该篇解决 Agent 开发里最基础的问题:怎么用 Python 通过 LangChain 调用一个聊天模型。
先抓住主线:
txt
输入消息 -> ChatOpenAI -> 模型回复Agent 看起来复杂,但底层离不开模型调用。后面学 Tool、RAG、Memory、LangGraph,都会继续围绕模型调用、消息组织和状态流转展开。
所以这一篇不是单纯学"调一次大模型",而是先把 Agent 的模型入口打通。
LangChain 是什么
LangChain 不是大模型本身。它是一套 AI 应用开发框架,用来统一管理:
- Model:调用不同模型提供商
- Message:组织 system / user / assistant / tool 消息
- Prompt:管理提示词模板
- Runnable:组合多个步骤
- Tool:把外部函数暴露给模型
- Agent:让模型在多步任务里做决策
这一篇只看 Model 层,也就是怎么创建 ChatOpenAI 并调用它。
langchain-openai 是什么
langchain-openai 是 LangChain 的 OpenAI 集成包。
它提供 ChatOpenAI,用来连接 OpenAI 官方接口,或者 DeepSeek 这种兼容 OpenAI 接口格式的第三方模型服务。
python
# 它负责把 LangChain 的统一模型接口,转换成"OpenAI 接口格式"的请求。
# 名字里有 openai,但不代表只能调用 OpenAI 官方模型。
# 只要第三方服务也支持 OpenAI 那套请求格式,比如 DeepSeek,也可以用它接入。
from langchain_openai import ChatOpenAI
# ChatOpenAI:代码里真正创建和调用的聊天模型客户端。
# 它不是模型本身,只负责接收配置、消息和参数,然后去请求远程模型服务。
model = ChatOpenAI(
model="deepseek-v4-pro",
api_key="your_deepseek_api_key_here",
base_url="https://api.deepseek.com",
)
# OpenAI 官方接口 / 兼容 OpenAI 格式的第三方接口:真正提供模型能力的远程接口。
# 这里 base_url 指向 DeepSeek,所以请求会发给 DeepSeek。
# 如果 base_url 指向 OpenAI,请求就会发给 OpenAI。
response = model.invoke("你好,请介绍一下 LangChain")安装依赖
本文默认使用 uv 管理 Python 项目和依赖:
bash
uv add langchain-openai python-dotenvlangchain-openai 负责模型集成,python-dotenv 负责读取 .env 文件。
如果只是临时用 pip 安装,也可以写成:
bash
pip install langchain-openai python-dotenv环境变量
这里以 DeepSeek 为例。DeepSeek 支持 OpenAI 那套接口格式,所以可以继续使用 langchain-openai 的 ChatOpenAI,只需要把模型名、API Key 和 base URL 换成 DeepSeek 的配置。
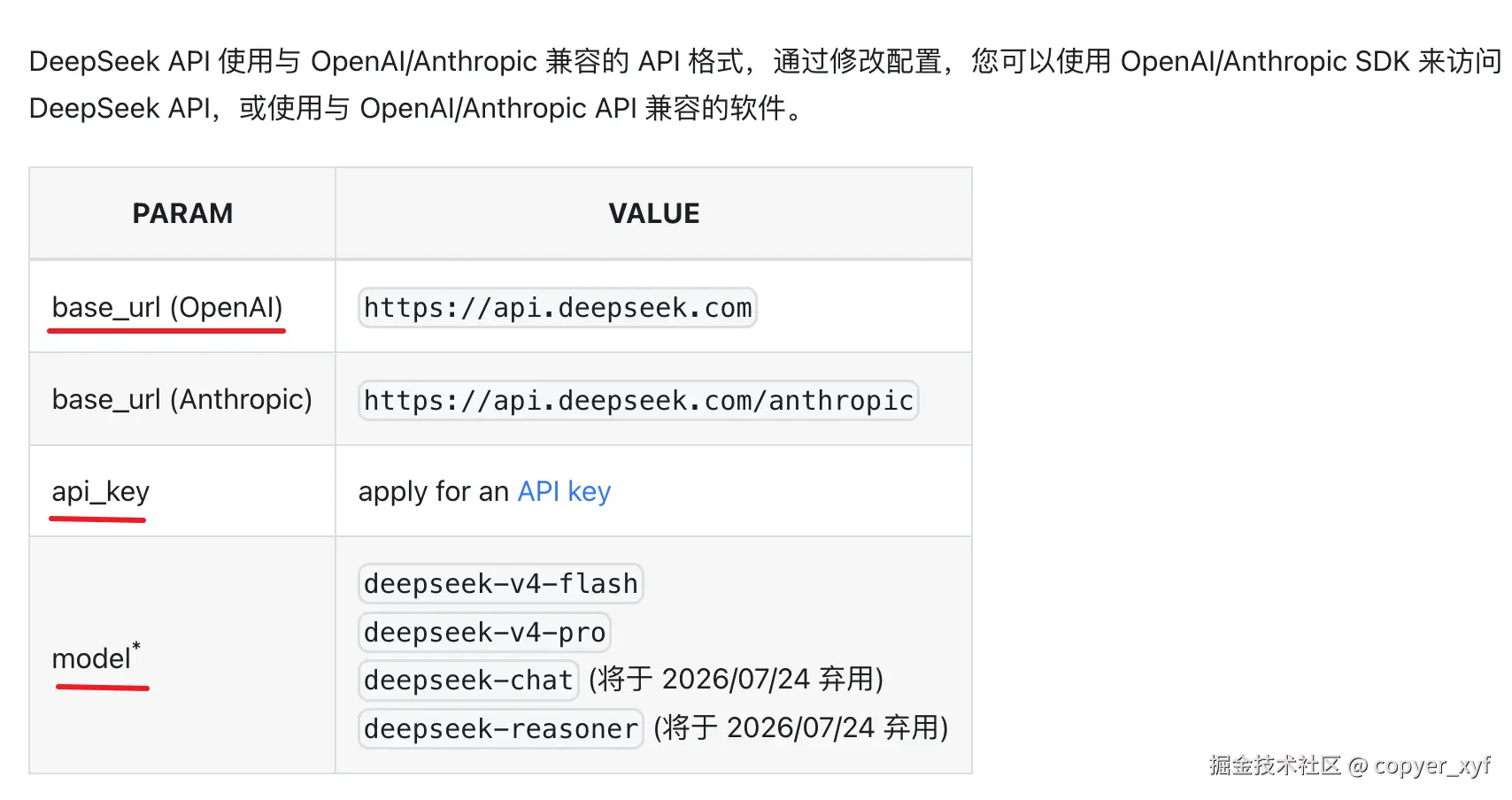
bash
LLM_MODEL=deepseek-v4-pro
LLM_API_KEY=your_deepseek_api_key_here
LLM_BASE_URL=https://api.deepseek.com说明:
LLM_MODEL:模型名称。DeepSeek 当前可以使用deepseek-v4-flash或deepseek-v4-pro。LLM_API_KEY:DeepSeek 平台申请的 API Key。LLM_BASE_URL:DeepSeek 提供的接口地址。它支持 OpenAI 那套请求格式,所以这里填https://api.deepseek.com。
这里的关键点是:langchain-openai 不等于只能调用 OpenAI 官方模型。只要服务商支持 OpenAI 那套接口格式,就可以通过改 base_url 接入。
只使用 OpenAI 官方服务时,LLM_BASE_URL 可以不写或改成 OpenAI 官方地址;使用 DeepSeek、代理、网关或其他兼容服务时再配置。
创建模型
python
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
load_dotenv()
# 读取必填环境变量。
# 如果变量不存在,直接抛错,让问题在启动阶段暴露出来,而不是等到请求模型时才失败。
def required_env(name: str) -> str:
value = os.getenv(name)
if not value:
raise RuntimeError(f"Missing environment variable: {name}")
return value
# 创建聊天模型客户端。
# 后续所有模型调用都从这里拿实例,避免每个示例重复配置 model、api_key、base_url。
def create_model() -> ChatOpenAI:
base_url = os.getenv("LLM_BASE_URL")
# 模型初始化集中在这里,后续 Prompt、Tool、Runnable 都复用同一个入口。
model_kwargs = {
"model": required_env("LLM_MODEL"),
"api_key": required_env("LLM_API_KEY"),
"temperature": 0.2,
"timeout": 30,
"max_retries": 2,
}
# 不配置 LLM_BASE_URL 时走默认 OpenAI 地址;配置后可以接 DeepSeek 这类服务。
if base_url:
model_kwargs["base_url"] = base_url
return ChatOpenAI(**model_kwargs)这里重点看两个自定义函数:required_env() 负责校验必填配置,create_model() 负责收口模型初始化。
非流式调用
非流式调用会等模型完整生成后,一次性返回结果。
python
def invoke_demo() -> None:
model = create_model()
# invoke 会等模型完整生成后再返回,适合一次性拿完整结果。
response = model.invoke(
[
{
"role": "user",
"content": "用三句话解释 LangChain 是什么。",
}
]
)
print(response.content)invoke 返回的是一个 AIMessage。最常用的是 content,也就是模型回复内容。
后面学 Tool 时,还会重点关注 tool_calls,因为模型想调用工具时,调用意图会出现在那里。
流式调用
流式调用会边生成边返回,适合聊天界面、命令行输出、长文本生成。
python
import sys
def stream_demo() -> None:
model = create_model()
# stream 会返回一段段 AIMessageChunk,适合做实时输出。
stream = model.stream(
[
{
"role": "user",
"content": "介绍一下重庆火锅文化。",
}
]
)
for chunk in stream:
# 这里只处理文本片段;后面接触多模态或工具调用时,content 可能会更复杂。
if isinstance(chunk.content, str):
sys.stdout.write(chunk.content)
sys.stdout.flush()
sys.stdout.write("\n")这里的关键是 for chunk in stream。
可以把 stream 理解成一个不断产出内容片段的迭代器。模型每生成一小段内容,就拿到一个 chunk,然后立刻输出。
参数怎么放
ChatOpenAI 初始化时常见的模型参数。
可以先按三类理解:
连接参数
python
ChatOpenAI(
api_key="...",
base_url="...",
model="deepseek-v4-pro",
)api_key:访问模型服务的密钥,应该从环境变量读取,不要写死在代码里。base_url:模型服务地址。使用 OpenAI 官方服务时可以不写;接 DeepSeek 这类服务时需要配置。model决定调用哪个模型。它适合放进环境变量,因为开发、测试、生产环境可能会使用不同模型。
生成控制
python
ChatOpenAI(
temperature=0.2,
max_tokens=1000,
top_p=1,
)temperature:控制随机性。越低越稳定,越高越发散。写代码、分类、抽取信息时通常调低;创意写作可以调高。max_tokens:限制模型最多生成多少 token,避免输出太长。top_p:另一种控制随机性的参数。入门阶段一般先调temperature,不要同时乱调两个。
请求控制
python
ChatOpenAI(
timeout=30,
max_retries=2,
)timeout:请求超时时间,避免网络卡住导致程序一直等待。max_retries:请求失败后的重试次数,适合处理临时网络波动。
小结
这一篇只需要记住三件事:
ChatOpenAI是 LangChain 的模型调用层。invoke一次性返回完整回复,stream边生成边返回。- 参数先按连接、模型选择、生成控制、请求控制四类理解。