端)
-
工作原理 :允许Agent读写本地机器上指定根目录(
root_dir)下的真实文件。 -
⚠️ 重要安全警告 :此后端赋予Agent直接的文件系统访问权限。切勿在Web服务器、API等多租户生产环境使用。仅在可信的本地开发中使用。
安全建议:
-
始终设置
virtual_mode=True以启用路径沙盒,阻止Agent使用..或~访问根目录之外的路径。 -
从可访问路径中排除包含密钥、密码的敏感文件(如
.env)。 -
对于需要高安全的生产环境,考虑使用沙盒后端。
temp_worksapace = "./agent_workspace"
os.makedirs(temp_worksapace, exist_ok=True)
agent = create_deep_agent(
model=llm,
tools=[search],
checkpointer=checkpointer,
system_prompt="你是一个智能助手,请根据用户输入的指令,进行相应的操作",
backend=FilesystemBackend(
root_dir = temp_worksapace,
virtual_mode=True
)
)
3、LocalShellBackend (本地Shell后端)
-
工作原理 :在
FilesystemBackend的基础上,额外提供了一个execute工具,允许Agent在主机上执行任意的 Shell 命令。 -
⚠️ 极度危险警告 :此后端赋予Agent在您的主机上执行任意命令的最高权限。仅限 在您完全信任Agent代码的本地开发环境中使用。禁止用于生产环境或处理不可信输入。
import os
import sys
import uuidfrom deepagents import create_deep_agent
from deepagents.backends import StateBackend, FilesystemBackend, LocalShellBackend
from langgraph.checkpoint.memory import InMemorySaverfrom agent.my_llm import zhipuai_client, llm
from langchain_core.tools import tool@tool
def search(query):
"""网络搜索工具"""
try:
response = zhipuai_client.web_search.web_search(search_engine="search_pro", search_query=query)
if response.search_result:
return "\n\n".join([result.content for result in response.search_result])
return "没有搜素到任何内容"
except Exception as e:
print(e)
return "搜索出现错了"checkpointer = InMemorySaver()
创建一个临时目录作为Agent的"沙盒"
temp_workspace = "./agent_workspace"
os.makedirs(temp_workspace, exist_ok=True)backend = LocalShellBackend(
root_dir=temp_workspace,
virtual_mode=True,
timeout=30,
max_output_bytes=50000,
env={
"PATH": f"{os.path.dirname(sys.executable)};{os.environ.get('PATH', '')}",
}
)
agent = create_deep_agent(
model=llm,
tools=[search],
checkpointer=checkpointer,
system_prompt="你是一个智能助手,请根据用户输入的指令,进行相应的操作",
backend=backend
)config = {"configurable": {"thread_id": str(uuid.uuid4())}}
resp = agent.invoke(input={"messages":[{"role": "user", "content": "请创建一个文件/plan.py,内容是用python打印hello world!的脚本"}]}, config=config)
print(resp["messages"][-1].content)
resp = agent.invoke(input={"messages":[{"role": "user", "content": "执行/plan.py"}]}, config=config)
print(resp["messages"][-1].content)
4、StoreBackend (LangGraph 存储后端)
-
工作原理 :使用 LangGraph 的
BaseStore抽象(支持 Redis、Postgres、内存等实现)来存储文件,从而实现跨不同执行线程的持久化存储。 -
最佳用途:存储需要长期记忆的数据,例如用户偏好、跨对话知识库。
注意:必须提供具体的存储实现。部署到LangSmith时可省略,平台会自动提供。
import uuid
from deepagents import create_deep_agent
from deepagents.backends import StateBackend, StoreBackend
from langgraph.checkpoint.memory import InMemorySaver
from langgraph.store.memory import InMemoryStore
from agent.my_llm import zhipuai_client, llm
from langchain_core.tools import tool
@tool
def search(query):
"""网络搜索工具"""
try:
response = zhipuai_client.web_search.web_search(search_engine="search_pro", search_query=query)
if response.search_result:
return "\n\n".join([result.content for result in response.search_result])
return "没有搜素到任何内容"
except Exception as e:
print(e)
return "搜索出现错了"
checkpointer = InMemorySaver()
store = InMemoryStore()
agent = create_deep_agent(
model=llm,
tools=[search],
checkpointer=checkpointer,
system_prompt="你是一个智能助手,请根据用户输入的指令,进行相应的操作",
backend=lambda rt: StoreBackend(rt),
store=store
)
config = {"configurable": {"thread_id": str(uuid.uuid4())}}
resp = agent.invoke(input={"messages":[{"role": "user", "content": "请创建一个文件/plan.txt,内容是项目启动计划"}]}, config=config)
print(resp["messages"][-1].content)
resp = agent.invoke(input={"messages":[{"role": "user", "content": "读取/plan.txt内容"}]}, config=config)
print(resp["messages"][-1].content)5、CompositeBackend (复合/路由后端)
-
工作原理:作为后端路由器,根据文件路径的前缀,将操作定向到不同的底层后端。
-
最佳用途 :实现混合存储策略。例如,临时工作文件用
StateBackend,长期记忆用StoreBackend,特定目录映射到本地磁盘。import os
import uuidfrom deepagents import create_deep_agent
from deepagents.backends import StateBackend, FilesystemBackend, CompositeBackend, StoreBackend
from langgraph.checkpoint.memory import InMemorySaverfrom agent.my_llm import zhipuai_client, llm
from langchain_core.tools import tool@tool
def search(query):
"""网络搜索工具"""
try:
response = zhipuai_client.web_search.web_search(search_engine="search_pro", search_query=query)
if response.search_result:
return "\n\n".join([result.content for result in response.search_result])
return "没有搜素到任何内容"
except Exception as e:
print(e)
return "搜索出现错了"checkpointer = InMemorySaver()
composite_backend = lambda rt: CompositeBackend(
default = StateBackend(rt),
routes = {
"/memories/": StoreBackend(rt)
}
)agent = create_deep_agent(
model=llm,
tools=[search],
checkpointer=checkpointer,
system_prompt="你是一个智能助手,请根据用户输入的指令,进行相应的操作",
backend=composite_backend
)config = {"configurable": {"thread_id": str(uuid.uuid4())}}
resp = agent.invoke(input={"messages":[{"role": "user", "content": "请创建一个文件/plan.txt,内容是项目启动计划"}]}, config=config)
print(resp["messages"][-1].content)
resp = agent.invoke(input={"messages":[{"role": "user", "content": "读取/plan.txt内容"}]}, config=config)
print(resp["messages"][-1].content)
文件后端和checkpointer、store的关系
-
DeepAgents 的 Backend
-
设计目标 :为 Agent 提供文件系统语义 的抽象。它的核心接口是
ls_info,read,write,edit等,让Agent感觉自己在一个真实的目录树下操作文件。 -
数据模型 :文件/目录树。操作对象是文件路径和文件内容。
-
持久化范围 :由具体实现决定。
StateBackend是线程内,FilesystemBackend是进程/机器内,StoreBackend可以跨进程/会话。 -
典型用例 :Agent的工作空间、长期记忆存储 (
/memories/)、技能和文档的加载来源。
-
-
LangGraph 的 Checkpointer
-
设计目标 :为 Agent 或者 StateGraph 提供状态快照与恢复机制。用于实现对话的持久化、暂停/继续、回溯以及人类介入审核(Human-in-the-loop)。
-
数据模型 :序列化的工作流状态 。它保存的是整个
State对象的检查点(checkpoint),包括所有通道的消息、变量值等。 -
持久化范围 :跨会话持久化工作流状态。允许用户离开后,稍后从完全相同的地方继续对话。
-
典型用例:聊天机器人记住之前的对话上下文;一个长时间运行的任务支持暂停和继续;需要人工审批节点的多步骤工作流。
-
-
LangChain 的 Store (BaseStore)
-
设计目标 :一个通用的、需要自定义操作的 长期存储。它是 LangGraph 存储层的底层抽象,非常简单。
-
数据模型 :命名空间下的键值对 。基本操作是
get,set,delete,list。 -
持久化范围 :由具体实现决定(如
InMemoryStore,RedisStore,PostgresStore)。 -
典型用例 :为
Checkpointer或StoreBackend提供底层存储驱动。也可直接用于缓存、会话存储等任何需要简单KV存储的场景。
-