这是作者做的第一个项目,写下这篇博客记录一下实现的过程和一些心得体会。这篇文章开始写于2025-6-22,具体发布日期可能不太清楚。作者本身是一名非科班的研究生,迫于实验室导师的压力以及作者转码还需要学习其他技术栈,所以这篇文章可能实现的时间会比较长,主要会对项目总结和思考过程的记录。鉴于作者是一名非科班的学生,所以如果有一些纰漏或者说的不对的地方,还请各位大佬批评指正
1 前言
基于C语言的单点内存型kv数据库源码项目地址:https://github.com/GDUT-CJL/jl_kvstore.git
目前市面上有很多成熟的数据库产品,如redis、mysql、memcached、rockdb等。数据库(Database)的主要作用是存储、管理和检索数据,以支持各种应用和系统的正常运行。它通常作为一个中间件而存在,是一个独立的进程可用于使用网络连接进行访问。而数据库又可以分为磁盘型数据库和内存行数据库。其主要区别有:
| 特性 | 磁盘数据库 | 内存数据库 |
|---|---|---|
| 存储位置 | 磁盘(硬盘/SSD) | 内存(RAM) |
| 速度 | 较慢(受磁盘IO限制) | 极快 |
| 持久性 | 高(数据存储在磁盘) | 需特殊配置(支持持久化)或易丢失 |
| 数据容量 | 大(受硬盘限制) | 较小(受内存限制,或通过分布式扩展) |
| 典型应用 | 业务系统、持久存储 | 缓存、会话管理、实时分析 |
| 磁盘数据库 | 内存数据库 | |
|---|---|---|
| 使用重点 | 持久化、存储大规模结构化或半结构化数据 | 高速读写、实时处理 |
| 典型场景 | 业务系统、数据仓库、存档、日志 | 缓存、会话、实时分析、排行榜 |
- 磁盘型数据库:主要用于需要持久存储大量数据、对数据可靠性要求高的场景,虽然速度较内存数据库慢,但可以存储海量数据
- 内存型数据库:主要用于对速度和实时性要求极高的场景,虽然容量有限,但速度远超磁盘数据库。
作者当然也是学习了redis数据库的源码之后,产生了想写一个数据库的想法。我们知道redis是一个数据结构数据库且是基于C语言写的,其中实现了很多的数据结构用于提升存储的效率。可以参看作者写的这篇文章描述了redis大致的存储结构Redis相关命令详解及其原理-CSDN博客。因此作者本人,也仿照着redis的结构,想自己动手实现一个内存型的数据库,通过动手实践去更加深入理解redis的复杂系统。

上面是内存数据库jlkvstrore的一个系统的架构图,其实比较简单粗暴。就是通过tcp协议,对客户端请求的命令在协议层进行解析,然后存储到对应的数据结构中。最后再进行一次磁盘持久化的操作。
2 网络层和协议层的实现
2.1网络层reactor实现
redis在处理网络的时候是一个单线程的逻辑。那么一个线程是如何实现高并发的呢?------epoll。诸如redis或其他很多的成熟的网络开源框架其实都是基于epoll的reactor的网络模型进行构建的。对于epoll可以参看下面两篇文章:
主要讲解了epoll的底层实现的原理、epoll的高效性以及为什么可以通过单线程实现高并发。在许多开源的框架中,对于epoll使用最多的就是reactor网络模型,它是一种基于回调的方式的网络模型,可以将网络消息与业务处理逻辑进行分离,从而可以让网络与实际的业务处理逻辑进行解耦,这也是开发中最重要的一个步骤。减少系统的耦合度,能够更加提高系统的稳定性和拓展性。
那么其实我们也可以仿照redis写一个reactor的结构,只要能做到接收到客户端的TCP请求然后根据内容进行调用不同的存储函数即可。一个简易版本的基于epoll的reactor网络模型在我的这篇博客中有实现,源码也在里面,可以参看百万并发 ------ Reactor模型-CSDN博客,而其主要实现的效果就是通过客户端发送相应的set、get指令,服务端可以解析处理即可。
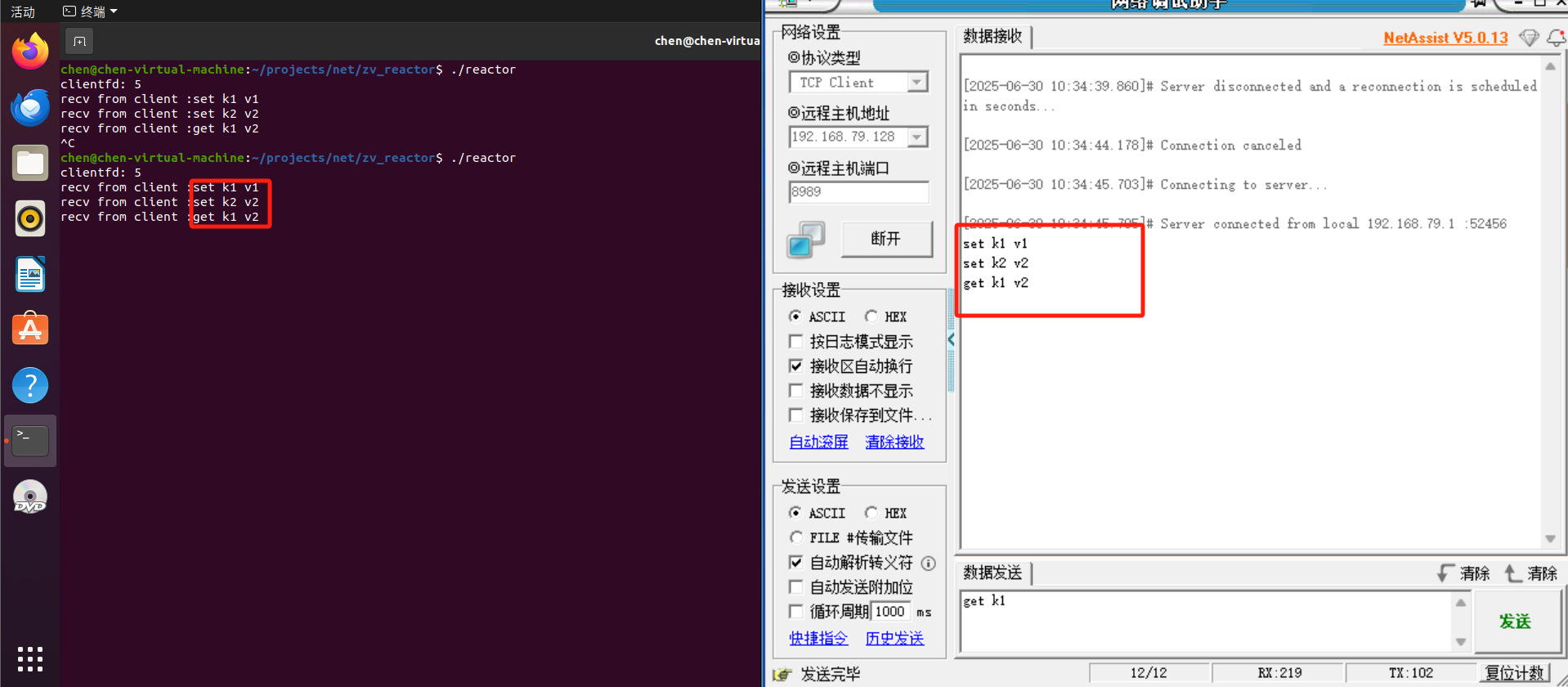
2.2 网络层优化
按照理论来说,由于epoll的底层实现的机制由红黑树+就绪队列两者完成,那么它的并发量就可以达到百万。这是epoll的高效性所决定的。这也是为什么epoll被很多的网络开源框架所使用的重要原因。
但是其实归根节点,epoll的reator网络模型使用I/O多路复用的机制对网络IO的接收和处理还是一个同步的过程。 那么它的性能相对于异步处理还是会差一些。比如我们可以每次建立一个连接,那么就创建一个线程对这个线程进行异步的处理。显然这种处理方式会比reactor模型快,但是这肯定不是个好方案,因为线程创建的代价、调度的代价还是很大的。而且异步的处理方式对应的管理和逻辑也会比较乱。有没有一种方式,即拥有同步的编程方式却又有异步的性能 ------ 协程
在golang中,由于协程的存在使得go语言在处理并发的网络的问题上十分的高效。于是作者通过学习,也想着采用了协程对网络结构进行优化。NtyCo协程框架实现与原理-CSDN博客。其ntyco的网络框架参看了源码:https://github.com/GDUT-CJL/jl_kvstore.git。在上面这篇博客中,作者也进行了性能测试,测试每建立1000个连接所需要的时间来看,协程需要的时间会更短,性能会更优。而最大并发量也能达到30W左右。(这里30W可能是由于作者本人电脑性能比较低,因此达不到更高的并发量)。

2.3 网络层粘包问题
在这里的客户端的连接我们采用简单的TCP发送字符串的格式,类似于Redis 的 RESP的协议。当然我的这个会更加的简便一些,使用TCP的传输肯定会遇到的问题就是TCP的粘包问题,这里可以参看我的这篇博客Tcp粘包分析_tcp通讯粘包-CSDN博客
有这么几种解决方案:
- 以换行符
\n为分隔符 :文本协议 + 换行结尾(如 Redis 的 RESP 协议简化版),按行读取,等待完整的命令行到达后再处理 - 定长消息头 + 消息体(Length-Prefixed):服务器先读 4 字节长度,再读指定长度的内容。
- 自定义分隔符(如
\r\n\r\n):类似 HTTP,用特殊分隔符标记消息结束。 - 使用成熟协议(如 Redis 的 RESP)
其实如果只是单条命令的发送不会发生粘包的问题,因为这里我采用的是对指令进行拆分。如果是set指令,那么通过空格进行拆分,如果拆分的个数不是三个会直接返回错误。如果是get指令,如果拆分的个数不是两个也会直接返回错误。因此,这也是一种防止TCP粘包的手段。
但是在后面引入分布式系统后,我对这个网络层进行优化,采用批量的提交的方式的时候。那么这时候就会出现问题。即多个set指令会一起提交,那么这个时候不进行拆包处理的话就会报错。这里拆包的方式我采用的是以\n换行符进行分隔,相对比较简单而且能够满足项目的需求
3 存储引擎层
对于存储引擎,作者这里实现了5种不同的存储引擎,并且对每个存储引擎的性能做了相应的测试。存储引擎可以进行任意的替换,与网络层解耦。
3.1 array
这里的数组对应与项目源码的kv_array.c和kv_array.h两个文件的内容
cpp
typedef struct kvs_array_item_s{
char* key;
char* value;
long long expired;
}kvs_array_item_t;
typedef struct kvs_array_s{
kvs_array_item_t* array;
int array_count;
pthread_mutex_t array_mutex;
}kvs_array_t;
struct kvs_array_s* array_table;
int init_array();
kvs_array_item_t* kvs_array_search_item(const char* key);
int kvs_array_exist(const char* key);
int kvs_array_set(char* key,char* value);
int kvs_set_array_expired(char* key,char* value,char* cmd,int expired);
char* kvs_array_get(const char* key);
int kvs_array_delete(const char* key);
int kvs_array_count();其实结构也比较简单,就是主要就是set、get、delete、count和exist这5个接口的函数。当然,在这里我还做了一个优化,模仿redis的内存清理,增加了一个kvs_set_array_expired的接口。这个接口可以设置key值存在的时间,命令也和redis的类似
cpp
set key value px/ex 时间采用的惰性清理,会在每次调用set、delete、get之前都进行判断该key对应的时间是否到期,到期就删除
cpp
static void _clean_expired_task(){
#if 1
struct timeval tv;
gettimeofday(&tv,NULL);
long long cur_time = (tv.tv_sec * 1000LL) + (tv.tv_usec / 1000);
for(int i = 0; i < MAX_ARRAY_NUMS; ++i){
kvs_array_item_t* enter = &array_table->array[i];
if(enter->key != NULL && enter->value != NULL){
if(enter->expired != 0 && cur_time > enter->expired){
kvs_free(enter->key);
kvs_free(enter->value);
enter->key = NULL;
enter->expired = 0;
enter->value = NULL;
array_table->array_count--;
}
}
}
#endif
}3.2 btree
对于B树我写在了这篇文章:磁盘存储链式的B树和B+树-CSDN博客
B树的代码比较复杂,作者本人也是借鉴别人的代码: https://github.com/jjejdhhd/kv-store/tree/main/kv-store-v1/btree.c。但是对于b树的结构和原理还是要大概理解。Mysql的存储结构是用到了B+树结构。B树和B+树是有区别的因此弄懂B+树的原理有利于后面的面试,其中需要留意几个点
- B+树的数据结构是为了查找数据所需的磁盘I/O次数更少,因为B+树内部只存储键值,从而可以存储更多的数据减少树的高度
- B+树是多叉平衡搜索树,因此层高与一些AVL树相比会低很多,因此磁盘寻址的时间也会大大降低。虽然B+树一个节点存储多个数据,但是一个节点的多个数据是连续的因此不会耗费太多时间
- B+树的所有叶子节点连接成为一个双向链表,方便范围查询以及减少查询的时间
3.3 rbtree
对于红黑树的原理,可以参看我的这篇博客红黑树底层实现-CSDN博客
红黑树的原理其实相对而言比较简单,主要是红黑节点的平衡算法,记住口诀"左根右、根叶黑、不红红、黑路同"。至于红黑树,个人觉得比较重要的就是红黑树的性质和使用的场景
使用场景:
- C++ STL中map和set的底层实现
- 进程调度cfs(用红黑树存储进程集合,把调度时间作为key,那么在整个树的最左下角的节点就是最小时间)
- 内存管理(每次malloc的时候都会分配一块小内存,那么这块内存就是用红黑树来存储的,如何表述一块内存呢?用开始地址+长度来表示,所以key->开始地址,val->大小)
- epoll中使用红黑树管理对于时间(key->fd,value->对应节点的结构体)
- nginx使用红黑树管理定时器,中序遍历第一个就是最小的定时器
|---------|-------------------|---------|------------|
| 特性 | 红黑树 | AVL树 | B树/B+树 |
| 平衡程度 | 较松(近似平衡) | 严格平衡 | 多路平衡 |
| 插入/删除性能 | 较快(旋转少) | 较慢(旋转多) | 适合磁盘,插入较复杂 |
| 查找性能 | 稍慢(树略高) | 更快(树更矮) | 适合大块数据 |
| 应用场景 | 内存数据结构(如 map/set) | 高频查找场景 | 数据库、文件系统 |
| 实现复杂度 | 中等 | 较高 | 高 |
3.4 hash
对于hash函数的使用,可以参看我的这篇文章海量数据去重的hash-CSDN博客
同样,也需要比较关注的是hash算法的性质和使用场景
使用场景:
- 使用 word 文档时,word 判断某个单词是否拼写正确
- 网络爬虫程序让它不去爬相同的 url 页面
- 垃圾邮件过滤算法
- 缓存穿透问题解决(布隆过滤器)
- 负载均衡与分布式系统(如redis)
优势(性质):
|--------------|--------------------------------------------|
| 优势 | 说明 |
| 高效性 | 哈希计算速度快,通常为 O(n),适合实时处理大量数据。 |
| 固定长度输出 | 无论输入多长,输出长度固定(如 SHA-256 输出 256 位),便于存储和比较。 |
| 确定性 | 相同输入 always 产生相同输出,保证可重复性。 |
| 雪崩效应 | 输入微小变化会导致输出巨大差异,增强安全性。 |
| 单向性(不可逆) | 无法从哈希值反推出原始输入,保护敏感信息。 |
| 抗碰撞性 | 很难找到两个不同输入产生相同哈希值(理想情况下),防止伪造。 |
3.5 skiplist
对于跳表的内容,在我的博客Redis存储原理与数据模型-CSDN博客中最后一章节有讲解到部分内容。
使用场景:
- Redis 使用跳表(结合哈希表)实现
Sorted Set(ZSet)- 支持按分数(score)快速插入、删除、查找;
- 支持范围查询(如
ZRANGE、ZREVRANK); - 实现比红黑树更简单,调试和维护成本低。
- 内存数据库或 LSM-Tree 架构中的内存表(如 LevelDB、RocksDB 的
MemTable)使用跳表- 数据在内存中有序存储;
- 支持高效的插入、查找和顺序遍历;
- 相比 B+ 树,跳表在并发环境下更容易实现无锁(lock-free)版本。
- 实时系统中的优先队列或定时器管理
- 需要按时间戳或优先级排序的任务调度。
- 支持快速插入、删除和查找最小/最大元素,且可扩展为支持范围操作。
|---------------|--------------------------------------------------|
| 优势 | 说明 |
| 实现简单 | 相比红黑树、AVL 树等平衡树,跳表逻辑清晰,代码易于理解和维护。 |
| 平均时间复杂度优秀 | 查找、插入、删除的平均时间复杂度为O(log n),最坏情况接近 O(n),但概率极低。 |
| 支持范围查询高效 | 中序遍历天然有序,适合ZRANGE、ZREVRANK等操作。 |
| 动态扩展性强 | 层级是随机生成的,无需复杂旋转或重新平衡操作。 |
| 良好的缓存局部性 | 相比指针复杂的树结构,跳表的链表结构在内存中更连续,缓存命中率较高。 |
| 天然支持并发 | 可基于 CAS 实现高效的无锁并发跳表,适合高并发场景。 |
| 可定制性强 | 可灵活调整层数概率(如 p=1/2 或 1/4),平衡空间与时间性能。 |
3.6 rocksdb
对于rocksdb的内容可以参看我的这篇博客不一样的KV存储 ------ Rocksdb-CSDN博客
rocksdb的底层使用的是LSM-Tree结构,将这部分的内容封装引入到该项目其一是为了接下来的分布式数据库做铺垫,我们知道Tidb数据库就是使用了rocksdb的存储引擎。其次就是为了进行对比rocksdb存储引擎和上面几个存储引擎的性能比较。
使用rocksdb最好的地方是rocksdb是一个嵌入式的存储引擎,能够直接使用嵌入在本项目的数据库中,且内部自带落盘和持久化的功能,不需要另外实现。
封装的接口如下:
cpp
#pragma once
struct rocks_obj* rocksdb_obj;
// 初始化 RocksDB
int init_Rocksdb();
// 关闭并清理 RocksDB 资源
void close_Rocksdb(struct rocks_obj* obj);
// 设置键值对
int kvs_rocksdb_set(struct rocks_obj* obj, const char* key, const char* value);
// 获取键值对
char* kvs_rocksdb_get(struct rocks_obj* obj, const char* key);
// 删除键值对
int kvs_rocksdb_delete(struct rocks_obj* obj, const char* key);
// 创建备份
int kvs_rocksdb_create_backup(struct rocks_obj* obj) ;
// 批量写入接口
int kvs_rocksdb_batch_set(struct rocks_obj* obj, const char** keys, const char** values, int count);使用场景:
|--------------------|-----------------|
| 场景 | 是否适合rocksdb |
| 高频写入(如日志、事件) | ✅ 非常适合 |
| 大量随机读写 | ✅ 支持良好 |
| 需要持久化本地状态 | ✅ 理想选择 |
| 分布式数据库底层存储 | ✅ 广泛使用 |
| 需要嵌入式、轻量级存储 | ✅ 优势明显 |
| 需要复杂查询(如 SQL、Join) | ❌ 不适合(非关系型) |
| 需要多节点共享访问 | ❌ 是单机引擎,不支持网络共享 |
rocksdb的使用其实最主要注意的是读放大、写放大以及空间放大的问题,关键是针对不同的业务场景进行性能调优,作者目前还没有对这些调优参数进行深入的理解,等以后在实现分布式数据库时再进行研究。
4 存储层
对于存储层的实现我也参考了redis的aof的刷盘策略,即使用异步的方式进行刷盘。我这里使用一个线程池,将刷盘的函数在线程池中执行。线程池的实现可以参看我的这个博客纯C手写线程池-CSDN博客
cpp
// 统一的刷盘函数,减少文件打开和关闭的次数
static int flush_to_disk(FILE* file, const char* format, const char* key, const char* value) {
if (key != NULL && value != NULL) {
fprintf(file, format, key, value);
}
return 0;
}
int flush_array(FILE* file) {
for (int i = 0; i < MAX_ARRAY_NUMS; ++i) {
flush_to_disk(file, "set %s %s\n", array_table[i].array->key, array_table[i].array->value);
}
return 0;
}
void flush_hash(FILE* file) {
for(int i = 0; i < Hash->max_slots; ++i) { // 遍历到最大槽位
hashnode_t* node = Hash->nodes[i];
while(node != NULL) {
flush_to_disk(file, "hset %s %s\n", node->key, node->value);
node = node->next;
}
}
}
void btree_flush_node(btree_node *cur, FILE* file) {
if (cur == NULL) return;
// 写入当前节点的键值对
for (int i = 0; i < cur->num; i++) {
flush_to_disk(file, "bset %s %s\n", cur->keys[i], cur->values[i]);
}
// 递归遍历子节点
if (cur->leaf == 0) {
for (int i = 0; i < cur->num + 1; i++) {
btree_flush_node(cur->children[i], file);
}
}
}
void flush_btree(FILE* file) {
if (kv_b.root_node != NULL) {
btree_flush_node(kv_b.root_node, file);
}
}
void flush_rbtree(RBNode* root, FILE* file) {
if (root != NIL) {
flush_to_disk(file, "rset %s %s\n", root->key, root->value);
flush_rbtree(root->left, file);
flush_rbtree(root->right, file);
}
}
void flush_skiplist(FILE* file){
skipnode_t* cur_node = sklist->head->next[0];
while (cur_node != NULL) {
flush_to_disk(file, "zset %s %s\n", cur_node->key, cur_node->value);
cur_node = cur_node->next[0];
}
}
void flush_dhash(FILE* file){
for(int i = 0; i < dhash.capacity; ++i){
if(dhash.buckets[i] != NULL){
flush_to_disk(file,"dset %s %s\n",dhash.buckets[i]->key,dhash.buckets[i]->value);
}
}
}
void kv_flush_to_disk(){
FILE* file = fopen(PATH_TO_FLUSH_DISK_TXT, "w");
if(file == NULL){
perror("fopen");
return;
}
flush_array(file);
flush_skiplist(file);
flush_hash(file);
flush_btree(file);
flush_rbtree(root, file);
flush_dhash(file);
fflush(file);
fclose(file);
}
void kv_flush_thread(void* arg){
while(1){
sleep(1);
kv_flush_to_disk();
}
}刷盘的逻辑比较简单,性能相对而言也不是很高,因为这是使用的文本格式进行刷盘的,主要是为了数据恢复的时候可以直接读取文本文件解析出对应的指令进行恢复,进一步的优化策略可以刷盘为二进制的文件,然后恢复时通过读取二进制文件进行恢复,这样性能相对会比较好一些
5 性能测试
下面测试的是各个存储引擎的QPS,使用测试用例想每个存储引擎发送10W的set指令,看每种存储引擎所花费的时间和qps
|----------|-----------------|---------|
| 存储引擎 | 花费时间 | qps |
| 数组 | 60911.000000 ms | 1641.74 |
| 红黑树 | 10893.000000 ms | 9180.21 |
| 哈希表(拉链法) | 12366.000000 ms | 8086.69 |
| 跳表 | 26556.000000 ms | 3765.63 |
| B树 | 13841.000000 ms | 7224.91 |
| 哈希表(寻址法) | 12316.000000 ms | 8119.52 |
| rocksdb | 11841.000000 ms | 8445.23 |
注意:其中rocksdb使用的是禁用写入WAL的方式测试,以对比将数据写入到内存中的速度,不使用刷盘的策略