日志的概述
为什么需要学习日志?
日志的作用就是查看问题
日志就是我们家里系统的"监控摄像头 + 记账本 + 行车记录仪",而 Spring Boot 把这套东西装好了,你基本不用自己搭。
1. 系统监控------给系统戴个"健康手环"
- 平时干啥:Spring Boot 会自动记下每个请求花了多久、有没有报错。哪天突然错误暴增,或者某个接口慢得像蜗牛,你翻日志就能看到。
- Spring Boot 怎么帮你:它内置了一个小工具(Actuator),你可以在不重启的情况下随时调整日志的"嗓门大小"(比如平时只记错误,出问题后改成记所有细节),方便排查问题。
- 还能报警:把日志里的错误数量统计出来,超过一定数值就发微信告警,你就能在用户骂娘之前发现系统挂了。
2. 数据采集------记录用户的"脚印",用来赚钱
- 平时干啥:谁访问了哪个页面、点了哪个按钮、停留了多久,这些用户行为都可以记在日志里。
- Spring Boot 怎么帮你:它默认的日志格式可以改成 JSON 格式,这样其他程序(比如大数据分析系统)就能直接读日志文件,分析出"哪个商品最受欢迎",然后给你推荐算法喂数据。Spring Boot 还会自动帮你把日志按天切分成小文件,方便清理和搬运。
3. 日志审计------出事之后能"甩锅"
- 平时干啥:谁删了数据库的一条数据?谁改了核心配置?这些操作统统记下来。
- Spring Boot 怎么帮你:配合 Spring Security,它会自动记录谁登录了、谁登录失败。你可以写几行代码,用 AOP(一种拦截技术)自动在每次用户操作时写一行日志:"张三在 10:00 删了订单 123"。哪天客户说"我数据没了",你翻出日志就能怼回去:"看,是你自己删的!"
总结一句
Spring Boot 把日志这套东西给你预制好了------你只用写业务代码,它自动帮你记下系统状态、用户行为、操作记录,出了问题看日志,要分析数据导日志,要合规留底也用日志。省心。【咱们开发人员就主要知道如何打日志】
日志的使用
打印日志
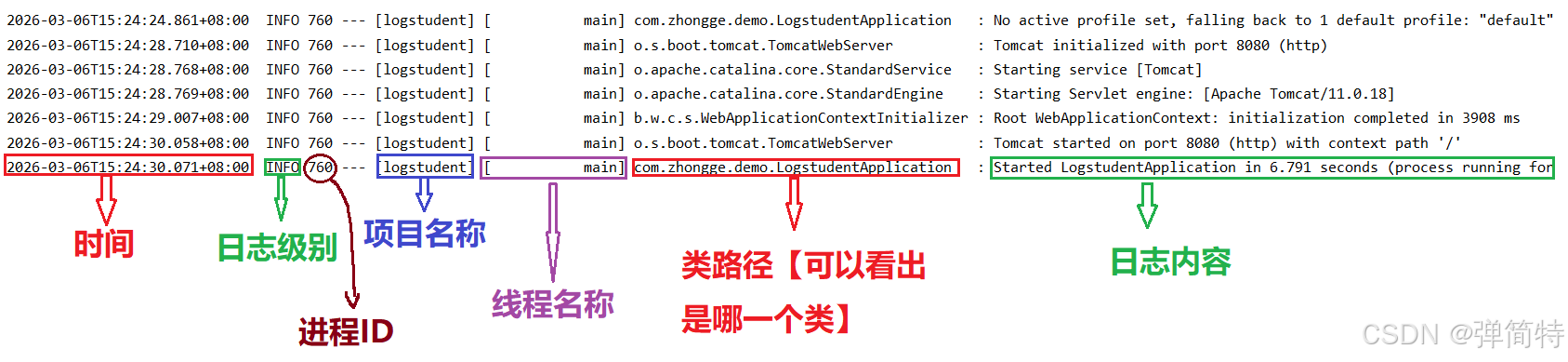
启动程序观察控制台信息
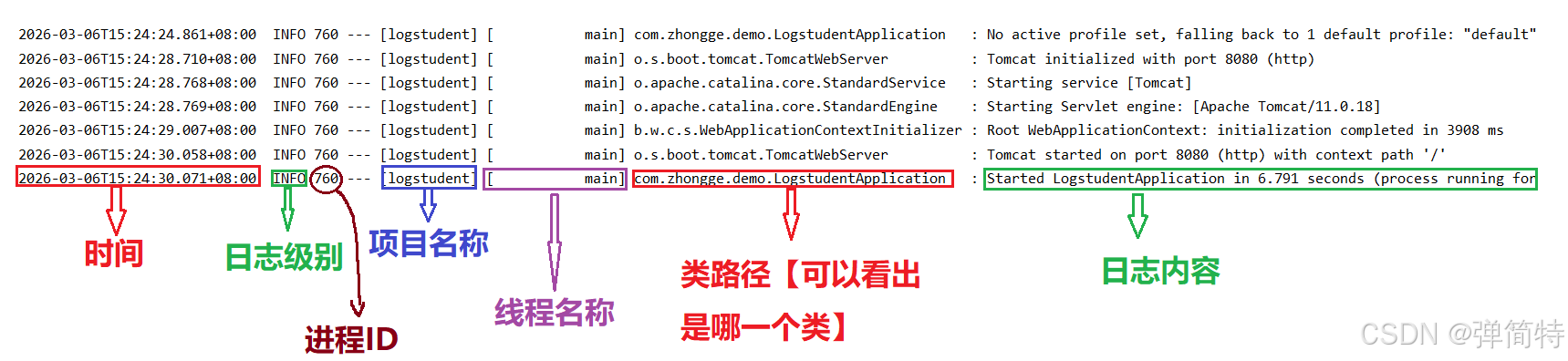
上述是我们启动程序由spring自动为我们打印出的日志样式,那么我们自己如何照葫芦画瓢呢?
如何打印出上述的日志
spring内置了一个日志框架Slf4j ,我们可以直接在程序中调⽤Slf4j 来输出⽇志
1.选择Slf4j这个包里面的

2.从工厂中拿到日志对象
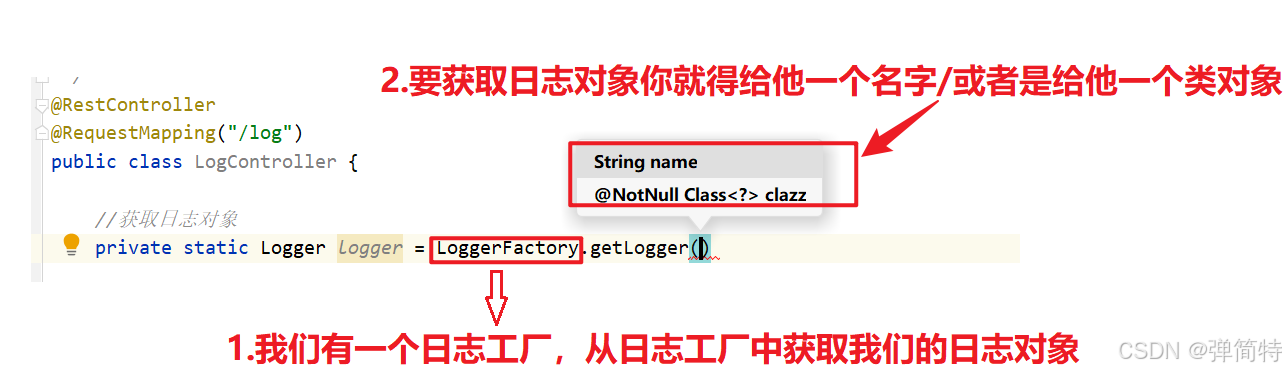
3.最终的完整获取日志对象代码:
java
private static Logger logger = LoggerFactory.getLogger(LogController.class);4.使用sout和使用logger打印日志的代码
java
package com.zhongge.demo.controller;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @ClassName LogController
* @Description TODO 日志的使用
* @Author 笨忠
* @Date 2026-03-06 15:51
* @Version 1.0
*/
@RestController
@RequestMapping("/log")
public class LogController {
//获取日志对象
private static Logger logger = LoggerFactory.getLogger(LogController.class);
//打印日志
@RequestMapping("/print")
public String print() {
//对比1:使用sout打印日志
System.out.println("sout 打印日志!!!");
//对比2:使用logger打印日志
logger.info("logger 打印日志!!!");
return "打印日志";
}
}5.结果:
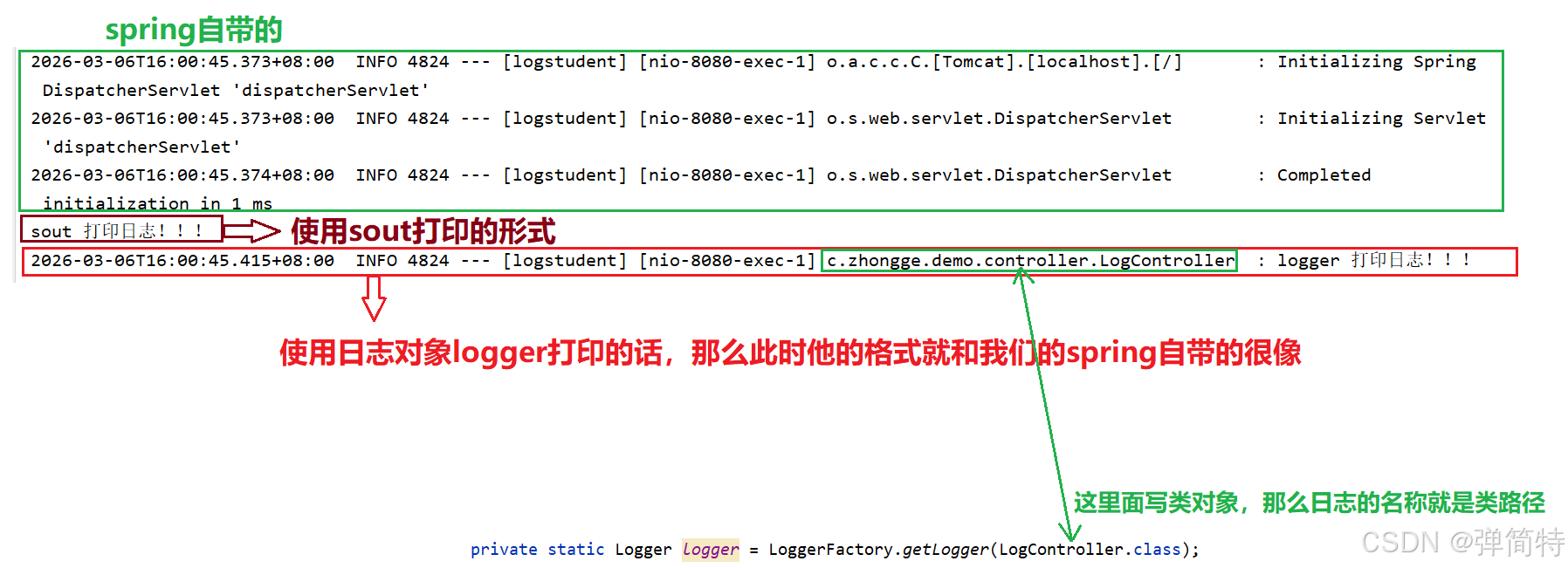
如果我们写的是自定义日志的名称:
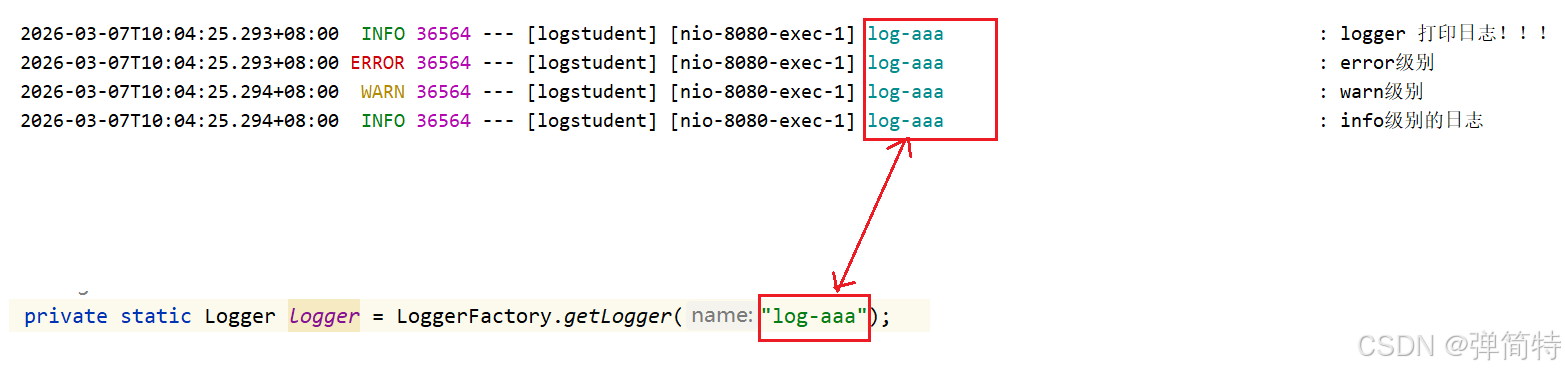
6.总结就是只有两行代码:
java
Logger logger = LoggerFactory.getLogger(LogController.class);
logger.info("日志信息");日志框架
我们有四个日志框架:
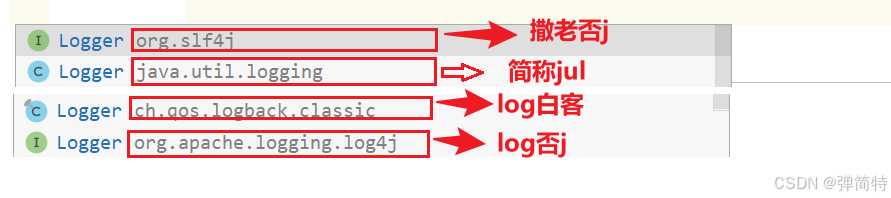
那么这四个日志框架有什么区别?为什么我们选择slf4j呢?
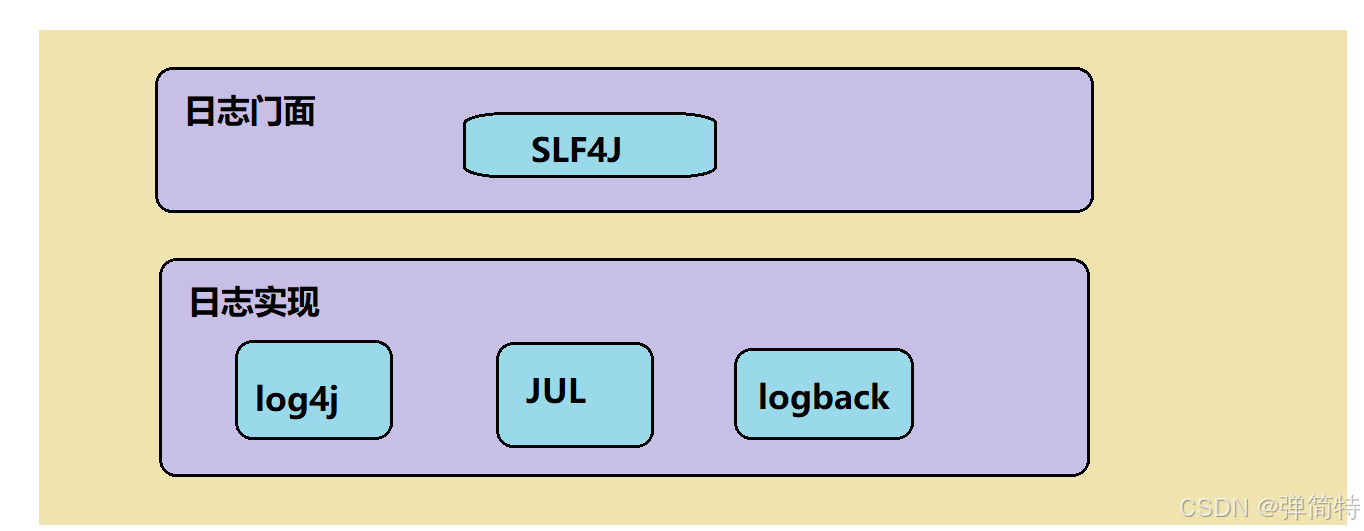
首先这四个我们分为两类:日志的门面【slf4j】和日志的实现【jul,logback,log4j】。
那么日志的门面和日志的实现有什么关系?
它们可以分成两类:
- 日志门面(日志接口) :
SLF4J(Simple Logging Facade for Java) - 日志实现 :
JUL(Java Util Logging)、Logback、Log4j
关系本质:通用遥控器与电视机

- SLF4J 就像是一个万能遥控器 。它上面只有几个通用的按钮:开机、关机、音量+、音量-、频道+、频道-(对应日志的
debug、info、error等方法)。你按这些按钮,不需要关心电视是哪个牌子。 - Logback、Log4j、JUL 就像是不同品牌的电视机。每个电视机都有自己的原装遥控器(它们各自的API),操作方式可能略有不同(比如有的用红外,有的用蓝牙)。但万能遥控器(SLF4J)可以通过学习(绑定/适配)来操控它们。
门面模式
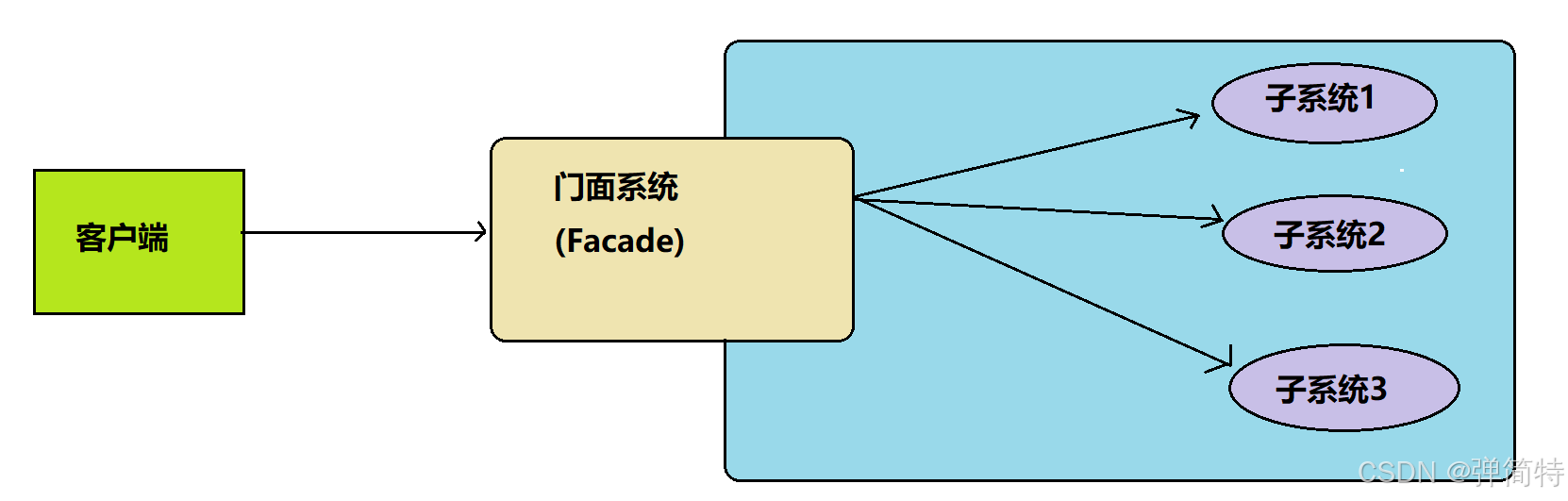
定义 :⻔⾯模式(Facade Pattern)⼜称为外观模式,提供了⼀个统⼀的接,⽤来访问⼦系统中的⼀群接.
其主要特征是定义了⼀个⾼层接,让⼦系统更容易使⽤.即要求⼀个⼦系统的外部与其内部的通信必须通过⼀个统⼀的对象进⾏.⻔⾯模式提供⼀个⾼层次的接⼝,使得⼦系统更易于使⽤.
门面模式的角色:
- 外观⻆⾊(Facade):也称⻔⾯⻆⾊,系统对外的统⼀接⼝.
- ⼦系统⻆⾊(SubSystem):可以同时有⼀个或多个SubSystem.每个SubSytem都不是⼀个单独的类,⽽是⼀个类的集合.SubSystem并不知道Facade的存在,对于SubSystem⽽⾔,Facade只是另⼀个
客⼾端⽽已(即Facade对SubSystem透明)
到底是什么意思呢?举个例子:
<一>、门面模式的两个角色,用「餐厅点餐」理解
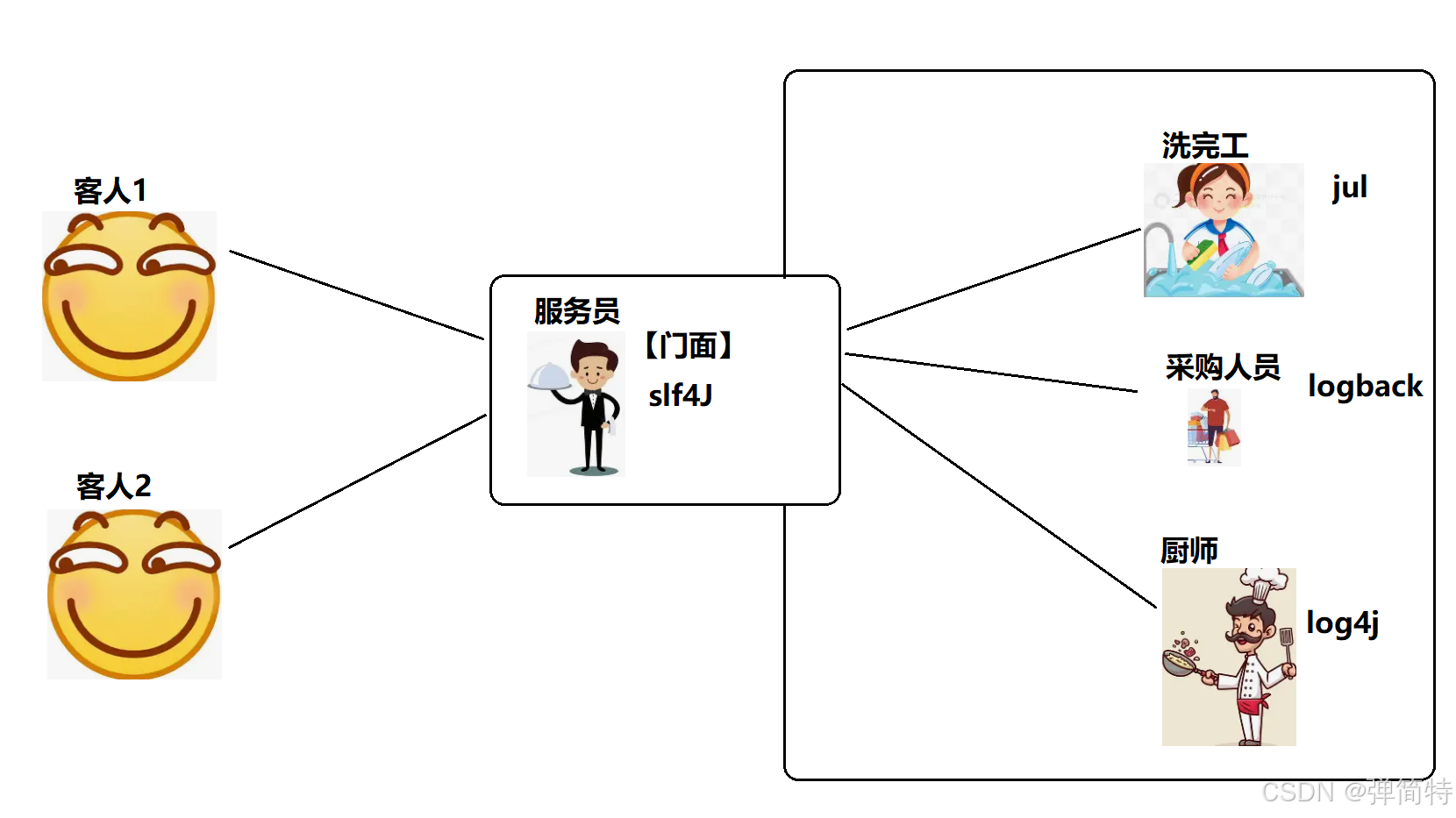
门面模式就两个角色:
- 外观角色(Facade) :就是餐厅里那个服务员 。
- 你只需要跟服务员说"我要一份红烧肉",其他事不用管。
- 服务员不炒菜、不买菜、不洗碗,他只负责把你的需求传进去 ,再把结果端出来。
- 对顾客来说,服务员就是餐厅的统一入口。
- 子系统角色(SubSystem) :就是后厨那一堆人------厨师、采购、洗碗工 。
- 他们每个人都有自己的分工(子系统里的多个类)。
- 重要的是:他们不知道服务员的存在。厨师只管做菜,他不会想"这是服务员让我做的",他只知道有人把菜单递进来了,他就做。
- 也就是说,服务员对厨师是透明的,厨师不需要知道服务员是谁。
门面模式的核心:让顾客(客户端)只跟服务员(门面)打交道,不用自己进后厨(子系统)找每个人。
<二>、把门面模式套到日志框架上
现在我们把上面的角色换成日志框架的术语:
- 外观角色(Facade) → SLF4J(就像服务员)
- 子系统角色(SubSystem) → JUL、Logback、Log4j(就像后厨里的各种人员)
1. SLF4J(服务员)
- SLF4J 只提供一个统一的接口:
logger.info("hello")、logger.debug("world")这些方法。 - 它自己不写日志(不炒菜),只是把你的日志需求传进去给真正的日志框架。
- 你在代码里永远只对着 SLF4J 编程,就像你只跟服务员点餐一样。
2. JUL、Logback、Log4j(后厨人员)
- 这三个才是真正干活的日志框架,它们负责把日志写到控制台、文件、数据库(相当于厨师做菜、采购备料、洗碗工洗碗)。
- 它们各有各的 API(不同的原装遥控器),但 SLF4J 通过一种叫**"适配器"或"绑定器"**的东西,把 SLF4J 的调用转成它们能听懂的命令。
- 重要的是:它们不知道 SLF4J 的存在 。
- Logback 收到日志请求时,它只知道有人叫它干活,它不会去想"这是 SLF4J 叫我做的"。
- 所以 SLF4J 对 Logback 是透明的------完全符合门面模式里"子系统不知道门面存在"的特点。
<三>、它们之间怎么连接的?------适配器(绑定器)
你可能会问:服务员(SLF4J)怎么把菜单传给后厨(Logback)?
这中间需要一个**"传菜员",在日志框架里叫绑定器**(Binding)。
- 如果你项目里用的是 Logback,就引入
slf4j-logback这个绑定器。 - 如果你用 Log4j,就引入
slf4j-log4j12。 - 如果你用 JUL(Java 自带的日志框架),就引入
slf4j-jdk14。
绑定器的作用:
- 它让 SLF4J 的 API 调用,能正确找到底层的 Logback、Log4j 或 JUL,并执行它们的代码。
- 你只要在项目里放一个绑定器,SLF4J 就自动知道该跟哪个"后厨"通信。
具体关系细节
- SLF4J(门面) :
- 它只定义了一套日志记录的接口(比如
org.slf4j.Logger,里面有info(),debug()等方法)。 - 它自己不输出日志,只是占个位置,起一个"调度"作用。
- 它就像一个空壳,里面没有真正写日志的代码。
- 它只定义了一套日志记录的接口(比如
- Logback、Log4j、JUL(实现) :
- 它们是真正干活的框架,负责把日志消息写到控制台、文件、数据库等地方。
- 它们各自有一套自己的API,如果没有SLF4J,你的代码就得直接调用它们的方法,一旦想换另一个,代码就得重写。
- 它们如何协作?
- 你的代码中只使用SLF4J的API。
- 在项目里,你需要引入SLF4J的jar包,以及一个 "适配器" (或者叫"绑定器"),这个适配器的作用就是把SLF4J的调用转换成具体日志框架的调用。
- 比如你想用Logback,就引入
slf4j-logback的适配包。Logback本身就实现了SLF4J的接口,所以能直接绑定。 - 比如你想用Log4j,就引入
slf4j-log4j12的适配包。 - 比如你想用JUL,就引入
slf4j-jdk14的适配包。
- 比如你想用Logback,就引入
- 运行时,SLF4J会通过适配器找到底层的日志框架,把日志指令传给它去执行。
<四>、为什么 Spring Boot 默认用 SLF4J + Logback?
Spring Boot 帮我们选好了组合:
- 门面(服务员):SLF4J
- 实现(后厨):Logback
- 绑定器:因为 Logback 本身就实现了 SLF4J 的接口,所以不需要额外的绑定器,直接就能用。
所以你在 Spring Boot 里写日志时:
java
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
Logger logger = LoggerFactory.getLogger(MyClass.class);
logger.info("你好");你用的是 SLF4J 的 API,但实际干活的是 Logback。
<五>、用门面模式有什么好处?
- 解耦:你的代码只依赖 SLF4J(服务员),不依赖具体日志框架(后厨)。将来你想从 Logback 换成 Log4j,只需要换掉绑定器,不用改一行代码。
- 统一入口:不管项目里用了多少第三方库(比如 Hibernate 用 JUL,Spring 用 Logback),只要把它们都桥接到 SLF4J,整个项目的日志输出就可以统一管理。
<六>、总结一句话
- SLF4J = 餐厅服务员(门面)
- JUL、Logback、Log4j = 后厨里的各种人员(子系统)
- 绑定器 = 传菜员,把服务员的指令传给具体的人
- 服务员(门面)不知道后厨内部是谁在干活,后厨也不知道外面有服务员------这就是门面模式的精髓。
现在再回头看定义:
外观角色(Facade):系统对外的统一接口。
子系统角色(SubSystem):不知道外观的存在,外观对子系统透明。
演示门面模式
场景 :在家,我们会开各个屋的灯【卧室的,客厅的,走廊灯】.离开家时,会关闭各个屋的灯
如果家⾥设置⼀个总开关,来控制整个屋的灯就会很⽅便.此时我们使用门面模式来实现:
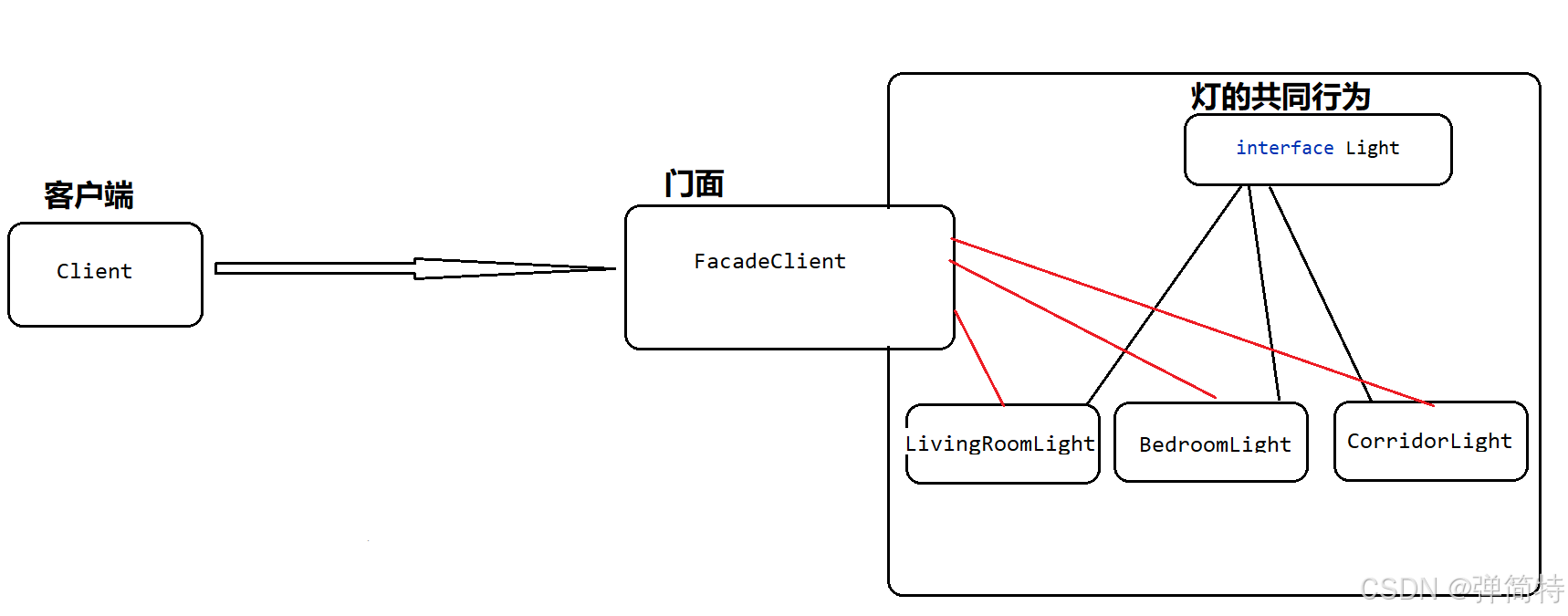
1.首先有不同的灯,所以我们可以将灯的行为抽象成一个接口
java
public interface Light {
//开灯
void on();
//关灯
void off();
}2.实现3个不同的灯【3个子系统】
java
//卧室的灯
public class BedroomLight implements Light{
@Override
public void on() {
System.out.println("打开卧室的灯");
}
@Override
public void off() {
System.out.println("关闭卧室的灯");
}
}
//客厅的灯
public class LivingRoomLight implements Light{
@Override
public void on() {
System.out.println("打开客厅的灯");
}
@Override
public void off() {
System.out.println("关闭客厅的灯");
}
}
//走廊的灯
public class CorridorLight implements Light{
@Override
public void on() {
System.out.println("打开走廊的灯");
}
@Override
public void off() {
System.out.println("关闭走廊的灯");
}
}3.为这几个灯实现一个总开关【门面】
java
public class FacadeClient {
//门面操控所用的灯
LivingRoomLight livingRoomLight = new LivingRoomLight();//客厅的灯
BedroomLight bedroomLight = new BedroomLight();//卧室的灯
CorridorLight corridorLight = new CorridorLight();//走廊的灯
//关灯
public void on() {
livingRoomLight.on();
bedroomLight.on();
corridorLight.on();
}
//开灯
public void off() {
livingRoomLight.off();
bedroomLight.off();
corridorLight.off();
}
}4.写一个客户端
java
public class Client {
public static void main(String[] args) {
//和门面对接
FacadeClient facadeClient = new FacadeClient();
//打开所有的灯
facadeClient.on();
//关闭所有的灯
facadeClient.off();
}
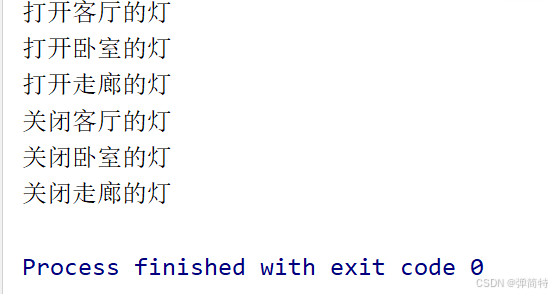
}5.结果:
日志格式的使用
日志级别
日志级别的分类
日志级别从高到低依次为:FATAL、ERROR、WARN、INFO、DEBUG、TRACE
- FATAL:致命信息,表示需要立即被处理的系统级错误。
- ERROR:错误信息,级别较高的错误日志信息,但仍然不影响系统的继续运行。
- WARN:警告信息,不影响使用,但需要注意的问题。
- INFO:普通信息,用于记录应用程序正常运行时的一些信息,例如系统启动完成、请求处理完成等。
- DEBUG:调试信息,需要调试时候的关键信息打印。
- TRACE:追踪信息,比DEBUG更细粒度的信息事件【一般我们不使用这个级别】(除非有特殊用意,否则请使用DEBUG级别替代)。
举个例子:
日志级别就像你公司里的事情汇报机制。你是大老板,下面两万人,要是什么事都找你,你早疯了。所以分了级,重要的事往上捅,小事自己消化。
- FATAL:公司核心机房炸了,业务全停。必须马上把你从被窝里叫起来拍板。
- ERROR:销售部系统出 bug,订单慢了,但还能接。你得知道,让技术总监赶紧修。
- WARN:行政说这个月水电费涨了20%,可能有人浪费。你心里有数就行,不用立刻管。
- INFO:每天各部门简报------销售额、招聘进度。扫一眼,知道公司正常运转。
- DEBUG:你想查某个项目为啥延期,助理翻出项目组每天的工作日报。平时不看,查问题才用。
- TRACE:你想知道某个员工几点去上了几次厕所,保安调出监控。只有闲得慌才看。
有了级别,你就能只盯FATAL和ERROR,偶尔翻翻WARN,其他爱谁谁,省心省力。
日志级别的使用
java
//没有fatal级别的方法,因为他是最致命的级别的,都已经致命了,你打印出来没有用呀
logger.error("error级别");
logger.warn("warn级别");
logger.info("info级别的日志");
logger.debug("debug级别");
logger.trace("trace级别");结果:
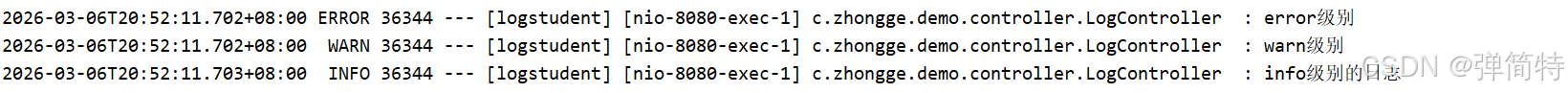
从结果中可以看出:他并没有将debug和trace级别的日志打印出来,原因就是说,我们的并不是什么鸡皮蒜毛的事情都要汇报,我们spring默认的级别就是info,那么只要是低于这个级别的都不需要打印出来了,也就是说info的事情是可以正常汇报的,那么比info级别还小的事情就不要汇报了。
日志配置
配置日志级别
那么我们说spring默认的日志级别是info,比这个日志级别小的就没必要打印了,所以我们是可以设置日志的默认级别的【通过配置文件来设置】:
yml
# 配置日志的级别
logging:
level:
root: trace #配置到最小级别此时所有的级别都可以打印出来了
java
logger.error("error级别");
logger.warn("warn级别");
logger.info("info级别的日志");
logger.debug("debug级别");
logger.trace("trace级别");结果:

解释日志级别的设置不同目录

root代表根目录的级别是info
现在如果我需要将com.zhongge.demo.controller目录/路径的日志级别设置为trace,则进行下述写法:
yml
logging:
level:
root: info
com:
zhongge:
demo:
controller: trace
配置日志持久化
我们在启动项目或者是开发的过程中,不可能一直盯着这个日志来观察,他不可能一下子就看得完,此时我们就需要将我们的日志保存下来,以便出现问题后追溯问题,把日志保存下来,持久化保存就是保存在我们的硬盘上面,这个过程叫做日志的持久化。
日志的持久化有两种方式:
- 第1种是配置日志的文件名
- 第2种是配置日志的存储目录
配置日志的文件名
Properties配置
properties
logging.file.name=log.logyml配置
yml
# 配置日志的文件名
logging:
file:
name: log.log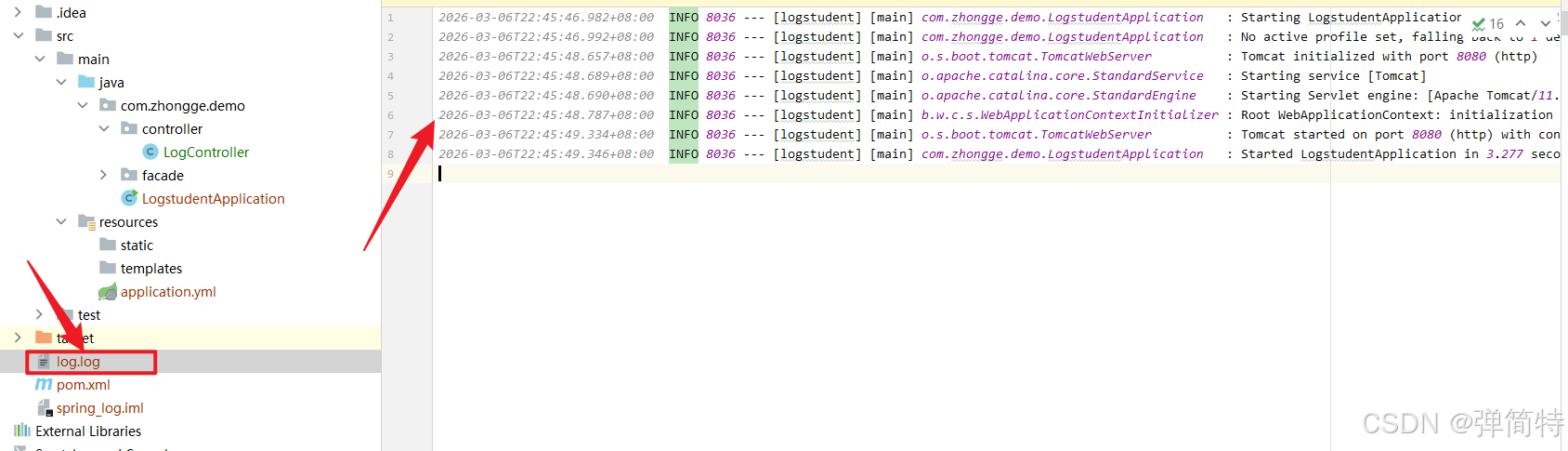
也可以加上路径
yml
# 配置日志的文件名
logging:
file:
name: logger/log.log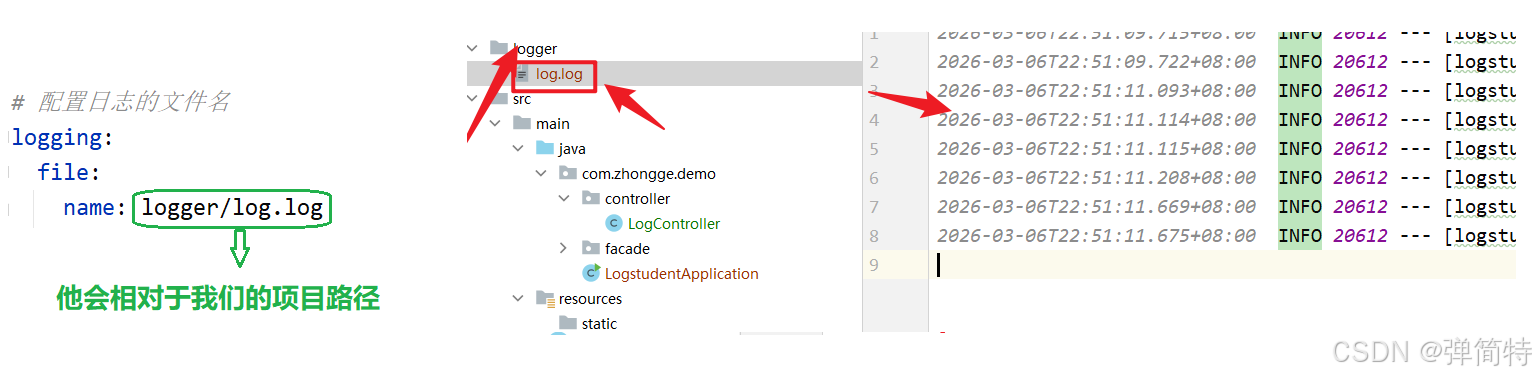
配置日志的存储目录
Properties配置
properties
logging.file.path=loggeryml配置
yml
logging:
file:
path: logger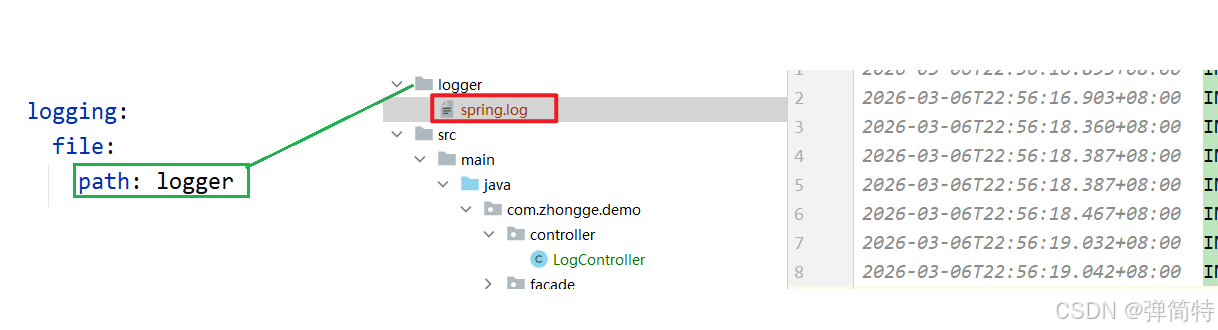
注意:这种⽅式只能设置⽇志的路径,⽂件名为固定的spring.log
注意: logging.file.name 和logging.file.path 两个都配置的情况下,只⽣效其⼀,以 logging.file.name 为准.

日志文件分割
为什么需要分割?
如果不分割,所有日志都写到一个文件里,随着项目运行,文件会变得巨大(几个GB),导致:
- 打开慢,查找问题困难
- 占用磁盘空间
- 备份、清理不方便
日志框架(如 Logback)内置了滚动策略(Rolling Policy),默认当文件超过 10MB 时自动分割。
核心配置项(附英文翻译)
| 配置项 | 英文单词 | 中文含义 | 说明 | 默认值 |
|---|---|---|---|---|
file-name-pattern |
file name pattern | 文件名模式 | 分割后的日志文件命名规则 | ${LOG_FILE}.%d{yyyy-MM-dd}.%i.gz |
max-file-size |
maximum file size | 最大文件大小 | 超过此大小触发分割 | 10MB |
file-name-pattern详解${LOG_FILE}:基础日志文件名(在logging.file.name或logging.file.path中定义)%d{yyyy-MM-dd}:当前日期,例如2025-03-06%i:索引号,从0开始递增,用于区分同一天生成的多个分割文件.gz:自动压缩为 gzip 格式,节省空间(也可不压缩,去掉即可)
配置示例(设置 1KB 便于观察效果)
-
properties 格式
properties# 日志文件基础名称(假设为 app.log) logging.file.name=log/app.log # 分割后文件名模式 logging.logback.rollingpolicy.file-name-pattern=${LOG_FILE}.%d{yyyy-MM-dd}.%i # 超过 1KB 就分割 logging.logback.rollingpolicy.max-file-size=1KB -
yml 格式
yamllogging: file: name: log/app.log # 基础日志文件名 logback: rollingpolicy: max-file-size: 1KB file-name-pattern: ${LOG_FILE}.%d{yyyy-MM-dd}.%i #如果超过的话,设置分割后的文件名字
实际效果
当 app.log 超过 1KB 时,系统会自动:
- 将当前日志重命名为
app.log.2025-03-06.0(可能压缩为.gz) - 创建新的
app.log继续写入 - 后续再超过大小,则生成
app.log.2025-03-06.1、app.log.2025-03-06.2......
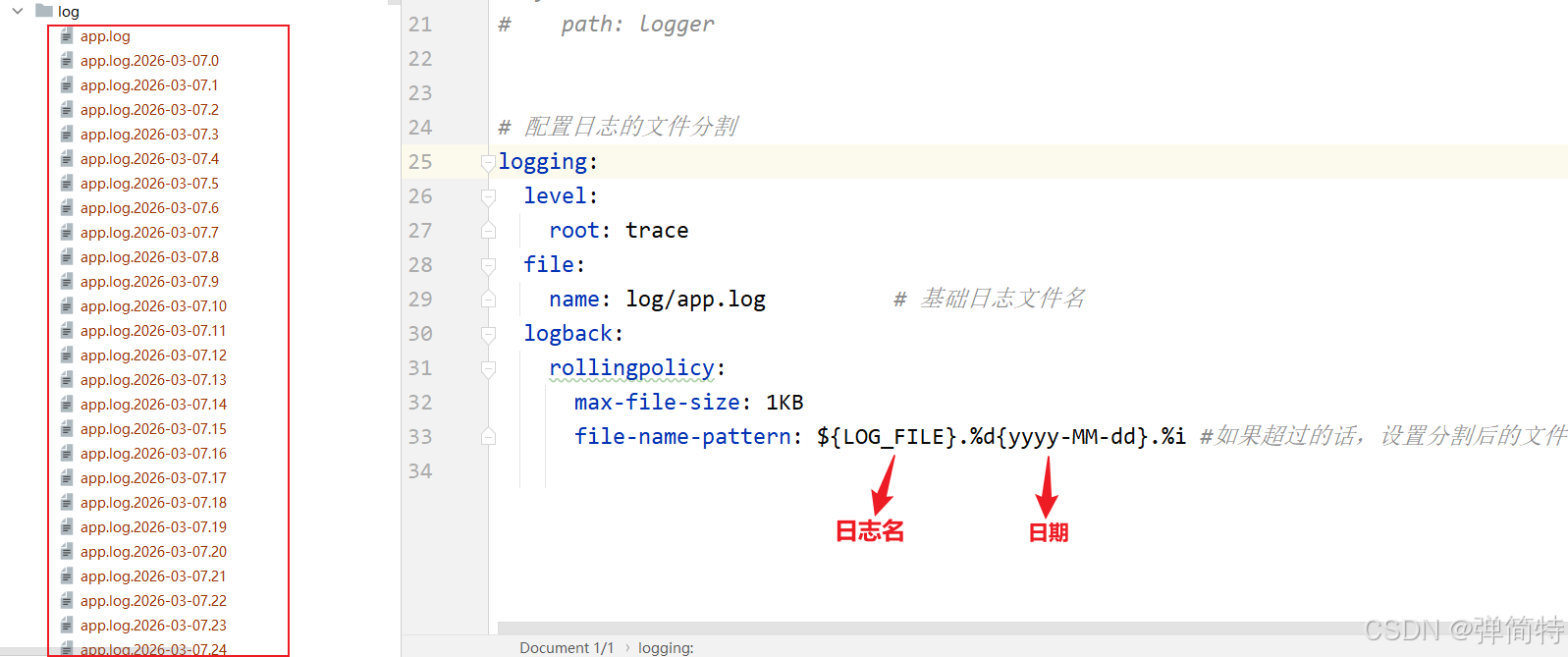
注意:max-file-size :一般设置为 200MB、500MB 或 1GB,没有绝对标准,根据日志量和磁盘空间决定。
日志格式配置【了解,一般我们不去配置,直接复制粘贴】
Spring Boot 允许分别定制 控制台(Console) 和 文件(File) 的日志输出格式。默认格式已经很全面,但如果需要调整(如增加类名、方法名、行号),可以自行配置。
常用占位符
| 占位符 | 英文全称 | 中文含义 | 示例输出 |
|---|---|---|---|
%d |
date | 日期时间 | 2025-03-06 14:30:25.123 |
%p |
level | 日志级别 | ERROR, INFO |
%t |
thread | 线程名 | http-nio-8080-exec-1 |
%c |
class | 类的全限定名 | com.example.demo.controller.UserController |
%M |
method | 方法名 | getUserById |
%L |
line | 代码行号 | 42 |
%m 或 %msg |
message | 日志消息 | 你写的日志内容 |
%n |
newline | 换行符 | (平台无关的换行) |
%clr(...){color} |
color | 给文本上色 | %clr(ERROR){red} 将 ERROR 显示为红色 |
%5p |
width | 级别输出占5位,右对齐,不足补空格 | INFO 显示为 " INFO"(前面一个空格) |
%-5p |
left-align | 左对齐,不足补空格 | INFO 显示为 "INFO " |
%.15 |
truncate | 超过15字符截断 | 长类名只显示前15个字符 |
%15.15 |
both | 最小15字符(右补),超过截断 | 保证输出宽度固定为15 |
颜色支持(%clr)
可用的颜色:blue、cyan、faint(淡色)、green、magenta、red、yellow。
默认格式拆解(控制台)
%clr(%d{${LOG_DATEFORMAT_PATTERN:-yyyy-MM-dd'T'HH:mm:ss.SSSXXX}}){faint}
%clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint}
%clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint}
%m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}- 日期(淡色)、级别(自动颜色)、进程ID(品红)、分隔符(淡色)、线程名(淡色固定宽度15)、Logger名(青色,最多40字符左对齐)、消息和异常。
自定义配置示例
-
properties 格式
propertieslogging.pattern.console=%d{yyyy-MM-dd HH:mm:ss.SSS} %c %M %L [%thread] %m%n logging.pattern.file=%d{yyyy-MM-dd HH:mm:ss.SSS} %c %M %L [%thread] %m%n -
yml 格式
yamllogging: pattern: console: '%d{yyyy-MM-dd HH:mm:ss.SSS} %c %M %L [%thread] %m%n' file: '%d{yyyy-MM-dd HH:mm:ss.SSS} %c %M %L [%thread] %m%n'
让控制台颜色生效
IDEA 默认可能不显示 ANSI 颜色,需添加 JVM 参数:
-Dspring.output.ansi.enabled=ALWAYS添加位置:Run/Debug Configuration → VM options。
建议
通常使用默认格式即可,除非需要调试特定问题(如追踪代码行)。过多输出(如行号、方法名)会影响性能,谨慎使用。
附:配置项英文单词速记表【声明:AI辅助整理】
| 配置前缀 | 英文单词 | 含义 |
|---|---|---|
logging.logback.rollingpolicy.file-name-pattern |
file name pattern | 文件名模式 |
logging.logback.rollingpolicy.max-file-size |
max file size | 最大文件大小 |
logging.pattern.console |
console pattern | 控制台输出格式 |
logging.pattern.file |
file pattern | 文件输出格式 |
%d |
date | 日期 |
%p |
level | 级别 |
%t |
thread | 线程 |
%c |
class | 类 |
%M |
method | 方法 |
%L |
line | 行号 |
%m |
message | 消息 |
%n |
newline | 换行 |
%clr |
color | 颜色 |
%i |
index | 索引(分割文件序号) |
简单的日志输出
为什么需要简化?
因为每次在类中输出日志,都要写一行:
java
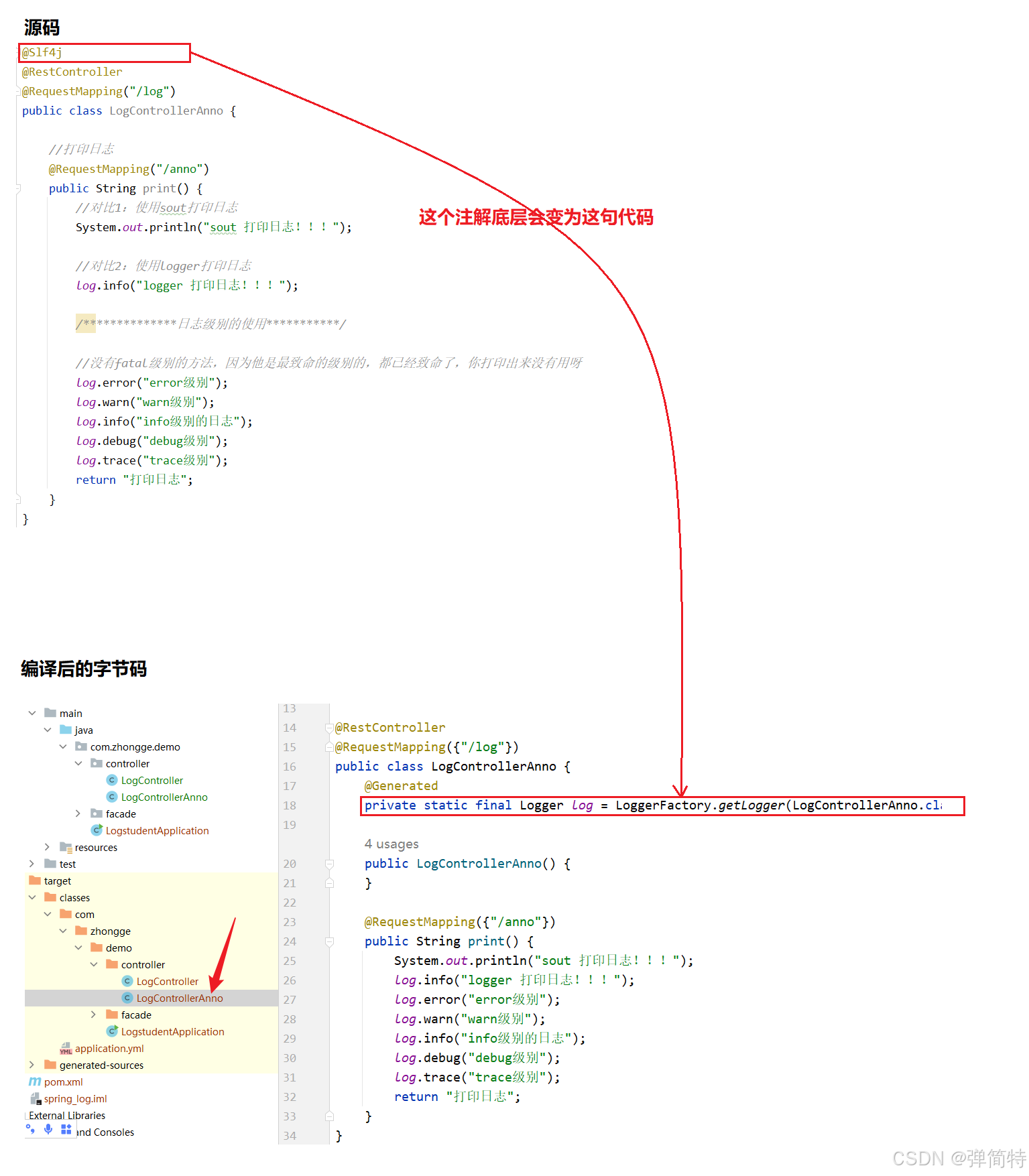
private static final Logger log = LoggerFactory.getLogger(XXX.class);每个类都要重复,代码臃肿且容易遗漏。此时我们可以将这一行封装为一个注解,Lombok 通过注解自动生成日志对象,一行搞定。
3.1 添加 Lombok 依赖
在 pom.xml 中加入:
xml
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>optional:表示该依赖只在编译时使用,不会传递到其他模块。
3.2 使用 @Slf4j 注解输出日志
java
package com.zhongge.demo.controller;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
/**
* @ClassName LogController
* @Description TODO 日志的使用[注解]
* @Author 笨忠
* @Date 2026-03-06 15:51
* @Version 1.0
*/
@Slf4j
@RestController
@RequestMapping("/log")
public class LogControllerAnno {
//打印日志
@RequestMapping("/anno")
public String print() {
//对比1:使用sout打印日志
System.out.println("sout 打印日志!!!");
//对比2:使用logger打印日志
log.info("logger 打印日志!!!");
/**************日志级别的使用***********/
//没有fatal级别的方法,因为他是最致命的级别的,都已经致命了,你打印出来没有用呀
log.error("error级别");
log.warn("warn级别");
log.info("info级别的日志");
log.debug("debug级别");
log.trace("trace级别");
return "打印日志";
}
}@Slf4j:Lombok 提供的注解,编译后会为当前类生成一个名为log的静态日志对象(基于 SLF4J API)。log:直接使用该对象调用info()、debug()、error()等方法。
原理: