1. Kotlin 的作用域函数
1.1 作用域函数的核心共性
所有作用域函数(let、run、with、apply、also)都有以下几个核心特点:
- 创建临时作用域:把对象的操作逻辑封装的 Lambda 中,代码更内聚;
- 简化对象引用:在作用域内用简洁的方式(
it或this)指代目标对象,避免重复写变量名; - 空安全友好: 除了
with,其余的都能结合?.实现"对象非空才执行逻辑";
1.2 核心作用域函数详解
1.2.1 let 函数
- 上下文对象:通过
it访问(可自定义名称); - 返回值:Lambda 表达式的最后一行;
- 核心场景:
- 处理可空对象(
?.let),避免空指针; - 对对象做转换、计算,需要返回新结果;
- 不想重复写对象名,且需要把对象作为参数传递;
- 处理可空对象(
代码示例:
kotlin
val str: String? = "Kotlin"
// 场景:可空对象处理 + 转换结果
val result = str?.let { nonNullStr ->
"原始字符串:$nonNullStr, 长度:${nonNullStr.length}"
} ?: "字符串为空"
println(result) // 原始字符串:Kotlin, 长度:61.2.2 run 函数(扩展形式)
- 上下文对象:通过
this访问(可省略); - 返回值:Lambda 表达式的最后一行;
- 核心场景:
- 操作可空对象的属、方法,(比
let更简洁,无需it); - 对对象执行多步逻辑,最终返回一个计算结果;
- 操作可空对象的属、方法,(比
代码示例:
kotlin
val user: User? = User("Eileen", 30)
// 场景:操作对象属性 + 返回计算结果
val userDesc = user?.run {
age += 1 // 直接操作属性(this.age,省略 this)
"姓名: $name, 更新后年龄: $age" // 返回自定义结果
} ?: "用户为空"
println(userDesc) // 姓名: Eileen, 更新后年龄: 311.2.3 with 函数
- 上下文对象:通过
this访问(可省略) - 返回值:Lambda 表达式的最后一行;
- 核心场景:
- 操作非空对象的多个属性、方法(避免重复写对象名);
- 注意:
with不是扩展函数,不能直接结合?.,如果对象可能为空,需先判空;
代码示例:
kotlin
val list = listOf("A", "B", "C")
// 场景:操作非空对象的多个方法
val listInfo = with(list) {
"列表大小: $size, 第一个元素: ${first()}" // 省略 this
}
println(listInfo) // 列表大小: 3, 第一个元素: A
// 处理可空对象(需先判空)
val nullableList: List<String>? = null
val nullableInfo = if (nullableList != null) {
with(nullableList) {
"列表大小: $size"
}
} else {
"列表为空"
}1.2.4 apply 函数
- 上下文对象:通过
this访问(可省略); - 返回值:上下文对象本身;
- 核心场景:
- 对象初始化(设置多个属性);
- 对对象做修改,但需要返回对象本身(链式调用)
- 可空对象处理(
?.apply)
代码示例:
kotlin
// 场景 1: 对象初始化(最常用)
val person = User().apply {
name = "Eileen" // 省略 this
age = 34
gender = "女"
}
// person 是初始化后的对象本身
// 场景 2: 修改对象 + 链式调用
val strBuilder = StringBuilder().apply {
append("Hello")
append(" Kotlin")
}.toString() // 先 apply 修改,再调用 toString
println(strBuilder) // Hello Kotlin1.2.5 also 函数
- 上下文对象:通过
it访问(可自定义名称) - 返回对象:上下文对象本身
- 核心场景:
- 对对象执行"附加操作"(如打印日志、保存数据),但不改变对象本身;
- 链式调用中,在不改变返回值的前提下添加副作用;
- 可空对象处理(
?.also);
示例代码:
kotlin
val numbers = mutableListOf(1, 2, 3)
// 场景 1:附加操作 + 返回对象本身
val newNumbers = numbers.also {
println("原始列表: $it") // 附加操作:打印日志 输出:原始列表: [1, 2, 3]
it.add(4) // 修改对象(可选)
}
println(newNumbers) // [1, 2, 3, 4]
// 场景 2:链式调用
val result = mutableListOf<Int>()
.also { println("开始添加元素") }
.apply { add(1);add(2) }
.also { println("添加完成,当前列表: $it") } // 添加完成,当前列表: [1, 2]
.sum()
println(result) // 31.3 快速区分(核心对比)

选择建议:
- 如果我们想要 初始化对象或操作对象的属性、方法 ,并且不需要返回值,使用
apply; - 如果我们需要 转换对象、在对象上下文中计算结果 ,使用
let(用it)或run(用this); - 如果我们想要 对一个非空对象执行 Lambda ,
let与安全调用符?.是绝配; - 如果我们想要 对已经存在的对象调用多个函数 ,可以用
with; - 如果我们需要 对对象进行附加操作(如打印日志、校验等) ,且不影响对象本身,使用
also; - 如果我们需要 处理可空对象 ,优先用
?.let/?.run/?.apply/?.also,避免with;
2 Kotlin 空安全机制
Kotlin 把可空类型和非空类型做了明确的语法区分,编译器会在编译期就检查可能出现空指针的代码,而不是等到运行时才抛出异常。
2.1 非空类型 vs 可空类型
2.1.1 非空类型(默认)
在 Kotlin 中,所有变量默认都是非空的,我们不能给它赋值 null,编译器会直接报错:
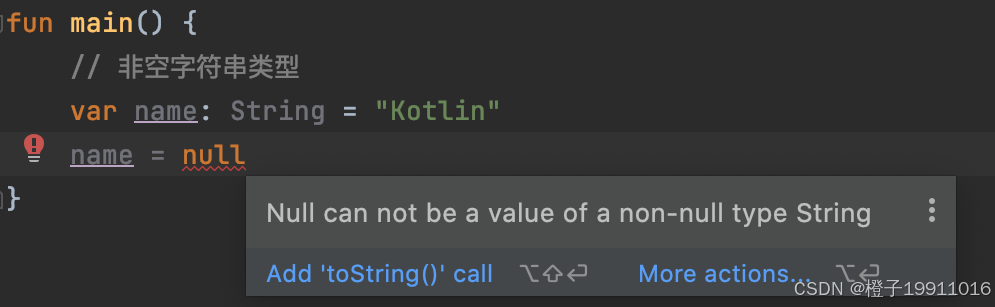
2.1.2 可空类型(显式声明)
如果需要变量能接收 null,必须在类型后加 ? 声明为可空类型:
kotlin
// 可空字符串类型
var nullableName: String? = "Kotlin"
// 合法:可空类型可以赋值 null
nullableName = null2.2 如何安全的操作可空类型
Kotlin 的空安全机制是其核心特性之一,旨在编译期消除空引用异常(NPE,NullPointerException)(编译器校验空安全)。
声明了可空类型后,直接调用它的属性、方法会编译报错(NPE)。Kotlin 提供了多种安全操作方式。
2.2.1 安全调用操作符 ?.
当调用可空对象的属性或方法时,可以使用 ?.。如果对象不为空,则执行,否则直接返回 null:
kotlin
val nullableName: String? = null
// 安全调用:nullableName 为 null,结果为 null,不会报错
var length: Int? = nullableName?.length
println(length) // null
val nonNullName: String? = "Java"
val nonNullLength = nonNullName?.length
println(nonNullLength) // 4
// 链式调用
val city: String? = user?.address?.city2.2.2 埃尔维斯操作符 ?:(猫王表情操作符)
用于为可空表达式提供一个默认值。如果左侧表达式结果非空,则返回该值,否则,返回右侧表达式:
kotlin
val nullableName: String? = null
// 如果 nullableName 为 null,返回默认值 "Unknown"
val realName = nullableName ?: "Unknown"
println(realName) // Unknown
// 组合使用:先安全调用获取长度,为空则返回 0
val length = nullableName?.length ?: 0
println(length) // 02.2.3 非空断言操作符 !!
将任意值转换为非空类型,相当于强制告诉编译器:"我确定这个变量不为 null,出问题我自己负责"。如果变量实际为 null,运行时会抛出 NPE(谨慎使用):
kotlin
val nullableName: String? = null
// 运行时抛出 NPE:KotlinNullPointerException
val length = nullableName!!.length2.2.4 let 函数/run 函数(处理可空变量)
常用于对可空变量执行一段逻辑,仅当变量非空时才会执行 let /run内的代码:
kotlin
val nullableName: String? = "Kotlin"
nullableName?.let {
// it 代表非空的 nullableName
println("名字是: $it, 长度: ${it.length}") // 名字是: Kotlin, 长度: 6
}
val nullName: String? = null
nullName?.let {
// 变量为 null,此代码块不会执行
println(it)
}
val name: String? = "Android"
// 安全调用
val length = name?.length ?: 0 // 空则返回 0
// let 作用域
name?.let {
println("名称: $it") // 名称: Android
}2.2.5 智能类型转换(if 判断)
通过 if 显式检查变量是否为 null 后,编译器会自动将可空类型转换为非空类型:
kotlin
val nullableName: String? = "Kotlin"
if (nullableName != null) {
// 编译器智能识别:此处 nullableName 已是非空类型,可直接调用 length
val length = nullableName.length
println(length) // 6
}3 suspend 函数原理(协程),挂起与阻塞的区别
suspend仅标记函数可被挂起,不阻塞线程,挂起时释放线程资源;- 阻塞:线程暂停执行,资源被占用;挂起:协程暂停,线程可处理其他任务;
- 只能在协程/其他 suspend 函数中调用;
3.1 协程的本质
协程是轻量级的线程,但本质上它不是线程 ------ 它是运行在线程上的可暂停/恢复的执行单元。
线程是操作系统级别的调度单位,而协程是 Kotlin 层面的调度,完全由用户态代码控制,无需操作系统介入。
3.2 suspend 函数的底层原理
suspend 关键字翻译过来就是"挂起"。
用 suspend 关键字修饰的函数叫挂起函数,它可以在不阻塞线程的情况下暂停执行,并在未来的某个时刻恢复。挂起函数只能在协程或其他挂起函数中调用。
从语法上看,suspend 只是给函数加了一个标记:
- 被
suspend标记的函数只能在协程体或另一个suspend函数中调用; - 普通函数不能直接调用
suspend函数(编译器会报错);

Kotlin 编译器会对 suspend 函数做底层转换,核心是「CPS(Continuation - Passing Style)续体传递」:
- 续体(Continuation):可以理解为"函数执行到一半被暂停时,保存的执行状态"(比如局部变量、下一步要执行的代码位置);
- 转换过程:编译器会把
suspend函数的签名改写,额外增加一个 Continuation 参数,用于保存/恢复执行状态;
suspend 原理:本质是编译器通过 CPS 转换,给函数增加续体(Continuation)参数,实现"暂停时保存状态、恢复时继续执行"且不会阻塞线程。
Continuation 是一个接口,代表程序在某个点之后的"剩余计算"。它包含一个 resumeWith 方法,用于在挂起恢复后继续执行:
kotlin
@SinceKotlin("1.3")
public interface Continuation<in T> {
public val context: CoroutineContext
public fun resumeWith(result: Result<T>)
}编译器会将每个挂起函数转换为一个带有额外 Continuation 参数的函数。这个 Continuation 参数用于在函数挂起后,当结果准备好时恢复执行。
执行流程:
- 协程执行到
fetchData(),调用delay(1000); delay是挂起函数,它会:- 保存当前协程的执行状态(比如"执行完
fetchData后要执行println")到Continuation; - 释放当前线程(比如 Main 线程),让线程去处理其他任务(比如 UI 刷新);
- 保存当前协程的执行状态(比如"执行完
- 1000ms 后,协程调度器会拿之前保存的
Continuation,在合适的线程(比如还是 Main 线程)恢复协程执行; fetchData()继续执行,返回结果,最终执行println(data);
挂起 ≠ 线程阻塞:挂起函数执行时,不会阻塞它所在的线程 ------ 线程会被释放去做其它事,直到挂起函数完成后,协程再恢复执行。
3.3 挂起(suspend)和阻塞(block) 的核心区别
挂起 vs 阻塞:核心区别是线程是否被释放 ------ 挂起释放线程(线程可做其它事),阻塞卡住线程(线程无响应)。

代码示例:
kotlin
// 场景 1: 阻塞(Thread.sleep)------ 主线程卡死 1s
CoroutineScope(Dispatchers.Main).launch {
println("开始阻塞")
Thread.sleep(1000) // 阻塞主线程,UI 完全卡死
println("阻塞结束")
}
// 场景 2: 挂起(delay)------ 主线程不阻塞,UI 正常响应
CoroutineScope(Dispatchers.Main).launch {
println("开始挂起")
delay(1000) // 挂起协程,主线程释放去处理 UI,1s 后恢复
println("挂起结束")
}底层逻辑对比:
Thread.sleep(1000):操作系统把当前线程标记为"阻塞态",1s 内这个线程什么都做不了,只能等待,直到超时后被唤醒;delay(1000):Kotlin 协程框架把当前协程的执行状态保存下来,然后让线程回到"就绪态",继续处理其它任务(比如点击事件、页面刷新),1s 后再让协程在这个线程上恢复执行;
3.4 挂起函数调度器(Dispatchers)
挂起函数的恢复线程由调度器(Dispatcher)决定,这也是协程灵活的关键:
Dispatchers.Main:恢复到主线程(Android 常用);Dispatchers.IO:恢复到 IO 线程池(适合网络/文件操作);Dispatchers.Default:恢复到 CPU 密集型线程池(适合计算);
代码示例:
kotlin
suspend fun fetchData(): String {
// withContext 指定调度器,执行耗时 IO 操作
return withContext(Dispatchers.IO) {
// 这里的代码运行在 IO 线程,挂起时不会阻塞主线程
val result = api.requestData() // 网络请求(挂起)
result
}
}4 Flow 与 LiveData 选型场景
4.1 核心定位
!LIveData vs Flow(https://i-blog.csdnimg.cn/direct/bd81557aced74dfd8aa7fb6fd8bf6834.png#pic_center#pic_center 1080%x100%)
LiveData vs Flow
- LiveData:生命周期感知、仅支持 Android 平台、简单易用、总是接收主线程通知、不支持线程切换、数据粘性等;
- Flow:背压支持、丰富的操作符、冷流/热流、可指定线程调度、独立于生命周期、可组合、与协程无缝集成、支持多种数据流类型(StateFlow / SharedFlow);
冷流 vs 热流:
- 冷流(Cold Flow): 是惰性的,每次收集(
collect)时才开始执行,产生数据,每个收集者会触发一次全新的数据流发射,收到独立的数据流; - 热流(Hot Flow): 是活跃的,是独立于收集者/订阅者存在的数据流,它能够主动向多个收集者/订阅者发送数据,并且多个收集者/订阅者共享数据。即使没有收集者/订阅者,热流也可以产生和缓存数据,适用于状态管理和事件分发;
StateFlow vs SharedFlow:
- StateFlow: 专注于保存和分发"状态"(比如 UI 显示的文本、按钮是否可点击、列表数据),是 LiveData 的直接替代;
- SharedFlow: 专注于分发"事件"(比如弹窗提示、页面跳转、Snackbar 显示),适合一次性、无需缓存的通知类场景;

4.2 核心场景
场景 1:UI 层观察数据(Activity/Fragment)
优先选 LiveData/StateFlow(StateFlow 是 Flow 的热流变体,专为 UI 状态设计):
- 如果是简单的 UI 状态(比如按钮是否可点击、文本内容),且项目未大量使用协程 ------ 用 LiveData,上手简单,原生适配生命周期;
- 如果项目已全面使用协程,且需要对数据做简单转换 ------ 用 StateFlow,结合
repeatOnLifecycle实现生命周期感知,比 LiveData 更灵活;
代码示例(StateFlow + 生命周期感知):
kotlin
// ViewModel 中定义 StateFlow
class TestViewModel : ViewModel() {
private val _uiState = MutableStateFlow("初始状态")
val uiState: StateFlow<String> = _uiState
fun updateState(newState: String) {
_uiState.value = newState
}
}
class TestActivity : AppCompatActivity() {
private val viewModel by viewModels<TestViewModel>()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_test)
// repeatOnLifecycle 确保在 RESUMED 状态才收集,PAUSED 时取消
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.RESUMED) {
viewModel.uiState.collect { state ->
// 更新 UI(自动在主线程)
}
}
}
}
}场景 2:数据层/域层处理异步数据(Repository/UseCase)
必须选 Flow:数据层需要处理复杂的异步逻辑(比如网络请求 + 数据库缓存、数据过滤/合并/重试、批量数据处理),LiveData 操作符极少,无法满足;Flow 的丰富操作符能优雅的解决这些问题。
代码示例(Repository 中用 Flow 处理网络 + 本地数据):
kotlin
class TestRepository(private val api: TestApi, private val db: TestDao) {
fun getTestFlow(id: String): Flow<Test?> {
return flow {
// 1. 先发射本地缓存数据
emit(db.getTest(id))
// 2. 网络请求更新数据(flowOn 指定 IO 线程)
val remoteTest = api.getTest(id)
// 3. 保存到本地
db.insertTest(remoteTest)
// 4. 发射最新网络数据
emit(remoteTest)
}.flowOn(Dispatchers.IO) // 发射数据的线程
.catch { e -> // 异常处理
Log.e("Repo", "获取用户失败", e)
emit(null) // 发射默认值
}
}
}场景 3:跨平台/非 Android 场景(比如 Kotlin/JVM 后端)
只能选 Flow:LiveData 是 Android 框架专属,Flow 是 Kotlin 标准库的一部分,支持所有 Kotlin 平台。
场景 4:一次性异步请求(比如单次网络请求)
优先选 Flow(或 suspend 函数):LiveData 适合"持续变换的状态",一次性请求 Flow 更加贴切(冷流特性、订阅时执行,取消订阅时停止)。
代码示例:
kotlin
// 一次性请求:获取用户详情
suspend fun getUserDetail(userId: String): User {
return withContext(Dispatchers.IO) {
api.getUserDetail(userId)
}
}
// 或用 Flow 包装(支持重试/异常处理)
fun getUserDetailFlow(userId: String): Flow<User> {
return flow {
emit(api.getUserDetail(userId))
}.retry(2) // 失败重试 2 次
.flowOn(Dispatchers.IO)
}场景 5:需要共享数据流(多观察者订阅同一数据源)
选 StateFlow/SharedFlow(Flow 的热流变体):LiveData 本质是热流,但 Flow 的 StateFlow(单值状态)/SharedFlow(多值事件)功能更强大(支持缓存、重试、背压)。
代码示例:
kotlin
class TestViewModel : ViewModel() {
// 发送 Snackbar 提示事件(一次性、不保存状态)
private val _snackbarEvent = MutableSharedFlow<String>()
val snackbarEvent: SharedFlow<String> = _snackbarEvent
fun showSnackbar(message: String) {
viewModelScope.launch {
_snackbarEvent.emit(message)
}
}
}
// Activity 中观察
class TestActivity : AppCompatActivity() {
private val viewModel by viewModels<TestViewModel>()
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_test)
lifecycleScope.launch {
repeatOnLifecycle(Lifecycle.State.RESUMED) {
viewModel.snackbarEvent.collect { message ->
// 更新 UI
}
}
}
}
}4.3 选型总结建议
- UI 层状态观察:简单场景 ------ LiveData,协程项目/需要灵活操作 ------ StateFlow(替代 LiveData)
- 数据层 / 复杂异步处理:必须 Flow,操作符丰富,异常处理强;
- 一次性异步请求:选
suspend函数 + Flow,带重试、异常处理; - 跨平台 / 非 Android:必选 Flow;
- 多观察者共享数据流:选 StateFlow(状态)/ SharedFlow(事件);
4.4 总结
Flow 与 LiveData 选型的核心要点:
- LiveData:优势是原生生命周期感知,适合 Android UI 层简单状态观察,上手成本低,但功能单一;
- Flow:优势是通用、灵活、功能丰富,适合所有异步数据处理场景(尤其是数据层),结合 StateFlow / SharedFlow +
repeatOnLifecycle完全可以替代 LiveData; - 趋势:Jetpack 官方推荐用 StateFlow / SharedFlow 替代 LiveData(更贴合协程生态,功能更强),新项目建议优先给予 Flow 构建数据流;
在 Android 开发中,LiveData 适合简单的 UI 数据绑定,Flow 适合复杂的数据处理和业务层。但现在 Google 推荐在 ViewModel 中使用 StateFlow / SharedFlow 代替 LiveData,配合生命周期安全收集。新项目可以优先考虑 Flow。
5 volatile 与 synchronized 区别
5.1 核心定位
两者都是解决多线程并发安全问题的手段,但有所不同:
volatile:轻量级关键字,主要保证可见性,禁止指令重排序,但不保证原子性;- 修饰变量,强制线程每次从内存中读取,写操作直接写入主内存,防止指令重排;
synchronized:重量级锁机制,可以保证可见性和原子性;- 修饰方法或代码块,保证同一时刻只能有一个线程执行,同时保证变量的可见性(进入
synchronized块会刷新缓存,退出时会写入主内存);
- 修饰方法或代码块,保证同一时刻只能有一个线程执行,同时保证变量的可见性(进入
volatile vs synchronized:

可见性、原子性、有序性:
- 可见性: 一个线程修改的变量,其它线程能否看到最新值(默认情况下,线程会缓存变量到工作内存,修改后不会立即同步到主内存);
- 原子性: 一个操作或多个操作要么全部执行且执行过程不被中断,要么全部不执行;
- 有序性: 程序执行顺序按代码书写顺序执行(编译器 / CPU 会优化指令重排序,可能导致多线程下执行顺序错乱);
5.2 volatile 原理
- 可见性: Java 内存模型(JNM)规定,所有变量存储在主内存,每个线程有自己的工作内存。线程对变量的操作必须在工作内存中进行,不能直接读写内存。
volatile修饰的变量,每次使用前都必须从主内存刷新,每次修改后必须立即写回主内存,从而保证多线程间的可见性; - 禁止重排序:
volatile通过插入内存屏障指令,防止编译器或 CPU 对指令进行重排序,确保程序执行顺序符合预期(尤其对单例双重检查至关重要);
5.3 synchronized 原理
- 可见性: 线程在进入同步块时,会清空工作内存中共享变量的副本,重新从主内存加载;退出同步块时,会将工作内存中的修改刷新到主内存;
- 原子性: 通过 monitorenter 和 monitorexit 指令实现,任何时刻只有一个线程能进入同步块;
- 锁优化: JDK 1.6 后引入偏向锁、轻量级锁、重量级锁的升级过程,减少性能开销;
5.4 双重校验锁(Double - Checked Locking,DCL)单例
Kotlin 版本:
kotlin
class Singleton private constructor() {
companion object {
// 关键:必须加 @Volatile 注解
@Volatile
private var instance: Singleton? = null
fun getInstance(): Singleton {
// 第一次校验:避免每次获取实例都加锁(提高性能)
if (instance == null) {
// 加锁:保证同一时间只有一个线程进入初始化逻辑
synchronized(Singleton::class.java) {
// 第二次校验:防止多个线程等待锁后重复初始化
if (instance == null) {
instance = Singleton() // 核心:这行代码会被指令重排序
}
}
}
return instance!!
}
}
}Java 版本:
java
public class Singleton {
// 关键:必须加 volatile 关键字
private volatile static Singleton instance;
private Singleton() {
}
public static Singleton getInstance() {
if (instance == null) {
synchronized (Singleton.class) {
if (instance == null) {
instance = new Singleton(); // 指令重排序的风险点
}
}
}
return instance;
}
}核心问题:instance = new Singleton() 的指令重排序
- 指令 1:分配内存空间(
memory = allocate()); - 指令 2:初始化对象(
ctorInstance(memory)); - 指令 3:将
instance引用指向分配的内存地址(instance = memory);
关键是:JVM 允许"指令重排序",为了优化性能,JVM / CPU 可能会调整指令执行顺序。 比如把上述指令重排为:
- 分配内存空间(指令 1);
- 将
instance引用指向内存地址(指令 3); - 初始化对象(指令 2);
这种重排序在单线程下完全没问题,但是在多线程下会导致致命问题 ------ 获取到"未初始化完成"的对象。
假设存在线程 A 和线程 B,执行流程如下:
- 线程 A 进入
synchronized代码块,执行instance = new Singleton(),JVM 重排序指令:先执行「分配内存 + 引用指向内存」(指令 1,3),还没有初始化对象(指令 2); - 此时,
instance引用已经不为null(指向了一块未初始化的内存); - 线程 B 执行第一次校验
if(instance == null),发现instance不为null,直接返回这个"未初始化完成"的对象; - 线程 B 尝试调用这个对象的方法,由于对象还未初始化完成,会抛出空指针异常或其他未知错误;
volatile 解决的问题是:禁止指令重排序
- 给
instance变量加了volatile后,JVM 会在写该变量时插入「内存屏障(Memory Barrier)」; - 内存屏障会强制保证:
instance = new Singleton()的 3 个指令必须按「分配内存 ---> 初始化对象 ---> 引用指向内存」的顺序,不允许重排序; - 这样一来,只有当对象完全初始化完成后,
instance引用才会被赋值,其他线程永远不会获取到"未初始化完成"的对象;
为什么需要"双重校验"?
- 第一次判空:避免每次获取实例都进入
synchronized代码快(加锁/解锁都有性能开销), 只有实例未初始化时才加锁,提升并发性能; - 第二次判空:防止多个线程同时等待
synchronized锁, 比如线程 A 初始化完成后,线程 B 拿到锁,此时,第二次判空就会发现instance已不为null,避免重复初始化;
总结:
- 根本原因:
new Singleton()会被 JVM 指令重排序,导致多线程下可能获取"未初始化完成"的对象; volatile的作用:通过内存屏障禁止指令重排序,保证对象完全初始化后,instance引用才会被赋值;- 额外提醒:双重校验锁的"双重判空"是为了性能 + 避免重复初始化,而
volatile是为了解决指令重排序的并发安全问题,两者缺一不可;
6 ThreadLocal 原理与内存泄漏风险
6.1 ThreadLocal 核心原理
ThreadLocal 直译是"线程本地变量",核心作用是为每个线程创建独立的变量副本,让多线程操作时互不干扰。(解决多线程共享变量的并发安全问题,和 synchronized "锁资源"的思路完全不同)。
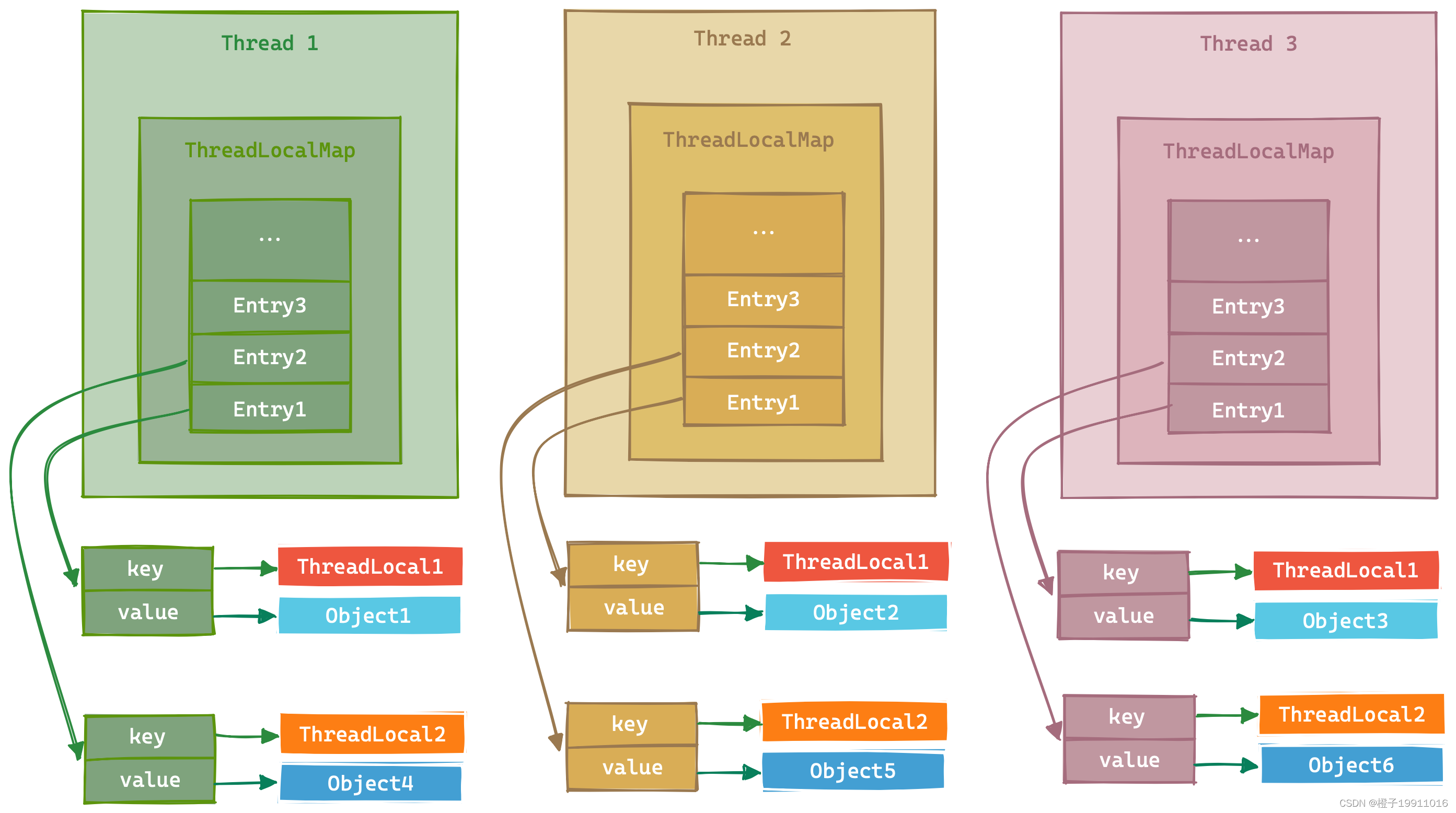
Thread(线程)
---> ThreadLocalMap(线程持有的 Map)
---> Entry(键值对)
---> key = ThreadLocal 实例,value = 变量副本6.2 底层原理
6.2.1 Thread 类持有 ThreadLocalMap
每个 Thread 实例内部都维护了一个 ThreadLocalMap(一个定制的哈希表) 类型的成员变量(threadLocals):
java
public class Thread implements Runnable {
// 每个线程独有自己的 ThreadLocalMap
ThreadLocal.ThreadLocalMap threadLocals = null;
}6.2.2 ThreadLocalMap 是 ThreadLocal 的静态内部类
ThreadLocalMap 的核心作用是存储"ThreadLocal 实例 ---> 变量副本" 的映射。它的 Entry 继承 WeakReference<ThreadLocal<?>>,key 是 ThreadLocal 实例(弱引用),value 是存储的值。
- 键(key): ThreadLocal 实例,是弱引用,这是内存泄漏的关键;
- 值(value): 线程专属的变量的副本(强引用);
java
public class ThreadLocal<T> {
static class ThreadLocalMap {
static class Entry extends WeakReference<ThreadLocal<?>> {
/** The value associated with this ThreadLocal. */
Object value;
Entry(ThreadLocal<?> k, Object v) {
super(k);
value = v;
}
}
}
}每个线程可以关联多个 ThreadLocal,通过 ThreadLocalMap 存储。
6.2.3 ThreadLocal 的核心方法实现
ThreadLocal 对外暴露的 set(T value)/get()/remove 方法,本质是操作当前线程的 ThreadLocalMap:
set(T value): 获取当前线程的 ThreadLocalMap,若map存在,则以当前 ThreadLocal 实例为key存入value,若map不存在,则创建并初始化;get(): 获取当前线程的 ThreadLocalMap,以当前 ThreadLocal 为key查找 Entry,若找到,则返回value,若找不到,则调用setInitialValue()并插入;remove(): 移除当前线程中 ThreadLocal 对应的 Entry;
java
public class ThreadLocal<T> {
// 1. 设置变量副本:给当前线程的 ThreadLocalMap 存值
public void set(T value) {
Thread t = Thread.currentThread(); // 获取当前线程
ThreadLocalMap map = getMap(t); // 获取线程的 ThreadLocalMap
if (map != null) {
map.set(this, value); // this = 当前 ThreadLocal 实例(作为 key)
} else {
createMap(t, value); // 初始化 Map
}
}
// 2. 获取变量副本:从当前线程的 ThreadLocalMap 取值
public T get() {
Thread t = Thread.currentThread();
ThreadLocalMap map = getMap(t);
if (map != null) {
ThreadLocalMap.Entry e = map.getEntry(this);
if (e != null) {
@SuppressWarnings("unchecked")
T result = (T)e.value;
return result; // 返回当前线程的专属副本
}
}
return setInitialValue(); // 无值时初始化
}
// 3. 移除变量副本:避免内存泄漏的关键
public void remove() {
ThreadLocalMap m = getMap(Thread.currentThread());
if (m != null) {
m.remove(this);
}
}
}6.2.4 核心特性总结
- 线程隔离:每个线程的变量副本存在自己的 ThreadLocalMap 中,线程间互不干扰;
- 无锁并发:无需加锁,通过"空间换时间"解决并发安全(
synchronized是"时间换空间"); - 典型场景:存储线程专属的上下文(比如数据库连接、用户登录信息,日志追踪 ID);
6.3 ThreadLocal 的内存泄漏风险
ThreadLocal 内存泄漏的根源是「弱引用的 key + 强引用的 value」组合,以及 ThreadLocalMap 的清理机制不及时。
强引用 vs 弱引用:
- 强引用:普通引用(比如
Object obj = new Object()),只要强引用存在,GC 永远不会回收对象; - 弱引用:GC 扫描时,只发现弱引用指向的对象无其它强引用,就会立即回收(不管内存是否充足);
内存泄漏发生的过程:
ThreadLocal 实例失去强引用
------> GC 回收 ThreadLocal 实例,key 是弱引用
------> ThreadLocalMap 中留下"空 key" 的 Entry:key = null, value = 变量副本(强引用)
------> Thread 线程未结束(value 始终被 Thread → ThreadLocalMap → Entry 强引用)
------> value 无法被 GC 回收
------> 内存泄漏关键细节:
- ThreadLocalMap 的
key是 ThreadLocal 的弱引用,目的是避免 ThreadLocal 实例无法被回收; value是强引用的,如果 Thread 线程长期存活(比如线程池中的核心线程),且没有手动移除 Entry,value会一直占用内存,最终会导致内存泄漏;
为什么要设计 key 为弱引用?
如果 key 是最强引用,当 ThreadLocal 实例失去外部强引用后,ThreadLocalMap 仍持有强引用,ThreadLocal 实例永远无法被 GC 回收,导致更严重的内存泄漏。
所以,"key 设为弱引用"是降低内存泄漏风险的设计,而非导致内存泄漏的根本原因,根本原因是 value 的强引用未被清理。
6.4 如何规避 ThreadLocal 内存泄漏
使用完 ThreadLocal 后,调用 remove() 方法清理。
6.4.1 最佳实践:try-finally 保证 remove() 执行
kotlin
// 存储用户登录信息
val userContext = ThreadLocal<String>()
fun doBusiness() {
try {
// 设置线程本地变量
userContext.set("用户 ID:123456")
// 业务逻辑
println("当前线程的用户信息: ${userContext.get()}")
} finally {
// 必须手动移除,释放 value 引用
userContext.remove()
}
}6.4.2 辅助机制:ThreadLocalMap 的自动清理
ThreadLocalMap 本身有一些被动清理逻辑,如在调用 get()/set(T value)/remove() 方法时,ThreadLocalMap 会尝试清理 key 为 null 的 Entry(启发式扫描),当这并不能保证所有过期 Entry 被及时清理。如果线程一直不调用这个方法,泄漏仍可能发生:
ThreadLocal.get()--->ThreadLocalMap.getEntry(this)--->ThreadLocalMap.expungeStaleEntry:清理无效 Entry;ThreadLocal.set()--->ThreadLocalMap.set(this, value)--->ThreadLocalMap.rehash()--->ThreadLocalMap.expungeStaleEntry:清理无效 Entry;
6.5 总结
- 原理:每个 Thread 持有专属的 ThreadLocalMap,
key是 ThreadLocal 的弱引用,value是线程本地变量副本,通过"空间换时间"实现线程隔离; - 内存泄漏根源:
key被 GC 回收后,value仍被 Thread 强引用,且未手动清理,导致value无法回收; - 规避方案:核心是「使用完必须调用
remove()」,结合try - finally保证执行,线程池场景尤其注意;
7 CoroutineScope 与 SupervisorJob 作用
7.1 CoroutineScope(协程作用域):协程的"生命周期管家"
CoroutineScope(协程作用域):为协程提供了一个运行的上下文/协程的作用域容器,所用通过该作用域启动的协程(如 async、launch)都是该作用域的子协程。
7.1.1 核心作用
- 生命周期绑定: 协程作用域会绑定一个 Job,所有在该作用域内启动的协程,都会关联到该 Job 上。这样就可以统一管理一组协程的生命周期,解决"协程失控"问题(如协程泄漏、无法批量取消等);
- 结构性并发: 协程作用域会跟踪其内部的子协程,并确保在作用域完成之前,所有的子协程都已完成(无论成功还是失败)。当作用域被取消时,会自动取消所有子协程;
- 层级管理: 协程作用域将内部协程标记为子协程,遵循「子协程异常会向上取消父协程、父协程取消会向下取消所有子协程」的传播规则,保证作用域的一致性(除非用 SupervisorJob 隔离);
- 上下文统一配置: 可预先配置 Dispatchers(线程)、CoroutineExceptionHandler(异常处理器)等,作用域内所有协程默认继承;
- 提供扩展函数:比如
launch、async等扩展函数,方便在作用域内启动协程; - 避免协程泄漏:比如 Activity 销毁时,取消 CoroutineScope,其他所有协程都会被终止,避免内存泄漏;
代码示例:
kotlin
fun main() = runBlocking {
// 1. 创建协程作用域(默认 Job() + 主线程调度器)
val scope = CoroutineScope(Job() + Dispatchers.Default)
// 2. 作用域内启动多个协程,统一管理
val job1 = scope.launch {
repeat(10) {
delay(100)
println("协程 1 执行中: $it")
}
}
val job2 = scope.launch {
delay(250)
println("协程 2 执行完成")
}
delay(200)
// 3. 取消作用域:批量取消所有子协程
scope.cancel()
println("作用域已取消")
job1.join()
job2.join()
println("所有协程终止")
}
// 协程 1 执行中: 0
// 协程 1 执行中: 1
// 作用域已取消
// 所有协程终止取消 scope 后,协程 1、协程 2 都被终止,协程 1 不会执行到后续循环,协程 2 也不会打印"协程 2 执行完成"。
7.1.2 常见使用场景
- Activity/Fragment 中:Activity/Fragment 绑定
lifecycleScope(自带 CoroutineScope),页面销毁时自动取消所有协程; - ViewModel 中:
viewModelScope是封装好的 CoroutineScope,ViewModel 销毁时自动取消协程; - 普通业务:独立创建 CoroutineScope 管理一组相关协程(比如批量下载任务);
7.2 SupervisorJob(监督作用):协程的"异常隔离器"
SupervisorJob 是 Job 的子类,但是它改变了异常传播的默认行为。普通 Job 在子协程失败时会立即取消父协程和所有的兄弟协程;而 SupervsiorJob 的子协程失败不会影响父协程和其他兄弟协程,只会取消失败的子协程。
SupervisorJob 适用于需要并行执行多个独立任务,且希望一个任务的失败不影响其他任务的场景。例如,同时发起多个网络请求,其中一个失败不应取消其他请求。
普通 Job(异常传播,所有协程终止):
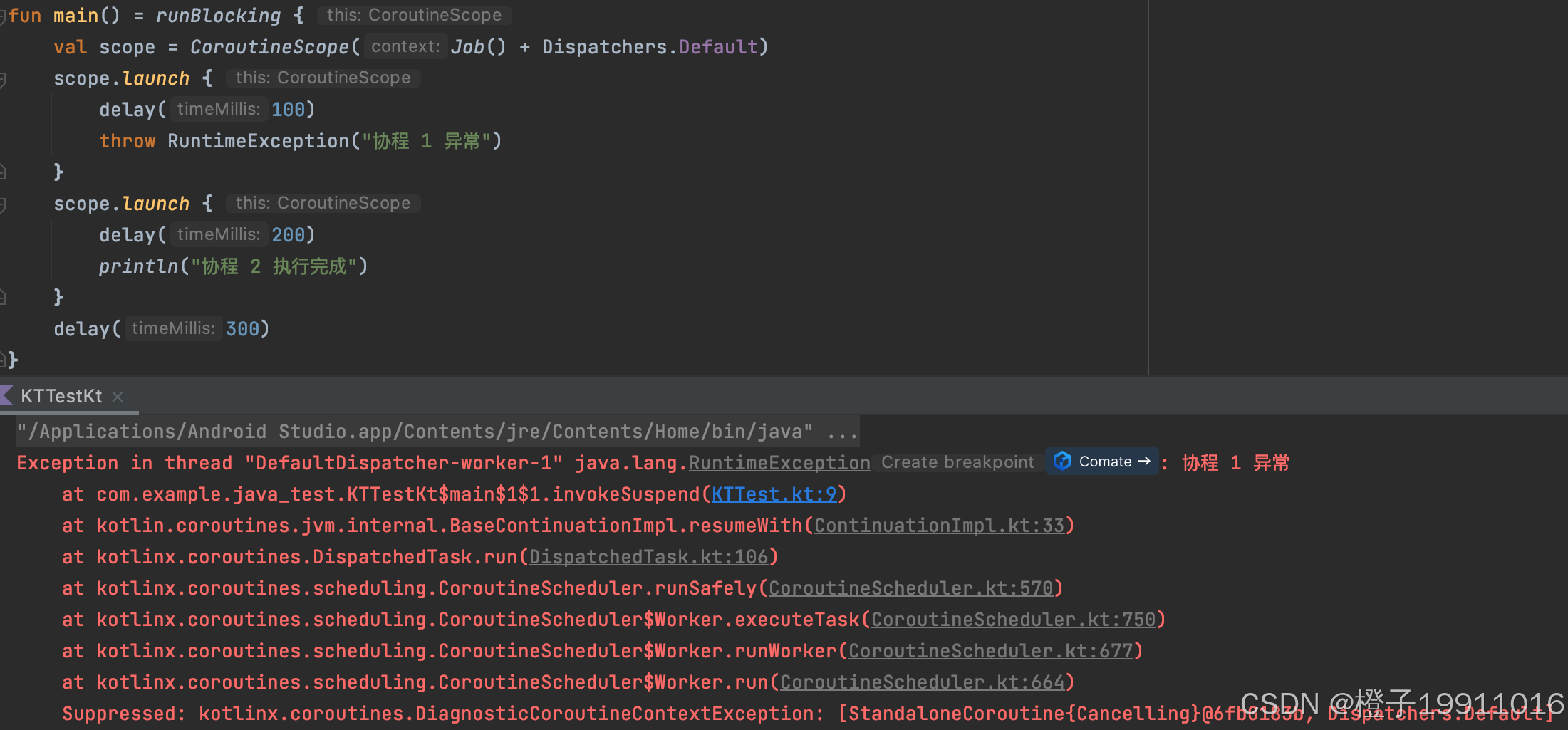
仅输出异常堆栈。
SupervisorJob(异常隔离,其他协程正常执行):

7.3 supervisorScope 与 SupervisorJob 的关系
supervisorScope 是 SupervisorJob 的"便捷封装",作用是:
- 临时创建一个带 SupervisorJob 的作用域;
- 作用域内的协程异常隔离,且
supervisorScope会等待所有子协程完成(即使部分子协程异常);
代码示例:
kotlin
fun main() = runBlocking {
supervisorScope {
launch {
delay(100)
throw RuntimeException("协程 1 异常")
}
launch {
delay(200)
println("协程 2 执行完成")
}
}
println("supervisorScope 执行完成")
}
//Exception in thread "main" java.lang.RuntimeException: 协程 1 异常
//at com.example.java_test.KTTestKt$main$1$1$1.invokeSuspend(KTTest.kt:9)
//at kotlin.coroutines.jvm.internal.BaseContinuationImpl.resumeWith(ContinuationImpl.kt:33)
//at kotlinx.coroutines.DispatchedTaskKt.resume(DispatchedTask.kt:234)
//at kotlinx.coroutines.DispatchedTaskKt.dispatch(DispatchedTask.kt:166)
//at kotlinx.coroutines.CancellableContinuationImpl.dispatchResume(CancellableContinuationImpl.kt:397)
//at kotlinx.coroutines.CancellableContinuationImpl.resumeImpl(CancellableContinuationImpl.kt:431)
//at kotlinx.coroutines.CancellableContinuationImpl.resumeImpl$default(CancellableContinuationImpl.kt:420)
//at kotlinx.coroutines.CancellableContinuationImpl.resumeUndispatched(CancellableContinuationImpl.kt:518)
//at kotlinx.coroutines.EventLoopImplBase$DelayedResumeTask.run(EventLoop.common.kt:500)
//at kotlinx.coroutines.EventLoopImplBase.processNextEvent(EventLoop.common.kt:284)
//at kotlinx.coroutines.BlockingCoroutine.joinBlocking(Builders.kt:85)
//at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking(Builders.kt:59)
//at kotlinx.coroutines.BuildersKt.runBlocking(Unknown Source)
//at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking$default(Builders.kt:38)
//at kotlinx.coroutines.BuildersKt.runBlocking$default(Unknown Source)
//at com.example.java_test.KTTestKt.main(KTTest.kt:5)
//at com.example.java_test.KTTestKt.main(KTTest.kt)
//Suppressed: kotlinx.coroutines.DiagnosticCoroutineContextException: [StandaloneCoroutine{Cancelling}@33723e30, BlockingEventLoop@64f6106c]
//协程 2 执行完成
//supervisorScope 执行完成7.4 CoroutineScope + SupervisorJob:黄金组合
- CoroutineScope 需要 Job: 每个 CoroutineScope 都必须包含一个 Job,作为其上下文的一部分(可以是
Job()、SupervisorJob()或它们与其他元素的组合)。这个 Job 决定了作用域内协程的父子关系以及取消传播行为; - SupervisorJob 可嵌入 CoroutineScope: 当使用
CoroutineScope(SupervisorJob())创建作用域时,该作用域的所有子协程都将以 Supervisor 作为父 Job,从而获得失败隔离性的特性; - SupervisorScope 构建器: Kotlin 提供了
supervisorScope函数,它是一个内置的作用域构建器,内部自动使用了 SupervisorJob,方便快速创建隔离失败的作用域;
典型场景:Android 多接口并行请求
kotlin
class TestActivity : AppCompatActivity() {
// 创建带 SupervisorJob 的协程作用域(绑定 Activity 生命周期
private val requestScope = CoroutineScope(SupervisorJob() + Dispatchers.IO)
override fun onCreate(savedInstanceState: Bundle?) {
super.onCreate(savedInstanceState)
setContentView(R.layout.activity_test)
// 并行请求 3 个接口
requestScope.launch { fetchUserInfo() }
requestScope.launch { fetchGoodsList() }
requestScope.launch { fetchOrderHistory() }
}
// 单个接口请求失败,仅自身终止,不影响其他
private suspend fun fetchUserInfo() {
try {
// 模拟接口异常
throw RuntimeException("用户信息请求失败")
} catch (e: Exception) {
println("用户信息请求失败: ${e.message}")
}
}
private suspend fun fetchGoodsList() {
delay(1000)
println("商品列表请求成功")
}
private suspend fun fetchOrderHistory() {
delay(1500)
println("订单历史请求成功")
}
override fun onDestroy() {
super.onDestroy()
requestScope.cancel()
}
}
// System.out: 用户信息请求失败: 用户信息请求失败
// System.out: 商品列表请求成功
// System.out: 订单历史请求成功注意事项:
- SupervisorJob 不会自动取消:与普通 Job 一样,SupervisorJob 也需手动取消(例如通过作用域的
cancel()或等待所有子协程完成),否则可能导致协程泄漏; - SupervisorJob 作为父 Job 时,子协程的异常不会传递传递给父协程,但子协程内部的异常仍会取消它自己。要处理子协程的异常,仍然需要在子协程内部捕获或使用 CoroutineExceptionHandler;
- 如果作用域使用
SupervisorJob(),但启动的协程是async,那么异常仍然只在调用await()时抛出,不会自动传播。
8 launch/async 区别与异常处理
8.1 launch 和 async 的核心区别
launch vs async
launch:通常用于执行不需要返回值的任务,例如写数据库、发送网络请求但不关心结果等;async:用于需要返回结果的并发任务。async类似于 Future,但它是挂起函数式的;

代码示例:
kotlin
fun main() = runBlocking {
// 1. launch: 无返回值,仅执行逻辑
val launchJob = launch {
delay(100)
println("launch 协程执行完成") // 副作用操作
}
launchJob.join() // // 挂起函数,等待协程完成(无返回值)
// 2. async: 有返回值,通过 await() 获取
val asyncDeferred = async {
delay(100)
"async 协程返回结果" // 返回 String 类型
}
val result = asyncDeferred.await() // 挂起等待结果
println("async 结果: $result")
}
// launch 协程执行完成
// async 结果: async 协程返回结果8.2 launch 和 async 的异常处理
协程异常处理的核心差异在于「异常是否立即传播」,这直接决定了处理方式的不同:
launch的异常行为: 如果launch内部的协程抛出未捕获的异常,它会立即传播到父协程(或顶层协程),并且会导致父协程取消。如果未设置全局的 CoroutineExceptionHandler,默认的未捕获异常处理器会打印堆栈并将异常抛出给线程(可能使应用崩溃);async的异常行为:async块内部的异常不会立即传播,而是被封装在返回的 Deferred 对象中。当我们调用await()时,异常才会被抛出。如果从未调用await(),异常可能被静默吞噬(取决于作用域的结构化并发规则);
8.2.1 launch 协程的异常处理
如果 launch 内部的异常未被捕获,它会向上传递给父协程(顶层协程),不处理会导致父协程取消。
处理方式 1:try - catch 包裹协程体(最常用)
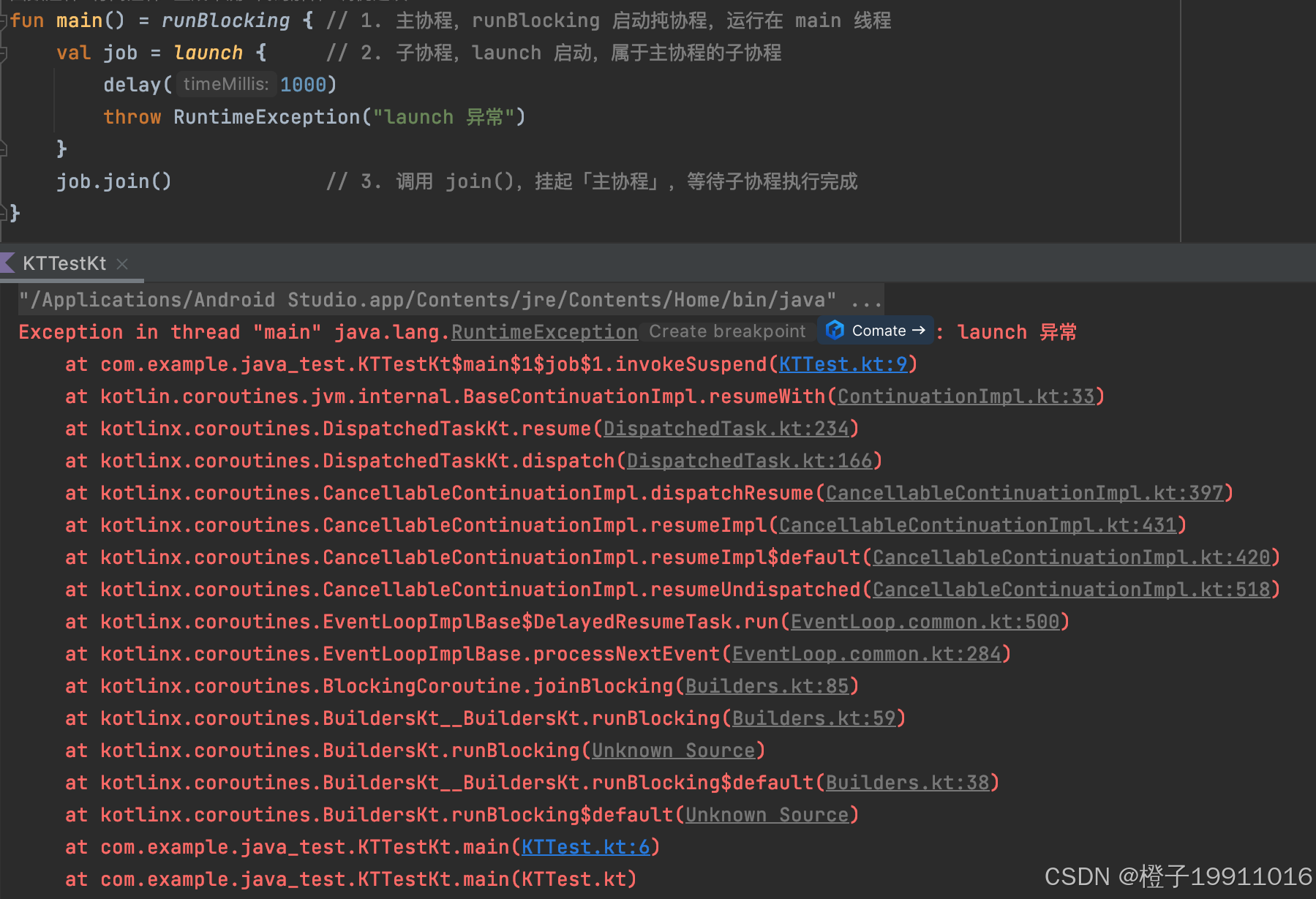
job.join() 是一个挂起函数,挂起的是当前协程(即调用它的协程),而不是子协程本身。子协程继续运行,当前协程暂停,直到子协程完成(正常或异常)。
使用 try - catch 捕获异常:
kotlin
fun main() = runBlocking { // 1. 主协程,runBlocking 启动扽协程,运行在 main 线程
val job = launch { // 2. 子协程,launch 启动,属于主协程的子协程
try {
delay(1000)
throw RuntimeException("launch 异常") // 模拟抛出异常
} catch (e: Exception) {
println("捕获 launch 异常: ${e.message}")
}
}
job.join() // 3. 调用 join(),挂起「主协程」,等待子协程执行完成
println("父协程仍正常执行")
}
// 捕获 launch 异常: launch 异常
// 父协程仍正常执行处理方式 2:设置 CoroutineExceptionHandler(全局异常处理器)
适合统一处理多个 launch 协程的异常,需要在协程上下文(CoroutineContext)中指定:
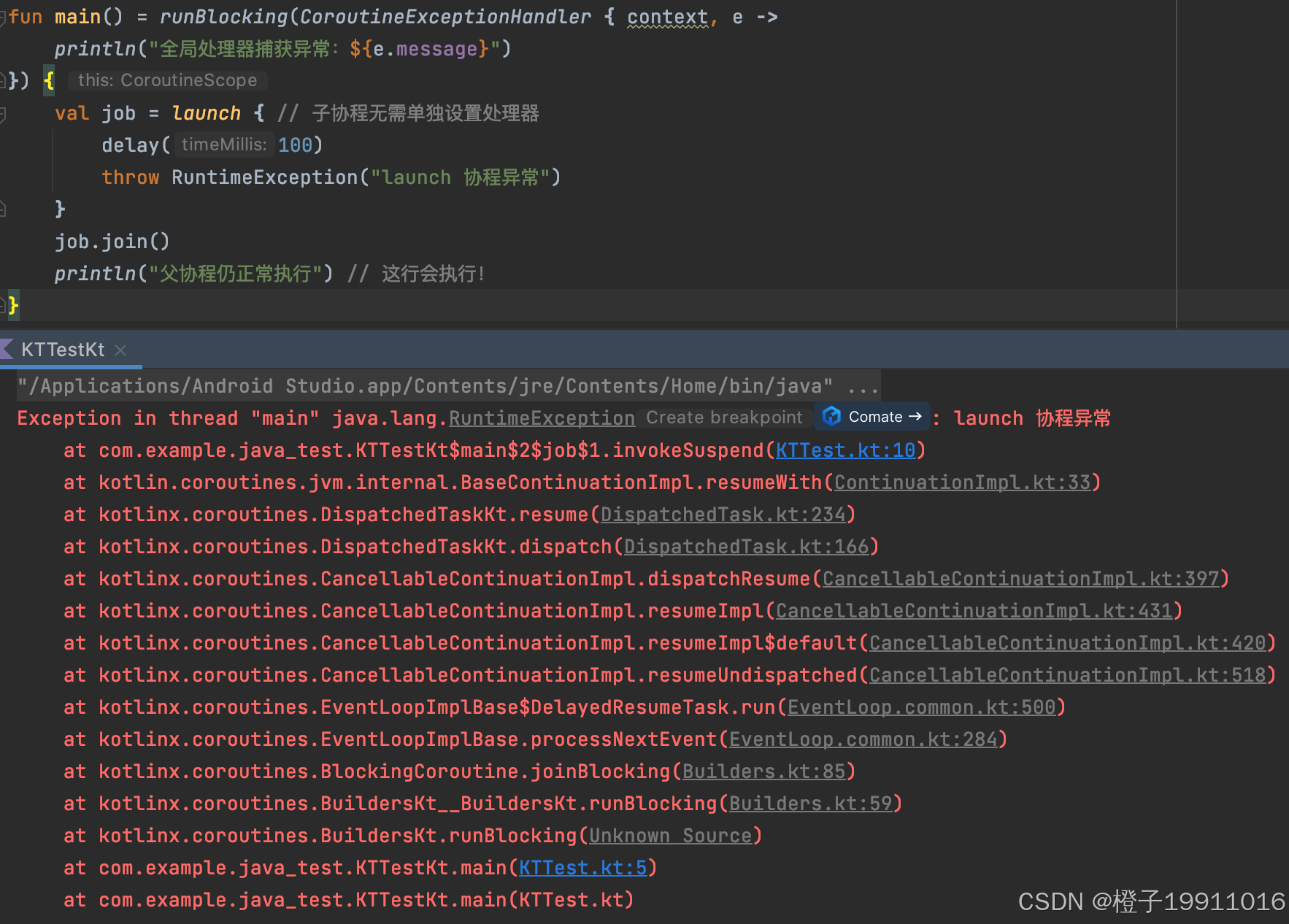
这里发现设置了 CoroutineExceptionHandler 后,代码并未达到预期(异常未被捕获,println 也没有执行),这是因为 runBlocking 是一个特殊的根协程 ------ 与其他的 CoroutineScope 不同, runBlocking 会将协程内未处理的异常直接抛到调用它的线程,因此,即使我们给 runBlocking 设置了 CoroutineExceptionHandler,这个处理器只能"感知异常",但无法阻止 runBlocking 向主线程抛异常,最终导致程序崩溃。
用 SupervisorJob + 独立 CoroutineScope(适合多子协程场景):
kotlin
fun main() = runBlocking {
// 1. 定义异常处理器
val exceptionHandler = CoroutineExceptionHandler { context, e ->
println("全局处理器捕获异常: ${e.message}")
}
// 2. 创建带 SupervisorJob 的独立协程作用域(隔离异常)
val scope = CoroutineScope(SupervisorJob() + exceptionHandler)
// 3. 子协程运行在独立的作用域中,异常不会传播到 runBlocking
val job = scope.launch {
delay(100)
throw RuntimeException("launch 协程异常")
}
job.join()
println("父协程仍正常执行")
}
// 全局处理器捕获异常: launch 协程异常
// 父协程仍正常执行8.2.2 async 协程的异常处理
用 async 启动的协程,异常不会自动传播,而是会暂存在 Deferred 对象中,直到调用 await() 方法时才会抛出。如果一直未调用 await() 方法,异常会"静默丢失"。
处理方式 1:try - catch 包裹 await()(核心方式)

这里可以看出,不仅打印了异常,而且没有影响到父协程。
处理方式 2:async + SupervisorJob(避免异常传播到父协程)
如果多个 async 协程并行执行,希望单个协程异常不影响其他协程,可结合 SupervisorJob:
kotlin
fun main() = runBlocking {
// 用 SupervisorJob 隔离异常
val scope = CoroutineScope(SupervisorJob() + Dispatchers.Default)
val deferred1 = scope.async {
throw RuntimeException("async1 异常")
}
val deferred2 = scope.async {
delay(100)
"async2 正常结果"
}
// 分别处理异常
try {
println("${deferred1.await()}")
} catch (e: Exception) {
println("捕获 async1 异常: ${e.message}")
}
println("async2 结果: ${deferred2.await()}")
scope.cancel()
}
// 捕获 async1 异常: async1 异常
// async2 结果: async2 正常结果async 异常"静默丢失"问题
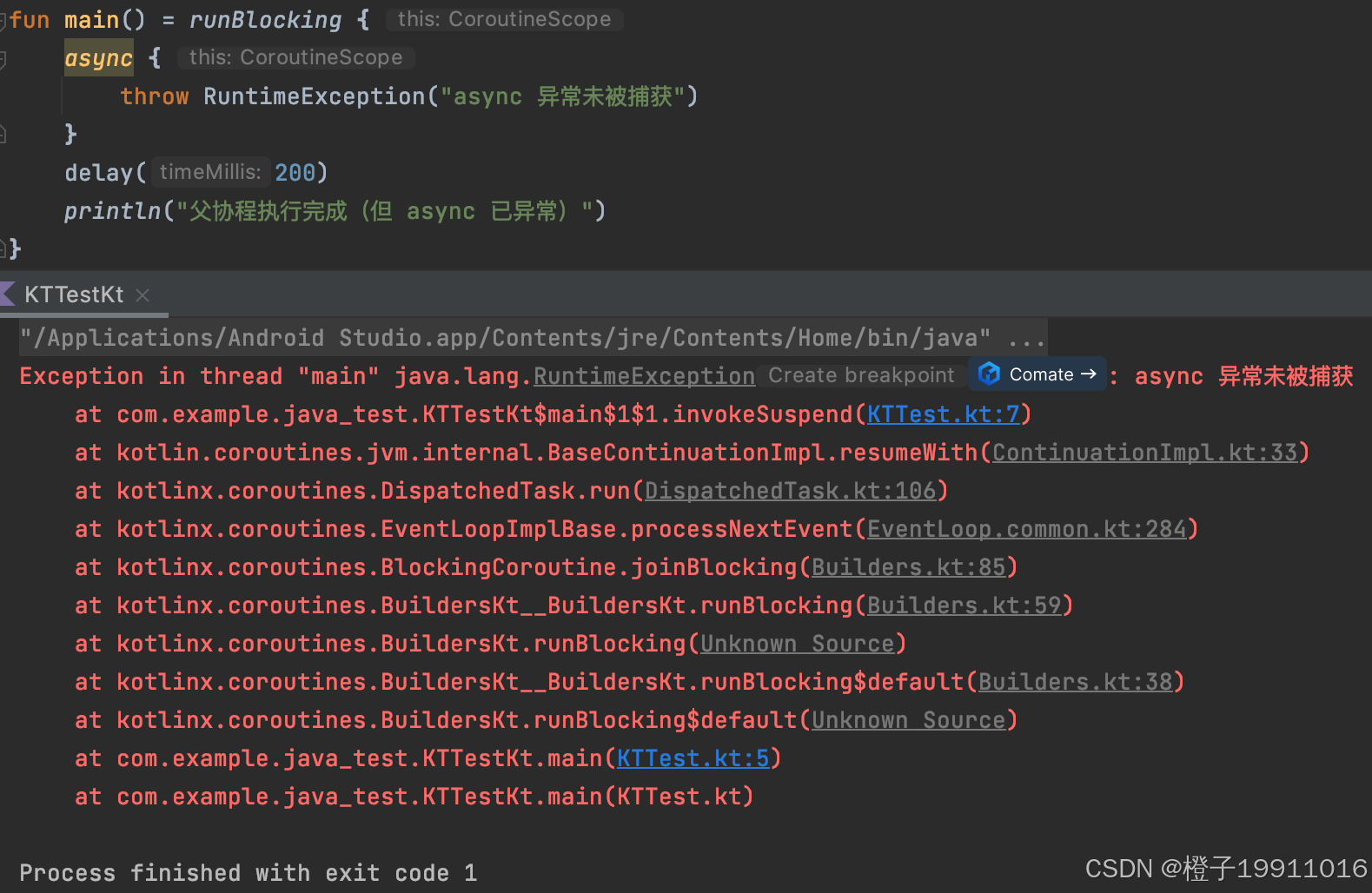
如果启动 async 后不调用 await(),异常不会抛出,但协程会取消,且可能导致资源泄漏:
kotlin
fun main() = runBlocking {
// 1. 创建独立的 CoroutineScope(非 runBlocking 直接子协程)
val scope = CoroutineScope(Job())
// 2. async 运行在独立 scope 中,异常会静默丢失
scope.async {
throw RuntimeException("async 异常未被捕获")
}
delay(200)
println("父协程执行完成(async 异常已丢失)")
}
// 父协程执行完成(async 异常已丢失)需要注意的是,这里给 async 设置了独立的 CoroutineScope,而非runBlocking 的直接子协程。这是因为在 runBlocking 中使用 async,即使是未调用 await(),异常也会抛到主线程。
8.3 多协程组合的异常处理
场景 1:launch 启动多个子协程(异常会取消所有子协程)
默认情况下,父协程的一个子协程异常会导致所有子协程被取消:
kotlin
fun main() = runBlocking {
val parentJob = launch {
launch {
delay(200)
println("子协程 1 执行完成")
}
launch {
delay(100)
throw RuntimeException("子协程 2 异常")
}
}
parentJob.join()
}
//Exception in thread "main" java.lang.RuntimeException: 子协程 2 异常
//at com.example.java_test.KTTestKt$main$1$parentJob$1$2.invokeSuspend(KTTest.kt:13)
//at kotlin.coroutines.jvm.internal.BaseContinuationImpl.resumeWith(ContinuationImpl.kt:33)
//at kotlinx.coroutines.DispatchedTaskKt.resume(DispatchedTask.kt:234)
//at kotlinx.coroutines.DispatchedTaskKt.dispatch(DispatchedTask.kt:166)
//at kotlinx.coroutines.CancellableContinuationImpl.dispatchResume(CancellableContinuationImpl.kt:397)
//at kotlinx.coroutines.CancellableContinuationImpl.resumeImpl(CancellableContinuationImpl.kt:431)
//at kotlinx.coroutines.CancellableContinuationImpl.resumeImpl$default(CancellableContinuationImpl.kt:420)
//at kotlinx.coroutines.CancellableContinuationImpl.resumeUndispatched(CancellableContinuationImpl.kt:518)
//at kotlinx.coroutines.EventLoopImplBase$DelayedResumeTask.run(EventLoop.common.kt:500)
//at kotlinx.coroutines.EventLoopImplBase.processNextEvent(EventLoop.common.kt:284)
//at kotlinx.coroutines.BlockingCoroutine.joinBlocking(Builders.kt:85)
//at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking(Builders.kt:59)
//at kotlinx.coroutines.BuildersKt.runBlocking(Unknown Source)
//at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking$default(Builders.kt:38)
//at kotlinx.coroutines.BuildersKt.runBlocking$default(Unknown Source)
//at com.example.java_test.KTTestKt.main(KTTest.kt:5)
//at com.example.java_test.KTTestKt.main(KTTest.kt)解决:用 SupervisorScope 隔离子线程,单个协程异常不影响其他:
kotlin
fun main() = runBlocking {
launch {
supervisorScope {
launch {
delay(200)
println("子协程 1 执行完成")
}
launch {
delay(100)
throw RuntimeException("子协程 2 异常")
}
}
}.join()
}
//Exception in thread "main" java.lang.RuntimeException: 子协程 2 异常
//at com.example.java_test.KTTestKt$main$1$1$1$2.invokeSuspend(KTTest.kt:14)
//at kotlin.coroutines.jvm.internal.BaseContinuationImpl.resumeWith(ContinuationImpl.kt:33)
//at kotlinx.coroutines.DispatchedTaskKt.resume(DispatchedTask.kt:234)
//at kotlinx.coroutines.DispatchedTaskKt.dispatch(DispatchedTask.kt:166)
//at kotlinx.coroutines.CancellableContinuationImpl.dispatchResume(CancellableContinuationImpl.kt:397)
//at kotlinx.coroutines.CancellableContinuationImpl.resumeImpl(CancellableContinuationImpl.kt:431)
//at kotlinx.coroutines.CancellableContinuationImpl.resumeImpl$default(CancellableContinuationImpl.kt:420)
//at kotlinx.coroutines.CancellableContinuationImpl.resumeUndispatched(CancellableContinuationImpl.kt:518)
//at kotlinx.coroutines.EventLoopImplBase$DelayedResumeTask.run(EventLoop.common.kt:500)
//at kotlinx.coroutines.EventLoopImplBase.processNextEvent(EventLoop.common.kt:284)
//at kotlinx.coroutines.BlockingCoroutine.joinBlocking(Builders.kt:85)
//at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking(Builders.kt:59)
//at kotlinx.coroutines.BuildersKt.runBlocking(Unknown Source)
//at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking$default(Builders.kt:38)
//at kotlinx.coroutines.BuildersKt.runBlocking$default(Unknown Source)
//at com.example.java_test.KTTestKt.main(KTTest.kt:5)
//at com.example.java_test.KTTestKt.main(KTTest.kt)
//Suppressed: kotlinx.coroutines.DiagnosticCoroutineContextException: [StandaloneCoroutine{Cancelling}@7a30d1e6, BlockingEventLoop@5891e32e]
//子协程 1 执行完成场景 2:async 并行执行多个任务(合并结果)
kotlin
fun main() = runBlocking {
val deferred1 = async { fetchData1() }
val deferred2 = async { fetchData2() }
try {
val result1 = deferred1.await()
val result2 = deferred2.await()
println("合并结果: $result1 + $result2")
} catch (e: Exception) {
println("某个任务异常: ${e.message}")
// 取消其他未完成的任务
deferred1.cancel()
deferred2.cancel()
}
}
suspend fun fetchData1(): String {
delay(100)
return "数据 1"
}
suspend fun fetchData2(): String {
delay(100)
throw RuntimeException("获取数据 2 失败")
}
//某个任务异常: 获取数据 2 失败
//Exception in thread "main" java.lang.RuntimeException: 获取数据 2 失败
//at com.example.java_test.KTTestKt.fetchData2(KTTest.kt:30)
//at com.example.java_test.KTTestKt$fetchData2$1.invokeSuspend(KTTest.kt)
//at kotlin.coroutines.jvm.internal.BaseContinuationImpl.resumeWith(ContinuationImpl.kt:33)
//at kotlinx.coroutines.DispatchedTaskKt.resume(DispatchedTask.kt:234)
//at kotlinx.coroutines.DispatchedTaskKt.dispatch(DispatchedTask.kt:166)
//at kotlinx.coroutines.CancellableContinuationImpl.dispatchResume(CancellableContinuationImpl.kt:397)
//at kotlinx.coroutines.CancellableContinuationImpl.resumeImpl(CancellableContinuationImpl.kt:431)
//at kotlinx.coroutines.CancellableContinuationImpl.resumeImpl$default(CancellableContinuationImpl.kt:420)
//at kotlinx.coroutines.CancellableContinuationImpl.resumeUndispatched(CancellableContinuationImpl.kt:518)
//at kotlinx.coroutines.EventLoopImplBase$DelayedResumeTask.run(EventLoop.common.kt:500)
//at kotlinx.coroutines.EventLoopImplBase.processNextEvent(EventLoop.common.kt:284)
//at kotlinx.coroutines.BlockingCoroutine.joinBlocking(Builders.kt:85)
//at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking(Builders.kt:59)
//at kotlinx.coroutines.BuildersKt.runBlocking(Unknown Source)
//at kotlinx.coroutines.BuildersKt__BuildersKt.runBlocking$default(Builders.kt:38)
//at kotlinx.coroutines.BuildersKt.runBlocking$default(Unknown Source)
//at com.example.java_test.KTTestKt.main(KTTest.kt:5)
//at com.example.java_test.KTTestKt.main(KTTest.kt)8.4 结构化并发下的异常传播规则
在结构化并非中,协程之间存在父子关系。默认规则:
- 如果一个子协程抛出异常,它会取消父协程,父协程取消后,所有其他子协程也会取消;
- 这种传播机制是为了保证整个作用域的一致性和资源清理;
- 例外情况:如果使用 SupervisorJob 或 supervisorScope,则子协程的异常不会向上传播取消父协程,只影响自身;
8.5 总结
launch/async 区别与异常处理的核心要点:
- 核心区别:
launch:无返回值,异常立即传播,适合执行副作用操作;async:有返回值(await()获取),异常暂存到await()时抛出,适合获取异步结果;
- 异常处理原则:
launch:用try - catch包裹协程体,或全局 CoroutineExceptionHandler;async:必须在await()处于try - catch捕获,避免异常静默丢失;
- 隔离异常:用 SupervisorJob/supervisorScope 可避免单个协程异常影响其它协程,适合多协程并行场景;
launch 是"只管执行,不管结果",异常马上抛;async 是"执行并返回结果",异常等我们取结果时才抛。
9 协程调度器(Dispatchers.IO/Default/Main)实现原理
Kotlin 协程的调度器(CoroutineDispatcher)负责决定协程在哪个线程或线程池上执行。内置了三个核心调度器 Disaptchers.Default、Dispatchers.IO、Disaptcher.Main。
coroutine /,kəʊruː'tiːn/ 协同程序 scheduler /ˈʃɛdjuːlə/ 调度程序 dispatcher /dɪˈspætʃə®/ 调度员
9.1 核心组件
9.1.1 Dispatchers:协程调度器的全局入口(单例对象),提供 Default/IO/Main 等调度器
Dispatchers 是 Kotlin object 单例,提供调度器实例(Default/IO/Main 等)。
kotlin
public actual object Dispatchers {
// Default 调度器:CPU 密集型任务专用
@JvmStatic
public actual val Default: CoroutineDispatcher = DefaultScheduler
// Main 调度器:主线程/UI 线程专用(延迟加载)
@JvmStatic
public actual val Main: MainCoroutineDispatcher get() = MainDispatcherLoader.dispatcher
// IO 调度器:IO 密集型任务专用
@JvmStatic
public val IO: CoroutineDispatcher = DefaultIoScheduler
}说明:
public actual object:object保证全局单例,actual是 Kotlin 多平台特性;@JvmStatic:生成 Java 静态方法(如Dispatchers.getDefault()/getMain()/getIO()),兼容 Java 调用;get()语法:表面是"每次访问调用 getter",但MainDispatcherLoader.dispatcher是线程安全的懒加载单例;
9.1.2 CoroutineDispatcher:所有协程调度器的抽象父类,定义调度器的核心行为
所有协程调度器(Default/IO/Main)都必须实现它的抽象方法:
kotlin
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
public open fun isDispatchNeeded(context: CoroutineContext): Boolean = true
@ExperimentalCoroutinesApi
public open fun limitedParallelism(parallelism: Int): CoroutineDispatcher {
parallelism.checkParallelism() // 校验:并发数必须 ≥1
return LimitedDispatcher(this, parallelism) // 返回包装后的调度器
}
public abstract fun dispatch(context: CoroutineContext, block: Runnable)
@InternalCoroutinesApi
public open fun dispatchYield(context: CoroutineContext, block: Runnable): Unit = dispatch(context, block)
}
// LimitedDispatcher.kt
internal fun Int.checkParallelism() = require(this >= 1) { "Expected positive parallelism level, but got $this" }
// 协程上下文元素的基类:让 CoroutineDispatcher 可以被添加到 CoroutineContext 中
@SinceKotlin("1.3")
public abstract class AbstractCoroutineContextElement(public override val key: Key<*>) : Element
// 协程拦截器核心接口:调度器通过该接口拦截协程的执行流程,替换协程的执行线程(底层核心逻辑)
@SinceKotlin("1.3")
public interface ContinuationInterceptor : CoroutineContext.Element {
}
public interface CoroutineContext {
public interface Element : CoroutineContext {
}
}dispatch(context: CoroutineContext, block: Runnable):核心抽象方法,调度任务到指定线程
- 设置为抽象方法的原因:不同调度器的调度逻辑完全不同,必须由子类实现
- Dispatchers.Default/IO:实现"将任务提交到 CoroutineScheudler 线程池";
- Dispatchers.Main(Android):实现"通过Handler 将任务提交到主线程 Looper";
- 参数说明:
context:协程上下文(可获取协程名称、Job 等信息,用于调度优化);block;待执行的协程任务(封装了协程的执行逻辑);
dispatchYield(context: CoroutineContext, block: Runnable):调度"可让出"的任务,主动让出线程,优先执行其他高优先级任务。
isDispatchNeeded(context: CoroutineContext): Boolean :判断"是否需要切换线程"
- 返回值:
true(默认需要切换线程); - 优化性能:避免"当前线程就是目标线程"时的无效调度
- 重写场景:
- Dispatchers.Main:重写后会检查当前线程是否是主线程,若返回
false(无需切换),避免不必要的线程切换; - Dispatchers.Unconfined:重写返回 false(不限制线程,在当前调用线程执行);
- Dispatchers.Main:重写后会检查当前线程是否是主线程,若返回
limitedParallelism(parallelism: Int): CoroutineDispatcher:限制调度器的最大并发数,返回一个包装好的调度器
- 实现逻辑:
- 先通过
checkParallelism(parallelism: Int)方法校验并发数(必须 ≥1,否则抛出异常); - 返回 LimitedDispatcher,包装当前调度器,添加并发数限制;
- 先通过
- 实现场景:
Dispatchers.IO.limitedParallelism(32):将 IO 调度器的最大并发数限制为 32,避免线程爆炸;- 自定义调度器:给自研调度器快速添加并发控制,无需重复造轮子;
9.1.3 CoroutineScheduler:为协程量身定制的"智能线程池,比 JDK ThreadPoolExecutor 更轻量、更适配协程特性"
CoroutineScheduler 通过任务分类和工作窃取,最大化利用 CPU 资源,同时避免 IO 任务导致的线程爆。
CoroutineScheduler 的核心角色:
- 协程专属线程池: 替代 JDK ThreadPoolExecutor,深度适配协程"轻量、异步、优先级调度"的特性;
- 任务分类管理: 区分 CPU 密集型(非阻塞)和 IO 密集型(阻塞)任务,分别管理队列和线程;
- 弹性线程管理: 动态创建/销毁线程,核心线程数
corePoolSize、最大线程数maxPoolSize可配置; - Executor 兼容: 实现 JDK Executor 接口,兼容传统 Runnable 调度;
CoroutineScheduler 的关键字段和构造参数:
kotlin
internal class CoroutineScheduler(
@JvmField val corePoolSize: Int, // 核心线程数(Default 为 2,IO 为 1)
@JvmField val maxPoolSize: Int, // 最大线程数(Default 为 CPU 核心数,IO 为 64)
@JvmField val idleWorkerKeepAliveNs: Long = IDLE_WORKER_KEEP_ALIVE_NS, // 空闲线程存活时间
@JvmField val schedulerName: String = DEFAULT_SCHEDULER_NAME // 调度器名称(用于线程明名/调试)
) : Executor, Closeable {
@JvmField
val globalCpuQueue = GlobalQueue() // CPU 密集型任务全局队列(非阻塞任务)
@JvmField
val globalBlockingQueue = GlobalQueue() // IO 密集型任务全队队列(阻塞任务)
...
}说明:
corePoolSize/maxPoolSize:核心线程数/最大线程数,弹性扩容 --- 线程数在 core, max 之间动态调整;- Default:core = 2,max = CPU 核心数;IO:core = 1,max = 64;
idleWorkerKeepAliveNs:空闲线程存活时间(默认 60s),空闲线程超过该时间则销毁,仅保留核心线程;globalCpuQueue:CPU 任务全局队列,存储非阻塞任务(如计算、排序),优先级高于阻塞任务;globalBlockingQueue:IO 任务全局队列,存储阻塞任务(如网络、文件),最大线程数 64,避免占用 CPU 核心线程;- Executor 实现:兼容 JDK 标准 Executor 接口,可通过
execut(Runnable)提交任务,适配传统并发代码;
addToGlobalQueue(task: Task): Boolean --- 任务分类入队:
kotlin
private fun addToGlobalQueue(task: Task): Boolean {
return if (task.isBlocking) {
globalBlockingQueue.addLast(task) // 阻塞任务 → 加入 IO 全局队列
} else {
globalCpuQueue.addLast(task) // 非阻塞任务 → 加入 CPU 全局队列
}
} 说明:根据任务是否为"阻塞型"(task.isBlocking),将任务分类加入对应全局队列:
- CPU 任务和 IO 任务隔离,避免 IO 阻塞任务占用 CPU 核心线程;
- 全局队列是 GlobalQueue(协程自研无锁队列),保证高并发下的性能;
execute(command: Runnable) --- Executor 接口实现(任务提交入口):
kotlin
override fun execute(command: Runnable) = dispatch(command)说明:实现 JDK Executor.execute(command: Runnable),将传统 Runnable 任务转发到 dispath(command) 方法 ------ 兼容传统并发代码,让 CoroutineSheduler 可直接作为 JDK 线程池使用。
dispath(block: Runnable, taskContext: TaskContext = NonBlockingContext, tailDispatch: Boolean = false) --- 核心任务调度方法(协程任务提交核心)
kotlin
fun dispatch(block: Runnable, taskContext: TaskContext = NonBlockingContext, tailDispatch: Boolean = false) {
trackTask() // 虚拟时间支持(测试/调试用)
// 步骤 1: 将 Runnable 封装为协程 Task(添加提交时间、上下文等元信息)
val task = createTask(block, taskContext)
// 步骤 2: 尝试提交到当前 Worker 到本地队列(工作窃取优化)
val currentWorker = currentWorker()
val notAdded = currentWorker.submitToLocalQueue(task, tailDispatch)
// 步骤 3: 本地队列提交失败 → 加入全局队列
if (notAdded != null) {
if (!addToGlobalQueue(notAdded)) {
// 全局队列已关闭 → 抛异常(调度器终止)
throw RejectedExecutionException("$schedulerName was terminated")
}
}
// 步骤 4:判断是否需要唤醒/创建线程执行任务
val skipUnpark = tailDispatch && currentWorker != null
// Checking 'task' instead of 'notAdded' is completely okay
if (task.mode == TASK_NON_BLOCKING) { // CPU 任务
if (skipUnpark) return
signalCpuWork() // 创建/唤醒 CPU 线程
} else { // IO 阻塞任务
// Increment blocking tasks anyway
signalBlockingWork(skipUnpark = skipUnpark) // 唤醒/创建 IO 线程
}
}核心逻辑:
- 步骤 1:
createTask(block, tastContext)将普通 Runnable 封装为 Task(协程专属任务对象),记录提交时间、上下文等; - 步骤 2:优先提交到当前 Worker 的本地队列(而非全局队列)--- 这是"工作窃取"算法的核心;
- 每个 Worker 有本地队列,任务优先在本地执行,减少全局竞争;
- 本地队列满了才提交到全局队列;
- 步骤 3:本地队列提交失败,加入对应的全局队列(CPU/IO)
- 步骤 4:根据任务类型(CPU/IO),调用
signalCpuWork/signalBlockingWork唤醒/创建线程,保证任务被执行;
createTask(block: Runnable, taskContext: TaskContext): Task --- 任务封装
kotlin
fun createTask(block: Runnable, taskContext: TaskContext): Task {
val nanoTime = schedulerTimeSource.nanoTime()
if (block is Task) {
// 已封装为 Task → 更新元信息(提交时间、上下文)
block.submissionTime = nanoTime
block.taskContext = taskContext
return block
}
// 普通 Runnable → 封装为 TaskImpl(Task 子类)
return TaskImpl(block, nanoTime, taskContext)
}
internal class TaskImpl(
@JvmField val block: Runnable,
submissionTime: Long,
taskContext: TaskContext
) : Task(submissionTime, taskContext) {
override fun run() {
try {
block.run()
} finally {
taskContext.afterTask()
}
}
override fun toString(): String =
"Task[${block.classSimpleName}@${block.hexAddress}, $submissionTime, $taskContext]"
}
internal abstract class Task(
@JvmField var submissionTime: Long,
@JvmField var taskContext: TaskContext
) : Runnable {
constructor() : this(0, NonBlockingContext)
inline val mode: Int get() = taskContext.taskMode // TASK_XXX
}将任意 Runnable 封装为协程 Task 对象,补充调度所需的元信息(提交时间、上下文)。这样统一任务类型,让所有任务都能被 CoroutineSheduler 调度(支持优先级、阻塞标记等特性)。
signalCpuWork() --- CPU 任务的线程唤醒/创建
kotlin
fun signalCpuWork() {
if (tryUnpark()) return // 步骤 1: 尝试唤醒已暂停的 Worker 线程
if (tryCreateWorker()) return // 步骤 2: 唤醒失败 → 尝试创建新 Worker 线程
tryUnpark() // 步骤 3: 再次尝试唤醒(处理竞态)
}优先唤醒空闲线程,无空闲线程则创建新线程,保证 CPU 任务快速执行。这样,可以最小化线程创建开销(优先复用空闲线程),同时保证任务不排队。
signalBlockingWork(skipUnpark: Boolean) --- IO 任务的线程唤醒/创建
kotlin
private fun signalBlockingWork(skipUnpark: Boolean) {
// 步骤 1: 增加阻塞任务计数(保证线程数不超过 maxPoolSize)
val stateSnapshot = incrementBlockingTasks()
if (skipUnpark) return
if (tryUnpark()) return // 步骤 2: 唤醒空闲线程
if (tryCreateWorker(stateSnapshot)) return // 步骤 3: 创建新线程
tryUnpark() // 步骤 4: 再次尝试唤醒(处理竞态)
}比 signalCpuWork() 多了 incrementBlockingTasks() --- 先记录阻塞任务数,保证创建的线程数不超过 maxPoolSize(IO 为 64)。IO 任务允许创建更多线程(最大 64),但需先记录计数,避免线程爆炸。
tryUnpark() --- 唤醒空闲 Worker 线程
kotlin
private fun tryUnpark(): Boolean {
while (true) {
// 步骤 1: 从暂停的 Worker 栈中取出一个 Worker
val worker = parkedWorkersStackPop() ?: return false
// 步骤 2: CAS 操作标记 Worker 为"已认领"(线程安全)
if (worker.workerCtl.compareAndSet(PARKED, CLAIMED)) {
LockSupport.unpark(worker) // 步骤 3: 唤醒 Worker 线程
return true
}
}
}核心逻辑:
- 从
parkedWorkersStackPop()(暂停的 Worker 栈)中取出空闲线程; - 用 CAS 操作保证线程安全(避免多线程同时认领一个 Worker);
- 调用
LockSupport.unpark(worker)唤醒 Worker,让其处理队列任务;
复用空闲线程,减少线程创建/销毁的开销(线程创建是重量级操作)。
9.2 Dispatchers.Main:主线程(UI 线程)调度器
Dispatchers.Main 是为 UI 操作设计的调度器,底层绑定平台的"主线程/UI 线程"。
Dispatchers.Main 是对外暴露的入口,本身不存储调度器实例,仅通过 get() 语法转发到 MainDispatcherLoader.dispather
kotlin
public actual object Dispatchers {
@JvmStatic
public actual val Main: MainCoroutineDispatcher get() = MainDispatcherLoader.dispatcher
}说明:
actual关键字:适配 Kotlin 多平台特性,保证 Android/iOS/JVM 等平台有各自的具体实现;@JvmStatic:生成 Java 静态方法(Dispatchers.getMain()),兼容 Java 调用;get()语法:延迟加载,表面是"每次访问调用getter",但MainDispatcherLoader.disaptcher是静态初始化的单例,实际全局仅一个实例;
MainDispatcherLoader --- Main调度器的加载引擎:
kotlin
internal object MainDispatcherLoader {
// 1. 高性能加载开关:默认启动协程自研的 FastServiceLoader
private val FAST_SERVICE_LOADER_ENABLED = systemProp(FAST_SERVICE_LOADER_PROPERTY_NAME, true)
// 2. 静态初始化的 Main 调度器实例(类加载时完成加载)
@JvmField
val dispatcher: MainCoroutineDispatcher = loadMainDispatcher()
private fun loadMainDispatcher(): MainCoroutineDispatcher {
return try {
// 步骤 1: 加载所有 MainDispatcherFactory(二选一:FastServiceLoader/JDK ServiceLoader)
val factories = if (FAST_SERVICE_LOADER_ENABLED) {
FastServiceLoader.loadMainDispatcherFactory() // 低开销、高性能
} else {
// JDK 原生加载器,显式指定类加载器适配 Android R8 混淆
ServiceLoader.load(
MainDispatcherFactory::class.java,
MainDispatcherFactory::class.java.classLoader
).iterator().asSequence().toList()
}
// 步骤 2: 选优先级最高的工厂创建调度器(如 Android 的 AndroidMainDispatcherFactory 优先级 100)
@Suppress("ConstantConditionIf")
factories.maxByOrNull { it.loadPriority }?.tryCreateDispatcher(factories)
?: createMissingDispatcher() // 无工厂 → 兜底
} catch (e: Throwable) {
// 步骤 3: 任何加载异常 → 兜底(避免崩溃)
createMissingDispatcher(e)
}
}
}核心原理:
- 工厂加载机制:通过 ServiceLoader/FastServiceLoader 扫描并加载平台专属的 MainDispatcherFactory(如 Android 平台的 AndroidMainDispatcherFactory)
- 优先级选择:多个工厂按
loadPriority排序,保证平台专属工厂(高优先级)优先创建调度器; - 极致容错:无工厂/加载失败时,调用
createMissingDispatcher()创建兜底调度器,避免应用崩溃;
MainCoroutineDispatcher 是 CoroutineDispatcher 的子类,为"主线程调度器"增加专属的约束:
kotlin
public abstract class MainCoroutineDispatcher : CoroutineDispatcher() {
override fun limitedParallelism(parallelism: Int): CoroutineDispatcher {
parallelism.checkParallelism()
// MainCoroutineDispatcher is single-threaded -- short-circuit any attempts to limit it
return this
}
}
// LimitedDispatcher.kt
internal fun Int.checkParallelism() = require(this >= 1) { "Expected positive parallelism level, but got $this" }重写方法:
- 重写
limitedParallelism(parallelism: Int):主线程本身是单线程的,因此无论传入多少并发数,都直接返回自身,拒绝任何"并发数限制"操作; - 子类需要实现
dispatch方法:不同平台的子类(如 Android 的 HandlerDispatcher)会实现该方法,将任务调度到主线程(如 Android 绑定 Looper/Handler)
类的继承/实现关系:

调用链路:
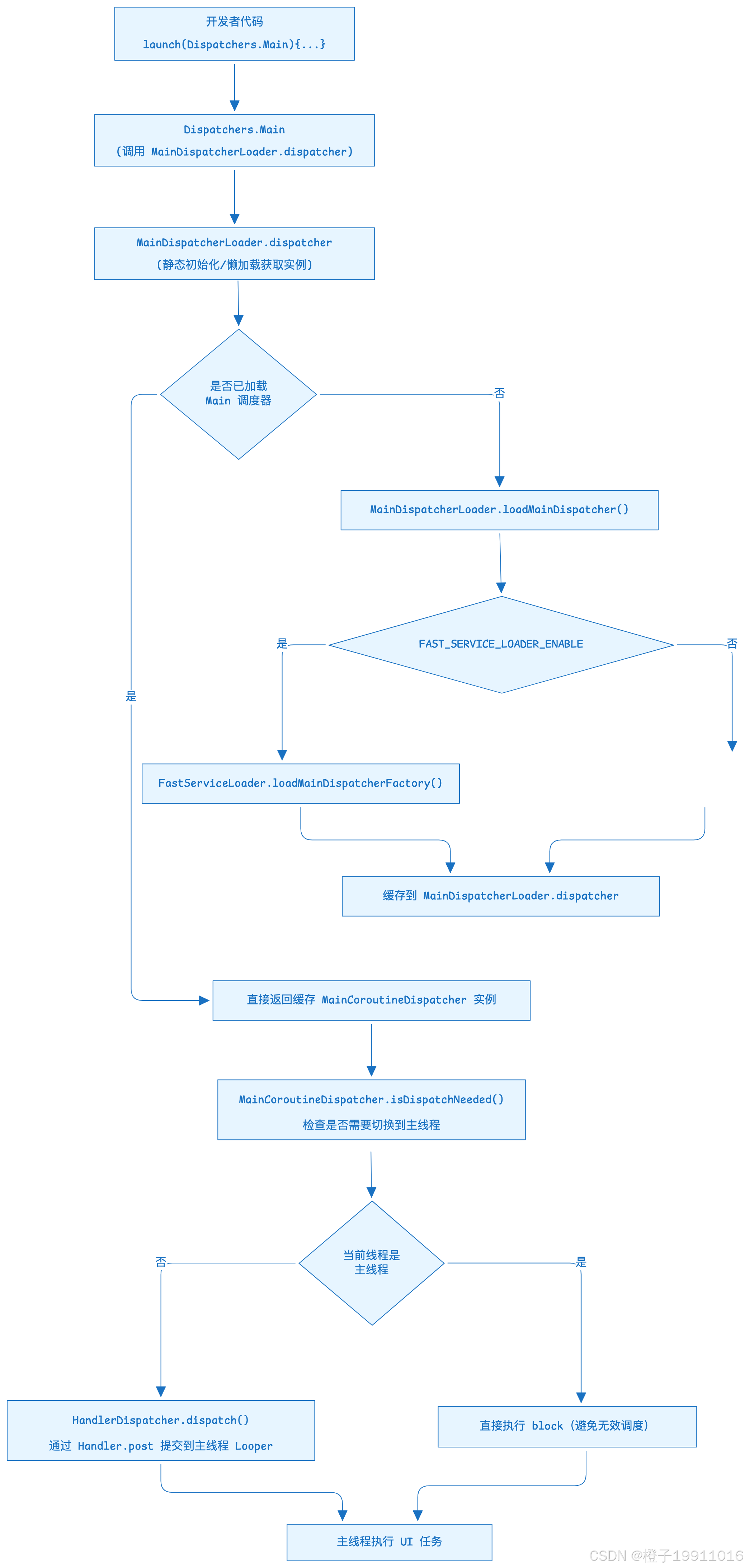
Dispatchers.Main 的实现原理:
- 入口层:Dispatchers.Main 作为对外暴露的单例入口,仅负责转发到
MainDispatcherLoader.dispatcher,保证多平台统一调用方式,兼容 Java 开发; - 加载层:MainDispatcherLoader 在类加载时执行
MainDispatcherLoader.loadMainDispatcher()- 优先使用 FastServiceLoader(高性能)加载平台专属的 MainDispatcherFactory;
- 选优先级最高的工厂创建主线程调度器(如 Android 绑定 Looper/Handler);
- 加载失败则创建兜底调度器;
- 抽象层:MainCoroutineDispatcher 作为抽象父类,实现单线程约束
- MainCoroutineDispatcher 继承 CoroutineDispatcher,遵循调度器的通用逻辑;
- 重写
limitedParallelism方法,拒绝并发数限制(主线程天然单线程);
- 执行层:不同平台的 MainCoroutineDispatcher 子类实现具体调度逻辑
- Android:HandlerDispatcher 封装主线程 Looper/Hander,将任务提交到主线程消息队列;
9.3 Dispatcher.Default:CPU 密集型任务的线程池
Dispatchers.Default 是为 CPU 密集型任务(如计算、排序、JSON 解析)设计的调度器,底层基于「固定大小的线程池」实现,它限制了并发线程数,以避免过多线程切换导致线程下降。
Dispathcers.Default 是对外暴露的入口,直接指向 DefaultScheduler 单例,是开发者接触的第一层:
kotlin
public actual object Dispatchers {
@JvmStatic
public actual val Default: CoroutineDispatcher = DefaultScheduler
}DefaultScheduler 是 object 单例,类加载时初始化,全局唯一,无延迟加载(区别于 Dispatchers.Main)。
DefaultScheduler --- Default 调度器的专属封装
kotlin
internal object DefaultScheduler : SchedulerCoroutineDispatcher(
CORE_POOL_SIZE, MAX_POOL_SIZE,
IDLE_WORKER_KEEP_ALIVE_NS, DEFAULT_SCHEDULER_NAME
) {
}DefaultScheduler 是 SchedulerCoroutineDispatcher 的单例实现,仅负责传递 SchedulerCoroutineDispatcher 的初始化参数,无额外逻辑。
SchedulerCoroutineDispatcher --- 调度器的核心封装层
kotlin
internal open class SchedulerCoroutineDispatcher(
private val corePoolSize: Int = CORE_POOL_SIZE, // 核心线程数(默认 2)
private val maxPoolSize: Int = MAX_POOL_SIZE, // 最大线程数(默认 = CPU 核心数,如 8 核 CPU 则为 8)
private val idleWorkerKeepAliveNs: Long = IDLE_WORKER_KEEP_ALIVE_NS, // 空闲线程存活时间(默认 60s)
private val schedulerName: String = "CoroutineScheduler", // 调度器名称(默认 "CoroutineScheudler"),用于调试/线程名
) : ExecutorCoroutineDispatcher() {
// 暴露了底层 Executor(JDK 标准接口),兼容传统并发代码
override val executor: Executor
get() = coroutineScheduler
// 底层调度引擎(可重置,用于测试)
private var coroutineScheduler = createScheduler()
// 创建 CoroutineScheduler(核心线程池引擎)
private fun createScheduler() =
CoroutineScheduler(corePoolSize, maxPoolSize, idleWorkerKeepAliveNs, schedulerName)
// 实现 CoroutineDispatcher 的核心调度方式:转发任务到底层引擎
override fun dispatch(context: CoroutineContext, block: Runnable): Unit = coroutineScheduler.dispatch(block)
// 实现"可让出"任务的调度:转发到底层引擎(标记 tailDispatcher = true)
override fun dispatchYield(context: CoroutineContext, block: Runnable): Unit =
coroutineScheduler.dispatch(block, tailDispatch = true)
// 内部扩展方法:支持自定义 TaskContext 调度
internal fun dispatchWithContext(block: Runnable, context: TaskContext, tailDispatch: Boolean) {
coroutineScheduler.dispatch(block, context, tailDispatch)
}
}SchedulerCoroutineDispatcher 是 ExcutorCoroutineDispatcher 的子类。ExecutorCoroutineDispatcher 是一个抽象类,并继承了 CoroutineDispatcher。 因此,DefaultScheduler 本质来说是 CoroutineDispatcher 的子类。
关键逻辑:
- 继承 ExecutorCoroutineDispatcher:是 CoroutineDispatcher 的子类;
- 引擎创建:通过
createScheduler()初始化 CoroutineScheduler,封装线程池参数(核心/最大线程数、空闲存活时间等);corePoolSize = CORE_POOL_SIZE:默认 CPU 核心数,至少为 2,可通过系统属性kotlinx.coroutines.scheduler.core.pool.size调整;maxPoolSize = MAX_POOL_SIZE:通常与corePoolSize相同(但 IO 会有更大的值);idleWorkerKeepAliveNs:空闲线程存活时间;
- 任务转发:将
dispatch/dispatchYield等方法的调用,全部转发到 CoroutineScheduler(底层线程池引擎);
在 SchedulerCoroutineDispatche.dispatch(context: CoroutineContext, block: Runnable) 方法中,将任务交给了 coroutineScheudler.dispatch(block) 方法执行,需要注意的是,这里传递了一个参数 block,没有传递 taskContext,使用默认值:
kotlin
@JvmField
internal val NonBlockingContext: TaskContext = TaskContextImpl(TASK_NON_BLOCKING)
internal class CoroutineScheduler(
@JvmField val corePoolSize: Int,
@JvmField val maxPoolSize: Int,
@JvmField val idleWorkerKeepAliveNs: Long = IDLE_WORKER_KEEP_ALIVE_NS,
@JvmField val schedulerName: String = DEFAULT_SCHEDULER_NAME
) : Executor, Closeable {
fun dispatch(block: Runnable, taskContext: TaskContext = NonBlockingContext, tailDispatch: Boolean = false) {
trackTask() // this is needed for virtual time support
val task = createTask(block, taskContext)
// try to submit the task to the local queue and act depending on the result
val currentWorker = currentWorker()
val notAdded = currentWorker.submitToLocalQueue(task, tailDispatch)
if (notAdded != null) {
if (!addToGlobalQueue(notAdded)) {
// Global queue is closed in the last step of close/shutdown -- no more tasks should be accepted
throw RejectedExecutionException("$schedulerName was terminated")
}
}
val skipUnpark = tailDispatch && currentWorker != null
// Checking 'task' instead of 'notAdded' is completely okay
if (task.mode == TASK_NON_BLOCKING) {
if (skipUnpark) return
signalCpuWork()
} else {
// Increment blocking tasks anyway
signalBlockingWork(skipUnpark = skipUnpark)
}
}
}ExecutorCoroutineDispatcher --- CoroutineDispatcher 的子类,为"基于 Executor 的调度器"增加的抽象约束
kotlin
public abstract class ExecutorCoroutineDispatcher: CoroutineDispatcher(), Closeable {
public abstract val executor: Executor
}说明:
- 强制子类暴露
executor属性,保证调度器可兼容 JDK 标注的 Executor 接口,支持传统 Runnable 任务调度; - 实现 Closeable:支持调度器的关闭操作,释放线程资源;
类的继承关系/实现关系:

继承/实现核心逻辑:
- 顶层抽象:CoroutineDispatcher 是所有协程调度器的父类,定义
dispatch核心契约; - 中间适配:ExecutorCoroutineDispatcher 继承 CoroutineDispatcher,同时实现 Executor(兼容 JDK 线程池)和 Closeable(支持关闭);
- 具体封装:SchedulerCoroutineDispatcher 是核心桥梁,持有 CoroutineScheduler 实例,将
dispatch调用转发底层引擎; - 单例入口:DefaultScheduler 是 SchedulerCoroutineDispatcher 的单例实现,作为 Dispatchers.Default 的实际指向;
方法调用的核心逻辑:
- 开发者通过 Dispatchers.Default 提交任务,实际调用 DefaultScheduler(继承自 SchedulerCoroutineDispatcher)的
dispatch方法; - SchedulerCoroutineDispatcher 不处理任务,仅转发给内部持有的 CoroutineScheduler 实例;
- CoroutineScheduler 作为底层引擎,完成「任务封装 → 队列分发 → 线程唤醒/创建 → 任务执行」的全流程;
- 线程管理遵循"弹性原则":优先复用空闲线程,无空闲则创建新线程(不超过 CPU 核心数),空闲则创建新线程(不超过 CPU 核心数),空闲 60s 销毁;
核心方法调用链路:
- 开发者层: 调用
launch(Dispatchers.Default) { ... },协程框架会将任务封装为 Runnable,并触发 Dispatchers.Default 的dispatch方法; - 入口层: Dispatchers.Default 本质是 DefaultScheduler 单例(继承 SchedulerCoroutineDispatcher),直接转发调用到
SchedulerCoroutineDispatcher.dispatch(context, block)方法; - 封装层:
SchedulerCoroutineDispatcher.dispatch(context, block)不处理任务逻辑,仅将block(任务)转发给内部持有的CoroutineScheduler.dispatch(block)方法; - 引擎层 --- 任务封装:
CoroutineScheduler.dispatch(block)首先调用createTask(),将普通的 Runnable 封装为协程专属 Task(记录提交时间、任务类型等元信息); - 引擎层 --- 队列分发:
- 优先尝试将 Task 提交到当前 Worker 线程的本地队列(工作窃取优化、减少全局竞争);
- 本地队列提交失败(如队列满),则调用
addToGlobalQueue(),将 Task 加入globalCpuQueue(CPU 任务全局队列);
- 引擎层 --- 线程唤醒/创建: 调用
signalCpuWork()保证任务执行- 第一步:
tryUnPark()从暂停的 Worker 栈中唤醒空闲线程; - 第二步:唤醒失败则
tryCreateWorker()创建新 Worker 线程(不超过maxPoolSize,即 CPU 核心数); - 第三步:再次尝试
tryUnpark()处理竞态问题;
- 第一步:
- 执行层: Worker 线程被唤醒/创建后,循环从「本地队列 → 全局队列」去Task 执行,执行完后:
- 若空闲时间超过
idleWorkerKeepAlivesNs(60s),则销毁线程; - 若超过时则进入暂停状态,加入
parkedWorkersStack等待下次唤醒;
- 若空闲时间超过
调用链路:
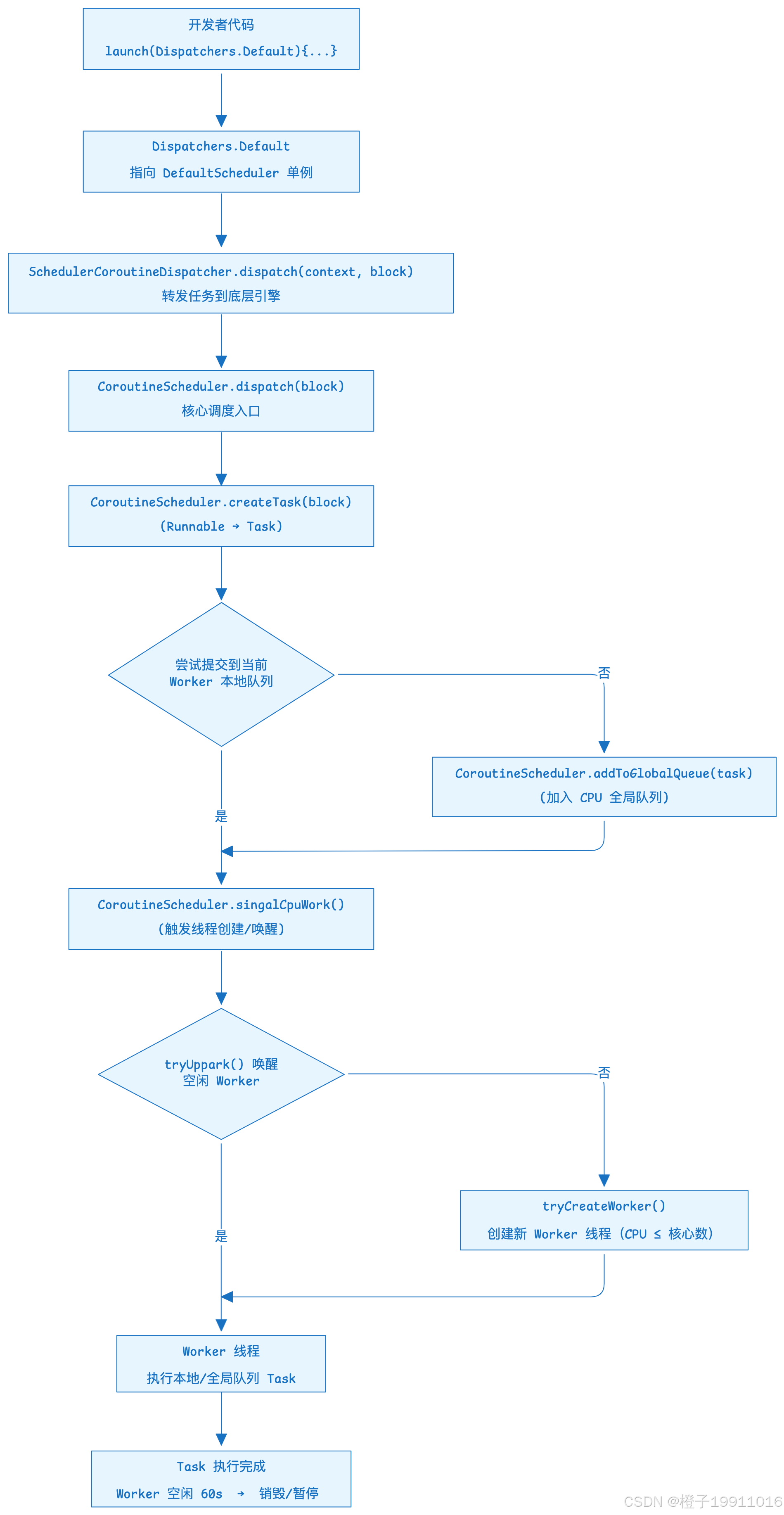
Dispatchers.Default 的实现原理:基于协程自研的 CoroutineScheduler 引擎的 CPU 密集型任务调度
- 入口层:Dispatcher.Default 作为对外暴露的入口,直接指向 DefaultScheduler 单例,保证全局唯一,同时通过
@JVMStatic兼容 Java 调用,actual适配多平台; - 封装层:DefaultScheduler 继承 SchedulerCoroutineDispatcher
- 实现 CoroutineDispatcher 的核心方法(
dispatch/diaptacherYield),将任务转发到底层引擎; - 暴露
executor属性,兼容 JDK Executor 接口 - 初始化时根据预设参数(核心线程数 2、最大线程 = CPU 核心数)创建 CoroutineScheduler 实例;
- 实现 CoroutineDispatcher 的核心方法(
- 执行层:CoroutineScheduler 是协程自研的线程池
- 管理弹性线程池(线程数在 2, CPU 核心数 之间动态调整);
- 采用"本地队列 + 全局队列"的工作窃取算法,最大化 CPU 利用率;
- 优先复用空闲线程,空闲任务超过 60s 销毁,仅保留核心线程数;
- 处理 CPU 密集型任务(非阻塞),保证计算类任务的执行效率;
9.3 Dispatchers.IO:IO 密集型任务的线程池
Dispatchers.IO 是为 IO 密集型任务(如网络请求、文件读写、数据库操作)设计的调度器,底层基于「可扩容的线程池」实现。它可以创建更多线程,因为 I/O 操作通常会阻塞线程,需要大量线程来并发处理。
Dispatchets.IO 对外暴露为单例入口,直接指向 DefaultIoScheduler,兼容 Java 调用(@JvmStatic)
kotlin
public actual object Dispatchers {
@JvmStatic
public val IO: CoroutineDispatcher = DefaultIoScheduler
}DefaultIoScheduler 核心是基于 UnlimitedIoScheduler(无界 IO 调度器) + limitedParallelism(并发数限制) 实现 IO 调度器的弹性并发控制:
kotlin
internal object DefaultIoScheduler : ExecutorCoroutineDispatcher(), Executor { // 单例类 + 双重继承
// 核心属性:默认 IO 调度器实例(限制并发数)
private val default = UnlimitedIoScheduler.limitedParallelism(
// 读取 JVM 系统属性,默认 64(且不低于 CPU 核心数)
systemProp(
IO_PARALLELISM_PROPERTY_NAME, // 系统属性名:kotlinx.coroutines.io.parallelism
64.coerceAtLeast(AVAILABLE_PROCESSORS) // 默认值:max(64. CPU 核心数)
)
)
// 兼容 JDK Executor 接口:返回自身(execute 转发到 dispatch)
override val executor: Executor
get() = this // 返回自身,因为实现了 Executor 接口
// 实现 Executor.execute 方法:转发到 dispatch 逻辑
override fun execute(command: java.lang.Runnable) = dispatch(EmptyCoroutineContext, command)
// 暴露并发数限制能力:自定义 IO 调度器的并发数
@ExperimentalCoroutinesApi
override fun limitedParallelism(parallelism: Int): CoroutineDispatcher {
// See documentation to Dispatchers.IO for the rationale
return UnlimitedIoScheduler.limitedParallelism(parallelism)
}
// 核心任务调度:所有 dispatch 调度转发到 default(带并发限制的 UnlimitedIoScheduler)
override fun dispatch(context: CoroutineContext, block: Runnable) {
default.dispatch(context, block) // 转发到 LimitedDispatcher 实例执行
}
}
public abstract class ExecutorCoroutineDispatcher: CoroutineDispatcher(), Closeable {
public abstract val executor: Executor
...
}
public interface Executor {
void execute(Runnable command);
}
private object UnlimitedIoScheduler : CoroutineDispatcher() {
}
public abstract class CoroutineDispatcher :
AbstractCoroutineContextElement(ContinuationInterceptor), ContinuationInterceptor {
@ExperimentalCoroutinesApi
public open fun limitedParallelism(parallelism: Int): CoroutineDispatcher {
parallelism.checkParallelism()
return LimitedDispatcher(this, parallelism)
}
}
// LimitedDispatcher.kt
internal fun Int.checkParallelism() = require(this >= 1) { "Expected positive parallelism level, but got $this" }说明:
- 类继承关系:
ExecutorCoroutineDispatcher()+ Executor- ExecutorCoroutineDispatcher:协程调度器的基类,核心是「将协程调度器适配为 JDK Executor」,解决协程和 JDK 线程池的兼容问题;
- Executor:实现 JDK 标准的 Executor 接口,让 DefaultIoScheduler 可以直接作为线程池执行器使用(如
executor.execute(runnable)); - 双重继承的目的:既保留协程调度器的能力,又兼容 JDK 线程池的使用方式,降低和传统并发代码的集成成本;
- 核心属性
default:限制并发数的 IO 调度器- UnlimitedIoScheduler:无边界 IO 调度器,底层是 JDK CachedThreadPool 类型的线程池(核心线程 0,理论上可无限扩容,空闲 60s 销毁);
limitedParallelism(n):给无边界线程池加上并发数上限,避免创建过多线程导致系统资源耗尽;- 参数规则:
- 有限读取 JVM 系统属性
kotlinx.coroutines.io.parallelism(支持动态配置); - 无配置时,默认值为
max(64, CPU 核心数)(比如 8 核 CPU 读取 64,128 核 CPU 读取 128);
- 有限读取 JVM 系统属性
- 设计意图:即保留 IO 调度器的弹性扩张的特性(适配 IO 任务等待多的特点),又通过
limitedParallelism限制最大并发数,避免线程爆炸;
- 核心方法:
override val executor: Executor get() = this- 作用:实现 ExecutorCoroutineDispatcher 的
executor属性,返回自身,因为 DefaultIoScheduler 实现了 Executor 接口; - 意义:让协程调度器可以直接作为 JDK Executor 使用(比如
Dispatchers.IO.executor.execute(runnable)),兼容传统并发代码;
- 作用:实现 ExecutorCoroutineDispatcher 的
override fun execute(command: java.lang.Runnable) = dispatch(EmptyCoroutineContext, command)- 作用:实现 Executor 接口的
execute放,将 JDK Runnable 任务转发到协程调度器的dispatch方法; - 逻辑:EmptyCoroutineContext 表示无额外协程上下文,仅执行基础任务调度,完成「Executor ---> 协程调度器」的适配;
- 作用:实现 Executor 接口的
UnlimitedIoScheudler.limitedParallelism(parallelism: Int): CoroutineDispatcher:- 作用:返回 IO 调度器 LimitedDispatcher 实例;
- 场景:比如业务需要限制 IO 并发数为 32,可调用
Dispatcher.IO.limitedParallelism(32)创建专属调度器; - 实现:直接复用
UnlimitedIoScheculer.limitedParallelism方法,保证自定义调度器仍基于无界 IO 线程池,但限制并发数;
dispatch(context: CoroutineContext, block: Runnable)- 核心:所有协程任务的调度入口,完全转发到
default实例(LimitedDispatcher)执行; - 设计:DefaultIoScheduler 本身是门面类,不处理实际的调度逻辑,所有任务都交给 UnlimitedIoScheduler + 并发线之后的
default实例(LimitedDispatcher)执行;
- 核心:所有协程任务的调度入口,完全转发到
UnlimitedIoScheduler.limitedParallelism(parallelism: Int) 方法最终返回的是 LimitedDispatcher 实例。
以下是 LimitedDispatcher 的关键成员变量:
kotlin
internal class LimitedDispatcher(
private val dispatcher: CoroutineDispatcher, // 被包装的原始调度器(UnLimitedIoScheduler)
private val parallelism: Int // 最大并发数(如 IO 调度器的 64)
) : CoroutineDispatcher(), Runnable, Delay by (dispatcher as? Delay ?: DefaultDelay) {
@Volatile
private var runningWorkers = 0 // 并发控制:当前运行的工作线程数(@Volatile 保证可见性)
// 无所任务队列:存储代执行的任务,singleConsumer = false 支持多生产者多消费者
private val queue = LockFreeTaskQueue<Runnable>(singleConsumer = false)
// 线程安全锁:用于 worker 数量的修改(K/N 兼容)
// A separate object that we can synchronize on for K/N
private val workerAllocationLock = SynchronizedObject()
...
}说明:
dispatcher:被包装的原调度器(如 IO 调度器的 UnlimitedIoScheduler),最总任务由它调度,LimitedDispatcher 仅控制并发数;parallelism:最大并发数(如 64),由limitedParallelism(parallelism)传入,必须 ≥1(通过parallelism.checkParallelism()校验);runningWorks:当前活跃的工作线程数,volatile修饰,保证多线程下的可见性,仅通过workAllocationLock修改;queue:无锁任务队列, LockFreeTaskQueue 是协程自研发的无锁队列,避免synchronized性能损耗;workAllocationLock:同步锁对象, 用于保护runningWorks的修改,保证线程安全(兼容 Kotlin/Native)Delay by ...:委托模式,复用原调度器 Delay 能力(如delay()延迟调度)。无需重复实现,直接委托给原调度器或默认的 DefaultDelay;
limitedParallelism(parallelism: Int): CoroutineDispatcher 方法 ------ 并发数限制的"降级"逻辑:
kotlin
internal class LimitedDispatcher(
private val dispatcher: CoroutineDispatcher,
private val parallelism: Int
) : CoroutineDispatcher(), Runnable, Delay by (dispatcher as? Delay ?: DefaultDelay) {
@ExperimentalCoroutinesApi
override fun limitedParallelism(parallelism: Int): CoroutineDispatcher {
parallelism.checkParallelism() // 校验:必须 >= 1
// 若新并发数 ≥ 当前并发数 → 返回自身(无需再包装)
if (parallelism >= this.parallelism) return this
// 否则 → 调用父类方法,创建新的 LimitedDispatcher(更低的并发数)
return super.limitedParallelism(parallelism)
}
}
internal fun Int.checkParallelism() = require(this >= 1) { "Expected positive parallelism level, but got $this" }说明:
- 避免"过度包装":如果新的并发数比当前更大,直接返回自身(比如当前并发数 64,传入 128 --- 无需限制);
- 链式限制:如果新并发数更小(如 64 ---> 32),创建新的 LimitedDispatcher,形成"多层限制"(最终取得小并发数);
run() 方法 ------ 工作线程的核心执行逻辑:
这里 LimitedDispatcher 最核心的方法(因为实现了 Runnable),每个工作线程都会执行这个方法,循环处理任务队列:
kotlin
internal class LimitedDispatcher(
private val dispatcher: CoroutineDispatcher,
private val parallelism: Int
) : CoroutineDispatcher(), Runnable, Delay by (dispatcher as? Delay ?: DefaultDelay) {
override fun run() {
var fairnessCounter = 0 // 公平性计数器:避免单个线程霸占所有任务
while (true) {
// 步骤 1: 从队列取任务
val task = queue.removeFirstOrNull()
if (task != null) {
try {
task.run() // 执行任务
} catch (e: Throwable) {
// 捕获任务异常,避免工作线程崩溃
handleCoroutineException(EmptyCoroutineContext, e)
}
// 步骤 2: 公平性控制(每执行 16 个任务,让出线程)
if (++fairnessCounter >= 16 && dispatcher.isDispatchNeeded(this)) {
// 重新调度自身,让其他线程有机会执行任务
dispatcher.dispatch(this, this)
return // 当前线程退出,新调度的线程继续处理
}
continue // 继续取任务执行
}
// 步骤 3: 无任务时,释放 worker 资源
synchronized(workerAllocationLock) {
--runningWorkers // 减少活跃 worker 数
if (queue.size == 0) return // 队列空 → 退出当前 worker
// 队列非空(可能是刚添加的任务) → 重新占用 worker
++runningWorkers
fairnessCounter = 0 // 重置公平性计数器
}
}
}
}核心逻辑拆解:
- 任务循环:不断从队列取任务执行,直到队列为空;
- 异常防护:捕获任务执行的所有异常,避免单个任务崩溃导致整个工作线程退出;
- 公平性控制:每执行 16 个任务,当前线程会"让出"(重新调度自身),让其他线程有机会执行任务,避免单个线程霸占所有任务;
- 资源释放:无任务时减少
runningWorkers,若队列又有任务则重新增加,保证资源不浪费;
dispatchInternal(block: Runnable, dispatch: ()-> Unit) 方法 ------ 任务提交的核心逻辑:
这是任务提交的核心,控制"是否需要启动新的工作线程":
kotlin
internal class LimitedDispatcher(
private val dispatcher: CoroutineDispatcher,
private val parallelism: Int
) : CoroutineDispatcher(), Runnable, Delay by (dispatcher as? Delay ?: DefaultDelay) {
private inline fun dispatchInternal(block: Runnable, dispatch: () -> Unit) {
// 步骤 1: 添加任务到队列,并检查是否已有足够的 worker
if (addAndTryDispatching(block)) return
// 步骤 2: 尝试分配新的 worker(未超过并发数)
if (!tryAllocateWorker()) return
// 步骤 3: 调度当前 LimitedDispatcher(Runnable)到原调度器执行
dispatch()
}
// 步骤 1 辅助方法:添加任务到队列,返回是否已有足够 worker
private fun addAndTryDispatching(block: Runnable): Boolean {
queue.addLast(block) // 任务加入队列
return runningWorkers >= parallelism // 已有足够 worker → 无需启动新的
}
// 步骤 2 辅助方法:尝试分配新的 worker(线程安全)
private fun tryAllocateWorker(): Boolean {
synchronized(workerAllocationLock) {
if (runningWorkers >= parallelism) return false // 超过并发数 → 失败
++runningWorkers // 未超过 → 增加 worker 数
return true
}
}
}核心逻辑分析:
- 添加任务:先把任务加入队列,保证任务不丢失;
- 检查 worker 数:如果已有足够的 worker(
runningWorkers >= parallelism),直接返回(已有 worker 会处理新任务); - 分配新 worker:若 worker 数不足,尝试增加
runningWorkers; - 调度执行:将当前 LimitedDispatcher(作为 Runnable)提交到原调度器执行,启动新的工作线程;
dispatch()/dispatchYield() 方法 ------ 任务提交入口:
两个方法都是任务提交的入口,核心逻辑委托给 dispatchInternal(block: Runnable, dispatch: () -> Unit):
kotlin
internal class LimitedDispatcher(
private val dispatcher: CoroutineDispatcher,
private val parallelism: Int
) : CoroutineDispatcher(), Runnable, Delay by (dispatcher as? Delay ?: DefaultDelay) {
override fun dispatch(context: CoroutineContext, block: Runnable) {
dispatchInternal(block) {
dispatcher.dispatch(this, this) // 普通调度
}
}
@InternalCoroutinesApi
override fun dispatchYield(context: CoroutineContext, block: Runnable) {
dispatchInternal(block) {
dispatcher.dispatchYield(this, this) // 可让出的调度
}
}
}核心差异:
dispatch(context: CoroutineContext, block: Runnable):提交普通任务,最终调用原调度器的dispatch;dispatchYield(context: CoroutineContext, block: Runnable):提交"可让出"的任务(如调用yield()后的任务),最终调用元调度器的dispatchYield;
类的继承关系/实现关系:
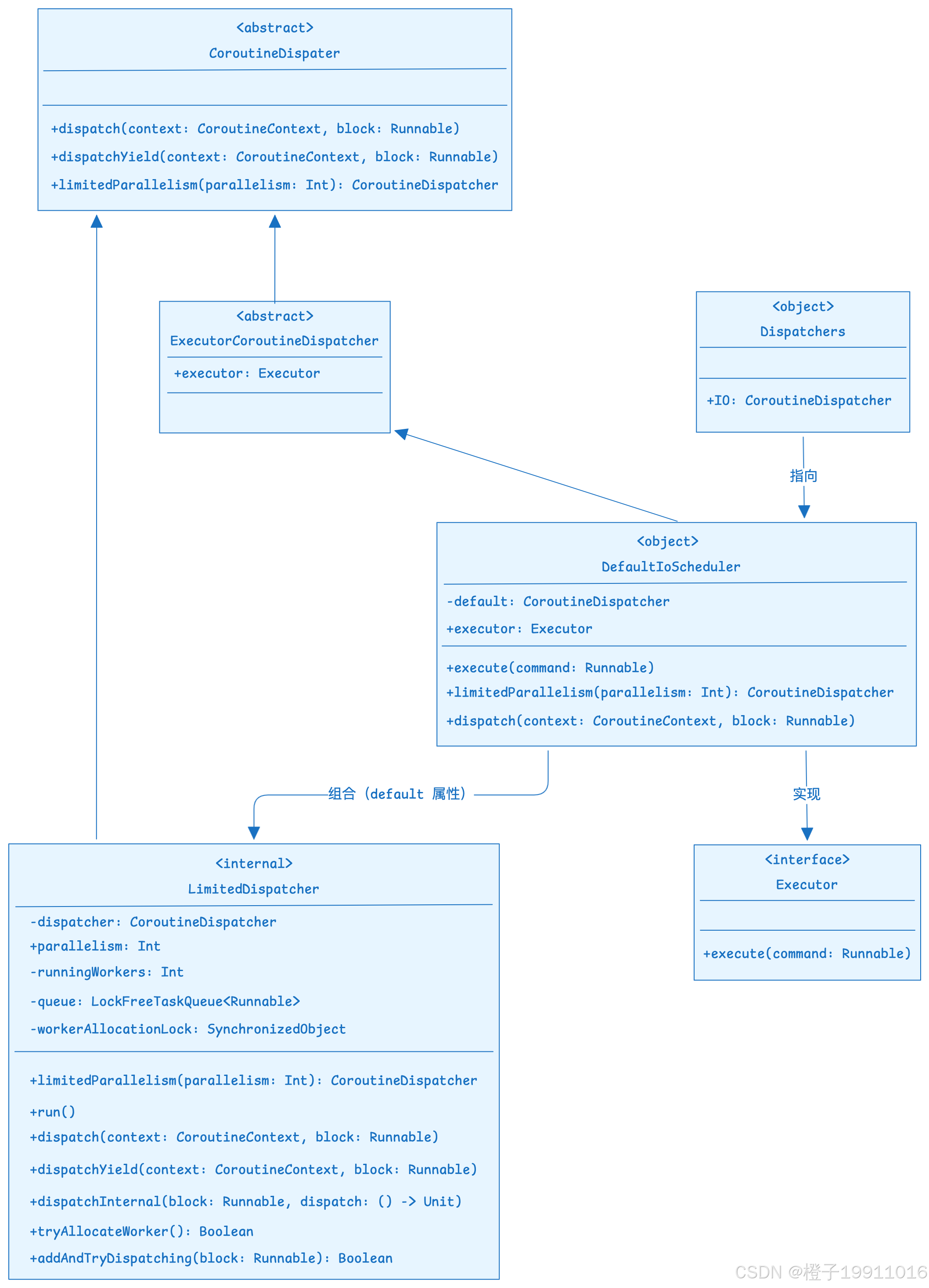
9.4 调度器的线程切换核心示例(底层视角)
以 "IO 线程请求数据 ---> Main 线程更新 UI" 为例,拆解调度器的工作流程:
kotlin
fun main() = runBlocking {
// 1. 用 IO 调度器执行网络请求(IO 线程池)
val data = withContext(Dispatchers.IO) {
// 底层:任务被提交到 IO 线程池的某个线程执行
fetchDataFromNetwork() // IO 密集型任务
}
// 2. 用 Main 调度器更新 UI(主线程)
withContext(Dispatchers.Main) {
// 底层:任务被封装为 Runnable,通过 Handler 提交到主线程 MessageQueue
updateUi(data) // UI 操作
}
}执行流程(底层):
withContext(Dispatchers.IO)触发IODispatcher.dispatch,将fetchDataFromNetwork提交到 IO 线程池的线程 T1;- T1 执行完任务后,将结果返回,协程从 IO 线程挂起恢复;
withContext(Dispatchers.Main)触发MainDispatcher.dispatch,将updateUI提交到主线程的 MessageQueue;- 主线程 Looper 取出任务,在主线程执行
updateUI;
9.5 协程调度器的通用逻辑
调度器本质:CoroutineDispatcher 是调度器的根,它是一个抽象类,其核心方法是 dispatch(context: CoroutineContext, block: Runnable) ,该方法接收「执行上下文」和「协程任务」两个参数,它负责将协程的执行块提交给底层线程(池)执行 ------ 所有的具体调度器(IO/Default/Main)都需要实现此方法。
通用流程:任务提交到执行
- 入口转发:开发者通过
Dispatchers.xxx提交任务,入口单例(如 DefaultScheduler/DefaultIoScheduler)将任务转发到封装层的dispatch方法; - 前置判断:调用
isDispatchNeeded判断是否需要切换线程(如 Main 调度器检查当前是否为主线程,避免无效交换); - 任务封装:将普通 Runnable 封装为协程专属任务对象(如 Task),补充调度元信息(优先级、提交时间、是否阻塞等);
- 引擎调度:
- 通用引擎(Default/IO):CoroutineScheduler 负责"本地队列 + 全局队列"分发、工作窃取、弹性线程唤醒/创建;
- 平台引擎(Main):平台专属实现(如 HandlerDispatcher)将任务提交到主线程消息队列;
- 任务执行:底层线程(线程池/主线程)执行任务,执行完后按规则回收线程(如 CoroutineSheduler 空闲 60s 销毁线程);
性能优化:避免无效开销
- 线程切换优化:
isDispatchNeeded方法判断是否需要切换线程(如 Main 调度器在主线程调用时直接执行任务); - 工作窃取算法:CoroutineScheduler 优先将任务提交到 Worker 本地队列,减少全局队列竞争,最大化 CPU 利用率;
- 弹性线程管理:CoroutineScheduler 优先复用空闲线程(
tryUnpark),无空闲则创建新线程(不超过最大线程数),空闲超时销毁,平衡性能与资源占用;
以 CouroutineDispatcher 为统一抽象标准,通过分层封装适配不同业务场景(CPU/IO/主线程),最终由底层引擎(自研线程池/平台主线程)完成任务的线程调度:
- 统一契约:所有调度器遵循 CoroutineDispatcher 定义的核心行为,保证调用方式一致;
- 分层转发:入口层暴露单例,封装层处理场景适配,执行层完成实际线程调度;
- 适配优化:底层引擎按场景优化(CPU 密集型用弹性线程池、IO 密集型用高并发、主线程用平台绑定),同时通过各种策略(工作窃取、线程复用、容错兜底)保证性能和稳定性;