一、Map是个什么东西
Map 是一种存储Key-Value的数据结构。底层依托数组 实现,通过哈希函数将 Key 转换为数组下标,从而将搜索复杂度降至 O(1)。
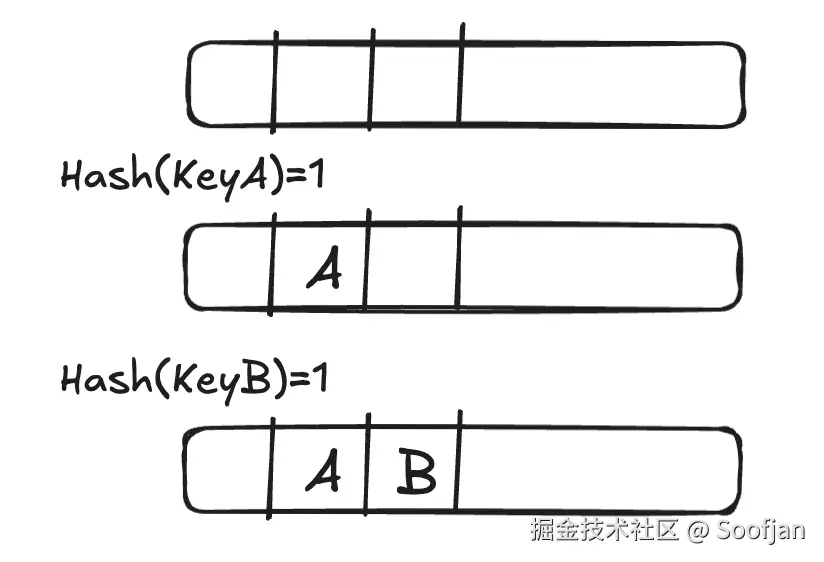
但是数组大小是有限的,数据是无限的,不同的 Key 难免会计算出相同的哈希值,产生哈希冲突。目前主流有两种解决方法
有两种解决方法:
- 链表法。存值的时候插入链表节点。这样插入,删除都很快。但是因为是链表,在内存离散分布,内存局部性利用率低。
- 开放寻址法。遇到冲突往n+1找。这样大多数据都在连续的数组空间内,内存局部利用率就高,但是也比链表扩容次数多。
现在的Go Map 1.24之后的实现已经转为了SwissTable。但是我认为去了解一下之前的实现,对于我们现在的新结构的理解是有帮助的。
二、Go Map 1.24之前的实现
Go 的 Map 底层由 2^n 个桶(Bucket)组成。每个桶内固定有 8 个槽位。
为了追求极致的性能,桶内的布局并不是简单的 K-V, K-V... 循环,而是采取了分块存储:先排 8 个 tophash(哈希高位),再排 8 个 Key,最后排 8 个 Value。
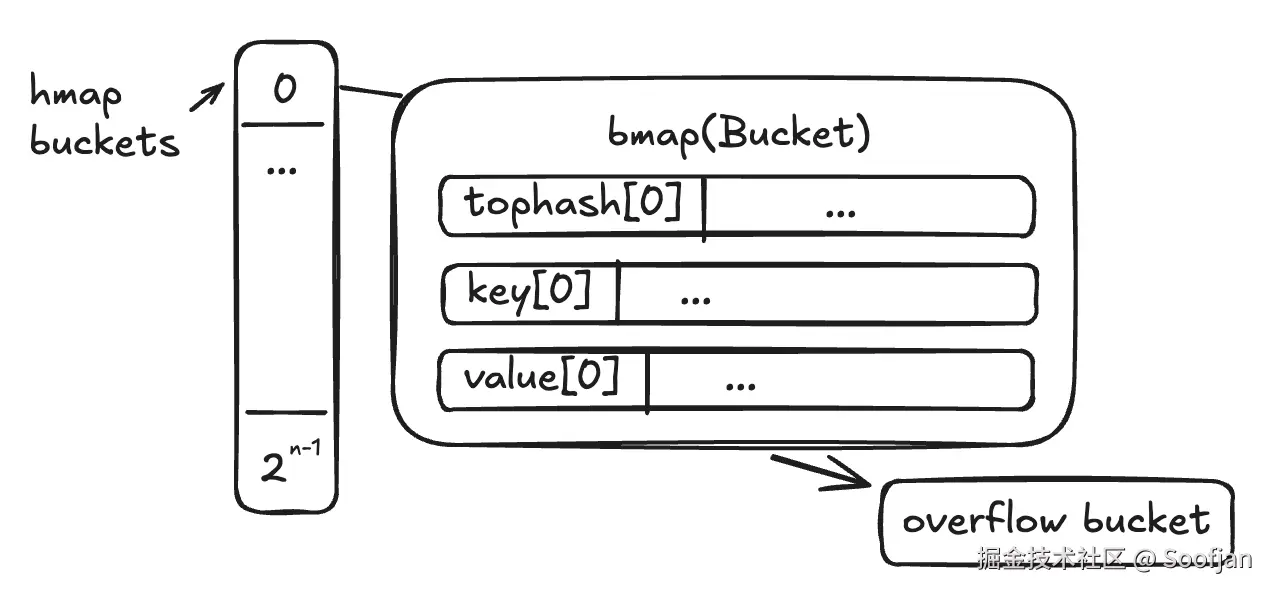
- 这种设计核心目的有两个
一是利用 tophash 快速过滤无效匹配;二是利用 K/V 分离存储 来优化内存对齐,减少因类型对齐而产生的额外内存填充(Padding)。
- 讲讲为什么这里能够就是优化内存对齐。
首先如果是交替存储 Key1Value1Key2Value2...
假设Key 是 int64(8字节),Value 是 bool(1字节)
由于int64要求必须从 8 的倍数地址开始存(对齐限制),为了保证下一个key2也能对齐,编译器会在value1(1字节)后面偷偷补上7 个字节的padding
三、Go Map 1.24之前的增删改查以及扩容
- 查找
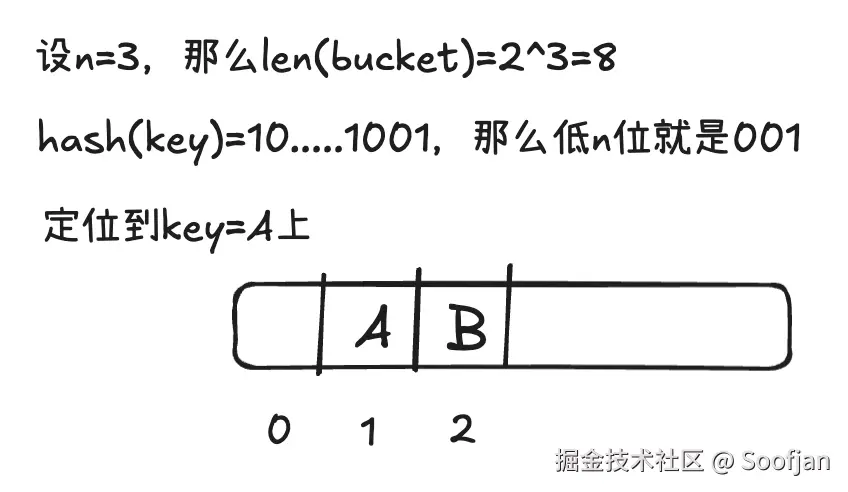
首先利用哈希值的低 N 位确定桶(Bucket)的位置
进入桶后,利用哈希值的高 8 位(TopHash)与桶内的 8 个槽位进行快速比对。
如果 TopHash 匹配,再对比具体的 Key,从而精确定位 Value。
- 增加,修改,删除
首先按查找流程定位元素:
- 若存在: 执行更新(修改)或删除操作。
- 若不存在: 寻找空闲槽位进行插入。如果当前桶的 8 个槽位已满,则挂载并进入溢出桶(Overflow Bucket)继续寻找空位。
- 扩容
Go Map 的扩容分为两种触发条件:
- 双倍扩容: 当负载因子超过 6.5 时,说明数据太多,需翻倍扩容。
- 等量扩容: 当溢出桶过多(通常是由于频繁增删导致碎片化)时,为了整理内存进行等量扩容。
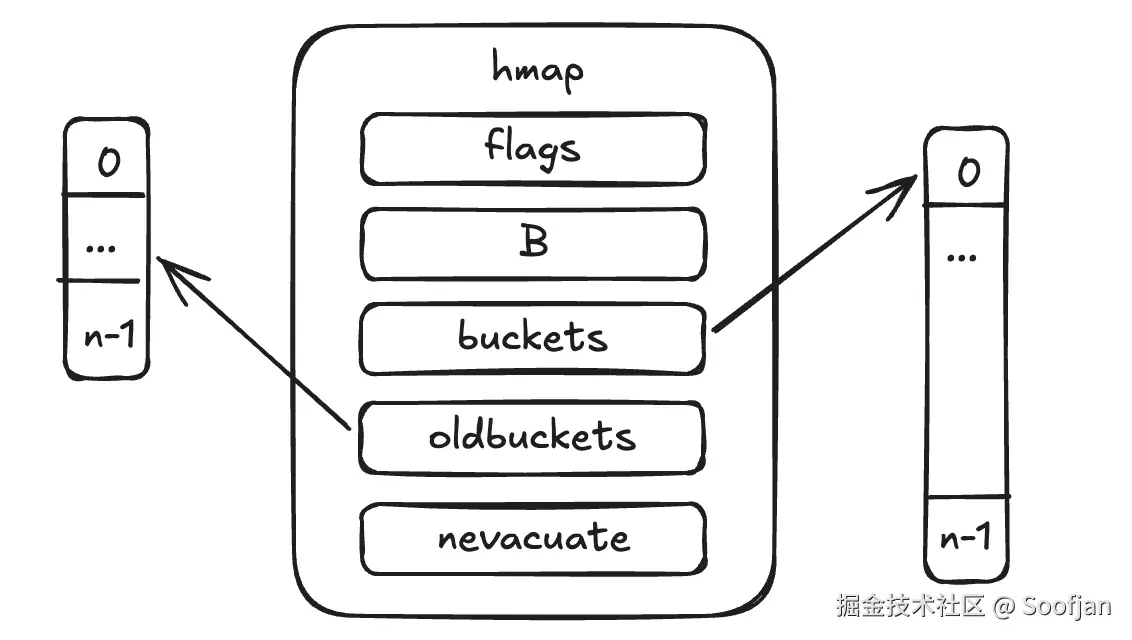
渐进式搬迁逻辑: 扩容并非一次性完成,而是通过 nevacuate 标志位记录搬迁进度。
写入: 直接操作新桶,并触发 1-2 个旧桶的搬迁。
查找/修改: 需对比 nevacuate。如果目标桶索引小于 nevacuate,说明已搬迁完成,去新桶 找;反之,则去旧桶找。"