本章涵盖以下内容:
- 使用 Rewrite-Retrieve-Read 重写用户问题,以获得更好的 embedding 对齐效果
- 使用 step-back query 检索更高层次的上下文
- 生成假设性文档,使问题与 embedding 更好对齐
- 将复杂查询拆解为单步或多步序列
有时,你可能已经在 Retrieval-Augmented Generation(RAG) 的数据准备上投入了大量时间------收集文档、把它们切分成 chunk,并为综合生成和检索创建 embedding(这一部分我们在第 8 章已经讲过)。但即便如此,你仍然可能会发现向量存储返回的结果质量不高。问题未必出在向量存储里缺少相关内容,而可能恰恰出在用户的问题本身。例如,问题的表述可能很差、不够清晰,或者过于复杂。那些没有被清楚、简洁表达出来的问题,既会让向量存储困惑,也会让 LLM 困惑,最终导致检索结果变弱。
在本章中,我会向你展示一些技术,用来优化用户问题,让查询引擎和 LLM 更容易理解它。通过改进问题本身,你通常会看到更好的检索效果,从而为 LLM 提供更相关的上下文,并最终生成更可靠的回答。我们先从一种非常直接的方法开始:使用 LLM 来帮助改写问题。
9.1 Rewrite-Retrieve-Read
要改进一个措辞不佳的问题,一种有效的方法是让 LLM 把它改写成更清晰的形式。Xinbei Ma 等人在论文 "Query Rewriting for Retrieval-Augmented Large Language Models" 中讨论了这一做法,而图 9.1 正是受到该论文启发绘制的。在标准的 Retrieve-and-Read 工作流中,retriever 会直接处理原始问题,并把检索结果送给 LLM 进行综合生成。而如果在前面增加一个 Rewrite 步骤,由一个 rewriter(通常就是 LLM)先对问题进行改写,再交给 retriever,那么这一改进后的工作流就叫作 Rewrite-Retrieve-Read。
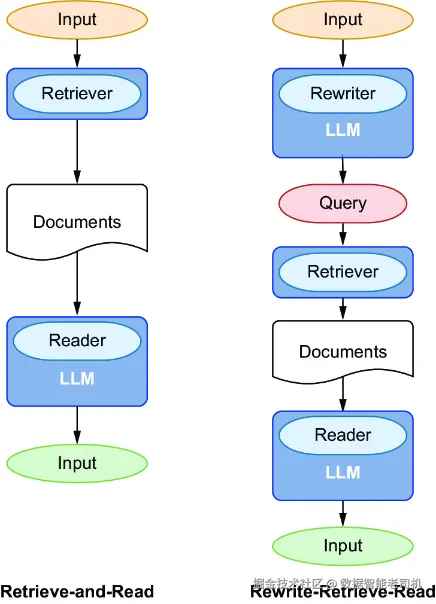
图 9.1 在标准的 Retrieve-and-Read 方案中,retriever 直接处理用户问题,并将结果交给 LLM 进行综合生成。而在 Rewrite-Retrieve-Read 方法中,会先加入一个 Rewrite 步骤,用 LLM 改写查询,再将其交给 retriever,从而提高检索过程的清晰度。(来源:https://arxiv.org/pdf/2305.14283.pdf)
我通常会把这项技术用在:为向量存储生成一个更定制化的搜索查询,但在最终的答案综合 prompt 中依然保留原始问题。这样做的好处是,改写后的查询可以专门为检索优化,特别适合向量数据库中的语义搜索;而原始问题仍然会被保留下来,供 LLM 用于最终答案综合。你可以看图 9.2 所示的工作流,它是在你之前于图 5.2(第 5 章第 5.1.1 节)看到的 RAG 图基础上修改而来的。
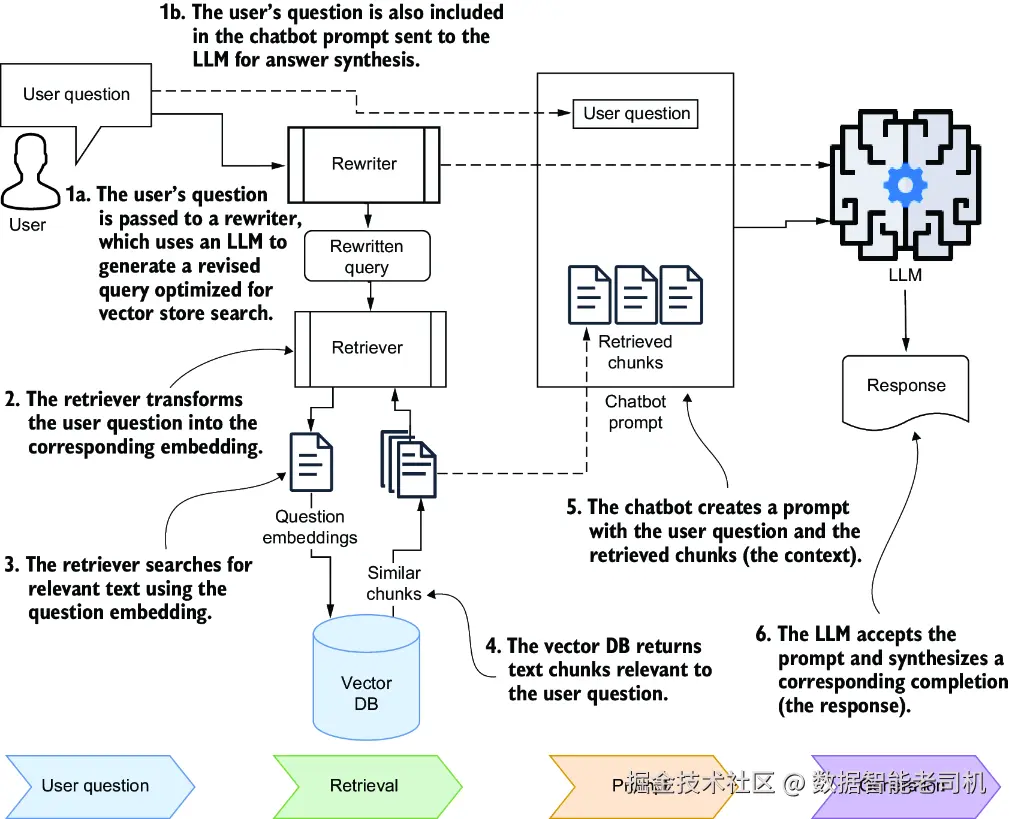
图 9.2 使用查询改写生成一个优化后的向量存储查询,同时保留原始问题,用于通过聊天机器人 prompt 进行答案综合
用于改写查询的 prompt 可以非常简单,下面这个就是根据 LangChain Hub 上一个很流行的 prompt 改写而来的:
css
Revise the original question to make it more refined and precise for search
on ChromaDB, allowing for a more accurate and insightful response.
Original question: {user_question}
Revised ChromaDB query:要应用 Rewrite-Retrieve-Read 技术,并使用上面的 prompt 来改写原始用户问题,请打开一个新的操作系统终端,进入第 9 章对应的代码目录,并设置你的环境:
makefile
C:\Github\building-llm-applications\ch09>
C:\Github\building-llm-applications\ch09>python -m venv env_ch09
C:\Github\building-llm-applications\ch09>env_ch09\Scripts\activate
(env_ch09) C:\Github\building-llm-applications\ch09>
↪pip install -r requirements.txt
(env_ch09) C:\Github\building-llm-applications\ch09>jupyter notebook启动 Jupyter Notebook 之后,创建一个新的 notebook,并命名为 09-question_transformations.ipynb。然后,像上一章那样,把来自 Wikivoyage 的英国旅游目的地内容重新导入。为了方便起见,我把那段代码也放在这里了。
代码清单 9.1 从 URL 切分并摄取内容
ini
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import HTMLSectionSplitter
from langchain_community.document_loaders import AsyncHtmlLoader
import getpass
OPENAI_API_KEY = getpass.getpass('Enter your OPENAI_API_KEY')
uk_granular_collection = Chroma(
collection_name="uk_granular",
embedding_function=OpenAIEmbeddings(openai_api_key=OPENAI_API_KEY),
)
uk_granular_collection.reset_collection() #1
uk_destinations = [
"Cornwall", "North_Cornwall", "South_Cornwall", "West_Cornwall",
"Tintagel", "Bodmin", "Wadebridge", "Penzance", "Newquay",
"St_Ives", "Port_Isaac", "Looe", "Polperro", "Porthleven",
"East_Sussex", "Brighton", "Battle", "Hastings_(England)",
"Rye_(England)", "Seaford", "Ashdown_Forest"
]
wikivoyage_root_url = "https://en.wikivoyage.org/wiki"
uk_destination_urls = [f'{wikivoyage_root_url}/{d}'
for d in uk_destinations]
headers_to_split_on = [("h1", "Header 1"),("h2", "Header 2")]
html_section_splitter = HTMLSectionSplitter(
headers_to_split_on=headers_to_split_on)
def split_docs_into_granular_chunks(docs):
all_chunks = []
for doc in docs:
html_string = doc.page_content #2
temp_chunks = html_section_splitter.split_text(
html_string) #3
h2_temp_chunks = [chunk for chunk in
temp_chunks if "Header 2"
in chunk.metadata] #4
all_chunks.extend(h2_temp_chunks)
return all_chunks
for destination_url in uk_destination_urls:
html_loader = AsyncHtmlLoader(
destination_url) #5
docs = html_loader.load() #6
for doc in docs:
print(doc.metadata)
granular_chunks = split_docs_into_granular_chunks(docs)
uk_granular_collection.add_documents(
documents=granular_chunks)
#1 In case it exists
#2 Extracts the HTML text from the document
#3 Each chunk is an H1 or H2 HTML section.
#4 Only keeps content associated with H2 sections
#5 Loader for one destination
#6 Documents of one destination这套设置会为 Rewrite-Retrieve-Read 工作流中的高效查询改写与检索做好数据准备。Rewrite 步骤会帮助你构造更精炼的搜索查询,从而提升检索效果和最终生成回答的质量。
9.1.1 使用原始用户问题检索内容
我们先从直接使用原始用户问题做搜索开始:
ini
user_question = "Tell me some fun things I can enjoy in Cornwall"
initial_results = uk_granular_collection.similarity_search(
query=user_question,k=4)
for doc in initial_results:
print(doc)输出大致会像下面这样(中间我做了不少删减):
ini
page_content='Do
[ edit ]
Cornwall, in particular Newquay, is the UK's surfing capital, with
equipment hire and surf schools present on many of the county's beaches,
and events like the UK championships or Boardmasters festival.
The South West Coast Path runs [REDUCED...]
The Camel Trail is an 18-mile (29 km) [REDUCED...]
The Cornish Film Festival is held annually [REDUCED...]
The Royal Cornwall Show is an agricultural show [REDUCED...]
Camel Creek Adventure Park , Tredinnick, Wadebridge offers great family days out at Cornwall's top theme park.
Festivals
[ edit ]
St Piran's Day (Cornish: Gool Peran ) is the national day of Cornwall,
[REDUCED...].' metadata={'Header 2': 'Do'}
page_content='Do
[ edit ]
The South West Coast Path runs [REDUCED...]
The Camel Trail is an 18-mile (29 km) off-road cycle-track [REDUCED...]
The Cornish Film Festival is held annually [REDUCED...]
Cornwall, in particular Newquay, is the UK's surfing capital, [REDUCED...]
Cricket: Cornwall CCC play in the National Counties [REDUCED...] '
metadata={'Header 2': 'Do'}
page_content='Buy
[ edit ]
In the village centre you will find the usual [REDUCED...] '
metadata={'Header 2': 'Buy'}
page_content='Do
[ edit ]
The South West Coast Path runs along [REDUCED...]
St Piran's Day (Cornish: Gool Peran ) is the national day of
Cornwall[REDUCED...] ' metadata={'Header 2': 'Do'}这些输出确实提供了一些关于"有趣活动"的信息,但看起来还是有些局限。这很可能和问题本身的表述方式有关。
9.1.2 设置查询改写链
为了把用户问题改写成一个更适合 ChromaDB 的查询,我们可以借助 LLM,把它转换成更适合语义搜索的形式。搭建一条 query rewriter chain,可以帮助我们自动完成这一步。先导入所需库:
javascript
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import ChatPromptTemplate
llm = ChatOpenAI(model="gpt-5-mini", openai_api_key=OPENAI_API_KEY)接着,定义 prompt,让 LLM 去改写用户问题:
ini
rewriter_prompt_template = """
Generate search query for the ChromaDB vector store
from a user question, allowing for a more accurate
response through semantic search.
Just return the revised ChromaDB query, with quotes around it.
User question: {user_question}
Revised ChromaDB query:
"""
rewriter_prompt = ChatPromptTemplate.from_template(
rewriter_prompt_template)然后,构建执行改写过程的链:
ini
rewriter_chain = rewriter_prompt | llm | StrOutputParser()这样,你就可以把一个用户问题传进 rewriter chain,得到一个为 ChromaDB 量身定制、用于提高检索准确率的查询。
9.1.3 使用改写后的查询检索内容
现在我们来用这条改写链生成一个更有针对性的查询,看看与原始问题相比,它是否能返回更准确的结果。首先,生成改写后的查询:
ini
user_question ="Tell me some fun things I can do in Cornwall"
search_query = rewriter_chain.invoke(
{"user_question": user_question})
print(search_query)如果你打印 search_query,你应该会看到类似这样的输出:
arduino
"fun activities to do in Cornwall"然后,用这个更精炼的查询去搜索向量存储:
ini
improved_results = uk_granular_collection.similarity_search(
query=search_query,k=3)最后,把结果打印出来,检查其相关性:
bash
for doc in improved_results:
print(doc)你会得到类似下面这样的输出,我也做了删减以节省篇幅:
less
page_content='Do
[ edit ]
Cornwall, in particular Newquay, is the UK's surfing capital, [REDUCED...]
The South West Coast Path runs along the coastline [REDUCED...]
The Cornish section is supposed to be the most [REDUCED...]
The Camel Trail is an 18-mile (29 km) off-road cycle-track [REDUCED...]
The Cornish Film Festival is held annually each November around Newquay .
The Royal Cornwall Show is an agricultural show [REDUCED...]
Camel Creek Adventure Park , Tredinnick, Wadebridge offers [REDUCED...]
Festivals
[ edit ]
' Obby 'Oss is held annually on May Day (1 May), [REDUCED...]
St Piran's Day (Cornish: Gool Peran ) is the national day [REDUCED...]' metadata={'Header 2': 'Do'}
page_content='Do
[ edit ]
The South West Coast Path runs [REDUCED...]
The Camel Trail is an 18-mile (29 km) off-road cycle- [REDUCED...]
The Cornish Film Festival is held annually each November around Newquay .
Cornwall, in particular Newquay, is the UK's surfing capital, [REDUCED...]
Cricket: Cornwall CCC play in the National Counties Cricket [REDUCED...]' metadata={'Header 2': 'Do'}
page_content='Do
[ edit ]
Helford River is an idyllic river estuary between Falmouth and Penzance.
An ideal stop over for yachts heading for the Isles of Scilly, or further
afield, with a selection of excellent pubs and other attractions. There is
also a passenger ferry [REDUCED...].
The South West Coast Path runs along the coastline [REDUCED...].
[REDUCED...]
Festivals
[ edit ]
Allantide (Cornish: Kalan Gwav or Nos Kalan Gwav ) ia a Cornish festival
[REDUCED...] Chewidden Thursday is a festival celebrated by the tin miners
[REDUCED...].
Furry Dance , also known as Flora Day, takes place in [REDUCED...].
Golowan , sometimes also Goluan or Gol-Jowan , is the Cornish word for
the Midsummer celebrations, widespread prior to the late 19th century and
most popular in the Penwith area and in particular Penzance and Newlyn .
[REDUCED...].
Guldize is an ancient harvest festival in Autumn, [REDUCED...]
Montol Festival is an annual heritage, arts and community [REDUCED...].
Nickanan Night is traditionally held on the Monday before Lent. [REDUCED...]
St Piran's Day (Cornish: Gool Peran ) is the national day of Cornwall
[REDUCED...].' metadata={'Header 2': 'Do'}这种做法通常会返回与原始意图更一致的结果,并展示出更广范围的 Cornwall 活动内容。与直接使用原始问题相比,经过改写后,向量存储 retriever 返回了更多样、更贴近需求的文本块。
9.1.4 把所有步骤组合成一条完整的 RAG 链
现在,你可以构建一条完整工作流:先把原始用户问题转换成一个用于向量检索的搜索查询;而在最终生成答案时,仍然保留原始问题。下面的代码清单展示了这条完整 RAG 链,其中包含查询改写步骤。
代码清单 9.2 带查询改写的完整 RAG 链
ini
from langchain_core.runnables import RunnablePassthrough
retriever = uk_granular_collection.as_retriever()
rag_prompt_template = """
Given a question and some context, answer the question.
If you do not know the answer, just say I do not know.
Context: {context}
Question: {question}
"""
rag_prompt = ChatPromptTemplate.from_template(
rag_prompt_template)
rewrite_retrieve_read_rag_chain = (
{
"context": {"user_question": RunnablePassthrough()}
| rewriter_chain | retriever, #1
"question": RunnablePassthrough(), #2
}
| rag_prompt
| llm
| StrOutputParser()
)
#1 The context is returned by the retriever after feeding to it the rewritten query.
#2 The original user question现在运行完整工作流:
ini
user_question = "Tell me some fun things I can do in Cornwall"
answer = rewrite_retrieve_read_rag_chain.invoke(user_question)
print(answer)打印 answer 时,你应该会看到类似这样的回答:
vbnet
In Cornwall, you can enjoy a variety of fun activities such as:
1. Surfing in Newquay, known as the UK's surfing capital, where you can find equipment hire and surf schools on many beaches.
2. Walking along the scenic South West Coast Path, which offers beautiful views and takes you to towns, cliffs, and beaches.
3. Cycling on the Camel Trail, an 18-mile off-road cycle track that follows the picturesque river Camel.
4. Attending the Cornish Film Festival held annually in November around Newquay.
5. Exploring the Helford River, where you can take a ferry ride, visit pubs, and enjoy attractions like the Gweek Seal Sanctuary and Trebah Gardens.
6. Participating in local festivals such as St Piran's Day or the Furry Dance in Helston.
7. Visiting Camel Creek Adventure Park for family-friendly entertainment and activities.
8. Enjoying various agricultural shows, like the Royal Cornwall Show in June.
There are plenty of options for both adventure and relaxation in Cornwall!这个输出展示了一个相当令人满意的回答,而它正是基于组合后的 Rewrite-Retrieve-Read 工作流生成的。接下来,我会继续介绍更多进一步优化 Rewrite-Retrieve-Read 过程的方法。
9.2 生成多个查询
Rewrite-Retrieve-Read 方法默认假设:原始用户问题表述得不好。但如果问题本身表达得已经不错,只是其中隐含了多个子问题,那么把它改写成一个"更好的单一查询"可能并不有效。在这种情况下,更合适的做法是让 LLM 把原始问题拆解成多个明确问题。然后,每个问题都可以分别去查询向量存储,再把这些结果综合成一个完整回答。图 9.3 展示了这种工作流。
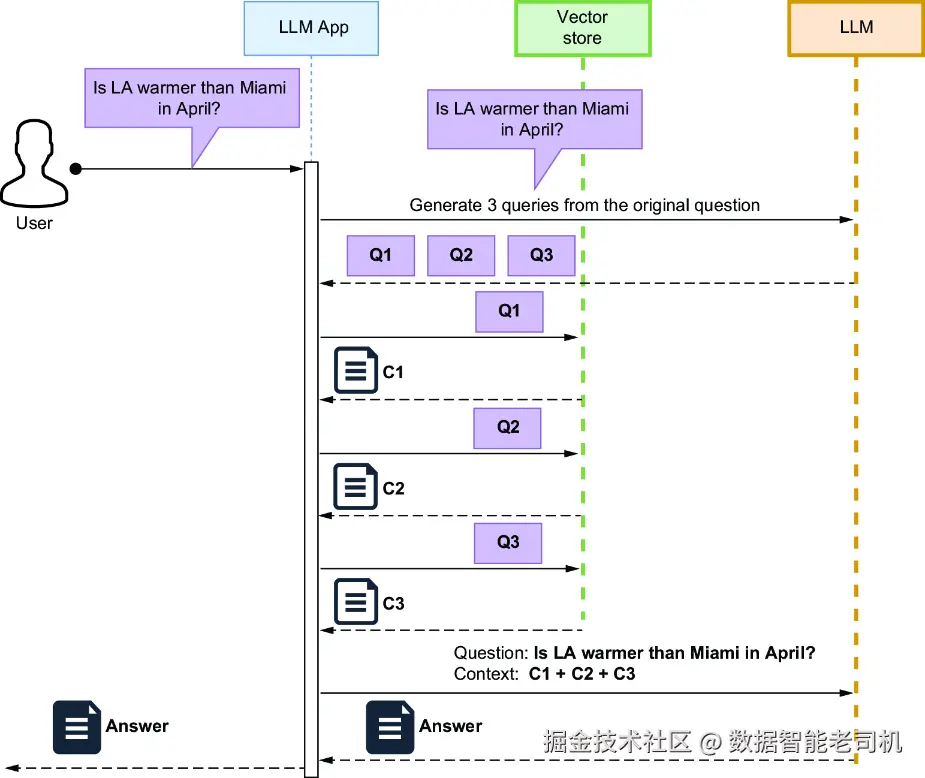
图 9.3 多查询生成工作流
在图 9.3 中,LLM 应用会把原始问题改写成多个明确问题,然后针对这些问题分别查询向量存储以收集上下文,最后用一个包含原始问题和检索上下文的 prompt 来综合答案。
例如,如果你用下面这个 prompt 去问 ChatGPT:
vbnet
Reformulate the following question into multiple explicit questions for my vector store so I can get more easily a correct answer:
Is LA warmer than Miami in April?你可能会得到如下几个可以分别执行在向量存储上的问题:
vbnet
What is the average temperature in Los Angeles during April?
What is the average temperature in Miami during April?
Can you compare the April temperatures in Los Angeles and Miami and determine which one tends to be warmer?
Is there a notable difference in temperature between Los Angeles and Miami in April?
Could you provide insights into how the temperatures in Los Angeles and Miami compare specifically in the month of April?这种方法在设计通用型 LLM 应用时尤其有用。你可以用下面这样一个 prompt,为任意用户问题自动生成多个查询,它改编自 LangChain 的一个示例:
ini
QUERY_PROMPT = PromptTemplate(
input_variables=["question"],
template="""You are an AI language model assistant.
Your task is to generate five different versions of the given
user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user
question, your goal is to help the user overcome some of the
limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines.
Original question: {question}""",
)LangChain 的 MultiQueryRetriever 类允许你传入一个 prompt、一个 LLM 引用,以及一个 retriever(例如由向量数据库派生出来的 retriever)。当 MultiQueryRetriever 实例处理一个用户查询时,它会自动执行整个多查询工作流,就像图 9.3 里展示的那样。这种做法把多次检索 和答案综合 结合在了一起。接下来,我会先展示如何实现一个自定义的 MultiQueryRetriever。
9.2.1 设置用于生成多个查询的链
首先,导入必要的库:
javascript
from langchain_classic.retrievers.multi_query import MultiQueryRetriever
from langchain_core.prompts import ChatPromptTemplate
from typing import List
from langchain_core.output_parsers import BaseOutputParser
from pydantic import BaseModel, Field然后,先设置前面提到过的 prompt,让 LLM 为同一个用户问题生成多个变体:
ini
multi_query_gen_prompt_template = """
You are an AI language model assistant. Your task
is to generate five different versions of the given
user question to retrieve relevant documents from a vector
database. By generating multiple perspectives on the user
question, your goal is to help the user overcome some of
the limitations of the distance-based similarity search.
Provide these alternative questions separated by newlines.
Original question: {question}
"""
multi_query_gen_prompt = ChatPromptTemplate.from_template(
multi_query_gen_prompt_template)由于 LLM 会生成 5 个替代问题,因此把输出格式化成字符串列表 会更方便,每个字符串对应一个问题。这样就能对每个问题独立处理。为此,我们需要实现一个自定义结果解析器,而不是使用标准的 StrOutputParser:
python
class LineListOutputParser(BaseOutputParser[List[str]]):
"""Parse out a question from each output line."""
def parse(self, text: str) -> List[str]:
lines = text.strip().split("\n")
return list(filter(None, lines))
questions_parser = LineListOutputParser()有了这些组件之后,就可以设置用于生成多查询的链:
ini
llm = ChatOpenAI(model="gpt-5-nano", openai_api_key=OPENAI_API_KEY)
multi_query_gen_chain = multi_query_gen_prompt | llm | questions_parser现在试着运行这条链:
ini
user_question = "Tell me some fun things I can do in Cornwall."
multiple_queries = multi_query_gen_chain.invoke(user_question)如果你打印 multiple_queries,你应该会得到类似这样的一个问题列表:
vbnet
['What are some enjoyable activities to explore in Cornwall? ',
'Can you suggest interesting attractions or events in Cornwall for a fun
experience? ',
'What are the top leisure activities to try out while visiting Cornwall? ',
'What fun experiences or adventures does Cornwall have to offer? ',
'Could you recommend some entertaining things to do while in Cornwall?']到这里,距离完整搭建好只差最后一步了:接下来我们就来配置 multi-query retriever。
9.2.2 设置一个自定义 multi-query retriever
要配置一个自定义 multi-query retriever,先创建一个普通 retriever,然后把它嵌入 multi-query retriever 中:
ini
basic_retriever = uk_granular_collection.as_retriever()
multi_query_retriever = MultiQueryRetriever(
retriever=basic_retriever, llm_chain=multi_query_gen_chain,
parser_key="lines" #1
)
#1 The key for the parsed output现在用一个示例问题来测试它:
ini
user_question = "Tell me some fun things I can do in Cornwall"
retrieved_docs = multi_query_retriever.invoke(user_question)打印 retrieved_docs 后,你应该会看到类似如下的输出:
vbnet
[Document(metadata={'Header 2': 'Do'}, page_content='Do \n [ edit ] \n \n Cornwall, in particular Newquay, is the UK's surfing capital, with equipment hire and surf schools present on many of the county's beaches, and events like the UK championships or Boardmasters festival. \n The South West Coast Path runs along the coastline of Britain's south-west peninsula. The Cornish section is supposed to be the most scenic (unless you talk to someone in Devon, [... REDUCED ...] There is large parties widespread across the whole of Cornwall, with people dressing in the black, white and silver national colours.'),
Document(metadata={'Header 2': 'Do'}, page_content='Do \n [ edit ] \n \n The South West Coast Path runs along the coastline of Britain's south-west peninsula. The Cornish section is supposed to be the most scenic (unless you talk to someone [... REDUCED ...] They are unbiased and won't express an opinion on accommodations, more than giving its tourist board rating and facilities."),
Document(metadata={'Header 2': 'Contents'}, page_content='Contents \n \n \n \n \n \n \n \n 1 Towns and villages [... REDUCED ...] Cornwall . It includes much of the Cornish coast along the Celtic Sea and some top surfing areas.'),
Document(metadata={'Header 2': 'Do'}, page_content="Do \n [ edit ] \n \n The South West Coast Path runs along the coastline of Britain's south-west peninsula. The Cornish section is supposed to be the most scenic (unless you talk to someone in Devon, in which [... REDUCED ...], with people dressing in the black, white and silver national colours."),
Document(metadata={'Header 2': 'Festivals'}, page_content='Festivals \n [ edit ] \n \n These festivals tend to not be public holidays and not all are celebrated fully across [... REDUCED ...] is large parties widespread across the whole of Cornwall, with people dressing in the black, white and silver national colours. \n Tom Bawcock's Eve : on 23rd December, stargazey pies are traditionally consumed. In mythology, pies were seen bizarrely as the reason the devil stayed out of Cornwall.'),
Document(metadata={'Header 2': 'Contents'}, page_content='Contents \n \n \n \n \n \n \n \n 1 Towns and villages [... REDUCED ...] South Cornwall is in Cornwall . It includes much of the stunning Cornish coast along the English Channel of the Atlantic Ocean.'),
Document(metadata={'Header 2': 'See'}, page_content="See \n [ edit ] \n \n The Cheesewring at Minions, Bodmin Moor. \n St. Michael's Mount lies offshore close to Penzance. \n Cornwall boasts many attractions [... REDUCED ...] Madron is a sheltered garden bursting with exotic trees and shrubs. \n \n Kynance Cove offers great views towards the Lizard.")]9.2.3 使用标准的 MultiQueryRetriever 实例
对于比较直接的用例,你也可以直接使用标准的 MultiQueryRetriever 实例来完成多查询生成。先实例化这个 retriever:
ini
std_multi_query_retriever = MultiQueryRetriever.from_llm(
retriever=basic_retriever, llm=llm
)然后,用同一个问题来测试它:
ini
user_question = " Tell me some fun things I can do in Cornwall"
retrieved_docs = std_multi_query_retriever.invoke(user_question)retrieved_docs 中的输出会和你前面看到的结果大体相似。不过,在某些情况下,无论是改写原始问题,还是把它拆成多个明确问题,都未必能得到理想结果。继续往下看,我们会介绍另一种在这些场景下也能提高准确率的技术。
9.3 Step-back 问题
当你把一个非常细节化的问题直接送进向量存储时------尤其是在文档已经被切成很多细小、专门化 chunk 的情况下------你检索到的内容可能会过于聚焦,从而丢失更广泛的背景上下文。这会限制 LLM 生成全面回答的能力。
正如我们在 7.4 节讨论过的,一种解决办法是创建两套文档块:一套是用于综合生成的粗粒度 chunk,另一套是用于精细检索的细粒度 chunk。另一种解决办法则不是去改文档 chunk,而是去调整用户问题本身,这种方法叫做 step-back question。
在这种方法中,你先从用户的细节问题出发,再为它生成一个更宽泛的问题,用于检索更抽象、更高层次的上下文。这个 step-back context 会比原始具体问题得到的上下文更宏观。然后,你把细节上下文和更宽泛的抽象上下文一起提供给 LLM,让它生成一个更完整的回答。图 9.4 展示了这一流程:LLM 应用先把细节问题(Q_D)送进向量存储,取回细节上下文(C_D);然后再提示 LLM,基于 Q_D 生成一个更抽象的问题(Q_A),并同样送进向量存储以获取抽象上下文(C_A);最后,LLM 应用把 Q_D、C_D 和 C_A 一起组合进一个 prompt 中,使 LLM 能够综合生成更全面的答案。
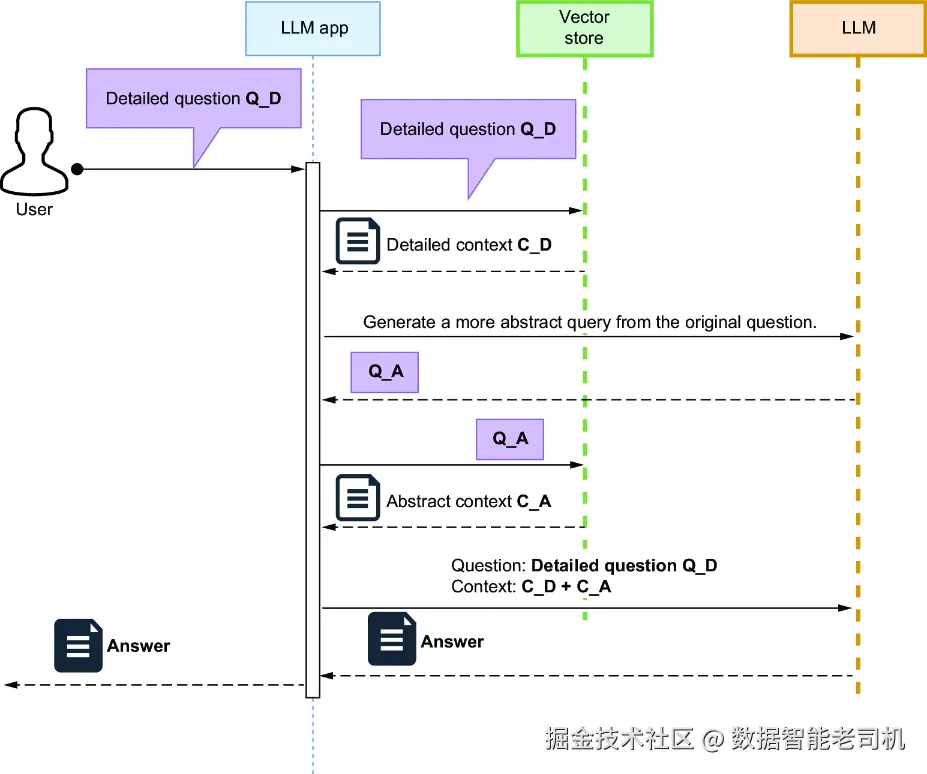
图 9.4 Step-back 问题工作流
LLM 应用先把原始细节问题送进向量存储以获取细节上下文,然后再生成并执行一个更宽泛的问题,以取回更抽象的上下文。最后,它把这两类上下文和原始问题一起组合起来,使 LLM 能够生成一个全面回答。这个技术由 Huaixiu Steven Zheng 等人提出,并在 "Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models" (https://mng.bz/rZEy)中有更详细的解释。
要实现这个思路,你可以使用类似下面这样的 prompt 来生成 step-back question:
css
Generate a less specific question (aka Step-back question)
for the following detailed question, so that a wider context
can be retrieved.
Detailed question: {detailed_question}
Step-back question:例如,如果你把这个 prompt 用在细节问题 "Can you give me some tips for a trip to Brighton?" 上,那么生成出的更抽象 step-back 问题可能会是:
less
Step-back question: "What should I know before visiting a
popular coastal town?"这个更宽泛的问题能够帮助系统检索到更一般性的信息,而这些信息与原始细节上下文结合之后,就能让 LLM 产出更均衡、更完整的回答。
9.3.1 设置用于生成 step-back question 的链
实现 step-back question 技术其实并不复杂:它本质上就是设计一个合适的 prompt 来生成更宽泛的问题,然后再走一遍标准的 RAG 工作流。下面是一段示例实现,模式上和前面 Rewrite-Retrieve-Read 非常相近。先在你的 Jupyter Notebook 里设置 prompt:
ini
llm = ChatOpenAI(model="gpt-5", openai_api_key=OPENAI_API_KEY)
step_back_prompt_template = """
Generate a less specific question (aka Step-back question)
for the following detailed question, so that a wider context
can be retrieved.
Detailed question: {detailed_question}
Step-back question:
"""
step_back_prompt = ChatPromptTemplate.from_template(
step_back_prompt_template)注意 我这里选择使用 GPT-5,而不是 GPT-5-nano 或 GPT-5-mini,因为它通常更擅长生成既抽象、又与上下文相关的问题,同时也能给出更连贯、更完整的最终回答。当然,我还是鼓励你自己试试不同模型,比较它们输出的差异。
现在创建对应的链:
ini
step_back_question_gen_chain = step_back_prompt | llm | StrOutputParser()用一个示例问题测试一下:
ini
user_question = "Can you give me some tips for a trip to Brighton?"
step_back_question = step_back_question_gen_chain.invoke(user_question)如果你打印 step_back_question,你应该会看到类似这样的输出:
vbnet
'What are some general tips for planning a successful trip to a coastal city?'这个生成出来的 step-back question 之后就可以被纳入 RAG 架构中,用来从向量存储中检索更宽泛的上下文,再把这些上下文交给 LLM,以帮助它生成一个更完整的回答。
9.3.2 把 step-back question 生成整合进 RAG 链
你可以把 step-back question 生成链直接整合进 RAG 工作流。下面的代码清单展示了具体写法。
代码清单 9.3 在 RAG 中整合 step-back question 生成
ini
retriever = uk_granular_collection.as_retriever()
rag_prompt_template = """
Given a question and some context, answer the question.
If you do not know the answer, just say I do not know.
Context: {context}
Question: {question}
"""
rag_prompt = ChatPromptTemplate.from_template(rag_prompt_template)
step_back_question_rag_chain = (
{
"context": {"detailed_question": RunnablePassthrough()}
| step_back_question_gen_chain
| retriever, #1
"question": RunnablePassthrough(), #2
}
| rag_prompt
| llm
| StrOutputParser()
)
#1 The context is returned by the retriever after feeding to it the step-back question.
#2 The original user question现在运行这条链:
ini
user_question = "Can you give me some tips for a trip to Brighton?"
answer = step_back_question_rag_chain.invoke(user_question)
print(answer)你应该会看到类似下面这样的综合回答:
markdown
Here are some tips for a trip to Brighton:
1. **Stay Safe**: While Brighton is generally safe, be cautious in busy areas, especially West Street after midnight due to the nightlife crowd.
2. **Watch for Traffic**: Be mindful of traffic, especially in busy areas.
3. **Valuables**: Take standard precautions with your valuables to avoid theft.
4. **Homelessness**: Be aware that there may be homeless individuals asking for money, but most are harmless.
5. **Beaches**: Lifeguards patrol the beaches from late May to early September. Pay attention to signposts about which areas are covered.
6. **Emergency Contacts**: In case of emergencies related to the sea, call 999 and ask for the Coastguard.
7. **Explore Local Venues**: Enjoy local venues favored by residents for a civilized night out.
8. **Cultural Areas**: Visit areas like The Lanes and North Laine for a vibrant cultural experience.
9. **Stay Informed**: Keep an eye on your surroundings, especially in crowded places.
Enjoy your trip to Brighton!这种技术为以 embedding 为核心的方法提供了另一种思路:它不是改文档表示,而是通过把问题本身拓宽,从而改进上下文检索。接下来,我会介绍另一种同样依靠问题转换来优化检索的技术。
9.4 Hypothetical Document Embeddings(HyDE)
正如第 8 章讨论的那样,给文档块附加"假设性问题的 embedding",能够增强 RAG 检索能力,因为这样每个 chunk 都会额外带上一些更接近用户提问方式的向量表示。通常来说,这些假设性问题的 embedding,会比原始 chunk 文本本身的 embedding,更接近用户问题的语义。
而 Hypothetical Document Embeddings(HyDE) 则实现了一个相似的效果,只不过它不去改变原始 chunk 的 embedding,而是基于用户问题生成一个"假设性文档"。HyDE 技术如图 9.5 所示。在这种方法中,LLM 会生成一个"如果要回答用户问题,理应出现的文档片段"。之后,用这个生成出来的假设性文档去做检索,而不是用用户的原始问题。由于这些假设性文档在语义上更接近真实文档 chunk 的表达方式,因此它们能提高检索到相关内容的概率。
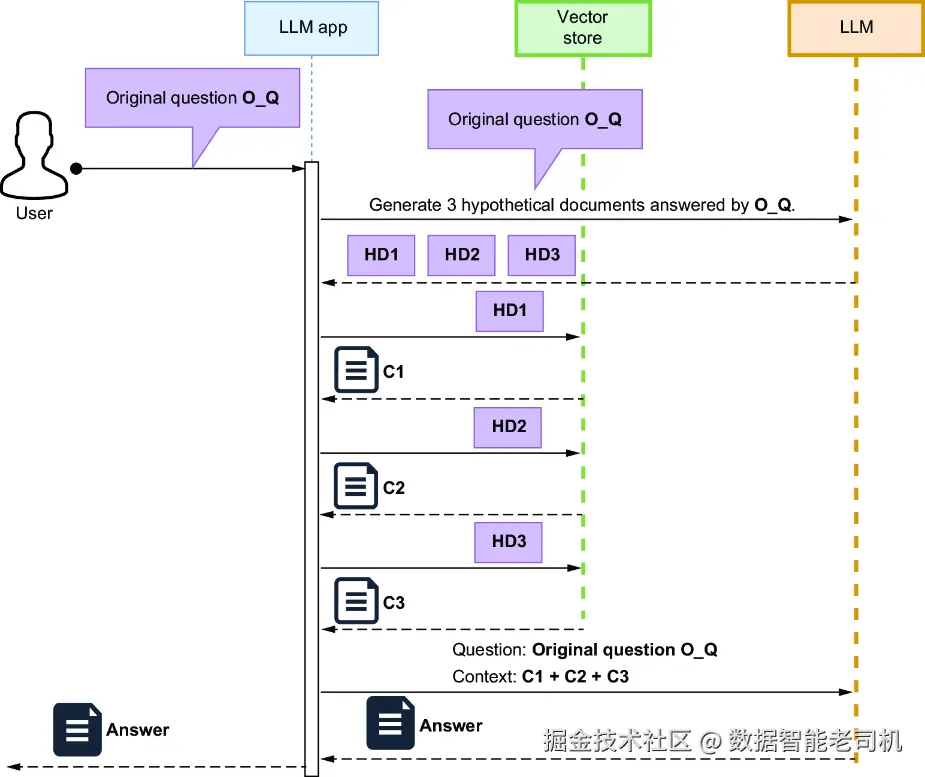
图 9.5 Hypothetical Document Embeddings(HyDE)技术
正如图 9.5 的时序图所示,系统会用生成出来的假设性文档来检索相关内容,目的是提高"用户问题"和"文档 chunk embedding"之间的语义相似度。这项技术由 Luyu Gao 等人在论文 "Precise Zero-Shot Dense Retrieval Without Relevance Labels" (https://arxiv.org/pdf/2212.10496v1.pdf)中提出。下面我们就来实现这个流程。
9.4.1 为用户问题生成一个假设性文档
实现 HyDE 的模式其实也很熟悉:先设计一条链,让它生成一个"本应可以回答该问题的假设性文档",然后再把这个生成出来的文档作为检索输入,嵌入到更大的 RAG 工作流中。首先,先设置 prompt:
ini
llm = ChatOpenAI(model="gpt-5-nano", openai_api_key=OPENAI_API_KEY)
hyde_prompt_template = """
Write one sentence that could answer the provided question.
Do not add anything else.
Question: {question}
Sentence:
"""
hyde_prompt = ChatPromptTemplate.from_template(hyde_prompt_template)接着构建 HyDE 链:
ini
hyde_chain = hyde_prompt | llm | StrOutputParser()用一个示例问题测试一下:
ini
user_question = "What are the best beaches in Cornwall?"
hypotetical_document = hyde_chain.invoke(user_question)如果你打印 hypotetical_document,应该会看到类似这样的输出:
ruby
Some of the best beaches in Cornwall include Fistral Beach, Porthcurno Beach, and St Ives Bay.这个生成出来的假设性文档,就可以被纳入 RAG 链中去检索相关内容,从而改善"用户问题"与"向量存储中文档 chunk"之间的对齐效果。接下来我们就来看看,如何把这一步整合进更大的 RAG 工作流。
9.4.2 把 HyDE 链整合进 RAG 链
你可以像下面这样,把 HyDE 链整合进一条 RAG 工作流中。
代码清单 9.4 在 RAG 工作流中整合 HyDE 链
ini
retriever = uk_granular_collection.as_retriever()
rag_prompt_template = """
Given a question and some context, answer the question.
Only use the provided context to answer the question.
If you do not know the answer, just say I do not know.
Context: {context}
Question: {question}
"""
rag_prompt = ChatPromptTemplate.from_template(rag_prompt_template)
hyde_rag_chain = (
{
"context": {"question": RunnablePassthrough()}
| hyde_chain | retriever, #1
"question": RunnablePassthrough(), #2
}
| rag_prompt
| llm
| StrOutputParser()
)
#1 The context is returned by the retriever after feeding to it the hypothetical document.
#2 The original user question现在运行整条 RAG 链:
ini
user_question = "What are the best beaches in Cornwall?"
answer = hyde_rag_chain.invoke(user_question)
print(answer)你应该会看到一个类似下面这样的综合回答:
ruby
The best beaches in Cornwall mentioned in the context include Bude, Polzeath, Watergate Bay, Perranporth, Porthtowan, Fistral Beach, Newquay, St Agnes, St Ives, Gyllyngvase beach in Falmouth, and Praa Sands. Additionally, in Newquay, popular beaches are Crantock Beach, Fistral Beach, Great Western, Harbour, Holywell Bay, Lusty Glaze Beach, Porth Joke, Porth, Tolcarne Beach, Towan Beach, Whipsiderry, and Watergate Bay.到这里,我们就完成了把 HyDE 整合进 RAG 链的实现。它通过引入一个"假设性文档"来改善检索过程。接下来,在继续往后之前,我想先简要回到前面讲过的"多查询生成"技术,因为它同样能帮助我们进一步聚焦检索目标。
9.5 单步拆解与多步拆解
在 9.2 节介绍的"多个问题 / 子问题"方法中,原始用户问题往往隐含着多个子问题。在那种情况下,我们会让 LLM 生成一组明确、彼此独立的问题,每个问题都可以单独(或者并行)执行在向量存储上。这种方法叫做单步拆解(single-step decomposition) 。当这些问题彼此独立,并且原始复杂问题可以被拆成多个简单、单步问题时,这种方式非常有效。
但是,如果原始问题中包含的是多个相互依赖的问题,就需要采用另一种方法。例如,如果你的数据存储中包含旅游信息,请看这样一个问题:
"What is the average August temperature at the most popular sandy beach in Cornwall?"
这个问题就需要一连串相互依赖的查询,每一个问题的答案都会决定下一个问题该怎么问。
在这种情况下,你可以让 LLM 先生成一个"拆解计划",把原始问题拆成一系列彼此依赖的查询。每个查询中都会包含一个参数,这个参数要由上一步的答案来填充。一旦 LLM 返回这样一组带参数的问题序列,你就可以按顺序逐步执行它们------每一步都把当前答案存下来,并注入到下一步查询中。这个过程会一直持续下去,直到你拿到最终答案,如图 9.6 所示。
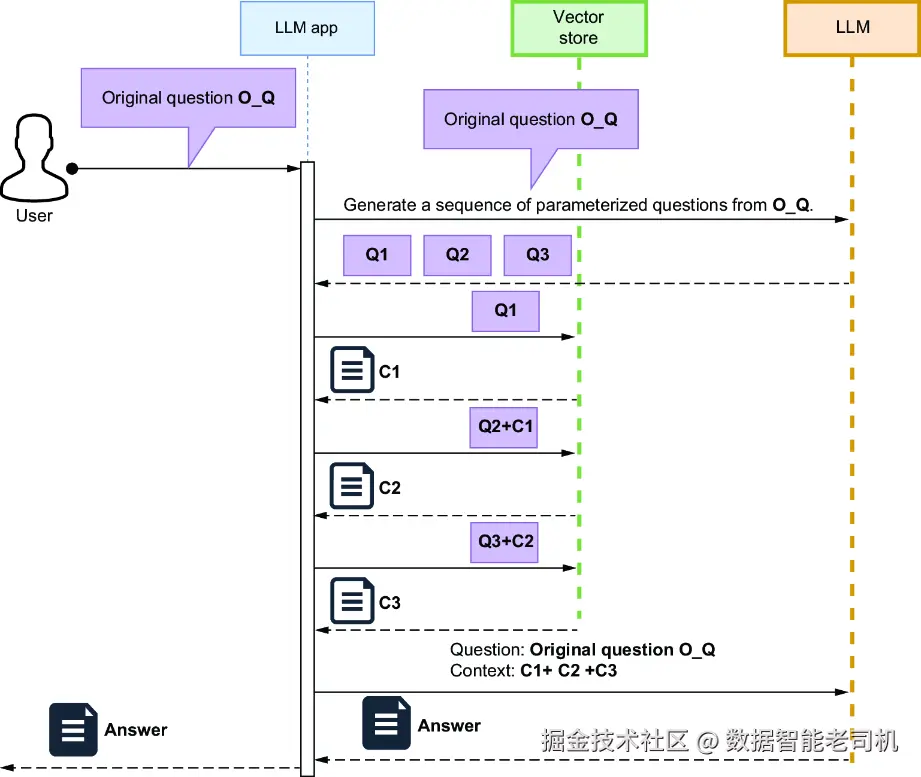
图 9.6 多步拆解工作流
在这个时序图所示的工作流中,原始复杂问题会先被发送给 LLM,由它拆解成一系列参数化问题。接着,每个问题会按顺序在向量存储上执行,并把前一步得到的答案作为参数传给后一步。所有问题都回答完之后,LLM 再把这些收集到的信息综合起来,生成最终回答。为了让 LLM 生成这组问题序列,你可以使用如下模板:
vbnet
Break down the following question into multiple dependent steps
That I can execute on a vector store or other data sources (e.g.,
databases) to obtain the final answer. Assume you have granular
data in your data sources, but not aggregate data. Each
subsequent question can take a parameter from the result of the
previous step.
For each step, include the question and the corresponding
parameter that will be filled with the previous answer.
Provide the sequence of questions in JSON format as a list,
where each step includes:
- Question: The text of the question.
- Parameter: The parameter to be filled with the previous answer.
------
Original question: {user_question}
Multiple dependent questions:为了让你更直观地理解这样的多步问题序列会是什么样子,你可以直接把上面的 prompt 放到 ChatGPT 中试一下。如果把 user_question 换成:
"What is the average August temperature at the most popular sandy beach in Cornwall?"
那么你会得到类似这样的输出:
css
[ { "Question": "What is the most popular sandy beach in Cornwall?", "Parameter": "None (initial query to the full data source)" }, { "Question": "What are the recorded daily temperatures in August for
[Beach Name]?", "Parameter": "Beach Name from the previous answer" }, { "Question": "What is the average temperature from the following list of
daily temperatures: [Daily Temperatures]?", "Parameter": "Daily Temperatures from the previous answer" }]之后,你就可以把这些问题依次执行在向量存储或者 SQL 数据库中,并用前一步的答案去填充后一步的参数。等最后一个问题执行完成之后,你就得到了足够的上下文,可以让 LLM 回答最初那个原始问题了。
注意 如果你用的是 SQL 数据库,那么其实可以直接借助像 AVG 这样的 SQL 原生函数,把过程简化很多。不过这里的重点在于说明概念,而不是展示最优实现方式。
这里我不会给出完整实现,但你应该已经能看出来:这种方法建立在若干高级 RAG 技术之上,例如:
- 将自然语言问题路由到合适的内容存储中
- 基于自然语言问题,为特定内容存储(如 SQL 数据库)生成查询语句
虽然 LangChain 目前没有专门的类来做多步问题拆解 ,但你可以参考 LlamaIndex 中的 MultiStepQueryEngine 类,从中获得一些实现灵感。
到这里,我们关于"通过问题转换来增强检索效果"的这一组技术就讲完了。下一章中,你还会学习更多提升 RAG 性能的方法。
小结
- 含糊或过于复杂的问题往往会带来糟糕的检索效果,因为向量存储匹配的是语义相似性,而不是严格的逻辑精度。查询优化的目标,就是把不清晰的问题转换成适合检索的输入。
- 查询改写(Rewrite-Retrieve-Read) 会使用 LLM 把用户问题重写成更清晰、更具体的版本,再去执行检索。例如,"Fix my code" 可以被改写成 "How to resolve ImportError: No module named pandas in Python?"。
- 多查询检索(multi-query retrieval) 会生成 3 到 5 个原始问题的变体,分别检索文档,再通过 Reciprocal Rank Fusion(RRF) 合并结果。这样能覆盖同一意图的不同表述方式。
- 由粗到细的检索(coarse-to-fine retrieval) 会先用高层摘要(例如 500 字的 chunk)找到相关 section,再在这些 section 内部用更细粒度的 chunk(例如 100 字)做二次检索,从而逐步缩小范围。
- Step-back prompting 会先生成一个更宽泛的问题,用它检索基础知识。例如,"How do I configure SSL in Flask?" 可以被扩展成 "What is SSL, and how do web frameworks handle it?"。
- Hypothetical Document Embeddings(HyDE) 会先为用户问题生成一个"假答案",然后检索那些与这个生成答案更相似的文档,而不是直接拿原始问题去检索。
- 查询拆解(query decomposition) 会把复杂问题拆成独立子问题。例如,"What are the performance differences between PostgreSQL and MongoDB for time-series data?" 可以拆成分别询问两个数据库在 time-series 场景下能力的问题。
- Reciprocal Rank Fusion(RRF) 的做法是:对所有查询结果列表中的每个文档,计算
1 / (rank + k)的分数并求和,其中k通常设为 60。出现在多个列表中的文档会得到更高分。 - Step-back prompting 往往包含两次检索:先检索宽泛问题对应的文档,再检索具体问题对应的文档,最后把这两类上下文一起送进最终 prompt。
- 一定要在你自己的数据集上测试这些查询优化技术。
MultiQueryRetriever很适合处理含糊问题;而当用户问题与文档表述方式差异较大时,HyDE 通常尤其有效。