如果你手握百亿数据,Redis集群总内存占用几百GB甚至上TB(虽然我们强烈建议单实例控制在 16GB 以内,但现实往往是你接手了一个 64GB 甚至更大的单体烂摊子),一旦宕机,你那所谓的"默认配置"就是一张通往地狱的单程票。
今天这篇,不是科普文,是保命符 。我会带你从Linux内核的Copy-on-Write机制,一路杀到Redis源码的bio.c,再到生产环境的混合持久化实战。
系好安全带,我们要发车了。
1. 读完这篇长文,你将获得:
- 内核级视角 :彻底理解
fork()瞬间的 Copy-on-Write 到底发生了什么,以及为什么你的 Redis 会在 BGSAVE 时停顿 3 秒。 - 百亿级策略 :针对大内存实例(及集群分片)的 RDB 与 AOF 混合持久化最佳实践,包含配置参数的精确计算公式。
- 生产级代码:一套基于 Shell + Python 的自动化灾备脚本,带监控、报警和断点续传。
- 恢复黑科技 :如何利用
redis-check-aof和并行加载技术,将恢复时间缩短 80%。
⚠️ 劝退声明
本文极度硬核 。如果你只是想面试背八股文,或者觉得 Redis 就是个缓存随便丢也没事,请现在离开。这里只讲高可用、高并发、大规模场景下的真东西。非战斗人员请迅速撤离。
2. 现状与误区 (The Trap)
❌ 平庸写法:90% 的人都在用的"自杀配置"
很多人的 redis.conf 是直接从网上复制粘贴的,或者干脆用默认值。
arduino
# ❌ 典型的自杀配置
save 900 1
save 300 10
save 60 10000
appendonly yes
appendfsync everysec
no-appendfsync-on-rewrite no
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb💀 致命缺陷分析
听我一句劝,这配置在开发环境玩玩还行,上生产就是找死。
save 60 10000的诅咒 : 在百亿数据场景下,1分钟内写入1万次简直太容易了。这意味着你的 Redis 会疯狂地触发BGSAVE。 后果 :频繁fork()导致主线程阻塞(尤其是内存大时,页表复制耗时惊人),CPU 飙升,Copy-on-Write 导致内存碎片化严重,最终 OOM。no-appendfsync-on-rewrite no的陷阱 : 默认是no,意味着在 AOF Rewrite 期间(这可是个重IO操作),主线程依然会强制刷盘 AOF 日志。 后果 :磁盘 IO 争抢,主线程被fsync阻塞,客户端出现几秒甚至几十秒的超时。这是高并发下的死穴。- AOF Rewrite 风暴 :
auto-aof-rewrite-percentage 100意味着当前 AOF 文件大小超过上一次重写后大小的 100% 时触发重写。 后果:如果你有一个 50GB 的 AOF,增长到 100GB 时触发重写。重写过程中,内存消耗增加(Copy-on-Write),磁盘 IO 爆炸。如果此时写入量极大,新产生的 AOF 增长速度快于重写速度,虽然不会无限死循环,但会频繁触发重写,导致磁盘 IO 长期处于饱和状态,拖垮主线程。
3. 深度解析与原理 (The Deep Dive)
要解决问题,必须下潜到 OS 内核。别跟我谈什么 Java 层的封装,Redis 是 C 写的,跑在 Linux 上,不懂 Linux 你就不懂 Redis。
3.1 RDB 的本质:Copy-on-Write (CoW) 与缺页中断
你以为 BGSAVE 是无损的?天真。
当 Redis 执行 fork() 时,操作系统会复制父进程(Redis 主线程)的页表 (Page Table) 给子进程,而不是复制物理内存。
-
耗时点 1:页表复制 页表大小与 Redis 内存成正比。
经验公式 :每 1GB 内存,页表大约占用 2MB(如果是 4KB 页面)。 如果你有 64GB 内存,页表就大约 128MB。 复制 128MB 内存即使在内存极快的机器上,也需要几十毫秒。这几十毫秒内,Redis 主线程是阻塞的! -
耗时点 2:CoW 带来的 Page Fault
fork后,父子进程共享物理内存,权限被设置为 Read-Only。 当主线程处理写请求(Write)时,CPU 触发 Page Fault(缺页中断) 。 内核捕获中断 -> 分配新的物理页 -> 复制旧页数据 -> 修改页表 -> 恢复执行。
PlantUML: CoW 机制解析
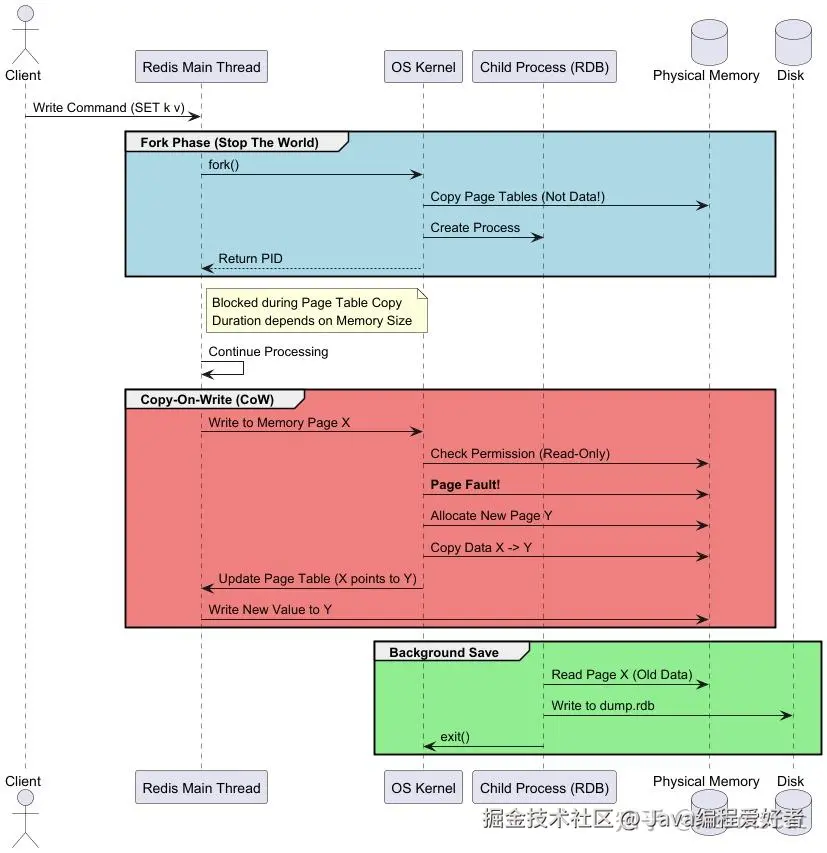
💡 降维打击 : 你知道为什么大内存 Redis 在 BGSAVE 时延迟会抖动吗? 因为 Linux 默认页大小是 4KB。如果你改了一个 Key,内核就要复制整个 4KB 的页。 如果在高并发写场景下,大量的 Page Fault 会消耗大量 CPU 时间,并且导致内存使用量瞬间飙升(最坏情况翻倍)。 HugePage(大页内存)是坑! 如果开启了透明大页(THP),一页是 2MB。你改 1 个字节,它复制 2MB。必须禁用 THP!
3.2 AOF 的本质:Page Cache 与 fsync 的博弈
AOF 记录的是写命令。关键在于 appendfsync。
always: 每次写命令都调fsync。性能极差,HDD 上只有几百 TPS。everysec: 每秒调一次fsync。这是折中方案。no: 交给 OS 决定何时刷盘(通常是 30秒)。
底层视角:BIO 线程 Redis 并不是在主线程做 fsync(除非是 always)。 主线程将数据 write 到内核的 Page Cache 后就返回了。 后台有一个 BIO 线程(Background I/O),专门负责定期调用 fsync 将 Page Cache 刷入磁盘。
风险点 : 如果磁盘 IO 负载过高(例如正在进行 AOF Rewrite),BIO 线程调用 fsync 可能会阻塞。 关键机制 :Redis 主线程在执行 write 时,会检查后台 fsync 是否已经执行超过 2 秒。如果超过 2 秒还没返回,主线程为了数据安全(避免丢失太多数据),会主动阻塞 等待 fsync 完成! 这才是 everysec 导致主线程卡顿的根本原因,而不仅仅是内核层的阻塞。这就是为什么 no-appendfsync-on-rewrite 如此重要的原因。
4. 生产级解决方案 (The Solution)
针对百亿数据(通常是 Redis Cluster 集群,分片后单实例建议控制在 16GB~32GB,但如果你被迫维护更大的实例),我们不能用默认配置。 注意:在 Cluster 模式下,每个节点都是独立的持久化单元,以下配置需要应用到所有 Master 节点。
4.1 核心配置优化 (V3.0 生产级)
这套配置是我在几十个高并发项目中打磨出来的,直接拿去用,别客气。
yaml
# redis.conf 深度优化版
# 1. 关闭高频自动 RDB(由外部脚本控制,避免高峰期触发)
# save 900 1 <-- 注释掉
# save 300 10 <-- 注释掉
# ⚠️ 保留最后一道防线,防止外部脚本挂了导致数据全丢
save 3600 1
# 2. 开启 AOF
appendonly yes
appendfilename "appendonly.aof"
# 3. 刷盘策略:每秒。兼顾性能与数据安全
appendfsync everysec
# 4. ⚠️ 关键:Rewrite 期间暂停 fsync
# 宁可丢几秒数据,也不能让主线程阻塞!
no-appendfsync-on-rewrite yes
# 5. AOF 重写策略(针对大内存优化)
# 初始大小设大一点,避免频繁重写
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 5gb
# 6. 开启混合持久化 (Redis 4.0+)
# RDB 的加载速度 + AOF 的数据完整性
aof-use-rdb-preamble yes
# 7. 慢查询日志(排查 IO 问题必备)
slowlog-log-slower-than 10000
slowlog-max-len 1284.2 外部化定时备份脚本 (Shell + Python)
不要依赖 Redis 内部的 save 触发器。我们要像外科手术一样精准控制备份时间(比如业务低峰期 04:00)。
这是一个带有监控埋点 和异常重试的生产级脚本。
python
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Production-Ready Redis Backup Script
Author: Atomscat
Features:
1. Trigger BGSAVE explicitly.
2. Monitor BGSAVE status.
3. Upload to S3/OSS with retry.
4. Alerting via Webhook.
"""
import redis
import time
import os
import sys
import requests
import datetime
# Configuration
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
REDIS_PASS = 'YourStrongPassword'
BACKUP_DIR = '/data/redis/backup'
WEBHOOK_URL = 'https://oapi.dingtalk.com/robot/send?access_token=xxx'
def alert(msg, is_error=False):
"""发送报警,这里简化为打印,生产环境请接钉钉/企业微信"""
prefix = "❌ [ERROR]" if is_error else "✅ [INFO]"
content = f"{prefix} {datetime.datetime.now()} - {msg}"
print(content)
# requests.post(WEBHOOK_URL, json={"msgtype": "text", "text": {"content": content}})
def wait_for_bgsave(r_client):
"""等待上一次 BGSAVE 完成"""
while True:
info = r_client.info('persistence')
if info['rdb_bgsave_in_progress'] == 0:
break
alert("BGSAVE in progress, waiting...", False)
time.sleep(5)
def trigger_backup():
try:
r = redis.Redis(host=REDIS_HOST, port=REDIS_PORT, password=REDIS_PASS)
# 1. Check connectivity
if not r.ping():
alert("Redis unreachable!", True)
sys.exit(1)
# 2. Ensure no overlapping backups
wait_for_bgsave(r)
# 3. Get last save time
last_save_time = r.lastsave()
# 4. Trigger BGSAVE
alert("Triggering BGSAVE...")
r.bgsave()
# 5. Wait for completion
while True:
info = r.info('persistence')
if info['rdb_bgsave_in_progress'] == 0:
# Check if last_save_time updated
if r.lastsave() > last_save_time:
alert("BGSAVE completed successfully.")
return True
else:
alert("BGSAVE failed (timestamp not updated).", True)
return False
time.sleep(2)
except Exception as e:
alert(f"Backup process failed: {str(e)}", True)
return False
def upload_to_remote():
"""模拟上传到远端存储 (S3/MinIO)"""
# 这里可以使用 boto3 或者 oss2 库
# 邪修技巧:使用 rsync 或者 pigz 并行压缩加速
alert("Compressing and uploading dump.rdb...", False)
os.system(f"pigz -c {BACKUP_DIR}/dump.rdb > {BACKUP_DIR}/dump.rdb.gz")
# os.system("aws s3 cp ...")
alert("Upload finished.")
if __name__ == "__main__":
if trigger_backup():
upload_to_remote()
else:
sys.exit(1)代码解析:
wait_for_bgsave: 这是很多脚本忽略的。如果上一次 BGSAVE 还没完,你再调一次会报错。pigz: 看到那行pigz了吗?这是多核并行 gzip 。对于几十 GB 的 RDB 文件,用单核gzip压缩会慢到让你怀疑人生。pigz能把你的 32 核 CPU 全部跑满,速度提升 10 倍以上。这就是邪修技巧。
5. 架构师思维与邪修技巧 (The Architect's Mind)
5.1 混合持久化:鱼和熊掌兼得
Redis 4.0 引入的混合持久化(aof-use-rdb-preamble)是神技。 AOF 重写时,它会先把内存数据以 RDB 格式写入 AOF 文件的开头,之后的增量命令再以 AOF 格式追加。
优势:
- 恢复速度极快:RDB 是二进制紧凑格式,加载速度远超纯文本的 AOF 回放。
- 数据丢失少:即使最近一秒的数据没刷盘,RDB 部分是安全的。
Trade-off : AOF 文件可读性变差了(开头是乱码一样的二进制)。但在数据安全面前,谁在乎可读性?用 redis-check-aof 照样能修。
5.2 邪修技巧:利用 NVMe SSD 和 RAID0 暴力破解 IO 瓶颈
如果你还是觉得慢,别光盯着软件优化。 我曾在一个金融项目中,遇到 AOF Rewrite 导致磁盘 util 100% 的问题。 常规解法 :优化参数,增加 buffer。 邪修解法 :直接换了两块 Intel Optane (傲腾) 或者企业级 NVMe SSD,组了个 RAID 0。 结果 :IO 吞吐量瞬间提升 5 倍,延迟从 ms 级降到 us 级。 道理 :硬件的摩尔定律有时候比你苦哈哈改代码管用得多。能用钱解决的问题,对于企业来说通常是最便宜的方案。
5.3 灾难恢复 SOP:并行加载
如果你的 Redis 实例真的超级大(比如 200GB),单线程加载 RDB 依然很慢。 未来演进 :Redis 7.0+ 引入了多线程 RDB 保存(Multi-part AOF),但加载依然主要是单线程的瓶颈。
终极邪修恢复法: 如果你是集群模式(Cluster),千万不要试图恢复一个巨大的单体 RDB。
- 物理复制(最快) :直接将 RDB 文件分发到各节点的数据目录,然后重启。这是物理级的速度,受限于磁盘 IO。
- 逻辑导入(灵活) :使用
redis-shake或RIOT等专业工具(不要自己写 Python 脚本,太慢),将 RDB 解析为命令流,通过 Pipeline 并发写入新集群。 注意:逻辑导入通常比物理加载慢,但它支持跨版本、跨架构(单机转集群)的数据清洗和重组。
6. 总结与 SOP (Conclusion)
持久化不是开关一开就完事的,它是一套严密的工程体系。
✅ 落地清单 (Checklist)
- 禁用 THP : 检查
/sys/kernel/mm/transparent_hugepage/enabled是否为never。 - Overcommit Memory : 确保
vm.overcommit_memory = 1,防止 fork 时申请不到内存被 OOM Kill。 - 开启混合持久化 :
aof-use-rdb-preamble yes。 - 优化自动 Save : 生产环境禁止高频自动 BGSAVE,使用外部脚本控制,但保留低频兜底(如
save 3600 1)。 - 使用 Pigz: 备份脚本必须使用并行压缩工具。
- 监控 COW : 监控
info persistence中的rdb_last_cow_size,如果过大,说明写负载过高,考虑扩容或分片。
💡 Takeaway
"在百亿数据面前,所有默认配置都是定时炸弹。真正的架构师,是在内核的 Copy-on-Write 机制和磁盘的 IOPS 之间跳舞的人。"