Docker核心前置教程(专为Hadoop部署准备)
本教程聚焦Hadoop部署必需的Docker核心技能 ,剔除无关知识点,只讲后续搭建Hadoop单机/分布式集群时一定会用到的Docker操作,确保知识点精准、实战性强。

一、Docker核心概念(Hadoop视角极简版)
先理解4个核心概念,后续操作不会懵:
| 概念 | 通俗解释 | Hadoop部署中的作用 |
|---|---|---|
| 镜像(Image) | 只读的"模板",包含运行程序的所有环境(系统、软件、配置) | 打包JDK、Hadoop、SSH等环境,避免每台Hadoop节点重复配置 |
| 容器(Container) | 镜像的运行实例,独立隔离的环境(轻量级虚拟机) | 一个容器就是一个Hadoop节点(NameNode/DataNode/ResourceManager等) |
| 网络(Network) | Docker容器间的通信规则 | 分布式Hadoop需要节点间互通(如NameNode和DataNode通信),必须配置自定义网络 |
| 数据卷(Volume) | 容器与宿主机共享的目录(容器删了数据不丢) | 存储HDFS数据、Hadoop日志,避免容器重启/删除导致数据丢失 |
二、Docker基础环境验证(必做)
确保Docker安装正确、能正常使用,这是所有操作的前提:
bash
# 1. 检查Docker服务状态(必须显示active (running))
sudo systemctl status docker
# 2. 验证Docker功能(运行官方测试镜像,输出"Hello from Docker!"则正常)
sudo docker run --rm hello-world
# 3. (可选)添加当前用户到docker组,避免每次输sudo(需重启生效)
sudo usermod -aG docker $USER
newgrp docker # 立即生效三、镜像管理(Hadoop部署核心操作)
Hadoop部署需要基于基础系统镜像(如Ubuntu/CentOS)构建自定义镜像,以下是必备操作:
1. 拉取基础镜像(Hadoop的基础环境)
bash
# 拉取Ubuntu 22.04镜像(Hadoop适配性最好的基础系统)
docker pull ubuntu:22.04
# 查看本地镜像(确认拉取成功)
docker images # 输出包含ubuntu:22.04则成功
docker images | grep ubuntu # 过滤查看Ubuntu镜像2. 构建自定义镜像(Dockerfile核心)
后续部署Hadoop需要将JDK、SSH、Hadoop打包成镜像,必须掌握Dockerfile构建:
步骤1:创建Dockerfile目录和文件
bash
# 创建目录(统一管理构建文件)
mkdir -p ~/docker-hadoop-base
cd ~/docker-hadoop-base
# 创建空的Dockerfile(后续部署Hadoop会填充内容,先练格式)
touch Dockerfile步骤2:编写极简Dockerfile(练语法,后续直接复用)
sudo nano Dockerfile编辑Dockerfile(用vim或nano):
dockerfile
# 基础镜像(Hadoop的基础系统)
FROM ubuntu:22.04
# 设置环境变量(避免Ubuntu交互提示,Hadoop构建必加)
ENV DEBIAN_FRONTEND=noninteractive
# 安装Hadoop必需的基础依赖(SSH、ping、编辑器等)
RUN apt update && apt install -y \
openssh-server \
iputils-ping \
net-tools \
vim \
&& apt clean # 清理缓存,减小镜像体积
# 配置SSH(Hadoop免密登录必需)
RUN mkdir /var/run/sshd \
&& echo "root:123456" | chpasswd \
&& sed -i 's/#PermitRootLogin prohibit-password/PermitRootLogin yes/' /etc/ssh/sshd_config
# 暴露端口(Hadoop节点通信必需:22是SSH端口)
EXPOSE 22
# 容器启动命令(启动SSH服务,Hadoop节点必需)
CMD ["/usr/sbin/sshd", "-D"]步骤3:构建镜像
bash
# 构建镜像,-t指定标签(名称:版本),.表示当前目录的Dockerfile
docker build -t hadoop-base:ubuntu22.04 .
# 验证构建结果(输出包含hadoop-base:ubuntu22.04则成功)
docker images | grep hadoop-base输出如下:

一、整体过程总结
你执行的docker build -t hadoop-base:ubuntu22.04 .是基于当前目录的Dockerfile构建自定义Docker镜像 的命令,整个输出是Docker按Dockerfile的步骤一步步构建镜像的全过程,最终成功生成了标签为hadoop-base:ubuntu22.04的镜像(后续部署Hadoop的基础镜像)。
二、逐行解析输出含义
-
废弃提示(非错误,可忽略)
DEPRECATED: The legacy builder is deprecated and will be removed in a future release.
BuildKit is currently disabled; enable it by removing the DOCKER_BUILDKIT=0
environment-variable.
- 含义:Docker提示你当前使用的是"旧版构建器",未来会移除,建议启用新版BuildKit构建器;
- 影响:完全不影响镜像构建和使用,只是一个兼容性提示,新手暂时不用管。
-
发送构建上下文
Sending build context to Docker daemon 2.56kB
- 含义:Docker会把当前目录(
.)下的所有文件/目录(称为"构建上下文")发送给Docker守护进程(daemon),供构建镜像使用; - 关键:2.56kB说明上下文很小(只有Dockerfile等少量文件),构建效率高(如果上下文包含大文件,这里会很慢)。
- 按Dockerfile步骤构建(Step 1/6 ~ Step 6/6)
Dockerfile里写了6个指令(FROM/ENV/RUN/EXPOSE/CMD),构建时会按顺序执行每个步骤,每个步骤生成一个"镜像层"(分层存储是Docker的核心特性):
| 输出行 | 对应Dockerfile指令 | 具体含义 |
|---|---|---|
| Step 1/6 : FROM ubuntu:22.04 ---> 8ea4cbcf3a26 | FROM ubuntu:22.04 |
① 基于官方的Ubuntu 22.04镜像作为"基础层"; ② 8ea4cbcf3a26是官方Ubuntu镜像的唯一ID(哈希值)。 |
| Step 2/6 : ENV DEBIAN_FRONTEND=noninteractive ---> Using cache ---> a1681dfa4c3c | ENV DEBIAN_FRONTEND=noninteractive |
① 设置环境变量,避免Ubuntu安装软件时弹出交互提示; ② Using cache:该步骤之前执行过,直接复用缓存(加速构建); ③ a1681dfa4c3c:该步骤生成的镜像层ID。 |
| Step 3/6 : RUN apt update && apt install -y openssh-server iputils-ping net-tools vim && apt clean ---> Using cache ---> ab30e2a66a69 | RUN apt update && apt install -y ... |
① 在基础镜像中安装SSH服务、ping、网络工具、vim等Hadoop必需的依赖; ② apt clean清理缓存,减小镜像体积; ③ 复用缓存,生成新的镜像层ab30e2a66a69。 |
| Step 4/6 : RUN mkdir /var/run/sshd && echo "root:123456" | chpasswd && sed -i ... ---> Using cache ---> ae0518e9d33f | ① 创建SSH运行目录、设置root密码、修改SSH配置允许root登录; ② 复用缓存,生成镜像层ae0518e9d33f(这一步是SSH登录的核心配置)。 |
| Step 5/6 : EXPOSE 22 ---> Using cache ---> d3928117f1e1 | EXPOSE 22 |
① 声明容器要暴露22端口(SSH端口,Hadoop节点通信必需); ② 注意:EXPOSE只是"声明",启动容器时需用-p映射端口才真正可访问。 |
| Step 6/6 : CMD "/usr/sbin/sshd", "-D" ---> Using cache ---> ab5bcc15f783 | CMD ["/usr/sbin/sshd", "-D"] |
① 设置容器启动时默认执行的命令:启动SSH服务并后台运行; ② 这是保证容器启动后SSH服务可用的关键(Hadoop依赖SSH)。 |
-
构建成功提示
Successfully built ab5bcc15f783
Successfully tagged hadoop-base:ubuntu22.04
Successfully built ab5bcc15f783:镜像构建成功,ab5bcc15f783是该镜像的唯一ID;Successfully tagged hadoop-base:ubuntu22.04:给镜像打上"名称:版本"标签(hadoop-base:ubuntu22.04),后续启动容器时可直接用这个标签(比记镜像ID方便)。
三、关键知识点(Hadoop部署前置)
- 分层构建 :每个
RUN/ENV/CMD等指令对应一个镜像层,复用缓存(Using cache)能大幅加速后续构建(修改Dockerfile后,仅重新执行修改后的步骤,之前的步骤复用缓存); - 镜像标签 :
-t hadoop-base:ubuntu22.04是给镜像打标签,方便后续识别和使用(比如启动容器时直接用docker run hadoop-base:ubuntu22.04); - 核心成果:你现在有了一个包含Ubuntu 22.04 + SSH服务 + 基础工具的镜像,这是后续部署Hadoop的"基础环境镜像",接下来只需在这个镜像基础上添加JDK、Hadoop即可。
3. 镜像常用操作(清理/删除)
查看镜像
sudo docker images
这张图是 docker images 命令的输出,每一列的含义如下:
| 列名 | 含义 |
|---|---|
| REPOSITORY | 镜像的仓库名(名称),用来标识镜像的来源或用途。 例如:hadoop-base 是你构建的Hadoop基础镜像,ubuntu 是官方系统镜像。 |
| TAG | 镜像的版本标签,用来区分同一仓库下的不同版本。 例如:ubuntu22.04 表示基于Ubuntu 22.04构建,latest 是默认的最新版本标签。 |
| IMAGE ID | 镜像的唯一ID(哈希值),是Docker内部用来唯一标识镜像的字符串。 例如:ab5bcc15f783 就是你刚构建的 hadoop-base:ubuntu22.04 镜像的ID。 |
| CREATED | 镜像的创建时间,显示镜像是什么时候构建或拉取的。 例如:9 minutes ago 表示 hadoop-base 是9分钟前刚构建的。 |
| SIZE | 镜像占用的磁盘空间大小。 例如:hadoop-base:ubuntu22.04 是305MB,因为它包含了Ubuntu系统和SSH等工具;hello-world 只有10.1KB,是一个极小的测试镜像。 |
结合你的输出举例:
hadoop-base仓库下的ubuntu22.04标签,ID是ab5bcc15f783,9分钟前构建,大小305MB。ubuntu仓库下的22.04标签,是官方基础镜像,3周前拉取,大小77.9MB。
https://www.doubao.com/thread/w143c6f722c6b23dd
bash
# 删除单个镜像(清理无用镜像)
docker rmi hadoop-base:ubuntu22.04 # 按标签删除
docker rmi 镜像ID # 按ID删除
# 强制删除所有未使用镜像(清理空间,谨慎使用)
docker image prune -f四、验证构建成果(确保镜像可用)
执行以下命令,验证镜像是否能正常启动容器、SSH服务是否可用:
bash
# 启动容器(后台运行,映射22端口)
docker run -d --name hadoop-test -p 2222:22 hadoop-base:ubuntu22.04
# 查看容器是否运行
docker ps # 输出包含hadoop-test,状态为Up则正常
# 进入容器,验证SSH服务
docker exec -it hadoop-test /bin/bash
service ssh status # 输出active (running)则SSH正常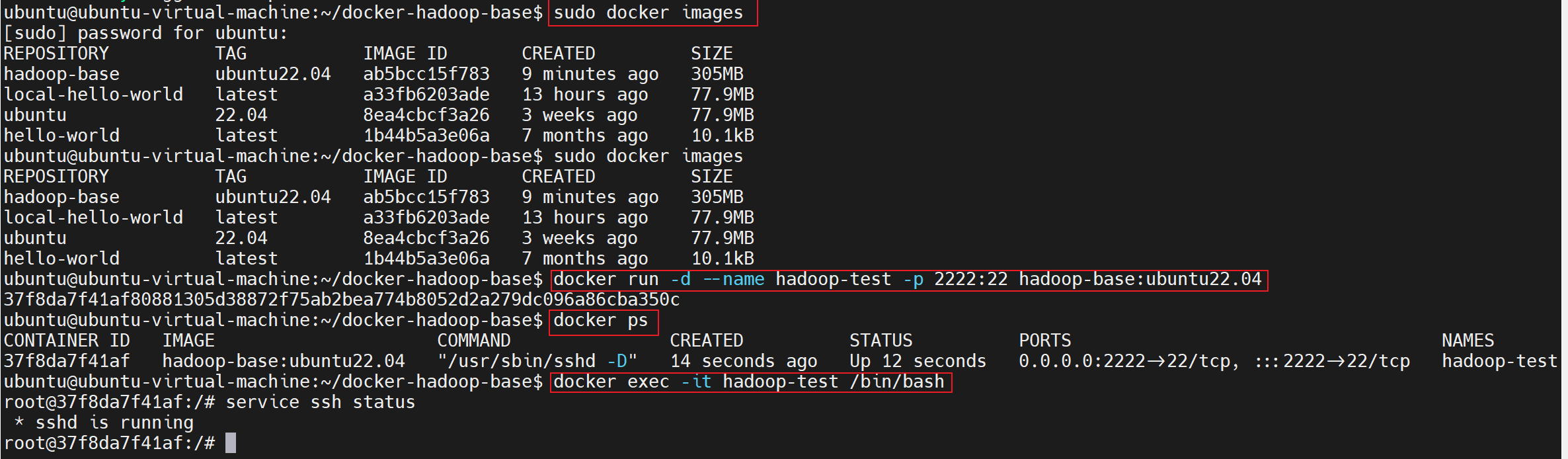
docker run -d --name hadoop-test -p 2222:22 hadoop-base:ubuntu22.04 解释如下
https://www.doubao.com/thread/w0e0e6b8d62c9167fdocker exec -it hadoop-test /bin/bash 解释如下
https://www.doubao.com/thread/w7c09126c26848556
总结
- 整个过程是Docker按Dockerfile的指令,一步步构建出适配Hadoop部署的基础镜像;
- 核心成果:生成了
hadoop-base:ubuntu22.04镜像,包含Hadoop必需的SSH服务和基础环境; - 关键提示:
Using cache是正常优化,不影响镜像功能,后续修改Dockerfile后缓存会自动失效并重新构建对应步骤。
这个镜像就是你后续部署Hadoop的"底座",接下来只需往里面添加JDK、Hadoop配置即可。
备注:关闭容器避免端口冲突
步骤1:先执行命令查看哪个容器占用了2222端口:
bash
# 查看所有容器(包括运行/停止的),找到映射2222端口的容器名/ID
docker ps -a | grep 2222
# 或直接查看所有运行中的容器
docker ps步骤2:停止并删除占用端口的容器
方式1:按容器名停止+删除(推荐,比如占用容器是hadoop-test)
bash
# 1. 停止容器(先停再删,避免强制删除导致数据问题)
docker stop hadoop-test
# 2. 删除容器(释放端口)
docker rm hadoop-test为什么需要删除容器才能释放端口
https://www.doubao.com/thread/w27b5c3d32974b37c
方式2:如果不知道容器名,按端口查PID后停止(通用方法)
bash
# 1. 查找占用2222端口的进程PID
sudo lsof -i:2222
# 2. 停止该进程(替换PID为实际数值)
sudo kill -9 PID
# 3. 清理残留容器(如果有)
docker rm -f $(docker ps -aq) # 强制删除所有容器(谨慎使用,会删所有容器)步骤3:重新启动hadoop-node1容器
端口释放后,重新执行启动命令即可:
bash
docker run -d --name hadoop-node1 -p 2222:22 -v ~/hadoop-data:/opt/hadoop/data hadoop-base:ubuntu22.04避坑:后续避免端口冲突的小技巧
-
启动新容器时换端口 :比如把2222换成2223/2224,避免重复:
bashdocker run -d --name hadoop-node1 -p 2223:22 -v ~/hadoop-data:/opt/hadoop/data hadoop-base:ubuntu22.04 -
一次性停止+删除所有容器 (测试环境可用,清理所有残留):
bash# 停止所有运行中的容器 docker stop $(docker ps -q) # 删除所有容器 docker rm $(docker ps -aq) -
查看端口映射情况 :启动容器后,验证端口是否正确映射:
bashdocker port hadoop-node1✅ 输出示例(正常映射):
22/tcp -> 0.0.0.0:2222
验证容器是否正常启动
执行以下命令,确认hadoop-node1容器运行正常:
bash
# 查看容器状态(Up表示运行中)
docker ps | grep hadoop-node1
# 验证数据卷挂载(确认~/hadoop-data已挂载到容器)
docker inspect hadoop-node1 | grep -A 5 "Mounts"总结
- 核心操作 :
docker stop 容器名+docker rm 容器名关闭并删除占用端口的容器; - 端口冲突原因:同一宿主机端口只能映射给一个容器,重复映射会报错;
- 验证标准 :重新启动
hadoop-node1后,docker ps显示容器状态为Up,无端口占用报错。
执行完上述步骤后,你的hadoop-node1容器就能正常启动,后续可通过docker exec -it hadoop-node1 /bin/bash进入容器配置Hadoop环境。
https://www.doubao.com/thread/w39b0cf5f8055dfe0
五、容器管理(Hadoop节点核心操作)
Hadoop的每个节点都是一个Docker容器,以下操作是日常管理的核心:
1. 启动容器(Hadoop节点启动必用)
基础启动(交互式,测试用)
bash
# 启动容器,--name指定容器名,-it交互式,/bin/bash进入命令行
docker run -it --name hadoop-node1 hadoop-base:ubuntu22.04 /bin/bash
# 退出容器(仅退出,容器不停止)
exit # 或按Ctrl+P+Q生产级启动(Hadoop部署核心,后台运行+持久化)
bash
# 删除hadoop-node1容器
docker rm -f hadoop-node1
# 启动Hadoop节点容器:
# --name: 容器名hadoop-node1
# -p: 宿主机2222端口映射容器22端口(SSH)
# -v: 宿主机~/hadoop-data挂载到容器/opt/hadoop/data(数据持久化)
docker run -d --name hadoop-node1 -p 2222:22 -v ~/hadoop-data:/opt/hadoop/data hadoop-base:ubuntu22.042. 容器状态管理
bash
# 查看运行中的容器
docker ps
# 查看所有容器(包括停止的)
docker ps -a
# 启动停止的容器
docker start hadoop-node1
# 停止运行的容器
docker stop hadoop-node1
# 重启容器
docker restart hadoop-node1
# 删除容器(需先停止)
docker rm hadoop-node1
# 强制删除运行中的容器(谨慎使用)
docker rm -f hadoop-node1
3. 进入运行中的容器(修改配置/执行命令)
Hadoop部署中需要频繁进入容器修改配置,这是最常用的命令:
bash
# 交互式进入容器(推荐,Hadoop配置必用)
docker exec -it hadoop-node1 /bin/bash
# 示例:进入容器后验证SSH服务
service ssh status # 输出"active (running)"则正常五、网络管理(分布式Hadoop核心)
分布式Hadoop需要多个容器互通,必须掌握Docker自定义网络:
1. 创建自定义网络(避免IP冲突)
bash
# 创建桥接网络,指定子网(Hadoop集群固定IP段,避免冲突)
docker network create --driver bridge --subnet=172.18.0.0/16 hadoop-network
# 查看网络列表(确认创建成功)
docker network ls2. 容器加入网络(两种方式)
方式1:启动容器时直接加入
bash
# --network hadoop-network \ # 加入自定义网络
# --ip 172.18.0.2 \ # 指定固定IP(Hadoop节点IP固定,避免重启变化)
docker run -d --name hadoop-namenode --network hadoop-network --ip 172.18.0.2 hadoop-base:ubuntu22.04方式2:给已启动容器加网络
bash
# 将已创建的容器 hadoop-node1 加入到名为 hadoop-network 的自定义 Docker 网络中 的核心指令
docker network connect hadoop-network hadoop-node1查看 hadoop-network 网络详情(推荐,直接看 IP 分配)
执行以下命令,会输出 hadoop-network 的完整配置,包含所有接入容器的 IP 和名称:
docker network inspect hadoop-network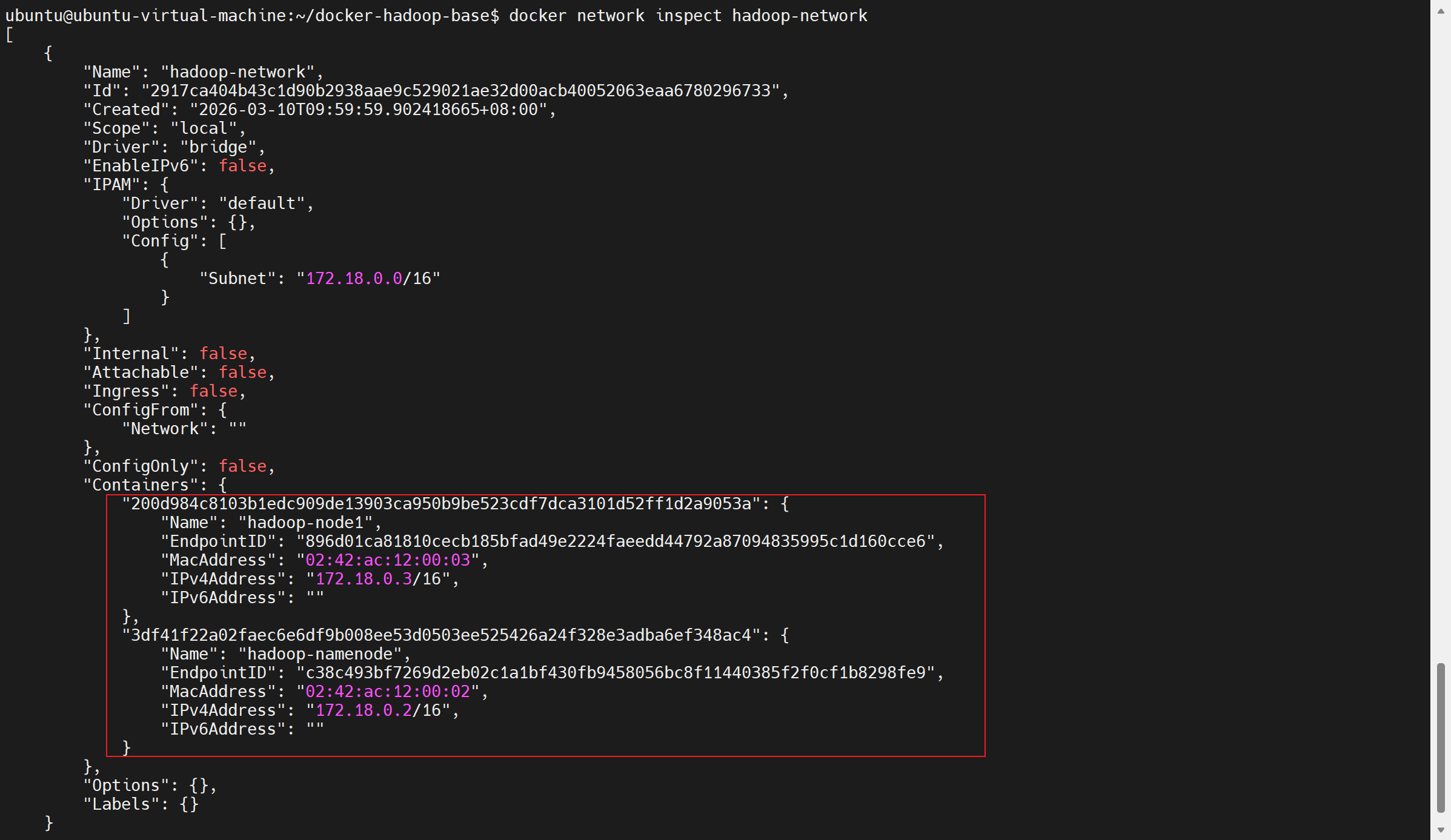
3. 验证容器网络互通(Hadoop必需)
# 1. 停止容器(先停再删,避免强制删除导致数据问题)
docker stop hadoop-datanode1
# 2. 删除容器(释放端口)
docker rm hadoop-datanode1
bash
# 启动第二个容器作为DataNode
docker run -d --name hadoop-datanode1 --network hadoop-network --ip 172.18.0.4 hadoop-base:ubuntu22.04
# 进入namenode容器,ping datanode(能通则网络正常)
docker exec -it hadoop-namenode ping hadoop-datanode1
docker exec -it hadoop-namenode ping 172.18.0.4
4. 网络常用操作
bash
# 查看网络详情(包含连接的容器和IP)
docker network inspect hadoop-network
# 断开容器与网络的连接
docker network disconnect hadoop-network hadoop-node1
# 删除自定义网络(需先断开所有容器)
docker network rm hadoop-network六、数据卷管理(Hadoop数据持久化)
Hadoop的HDFS数据、日志必须持久化,否则容器删除数据就丢了:
1. 创建命名卷(推荐,管理规范)
bash
# 创建数据卷(存储HDFS数据)
docker volume create hadoop-hdfs-data
# 查看数据卷(确认创建成功)
docker volume ls
# 查看数据卷的宿主机路径(了解数据存在哪)
docker volume inspect hadoop-hdfs-data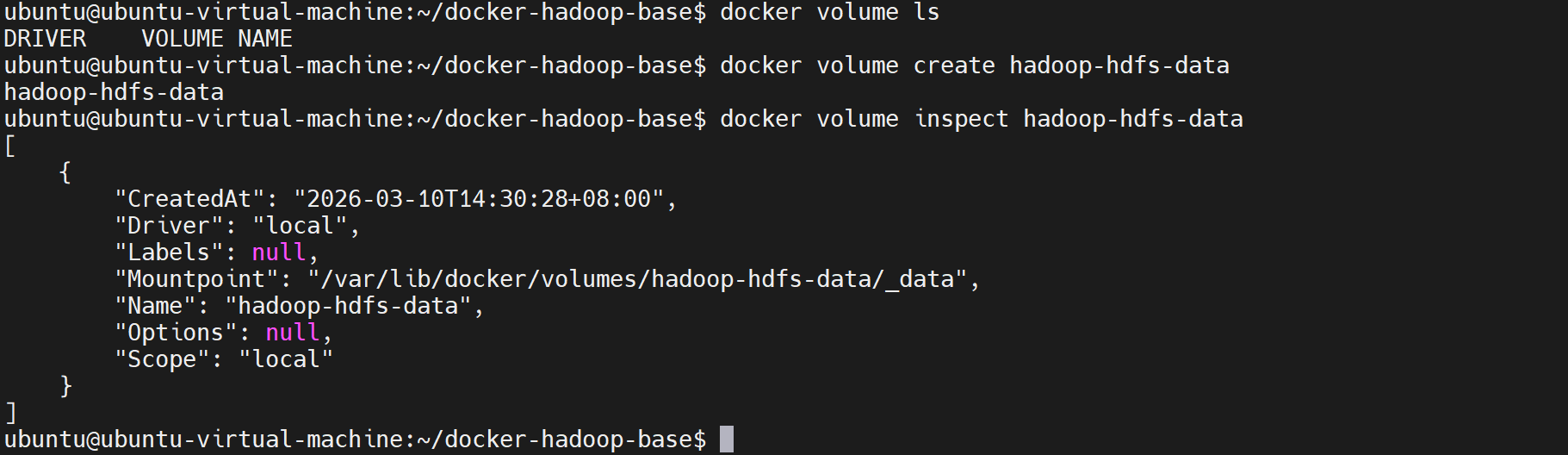
2. 挂载数据命名卷到容器
bash
# \ # hadoop-hdfs-data数据命名卷→容器目录
docker run -d --name hadoop-namenode --network hadoop-network -v hadoop-hdfs-data:/opt/hadoop/data hadoop-base:ubuntu22.04名称冲突的解决办法
方案 1:删除旧容器,重新创建(推荐,全新配置)
适合旧容器还未配置 Hadoop,只是空的基础容器的场景,步骤
# 1. 停止并删除旧的hadoop-namenode容器(释放名称)
docker stop hadoop-namenode
docker rm hadoop-namenode
# 2. 重新启动容器(带数据卷挂载)
docker run -d --name hadoop-namenode --network hadoop-network --ip 172.18.0.2 -v hadoop-hdfs-data:/opt/hadoop/data hadoop-base:ubuntu22.04方案 2:给旧容器挂载数据卷(不删除,复用旧容器)
如果旧容器已有部分配置,不想删除,可通过docker run的替代方案给运行中的容器挂载数据卷(需借助工具,步骤稍复杂):
# 1. 先停止旧容器
docker stop hadoop-namenode
# 2. 提交旧容器为新镜像(保留原有配置)
docker commit hadoop-namenode hadoop-namenode:temp
# 3. 删除旧容器
docker rm hadoop-namenode
# 4. 基于新镜像启动容器(挂载数据卷)
docker run -d --name hadoop-namenode --network hadoop-network --ip 172.18.0.2 -v hadoop-hdfs-data:/opt/hadoop/data hadoop-namenode:temp
# 5. (可选)删除临时镜像(清理资源)
docker rmi hadoop-namenode:temp3. 数据卷常用操作
bash
# 删除数据卷(需先停止容器)
docker volume rm hadoop-hdfs-data
# 清理所有未使用数据卷(释放空间)
docker volume prune -fDocker 3种数据挂载方式核心对比(Hadoop视角)
| 挂载方式 | 语法示例 | 存储位置(宿主机) | 核心特点 | Hadoop场景适配性 |
|---|---|---|---|---|
| 命名卷(你用的方式) | -v hadoop-hdfs-data:/opt/hadoop/data |
/var/lib/docker/volumes/hadoop-hdfs-data/_data(Docker管理) |
1. 由Docker统一管理,无需手动建目录; 2. 名称直观(hadoop-hdfs-data),易管理; 3. 容器删除后卷仍保留,数据不丢; 4. 权限适配友好(Docker自动处理)。 | ✅ 推荐(生产/测试都适用,数据安全易管理) |
| 匿名卷 | -v /opt/hadoop/data |
/var/lib/docker/volumes/随机ID/_data(Docker管理) |
1. 无自定义名称,靠随机ID标识; 2. 数据也持久化,但难以区分(比如分不清是NameNode还是DataNode的卷); 3. 容器删除后卷仍保留,但不易定位。 | ❌ 不推荐(Hadoop多节点易混淆) |
| 宿主机目录挂载 | -v ~/hadoop-data:/opt/hadoop/data |
~/hadoop-data(用户指定的宿主机目录) |
1. 数据存在宿主机自定义目录,直观可见; 2. 需手动创建目录,且要处理权限(如容器内用户无读写权限); 3. 跨主机迁移麻烦(目录路径可能不一致)。 | ⚠️ 可选(测试环境方便查看数据,生产需注意权限) |
关键区别拆解(针对你的Hadoop场景)
1. 命名卷 vs 宿主机目录挂载(新手最易混淆)
你之前用过 -v ~/hadoop-data:/opt/hadoop/data(宿主机目录挂载),和现在的命名卷核心区别:
| 维度 | 命名卷(hadoop-hdfs-data:/opt/...) | 宿主机目录挂载(~/hadoop-data:/opt/...) |
|---|---|---|
| 目录创建 | Docker自动创建,无需手动操作 | 需手动创建~/hadoop-data,否则可能报错 |
| 权限问题 | Docker自动适配容器内用户权限 | 易出现权限错误(如容器内ubuntu用户无法读写宿主机目录) |
| 数据管理 | 用docker volume ls/inspect/rm管理 |
用Linux命令(ls/rm/mkdir)管理,易误删 |
| 跨环境迁移 | 可通过docker volume export导出,适配性强 |
需手动拷贝目录,跨主机路径可能不一致 |
| 直观性 | 需用docker volume inspect看路径 |
直接在宿主机~/hadoop-data看到数据,更直观 |
2. 命名卷 vs 匿名卷
匿名卷是命名卷的"无名称版本",比如 -v /opt/hadoop/data:
- 缺点:Docker会生成随机ID作为卷名(如
0f987654321),后续想查"哪个卷是NameNode的",需要逐个inspect,对Hadoop多节点集群来说极不友好; - 场景:仅适合临时存储,Hadoop集群完全不推荐。
Hadoop部署的挂载方式选择建议
- 测试环境 :
可选「宿主机目录挂载」(-v ~/hadoop-namenode-data:/opt/hadoop/data),方便直接在宿主机查看/修改HDFS元数据、日志,调试更高效; - 生产/正式集群 :
优先选「命名卷」(-v hadoop-namenode-data:/opt/hadoop/data),Docker统一管理,权限问题少,数据安全且易维护; - 绝对避免 :
匿名卷(无名称),多节点场景下根本无法区分数据归属。
实操验证(区分两种挂载)
1. 查看命名卷(你用的方式)
bash
# 列出所有命名卷
docker volume ls
# 查看hadoop-hdfs-data的详情(含宿主机路径)
docker volume inspect hadoop-hdfs-data2. 查看宿主机目录挂载
bash
# 直接查看宿主机目录
ls ~/hadoop-data
# 查看容器挂载详情(区分卷类型)
docker inspect hadoop-namenode | grep -E "Type|Source|Destination"
# 命名卷的Type是"volume",宿主机目录挂载的Type是"bind"总结
- 核心结论:你这条命令用的就是「命名卷挂载」,不存在"这种方式和命名卷的区别";
- 关键区分:重点区分「命名卷」和「宿主机目录挂载」------前者Docker管,易维护;后者用户管,易调试;
- Hadoop适配:测试用宿主机目录挂载,正式环境用命名卷,绝对避免匿名卷。
掌握这三种挂载方式的区别,后续部署Hadoop分布式集群时,能根据场景灵活选择,既保证数据持久化,又避免权限/管理坑。
七、核心操作验证(确保掌握)
执行以下步骤,验证所有核心技能是否掌握:
- 创建自定义网络
hadoop-network; - 基于
hadoop-base:ubuntu22.04启动2个容器(namenode/datanode1),加入该网络并指定固定IP; - 给
namenode挂载数据卷hadoop-hdfs-data; - 进入
namenode容器,pingdatanode1(能通则网络正常); - 停止并删除所有容器,删除数据卷和自定义网络。
总结
- 核心技能:镜像构建(Dockerfile)、容器启停/进入、自定义网络配置、数据卷挂载是Hadoop部署的4个核心前置技能;
- 关键原则:Hadoop容器需保证「网络互通、IP固定、数据持久化、端口可访问」;
- 后续复用:本教程的Dockerfile、容器启动命令、网络配置可直接复用在Hadoop部署中,只需填充JDK/Hadoop相关内容。
掌握以上内容,后续部署Hadoop时,只需聚焦Hadoop本身的配置,Docker层面的操作不会成为障碍。