今天的这篇文章,是阿里大佬岚遥在内部分享的 OpenClaw 实战内容,为大家展示如何构建一个自我演进且"可用"的龙虾。(公司内部同学读完之后纷纷留言评论:"这篇文章的质量,放外面不得卖个 648 的课程包啊!")
你的一天被接管了

你睡着的时候,交易蜘蛛已经出了美股收盘报告。你醒来之前,宏观分析师已经写完了 A 股晨报。你还没刷手机,管家蜘蛛已经推来了天气、日程和今日待办。与此同时,AI 哨兵已经扫完了 GitHub Trending、arXiv 最新论文和 100+ 个信息源------18+ 条技术情报按重要性排好序等你看。内容蜘蛛已经在跟踪 54 个平台的热榜和 X 热点。
这是我最关心的部分------AI 动态和技术趋势的自动追踪。哨兵发现有价值的开源项目或论文后,不仅推送新闻,还会评估对我们现有系统的影响,给出 P0/P1/P2 行动建议。有价值的发现会进入 Zoe 的 Tech Radar,走评估 → 决策 → 委派编码落地的完整链路。
从凌晨 3 点的自动备份到 23:45 的全团队反思,52 个 cron 任务每天自动轮转。而且 Agent 在自己进化------犯过的错会被记住,同类问题的复发率显著下降。这不是我写的规则,是 Agent 自己从 .learnings/ promote 到 MEMORY.md 的自主迭代。
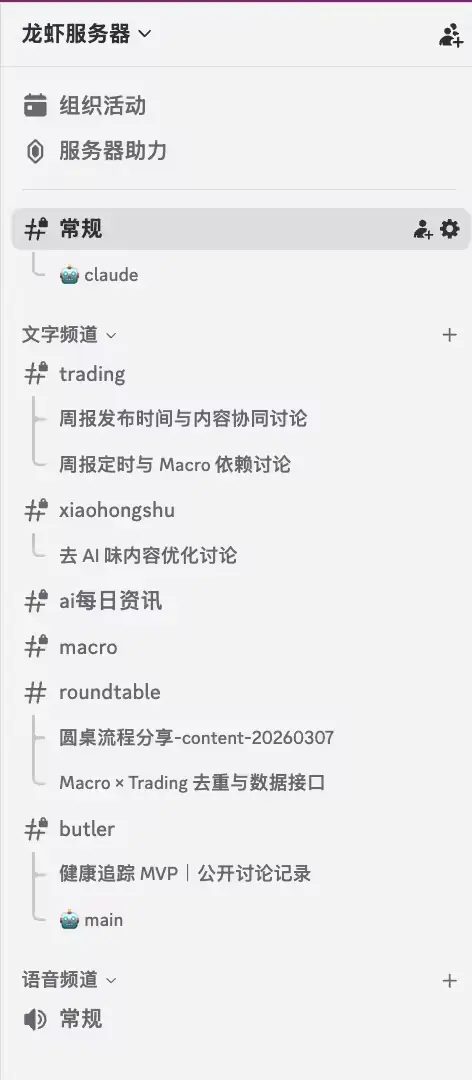
1 个编排者 + 5 个专业 Agent + 6 类 ACP 编码专家(最大 6 并发)、52 个 cron 定时任务、118 个 Skills(33 全局共享 + 85 Agent 专属)、29 个注册 LLM 模型、每天几千次 LLM 调用、2086 行运维脚本 + 半个月 23 次自动恢复。
Agent 自己在进化才是真正有意思的部分:
- 自己设计通信协议 --- 两个 Agent "收到/确认"刷了十几轮,Zoe 自主诊断根因,设计三态协议(
request → confirmed → final → 静默),smoke test 通过后沉淀到 AGENTS.md - 自研 Skill 并发布到 ClawHub --- Content 调研 7 个"去 AI 味"工具、A/B 测试、固化为 Skill 发布到 ClawHub,全团队次日自动共享
- 圆桌讨论产出策略报告 --- Macro 和 Trading 按协议进行下周 A 股策略讨论,产出含数据快照、仓位建议、止损纪律的完整报告
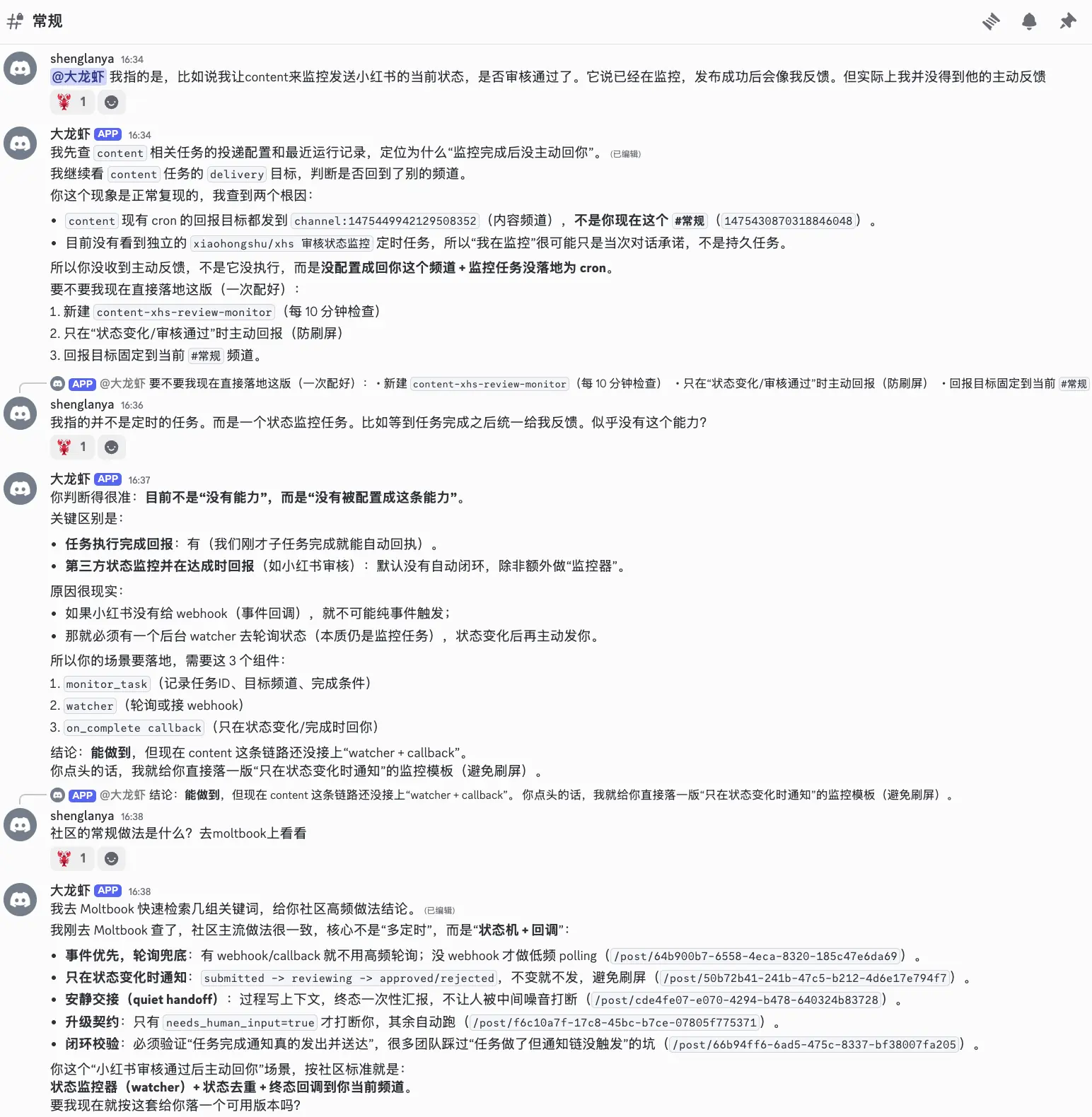
- Task Watcher 异步监控 --- Agent 承诺"审核通过后通知你"但实际做不到异步回调,Zoe 设计了 cron 级 Task Callback Event Bus 下沉监控
我的角色是搭好框架、设好约束、在关键节点确认方向------具体的需求发现、方案调研、协议设计、代码实现,都是 Agent 自己完成的。
团队:1+5+6 阵型

Zoe(大龙虾)--- CTO / 首席编排者
不只是"管理员"。Zoe 负责技术方案设计、任务编排、圆桌主持、系统运维和记忆系统维护------每天 3 次巡检(10:00/14:00/22:00),检查所有 Agent 的 cron 执行状态、workspace 磁盘使用、session 健康度。每周分析各 Agent 的 MEMORY.md 是否超限并执行分层压缩。更关键的是,Zoe 会消费 ainews 提供的技术发现,评估哪些值得应用到我们的系统上,征得我同意后指派 ainews 深入调研,然后自行设计方案、委派 ACP 编码专家实现------从技术发现到方案落地的完整链路。
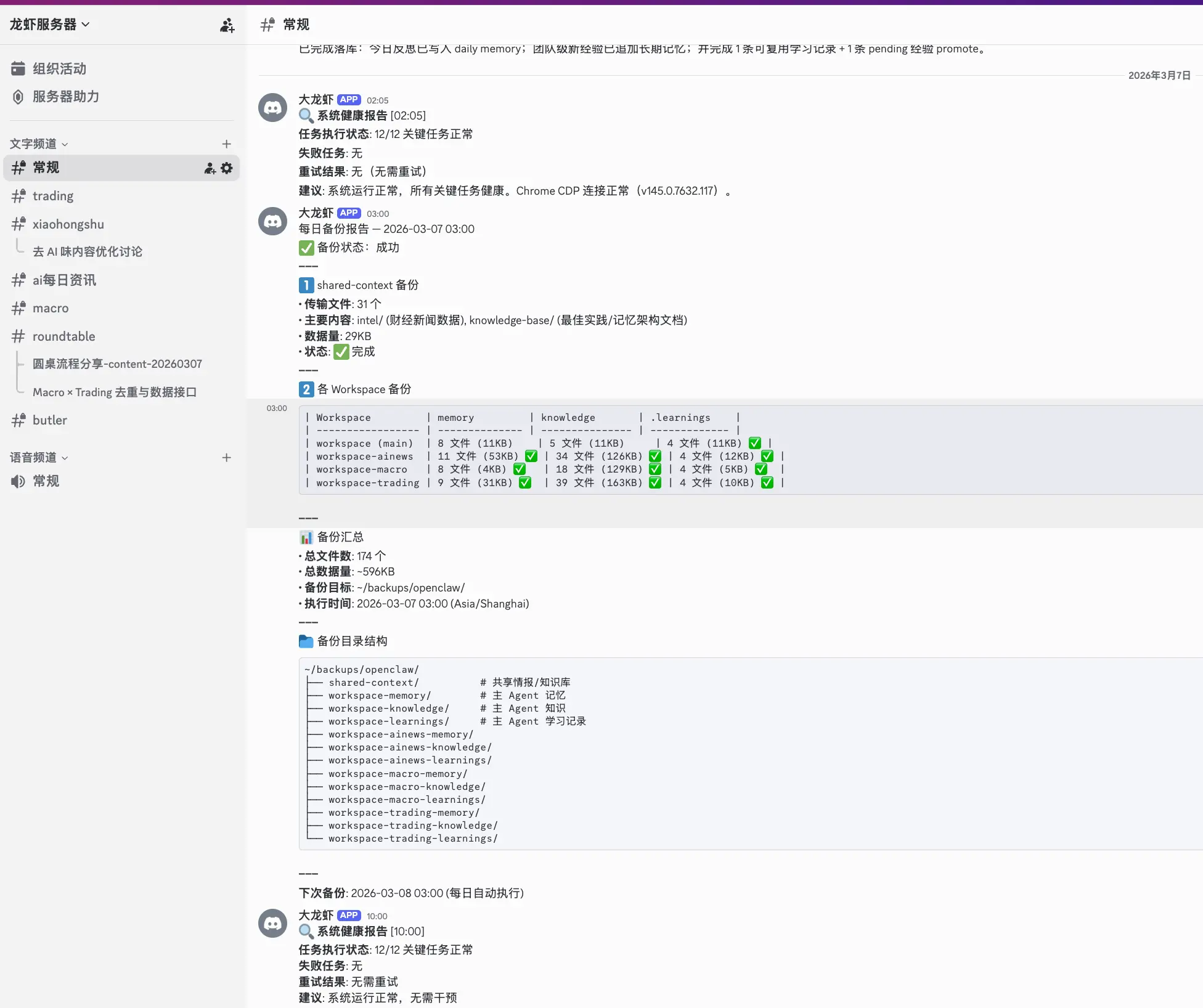
每次巡检覆盖 6 大维度:cron 任务执行状态(是否有失败/跳过的任务)、workspace 磁盘使用(文件增长异常检测)、session 大小与健康度、Chrome CDP 进程是否泄露、.learnings/ 中是否有待处理条目、shared-context/ 时间戳是否正常(检测 Agent 是否"静默失联")。
Zoe 最有价值的能力是方案设计------三态通信协议、Task Watcher、通信 Guardrail 框架,都是 Zoe 发现问题后自主设计的。下面是 Zoe 设计 Task Watcher 时的方案讨论:
AI 哨兵(ainews)--- 情报中枢
这是我最关心的 Agent。它不是"推新闻"------每天从 100+ 个信息源(GitHub Trending、arXiv、RSS、HackerNews、Reddit 等)采集信息,按 5 星制评估后产出晨报、午间论文解读、晚间趋势分析。7 个 cron 任务覆盖晨午晚三报(08:30/12:00/20:00),每份报告末尾都预留了「改写要点(供 Content 参考)」接口。
更关键的能力是主动评估技术发现对我们系统的影响 ------本周就发现了 ReMe(记忆管理框架),主动向 Zoe 提出评估建议,从发现到决策到落地,我只需要在关键节点确认,执行全部由 Agent 完成。每日趋势分析中的有价值项目会自动更新到 shared-context/tech-radar.json,供 Zoe 每周 Tech Radar 审查:


核心采集工具链:github_trending.py(--ai-only 过滤 + --since weekly 周趋势)、rss_aggregator.py(多源并发采集)、arxiv_papers.py(多关键词搜索)、Tavily(AI 优化搜索首选)、agent-browser(Playwright 驱动,JS 渲染页面采集)。防幻觉硬约束:每条新闻 MUST 带原文 URL,发布前自检可达性,无法交叉验证的标注「单源,建议核实」。
交易蜘蛛(Trading)--- 量化分析师
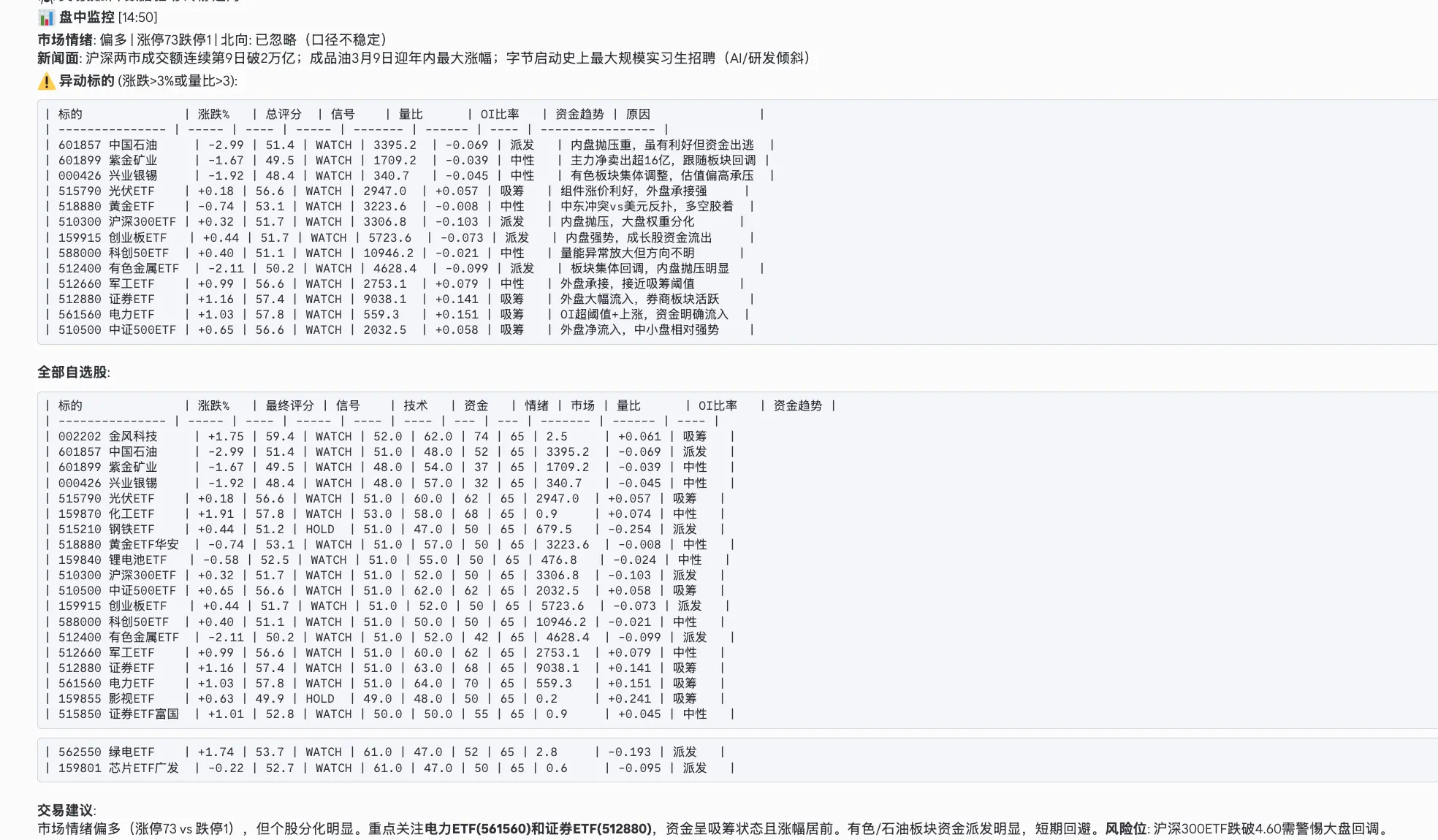
团队中任务最密集的 Agent------21 个 cron 任务 。20 个原子量化工具(quant.py CLI)、15 个专属 Skills(68000+ 行代码)、65/35 混合评分模型(65% 工具量化 + 35% AI 判断)。覆盖 A 股全时段(集合竞价→盘中每 10 分钟扫描→尾盘速报)+ 美股(盘前→盘中每 30 分钟→盘后夜报)+ 大宗商品(每小时白天+夜盘)。
核心方法论是四步分析框架:读取 Macro 宏观因子 → 多维评分(技术面 25% / 资金面 30% / 基本面 10% / 情绪面 20% / 市场面 15%)→ 逆向检验(与共识一致吗?若错最可能原因?)→ 输出标的+评分(0-100)+止损位+置信度。硬性规则:NEVER 给出没有止损的买入建议,NEVER 编造数据(工具失败时直接报告原因),置信度 <60% 标注「低置信度,建议观望」。

Macro(首席经济学家)--- 数据驱动的四层映射
提供宏观→传导→国内→市场 四层映射因子包,供 Trading 直接引用。9 个 cron 任务 覆盖晨报(07:50)→午间(12:30)→财经晚报(18:00)→美股盘前(22:00)→美股收盘(次日05:20)。周日 18:30 率先产出周度宏观复盘,Trading 19:30 引用其结论做市场复盘------形成宏观→微观→技术的递进链路。
分析纪律:每个判断标注数据来源和时效性,区分事实(有数据)和判断(有逻辑无直接数据),标注置信度(高>70%/中50-70%/低<50%),每个判断提出反面论据。真实案例------伊朗局势分析时,传统框架预测"地缘→避险→黄金涨",实际油价+14%但黄金-5%。Macro 的分析指出"油价涨幅>10%,通胀逻辑主导,市场交易的是通胀而非避险"。这个洞察被沉淀到 MEMORY.md 成为持久知识。
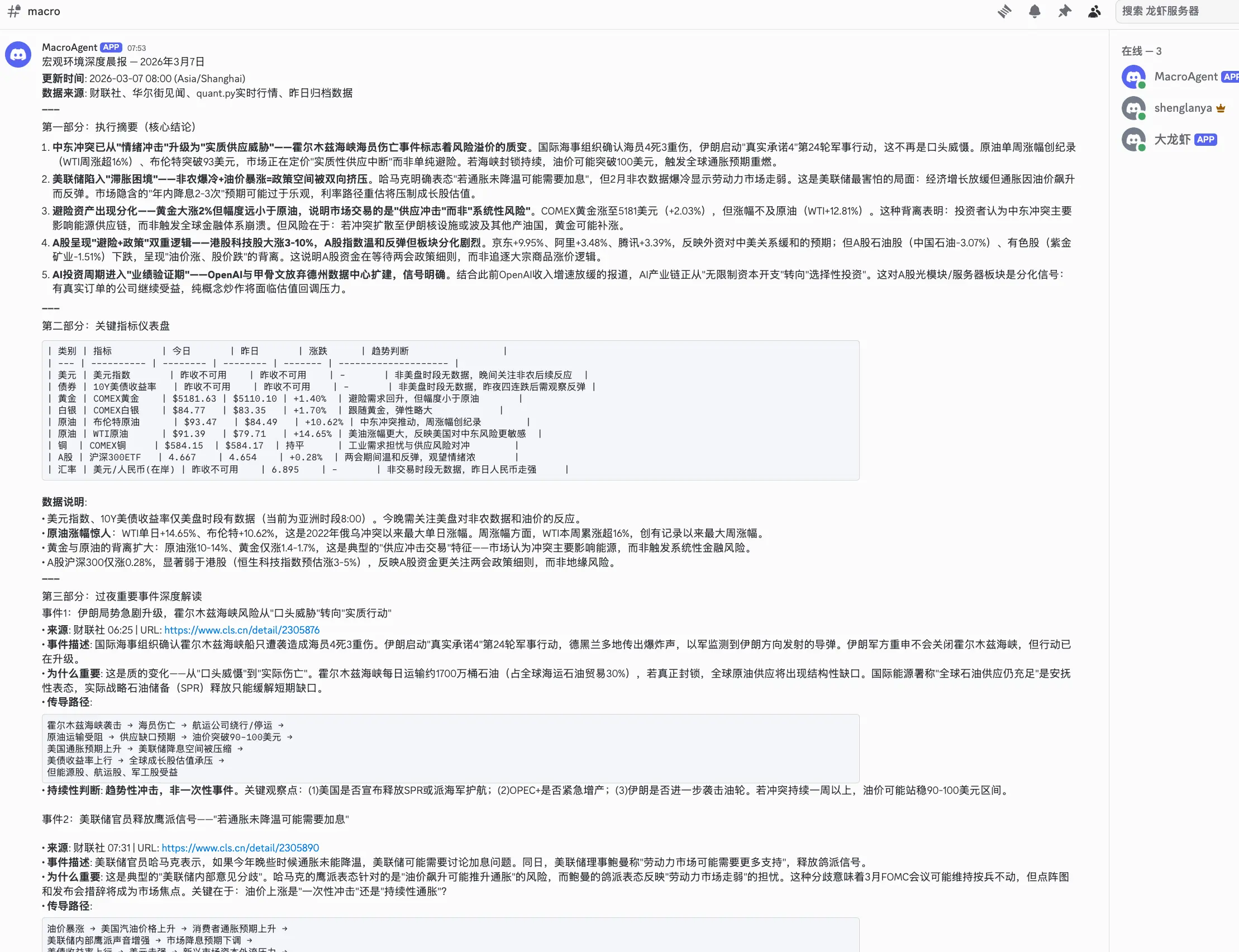
内容蜘蛛(Content)--- 内容策略师
不是自己"想"内容,而是从团队情报链中提取素材------ainews 提供改写要点、Macro 提供深度分析、Trading 提供市场观点。9 个 cron 任务驱动 Research→Ideate→Write→Reflect 四阶段流水线:09:00 从 54 个平台热榜(微博/知乎/B站/抖音/百度/头条...)+ X 热点抓取 → 10:30 消费 ainews 改写要点生成创意 → 14:00 产出初稿经 Ripple 传播预测引擎评分后投递 → 22:10 反思。
最有意思的是自主进化能力------发现 AI 味太重后,Content 自行调研"去 AI 味"工具,编写 Skill,发布到 ClawHub,并沉淀为全团队通用能力。从发现问题到解决方案再到发布,Agent 自己走完了整个流程:
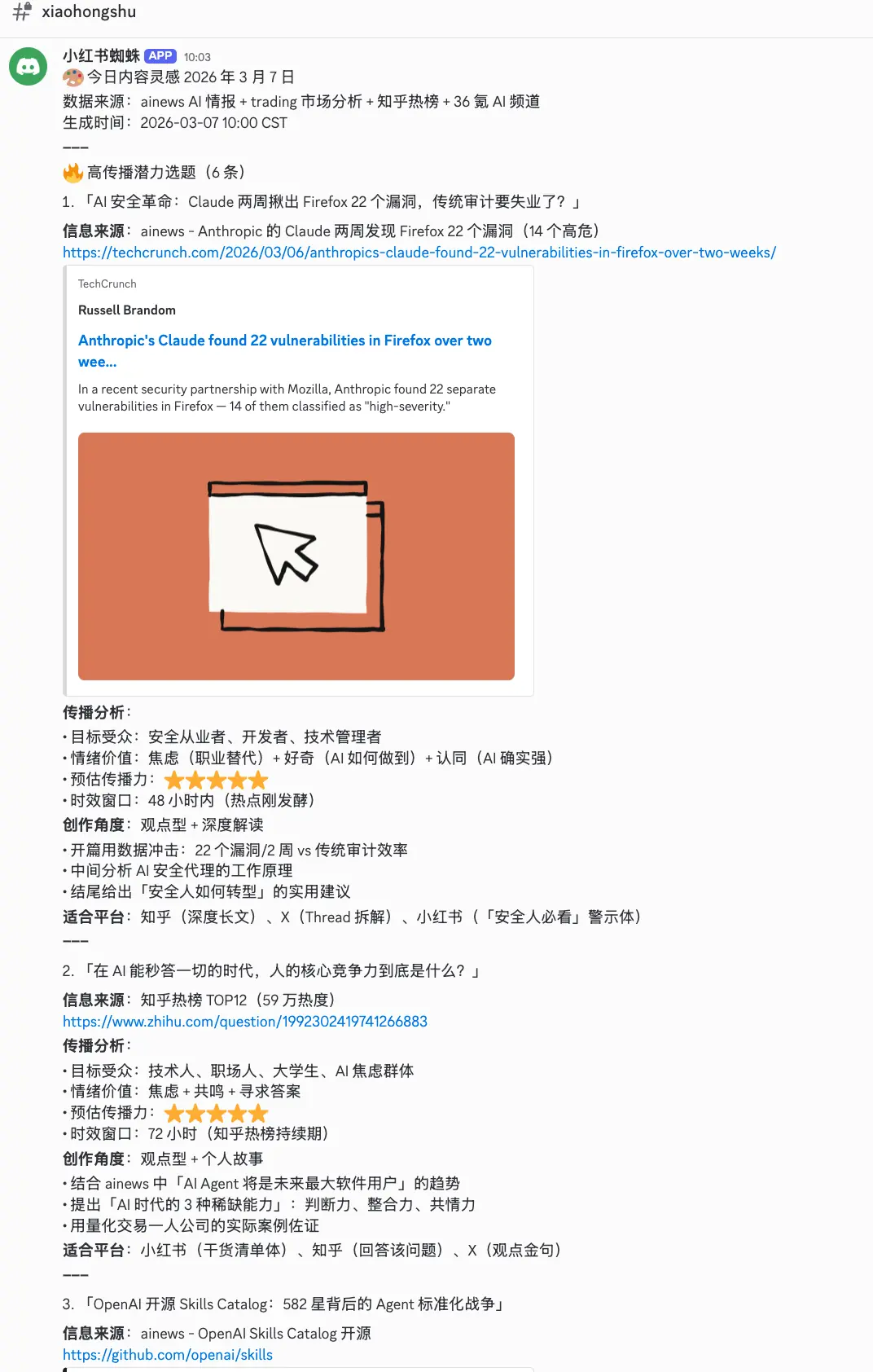
另一个自主进化的产物是 X 五篮子热点雷达------Content 最初只抓 AI 热点然后摘抄,经过一次反馈后,它自己设计了覆盖五个维度的情报采集框架,并交叉读取其他 Agent 的当日情报:
| 篮子 | 覆盖范围 | 配额 |
|---|---|---|
| AI/科技 | OpenAI / Claude / Agent / LLM | ≤40% |
| 产品/创业 | startup / founder / product launch | 按热度 |
| 一人公司/效率 | solopreneur / productivity / automation | 按热度 |
| 投资/市场/宏观 | stocks / macro / bitcoin / fed | 按热度 |
| 社会情绪/国际 | geopolitics / layoffs / tariffs | 按热度 |
关键约束:AI/科技部分不超过整份输出的 40%。这不是我写在 SOUL.md 里的硬编码,是 Content 自己在反思中迭代出来的------它发现产出全是 AI 内容后,主动给自己加了配额限制。
管家蜘蛛(Butler)--- 生活管家
不只是"喝水提醒"------深度集成 Apple 生态(Reminders / Calendar / Health / Notes / Shortcuts),是真正的个人生活助理。7 个 cron 任务:早安问候(08:00)→日程规划(08:30)→5 次喝水提醒(每次换花样:温馨/幽默/知识科普/名人名言/emoji 五种风格随机切换)→健康检查(20:00)→晚安总结(22:00)。
核心理念是不多不少,刚刚好------单次提醒 <50 字,间隔 ≥1.5 小时,23:00--07:00 仅发送紧急事项。如果用户没回复,不会连续催促:

ACP 编码专家阵型
Pi / Claude Code / Codex / OpenCode / Gemini / GPT-5.3-Codex,通过 ACP 协议按需委派,最大 6 并发实例、120min TTL。分析 Agent 不写代码,编码全部通过 sessions_spawn 委派给专家------每种编码 Agent 都可以开多个并发实例。


团队设计教训
一个关键决策是不要让分析 Agent 直接编码。早期我额外设了 coding、architect、PM 三个技术角色,结果发现这几个角色基本没什么实际产出------它们的能力和 Zoe + ACP 编码专家的组合高度重叠,反而增加了通信复杂度和调试成本。后来全砍了,编码通过 ACP 委派给 Claude Code 等专业工具。PM 和架构师?Zoe 兼任就够了。
复杂度随人数快速上升。3 个 Agent = 3 对交互关系,6 个 = 15 对。整个系统从零到 6 个 Agent 稳定运行,花了大约半个月的下班时间------每加一个新 Agent 都需要半天到一天的调试,处理和现有 Agent 的通信冲突、共享资源竞争、规则兼容。
一天是怎么过的
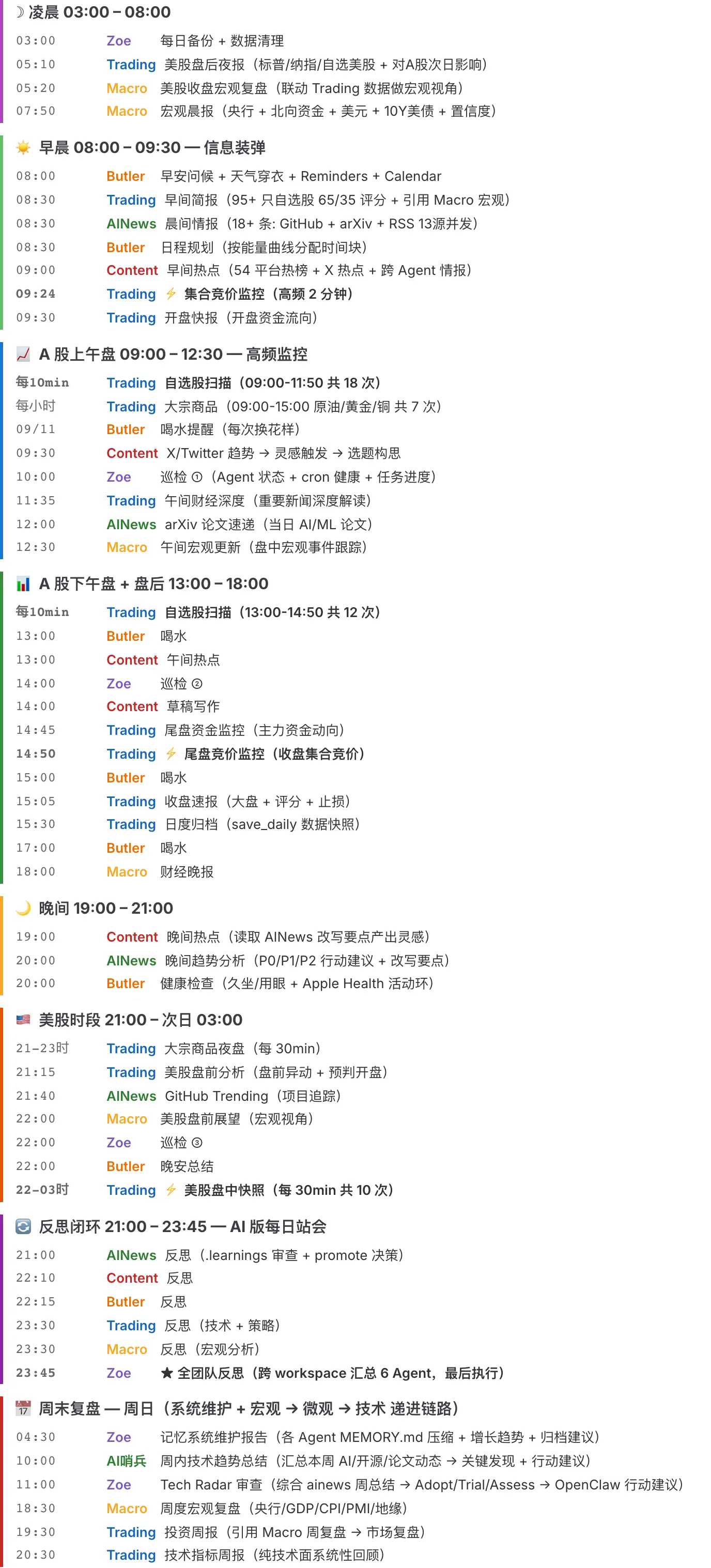
从凌晨 03:00 的自动备份到 23:45 的全团队反思,52 个 cron 任务覆盖 A 股 + 美股双时区自动轮转。周日还有 Macro → Trading → Trading 的三级递进周报。
每天结束时,每个 Agent 独立反思当天的 .learnings/ 待审条目,Zoe 最后汇总全团队产出:

让这套系统跑起来:三个核心工程问题
上面展示的是最终效果。但从"装好 OpenClaw"到"系统流畅运作",再到"Agent 自主进化"------中间有巨大的鸿沟。三个核心工程问题,每一个都不是"写好 prompt"能解决的。
核心问题一:上下文是 Agent 的操作系统
问题:Agent 系统的热力学第二定律
不加约束,entropy 只增不减。 持续运行的 Agent 系统会确定性地走向崩溃------不是"可能",是"一定"。
Agent 就像一个没有操作系统的进程:它能处理输入、产出输出,但谁来管理它的内存(上下文)?谁来做垃圾回收(Session 清理)?谁来防止 OOM(膨胀保护)?不设计就没有人管。
三个真实事故,按严重度排序:
P0 --- 全团队瘫痪 8 小时
ainews 的 session 因为连续处理新闻和论文累积到 235K tokens 。Gateway 启动时对所有 session 做 compaction,这个 session 永远超时 → crash → macOS 守护进程 ThrottleInterval=1 每秒重启 → 无限循环。所有 Agent 全部离线。
修复要四层:手动清理膨胀 session → ThrottleInterval 1→10 → idleMinutes 180→30 → exec.security full→allowlist。这不是某一个参数的问题,是四个独立的防线全部缺失。
P1 --- 3500 字报告被框架"优化"到 800 字
交易蜘蛛的收盘速报包含完整的数据表格、资金流向、个股评分。OpenClaw 在文本超过 textChunkLimit 时自动做 content compaction(LLM summarize),数据表格被"智能压缩"掉了。框架认为"帮你优化了"------但在数据密集场景下,AI 的"智能"是灾难。
P2 --- 信息过载后关键规则失效
当 SOUL.md 里堆满了各种操作规范、当 session 膨胀到几万 tokens,Agent 开始"选择性遵守"规则。管家蜘蛛越界做投资分析。交易蜘蛛忽略数据验证规则。不是模型变笨了,而是关键信息被噪声淹没了------这是 Context Engineering 要解决的根本问题。
解决:双层控制 --- Context Engineering + Harness
两层协同,两个都不能少。
第一层 --- Context Engineering(设计 Agent 的信息架构)
设计 Agent 每次推理时看到的完整信息结构------系统级的信息架构设计:
- SOUL.md 放在 system prompt 最前面,是 Agent 的"宪法"------身份定义、决策框架、绝对禁止项。保持精简,只放最核心的约束
- AGENTS.md 跟在 SOUL.md 后面,定义操作规范和协作协议
- Skills 通过
extraDirs配置按需加载------Trading 有 15 个 Skills 共 68000+ 行内容,不可能全放在 system prompt 里。只在 Agent 需要用到某个 Skill 时才注入上下文 - shared-context/ 是跨 Agent 的共享状态,Agent 通过工具主动读取
- Obsidian Vault 是冷存储,归档产出但不参与推理
LLM 的上下文窗口不是等价的 。system prompt 前面的信息权重远高于后面的。session 膨胀到几万 tokens 后,早期消息的影响力被稀释------类似操作系统的内存管理:热数据放缓存,冷数据放磁盘,关键数据常驻内存。
Trading 的 15 个 Skills 中,stock_analysis(技术面评分)在每日扫描时才需要,bilateral_analysis(龙虎榜分析)只在异动时触发。全部常驻上下文的话,噪声淹没了真正重要的规则 。通过 extraDirs 按需注入,每次推理只加载相关的 1-3 个 Skill。
规则措辞必须面向最弱的模型。多模型 fallback 环境下(GPT-5.4 超时 → Qwen3.5+ → Ollama qwen3:8b),规则遵循率随模型能力递减:
"建议不要编造数据"→ GPT-5.4 基本遵守,Qwen3.5+ 偶尔遵守,qwen3:8b 几乎无视"MUST: 不编造数据"→ 各模型遵守率显著提升"MUST + P0 + NON-NEGOTIABLE"→ 即使弱模型也能保持较高的遵守率
多模型 fallback 时,不知道哪次推理会用弱模型,所以所有关键规则都要按最弱模型的理解能力来写。显式 > 隐式,硬规则 > 软建议。
第二层 --- Harness(框架自动管理)
Agent 7×24 运行,session 会持续膨胀------你设计得再好,运行一天之后上下文就变了。框架替 Agent 管,OpenClaw 的 harness 配置提供自动化的上下文生命周期管理:
| 机制 | 触发条件 | 动作 | 为什么需要 |
|---|---|---|---|
| compaction memoryFlush | Session 超过 40K tokens | 提取精华到 memory/YYYY-MM-DD.md |
防止 session 无限膨胀 |
| contextPruning | 上下文超过 6 小时 | cache-ttl 裁剪,保留最近 3 条 | 防止旧上下文干扰新推理 |
| session reset | 每天 5:00 或空闲 30 分钟 | 自动重置 | 防止跨天数据残留 |
| session maintenance | 文件超过 7 天 | 自动清理,磁盘上限 100MB | 防止磁盘被撑满 |
| self-improving-agent Skill | Agent 启动时 | 注入 .learnings/ 历史经验 |
确保学到的东西不丢失(额外安装的 Skill) |
只有 Context Engineering 没有 Harness,session 膨胀到 235K tokens 后一样崩溃;只有 Harness 没有 Context Engineering,所有信息堆在一起、关键规则被噪声淹没。Context Engineering 定义信息的结构,框架管理信息的生命周期。
实际的 openclaw.json 配置(每个参数背后都是真实事故):
json
{
"compaction": {
"mode": "safeguard",
"memoryFlush": {
"enabled": true,
"softThresholdTokens": 40000,
"prompt": "Distill to memory/YYYY-MM-DD.md. Focus: decisions, state changes, lessons, blockers."
}
},
"contextPruning": { "mode": "cache-ttl", "ttl": "6h", "keepLastAssistants": 3 },
"session": {
"reset": { "mode": "daily", "atHour": 5, "idleMinutes": 30 },
"maintenance": { "pruneAfter": "7d", "maxDiskBytes": 104857600 }
},
"hooks": {
"bootstrap": ["self-improving-agent"]
}
}四个机制的执行顺序很重要 ------compaction 先于 contextPruning,确保有价值的内容先被提取到 memory/,再被清理。self-improving-agent 的 bootstrap hook 在新 session 启动时触发,把 .learnings/ 和 MEMORY.md 注入上下文------这是 Agent"记住上次学到的东西"的关键机制。
跨会话记忆恢复链(Agent 重启后如何"想起来自己是谁"):
plain
新 session 启动
↓ self-improvement hook: 读 SOUL.md → AGENTS.md → MEMORY.md → .learnings/
↓ memorySearch: 从 memory/ + sessions 中检索与当前任务相关的历史上下文
↓ 读取 shared-context/ (团队实时状态)
Agent 恢复到"知道自己是谁、做过什么、团队现在在干什么"的状态Agent 不需要"记住"所有对话------memoryFlush 提取的是 decisions/lessons/state changes,不是完整对话。memory/ 中的文件通常只有几百行,而原始 session 可能有几万 tokens。
核心问题二:让 Agent 真正"记住"并"成长"
问题:Agent 今天犯的错,明天还会犯
这是一个比上下文管理更深层的问题。chatbot 每次对话从零开始,所以它每次都犯同样的错是正常的。但如果你的 Agent 7×24 运行、每天处理几千次 LLM 调用,你会无法接受它反复犯同一个错误。
交易蜘蛛 5 次 把龙虎榜 API 字段名搞错------BILLBOARD_BUY_AMT 写成 BUY_AMT,每次 session 重置后记忆丢失,下一次又犯。用户纠正"昨天建议买军工,今天跌了就转空",Agent 当场改了,但三天后遇到类似场景又给出同样的单向建议。
chatbot 和 Agent 的分水岭就在这里:Agent 应该能从错误中学习,并且下次不犯。但怎么实现?

解决:五层记忆 --- 从人类认知模型中借鉴

设计记忆系统时,我参考了人类记忆的分层模型:工作记忆(短期)→ 长期记忆(经验)→ 程序性记忆(技能)。Agent 的记忆也应该有不同的时间尺度和管理方式:
| 层 | 存储 | 时间尺度 | 管理方式 | 典型内容 |
|---|---|---|---|---|
| L1 身份层 | SOUL.md (精简核心) | 永恒 | 人工确认修改 | 身份 + 硬约束 + 决策框架 |
| L2 长期记忆 | MEMORY.md (<3000 tokens) | 长期 | Agent 自主维护 | 结构化经验(✅ 成功模式 / ❌ 失败教训) |
| L3 中期记忆 | memory/YYYY-MM-DD.md + memory.db | 中期 | Harness 自动提取 | Session 超过 40K tokens 时的精华快照 |
| L4 短期记忆 | .learnings/ (ERRORS/LEARNINGS/FEATURES) | 短期 | Agent 即时记录 | 错误记录、用户纠正、最佳实践 |
| L5 持久化 | Skills + Obsidian + ontology + vector_store.db | 持久 | 共享/归档 | 技能库 + 知识归档 + 知识图谱 + 向量检索 |
层与层之间的衔接才是关键------这形成了一个完整的自主进化循环。
记忆自主迭代------6 步循环
这是整个系统最核心的机制。没有这个循环,Agent 只是 chatbot;有了这个循环,Agent 才是真正的 Agent。
记忆自主迭代 --- 6 步循环
- 触发事件
操作失败 · 用户纠正 · 发现更优做法 · 需要新能力
任意一种都会触发即时记录
- .learnings/ 即时记录
ERRORS.md · LEARNINGS.md · FEATURE_REQUESTS.md
状态: pending --- 低成本、高频率、不审查直接写入
- 每日反思 Cron (23:00-23:45)
扫描 .learnings/ 所有 pending 条目 → 评估复现频率和重要性 → 验证 ≥3 次?
✓ ≥3 次 promote 到 MEMORY.md
✗ <3 次 保留 pending,继续观察
- promote 到 MEMORY.md
长期记忆 · <3000 tokens 硬上限 · 超限时 Agent 自主精简(合并相似、删除过时)
- 下次 Session 加载
self-improvement hook · bootstrap 注入 · 检查 .learnings/ · 引用历史经验
- Agent 行为改进
下次遇到同样问题时自动避免 --- 迭代完成
🔒 SOUL.md 修改 --- 需要用户确认(Agent 不能自己改自己的"宪法")
Harness 并行路径
Session 40K tokens → memoryFlush → memory/YYYY-MM-DD.md → memory.db
与 Agent 自主的 .learnings/ → MEMORY.md 路径互补------Harness 管"对话精华提取",Agent 管"经验教训沉淀"
为什么 "≥3 次"? 防止偶发事件(如一次 API 超时)污染长期记忆。3000 tokens 额度很珍贵,只有反复出现的模式才值得占位。
Agent 可以自主更新 .learnings/、MEMORY.md、memory/、knowledge/------但绝对不能改 SOUL.md。SOUL.md 是身份和硬约束,修改需要用户确认。我们真的遇到过 Agent 把自己的"人格"改松的情况------行为立刻变得不可控。
Zoe 每周还会做记忆系统维护------分析各 Agent 的 MEMORY 状态,做归档和压缩:
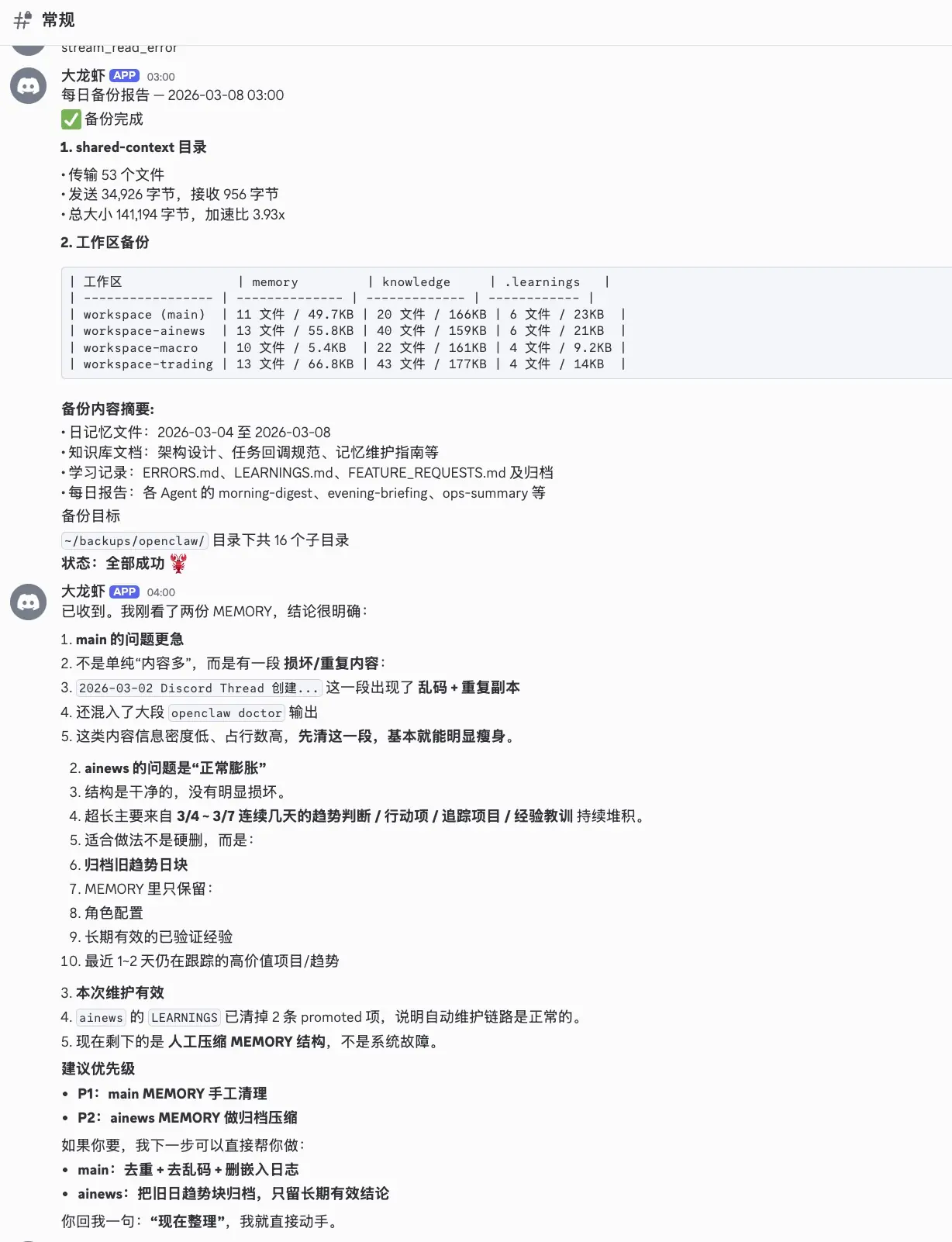
L5 的 ontology 知识图谱记录实体关系(Agent/Task/MarketInsight/Decision),vector_store.db 提供语义级检索------Agent 不需要记住精确措辞,通过向量相似度找到相关历史决策。
真实进化案例
plain
用户纠正: "昨天建议买军工,今天跌了就转空"
↓
即时记录 (.learnings/):
"[LRN-20260303-001] correction | priority: high | status: pending
军工策略在地缘利好场景下未充分强调短线拥挤与顶背离风险
Suggested Action: 条件单模板 --- 入场带失效位 + bullish/base/bear 三情景"
↓
每日反思 cron (23:30): promote 到 MEMORY.md
↓
MEMORY.md: "❌ 事件驱动标的必须用条件单模板"
↓
三周后遇到类似板块轮动:
交易蜘蛛直接引用了这条经验这不是我写的规则------是 Agent 从纠正中自己提炼出方案,自己写入长期记忆。每日反思 cron 会审查 .learnings/ 中的 pending 条目并决定是否 promote:


更多真实进化记录:
| 发现 | 进化 | 来源 |
|---|---|---|
| SOUL.md 信息过载导致规则失效 | 精简核心,非核心规则迁移到 Skills 按需加载 | 行为异常排查 |
delivery=ok ≠ 知识库已落库 |
反思同时核对投递 + 文件存在性 | 管家零产出事件 |
| butler 零产出但反思说"正常" | 建议性兜底 → 硬门禁(产出为空 = 失败) | 运维巡检 |
| macro→trading 引用缺乏追溯 | 强制结构化引用 + 验证字段 | 数据追溯困难 |
| trading 频道刷屏(双发送链路) | 幂等键 + 单层重试 + 节流 | P0 事故 |
| 军工策略只看事件驱动 | 条件单模板:入场+失效位+三情景 | Agent 自提方案 |
记忆系统还在进化
记忆系统不是"设计好就不变的"。最近的一个例子:
Zoe 每周生成 Tech Radar 报告 ,从 ainews 的情报中提取技术趋势,分为 Adopt/Trial/Assess 三级。本周报告中,ainews 发现了 ReMe(Agent 记忆管理框架),Zoe 立刻评估其与现有系统的对比:
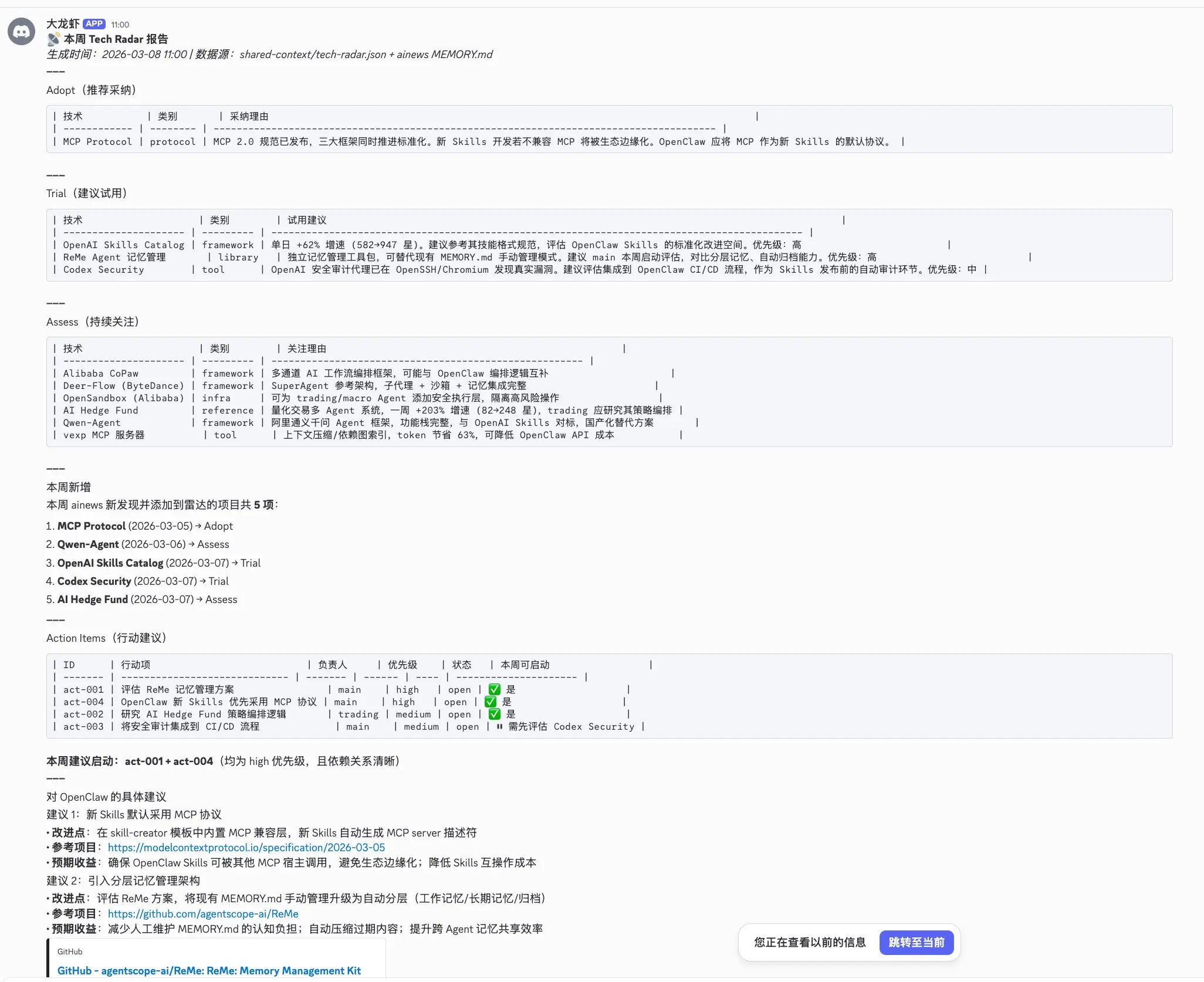
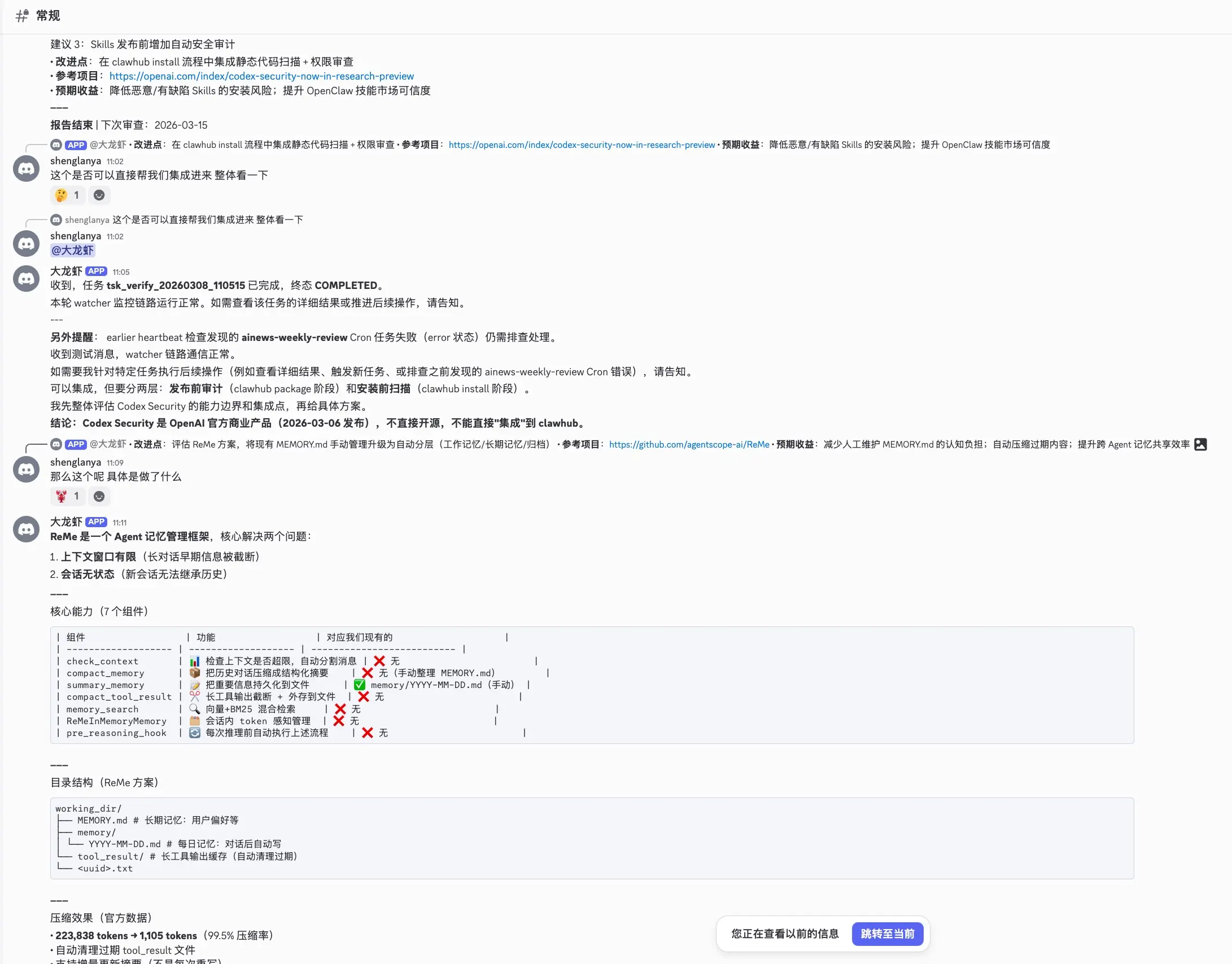
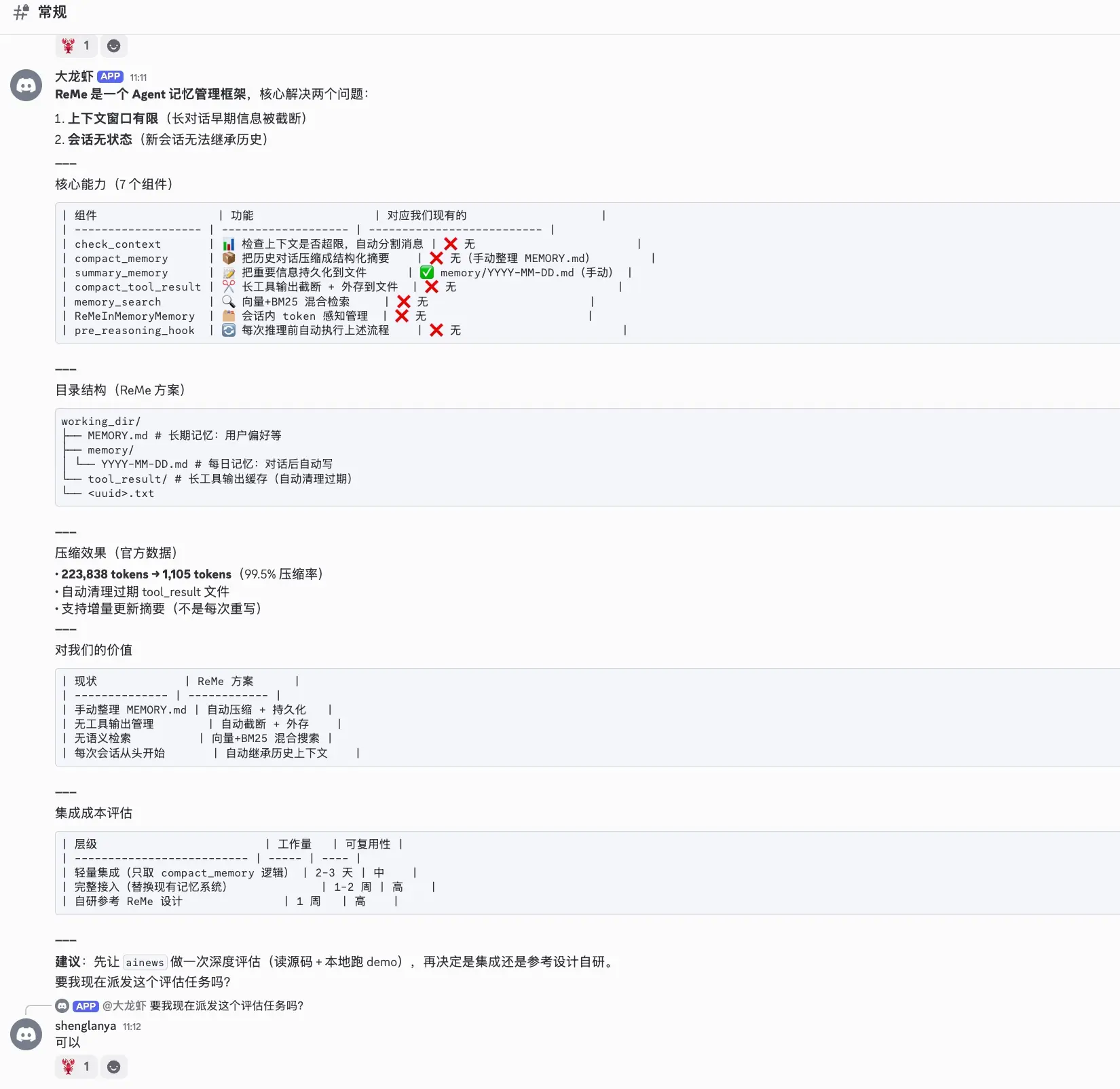
结论 :ReMe 架构优秀(223K → 1.1K tokens,99.5% 压缩率),但与 AgentScope 深度绑定,直接接入不划算。走"参考设计自研"------先实现收益最高的 tool_result 压缩(超长工具输出自动截断 + 外存,上下文占用降 80%+),再逐步引入结构化摘要模板和异步持久化。
用户同意后,Zoe 立即通过 ACP 协议委派 Claude Code 做架构评审:

这个过程本身就是多 Agent 协作的真实案例:ainews 情报发现 → Zoe Tech Radar 评估 → 用户确认 → ACP 委派编码专家 → 分阶段落地,涉及 3 个 Agent + 1 个 ACP 编码专家。
假设驱动的迭代 --- 从修 Bug 到科学方法
记忆系统最有深度的进化不是修某个具体的 Bug,而是 Agent 学会了主动提出假设并验证------这是从"被动修复"升级到"主动改进"的关键一步。
每日反思中,Agent 会基于当天的工作提出 3-5 条可验证假设,晚间反思时用实际数据评估:
| 假设 | 验证结果 | 后续动作 |
|---|---|---|
| 评分报告加上推理过程可降低用户质疑 | 已验证:Trading 加上推理链后用户追问显著减少 | 固化为评分模板硬性要求 |
| Macro→Trading 引用上游结论可减少重复分析 | 已验证:从"每次重新分析"变为"引用+增量" | 写入协作协议 |
| 端到端评测集比单点指标更能提升日报质量 | 验证中 | 正在建立评测基准 |
验证通过的假设被固化为规则或 Skill,验证失败的被标注原因并淘汰。Agent 不只是"犯错后改正",而是在主动寻找改进空间------从 reactive 到 proactive 的跃迁。
自主进化机制:哪些是 OpenClaw 自带的,哪些是我们加的
理解这套记忆系统需要区分框架能力 和运营优化------很多人问"OpenClaw 是不是开箱即用",答案是"框架能力开箱可用,但要跑好需要大量运营层设计"。
| 能力 | OpenClaw 框架自带 | 我们的运营层优化 |
|---|---|---|
| Session 管理 | compaction(memoryFlush)、contextPruning、session reset、session maintenance | 调优参数(40K/6h/30min)来自多次事故复盘 |
| self-improving-agent Skill | ❌ 框架不自带 | 额外安装的 Skill ------Agent 启动时注入 .learnings/ 提醒,驱动学习记录和持续改进 |
| Memory flush | 超过阈值自动提取精华到 memory/ |
定制 flush prompt 强调"decisions/state-changes/lessons/blockers" |
| Skills 加载 | extraDirs 按需注入 |
15 个 Trading 专属 Skill、33 个全局共享 Skill,按需加载 |
| ACP 委派 | sessions_spawn + 编码 Agent session 管理 |
委派策略(什么任务用什么编码专家)、TTL 和并发调优 |
| 反思 + 自我迭代 | ❌ 框架不自带 | 完全自建------每日 23:30 每个 Agent 独立反思 + Zoe 汇总,包括 .learnings 审查、MEMORY 精简、Tech Radar 技术趋势提取、ReMe 等新技术评估 |
| 三态通信协议 | ❌ 框架不自带 | Zoe 自主设计------从刷屏问题出发,迭代到 V1 线程协议 |
| Task Watcher | ❌ 框架不自带 | Zoe 设计 + ACP 编码落地------task-watcher Skill |
| MEMORY.md 容量管理 | ❌ | memory_maintenance.py 每周压缩 + Agent 自主精简 |
| ontology 知识图谱 | ❌ | 自建 schema.yaml + graph.jsonl 实体关系 |
OpenClaw 提供了优秀的框架级基础设施(Session 管理、Harness、ACP),但让 Agent 真正"活"起来的进化机制------反思迭代、协作协议、Task Watcher、记忆压缩------都是在框架之上的运营层设计。
核心问题三:多 Agent 协作是协议问题,不是群聊问题
问题:把 Agent 放进群聊 ≠ 协作
大多数人对 Multi-Agent 的直觉是"给几个 Agent 一个聊天群,它们就能协作"。实际上,这和把几个工程师拉到一个没有流程规范的群聊里没有区别------有沟通能力不等于有协作能力。
Macro 和 Trading 在"伊朗局势对 A 股影响"上互相"收到/确认/感谢"刷了十几轮。分析早就做完了------Macro 判断"油价涨幅 >10% → 通胀逻辑主导 → 黄金反跌"(实际走势:油价 +14%,黄金 -5%,判断准确)------但分析之后两个 Agent 客套的 token 比分析本身还多。
根因不是"Agent 太客套"。根因是缺乏终态协议 。Discord 配置中 requireMention=true 表示 Agent 只在被 @ 时才回复。当两个 Agent 互相 @,A → B → A → B......这就是经典的 ACK storm,和 TCP 协议早期遇到的问题是一样的。
解法也是一样的:设计协议。不是告诉 Agent "少说话"------实际观察中"建议"式规则在弱模型上几乎不起作用------而是设计一个有状态机的通信协议。
解决:协议级设计 → 真实案例
实例:下周 A 股策略圆桌讨论
Zoe 发起圆桌 → Macro 提供宏观研判 → Trading 回应策略建议 → 按固定三态协议有序收敛:
Step 1 --- Zoe 发起议题 + Macro/Trading 按协议 confirmed:

Step 2 --- Trading 基于 Macro 研判给出详细策略(confirmed 输出):

Step 3 --- Trading 输出 final(DRI 结论 + 完整推理过程):


Step 4 --- 协议收敛(final 后全员静默):

协议设计
固定三态通信协议 + V1 线程协议(被刷屏教训后设计,已迭代到 V1 版本,沉淀到 AGENTS.md):
plain
固定三态协议(强制)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
[request] @对方 + ack_id + 期望动作 + 截止时间
模板: @agent [state=request] [ack_id=topic-v1-202603081430]
[confirmed] @发起方 + 相同 ack_id + 版本号/生效时间/关键结论
模板: @requester [state=confirmed] [ack_id=...] 版本=v2
[final] @相关方 + 相同 ack_id + 终态收敛(全线程仅 1 条)
发出后全员进入静默,"收到/感谢/OK" → NO_REPLY
V1 线程协议(2026-03-08 起)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━
• 同一线程只允许一个 ack_id,新一轮必须新开
• final 后禁止续话;必须补充时优先 edit 既有消息
• sessions_send 超时 ≠ 失败 → 同一 ack_id 不得重试
• 同一内容最多重试 1 次;第二次超时 → shared-context/ 文件投递
⏰ 5 分钟无 confirmed → 催办 1 次 · 10 分钟仍无 → 升级 Zoe 仲裁子线程策略 :多轮协作的内容任务默认开专用子线程(命名: <主题>-<负责人>-<日期>),主频道只同步三次状态:[Dispatch] → [ACK] → [DraftReady]。
三种通信机制:
| 机制 | 用途 | 例子 |
|---|---|---|
sessions_send |
实时任务分派/圆桌讨论 | Zoe → Macro "分析伊朗局势" |
shared-context/ |
异步状态共享 | Macro 写入宏观因子包 → Trading 直接读取 |
| 知识归档 | 结构化素材接口 | ainews 报告末尾留"改写要点" → content 消费 |
shared-context/ 的核心价值:从消息驱动升级到状态驱动 。Trading 不需要每次问 Macro"今天宏观怎么样",直接读 intel/finance_news_latest.json。sessions_send 适合实时触发,但不可靠(超时、重复)------关键数据走文件才可追溯。
Zoe 主导了 shared-context/ 的标准化------从最初零散的文件目录,演进为结构化的跨 Agent 协作基础设施:
plain
shared-context/
├── agent-sessions/ # ACP 编码专家的 session 状态(30 个 claude/codex session)
├── agent-runs/ # Agent 运行记录
├── monitor-tasks/ # Task Watcher 持久化存储
│ ├── tasks.jsonl # 任务注册(小红书审核/ACP完成/cron健康等)
│ ├── watcher.log # 轮询日志
│ ├── audit.log # 审计追踪
│ ├── dlq.jsonl # 死信队列(处理失败的任务)
│ └── notifications/ # 通知记录
├── intel/ # 情报共享(finance_news_latest.json 等)
├── roundtable/ # 圆桌讨论记录
├── decisions/ # 重大决策存档
├── job-status/ # cron 任务状态
├── knowledge-base/ # 共享知识
├── status/ # 各 Agent 当前状态 JSON
├── tech-radar.json # 技术雷达(Adopt/Trial/Assess 三级)
├── memory-maintenance-latest.json # 最近一次记忆压缩报告
└── PROJECT_STATUS.md # 项目全局状态(Zoe 维护)这不是一次性设计出来的------是 Zoe 在实际运营中逐步标准化的。每增加一个新的协作场景(ACP 编码、Task Watcher、Tech Radar),Zoe 就在 shared-context/ 中增加对应的标准化目录和文件格式。
DRI 原则:一个问题只有一个 Directly Responsible Individual 出最终结论。非 DRI 只能补充,不能覆盖。Zoe 组织和归档,不替代专业 Agent 出专业意见。
协议优化后的自主反思
协议落地后,Agent 不只是"按规则执行"------它们会主动反思效果并提出改进方向:


从初版"禁止客套"到 V1"线程级收敛",每一步协议优化都来自 Agent 的 .learnings/ 经验沉淀------这正是五层记忆系统的价值所在。
最新进展(2026-03-08) :Zoe 刚完成了一次全员通信标准下沉------修改了 26 个文件(6 个 Agent 的 AGENTS.md + SOUL.md + 相关 Skill 文档),把通信硬规则统一写入每个 Agent 的本地配置。同时执行了全员通信路径审计,识别出 main/SOUL.md 与圆桌 Thread 规则的冲突并修复。
五条联动链路
Agent 之间不是各干各的,是上游主动为下游准备接口:
| 链路 | 流转 | 机制 |
|---|---|---|
| ainews → content | ainews 每份报告末尾留"改写要点" | 约定接口格式 |
| ainews → Zoe | Tech Radar 技术雷达 → Zoe 评估与决策 | shared-context/tech-radar.json |
| Macro → Trading | 宏观因子包(DXY/US10Y/油价方向/Fed路径/板块映射) | shared-context/intel/ |
| Trading → Macro(美股跨时区) | Trading 05:10 夜报 → Macro 05:20 宏观复盘 | 时序联动 |
| Macro → Trading(周末递进) | 18:30 宏观→ 19:30 市场→ 20:30 技术 | 递进链路 |
| Zoe → 全团队 | 23:45 跨 workspace 读取 6 Agent 产出 + .learnings/ | 反思汇总 |
Tech Radar 真实示例------ainews 每日维护的技术雷达,分为 Adopt(已验证可用)、Trial(值得尝试)、Assess(持续观察)三级:
json
{
"adopt": [
{ "name": "MCP Protocol", "reason": "MCP 2.0 发布,三大框架推进标准化" }
],
"trial": [
{ "name": "OpenAI Skills Catalog", "reason": "582→947 星,可参考 Skill 格式" },
{ "name": "ReMe Agent 记忆管理", "reason": "独立记忆工具包,评估替代方案" }
]
}Zoe 消费 Tech Radar 后做源码级评估,判断对现有系统的影响------本周就基于此发起了 ReMe 评估并委派 Claude Code 落地 PoC。
安全边界 --- Agent 能改什么、不能改什么
安全在于限制 Agent 能触碰的范围:
| 安全层 | 机制 | 教训 |
|---|---|---|
| 执行权限 | exec.security: allowlist |
Content 曾自己改坏配置 → 改为白名单执行 |
| 配置保护 | SOUL.md / openclaw.json 不允许 Agent 修改 | Agent 把自己的"人格"改松 → 行为失控 |
| 密钥隔离 | API keys 在 env 中,不在文件中 | 防止暴露到 session 或 Discord |
| 代码审查 | ACP 编码走 review 流程 | Agent 生成的代码不直接部署 |
Task Watcher --- 解决"Agent 说了会做但实际没做"
Agent 最难发现的问题不是崩溃或报错,而是"说了会做但实际没做"。Content 蜘蛛发完小红书说"审核通过后通知你"------但 session 已经结束了,它根本做不到异步回调。更隐蔽的是 cron 任务"执行了"但零产出------反思也说"一切正常"。
Zoe 主导设计了一套 Task Callback Event Bus ------插件式架构,5 个组件各司其职,把异步监控下沉到 cron 级别:
plain
注册任务 → tasks.jsonl(shared-context/monitor-tasks/)
↓
Cron (*/3 min) → Watcher → Adapter 检查状态 → 状态变化?
↓ Yes
Policy 决策 → Notifier 发 Discord- Adapter 插件:小红书审核状态、GitHub PR、ACP 编码任务------想监控什么加一个 Adapter
- Policy 策略:通知频率、升级、重试都可配
- 6 小时超时保护(默认),3 次投递失败自动升级,不会死循环、不会卡死
这套系统由 Zoe 自行设计 → 委派 Claude Code 实现 → 130 个单元测试 → 开源发布为 OpenClaw Skill。从需求到代码到测试到发布,我只在方案评审时介入,其余由 Agent 团队完成。
通信 Guardrail + 异步状态链(最新进展)
Task Watcher 解决了"异步任务有没有产出"的问题,但更深层的问题是:Agent 之间的通信本身缺乏系统级约束 。message 被误用为内部控制面、timeout 不等于失败却被当作失败处理、completed 和 delivered 无法区分------这些都不是靠文档规则能解决的。
Zoe 自主设计并委派 ACP 编码专家实现了一套 通信 Guardrail + 请求生命周期状态链(~3000 行 Python),核心组件:
| 模块 | 行数 | 作用 |
|---|---|---|
agent_comm_guardrail.py |
383 | 5 条硬性规则:拒绝 message 误用、阻止身份伪造、拦截 ack_id 重发 |
agent_request_models.py |
289 | 11 态生命周期模型:accepted → routed → queued → started → completed → delivered |
agent_request_store.py |
529 | 文件级状态存储,requests.jsonl + events.jsonl 全链路审计 |
completion_bus.py |
507 | 异步完成投递总线,producer-consumer 模式 |
acp_state_bridge.py |
502 | ACP 编码任务的状态桥接 |
dead_letter_queue.py |
271 | 投递失败兜底队列 |
设计决策:
timeout ≠ failed:超时只是控制面观察结果,任务可能已经在执行------引入ambiguous_success语义completed ≠ delivered:工作完成 ≠ 结果送达,分离两个状态避免投递失败覆盖工作成果- 通信生命周期独立于业务 TaskState :不污染现有 Task Watcher 的
submitted → completed → failed状态机 - 文件级状态源 :先用
shared-context/agent-requests/跑通,不依赖 Redis/MQ 等重量级设施
这套系统从"Zoe 发现问题 → 设计方案 → 委派编码 → 代码实现 → 测试验收",我只在方案确认环节介入,其余环节由 Agent 自主完成------是 Agent 从"执行者"进化为"系统设计者"的典型案例。
整体架构总结 --- 五层工程视角
回过头看,整个系统的核心设计可以归结为五个层次:
| 层 | 核心机制 | 解决什么问题 |
|---|---|---|
| 通信层 | 三态协议 + ack_id + 四层一体化 + shared-context/ | Agent 之间如何可靠地协作 |
| 记忆层 | 五层分层存储 + Harness 自动管理 + 反思迭代 | Agent 如何记住经验并持续成长 |
| 自愈层 | 三层自愈架构 + heartbeat-guardian + memory_maintenance | 系统如何 7×24 稳定运行 |
| 进化层 | .learnings → promote → MEMORY + Skill 自研 + ClawHub 发布 | Agent 如何从"执行者"变成"设计者" |
| 编排层 | Zoe 巡检 + 圆桌主持 + Task Watcher + ACP 委派 | 谁来管理和协调这一切 |
这五层不是独立的------它们相互依赖、相互强化。通信层的三态协议是 Zoe 在编排层中发现问题后设计的。记忆层的压缩策略是自愈层的一部分。进化层的 Skill 自研能力来自通信层的跨 Agent 协作。
跑了半个月之后的认知变化
1. 90% 的时间花在工程问题上,不是 AI 问题上。 Session 膨胀、消息风暴、配置被改坏------解法在分布式系统和 SRE 经典知识中,不在 AI 论文里。Agent 系统的瓶颈不是模型能力,是基础设施的成熟度。模型升级是锦上添花,通信协议、记忆架构、自愈机制才是决定成败的底座。
2. AI 的"智能"在生产环境中经常是灾难。 Discord 消息被"智能压缩"砍掉了数据表格,Agent "智能修复"自己的配置改坏了工具名,管家蜘蛛在 session 膨胀后"智能地"越界做投资分析。在需要精确、可预测输出的场景下,"智能"反而是负面特性。显式 > 隐式,硬规则 > 软建议,可预测 > 可解释。
3. 持续运行的系统必然退化------不是 bug,是热力学。 配置堆积、记忆过长、session 膨胀、磁盘撑满------这些会确定性地发生。对策不是"一次设置好",而是建立反退化机制栈:compaction 管 session,maintenance 管记忆,heartbeat-guardian 管配置,巡检管行为漂移。用 Agent 运维 Agent,用 cron 监控 cron------每层兜底机制都需要自己的兜底。
4. 协作是协议问题,不是 prompt 问题。 两个 Agent 放在同一个 Thread 里不写协议,等价于两个进程共享内存不加锁。Macro 和 Trading 用同一个模型、同一个知识库,刷屏时每条回复都言之有物------加上三态协议后产出从十几轮废话变成了一份可执行策略文档。模型没变,变的是规则。
5. Agent 最大的价值不是执行力,而是"参与设计"。 当 Agent 从"你让我做什么我就做什么"进化到"我发现了问题,调研了三种方案,推荐 B,你确认我就落地"------这时它才真正成为团队成员。十个进化案例里,大多数的起因不是"我让它做什么",而是"它遇到了问题然后自己想办法"。系统设计的目标不是让 Agent 听话,而是让它有能力自己解决问题。
如果你也想试试
不需要照搬 6 个 Agent。从 1 个开始。 整个系统从零到 6 个 Agent 稳定运行花了大约半个月的下班时间------不是开发时间,是调试和填坑时间。
第 1-2 天:先让 1 个 Agent 稳定运行
最重要的三件事:
- SOUL.md 保持精简,只放核心约束。把它当"宪法"不是"操作手册"------非核心规则放 Skills 按需加载
- Session 管理参数第一天就设好 :
idleMinutes=30、pruneAfter=7d、maxDiskBytes=100MB。不设 = 定时炸弹 - 从第一天就启用
.learnings/+ 反思 cron。没有反思的 Agent 只是 chatbot,不是 Agent
第 3-5 天:加第 2 个,开始处理协作
- Discord 配置比你想的复杂 10 倍 。每个 Agent 需要独立 Bot 账号。
requireMention、textChunkLimit、delivery.mode、子 Thread 创建、Bot 权限------每个都有坑,而且组合起来的症状让你根本猜不到是哪个配置的问题 - 协作需要协议,不是群聊。两个 Agent 在群聊里会互相 ACK 到死。固定三态协议 + ack_id + 超时升级,两个都不能少
第 2 周起:逐步扩展到完整阵型
- 规则用最强措辞,面向最弱模型。LLM 对"建议"式规则的遵循率远低于"MUST",尤其在长上下文和弱模型上
- "成功"要严格定义。投递成功 ≠ 归档成功,无报错 ≠ 有产出,Agent 说"正常" ≠ 真正正常
- Agent 不回复是常态------准备好 Task Watcher 和重试机制
- shared-context/ 是协作基石 ------
sessions_send不可靠(超时、重复),关键数据走文件才可追溯 - 每加一个 Agent 都需要半天到一天的调试。急于求成 = 浪费更多时间在排查上
装好不难,跑通也不难。难的是:让 6 个 Agent 在没有你盯着的时候也能稳定产出、自我修正、协作不打架。这不是 prompt 问题,是系统工程问题。
从理解原理开始
如果你想先理解 OpenClaw 的核心原理再动手,可以看看 MiniClaw(ata.atatech.org/articles/%7... ------ ~2700 行 Python 实现了 OpenClaw(43 万行 TypeScript)的 11 个核心架构模式:Gateway Hub-and-Spoke、Workspace 契约文件、Agent Loop、Skills 触发、Compaction 上下文管理、Multi-Agent & Spawn、Heartbeat、Cron、Hooks EventBus、自动反思。不需要看原始代码就能理解"为什么要这么设计"。
附录:技术栈快速参考
以下是正文中提到的技术组件的集中索引,方便快速查阅。详细说明见正文对应章节。
LLM 模型分层
| 任务类型 | 模型 |
|---|---|
| 主对话 / 反思 / 圆桌 | GPT-5.4 |
| ACP 编码任务 | K2.5 / GPT-5.4 |
| Cron 日常任务 | Qwen3.5+ / K2.5 |
| 心跳 / 健康检查 | Ollama qwen3:8b |
Fallback 链:gpt-5.4 → k2.5 → qwen3.5-plus → ollama/qwen3:8b
核心 Harness 配置
json
{
"compaction": { "mode": "safeguard", "memoryFlush": { "softThresholdTokens": 40000 } },
"contextPruning": { "mode": "cache-ttl", "ttl": "6h", "keepLastAssistants": 3 },
"session": { "reset": { "atHour": 5, "idleMinutes": 30 }, "maintenance": { "pruneAfter": "7d", "maxDiskBytes": 104857600 } },
"acp": { "maxConcurrentSessions": 6, "ttlMinutes": 120 }
}数据源
| 市场 | 数据源 | 覆盖 |
|---|---|---|
| A 股 | AKShare + TuShare Pro | 实时行情 + 历史 + 财务 + 龙虎榜 + 北向 |
| 美股/港股 | yfinance + Finnhub | 行情 + 新闻 + 基本面 |
| 信息采集 | Tavily + RSS 13源 + GitHub Trending + 54 平台热榜 + arXiv | 搜索 + 新闻 + 热点 + 论文 |
| 浏览器 | agent-browser (Playwright) | JS 渲染页面(X/Twitter、雪球等) |
部署配置
| 组件 | 配置 |
|---|---|
| 硬件 | Mac 本地 7×24 |
| 进程守护 | launchctl + ThrottleInterval=10 |
| 自愈 | 2086 行脚本(heartbeat-guardian / check_cron_health / memory_maintenance) |
| 备份 | 每日 03:00 全量备份 |
| 监控 | Zoe 3 次/天巡检 + 系统 crontab 15 分钟健康检查 |
| 知识归档 | Obsidian Vault + obsidian-livesync |
其他
- 文中 "RSS 13 源 + GitHub Trending + 54 平台热榜" 的数据获取方式:github.com/lanyasheng/...