一、WSL2 环境搭建(核心基础)
WSL2 是 Windows 运行 Linux 的兼容层,既能复用 Windows 文件系统,又能提供完整的 Linux 环境,是 Windows 部署大模型的最优解。
1 开启 WSL 功能
以管理员身份打开「Windows 终端」,执行以下命令开启 WSL 和虚拟机平台:
wsl --install
命令执行完成后,重启电脑(必须重启)。
2 安装 Ubuntu 发行版
打开 Microsoft Store,搜索「Ubuntu」,选择任意版本(推荐 22.04 LTS),点击「获取」安装。
安装完成后启动 Ubuntu,首次启动会自动配置,设置 Linux 用户名和密码(记好,后续 sudo 操作需要)。
3 切换 WSL 版本为 WSL2
打开 Windows 终端,执行命令确认 WSL 版本:
wsl --list --verbose
如果 Ubuntu 版本是 WSL1,执行以下命令切换为 WSL2:(具体看https://blog.csdn.net/partJava/article/details/158651323?fromshare=blogdetail&sharetype=blogdetail&sharerId=158651323&sharerefer=PC&sharesource=partJava&sharefrom=from_link![]() https://blog.csdn.net/partJava/article/details/158651323?fromshare=blogdetail&sharetype=blogdetail&sharerId=158651323&sharerefer=PC&sharesource=partJava&sharefrom=from_link教程)
https://blog.csdn.net/partJava/article/details/158651323?fromshare=blogdetail&sharetype=blogdetail&sharerId=158651323&sharerefer=PC&sharesource=partJava&sharefrom=from_link教程)
wsl --set-version Ubuntu 2
wsl --set-default-version 2
最后这样进入虚拟机的。

可以时不时更新一下软件包:sudo apt update && sudo apt upgrade -y
二、Linux 环境配置(WSL2 内操作)
1 安装 Conda(环境管理工具)
-
下载 Miniconda(轻量版 Conda):
wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -
执行安装脚本(一路回车,最后输入
yes同意初始化):bash Miniconda3-latest-Linux-x86_64.sh -
重启终端,验证 Conda 是否安装成功:
conda --version
具体可以先配置环境变量
export PATH=/usr/local/cuda-12.9/bin:$PATH
libcuda.so
export LD_LIBRARY_PATH=/usr/lib/wsl/lib/:$LD_LIBRARY_PATH

创建目标文件夹:mkdir -p dev/toolchains/miniconda3
安装命令:wget https://repo.anaconda.com/miniconda/Miniconda3-latest-Linux-x86_64.sh -O dev/toolchains/miniconda3/miniconda.sh
进对应文件夹:cd dev/toolchains/miniconda3
./miniconda.sh -b -u -p ~/dev/toolchains/miniconda3
删除脚本:rm miniconda.sh
~/dev/toolchains/miniconda3/bin/conda init
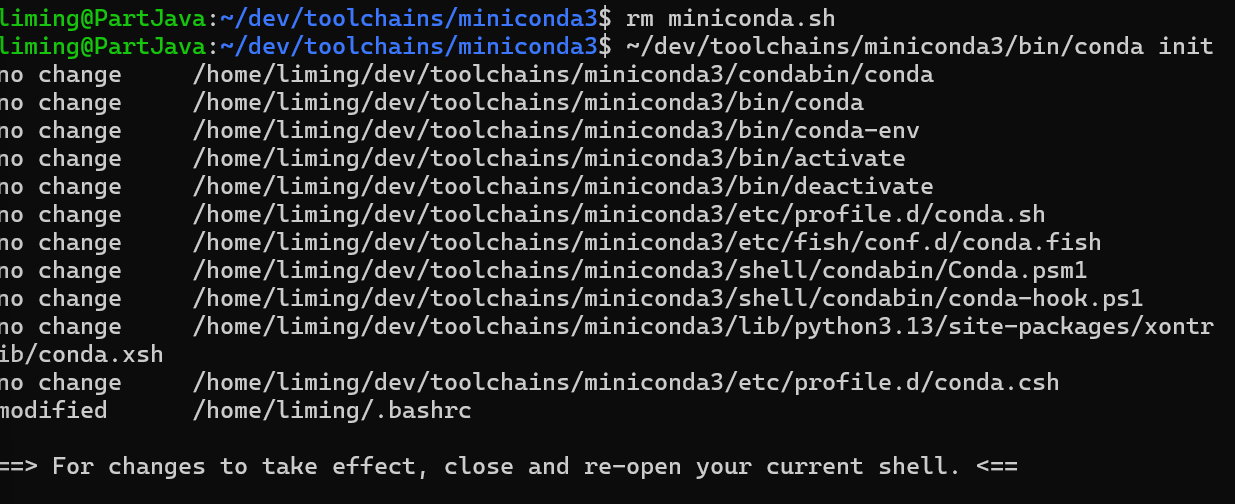
进入主文件夹:cd ~/
激活环境:source ~/.bashrc
查看环境是否成功: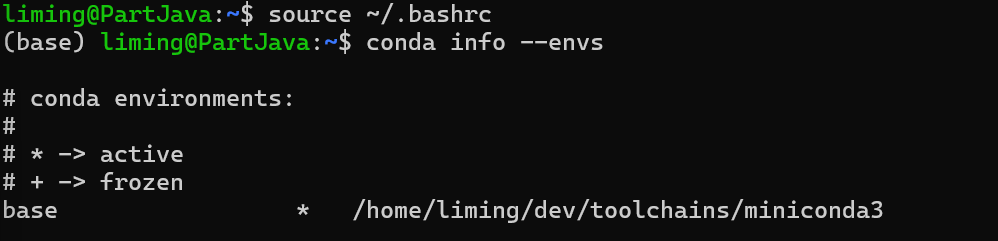
2 创建并激活 Python 环境
-
创建名为
pytorch的环境(Python 3.10 兼容性最佳):conda create -n pytorch python=3.10 -y -
激活环境(后续所有操作均在该环境下执行):
conda activate pytorch
亲测4070的本用的这个3.11的:conda create -n pytorch python=3.11 -y

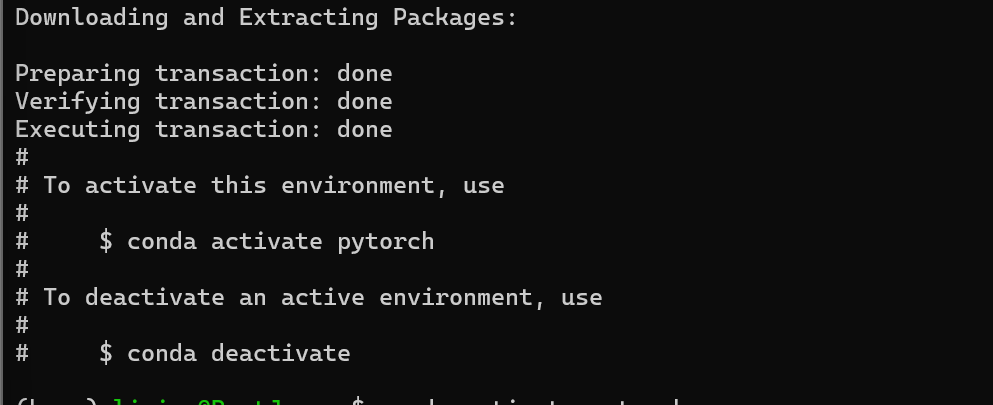
打开虚拟环境:conda activate pytorch
安装pytorch(可以后面再安装): pip3 install torch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 --index-url https://download.pytorch.org/whl/cu121

验证命令:python -c "import torch; print('PyTorch版本:', torch.version); print('GPU是否可用:', torch.cuda.is_available())"
3 验证 WSL2 GPU 可用性(关键)
注:GPU 验证放在虚拟环境配置后,能更精准确认环境与显卡的兼容性
-
在 Ubuntu 终端执行以下命令,安装 NVIDIA WSL 驱动依赖:
sudo apt update && sudo apt install -y nvidia-driver-535 -
验证 GPU 是否识别(激活 pytorch 环境后执行):
nvidia-smi若能看到显卡信息(包含 CUDA Version 等字段),说明 WSL2 显卡直通成功;若报错,需重新安装 NVIDIA WSL 驱动(确保下载的是「WSL 专用驱动」而非普通 Windows 驱动)。
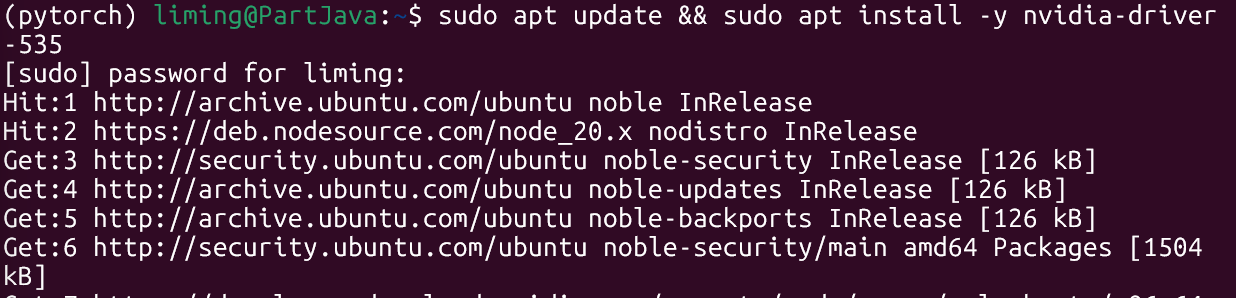

或者这个nvcc -V 也可以看配置。
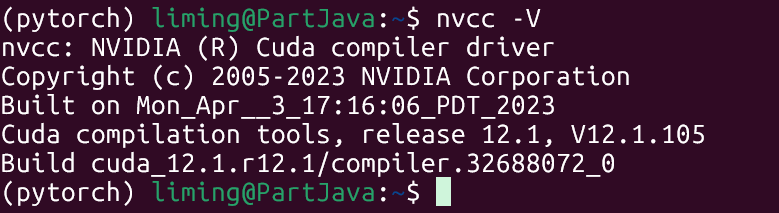
这也有完整的脚本,直接复制粘贴看版本:
bash
# ========== 1. 系统基础信息 ==========
echo -e "\n===== 1. 系统版本 ====="
lsb_release -a
uname -r # 内核版本
# ========== 2. WSL 信息 ==========
echo -e "\n===== 2. WSL 版本 ====="
wsl -l -v # Windows 终端命令,若报错则在 PowerShell 执行
# ========== 3. NVIDIA 驱动/GPU 检查 ==========
echo -e "\n===== 3. NVIDIA 驱动 & GPU ====="
nvidia-smi # 检查 GPU 驱动和可用 GPU
nvcc -V || echo "nvcc 命令未找到" # 检查 CUDA 编译器
# ========== 4. CUDA 相关 ==========
echo -e "\n===== 4. CUDA 路径 & 版本 ====="
ls /usr/local/ | grep cuda # 查看已安装的 CUDA 目录
echo "PATH 中的 CUDA 路径:"
echo $PATH | grep -o "/usr/local/cuda[^:]*"
echo "LD_LIBRARY_PATH 中的 CUDA 路径:"
echo $LD_LIBRARY_PATH | grep -o "/usr/local/cuda[^:]*"
# ========== 5. Conda 环境 ==========
echo -e "\n===== 5. Conda 环境列表 ====="
conda info --envs # 查看所有 conda 环境
echo -e "\n当前激活的 conda 环境:$CONDA_DEFAULT_ENV"
# ========== 6. Python & 包 ==========
echo -e "\n===== 6. Python 版本 & PyTorch ====="
python --version
pip list | grep -E "torch|cuda" # 查看 PyTorch 相关包
python -c "import torch; print('PyTorch 版本:', torch.__version__); print('CUDA 可用:', torch.cuda.is_available())" 2>/dev/null || echo "PyTorch 未安装/导入失败"
# ========== 7. 依赖库检查 ==========
echo -e "\n===== 7. 关键依赖库 ====="
ls -l /lib/x86_64-linux-gnu/ | grep libtinfo # 查看 libtinfo5/6
dpkg -l | grep cuda # 查看已安装的 CUDA 包
4 安装核心依赖包(新增关键步骤)补充说明:
transformers:HuggingFace 官方大模型核心库,vLLM/ModelScope 底层依赖,指定 4.57.3 版本避免兼容性问题;pip install transformers==4.57.3sentence-transformers:文本向量化库,Open WebUI 若启用 RAG 功能会依赖,提前安装避免后续报错。-
安装指定版本的 huggingface-hub(核心依赖,清华源+强制重装保证版本纯净)这个非常重要,一定要安装好:
pip install huggingface-hub==0.36.2 --force-reinstall -i https://pypi.tuna.tsinghua.edu.cn/simple
脚本检查:
python -c "
import torch
from transformers import AutoModel, AutoTokenizer
加载已下载的 all-MiniLM-L6-v2 模型
model_dir = '/home/liming/all-MiniLM-L6-v2'
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModel.from_pretrained(model_dir).to('cuda')
测试生成句向量
text = '测试:模型是否能正常运行在 GPU 上'
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True).to('cuda')
with torch.no_grad():
outputs = model(**inputs)
输出验证结果
print('✅ 模型运行设备:', model.device)
print('✅ GPU 是否可用:', torch.cuda.is_available())
print('✅ 句向量形状:', outputs.last_hidden_state.shape)
"
✅ 模型运行设备: cuda:0
✅ GPU 是否可用: True
✅ 句向量形状: torch.Size(1, 18, 384)
# 安装指定版本的 transformers(核心依赖)
pip install transformers==4.57.3
# 升级安装 sentence-transformers(文本向量化/嵌入依赖)
pip install -U sentence-transformers
4 安装 PyTorch 和 vLL
-
安装 PyTorch(这个上面安装了,ai方法不好,作用:适配 CUDA,无需手动装 CUDA,PyTorch 自带)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121 -
安装 vLLM(高性能大模型推理引擎):
pip install vllm -
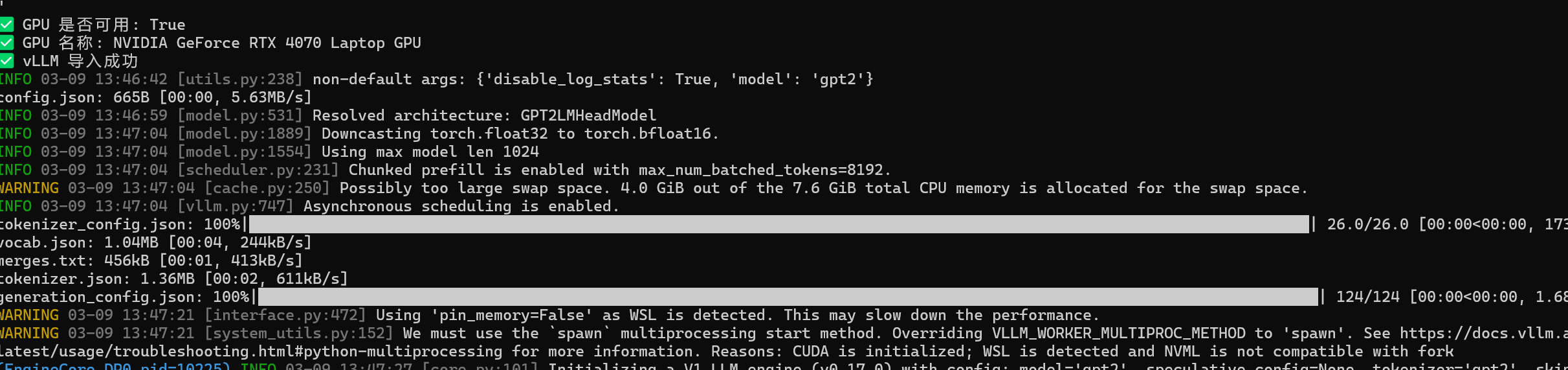
验证 vLLM 安装成功:
python -c "import vllm; print(vllm.__version__)"

测试代码:
python -c "
import torch
from vllm import LLM, SamplingParams
1. 验证 GPU 可用性(核心)
print('✅ GPU 是否可用:', torch.cuda.is_available())
print('✅ GPU 名称:', torch.cuda.get_device_name(0) if torch.cuda.is_available() else '无GPU')
2. 验证 vLLM 导入(确认安装成功)
print('✅ vLLM 导入成功')
3. 极简测试:加载小模型并推理(可选,验证核心功能)
try:
用 tiny 模型快速测试(下载量小)
llm = LLM(model='gpt2', tensor_parallel_size=1)
sampling_params = SamplingParams(max_tokens=10)
prompts = 'Hello, vLLM!'
outputs = llm.generate(prompts, sampling_params)
print('✅ vLLM 推理测试成功,输出:', outputs0.outputs0.text)
except Exception as e:
print('⚠️ 推理测试略过(模型下载可选),但 vLLM 核心安装已完成,错误:', str(e):100)
"
5 安装 ModelScope(模型下载工具)
pip install modelscope
四、下载 Qwen3-0.6B 模型
利用 ModelScope 下载模型到 Windows 桌面(WSL2 可通过/mnt/c/访问 Windows 路径),方便跨系统管理。看好对应的文件夹位置。
1 执行下载命令
# 下载模型到 Windows 桌面的 model 文件夹
modelscope download --model Qwen/Qwen3-0.6B --local_dir /mnt/c/Users/34970/Desktop/model/Qwen3-0.6B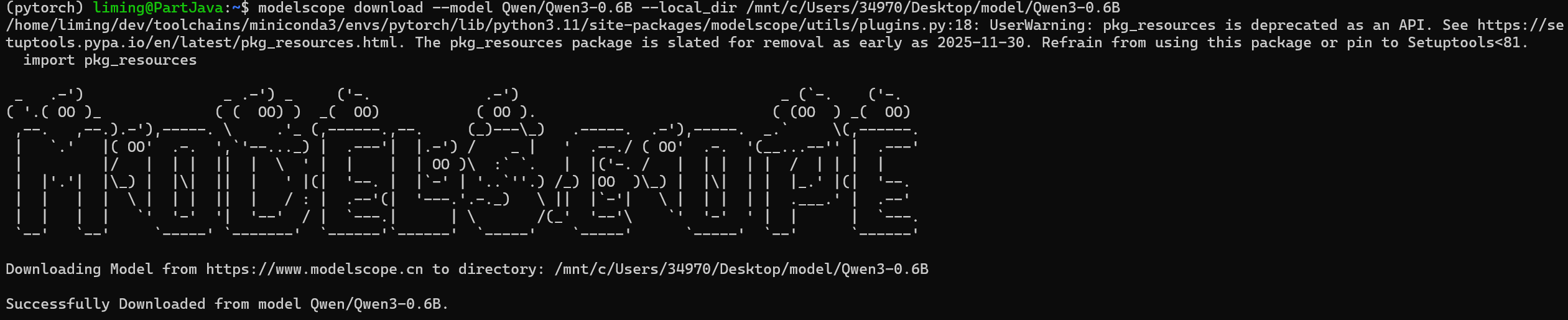
- 替换
34970为你的 Windows 用户名; - 下载完成后,可在 Windows 桌面看到
model/Qwen3-0.6B文件夹,内含模型权重和配置文件。
2 验证模型文件
在 WSL2 终端执行以下命令,确认模型文件存在:
ls -l /mnt/c/Users/34970/Desktop/model/Qwen3-0.6B能看到config.json、model.safetensors等核心文件,说明下载成功。
很多模型可以这里面去找,我用的最简单的0.6B的
https://hf-mirror.com![]() https://hf-mirror.com
https://hf-mirror.com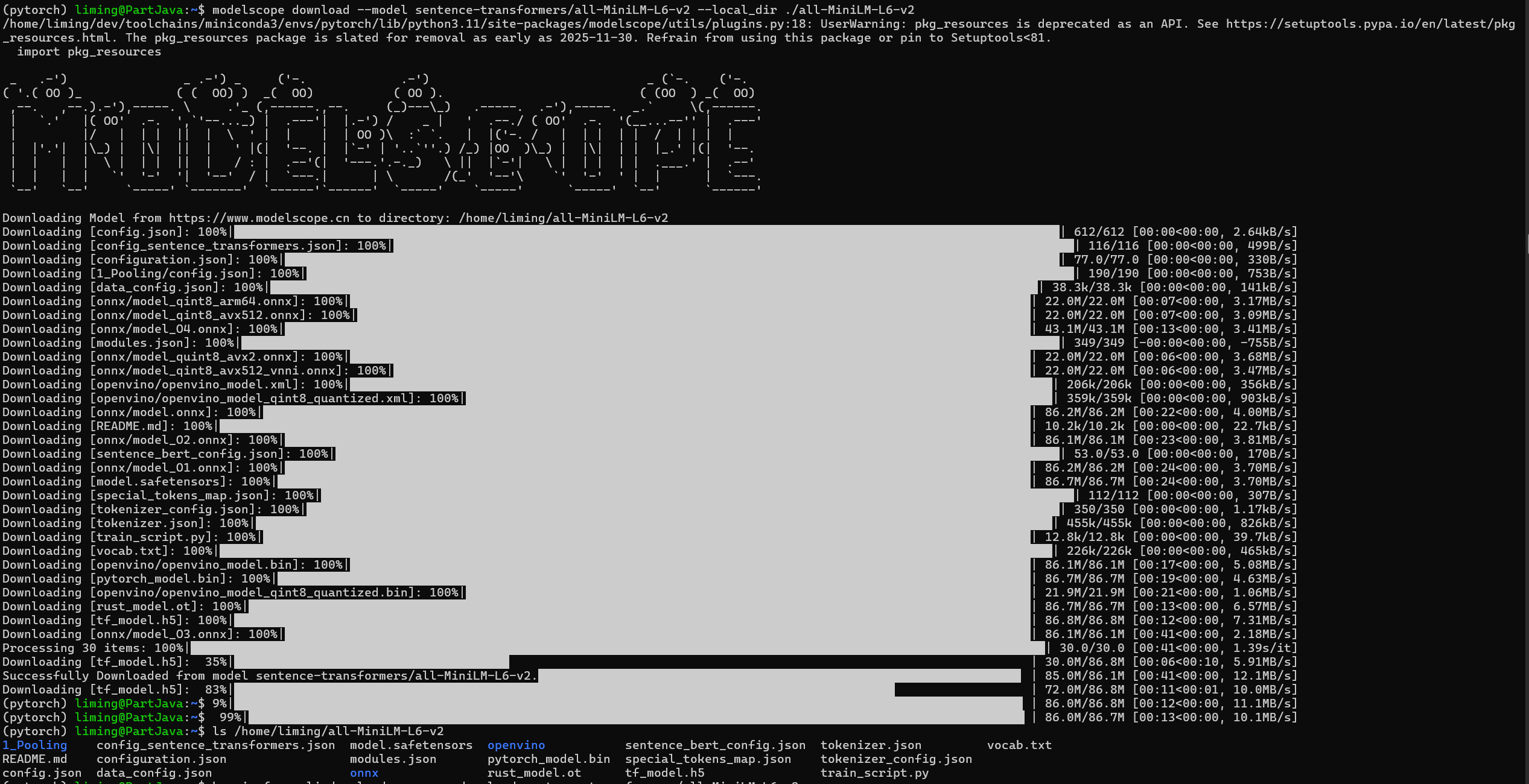
大概差不多的意思。
python -c "
import torch
from transformers import AutoModel, AutoTokenizer
加载已下载的 all-MiniLM-L6-v2 模型
model_dir = '/home/liming/all-MiniLM-L6-v2'
tokenizer = AutoTokenizer.from_pretrained(model_dir)
model = AutoModel.from_pretrained(model_dir).to('cuda')
测试生成句向量
text = '测试:模型是否能正常运行在 GPU 上'
inputs = tokenizer(text, return_tensors='pt', padding=True, truncation=True).to('cuda')
with torch.no_grad():
outputs = model(**inputs)
输出验证结果
print('✅ 模型运行设备:', model.device)
print('✅ GPU 是否可用:', torch.cuda.is_available())
print('✅ 句向量形状:', outputs.last_hidden_state.shape)
"
✅ 模型运行设备: cuda:0
✅ GPU 是否可用: True
✅ 句向量形状: torch.Size(1, 18, 384)
五、启动 vLLM 高性能推理服务
vLLM 是核心后端,负责将模型转为可网络调用的 API 服务,相比原生 Transformers 显存利用率更高、推理速度更快。
1 执行启动命令
在 WSL2 终端(保持pytorch环境激活)执行:
vllm serve /mnt/c/Users/34970/Desktop/model/Qwen3-0.6B \
--served-model-name qwen3-0.6b \
--host 0.0.0.0 \
--port 8000 \
--gpu-memory-utilization 0.5 \
--max-model-len 8192 \
--trust-remote-code
2 验证服务启动成功
等待终端输出以下关键日志,说明服务就绪:
Starting vLLM API server 0 on http://0.0.0.0:8000
Application startup complete.
127.0.0.1:57482 - "GET /v1/models HTTP/1.1" 200 OK- 不要关闭该终端!vLLM 服务需持续运行,关闭则后端失效。
- 日志中的
404 Not Found(访问/或favicon.ico)是正常现象,vLLM 无网页界面,仅提供 API。
六、部署 Open WebUI 可视化聊天界面
Open WebUI 是开源的大模型聊天界面,兼容 OpenAI API 格式,可无缝对接 vLLM 后端,实现网页聊天。
新建一个Ubuntu终端操作下面命令。
1 安装 Open WebUI
pip install open-webui 2 设置环境变量(对接 vLLM 后端)
2 设置环境变量(对接 vLLM 后端)
新开一个 WSL2 终端(Ctrl+Shift+T),激活pytorch环境后执行:
conda activate pytorch
# 加速 HuggingFace 模型下载(可选)
export HF_ENDPOINT=https://hf-mirror.com
# 自定义 Open WebUI 端口(避免和 vLLM 的 8000 冲突)
export PORT=6006
# 网页标签名称
export WEBUI_NAME=晴川学院大模型平台
# 关键:指定 vLLM 后端 API 地址
export OPENAI_API_BASE_URL=http://localhost:8000/v1
# 随便填 API Key(格式正确即可,vLLM 未设置密钥)
export OPENAI_API_KEY=sk-1234567890abcdefexport HF_ENDPOINT=https://hf-mirror.com
访问端口,默认为 8080
export PORT=6006
允许管理员访问用户聊天记录,默认为 true,建议设置为 false
export ENABLE_ADMIN_CHAT_ACCESS=true
浏览器标签显示的名称
export WEBUI_NAME=小张的大模型平台
启用使用 BM25 + ChromaDB 的集成搜索,使用 sentence_transformers 模型进行重新排序
export ENABLE_RAG_HYBRID_SEARCH=False
默认角色,支持 admin/user/pending 三种,对应管理员,普通用户和待审核用户
export DEFAULT_USER_ROLE=user
export WEBUI_NAME=某某某大模型平台
3 启动 Open WebUI
简单启动本地的模型,说明好端口:
1. 确保在 pytorch 环境里
conda activate pytorch
2. 关键:告诉 Open WebUI 去连接 vLLM 后端 export OPENAI_API_BASE_URL=http://localhost:8000/v1
export OPENAI_API_KEY=sk-123456 # 随便填,格式对就行
3. 你的模型平台名称
export WEBUI_NAME=张飞的学习模型
4. 重新启动
open-webui serve --port 6006
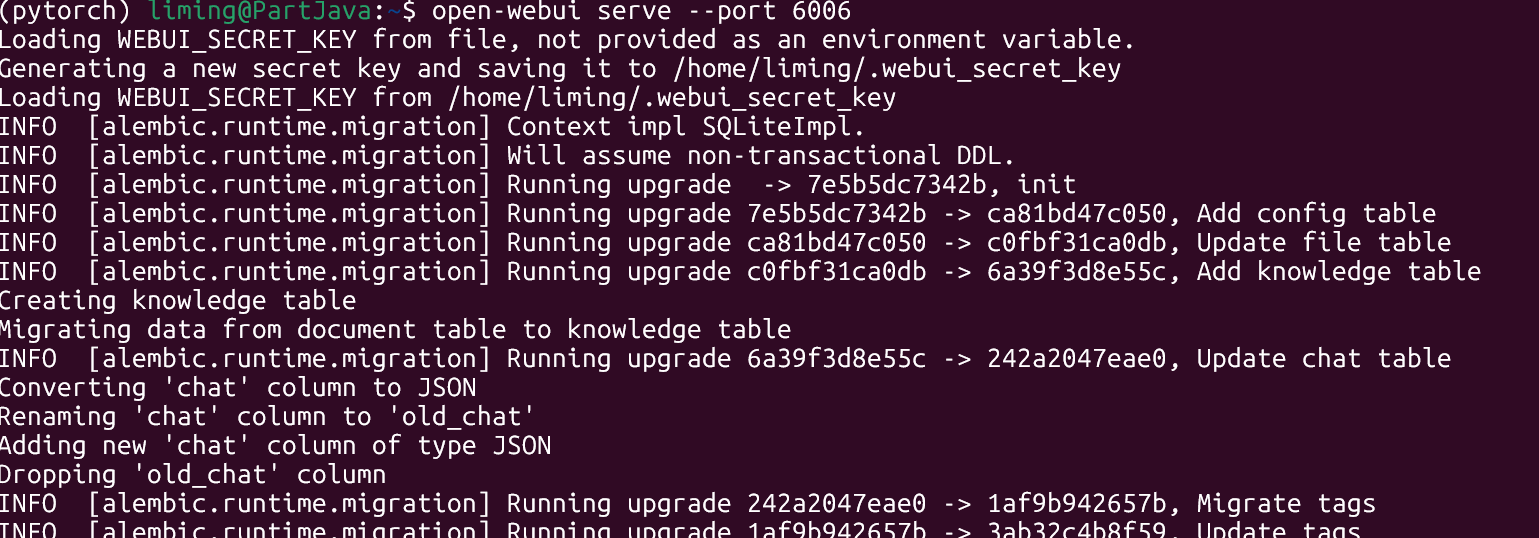
open-webui serve --port 6006 4 访问网页聊天界面
4 访问网页聊天界面
- 在 Windows 浏览器中输入:
http://localhost:6006; - 首次访问需创建管理员账号(用户名 + 密码);
- 右边上面的那个加号添加模型。
- url输入http://127.0.0.1.8000/v1
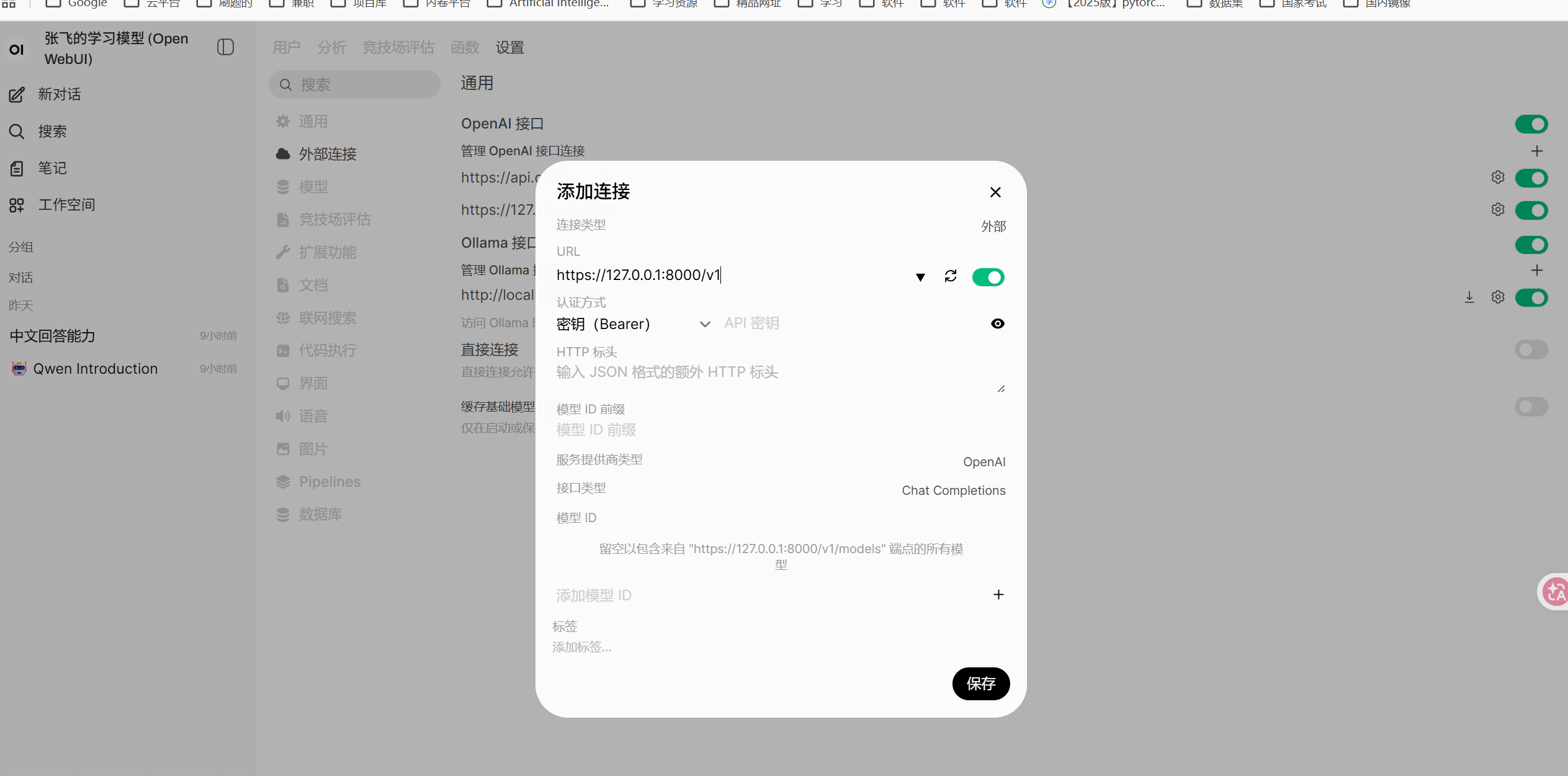
- 登录后,在聊天界面选择模型
qwen3-0.6b(和 vLLM 启动的模型名一致); - 输入问题(如「你好,介绍一下自己」),即可和 Qwen3-0.6B 对话!

七、关键避坑指南
1 WSL2 路径映射问题
- Windows 路径
C:\Users\34970\Desktop在 WSL2 中对应/mnt/c/Users/34970/Desktop; - 若访问 Windows 文件权限不足,执行:
chmod -R 755 /mnt/c/Users/34970/Desktop/model。
2 端口冲突问题
- 若启动时提示
Port 6006 is in use,将--port 6006改为6007/6008,浏览器访问时同步改端口; - vLLM 的 8000 端口和 Open WebUI 的 6006 端口需保证未被其他程序占用。
3 WSL2 性能提示
- 日志中
Using 'pin_memory=False' as WSL is detected仅为性能提醒,不影响功能; - 首次启动 vLLM 会执行
torch.compile编译模型(约 20 秒),后续重启会复用缓存,速度更快。
八、总结
核心流程回顾
- WSL2 搭建:解决 Windows 与 Linux 工具的兼容性问题,实现基础环境支撑;
- 环境配置:通过 Conda 管理 Python 环境 → 验证 GPU 可用性 → 安装 PyTorch/vLLM/ModelScope;
- 模型下载:将 Qwen3-0.6B 下载到 Windows 桌面,WSL2 可直接访问;
- vLLM 启动:将模型转为高性能 API 服务(8000 端口);
- Open WebUI 部署:提供网页界面,对接 vLLM 后端实现可视化聊天。
核心价值
- 本地化部署:数据不联网,隐私更安全;
- 低成本:无需云服务器,普通 PC 即可运行;
- 易用性:通过 Open WebUI 摆脱命令行,实现友好的网页交互;
- 高性能:vLLM 优化显存利用,推理速度远超原生 Transformers。
至此,你已完成从「环境搭建」到「可视化聊天」的全流程,可自由扩展模型(如 Qwen3-1.7B)或自定义 Open WebUI 配置,打造专属的本地大模型平台。