检索方式
我们在接触AI大模型之前,也会涉及到检索技术。像很多App的搜索、本地PC的文件检索等等。信息检索领域中常用的三种检索技术有:
-
关键字检索(简单的关键字匹配,如部分数据库的关键词搜索,检索速度快)
- 通过在文本中查找特定的关键字来进行检索。它事先会对文本数据建立关键字索引,检索时,根据用户输入的关键字,直接在索引中查找匹配的记录,从而快速定位到包含该关键字的文本内容。
-
全文检索(搜索更全面,更准确)
- 对文本中的所有词汇进行索引,能够对文本内容进行全面的搜索。检索时,会对用户输入的查询语句进行分词等处理,然后在整个文本中查找与每个分词都匹配的文档。
-
基于向量相似度的检索 (RAG技术中常用的)
- 基于语义级理解,能捕捉文本的深层语义关联(如同义词、上下文歧义、逻辑推理)。例如,查询 "如何修复笔记本故障" 和文档 "电脑主板维修指南" 会因语义相似被判定为高相关,无需显式配置规则。向量是语义的黑盒表征,相似度计算结果难以直观解释.
怎么选?
那么在实际的检索场景中该怎么选择对应的技术呢?
| 检索技术 | 关键词 | 全文 | 向量相似度 |
|---|---|---|---|
| 原理 | 字符串精确匹配 | 基于倒排索引 的关键词匹配+权重排序 | 基于向量嵌入 的语义相似度计算 |
| 优势 | 速度极快、实现简单、结果绝对精确 | 在关键词基础上,引入了自然语言处理(如分词)、相关性评分(如TF-IDF、BM25),能处理更灵活的文本查询,结果可解释性强 | 能理解语义、处理同义/近义、模糊查询和复杂概念,突破词汇鸿沟 |
| 短板 | 毫无灵活性,必须完全匹配 | 严格依赖词汇重叠,无法理解语义。例如,无法理解"苹果"公司和"苹果"水果的区别 | 可能忽略关键的字面细节(如精确的日期、代码、型号);计算开销相对较大 |
| 典型场景 | 数据库主键查询、代码中的函数名搜索、严格的ID匹配 | 搜索引擎、文档系统、日志分析 | RAG中理解用户提问"我心情低落,有什么故事能带来温暖?",并从知识库中匹配情感相关的段落 |
结合各个技术的优势和短板,在现实开发中往往两者/三者常结合使用,形成 "传统检索(关键词 + 精确匹配)+ 语义检索(向量 + 模糊匹配)" 的混合架构,以兼顾效率、准确性和语义理解能力。举个简单的🌰:
- 用户需求:找一下Vivo公司2025年发布的关于手机电池续航的官方报告
- "Vivo公司"、"2025年"、"官方报告"这些硬性约束 ,最适合用全文检索来严格过滤。
- "手机电池续航"这个核心语义 ,用向量检索来理解,可以覆盖到"电池寿命"、"续航能力"、"充电效率"等不同表述的文档。
实战:医疗知识混合检索实战
现在,我们就使用"全文检索 + 向量检索"结合的混合检索方式来现一个简单的医疗知识检索系统。废话少说就是干。
工欲善其事
原始数据
知识检索就必然需要有一个检索源,需要在网上找一份数据集,作为RAG的原始数据库。那么去哪找这些数据呢?
互联网搜索
直接百度搜索,或者在对应领域的权威网站去获取资料。有些时候可能需要我们对原始材料做一些格式化处理。
HuggingFace
之前在入坑大模型微调第一个Hugging Face程序已经接触过HuggingFace,他就像AI领域的gitHub。上面不仅提供了很多主流的大模型,也提供了许多可供微调的各种领域的专业数据。这些数据本身在这里就可以作为本次RAG外挂的原始文档。
ModelScope
ModelScope是中国版的HuggingFace。在没有Magic的情况下可以使用这个平台。同时这里也可能会有更多中文数据。
本次数据
本次项目使用的是ModelScope上找的的一份医疗对话数据。首先,在ModelScope-数据集-搜索-"医疗"相关数据集:
我们选择的是中文医疗对话数据: 
下载到本地后是一个csv格式的表格: 
BM25
BM25(rank_bm25)是一个用于评估查询(query)与文档(document)相关性的经典算法和函数。其核心任务是:给定一个用户查询(比如几个关键词)和一个文档集合,为每个文档计算一个分数,分数越高代表该文档与查询越相关,从而实现对文档的排序。
BM25的核心思想基于概率检索框架。它认为,一个词在文档中出现的次数(词频TF)越多,且在整个文档集合中出现的文档越少(逆文档频率IDF),那么这个词对于区分该文档的重要性就越高。
这个项目的全文检索算法就是使用python提供的rank_bm25。
向量数据库
前面 已经详细讲过RAG里什么是向量数据库以及相关使用,这里不再做过多赘述。
Coding
整体的核心框架流程图如下: 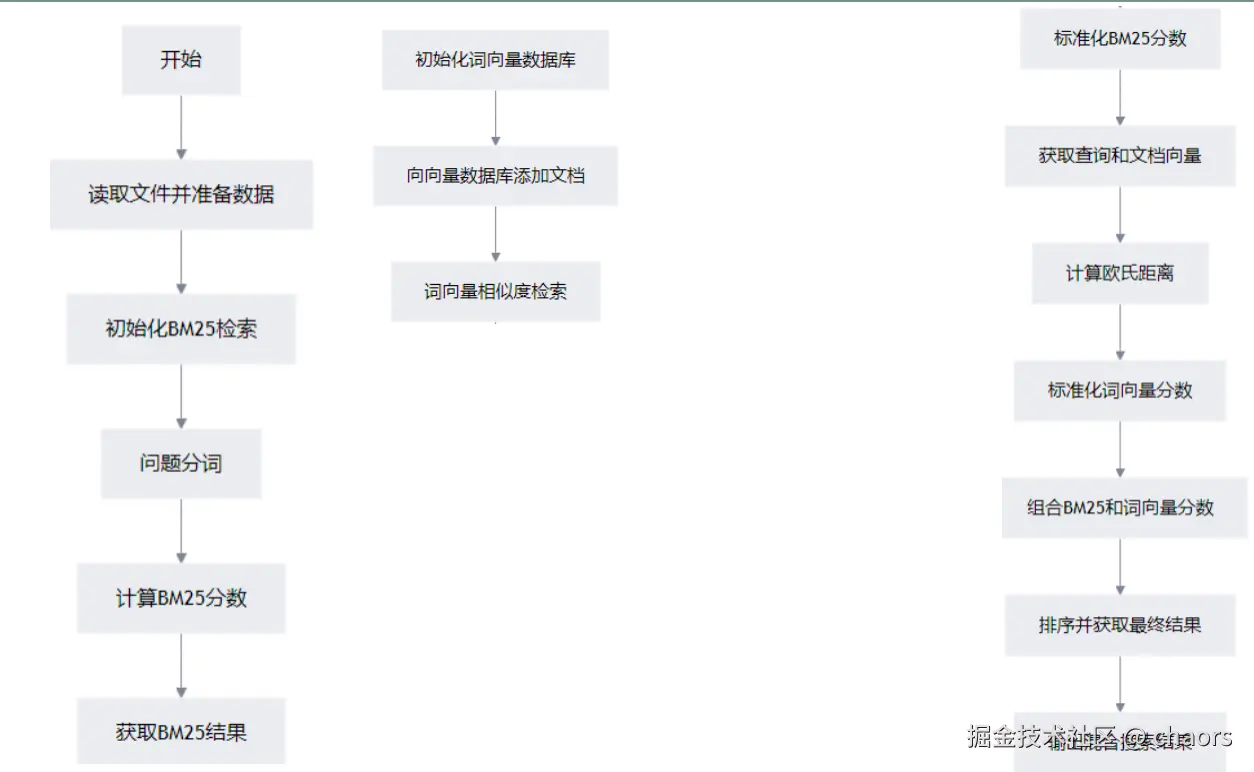
数据准备
全文检索
ini
# 2、BM25进行全文检索
def bm25_search(query):
# 在运用 BM25 算法进行全文检索时,需要对文档进行分词,以此把文本拆分成一个个独立的词语,方便后续计算词语在文档中的频率等统计信息
# 文档分词 jieba.lcut(doc) 函数会把 instructions 列表里的每个文档 doc 进行分词
tokenized_corpus = [jieba.lcut(doc) for doc in instructions]
print("tokenized_corpus:", tokenized_corpus)
# 初始化一个BM25Okapi对象,用于基于BM25算法的文本检索或相似度计算
# 对传入的文档计算必要的统计信息
bm25 = BM25Okapi(tokenized_corpus)
# 问题分词 :对查询的问题也需要进行分词处理,这样才能计算查询词和文档的相似度分数。
tokenized_query = jieba.lcut(query)
# 通过BM25算法计算查询词与文档的相似度分数
bm25_scores = bm25.get_scores(tokenized_query)
# 通过BM25算法获取与查询最相关的前3个结果
bm25_results = bm25.get_top_n(tokenized_query, outputs, n=3)
print("BM25 Score: ", bm25_scores)
print("BM25 Results: ", bm25_results)
# BM25分数归一化到[0,1]区间
# 用数组中的 (每个元素-最小值)/(最大值-最小值),实现将分数缩放到 [0, 1] 区间的目的。
# 例如:[1, 2, 3, 4, 5] 归一化后的结果是:[0, 0.25, 0.5, 0.75, 1]
#
# 使用 np.array() 函数把 bm25_scores 转换为 NumPy 数组。
# bm25_scores 原本可能是 Python 列表,转换为 NumPy 数组后,能更方便地进行数值计算,因为 NumPy 提供了很多高效的数组操作函数。
bm25_scores = np.array(bm25_scores)
max_score = bm25_scores.max() # 最高分数
min_score = bm25_scores.min() # 最低分数
bm25_scores_normalized = (bm25_scores - min_score) / (max_score - min_score)
print("bm25_scores_normalized:", bm25_scores_normalized)
print('-' * 100)
return bm25_scores_normalized向量检索
数据库构造
上一篇向量数据库讲的基本用法一致,这里不再赘述。通过封装一个MyVectorDBConnector类来包装向量检索功能。
初始化
ini
# 封装向量数据库(ChromaDB)
class MyVectorDBConnector:
# collection_name:向量数据库中集合的名称。
def __init__(self, collection_name):
# 初始化 ChromaDB 客户端 并重置数据库
chroma_client = chromadb.Client(Settings(allow_reset=True))
# 创建一个 集合 collection 在向量数据库中,集合是存储向量数据以及相关元数据的容器
#get_or_create_collection 方法用于获取或创建一个集合,如果集合不存在则创建一个新集合。
self.collection = chroma_client.get_or_create_collection(name=collection_name)
# 定义一个函数,用于将文本转换为向量表示,并返回一个包含向量表示的列表。
self.client = get_normal_client()向量获取
ini
# 封装向量模型与API的交互操作,通过自定义函数 get_embeddings 提供向量模型的调用。
def get_embeddings(self, texts, model=ALI_TONGYI_EMBEDDING_V4):
data = self.client.embeddings.create(input=texts, model=model).data
return [x.embedding for x in data]
# get_embeddings函数的变体版,因为各个模型对一次能处理的文本条数有限制且每个平台不一致,新增一个batch_size参数用以控制。
def get_embeddings_batch(self,texts, model=ALI_TONGYI_EMBEDDING_V4, batch_size=10):
all_embeddings = []
for i in range(0, len(texts), batch_size):
batch_text = texts[i:i + batch_size]
data = self.client.embeddings.create(input=batch_text, model=model).data
all_embeddings.extend([x.embedding for x in data])
return all_embeddings添加文档
python
def add_documents(self, instructions, outputs):
'''向 collection 中添加文档与向量'''
embeddings = self.get_embeddings_batch(instructions)
# 向 collection 中添加文档与向量
self.collection.add(
embeddings=embeddings, # 每个文档的向量
documents=outputs, # 文档的原文
ids=[f"id{i}" for i in range(len(instructions))] # 每个文档的 id
)检索函数
python
# 定义检索函数, 在向量数据库里进行检索操作
def search(self, query, top_n):
'''检索向量数据库'''
# self.collection.query() 这是 ChromaDB 集合对象的一个方法,用于在集合中执行查询操作。
results = self.collection.query(
# query_embeddings是查询文本的向量表示
# 调用在类初始化时传入的嵌入函数 self.embedding_fn,把查询文本 query 转换为向量。
# 要注意的是,期望接收一个字符串列表作为输入,所以这里把 query 放在列表 [query] 里。
query_embeddings=self.get_embeddings_batch([query]),
# 指定要返回的最相似文档的数量。
n_results=top_n
)
# 返回检索结果 results 是一个字典,其中包含了和查询向量最相似的 top_n 个文档的相关信息,像文档的原文、向量、ID 等。
return results相似度检索
python
# 3、向量相似度检索
def vector_search(query):
# 创建一个向量数据库对象
vector_db = MyVectorDBConnector("demo")
query_embedding = np.array(vector_db.get_embeddings_batch(query)) # 获取查询的向量表示,并把结果转换为 NumPy 数组
doc_embeddings = np.array(vector_db.get_embeddings_batch(instructions)) # 获取文档的向量表示,并把结果转换为 NumPy 数组
print("query_embedding:", query_embedding)
print("doc_embeddings:", doc_embeddings)
# 计算查询向量和文档向量之间的欧氏距离
# np.linalg.norm 函数用于计算向量的范数,这里计算的是向量差的 L2 范数,即欧氏距离。axis=1 表示按第二个维度计算。
vector_scores = np.linalg.norm(query_embedding - doc_embeddings, axis=1)
print("vector_scores:", vector_scores)
# 将距离转换为相似度分数并归一化到[0,1]区间
# 将欧氏距离转换为相似度分数,并将其归一化到 [0, 1] 区间。
max_score = np.max(vector_scores)
min_score = np.min(vector_scores)
# 因为欧氏距离越小,相似度越高。但是bm25的分数是值越大,相似度越高。
# 所以用 1 减去归一化后的距离得到相似度分数。和bm25度量方式进行统一
vector_scores_normalized = 1 - (vector_scores - min_score) / (max_score - min_score)
print("vector_scores_normalized:", vector_scores_normalized)
print('-' * 100)
return vector_scores_normalized这里要特别注意📢:
- bm25_search 数值越高,相关性越大
- vector_search 采用欧氏距离,因为数值越低,相关性越大。所以这里为了有可比性,需要用 1 减去归一化后的距离得到相似度分数 ,这样让vector_search结果和bm25_search一样,数值越高,相关性越大
混合检索
- query,查询内容
- top_k,最相关的结果个数
- bm25_weight,全文检索权重。当 bm25_weight = 0时完全为向量检索;反之亦然。权重越高对结果的贡献度将越高。
ini
# 4、混合检索:组合BM25和词向量相似度检索的结果
def hybrid_search(query, top_k=3, bm25_weight=0.5):
bm25_scores_normalized = bm25_search(query) # 得到的BM25分数的归一化结果
vector_scores_normalized = vector_search(query) # 向量相似度分数的归一化结果。
# 将两种方法的分数进行加权组合:
# 权重均为 0.5。这样可以综合考虑两种方法的优点,得到更准确的文档相关性评分。
combined_scores = bm25_weight * bm25_scores_normalized + (1-bm25_weight) * vector_scores_normalized
print('combined_scores:', combined_scores)
# 根据组合分数对结果排序并返回前3个最相关的文档
# 对 combined_scores 数组中的值进行降序排序,并返回排序后的索引值
# argsort:默认升序;[::-1]:倒序
top_index = combined_scores.argsort()[::-1]
print("top_index:", top_index)
print("top_index[:top_k]:", top_index[:top_k])
# 输出混合搜索的结果: 最相关的文档outputs
hybrid_results = [outputs[i] for i in top_index[:top_k]]
# hybrid_results = np.array(outputs)[top_index[:top_k]]
return hybrid_results调用
ini
if __name__ == '__main__':
# 查询的问题
query = "扁桃体发炎怎么办"
# 混合检索
hybrid_results = hybrid_search(query, top_k=3, bm25_weight=0.5)
print("Hybrid Search Results: ", hybrid_results)效果
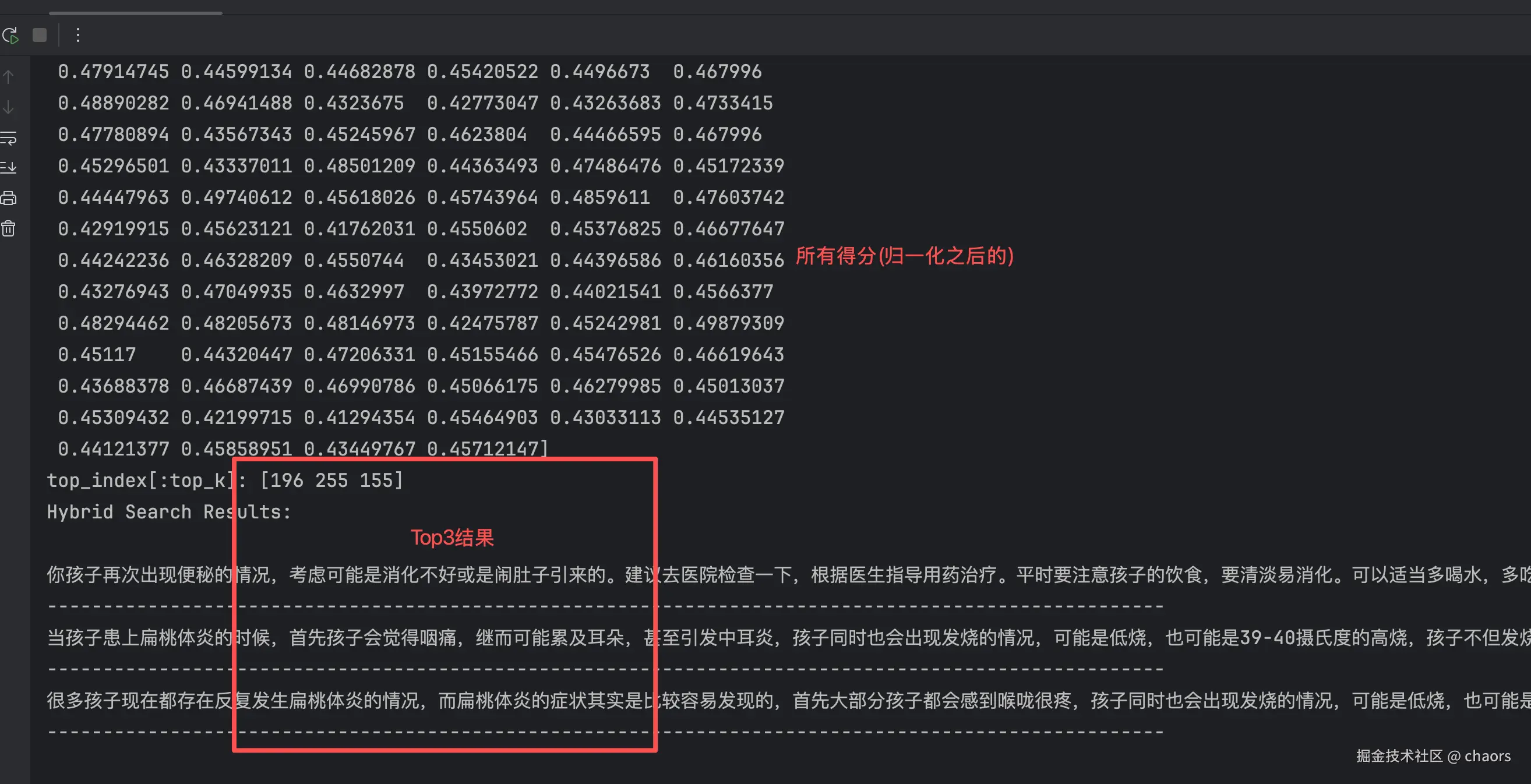
我们简单追溯一下这个结果。根据打印Top3为196,255,155。我们直接看看csv表格文件是否能对得上。
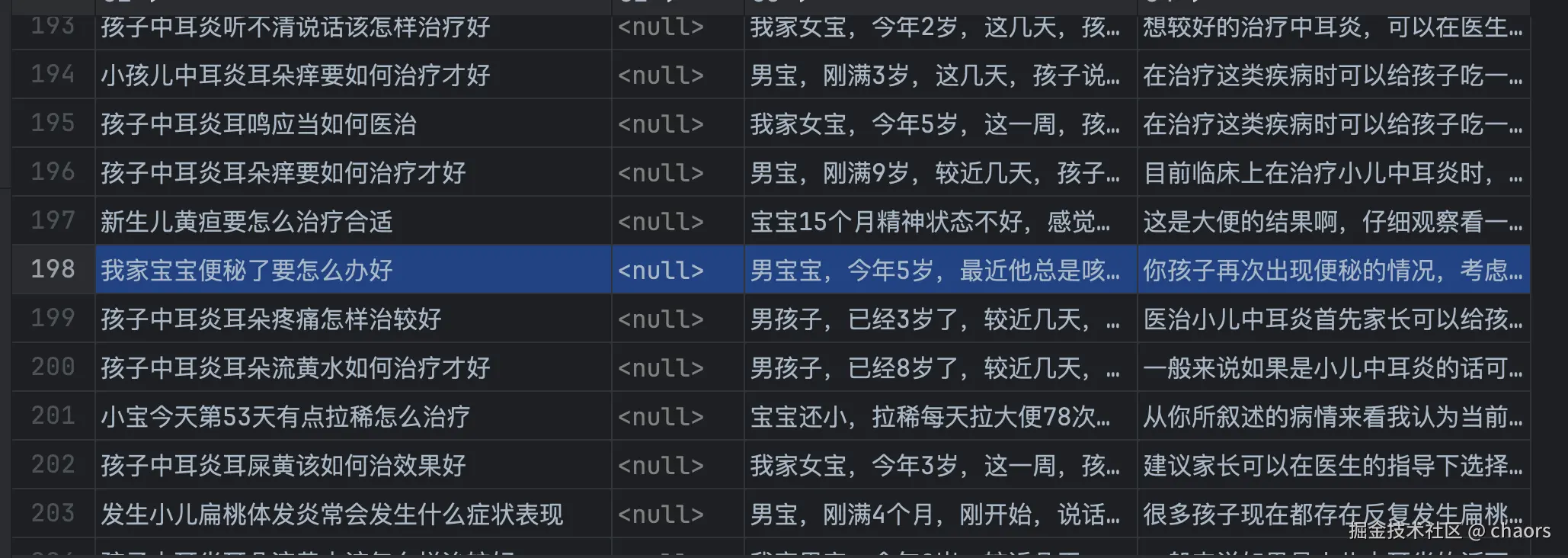

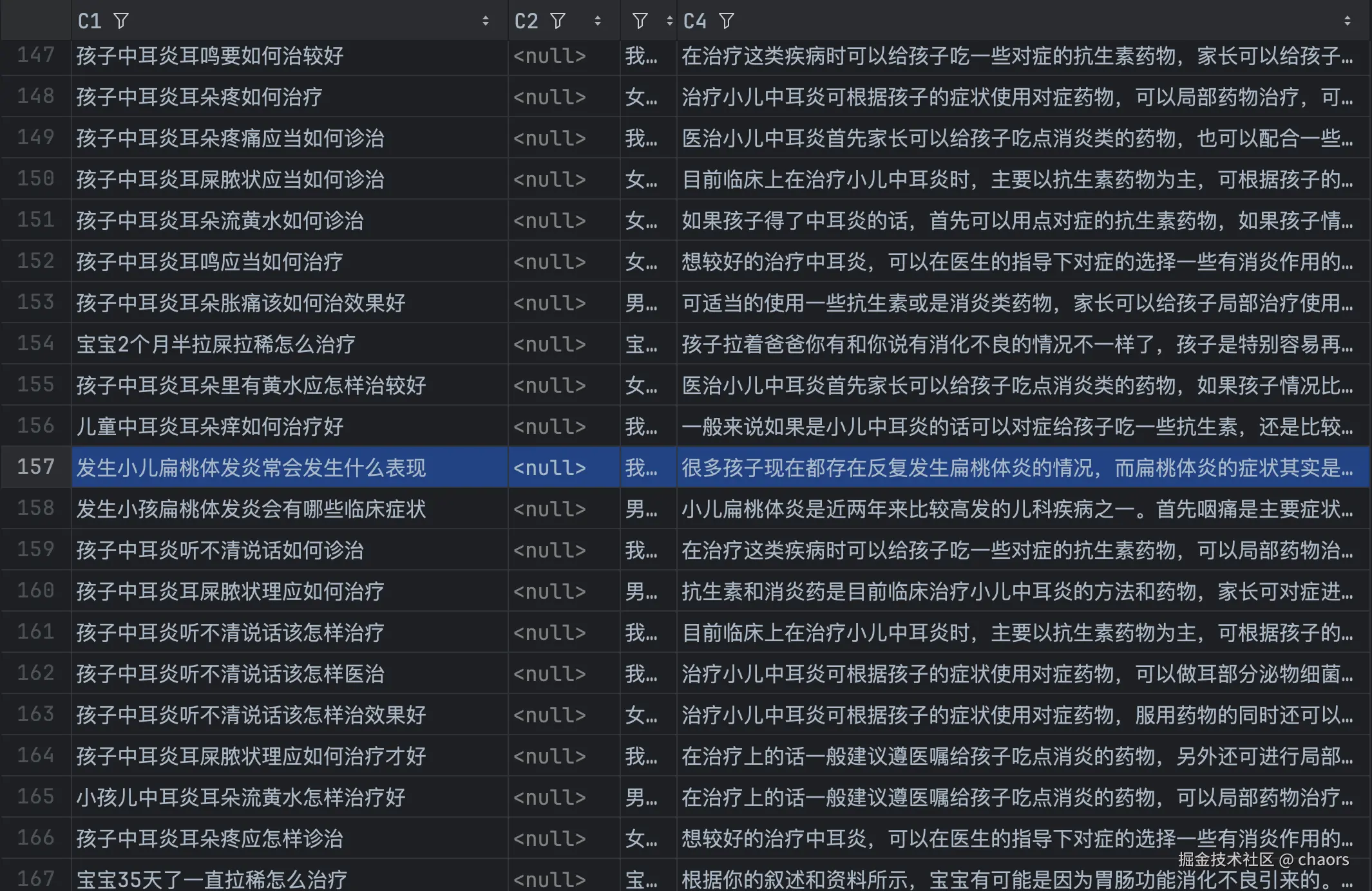
注意📢:Index_CSV = Index_result + 2, 因为:
- csv文件第一行是表头,处理时做了跳过
- 列表下标从0开始
综上图,基本没有问题。但是奇怪的是有一条(198)河query相关性不大,而且数据源中还有其他扁桃体炎相关的数据。好奇怪!??【有时间我在查查哈😄】
总体瑕不掩瑜,麻雀虽小五脏俱全,一个基于RAG向量数据库的医疗知识混合检索系统的核心就搭建完毕啦。