摘要 :本文介绍 Transformer 解码器中的编码器-解码器注意力层(交叉注意力层)的原理与数学推导。重点说明 Q 来自解码器、K/V 来自编码器的设定,以及 A t t e n t i o n ( Q d e c , K e n c , V e n c ) Attention(Q_{dec}, K_{enc}, V_{enc}) Attention(Qdec,Kenc,Venc) 的矩阵维度与计算流程;从掩码自注意力输出与编码器输出出发,推导交叉注意力如何将源序列信息整合到解码的每一步,并对应「输入 X + 已生成 y 前半段 → 预测 y 下一词」的训练流程。最后概括该层在关联输入输出、捕捉全局上下文以及增强解码能力中的作用。
关键词:Transformer;编码器-解码器注意力;交叉注意力;Query-Key-Value;多头注意力;序列到序列
首先我们介绍 Transformer 的 Decoder 模块的 编码器-解码器注意力层(通常称为"交叉注意力"层),即下图红框位置:
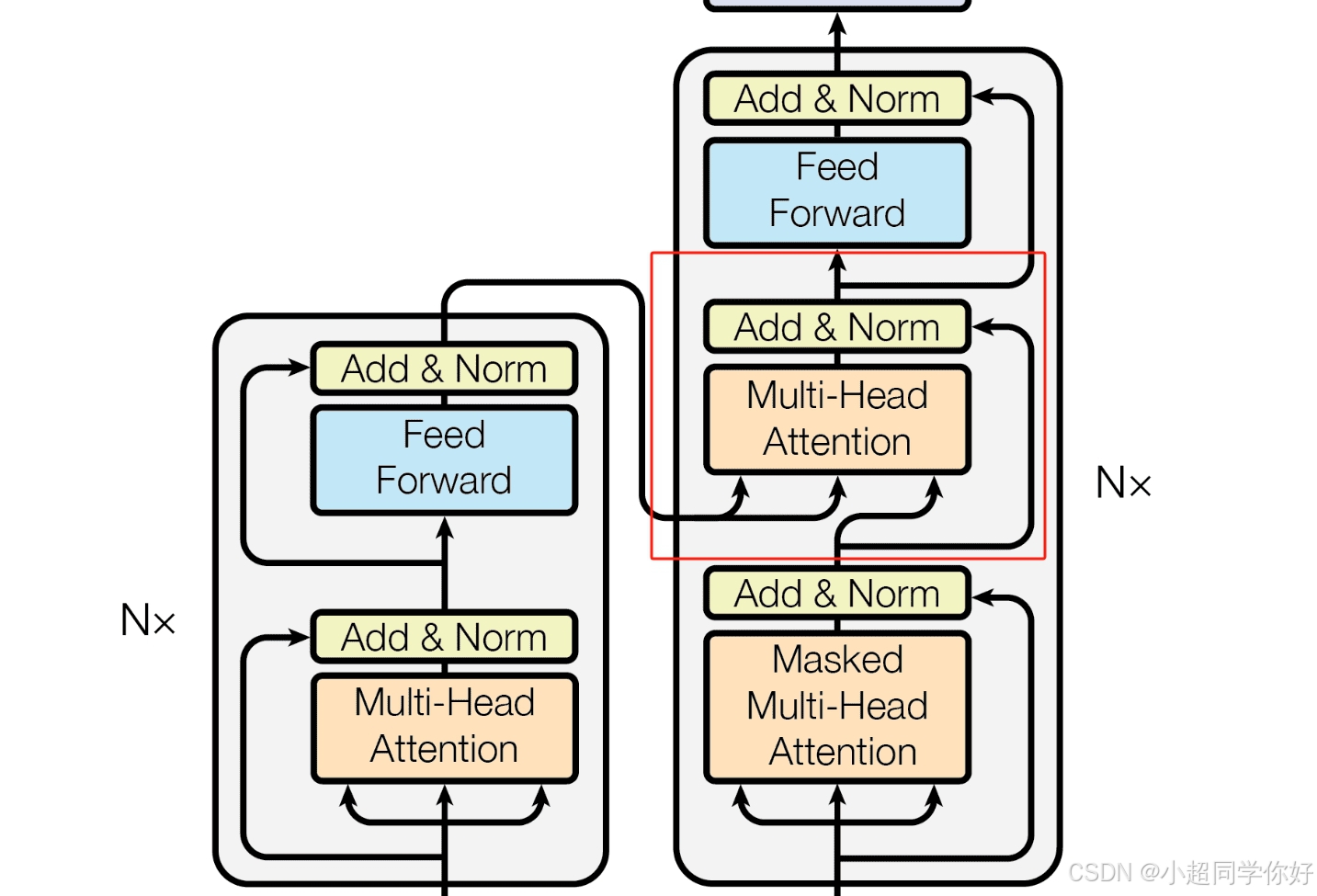
在Transformer模型的解码器部分,编码器-解码器注意力层(通常称为"交叉注意力"层)起着至关重要的作用。这一层允许解码器的每个位置访问整个编码器的输出,这对于将输入序列的上下文信息整合到输出序列的生成中是必需的。这个层的设计是为了确保解码器能够基于完整的输入序列信息来生成每个输出元素。
1 一些参数定义
首先,我们回到注意力公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk QKT)V
d k d_k dk是向量维度,比如GPT3里面12288维。
- Q: Query
- K : Key
- V : Value
对于Decoder的掩码注意力层,Q/K/V 是通过三个不同的权重矩阵 W Q W_Q WQ、 W K W_K WK、 W V W_V WV 由同一输入 X 线性变换得到:
- Q = X W Q Q = X W_Q Q=XWQ
- K = X W K K = X W_K K=XWK
- V = X W V V = X W_V V=XWV
where W Q , W K , W V ∈ R d k × d k W_Q,\, W_K,\, W_V \in \mathbb{R}^{d_k \times d_k} WQ,WK,WV∈Rdk×dk, X ∈ R L dec × d k X \in \mathbb{R}^{L_{\text{dec}} \times d_k} X∈RLdec×dk, Q , K , V ∈ R L dec × d k Q, K, V \in \mathbb{R}^{L_{\text{dec}} \times d_k} Q,K,V∈RLdec×dk.
对于中间层交叉注意力层,
- Q:来自 Decoder 自己------即当前 Decoder 层里、上一层子层(带掩码的自注意力)的输出,表示「当前要生成的位置」在问什么。
- K、V:都来自 Encoder 的最终输出,表示「源序列」的键和值。
上述公式依然没变,但是矩阵的大小有些许变化:
- Q d e c = X d e c W Q Q_{dec} = X_{dec} W_Q Qdec=XdecWQ
- K e n c = X e n c W K K_{enc} = X_{enc} W_K Kenc=XencWK
- V e n c = X e n c W V V_{enc} = X_{enc} W_V Venc=XencWV
where
- W Q , W K , W V ∈ R d k × d k W_Q,\, W_K,\, W_V \in \mathbb{R}^{d_k \times d_k} WQ,WK,WV∈Rdk×dk
- X d e c ∈ R L dec × d k X_{dec} \in \mathbb{R}^{L_{\text{dec}} \times d_k} Xdec∈RLdec×dk, X e n c ∈ R L enc × d k X_{enc} \in \mathbb{R}^{L_{\text{enc}} \times d_k} Xenc∈RLenc×dk
- Q d e c ∈ R L dec × d k Q_{dec} \in \mathbb{R}^{L_{\text{dec}} \times d_k} Qdec∈RLdec×dk, K e n c , V e n c ∈ R L enc × d k K_{enc}, V_{enc} \in \mathbb{R}^{L_{\text{enc}} \times d_k} Kenc,Venc∈RLenc×dk.
这里需要注意,虽然Q矩阵的大小和K/V可能不同,但这并不影响注意力层的计算。也就是说,Encoder 的输出只作为 K 和 V 参与交叉注意力;Q 始终由 Decoder 侧提供 。这样,Decoder 的每个位置用 Q 去「查」Encoder 的 K,得到权重后再对 Encoder 的 V 做加权求和,从而把源序列的信息拉过来用于生成当前词。 A t t e n t i o n ( Q , K , V ) Attention(Q,K,V) Attention(Q,K,V) 的矩阵大小和 Q Q Q 是一样的。
2 更详细的数学推导
2.1 掩码多头自注意力机制的输出计算
我们从 Transformer 8. Decoder: 掩码注意力机制以及数学推导 的最后一部分:掩码多头自注意力机制的输出开始说起:
A t t e n t i o n ( Q , K , V ) = a 1 × 1 v 1 × 1 a 1 × 1 v 1 × 2 ⋯ a 1 × 1 v 1 × 12288 a 2 × 1 v 1 × 1 + a 2 × 2 v 2 × 1 a 2 × 1 v 1 × 2 + a 2 × 2 v 2 × 2 ⋯ a 2 × 1 v 1 × 12288 + a 2 × 2 v 2 × 12288 a 3 × 1 v 1 × 1 + a 3 × 2 v 2 × 1 + a 3 × 3 v 3 × 1 ⋯ ⋯ ⋯ ⋮ ⋮ ⋱ ⋮ ∑ j = 1 1300 a 1300 × j v j × 1 ∑ j = 1 1300 a 1300 × j v j × 2 ⋯ ∑ j = 1 1300 a 1300 × j v j × 12288 ∈ R 1300 × 12288 Attention(Q,K,V) = \begin{bmatrix} a_{1\times1}v_{1\times1} & a_{1\times1}v_{1\times2} & \dotsb & a_{1\times1}v_{1\times12288} \\ a_{2\times1}v_{1\times1}+a_{2\times2}v_{2\times1} & a_{2\times1}v_{1\times2}+a_{2\times2}v_{2\times2} & \dotsb & a_{2\times1}v_{1\times12288}+a_{2\times2}v_{2\times12288} \\ a_{3\times1}v_{1\times1}+a_{3\times2}v_{2\times1}+a_{3\times3}v_{3\times1} & \dotsb & \dotsb & \dotsb \\ \vdots & \vdots & \ddots & \vdots \\ \sum_{j=1}^{1300}a_{1300\times j}v_{j\times1} & \sum_{j=1}^{1300}a_{1300\times j}v_{j\times2} & \dotsb & \sum_{j=1}^{1300}a_{1300\times j}v_{j\times12288} \end{bmatrix} \in \mathbb{R}^{1300 \times 12288} Attention(Q,K,V)= a1×1v1×1a2×1v1×1+a2×2v2×1a3×1v1×1+a3×2v2×1+a3×3v3×1⋮∑j=11300a1300×jvj×1a1×1v1×2a2×1v1×2+a2×2v2×2⋯⋮∑j=11300a1300×jvj×2⋯⋯⋯⋱⋯a1×1v1×12288a2×1v1×12288+a2×2v2×12288⋯⋮∑j=11300a1300×jvj×12288 ∈R1300×12288
(我们设置 L dec = 1300 , d k = 12288 L_{\text{dec}}=1300, d_k=12288 Ldec=1300,dk=12288 )
在这个矩阵中,v上携带的信息的时间点不会超出分数a中携带的信息的时间点,权重和句子信息在交互时都只能与"过去"的信息交互,而不能与"未来"的信息交互。比如,Attention(Q,K,V)的第一行是由 a a a 的第一行( a 1 × 1 a_{1\times1} a1×1)与 v v v 的第一行产生交集(不会涉及到 v v v 的第二,三行),也就是说, a a a 的现在时不会和 v v v 的未来式产生交集。
我们来简化一下上面的这个公式(我们省略了v的列标注,因为我们在下面的公式中需要着重说明v的行标注,对应了时序关系):
C d e c o d e r = a 11 v 1 a 11 v 1 ... a 11 v 1 a 21 v 1 + a 22 v 2 a 21 v 1 + a 22 v 2 ... a 21 v 1 + a 22 v 2 a 31 v 1 + a 32 v 2 + a 33 v 3 a 31 v 1 + a 32 v 2 + a 33 v 3 ... a 31 v 1 + a 32 v 2 + a 33 v 3 ⋮ ⋮ ⋱ ⋮ ∑ j = 1 1300 a 1300 × j v j ∑ j = 1 1300 a 1300 × j v j ⋯ ∑ j = 1 1300 a 1300 × j v j C_{decoder} = \begin{bmatrix} a_{11}v_{1} & a_{11}v_{1} & \ldots & a_{11}v_{1} \\ a_{21}v_{1} + a_{22}v_{2} & a_{21}v_{1} + a_{22}v_{2} & \ldots & a_{21}v_{1} + a_{22}v_{2} \\ a_{31}v_{1} + a_{32}v_{2} + a_{33}v_{3} & a_{31}v_{1} + a_{32}v_{2} + a_{33}v_{3} & \ldots & a_{31}v_{1} + a_{32}v_{2} + a_{33}v_{3} \\ \vdots & \vdots & \ddots & \vdots \\ \sum_{j=1}^{1300}a_{1300\times j}v_{j} & \sum_{j=1}^{1300}a_{1300\times j}v_{j} & \dotsb & \sum_{j=1}^{1300}a_{1300\times j}v_{j} \end{bmatrix} Cdecoder= a11v1a21v1+a22v2a31v1+a32v2+a33v3⋮∑j=11300a1300×jvja11v1a21v1+a22v2a31v1+a32v2+a33v3⋮∑j=11300a1300×jvj.........⋱⋯a11v1a21v1+a22v2a31v1+a32v2+a33v3⋮∑j=11300a1300×jvj
当我们使用覆盖的时间点来作为脚标:
C d e c o d e r = c 1 c 1 ... c 1 c 1 → 2 c 1 → 2 ... c 1 → 2 c 1 → 3 c 1 → 3 ... c 1 → 3 ⋮ ⋮ ⋱ ⋮ c 1 → 1300 c 1 → 1300 ... c 1 → 1300 C_{decoder} = \begin{bmatrix} c_{1} & c_{1} & \ldots & c_{1} \\ c_{1 \to 2} & c_{1 \to 2} & \ldots & c_{1 \to 2} \\ c_{1 \to 3} & c_{1 \to 3} & \ldots & c_{1 \to 3} \\ \vdots & \vdots & \ddots & \vdots \\ c_{1 \to 1300} & c_{1 \to 1300} & \ldots & c_{1 \to 1300} \end{bmatrix} Cdecoder= c1c1→2c1→3⋮c1→1300c1c1→2c1→3⋮c1→1300.........⋱...c1c1→2c1→3⋮c1→1300
比如说, c 1 → 2 = a 21 v 1 + a 22 v 2 c_{1 \to 2}=a_{21}v_{1} + a_{22}v_{2} c1→2=a21v1+a22v2 的下角标包含了 a / v a/v a/v 的序列长度1到2行(可以认真再看一遍 Transformer 8. Decoder: 掩码注意力机制以及数学推导 的数学推导以充分理解这部分内容)。
我们按照上面段落的参数写法,即:
X d e c o d e r = C d e c o d e r X_{decoder} = C_{decoder} Xdecoder=Cdecoder
由于 Q d e c = X d e c W Q Q_{dec} = X_{dec} W_Q Qdec=XdecWQ,而 W_Q 是我们需要训练的矩阵,这里我们可以类比为 C d e c o d e r C_{decoder} Cdecoder 与 Q d e c Q_{dec} Qdec 具备相同的解释意义。
2.2 Encoder模块的输出计算
现在,我们来到 Encoder 的输出。我们假定 L enc = 2000 , d k = 12288 L_{\text{enc}}=2000, d_k=12288 Lenc=2000,dk=12288 (只是一个假设)。
对于 Attention 公式:
A t t e n t i o n ( Q , K , V ) = s o f t m a x ( Q K T d k ) V Attention(Q,K,V) = softmax(\frac{QK^{T}}{\sqrt{d_k}})V Attention(Q,K,V)=softmax(dk QKT)V
这里我们设置:
A = s o f t m a x ( Q K T d k ) A = softmax(\frac{QK^{T}}{\sqrt{d_k}}) A=softmax(dk QKT)
那么 Attention 公式变成了:
A t t e n t i o n ( Q , K , V ) = A V Attention(Q,K,V) = A V Attention(Q,K,V)=AV
where V ∈ R L dec × d k → R 2000 × 12288 V \in \mathbb{R}^{L_{\text{dec}} \times d_k} \rightarrow \mathbb{R}^{2000 \times 12288} V∈RLdec×dk→R2000×12288, A ∈ R d k × d k → R 2000 × 2000 A \in \mathbb{R}^{ d_k \times d_k} \rightarrow \mathbb{R}^{2000 \times 2000} A∈Rdk×dk→R2000×2000。
更加详细的:
A = a 11 a 12 a 13 ... a 1 × 2000 a 21 a 22 a 23 ... a 2 × 2000 a 31 a 32 a 33 ... a 3 × 2000 ⋮ ⋮ ⋱ ⋮ a 2000 × 1 a 2000 × 2 a 2000 × 3 ... a 2000 × × 2000 \text{A} = \begin{bmatrix} a_{11} & a_{12} & a_{13} & \ldots& a_{1\times2000} \\ a_{21} & a_{22} & a_{23} & \ldots& a_{2\times2000} \\ a_{31} & a_{32} & a_{33} & \ldots& a_{3\times2000} \\ \vdots & \vdots & \ddots & \vdots \\ a_{2000\times1} & a_{2000\times2} & a_{2000\times3} & \ldots& a_{2000\times\times2000} \end{bmatrix} A= a11a21a31⋮a2000×1a12a22a32⋮a2000×2a13a23a33⋱a2000×3.........⋮...a1×2000a2×2000a3×2000a2000××2000
同时,V矩阵为(省略了特征维度即列数据,脚标代表的是时间点、seq_len的信息)------
V = v 1 v 1 ... v 1 v 2 v 2 ... v 2 v 3 v 3 ... v 3 ⋮ ⋮ ⋱ ⋮ v 2000 v 2000 ... v 2000 V = \begin{bmatrix} v_{1} & v_{1} & \ldots & v_{1} \\ v_{2} & v_{2} & \ldots & v_{2} \\ v_{3} & v_{3} & \ldots & v_{3} \\ \vdots & \vdots & \ddots & \vdots \\ v_{2000} & v_{2000} & \ldots & v_{2000} \end{bmatrix} V= v1v2v3⋮v2000v1v2v3⋮v2000.........⋱...v1v2v3⋮v2000
由于 C encoder = A × V \text{C}{\text{encoder}} = \text{A} \times V Cencoder=A×V,因此最终的结果矩阵 C encoder \text{C}{\text{encoder}} Cencoder 是:
C encoder = a 11 ⋅ v 1 + a 12 ⋅ v 2 + a 13 ⋅ v 3 + . . . + a 1 × 2000 ⋅ v 2000 a 11 ⋅ v 1 + a 12 ⋅ v 2 + a 13 ⋅ v 3 + . . . + a 1 × 2000 ⋅ v 2000 ... a 11 ⋅ v 1 + a 12 ⋅ v 2 + a 13 ⋅ v 3 + . . . + a 1 × 2000 ⋅ v 2000 a 21 ⋅ v 1 + a 22 ⋅ v 2 + a 23 ⋅ v 3 + . . . + a 2 × 2000 ⋅ v 2000 a 21 ⋅ v 1 + a 22 ⋅ v 2 + a 23 ⋅ v 3 + . . . + a 2 × 2000 ⋅ v 2000 ... a 21 ⋅ v 1 + a 22 ⋅ v 2 + a 23 ⋅ v 3 + . . . + a 2 × 2000 ⋅ v 2000 a 31 ⋅ v 1 + a 32 ⋅ v 2 + a 33 ⋅ v 3 + . . . + a 3 × 2000 ⋅ v 2000 a 31 ⋅ v 1 + a 32 ⋅ v 2 + a 33 ⋅ v 3 + . . . + a 3 × 2000 ⋅ v 2000 ... a 31 ⋅ v 1 + a 32 ⋅ v 2 + a 33 ⋅ v 3 + . . . + a 3 × 2000 ⋅ v 2000 ⋮ ⋮ ⋱ ⋮ a 2000 × 1 ⋅ v 1 + a 2000 × 2 ⋅ v 2 + a 2000 × 3 ⋅ v 3 + . . . + a 2000 × 2000 ⋅ v 2000 a 2000 × 1 ⋅ v 1 + a 2000 × 2 ⋅ v 2 + a 2000 × 3 ⋅ v 3 + . . . + a 2000 × 2000 ⋅ v 2000 ... a 2000 × 1 ⋅ v 1 + a 2000 × 2 ⋅ v 2 + a 2000 × 3 ⋅ v 3 + . . . + a 2000 × 2000 ⋅ v 2000 \text{C}{\text{encoder}} = \begin{bmatrix} a{11} \cdot v_1 + a_{12} \cdot v_2 + a_{13} \cdot v_3 + ... + a_{1\times2000} \cdot v_{2000} & a_{11} \cdot v_1 + a_{12} \cdot v_2 + a_{13} \cdot v_3 + ... + a_{1\times2000} \cdot v_{2000} & \ldots & a_{11} \cdot v_1 + a_{12} \cdot v_2 + a_{13} \cdot v_3 + ... + a_{1\times2000} \cdot v_{2000} \\ a_{21} \cdot v_1 + a_{22} \cdot v_2 + a_{23} \cdot v_3 + ... + a_{2\times2000} \cdot v_{2000} & a_{21} \cdot v_1 + a_{22} \cdot v_2 + a_{23} \cdot v_3 + ... + a_{2\times2000} \cdot v_{2000} & \ldots & a_{21} \cdot v_1 + a_{22} \cdot v_2 + a_{23} \cdot v_3 + ... + a_{2\times2000} \cdot v_{2000} \\ a_{31} \cdot v_1 + a_{32} \cdot v_2 + a_{33} \cdot v_3 + ... + a_{3\times2000} \cdot v_{2000} & a_{31} \cdot v_1 + a_{32} \cdot v_2 + a_{33} \cdot v_3 + ... + a_{3\times2000} \cdot v_{2000} & \ldots & a_{31} \cdot v_1 + a_{32} \cdot v_2 + a_{33} \cdot v_3 + ... + a_{3\times2000} \cdot v_{2000} \\ \vdots & \vdots & \ddots & \vdots \\ a_{2000\times1} \cdot v_1 + a_{2000\times2} \cdot v_2 + a_{2000\times3} \cdot v_3 + ... + a_{2000\times2000} \cdot v_{2000} & a_{2000\times1} \cdot v_1 + a_{2000\times2} \cdot v_2 + a_{2000\times3} \cdot v_3 + ... + a_{2000\times2000} \cdot v_{2000} & \ldots & a_{2000\times1} \cdot v_1 + a_{2000\times2} \cdot v_2 + a_{2000\times3} \cdot v_3 + ... + a_{2000\times2000} \cdot v_{2000} \end{bmatrix} Cencoder= a11⋅v1+a12⋅v2+a13⋅v3+...+a1×2000⋅v2000a21⋅v1+a22⋅v2+a23⋅v3+...+a2×2000⋅v2000a31⋅v1+a32⋅v2+a33⋅v3+...+a3×2000⋅v2000⋮a2000×1⋅v1+a2000×2⋅v2+a2000×3⋅v3+...+a2000×2000⋅v2000a11⋅v1+a12⋅v2+a13⋅v3+...+a1×2000⋅v2000a21⋅v1+a22⋅v2+a23⋅v3+...+a2×2000⋅v2000a31⋅v1+a32⋅v2+a33⋅v3+...+a3×2000⋅v2000⋮a2000×1⋅v1+a2000×2⋅v2+a2000×3⋅v3+...+a2000×2000⋅v2000.........⋱...a11⋅v1+a12⋅v2+a13⋅v3+...+a1×2000⋅v2000a21⋅v1+a22⋅v2+a23⋅v3+...+a2×2000⋅v2000a31⋅v1+a32⋅v2+a33⋅v3+...+a3×2000⋅v2000⋮a2000×1⋅v1+a2000×2⋅v2+a2000×3⋅v3+...+a2000×2000⋅v2000
同样的,当我们使用覆盖的时间点来作为脚标,则有:
C e n c o d e r = c 1 → 2000 c 1 → 2000 ... c 1 → 2000 c 1 → 2000 c 1 → 2000 ... c 1 → 2000 c 1 → 2000 c 1 → 2000 ... c 1 → 2000 ⋮ ⋮ ⋱ ⋮ c 1 → 2000 c 1 → 2000 ... c 1 → 2000 C_{encoder} = \begin{bmatrix} c_{1 \to 2000} & c_{1 \to 2000} & \ldots & c_{1 \to 2000} \\ c_{1 \to 2000} & c_{1 \to 2000} & \ldots & c_{1 \to 2000} \\ c_{1 \to 2000} & c_{1 \to 2000} & \ldots & c_{1 \to 2000} \\ \vdots & \vdots & \ddots & \vdots \\ c_{1 \to 2000} & c_{1 \to 2000} & \ldots & c_{1 \to 2000} \end{bmatrix} Cencoder= c1→2000c1→2000c1→2000⋮c1→2000c1→2000c1→2000c1→2000⋮c1→2000.........⋱...c1→2000c1→2000c1→2000⋮c1→2000
需要再次注意(这里很容易搞混), C e n c o d e r ∈ R L dec × d k → R 2000 × 12288 C_{encoder} \in \mathbb{R}^{L_{\text{dec}} \times d_k} \rightarrow \mathbb{R}^{2000 \times 12288} Cencoder∈RLdec×dk→R2000×12288。这里我们省略了特征维度即列数据。
我们之所以可以将 C e n c o d e r C_{encoder} Cencoder 按照一行一行来看,是因为我们认为: C e n c o d e r C_{encoder} Cencoder携带的是特征矩阵X的信息, C e n c o d e r C_{encoder} Cencoder中的每个元素都携带了全部时间步上的信息,随着行数的增加这段时间窗口越来越长。
2.3 Decoder-Encoder 层计算
首先还是回到注意力公式:
A t t e n t i o n ( Q d e c , K e n c , V e n c ) = s o f t m a x ( Q d e c K e n c T d k ) V e n c Attention(Q_{dec},K_{enc},V_{enc}) = softmax(\frac{Q_{dec}K_{enc}^{T}}{\sqrt{d_k}})V_{enc} Attention(Qdec,Kenc,Venc)=softmax(dk QdecKencT)Venc
- Q d e c = X d e c W Q Q_{dec} = X_{dec} W_Q Qdec=XdecWQ
- K e n c = X e n c W K K_{enc} = X_{enc} W_K Kenc=XencWK
- V e n c = X e n c W V V_{enc} = X_{enc} W_V Venc=XencWV
where
- W Q , W K , W V ∈ R d k × d k → R 12288 × 12288 W_Q,\, W_K,\, W_V \in \mathbb{R}^{d_k \times d_k} \rightarrow \mathbb{R}^{12288\times12288} WQ,WK,WV∈Rdk×dk→R12288×12288
- X d e c ∈ R L dec × d k → R 2000 × 12288 X_{dec} \in \mathbb{R}^{L_{\text{dec}} \times d_k} \rightarrow \mathbb{R}^{2000\times12288} Xdec∈RLdec×dk→R2000×12288
- X e n c ∈ R L enc × d k → R 1300 × 12288 X_{enc} \in \mathbb{R}^{L_{\text{enc}} \times d_k} \rightarrow \mathbb{R}^{1300\times12288} Xenc∈RLenc×dk→R1300×12288
- Q d e c ∈ R L dec × d k → R 2000 × 12288 Q_{dec} \in \mathbb{R}^{L_{\text{dec}} \times d_k} \rightarrow \mathbb{R}^{2000\times12288} Qdec∈RLdec×dk→R2000×12288
- K e n c , V e n c ∈ R L enc × d k → R 1300 × 12288 K_{enc}, V_{enc} \in \mathbb{R}^{L_{\text{enc}} \times d_k} \rightarrow \mathbb{R}^{1300\times12288} Kenc,Venc∈RLenc×dk→R1300×12288
从上面章节,我们可以获得:
C d e c o d e r = c 1 c 1 ... c 1 c 1 → 2 c 1 → 2 ... c 1 → 2 c 1 → 3 c 1 → 3 ... c 1 → 3 ⋮ ⋮ ⋱ ⋮ c 1 → 1300 c 1 → 1300 ... c 1 → 1300 C_{decoder} = \begin{bmatrix} c_{1} & c_{1} & \ldots & c_{1} \\ c_{1 \to 2} & c_{1 \to 2} & \ldots & c_{1 \to 2} \\ c_{1 \to 3} & c_{1 \to 3} & \ldots & c_{1 \to 3} \\ \vdots & \vdots & \ddots & \vdots \\ c_{1 \to 1300} & c_{1 \to 1300} & \ldots & c_{1 \to 1300} \end{bmatrix} Cdecoder= c1c1→2c1→3⋮c1→1300c1c1→2c1→3⋮c1→1300.........⋱...c1c1→2c1→3⋮c1→1300
where C d e c o d e r = X d e c ∈ R 1300 × 12288 C_{decoder} = X_{dec} \in \mathbb{R}^{1300\times12288} Cdecoder=Xdec∈R1300×12288.
由于 Q d e c = X d e c W Q Q_{dec} = X_{dec} W_Q Qdec=XdecWQ,而 c 是我们需要训练的矩阵,这里我们可以类比为 C d e c o d e r C_{decoder} Cdecoder 与 Q d e c Q_{dec} Qdec 具备相同的解释意义。
C e n c o d e r = c 1 → 2000 c 1 → 2000 ... c 1 → 2000 c 1 → 2000 c 1 → 2000 ... c 1 → 2000 c 1 → 2000 c 1 → 2000 ... c 1 → 2000 ⋮ ⋮ ⋱ ⋮ c 1 → 2000 c 1 → 2000 ... c 1 → 2000 C_{encoder} = \begin{bmatrix} c_{1 \to 2000} & c_{1 \to 2000} & \ldots & c_{1 \to 2000} \\ c_{1 \to 2000} & c_{1 \to 2000} & \ldots & c_{1 \to 2000} \\ c_{1 \to 2000} & c_{1 \to 2000} & \ldots & c_{1 \to 2000} \\ \vdots & \vdots & \ddots & \vdots \\ c_{1 \to 2000} & c_{1 \to 2000} & \ldots & c_{1 \to 2000} \end{bmatrix} Cencoder= c1→2000c1→2000c1→2000⋮c1→2000c1→2000c1→2000c1→2000⋮c1→2000.........⋱...c1→2000c1→2000c1→2000⋮c1→2000
where C e n c o d e r = X e n c ∈ R 2000 × 12288 C_{encoder}=X_{enc} \in \mathbb{R}^{2000\times12288} Cencoder=Xenc∈R2000×12288.
由于 K e n c = X e n c W K K_{enc} = X_{enc} W_K Kenc=XencWK, V e n c = X e n c W V V_{enc} = X_{enc} W_V Venc=XencWV,而 W K , W V W_K,W_V WK,WV 是我们需要训练的矩阵,这里我们可以类比为 C e n c o d e r C_{encoder} Cencoder 与 K e n c K_{enc} Kenc 以及 V e n c V_{enc} Venc 具备相同的解释意义。
编码器-解码器注意力层负责整合上面这两部分信息。具体来说,编码器解码器输出的结果结合的方式是------将解码器中的标签信息 C d e c o d e r C_{decoder} Cdecoder作为Q矩阵,将编码器中输出的特征信息 C e n c o d e r C_{encoder} Cencoder作为K和V矩阵,使用每行Q与全部的K、V相乘,来执行一种特殊的注意力机制。
这种特殊注意力机制的公式如下------
Context 1 = ∑ i Attention ( Q 1 , K i ) × V i \text{Context}1 = \sum{i} \text{Attention}(Q_1, K_i) \times V_i Context1=i∑Attention(Q1,Ki)×Vi
Context 2 = ∑ i Attention ( Q 2 , K i ) × V i \text{Context}2 = \sum{i} \text{Attention}(Q_2, K_i) \times V_i Context2=i∑Attention(Q2,Ki)×Vi
Context 3 = ∑ i Attention ( Q 3 , K i ) × V i \text{Context}3 = \sum{i} \text{Attention}(Q_3, K_i) \times V_i Context3=i∑Attention(Q3,Ki)×Vi
... ... ...... ......
Context 1300 = ∑ i Attention ( Q 1300 , K i ) × V i \text{Context}{1300} = \sum{i} \text{Attention}(Q_{1300}, K_i) \times V_i Context1300=i∑Attention(Q1300,Ki)×Vi
在这个公式中,Q与K转置相乘的地方不再是点积、而是按全新的加和规则相乘相加------转换成矩阵则有, C d e c o d e r ( Q ) C_{decoder}(Q) Cdecoder(Q)的第一行(长度为12288)乘以 C e n c o d e r ( K T ) C_{encoder}(K^T) Cencoder(KT)的第一列(长度为12288),加上 C d e c o d e r ( Q ) C_{decoder}(Q) Cdecoder(Q)的第一行乘以 C e n c o d e r ( K T ) C_{encoder}(K^T) Cencoder(KT)的第二列,加上 C d e c o d e r ( Q ) C_{decoder}(Q) Cdecoder(Q)的第一行乘以 C e n c o d e r ( K T ) C_{encoder}(K^T) Cencoder(KT)的第三列......直到所有的列都被乘完为止。
以此类推下去,直到形成新的注意力机制矩阵,后续进入softmax、并与V相乘的流程也类似。你是否注意到,这个注意力机制事实上代表了什么?还记得我们最初说decoder结构的输入与输出吗?
在decoder中我们实际走的训练流程是:
- 第一步,输入ebd_X & ebd_y0 >> 输出yhat0,对应真实标签y0
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------|----------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 输入Decoder 标签矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | | 1 | It | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 2 | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | 3 | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | 4 | best | 0.8342 | 0.2987 | 0.7642 | 0.2154 | 0.9812 | | 5 | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | 6 | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | | 对应 ➡ | 真实标签y | 索引 | | |----|-------| | 0 | It | | 1 | was | | 2 | the | | 3 | best | | 4 | of | | 5 | times | | 6 | "eos" | |
- 第三步,输入ebd_X & ebd_y:2 >> 输出yhat2,对应真实标签y2
|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|------|----------------------------------------------------------------------------------------------------------------------------------------------|
| 输入Encoder 特征矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-----|--------|--------|--------|--------|--------| | 0 | 这 | 0.1821 | 0.4000 | 0.2248 | 0.4440 | 0.7771 | | 1 | 是 | 0.1721 | 0.5030 | 0.8948 | 0.2385 | 0.0987 | | 2 | 最好的 | 0.1342 | 0.8297 | 0.2978 | 0.7120 | 0.2565 | | 3 | 时代 | 0.1248 | 0.5003 | 0.7559 | 0.4804 | 0.2593 | | 输入Decoder 标签矩阵 | 索引 | | y1 | y2 | y3 | y4 | y5 | |----|-------|--------|--------|--------|--------|--------| | 0 | "sos" | 0.5651 | 0.2220 | 0.5112 | 0.8543 | 0.1239 | | 1 | It | 0.5621 | 0.8920 | 0.7312 | 0.2543 | 0.1289 | | 2 | was | 0.2314 | 0.6794 | 0.9823 | 0.8452 | 0.3417 | | 3 | the | 0.4932 | 0.2045 | 0.7531 | 0.6582 | 0.9731 | | 4 | best | 0.8342 | 0.2987 | 0.7642 | 0.2154 | 0.9812 | | 5 | of | 0.3417 | 0.5792 | 0.4821 | 0.6721 | 0.1234 | | 6 | times | 0.2531 | 0.7345 | 0.9812 | 0.5487 | 0.2378 | | 对应 ➡ | 真实标签y | 索引 | | |----|-------| | 0 | It | | 1 | was | | 2 | the | | 3 | best | | 4 | of | | 5 | times | | 6 | "eos" | |
......以此类推下去。很显然,编码器-解码器注意力机制中的数学流程,正是【利用序列X + 序列y的前半段预测序列y的后半段】的计算方式!在这里每一步都是单独的方程,涉及到矩阵中不同的行,因此这里的所有时间步可以并行!本质上实现的是编码器-解码器注意力机制中、下列方程的并行 ↓
Context 1 = ∑ i Attention ( Q 1 , K i ) × V i \text{Context}1 = \sum{i} \text{Attention}(Q_1, K_i) \times V_i Context1=i∑Attention(Q1,Ki)×Vi
Context 2 = ∑ i Attention ( Q 2 , K i ) × V i \text{Context}2 = \sum{i} \text{Attention}(Q_2, K_i) \times V_i Context2=i∑Attention(Q2,Ki)×Vi
Context 3 = ∑ i Attention ( Q 3 , K i ) × V i \text{Context}3 = \sum{i} \text{Attention}(Q_3, K_i) \times V_i Context3=i∑Attention(Q3,Ki)×Vi
所以现在你知道编码器解码器层是如何实现信息整合的了。
现在,我们来总结一下编码器-解码器注意力层的核心作用------
- 关联输入和输出:在许多任务中,输出序列的生成需要依赖于输入序列的特定部分。这层允许模型学习在生成每个输出元素时应关注输入序列的哪些部分。
- 灵活的上下文捕捉:与自注意力层只能处理解码器自身的先前输出不同,编码器-解码器注意力层可以访问整个输入序列的上下文,这对于任务如机器翻译至关重要。
- 增强解码器能力:通过整合来自编码器的信息,这一设计显著增强了解码器处理复杂输入序列并准确生成输出的能力。
总之,编码器-解码器注意力层是Transformer解码器的核心部分,使解码器能够利用编码器处理的完整输入信息,从而生成语义上连贯且上下文相关的输出。