目录
[一、HTTP 协议基础](#一、HTTP 协议基础)
[1. URL 构成](#1. URL 构成)
[2. 路径](#2. 路径)
[3. 字符处理](#3. 字符处理)
[4. 请求构成](#4. 请求构成)
[5. 应答构成](#5. 应答构成)
[6. 状态码分类](#6. 状态码分类)
[7. 常见报头属性](#7. 常见报头属性)
[8. 重定向](#8. 重定向)
[二、HTTP 通信代码实现](#二、HTTP 通信代码实现)
[1. 主逻辑](#1. 主逻辑)
[2. 请求反序列化](#2. 请求反序列化)
[3. 获取文件后缀与 Content-Type](#3. 获取文件后缀与 Content-Type)
[4. 获取响应内容](#4. 获取响应内容)
[5. 响应序列化](#5. 响应序列化)
[三、HTTP 动态交互](#三、HTTP 动态交互)
[1. 浏览器标准](#1. 浏览器标准)
[2. 两种提交方式](#2. 两种提交方式)
[3. GET 参数处理代码](#3. GET 参数处理代码)
[4. GET 与 POST 的优缺点](#4. GET 与 POST 的优缺点)
[5. 其他 HTTP 方法(基本不用)](#5. 其他 HTTP 方法(基本不用))
[1. 短连接 vs 长连接](#1. 短连接 vs 长连接)
[2. 连接与状态](#2. 连接与状态)
[3. Cookie](#3. Cookie)
[4. Session](#4. Session)
一、HTTP 协议基础
1. URL 构成
URL 格式 :域名 + 路径
-
域名:通过 DNS(域名服务器)找到对应的 IP 地址
-
端口:HTTP 协议端口号固定
-
HTTP:80
-
HTTPS:443
-
-
服务器定位:IP + 端口就可以找到对应的服务器
URL 通信的本质就是 HTTP 通信。
2. 路径
上网的本质:向远端发送数据,数据传到远端服务器。
路径对应 Linux 服务器上的文件路径。当没有人获取文件时,资源就在服务器内部。
通过 IP + 端口 + 路径 就可以获取全网唯一的文件。
3. 字符处理
在浏览器搜索框中输入内容时,特殊字符(如 /、:、? 等)会被自动编码。

原因 :/、: 等是 HTTP 协议的特殊字符,如果直接放在 URL 中会导致解析错误。
-
客户端(浏览器):自动进行 URL 编码
-
服务器端:需要自动进行 URL 解码
浏览器和服务器通信的模式称为 B/S 模式(Browser/Server)。
4. 请求构成
HTTP 请求由以下部分组成:
-
请求行:方法 + URI + HTTP 版本
-
请求报头 :一系列的
Key: Value键值对,描述 HTTP 请求的属性 -
空行:分隔报头和正文
-
正文:请求携带的数据(可选)
5. 应答构成
HTTP 应答由以下部分组成:
-
状态栏:HTTP 版本 + 状态码 + 状态码描述
-
响应报头 :一系列的
Key: Value键值对 -
空行:分隔报头和正文
-
正文:响应的数据
URI 说明:
-
URI 默认为
/,表示请求首页 -
服务器可能会在路径前加上根目录(如
./wwwroot),找到对应的文件 -
如果请求的是目录,服务器会自动拼接首页文件名(如
index.html)
请求方法:
-
GET:从远端获取资源 -
POST:向远端推送数据
版本号:服务器需要服务不同版本的客户端,因此需要版本号来兼容。
6. 状态码分类
| 状态码范围 | 类别 | 说明 |
|---|---|---|
| 1xx | 信息性状态码 | 接受的请求正在处理 |
| 2xx | 成功状态码 | 请求处理完毕 |
| 3xx | 重定向状态码 | 需要跳转到其他页面 |
| 4xx | 客户端错误状态码 | 客户端请求错误(如 404 不存在) |
| 5xx | 服务器错误状态码 | 服务器内部错误 |
7. 常见报头属性
-
Content-Type:数据报类型(如text/html、image/jpeg) -
User-Agent:用户信息(浏览器类型、操作系统等),可用于推荐合适的软件版本 -
Accept-Encoding:客户端支持的压缩算法 -
Referer:之前访问的页面(来源页) -
wget:命令行工具,用于获取网页
8. 重定向
临时重定向(302):
-
不会更改客户端书签
-
仅仅做页面跳转
-
客户端可能会多次访问原地址(如商店临时换位置)
永久重定向(301):
-
客户端应该更新书签
-
之后不再访问原地址
-
对搜索引擎的作用:收到 301 状态码后,会在内部更新索引地址
二、HTTP 通信代码实现
1. 主逻辑
cpp
void handelquest(std::shared_ptr<mysocket>& sock, addr& ad) {
std::string queststr;
int n = sock->receive(&queststr);
if (n > 0) {
httprequest req;
req.deserialize(queststr); // 反序列化请求
httpresponse resp;
resp._version = "HTTP/1.1";
resp._code = 200;
resp._desc = "OK";
std::string uri = req.uri();
resp.settar(uri); // 设置目标文件
resp.questresponse(); // 获取响应内容
std::string retresponse = resp.serialize(); // 序列化响应
LOG(LogLevel::DEBUG) << retresponse;
sock->sendmsg(retresponse); // 发送响应
}
}2. 请求反序列化
按行读取:
cpp
static bool readoneline(std::string& bigstring, std::string* out, std::string sep = "\r\n") {
size_t pos = bigstring.find(sep);
LOG(LogLevel::DEBUG) << "分隔第一行结果:" << pos;
if (pos == std::string::npos) return false;
*out = bigstring.substr(0, pos);
bigstring.erase(0, pos + sep.size());
return true;
}解析请求行:
cpp
void praseline(std::string& line) {
std::stringstream ss(line);
ss >> _methord >> _uri >> _version;
}完整反序列化:
cpp
bool deserialize(std::string& line) {
std::string queline;
util::readoneline(line, &queline);
LOG(LogLevel::INFO) << "分开第一行:" << queline;
praseline(queline);
LOG(LogLevel::DEBUG) << "_methord: " << _methord;
LOG(LogLevel::DEBUG) << "_uri: " << _uri;
LOG(LogLevel::DEBUG) << "_version: " << _version;
// 处理根路径
if (_uri == "/") {
_uri = rootpath + _uri + pagehome;
LOG(LogLevel::DEBUG) << "_uri: " << _uri;
} else {
_uri = rootpath + _uri;
}
return true;
}3. 获取文件后缀与 Content-Type
cpp
std::string getsuffix(const std::string& file) {
size_t pos = file.rfind(".");
if (pos == std::string::npos) {
LOG(LogLevel::WARNING) << "没找到后缀";
return "";
}
std::string suffix = file.substr(pos);
LOG(LogLevel::DEBUG) << "找到后缀:" << suffix;
// 建立后缀到 Content-Type 的映射
if (suffix == ".html" || suffix == ".htm")
return "text/html";
else if (suffix == ".jpg")
return "image/jpeg";
else if (suffix == ".png")
return "image/png";
else
return "";
}4. 获取响应内容
cpp
bool questresponse() {
bool ret = util::get_content(_tarfile, &_text);
if (ret) {
// 找到文件
setcode(200);
int filesize = util::filesize(_tarfile);
setheader("Content-Length", std::to_string(filesize));
setheader("Content-Type", getsuffix(_tarfile));
LOG(LogLevel::INFO) << "文件大小" << filesize;
return true;
} else {
// 文件不存在,返回 404 页面
setcode(404);
_tarfile = rootpath + page404;
util::get_content(_tarfile, &_text);
int filesize = util::filesize(_tarfile);
setheader("Content-Length", std::to_string(filesize));
setheader("Content-Type", getsuffix(_tarfile));
LOG(LogLevel::INFO) << "404路径" << _tarfile;
LOG(LogLevel::WARNING) << "404";
LOG(LogLevel::INFO) << "404大小" << filesize;
return false;
}
}5. 响应序列化
cpp
std::string serialize() {
std::ostringstream oss;
// 状态行
oss << _version << " " << _code << " " << _desc << "\r\n";
LOG(LogLevel::DEBUG) << _version << " " << _code << " " << _desc;
// 响应报头
for (const auto& header : _headers) {
oss << header.first << ": " << header.second << "\r\n";
}
// 空行
if (!_blankline.empty()) {
oss << _blankline;
} else {
oss << "\r\n";
}
// 正文
oss << _text;
return oss.str();
}三、HTTP 动态交互
1. 浏览器标准
浏览器是流量的入口,各家浏览器有自己的技术特点,因此需要统一的标准。但标准的执行情况并不理想。
2. 两种提交方式
GET 方式:
-
在 URL 中提交参数
-
格式:
/路径?参数1=值1&参数2=值2 -
示例:
/register?reg_user=111®_email=111%401.com®_pw=111
POST 方式:
-
在请求正文中提交参数
-
不回显,相对更私密
3. GET 参数处理代码
路由注册:
cpp
using http_func_t = std::function<void(httprequest& quest, httpresponse& response)>;
std::unordered_map<std::string, http_func_t> _route;
void enquefunc(std::string rout, http_func_t func) {
_route[rout] = func;
}解析请求行中的参数:
cpp
bool deserialize(std::string& line) {
std::string queline;
util::readoneline(line, &queline);
LOG(LogLevel::INFO) << "分开第一行:" << queline;
praseline(queline);
// 查找问号,判断是否有参数
size_t p2 = queline.find('?');
if (p2 == std::string::npos) {
LOG(LogLevel::DEBUG) << "没找到问号";
// 处理普通文件请求
if (_uri == "/") {
_uri = rootpath + _uri + pagehome;
} else {
_uri = rootpath + _uri;
}
return true;
} else {
LOG(LogLevel::DEBUG) << "找到问号";
_istxec = 1; // 标记为需要执行
_args = queline.substr(p2 + 1); // 提取参数字符串
size_t p1 = queline.find('/');
_uri = queline.substr(p1, p2 - p1); // 提取路径部分
return true;
}
}4. GET 与 POST 的优缺点
GET:
-
优点:方便、直观
-
缺点:有长度限制(URL 长度限制),参数在 URL 中暴露
POST:
-
优点:可传输长数据,参数不回显,相对更私密
-
缺点:实现稍复杂
安全性:两种方式传输的数据都不加密。现在的 HTTPS 先加密数据再传输,解决安全问题。
5. 其他 HTTP 方法(基本不用)
| 方法 | 作用 |
|---|---|
| PUT | 传输文件,将指定文件放到 URL 指定位置 |
| HEAD | 仅返回报头,用于测试服务器是否可用 |
| DELETE | 删除文件 |
| OPTIONS | 查询服务器支持的方法 |
四、长连接与状态管理
1. 短连接 vs 长连接
一个网页包含 3 张图片时,上面的代码会发起 4 次请求:
-
1 次请求 HTML 页面
-
3 次请求图片资源
每次请求都要创建进程、拷贝内容、发送,开销很大。这是短连接,HTTP/1.0 使用较多。
HTTP/1.1 长连接:
-
可以一次连接发送多个请求和响应
-
提高效率
实现:
-
客户端在请求报头中加入:
Connection: keep-alive -
服务器在响应报头中也返回:
Connection: keep-alive -
之后就可以用同一个 TCP 连接通信
由于 HTTP 协议固定有空行分隔,服务器可以拆分出多个报头,连续读到多个报文。
2. 连接与状态
HTTP 协议的特点:
-
无连接:每次请求处理完就断开连接(逻辑上)
-
无状态:服务器不记忆任何客户端信息
注意:长短连接不是 HTTP 协议做的,而是由服务器和底层的 TCP 协议决定。
-
长连接时,服务器决定积累多个响应后再通过 HTTP 发送
-
这不是 HTTP 协议自己决定的
3. Cookie
HTTP 是无状态的,但网站只需要登录一次就能持续使用,这靠 Cookie 实现。
服务端设置 Cookie:
cpp
setheader("Set-Cookie", "username=john; Path=/");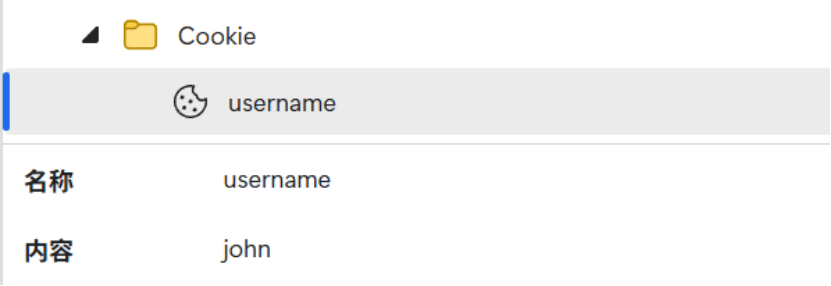
添加这行代码后,浏览器会存储对应的 Cookie。

后续请求中,浏览器会自动带上 Cookie:
Cookie 的属性:
-
Path:指定 Cookie 生效的路径 -
Expires:过期时间(不设置则默认为会话 Cookie,浏览器关闭即失效)
4. Session
Cookie 存储在本地,可能因木马、病毒等泄露。
Session 机制:
-
将用户信息存储在服务器端的 Session 节点中
-
本地只保存一个 Session ID
-
用户使用时携带 Session ID,服务器通过 ID 查找用户信息
安全性增强:
-
服务器可以用 IP 溯源
-
地址变更、异常登录检测等方式守护信息安全
-
即使 Cookie 被窃取,没有对应的服务器 Session 数据也无法登录